
大数据驱动的审计知识库建设与应用
2022-02-28 02:04:09黄佳佳李鹏伟徐超
财会月刊·上半月 2022年2期
黄佳佳 李鹏伟 徐超




【摘要】国家审计的数据基础和审计方式随着大数据的发展而发生改变, 其中文本分析技术逐渐深入应用到审计工作中。 由于审计行业的领域专业性, 有必要构建审计知识库以提高文本挖掘的准确性和可解释性。 以大规模审计文本数据为驱动、以专家指导思想为基础、以自然语言处理为技术手段构建审计知识库, 该知识库包括审计领域词典、领域文本训练语料与词向量模型、审计领域知识图谱, 进而探讨审计知识库在审计工作中的具体应用。
【关键词】审计知识库;大数据;领域词典;词向量;知识图谱
【中图分类号】 F239.1 【文献标识码】A 【文章编号】1004-0994(2022)03-0101-7
一、引言
在信息爆炸的时代背景下, 审计对象所产生的数据量日益庞大, 进而对现有审计数据基础和审计分析方法提出了新要求。 国家审计署相关领导也指出, 应推进以大数据为核心的审计信息化建设, 构建大数据审计工作模式, 积极开展审计大数据的综合利用[1] 。 讨论和运用大数据思想与技术创新当前审计工作模式就不可避免地涉及对审计文本大数据的处理。 现有关于大规模文本数据的研究和应用大多是采用互联网文本, 如微博、新闻、网络评论等, 而采用审计领域相关文本的研究相对较少。 人工智能领域专家认为, 有效利用大数据价值的主要任务不是获取越来越多的数据, 而是从数据中挖掘知识, 对知识进行有效的组织关联, 并用其解决实际问题[2] 。 从大数据技术与不同领域结合应用的效果来看, 大数据技术的应用效果也与领域高度相关, 即当拥有领域相关知识支撑时, 往往文本挖掘技术的应用效果更佳。 本文总结分析了审计文本数据的来源及特点, 认为审计文本具有领域特殊性, 因此有必要构建审计领域知识库, 使得采用大数据分析方法和人工智能文本分析方法分析审计文本时准确性更高、可理解性更强。
在大数据时代, 知识图谱不仅改变了搜索模式, 也改变了文本分析技术。 知识图谱与语义分析相结合可使得语义搜索更加准确、智能推荐更称心如意, 也可以实现自动问答、人机对话等新智能体验。 审计作为一项具有较多专家经验参与其中的工作, 基于大数据构建的审计知识图谱可以帮助审计人员快速排查审计风险点、有效提升审计工作效率、降低审计风险, 进而实现审计智能化。 基于此, 本文提出了一种大数据驱动的审计领域知识库构建方法(该审计知识库可对外开放共享), 并探讨了其在审计业务中的应用方式。
二、文献综述
学者们普遍认为审计所用的数据早已超越了统计和抽样调查, 审计数据具备海量、异构、多样等大数据特性[1,3] 。 秦荣生[4] 认为大数据有助于实现审计监督全覆盖, 而数据综合分析可帮助提升解释审计问题和风险的深度与广度。 在审计技术方面, 有学者开始考虑文本挖掘在审计领域的应用。 张志恒等[5] 构建了审计领域的文本挖掘框架, 并探讨了若干种文本挖掘方法在审计领域的应用, 为文本数据审计提供了新方向和新思路。 此外, 也有学者将文本挖掘方法应用到审计实务中, 主要包括文本关键词抽取与标签云展示、文本相似度计算、文本情感分析、关联规则挖掘等[3,6] , 采用这些技术的目的是从被审计单位的相关文件中发现审计疑点、总结投诉人员特点、评估被审计单位政策执行情况、评估银行信贷申请报告的情感倾向、挖掘上市公司的交易网络和审计费用与盈余质量的关系等[3,6,7] 。
