
深度学习刚性点云配准前沿进展
2022-02-28 07:31:40秦红星刘镇涛谭博元
中国图象图形学报 2022年2期
秦红星,刘镇涛,谭博元
1.重庆邮电大学计算机科学与技术学院, 重庆 400065; 2.重庆大学计算机学院, 重庆 400030
0 引 言
2010年至2020年期间,3维扫描设备的普及呈现出加速趋势,造成点云数据的急剧增长,推动了深度学习3维视觉领域的迅速发展。学者们从不同角度对该领域的发展做出了总结。Guo等人(2021)针对深度学习在3D点云领域的应用给出了综述。龙霄潇等人(2021)对3维视觉的前沿领域进行了系统的综述。点云配准是将两个或多个相机坐标系下的点云数据转换到世界坐标系完成拼接的过程,是3维视觉中的一项重要任务。比如:在3维重建中,通常利用扫描设备获取场景的局部信息,通过点云配准完成对整个场景的重建。在高精度地图与定位中,通过车辆行驶过程中采集到的局部点云片段配准到提前制作好的场景地图中,可以完成车辆的高精度定位。此外,点云配准还在位姿估计、机器人和医疗等领域得到了大量的应用。
以ICP(iterative closest point)(Besl和McKay,1992)、NDT(normal distributions transform)(Biber和Strasser,2003)和4PCS(4-points congruent sets)(Aiger等,2008)等为代表的传统方法已经在各个领域得到广泛应用,然而这些方法大多对噪声、异常点、低重叠和初始位姿敏感。另外,Johnson和Hebert(1999)、Frome等人(2004)、Rusu等人(2008,2009)、Salti等人(2014)设计了人工编码特征用于全局配准,这些方法通常统计空间坐标、曲率、法向量等几何属性得到直方图,然后通过人工编码得到几何特征,这种方式容易受到噪声、异常点的影响,特征匹配效率不高。对于传统方法,Cheng等人(2018)、Saiti和Theoharis(2020)给出了更为详尽的总结。在现实世界的点云数据采集过程中,存在着大量的噪声、异常点和较低的重叠,对传统方法带来了极大的挑战。近年来,深度学习在点云配准领域广泛应用并取得显著成效,引起了研究者广泛的兴趣。
本文旨在为深度学习刚性点云配准领域提供全面的综述。为方便起见,将基于深度学习的刚性点云配准称为深度点云配准。目前仅有少量综述性文章对深度学习点云配准研究进行了分析和总结。Huang等人(2021b)将点云配准分为同源配准和跨源配准,对传统方法、基于深度学习的方法进行了综述。Zhang等人(2020)对近年来深度学习方法进行了综述,但没有对算法进行明确的区分,并且缺乏完整的统一基准的对比参考数据。另外,Bello等人(2020)对体素点云数据、原始点云上的学习进行了综述,但只涉及点云特征提取部分。与前人的工作相比,本文的主要贡献在于:聚焦于深度学习点云配准,综合最新出现的参考文献,从算法的主要功能出发,对算法重新进行了分类和总结,重点阐述了最新出现的方法和发展趋势;将配准过程划分为不同的阶段,对不同算法在相同阶段中的处理方式进行了详细阐述并使用表格进行归纳,然后总结其优劣;对以往综述工作做出补充,详细介绍了多种度量指标并总结同类指标的差异,汇总了在不同基准下的较为详细的对比数据,并提供分析和总结。
1 点云配准问题概述
给定两个点云:源点云X={xi∈R3|i=1,…,N}和目标点云Y={yj∈R3|j=1,…,M}。其中,N与M分别为源点云和目标点云点的数量。点云配准的目标是求解源点云X到目标点云Y在世界坐标系下的相对变换,包括旋转矩阵R∈SO(3)和平移向量t∈R3,其中SO(3)为3维旋转群。点云配准可以描述为一个均方误差最小化问题
(1)
式中,ym表示任意点xi∈X在目标点云Y中的对应点(correspondence)。式(1)可以通过奇异值分解(singular value decomposition,SVD)求解R和t,然而对应点ym通常是未知的,在求解变换之前,需要建立逐点的对应关系
(2)
因此,式(1)与式(2)是一个典型的鸡和蛋的问题,式(2)的求解依赖于已知的R和t,而这恰好是式(1)求解的目标。在传统方法中,典型的ICP算法假设初始R=I并且t=0,首先在欧氏空间中使用最近邻操作来建立对应关系m,然后利用式(1)求解刚性变换,循环以上两个过程直到收敛。这样的解决方案通常会导致算法对初始位姿敏感。

随着深度学习在点云配准领域的应用,出现了一批不需要依靠对应关系的方法,本文将其称为无对应配准方法。无对应配准方法的关键问题在于如何利用网络学习一个从点云到全局特征的映射φ:R3×N→RK,并且寻找合适的旋转R和平移t使得φ(Y)=φ(RX+t),其中K表示全局特征的维度。
点云配准是一个典型的流水线处理过程,其流程如图1所示。在图1中,预处理过程通常用于对原始点云数据进行降噪、去异常值、去除非重叠区域和采样处理;另外,基于对应关系的点云配准在特征提取后还需要进行额外的特征匹配步骤来获得点对。
图1 深度点云配准流水线过程Fig.1 Pipeline process of deep point cloud registration
根据有无借助对应关系,本文将现有研究分为基于对应关系的深度点云配准和无对应配准分别进行介绍。目前该领域对跨源点云的研究较少,因此不再对其进行划分。
2 基于对应关系的深度点云配准
目前研究者们在合成数据与真实数据上都展开了研究,相比合成数据而言,真实数据的表面点拓扑结构更加复杂,并且点的数量更多,对鲁棒性的要求更高,许多研究者将真实数据上的点云配准拆分为多个子问题进行研究。而在合成数据中,现有的研究大多采用了端到端方法。为了方便对比,本文按照各个方法的主要功能,即特征提取、关键点检测、离群点对去除、姿态估计和端到端点云配准进行分类。相关代表方法整理如表1所示。
2.1 特征提取
在基于对应关系的点云配准中,学习鉴别力高的特征表示是配准好坏的关键。点云中包含丰富的空间几何信息,以合理的方式组织点云,从点云中提取更多的信息,才能丰富特征的辨识度。因此,如何从无组织的点云中提取更多的具有辨识度的信息是特征提取最受关注的问题。近年来,研究者们提出大量基于深度学习的特征提取方法,按照它们的特点,分为以下两种类型: 1)基于局部块(local patch)的特征提取;2)基于卷积的特征提取。