当前审计文本数据挖掘主要是直接利用现有文本挖掘算法, 鲜有研究深入考虑审计领域专业性对文本挖掘方法的挑战。 顾圣杰等[8] 探讨了知识图谱在审计风险识别方面的应用价值, 认为基于专家先验知识的知识图谱能够提升审计效率、实现审计智能化和审计风险点全覆盖。 在通用领域, 国内外学者已构建的代表性知识库包括Freebase[9] 、WordNet[10] 等。 但这些知识库并非为审计领域专门构建的, 因而其可能没有包含审计领域专业词汇, 以及这些词汇/概念的语义信息及相互之间的关系。
三、審计大数据与文本数据审计
大数据时代的到来给政府和企业的财务管理和审计工作都带来了巨大变化。 这种变化不仅意味着审计数据规模越来越大, 而且意味着审计技术与方法具有大数据特征。
1. 审计大数据。 多数学者认为, 进入大数据时代后, 审计环境、审计数据与审计技术等都需要或者正在发生较大变革, 审计正在进入审计大数据时代[1] 。 那么, 什么是审计大数据? 吕天阳等[1] 认为, 审计大数据是“在大数据时代开展审计监督所需的审计对象自身或与其相关对象的各类数据及其分析手段的统称”。
由于审计对象自身提供的财务数据可能存在造假等问题, 因而无法满足审计需求。 当前的合规性审计所需数据越来越多样化、多源化。 此外, 国家审计也在关注绩效审计、政策落实跟踪审计等。 这些审计内容涉及的数据来源范围广、覆盖面大, 使得国家审计需要在原有审计数据基础上进一步扩大数据来源, 综合使用不同部门提供的数据, 如财政部、商务部、国家统计局等。
可以说审计大数据的数据来源是以领域政务大数据为基础, 并包括与各审计对象相关的社会大数据与互联网大数据。 这些数据来源不同、类型各异, 整合和有效利用大规模的审计数据变得更加困难, 进而对审计技术提出了更高的要求, 即以关系数据为基础的传统SQL查询分析手段已显得捉襟见肘。 赵琛[11] 认为, 面向非结构化文本、面向对象间网状关系的智能分析方式是未来审计技术创新的重要方向。
2. 文本数据审计。 在审计大数据时代, 海量的多源异构数据极大地拓展了审计数据的范围。 例如, 在企业内部审计中, 审计对象已不再局限于与被审计单位财务相关的数据, 被审计单位内部的规章制度、会议记录、合同通知等文本数据也是重点审计对象; 此外, 与被审计单位相关的互联网文本, 如单位新闻、股票评论等也具有重要的辅助价值[5] 。 通过对非结构化文本的分析挖掘, 可以更加全面地评估被审计单位的内部控制情况、违法违规问题等。
在面向文本数据的审计工作中, 常用的文本挖掘技术包括文本检索、关联特征挖掘、分类、聚类、提取关键词、构建文本摘要、结果可视化等。 例如: 通过文本检索技术可使审计人员快速找到相关法律法规, 也可快速检索到被审计对象的相关文档, 如通知公告、政策文件等; 通过文本相似性分析(如聚类、分类)技术分析银行信贷客户的调查报告可迅速评估报告编写员工的履职情况, 进而有效降低内部控制合规风险[6] 。
四、审计知识库建设
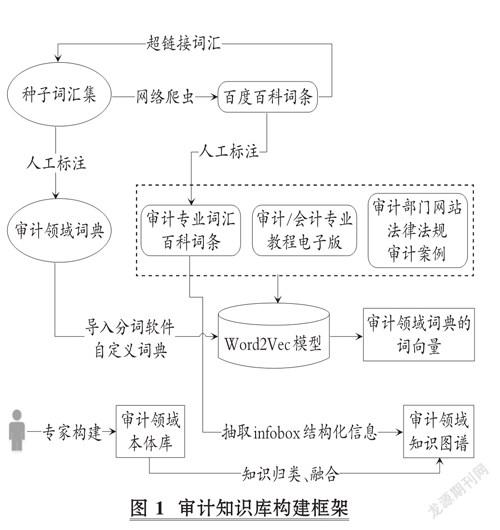
审计知识库构建框架如图1所示, 其构建过程包含如下几个步骤: ①审计领域专业词典收集与标注: 基于专家指定的小规模种子词汇迭代式获取百科文本超链接词汇, 最后人工标注出专业词汇。 ②审计专业词典的语义向量训练: 基于审计领域词典的大规模百科文本及领域的其他文本资料, 利用深度学习算法训练审计专业词汇的词向量。 ③审计领域知识图谱构建: 邀请审计领域专家构建审计领域本体知识框架, 利用百科文本的infobox信息抽取审计三元组构建审计知识图谱。