Qi等人(2017a)提出了PointNet,这是第1个直接在输入点云上提取特征的网络。PointNet主要解决了点云的无序性、置换不变性和旋转不变性问题。对于输入的无序点云,使用多层感知机(multilayer perceptrons,MLPs)分别对每个点提取特征,然后使用对称函数(最大池化)来达到置换不变的目的,最后使用T-net(transformation network)预测一个刚性变换矩阵,用于满足旋转不变性。
PointNet无法捕获空间点的语义信息,限制了特征的通用性。此外,由MLPs学习而来的网络无法处理密度不均匀的点云数据。Qi等人(2017b)进一步提出了PointNet++,针对以上问题进行了改进。PointNet++引入了一个由最远点采样层、分组层以及PointNet层组成的层次化结构来捕捉不同尺度的上下文信息。为了提高在不同密度下采样的性能,提出了多尺度聚合和多分辨率聚合,用于提取多个尺度的局部模式,并根据点密度进行自适应组合,最终得到密度自适应特征。
PointNet与PointNet++没有关注点与点之间的几何关系,限制了特征的表示能力,因而不能直接应用于点云配准领域。但其为解决点云特征提取中存在的无序性、密度变化、置换不变性和旋转不变性等问题提供了有效参考,促进了后续研究的开展。

表1 基于对应关系配准的典型方法Table 1 Typical methods of registration based on correspondence
2.1.1 基于局部块的特征提取
为了解决点云的无组织性问题,一些研究者利用体素、包围球和K最近邻(K-nearest neighbor,KNN)等方式对点云进行组织,以提取更为丰富的局部几何特征,这些方法通常称为基于局部块的方法。
Khoury等人(2017)提出一种紧凑几何特征(compact geometric features,CGF),通过在点上建立一个包围球,建立局部参考框架(local reference frame,LRF)得到描述局部邻域中点分布的直方图,然后训练一个神经网络将输入的直方图映射到一个低维的欧氏空间得到更紧凑的几何特征描述符。
Deng等人(2018b)提出了PPFNet。首先对采样点的局部邻域计算点对特征(point pair feature,PPF)(Rusu等,2008,2009),将其作为网络的输入,利用多个PointNet网络将不同尺度的局部特征和全局特征融合,最后经过MLPs编码得到最终的特征。PPFNet利用了全局上下文感知和编码特征,提高了特征的旋转不变性和对噪声的鲁棒性,但是PPF特征的计算需要大量的最近邻标注数据,并且局部参考框架的建立依赖于法向量的估计,导致了对噪声敏感。另外,寻找固定的K近邻点导致对点云稀疏程度的变化敏感。
为改进PPFNet的缺点,Deng(2018a)进一步提出了PPF-FoldNet。该方法是一种无监督的方法,首先提取PPF特征,使用了一个包含具有跳连接的类PointNet编码器和类FoldingNet(Yang等,2018)的解码器的框架,通过度量输入PPF特征和输出点对特征之间的差异,来获取最终点云的特征表示。PPF-FoldNet在噪声下取得了较好的效果,但仍然对点密度变化较为敏感。
Yew和Lee(2018)提出了3DFeatNet,针对网络训练中难以获取精确标注的问题,提出一种弱监督深度学习框架。从两个输入点云的所有描述符对之间的相似性度量中选择正样本以及置信度最高的负样本,然后使用注意力层来学习一个权重,用于衡量每个输入描述符对三元组损失的贡献,最后通过最小化三元组损失来训练网络。
使用类似PointNet的结构可以实现直接从原始点云中提取特征,但这也限制了卷积操作的使用,不利于捕获局部拓扑信息。针对这个问题,Gojcic等人(2019)提出了3DSmoothNet,设计了可以适用于卷积操作的平滑密度值(smoothed density value voxelization,SDV)体素格子,来编码原始点云,利用Siamese网络架构学习最终的特征。该方法增强了泛化能力,在单一的场景下进行训练,再扩展到其他场景中时仍然可以取得较好的结果。
2.1.2 基于卷积的特征提取
目前基于卷积的方法主要包括两种,一种是直接在点云上进行卷积操作来提取特征,另一种是通过将点云体素化后,使用体素卷积方法提取特征。
受PointNet和卷积操作的启发,Wang等人(2019)设计了边卷积(edge convolution,EdgeConv)操作。首先在点云中构建局部邻域图,然后在中心点与相邻点构成的边上应用类卷积操作,称为边卷积。进一步,在网络中多次叠加包含边卷积的层,得到动态图卷积神经网络(dynamic graph convolutional neural network,DGCNN)。与普通的图卷积神经网络不同,DGCNN中的图节点不是固定的,而是在网络的每一层之后动态更新,也就是说,一个点的近邻点集随着网络的加深逐层变化。因此,EdgeConv非常灵活,在网络中加入一定的EdgeConv层有利于捕获点之间的拓扑信息,但这样也引入了额外的K近邻计算开销。
为了解决不规则点云上的卷积问题,并更好地捕获局部几何信息,Thomas等人(2019)提出了核点卷积(kernel point convolution,KPConv),使用携带卷积权值的核点(kernel point)来模拟2维卷积中的核像素,进而定义原始点云上的卷积操作。KPConv通过点云位置与核点的关系来生成卷积核,其组合权重矩阵是人为设定的,不一定能得到最优结果,且灵活性有限。同时,针对不同的点云数据,核点空间需要专门进行定制,这使得其对超参数敏感。为此,Xu等人(2021b)提出了位置自适应卷积(position adaptive convolution,PAConv),通过网络从点的位置中自适应地学习权重矩阵,然后通过动态组合权重矩阵来构造卷积核。在现有的点云处理框架中,可以使用PAConv替换MLPs模块,无需改变框架的结构和参数,因此具备更好的灵活性。
Zeng等人(2017)提出了3DMatch网络,以体素为输入,首先需要把点云量化成体素表示,然后利用3D卷积神经网络来学习局部几何模式,得到512维度的特征描述符(descriptor)。