1. 审计领域词汇表构建。 在文本挖掘中, 一般首先需要对文本进行分词, 然后才能实施关键词检索、分类、聚类等。 分词就是将连续的句子单元分割成若干个词汇。 例如, 对“切实加强领导干部经济责任审计工作, 对规范权力运行、促进依法行政、推进国家治理体系和治理能力现代化具有重要意义”这一文本, 需分割成“切实 加强 领导干部经济责任审计 工作 规范 权力 运行 促进依法行政 推进 国家治理体系 治理能力 现代化 具有 重要 意义”。 由于审计文本具有较强的领域专业性, 即存在较多专业词汇, 如“领导干部经济责任审计”“国家治理体系”等, 直接使用当前的通用文本挖掘软件(如HanLP、Jieba等)往往无法识别这些词汇。 例如: 使用HanLP对上述句子进行分词时, 会将“领导干部经济责任审计”这一专业名词分割成“领导”“干部”“经济”“责任”“审计”5个词汇。 这些零散的词汇难以表达原来专业术语的语义内涵, 进而降低了后续文本挖掘方法的准确性。
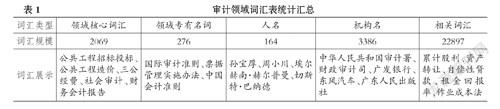
因此, 本文认为, 提高文本挖掘技术在审计领域应用效果的首要工作即为构建审计领域专业词典。 为此, 本文通过一种贪心式爬虫技术从百度百科词条中自动获取审计领域相关词汇, 具体而言包括如下步骤: ①请审计领域专业人员人工构建一个较小规模的审计领域核心种子词汇(共500个词汇), 包括“中华人民共和国审计署”“政府审计”“三公经费”等词汇。 ②利用网络爬虫技术从百度百科中爬取这些词汇的超链接词汇, 如从“中华人民共和国审计署”的百度百科信息中可获得超链接词汇“审计署”“中国审计报社”“审计署外交外事审计局”“侯凯”“中华人民共和国审计法”等词条。 ③将上述超链接词汇加入到种子词汇集中, 继续爬取这些词汇的超链接词汇。 ④经过3轮爬虫, 即可获得数十万条候选审计领域专业词汇及其百度百科文本。 此外, 我们也从互联网上搜索到审计专业词汇的中英文对照表, 进而获得扩展候选词表。 ⑤针对上述候选词汇, 邀请3位审计领域专家进行人工标注并剔除不相干词汇。 若2位以上专家认为该词汇非领域相关词汇, 则剔除该词汇。 最后, 共获得28792个审计领域相关词汇。 此外, 在人工标注过程中, 我们还对相关词汇进行了分类, 类别包括领域专有名词、领域核心词汇、人名、机构名和相关词汇, 汇总信息如表1所示。
表1中, 领域核心词汇仅指审计领域常用的核心词, 而领域专有名词主要包含审计领域各类法律法规及准则名称, 人名主要包括审计、会计、经济管理领域著名的人物姓名, 机构名包括我国各审计机关、国内外银行、国内外知名企业及大学等, 相关词汇主要包括审计、会计、经济管理领域常用的词汇。
2. 审计领域词向量训练。 在当前基于深度学习的文本挖掘技术中, 使用词向量(Word embedding)作为词汇的语义表达形式已成为一种共识。 基于Harris[12] 提出的分布假说, 词向量即上下文相似的词汇, 其语义也相似。 基于神经网络语言模型, 如CBOW和Sikp-gram模型[13] , 在大規模文本上训练出的词向量可有效表达词汇之间的语义相似性, 进而更加有效地度量文本之间的相似性, 从而提高文本分类、文本聚类等任务的准确性。
词向量所表达的语义与训练该向量的文本语料密切相关。 例如, 与通用语料(维基百科语料)相比, 利用本文构建的审计领域语料训练出的词向量模型与审计专业词汇最相似的词汇集合并不一致(这里对两种语料进行分词时, 均导入了本文构建的审计领域词表)。 表2展示了在两种语料下分别训练出的词向量中, 部分审计领域词汇中排名前五的最相似词汇的差异。
从表2可以看出, 对于一些在通用领域和审计领域共用但语义差距较大的词汇, 使用审计领域文本语料训练出的词向量更能表达这些词汇在审计领域的语义概念, 这些词汇的相似词汇也均为审计领域词汇, 而通用语料训练出的词向量无法准确度量这些领域词汇之间的语义相似性; 对于审计和会计领域词汇, 通用语料训练出的词向量更能表达审计领域经常共同出现的词汇, 这对提高审计领域文本搜索准确性而言意义重大。