由于点云的稀疏性,传统3D卷积操作会造成计算资源的浪费,并且3D卷积本身计算的时间复杂度也很高,因此Choy等人(2019b)提出全卷积几何特征(fully convolutional geometric features,FCGF),使用稀疏3D卷积代替传统的3D卷积,以缓解点云稀疏性带来的问题。通过使用稀疏卷积构建包含跳连接和残差块ResBlock的ResUNet网络架构来提取点云的局部几何特征,其网络结构如图2所示,图中卷积块参数分别为卷积核大小、步长和通道数。FCGF特征输出的维度仅为32维,较为紧凑,并且其运行效率相较以往有着巨大的提高,可以拓展到真实场景。另外,FCGF需要通过旋转增强来实现特征的旋转不变性。
FCGF对数据的采样出现过拟合,导致其泛化效果较差。Horache等人(2021)在FCGF的基础上提出了多尺度架构与自监督细化(multi-scale architecture and self-supervised fine-tuning,MS-SVConv)卷积神经网络。该方法首先体素化点云,通过选取不同大小的体素格子来获得不同尺度下的体素数据,然后将它们输入到一个共享权重的U-Net结构的网络中,分别提取特征。最后使用一个全连接层对这些特征进行融合,最终得到每个点的特征描述符。MS-SVConv延续了FCGF运算速度快、对旋转鲁棒的特点,同时大幅加强了泛化性能。
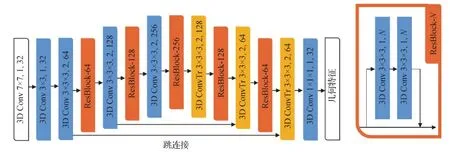
图2 特征提取框架FCGF(Choy 等,2019b)Fig.2 Feature extraction framework FCGF(Choy et al.,2019b)
Ao等人(2021)提出了一种新的神经网络结构SpinNet。SpinNet包含两个模块:1)空间点变换模块。首先估计出一个参考轴,使其与全局参考系的Z轴对齐,以消除这个方向上的自由度;然后利用球形体素化和XY平面变换操作消除XY平面的旋转自由度;最后将球形体素投影到一个圆柱形容器中。2)特征提取模块。使用一个共享权重的MLPs和最大池化聚合函数提取每个体素的初始特征,然后使用3D圆柱卷积(Joung等,2020)操作提取最终的特征。SpinNet保证了特征的旋转不变性,具有较好的泛化性能。
2.1.3 小结
基于局部块的方法通常依赖于建立局部坐标系或者提取传统特征作为网络输入来获取旋转不变性,带来了额外的计算开销。局部坐标系的建立依赖于对原始点法向量的估计,这会导致对噪声、异常点的敏感。尽管提取的传统特征是旋转不变的,但这并不能保证网络输出的特征具有好的旋转不变性。另外,对固定点数的局部块进行特征提取,会导致对密度变化敏感。对固定区域的局部块进行特征提取,限制了特征的感受野。基于卷积的方法可以在重叠区域的神经元之间共享激活单元,因此更加高效。并且卷积操作可以捕捉更加广泛的局部拓扑信息,增大了特征的感受野,从而提高特征的辨识度。另外,除动态图卷积外,其他的卷积操作不需要额外的邻域标签信息,降低了计算开销,计算速度得到显著提高。
2.2 关键点检测
在真实数据中,为了提取具有高分辨力的特征,通常在网络中输入的原始点数量都是较多的,然而对于求解刚性变换而言,在保证用于求解点足够有效的情况下,仅需要少量点对即可(必须超过 3个)。随机采样容易同比例采样噪声点,并且可能受到密度变化等因素的影响,因此无法较好地满足高效采样的要求。一些研究者开发了基于深度学习的关键点检测方法,旨在采样对配准任务贡献大的点。
Bai等人(2020)提出D3feat(description of 3D local features),使用包含KPConv的ResNet块组成的U-Net网络架构来实现在点云上提取特征并且检测关键点。为了解决密度对显著性的影响,提出了一个密度不变的显著性分数来评估某一点与其局部邻域的关系,最后通过该显著性分数和特征通道最大分数来计算关键点检测分数。
通常关键点的检测需要预测逐点的显著性,Lu等人(2020)提出一个基于随机采样的关键点检测器和特征提取网络RSKDD-Net。为了解决随机采样的信息损失问题,利用随机扩展群(random dilation)策略来扩大每个采样点的接受场,对相邻点进行聚类,然后使用注意力机制聚合近邻点的位置和特征,从而得到关键点。最后通过概率倒角距离损失和点到点损失来训练网络。
Huang等人(2021a)对以往的关键点提取方法进行了补充,指出提取关键点的前提是必须保证关键点应该在两个点云的重叠区域内。基于此观点,将问题延伸到低重叠场景,提出PREDATOR用于低重叠的点云配准,其网络框架如图3所示。PREDATOR通过PAConv和EdgeConv分别捕获密度不变的局部几何信息与上下文信息进而得到超点(super point),通过使用交叉注意力块(Sarlin等,2020)提取两点云的特征编码之间的上下文信息得到上下文特征,来预测超点位于重叠部分的概率。然后通过共享权重的解码器对超点进行上采样,最终输出点的特征和点位于重叠区域的概率以及点的显著性打分。值得注意的是,与以往的显著性定义不同,PREDATOR将显著性定义为某个点能找到另一与之匹配的点的可能性。
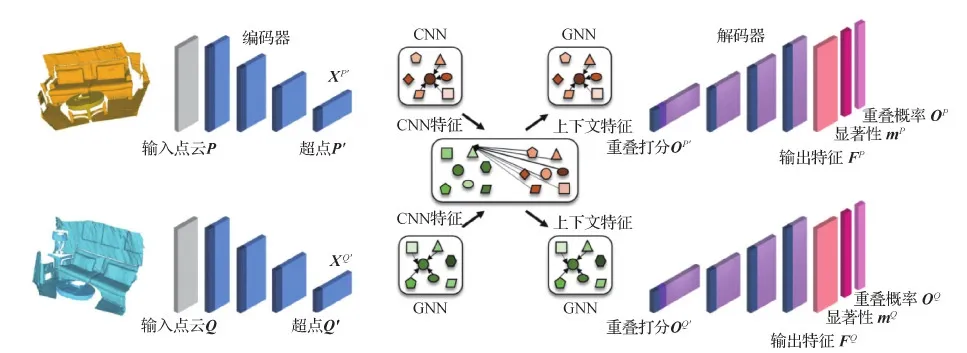
图3 关键点提取框架PREDATOR(Huang等,2021a)Fig.3 Key point extraction framework PREDATOR(Huang et al.,2021a)
另外一些端到端配准方法中也嵌入了关键点检测模块。比如:PRNet(partial-to-partial registration network)(Wang和Solomon,2019b)通过特征的二范数距离定义点的显著性,然后根据二范数的大小来选取显著性高的若干个关键点。为了提高计算效率,避免随机采样导致的网络性能下降,IDAM(iterative distance-aware similarity matrix)(Li等,2020)使用MLPs预测点的显著性来获取固定数量的关键点。
关键点的显著性通常与特征进行联合学习,由于显著性往往来自于独特的特征,这种显著性选取方式依赖于特征学习模块的编码,由网络自适应选取对于配准任务更为重要的点。另外,由于配准过程往往更加关注于重叠区域,适当地交换两个点云之间的信息可以使得关键点的检测更加精准。在一些端到端网络中也嵌入了关键点模块,对关键点检测技术的总结如表2所示。

表2 关键点检测方法概要总结Table 2 Summary of key point detection methods
2.3 点对离群值去除
点对离群值去除(outliers removal)是点云配准最为关键的任务之一。事实上,通过几何特征匹配得到的对应关系并不总是可靠的。造成这种情况的原因主要有3个:1)噪声和异常点。噪声和异常点会降低特征的辨识度。2)部分重叠问题。位于重叠区域之外的点显然没有对应点与之匹配。3)局部点云不显著问题。某些点云局部区域非常“平坦”,显著性较低,容易导致特征的误匹配。通常,特征匹配后得到的点对包含较多离群值,很难用于直接求解刚性变换,因此需要对其进行去除。
在3DRegNet(3D point registration network)(Pais等,2020)中,使用一个包含ResNet块的深度神经网络作为分类模块,用以预测某一个点对属于内点的置信度。3D点对之间存在丰富的几何信息,单纯地将点对离群值去除视为一个二分类模块并不能取得很好的效果。Yang等人(2020)观察到正确的点对之间应该满足几何上的兼容性,因此提出使用兼容性特征(compatibility features,CF)来表示点对。首先,针对点对的长度与角度进行兼容性检查,得到点对的兼容性分数。然后,聚合兼容性打分最高的点的信息,得到兼容性特征。最后,将提取的兼容性特征输入到一个MLPs中,进行密集的二分类,将点对区分为内点(inlier)和离群点(outlier)。与Yang等人(2020)的工作相似,PointDSC(point deep spatial consistency)(Bai等,2021)中将传统方法的空间几何一致性约束引入了深度学习领域,通过类似于Nonlocal网络(Wang等,2018)的SCNonlocal模块提取空间一致性特征。不同的是,PointDSC使用MLPs输出的置信度选择种子点,对每个种子点进行K近邻查找以提取满足空间一致性的点对的集合,最后从若干集合中选择最优的集合求解刚性变换,其网络框架如图4所示。
3DRegNet(Pais等,2020)、DGR(deep global registration)(Choy等,2020)方法将点对离群值去除考虑为二分类问题,利用网络预测点对的置信度。然而点对中可能包含非常多的离群值,这对网络的拟合效果造成影响,因此这类方法并没有达到理想中的性能,相比随机采样一致性(random sample consensus,RANSAC)(Fischler和Bolles等,1981)仍然存在一定差距。CF与PointDSC的工作本质上都是利用网络学习点对之间的旋转不变约束,因此对离群值的筛选变得更为严格,更加贴合真实数据配准需求。此外,PointDSC还通过类似于空间播种的方法选择多个一致性集合进一步加强鲁棒性,相比直接对点对进行分类的回归方法而言,离群值去除的性能有了较大的提高。在一些端到端网络中也嵌入了点对离群值去除模块,对上述方法的总结如表3所示。

图4 点对离群值去除框架PointDSC(Bai等,2021)Fig.4 Outlier removal framework PointDSC(Bai et al.,2021)

表3 点对离群值去除方法概要总结Table 3 Summary of outliers removal methods
2.4 姿态估计
在基于对应关系的点云配准中,姿态估计即通过对应关系计算源点云与目标点云之间的刚性变换R和t,是配准的最后阶段。SVD方法计算的是解析解,并且提供了可微分的实现(Papadopoulo和Lourakis,2000),因此在深度点云配准中得到广泛应用。大部分方法采用了常规的SVD求解方法,但在对SVD的使用上有所不同,因此本文仅从使用的角度对各个方法进行总结与讨论。
DCP(deep closest point)(Wang和Solomon,2019a)、DeepVCP(Lu等,2019)通过置信度的加权和计算对应点的位置,进而估计相对姿态。PRNet(Wang和Solomon,2019b)选取置信度较高的点对,用于SVD的计算。RPMNet(robust point matching network)(Yew和Lee,2020)、IDAM(Li等,2020)、DGR(Choy等,2020)通过置信度选择点对,但同时保留了置信度,将其作为权重,使用加权SVD求解刚性变换。PointDSC(Bai等,2021)在网络的训练阶段使用加权SVD方法,在测试阶段使用加权最小二乘法估计求解刚性变换。
仅对SVD求解模块输入点对坐标意味着丢弃网络中计算的点对置信度,因此网络的反向传播需要通过坐标值进行传递,而坐标的值通常是确定的数值,因此可能对网络中梯度的传递造成阻碍,而保留权重则意味着网络可以通过权重值来传播梯度。使用加权和计算的对应点并不真实存在于目标点云中,因此更加依赖于网络对置信度的估计。PointDSC在测试阶段使用传统优化技术对加权SVD进行替代,并且取得了成功,提供了新的思路。
2.5 端到端点云配准方法
点云数据配准结果主要取决于对应关系的估计,好的对应关系可以通过高效的特征提取、匹配与离群值去除模块来获取,一些研究者对这些流程进行了整合,通过训练一个深度神经网络来直接解决配准问题,输入两个点云,输出运动参数,这种网络称为端到端网络(end-to-end)。通常,端到端网络将各个流程的处理模块集成到一个网络中,对显存的需求较大,更适合数据量较小的配准任务。另外,一些网络并不是直接输入原始点云,而是输入处理后的点云相关数据,为叙述方便,本文统一将其归类为端到端网络。
Wang和Solomon(2019a)提出了深度最近点(DCP)方法,用于实现端到端的点云配准。DCP使用由Wang等人(2019)提出的DGCNN学习点云的嵌入(embeding),使用transformer(Vaswani等,2017)对上下文信息进行编码,实现对嵌入的微调。为了解决特征匹配的不可微分问题,使用嵌入的点积来度量相似度。DCP对噪声取得了较好的鲁棒性,但由于其采用单随机矩阵确定对应关系,这意味着点云X中的所有点在目标点云中都有一个对应,这种假设在异常值和低重叠情况下会引入错误的对应关系。
Wang和Solomon(2019b)进一步提出了PRNet,用来改进DCP。与DCP考虑所有输入点的对应不同,PRNet采用部分关键点进行配准。此外,为了获取高质量的对应关系,PRNet使用了一种演员—评论家(actor-critic)模式,使用全局池化聚合逐点特征来得到全局特征,然后通过一个子网络预测退火参数用于控制匹配的锐化程度。在匹配阶段,使用了近似可微的Gumbel-softmax(Jang等,2017)函数代替不可微argmax函数,确保反向传播时可以获得梯度。最后,使用迭代优化提高配准的精度。尽管在低重叠和噪声场景下PRNet取得了更好的效果,但是PRNet网络模型较为庞大,不利于现实场景应用。
Yew和Lee(2020)基于鲁棒点匹配算法(robust point matching,RPM)(Gold等,1998)提出RPMNet。在特征提取部分,采用与PPFNet相似的结构,同时在特征中加入点的3维坐标得到混合特征;使用参数预测网络来估计离群值参数与退火参数,然后结合混合特征计算点对匹配。在点对离群值去除阶段,引入一个可微的sinkhorn层,对匹配矩阵进行拓展,然后进行迭代归一化得到置信度更高的对应关系。RPMNet在噪声和部分重叠下取得了优秀的性能,但模型的初始输入需要额外的标签数据,因此不适用于密集的点云输入。与PRNet类似,RPMNet需要在迭代中重复计算特征,这增加了计算成本。
由于在网络模型中K近邻的计算效率不高,大多数模型通常使用特征的内积或者特征的二范数距离来表示两点之间的匹配相似度,这种方式忽略了特征在某个通道上的差异。为了改善这种情况,IDAM(Li等,2020)使用距离感知相似矩阵卷积学习特征匹配的相似性度量,以获取更好的匹配关系。该网络支持使用快速点特征直方图(fast point feature histograms,FPFH)或图卷积网络(graph neural network,GNN)来提取旋转不变的几何特征,并将其与一个简单的点对4维欧氏特征进行拼接得到距离增广特征张量,然后在该张量上应用1维卷积来学习特征匹配度量。为了提高相似矩阵卷积的运算效率和匹配的准确率,使用两阶段的点消除策略分别输出逐点的显著性打分和预测点对的置信度,进而计算每个点对的权重。IDAM在密集输入点的场景下有显著的运算优势,但网络仅仅依靠关键点的选择来避免离群点对,因此其配准结果依赖于网络对关键点的预测。
深度高斯混合模型配准(deep Gaussian mixture model registration,DeepGMR)(Yuan等,2020)将神经网络嵌入到极大似然(maximum likelihood estimate,MLE)框架,将目标点云用高斯混合模型(Gaussian mixed model,GMM)进行建模,利用网络预测任意两个点对的对应概率,然后利用可微分模块计算GMM参数,然后从GMM参数中估计最优变换。DeepGMR利用神经网络代替期望最大化算法中的E步(expectation-step),对初始位置和噪声不敏感,并且不需要迭代优化,是一种全局的配准方法。
Ginzburg和Raviv(2021)提出深度加权一致性(deep weighted consensus,DWC)用于全局配准。DWC是一种无监督网络,首先在点的局部邻域内提取线性变换不变特征(rotation-invariant,RI),然后使用两个DGCNN(Wang等,2019)分别提取RI的全局和局部特征,通过全局—局部融合网络得到最终特征。然后使用余弦相似性来定义两个点云概率匹配矩阵,采样包含K个对应关系的集合并分别计算刚性变换,然后选取满足内点数量最多的刚性变换,最后通过采用加权一致性损失优化对应关系。
Lu等人(2019)提出了深度虚拟对应点方法(deep virtual corresponding point,DeepVCP)以便在LiDAR(light detection and ranging)点云配准(真实数据)中能够避免动态对象,并采样有利于配准的稳定的、独特的特征,采用PointNet++提取点的语义特征。在关键点提取阶段,受3DFeatNet启发,设计了1个包含3个叠加完全连接层的多层感知器和一个Topk操作组成的点加权层,用于进一步提取关键点。在匹配阶段,为了在目标点云中找到对应点进行最终配准,使用了一个mini-PointNet提取逐个关键点的几何特征。然后通过候选点坐标与特征相似性的加权和来计算虚拟对应点,进而估计刚性变换。最后在损失中加入全局几何约束以保证网络预测的点的一致性。
深度全局配准(deep global registration,DGR)(Choy等,2020)是用于真实数据的端到端配准网络。在特征提取阶段,DGR采用FCGF(Choy等,2019b)。在离群值去除阶段,采用了类似3DRegNet的思路,但有所不同的是,DGR利用Minkowski引擎(Choy等,2019a)实现6D卷积操作,进而构建一个Res-UNet网络用于预测逐个点对的置信度。为了进一步提高算法的鲁棒性,在得到初步参数后,通过能量最小化函数对位姿进行微调。
一些方法为了提高配准精度,采用了递归网络的设计,例如:PRNet(Wang和Solomon,2019b)、PRMNet(Yew和Lee,2020)、IDAM(Li等,2020),但这也带来重复计算特征的开销,本质上是因为特征对于旋转的变化不够鲁棒;同时,递归的方式也导致了网络在训练过程中的不稳定,这可能是特征匹配模块在不同迭代过程中网络所关注到的信息不同所导致的。另外,由于配准过程中存在大量的干扰因素,例如:异常点、部分重叠等,这些因素导致了一些点不可能存在一一对应关系,因此考虑所有点的对应关系必然会导致算法应用的场景受到限制。
2.6 小结
在基于对应关系的深度点云配准中,核心任务是获取有效的对应关系。现有方法基本上都是通过特征提取和匹配来获取对应关系。通常经过特征提取和匹配阶段的对应关系并不一定是可靠的,其中包含大量离群点对,不能直接用于估计刚性变换,因此需要去除错误匹配的点对。关键点检测通常用于采样对于配准任务有效的点,这潜在地去除了一部分离群值的影响,但对于大规模离群值去除,专用的点对离群值去除模块能发挥更强大的功效。另外,对于不同的干扰而言:1)点云中的噪声、异常值主要影响的是特征的辨识度,直接的结果是导致误匹配。2)对于存在部分重叠的情况,主要的解决方案包括两种,一种是“锐化”对应关系,即选择置信度最高的一部分点;另一种是在特征匹配前去除非重叠区域的点以彻底排除非重叠点的影响。3)对于大旋转场景下,要求特征对旋转的变化具有较好鲁棒性。
3 无对应配准
3.1 无对应配准方法
主流的深度点云配准方法使用对应关系求解刚性变换,研究者们探索出了一条不依赖于对应关系的道路。相关方法概要整理如表4所示。
借鉴2维图像中的算法思路,Aoki等人(2019)提出PointNetLK,利用去除了T-net模块的PointNet网络从两个点云X和Y中提取相对位姿信息。然后利用逆合成(inverse compositional,IC)公式计算目标点云全局特征的雅可比矩阵。最后,利用一个可微的Lucas & Kanade(LK)算法优化全局特征之间的差异计算刚性变换,其网络框架如图5所示。

表4 无对应配准方法概要总结Table 4 Summary of correspondence-free registration methods
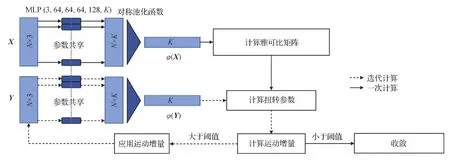
图5 无对应点云配准PointNetLK(Aoki等,2019)Fig.5 Point cloud registration without corresponding PointNetLK(Aoki et al.,2019)
Deng等人(2019)提出一种数据驱动的点云配准网络。利用不同输入但网络结构相同的PPF-FoldNet(输入为PPF姿态不变特征)和PC-FoldNet(输入为点云)输出特征的差异产生包含结构和姿态信息的新特征。在此基础上,设计了RelativeNet直接预测相对姿态。该方法在真实数据集中得到了较高的召回率,但配准精度较低。
PCRNet(Sarode等,2019)提出一种数据驱动的方法。与PointNetLK不同,PCRNet(point cloud registration network)将两个点云的全局特征进行拼接,直接利用类似Siamese(Held等,2016)的网络架构预测运动参数。Groβ等人(2019)设计了一种网络AlignNet-3D用于3维轨道状态估计。该方法将旋转角度划分为若干个子区间,由网络预测旋转所属区间,最后预测一个角度差得到最终的旋转角度参数。特征度量配准(FMR)(Huang等,2020)沿用了PointNetLK的思路,但不同的是,FMR利用刚性变换可逆的特性,使用编码器—解码器的模型对全局特征进行间接监督。编码器模块生成独特的特征后,使用解码器模块将特征映射回3维点云。这种方法可以通过监督或无监督的方式训练网络。FMR在真实数据集中取得了较高的精度,同时噪声、密度和低重叠具有一定鲁棒性。此外,FMR在跨源点云配准中也取得了最先进的结果。
Xu等人(2021a)提出了OMNet(overlapping mask network),为了避免非重叠点的负面影响,在每次迭代中分别预测两个源点云和目标点云的重叠掩码,对非重叠区域进行过滤,然后再通过MLPs从两个点云的全局特征中预测相对运动参数。OMNet通过移除重叠区域来避免全局特征受到干扰,取得了目前最先进的结果。
目前无对应方法通常都采用了与PointNet类似的网络结构用于提取感知空间位姿的全局特征,在姿态估计阶段,PointNetLK(Aoki等,2019)、FMR(Huang等,2020)使用传统优化方法,从特征中计算雅可比矩阵,进而估计运动参数,造成了较大的计算开销。其他的无对应方法使用了回归的方式预测运动参数,这样的好处在于避免计算雅可比矩阵的同时,通过网络学习从全局特征到运动参数的映射,从而使得全局特征更好地感知空间位姿的变化,但是这样的方式更加依赖于网络对训练数据的学习。
3.2 无对应方法与有对应方法的比较
相比于基于对应关系的方法,无对应方法直接关注于两个点云的相对位姿信息而不是局部几何信息,避免了计算对应关系的开销,降低了后续处理的难度,这直接导致了两者在参数估计上的差别。在有对应方法中,SVD是更有效、流行的求解方式;而无对应方法中,使用回归的方式更为有利。这主要是因为表示相对位姿信息的全局特征具有抽象性,通过网络的自适应学习更加合理。而采用SVD方法本质上是对对应关系进行监督。在配准的鲁棒性方面,无对应配准方法更容易受到非重叠区域的干扰,主要的原因在于缺乏明确的监督机制来保证全局特征与相对位姿信息唯一相关。对于合成数据的配准,无对应方法中的OMNet(Xu等,2021a)通过优化网络结构、引入重叠区域分割技术增强了全局特征的抗干扰能力,进而增强了在未知类别模型(unseen-categories)数据上的泛化性能,取得了先进的结果,展示了在泛化上的潜力。另外,目前无对应方法很少应用于真实场景的配准,尽管无对应方法能够避免计算对应关系带来的一些问题,但其更可能受到复杂场景数据的影响,其跨数据集的泛化仍然有待研究。
4 性能评估
4.1 公开数据集
本文总结了3维点云配准领域的通用数据集。用于配准任务的3维点云数据集可以分为两类:合成数据集和真实场景数据集。真实场景数据集通常由激光雷达或RGBD相机等设备获得,包含户外、室内场景。合成数据通常包含人工合成的各类物体的3维模型。Zhang等人(2020)已经对常用的数据集进行了详细的总结,本文仅对目前最具代表性的数据集进行介绍。
1)ModelNet40(Wu等,2015)。由12 311个不包含噪声和异常点的CAD(computer aided design)网格模型组成,总共包含40个常见类别,该数据集主要用于点云分类和检索,同时也是近年来深度学习点云配准领域中主要的合成数据集。获取地址:http://modelnet.cs.princeton.edu/。
2)3DMatch(Zeng等,2017)。该数据集由SUN3D(Xiao等,2013)、7-Scene(Shotton等,2013)等3维重建数据集中拆分而来,包括62个不同室内场景的RGB-D帧序列。获取地址:http://3dmatch.cs.princeton.edu。
4.2 性能评价指标
为了评估深度学习点云配准算法的性能,通常需要借助通用的、客观的评价指标进行度量。深度点云配准的实验性能评价标准从处理阶段来看,主要分为:特征匹配度量和配准误差度量。本小节对常用的度量指标进行了详细的阐述,分别给出其适用的场景并比较了其差别。
4.2.1 特征匹配度量
特征匹配度量主要用于直接衡量特征匹配模块性能的好坏,其主要包含以下两个指标:
1)内点比例(inlier ratio,IR)。该值表示特征匹配后有效的对应关系占所有对应关系的比例。对于一组假定的对应关系(p,q)∈Mi,j,内点比例为
(3)
式中,1[]表示Iverson括号,括号内为真取1,否则取0。R*与t*表示真实的旋转、平移标签,τ1表示最小距离误差阈值。
2)特征匹配召回率(feature match recall,FMR)。其表示配准任务中成功置信度高的任务占总配准任务的比例,计算为
(4)
式中,K表示数据集中用于配准的点云对数量,R1i表示第i个点云对中的内点比例,τ2表示内点比例的最小阈值。
IR与FMR的主要区别在于,IR用于直接度量两个点云的特征匹配的性能,而FMR是用于整个数据集中的配准好坏的预示性度量(假设当IR超过一定阈值后就可以完成配准)。
4.2.2 配准误差度量
1)均方根误差(root mean squard error,RMSE)、均方误差(mean squared error,MSE)与平均绝对误差(mean absolute deviation,MAE)分别记为E1、E2、E3,即
(5)
(6)
(7)
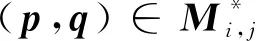
2)相对平移误差(relative translation error,RTE)和相对旋转误差(relative rotation error,RRE)用于度量平移、旋转的估计值与真实标签的差值,其单位分别为厘米(cm)、度(°),计算公式分别为
(8)
(9)
式中,R*与t*分别表示真实的旋转、平移标签,tr()表示矩阵的迹。
3)倒角距离(chamfer distance,CD)用于公平地度量存在轴对称场景下的配准精度,即
(10)
式中,Xc与Yc分别表示初始的源、目标点云,X、Y表示将经过变换后的源、目标点云。该公式由Yew和Lee(2020)提出。
4)配准召回率(registration recall,RR)表示整个数据集中配准误差小于一定阈值的点云对的比例,即
(11)
式中,C为数据集中用于配准的点云对数量,E1表示RMSE误差,τ3表示点云对的RMSE误差阈值。
RMSE、MSE和MAE是使用最为广泛的度量指标,但具有各向异性(anisotropic)的缺点。RRE与RTE是实际度量角度与平移距离差值的指标,是各向同性的(isotropic)。以上5种度量都对轴对称点云的配准存在不公平的惩罚,而CD是最公正的度量。此外,在真实数据集中的配准,往往更加关注配准的成功率,因此RR在真实数据配准中使用更为广泛。
4.3 合成点云数据配准性能评估
在合成点云数据上,需要人工处理原始数据集,但不同的处理方式都会对算法造成影响。此外,一些算法只针对某个特点的场景而设计,比如低重叠、大旋转等。因此,本小节对比了各个场景中主流相关方法的性能。
在部分重叠场景下,性能对比如表5所示。其中,无对应方法FMR(Huang等,2020)、OMNet(Xu等,2021a)在性能上相较于PointNetLK(Aoki等,2019)出现了较大的提升,这得益于网络结构的优化。另外,OMNet引入了重叠区域分割技术,相较于FMR效果更好。在基于对应关系的方法中,DeepGMR(Yuan等,2020)考虑了所有输入点的对应关系,因此无法适应部分重叠场景的配准任务。
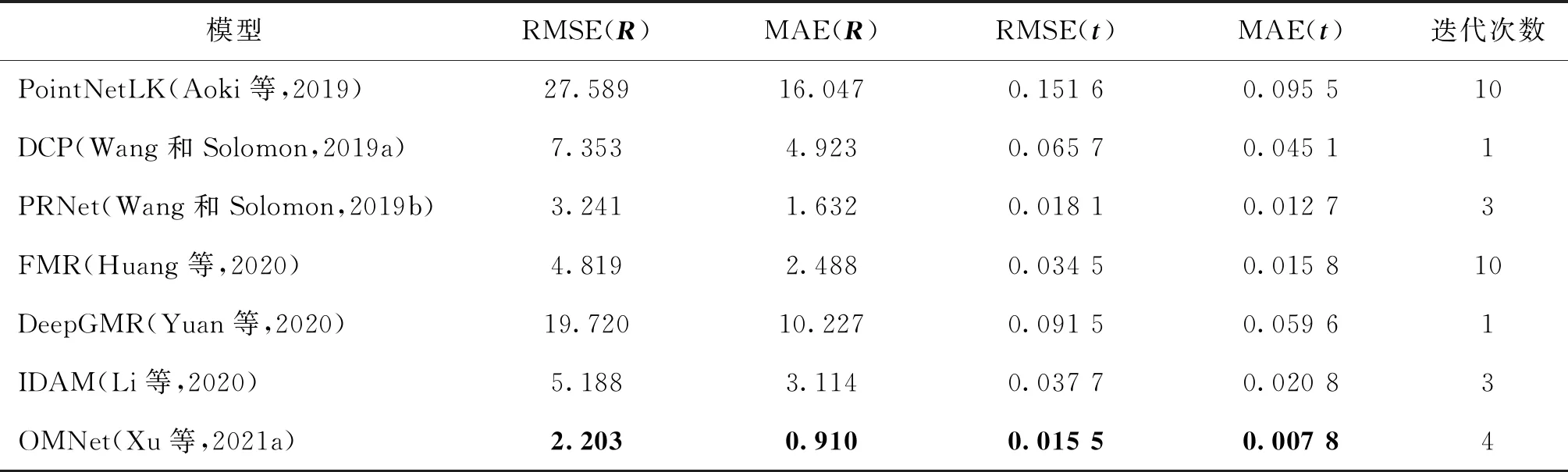
表5 ModelNet40基准下的部分重叠点云配准Table 5 Partial-to-partial registration on ModelNet40 benchmark
在不同采样点下的执行速度如表6所示。DCP(Wang和Solomon,2019a)与DeepGMR没有使用迭代的方式,因此其执行速度相比于其他方法更快。PointNetLK与FMR需要重复计算全局特征和雅可比矩阵,而OMNet采用了回归的方式预测相对姿态,避免使用复杂度较高的逆合成方法计算雅可比矩阵,从而显著提高了算法的运行速度。相比于RPMNet(Yew和Lee,2020)、PRNet(Wang和Solomon,2019b),IDAM(Li 等,2020)在每次迭代中重复使用了特征提取模块提取到的特征,避免了重复计算特征的开销,并且使用关键点技术去除了一部分点对,因此运行速度更快。尽管PRNet也采用了关键点技术,但因其网络过于庞大,执行速度仍然较慢。另外,RPMNet迭代地归一化对应关系矩阵的行和列,这种方法在点数量较多的情况下,计算时间出现了大幅增加。
全局配准性能对比如表7所示。全局配准是指任意的初始位姿下的配准,DeepGMR和DCP在这种实验设置下取得了更为优秀的性能,但DCP泛化效果较差,这可能是因为其特征提取模块的泛化性能较差。

表6 ModelNet40基准下各算法在不同采样点的执行速度Table 6 The execution speed of each algorithm at different sampling points on ModelNet40 Benchmark
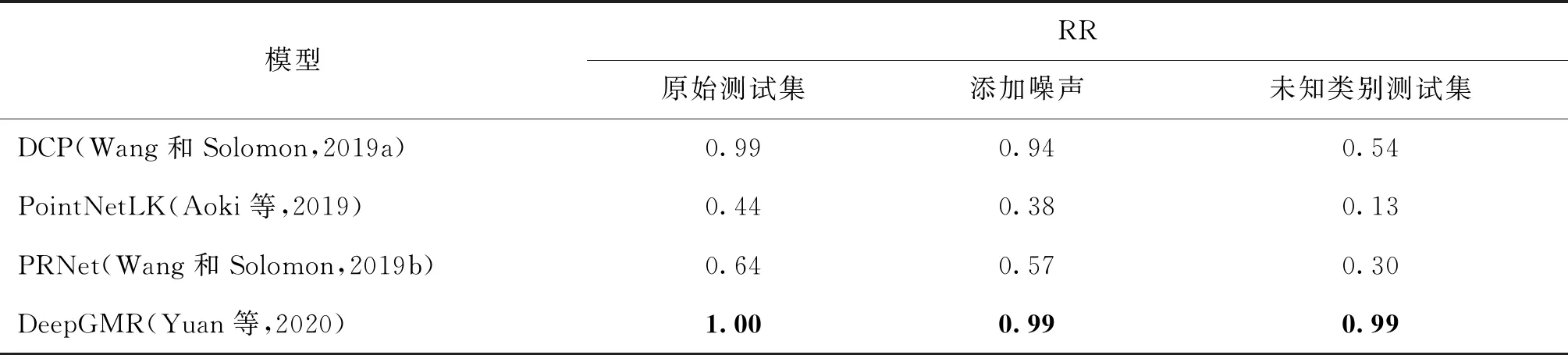
表7 ModelNet40基准下全局配准召回率Table 7 Global registration recall on ModelNet40 benchmark
综上所述,随着深度点云配准领域的发展,各方法分别在对初始位姿、部分重叠等干扰上的鲁棒性得到了显著的提升,但很多算法仍然存在一定的局限性,例如:DeepGMR在全局配准中取得了优秀的结果,但其无法配准部分重叠的点云数据;此外,在合成数据集上的不同处理方法产生的数据很难为研究者提供统一、公正的对比,针对不同任务的统一的基准亟需研究人员的关注。
4.4 真实点云数据配准性能评估
目前,在真实数据中的端到端方法较少,许多工作在特征提取、离群值去除两个主要的阶段上建立了比较基准。特征提取的工作相对较多,离群值去除在近两年得到了发展。
表8展示了在3DMatch比较基准上主流特征提取算法的性能。从时间尺度上看,近年来特征提取算法的研究呈现出了高速发展的趋势,已经在匹配回调率、旋转不变性、紧凑性和泛化能力上都有着巨大的提升。3DMatch(Zeng等,2017)率先开发了在体素上提取点云特征的方法。CGF(Khoury等,2017)、PPFNet(Deng等,2018b)和PPF-FoldNet(Deng等,2018a)依赖于对手工特征进行二次编码,限制了网络的学习能力,性能较差。近年来,随着卷积网络的应用,特征辨识度和旋转鲁棒性得到了很大的改善。FCGF(Choy等,2019b)依赖于固定大小的体素进行稀疏体素卷积,导致泛化性能较差。Ms-SVConv(Horache等,2021)在FCGF的基础上,通过多尺度的稀疏体素卷积大幅提高了泛化能力,达到了目前先进的效果。而SpinNet(Ao等,2021)将输入点云转化为圆柱体素,在不需要旋转增强的情况下取得了较好的泛化效果。SpinNet的成功在一定程度上说明:相比于纯粹地依赖于网络的学习,通过合适的引导和监督,可以让网络学习到更加普适的描述点特征的方式。

表8 3DMatch基准下的特征匹配Table 8 Feature match results on 3DMatch benchmark
表9展示了在3DMatch比较基准上点对离群值去除性能。端到端的DGR(Choy等,2020)使用离群值去除网络模块并未取得理想的效果,其效果仍然依赖RANSAC(Fischler和Bolles,1981)算法作为保护措施(safeguard)。3DRegNet(Pais等,2020)采用了与DGR一样的特征提取模块FCGF和二分类网络,尽管运行速度更快,但是效果较差,这与3DRegNet采用单独训练的方式和网络构成有关。最近提出的PointDSC(Bai等,2021)取得了优于RANSAC的效果,展示了神经网络在离群值去除上的潜力,促进端到端网络在真实数据点云配准上的发展。总的来说,基于深度学习的真实点云数据配准研究仍然有着巨大的发展空间。
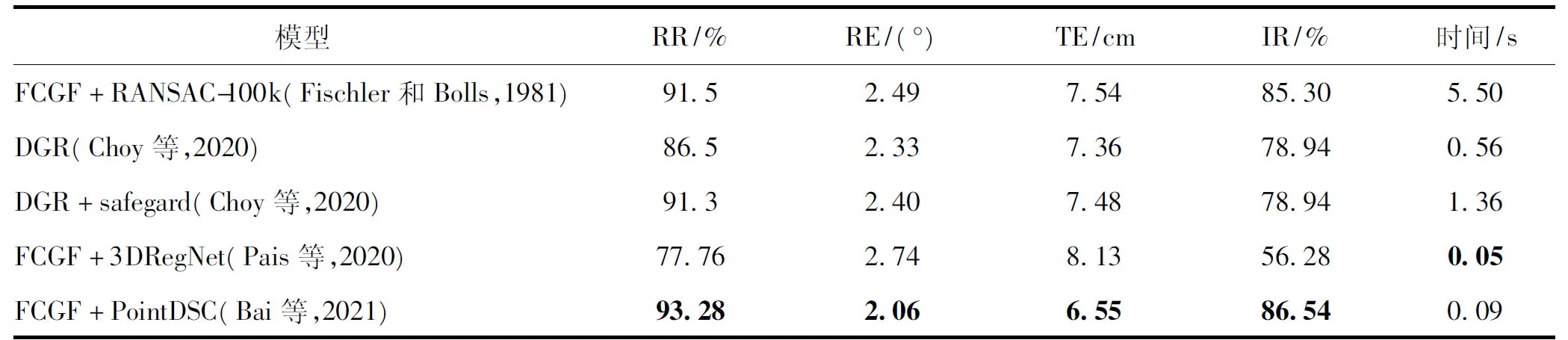
表9 3DMatch基准上的离群值去除Table 9 Outliers removal on 3DMatch benchmark
5 结 语
点云配准是诸多计算机视觉应用的重要组成部分。本文对深度点云配准领域的研究进行了综述,首先根据现有深度点云配准方法的特点将其划分为两大类,在不同类别下,进行了详细的分组阐述和对比总结。然后列举了主要方法在不同测试基准上的性能。目前,尽管深度点云配准技术取得了巨大的进步,但是仍然难以满足现实需求,主要的困难表现在鲁棒性和泛化两个方向,导致这些问题的因素有很多,比如:大量噪声和异常值、低重叠、不同的初始位姿、对称性、大尺度场景下的内存负担和计算开销等。针对这些问题,研究者开发了各种各样的算法,然而,这些算法大多具有局限性。最后,本文从目前点云配准面临的挑战这一点出发,对未来的研究趋势进行展望。
1)在不同的应用场景中,算法面临的挑战不同,这对点云配准算法的通用性提出了要求。然而从目前研究阶段来看,开发通用的算法是困难的。并且,基于对应关系的深度点云配准是一个流水线式的处理流程,在计算运动参数之前,通常需要经过多个模块的处理。因此,开发轻量、高效的专用模块是更受欢迎的研究热点。
2)现实中的传感器获取点云通常由于视角的限制而得到部分重叠的点云数据,直接对这些数据进行配准通常是困难的,尽管目前一部分研究者开发了能够在部分重叠下配准的网络,但通常对重叠率有一定的要求。目前出现了一个更先进的思路:一些研究人员开发了用于分割重叠区域的网络(Sarode等,2020;Huang等,2021a;Xu等,2021a),将部分重叠问题转化为完全重叠问题。这种方法有望解除对重叠率要求的限制,从而在根本上解决部分重叠点云配准的问题,因此具有较大的应用价值和前景空间。
3)真实场景中会获得海量的点,通常使用降采样对点云进行处理,然而降采样可能会导致局部几何信息的丢失,不利于局部几何特征的提取。关键点技术能有效弥补这个缺点,通过寻找独特的、对配准任务有效的少量点用于下游任务,可以显著降低内存负担并减少计算开销,对于在真实应用场景中的配准具有重大意义。目前,关键点检测技术在点云配准领域中得到了广泛的应用,但得到的关注却较少。因为显著性的定义并不明确,现阶段主流方法大多采用MLPs从数据中学习显著性。因此,开发更高效、明确的关键点检测方法仍然是现阶段亟待解决的问题。
4)基于回归的离群值去除方法在真实数据点云配准中未能取得理想的效果,目前仍然依赖传统的RANSAC(Fischler和Bolles,1981)算法,然而该算法具有随机性,且迭代次数随离群值数目的增加出现指数级增长。一些研究者将RANSAC算法的思想引入到神经网络中,取得了更优的效果,这表明神经网络与传统技术的结合具有较大的潜力,通常来说,传统方法具有透明的特点,而神经网络则有强大的拟合能力,如何将两者的优势进行结合是目前研究的热点。
5)无对应配准方法依赖于学习和位姿相关的全局特征,然而神经网络学习出来的全局特征是非常抽象的,很难准确地施加约束。现有方法提取出的全局特征对噪声和部分重叠比较敏感,这主要是全局特征中融合了一些杂乱的信息导致的。另外,无对应方法尚未广泛应用于真实数据,其鲁棒性仍然受到一些研究者的质疑。综合来说,如何鲁棒地提取位姿感知的全局特征也是未来的主要研究方向之一。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
中国房地产业(2016年9期)2016-03-01 01:26:47
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
噪声与振动控制(2015年4期)2015-01-01 07:08:21
中国卫生(2014年2期)2014-11-12 13:00:16
西安交通大学学报(2014年8期)2014-04-16 05:07:06
语文知识(2014年7期)2014-02-28 22:00:26