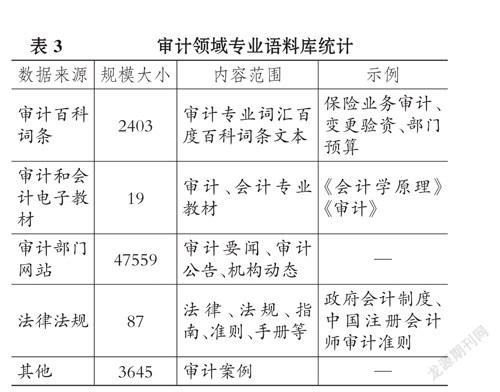
因此, 有必要收集审计领域专业文本来训练审计领域专业词汇的词向量。 本文在标注审计专业词汇后, 将这些专业词汇对应的百度百科文本也保留下来作为部分训练语料, 共包括2403条百科词条。 此外, 本文还收集了审计领域的其他文本数据来构建训练语料库, 包括审计和会计电子教材、各审计机关网站的新闻和公告等、审计/会计等法律准则。 语料统计信息如表3所示。
对上述收集到的原始文本语料进行文本清洗等预处理, 共获得53695条审计领域文本语料。 将上文构建的审计领域专业词汇表导入分词软件jieba中, 对上述语料进行分词、剔除停用词处理。 将处理完成后的语料投入到词向量模型CBOW中, 即可训练出包含审计专业词汇的词向量模型。 将该模型训练出的词向量应用于审计文本挖掘任务, 如关键词检索、相似文本搜索等任务, 可提高这些挖掘任务的精准度。
3. 审计领域知识图谱构建。 以知识图谱为代表的知识库是将人类知识组织成结构化的知识系统, 其是推动人工智能学科发展和应用(如智能检索、智能推荐、智能问答等)的重要基础技术[14] 。 知识图谱使用三元组描述客观世界中概念、实体及它们之间的关系。 三元组中的概念/实体表示为图谱中的边, 概念/实体之间的关系表达为图谱中点之间的连边。 例如, 表4所示的三元组可构建成图2所示的图谱。
构建知识图谱的代价较大, 且并非一气呵成, 需要循序渐进地从零到有、从小到大不断扩充, 以保证知识的准确性和有效性。 此外, 完全依赖自动化方法构建的知识图谱往往准确性难以保证, 一般需要人工构建基础本体知识, 然后在此基础上自动化扩建图谱。
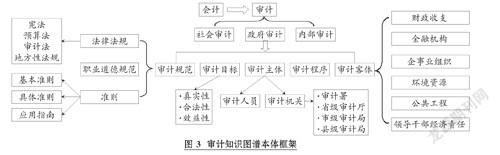
(1)本体建设。 本体即“一种概念化的精确的规格说明”[15] , 用于描述某个领域内概念与概念之间的关系。 一般情况下, 构建本体需要本领域相关专家的指导[16] 。 针对审计知识图谱的构建, 我们首先邀请审计领域专家构建了审计概念框架, 如图3所示。 然后在该框架的基础上, 进一步构建和扩充相关概念的子概念。 例如: 在“资源环境审计”概念下构建关系“审计内容”, 包括实体“财务审计”“合规审计”等; 在“审计客体”概念下扩充子概念“农业审计”“社会保障审计”等。
通过上述人工构建本体的方法, 共构建本体三元组878个。 该本体库主要描述审计领域重要概念与概念之间的隶属关系, 是整个知识图谱的“骨架”。 其他抽取出的实体均属于该“骨架”的下级概念或实体。
(2)结构化信息抽取。 利用百科infobox中的结构化信息从零到有构建知识图谱是常用手段。 例如, 从图4的“中华人民共和国审计署”百度词条的infobox信息中可抽取(“中华人民共和国审计署”, “成立时间”, “ 1983年9月15日”)、 (“中华人民共和国审计署”, “机关隶属”, “中华人民共和国国务院”)等三元组。
通过上述自动化抽取方式, 共抽取出74802条三元组。 这些三元组来自审计领域中专业词汇的百度词条infobox, 因而信息来源可靠、准确性较高, 可填充到本体库中, 构建出审计知识图谱的基础版本。 此外, 根据这些词条与本体库的对应关系, 可将抽取出的三元组映射到本体网络的子节点上。 例如: 从“资源环境审计”词条中抽取的相关三元组可归并到“资源环境审计”概念下; 根据关键词“准则”可将“中国注册会计师执业准则”相关三元组映射到“准则”概念下。
除了从infobox中抽取的信息, 本文还从其他渠道收集审计领域结构化信息, 如会计科目编号、会计/审计专业名词中英文对照表、审计法律法规准则列表、审计机构列表、审计人物、审计机关领导信息等, 将其填充入基础知识图谱中, 这部分结构化数据约包含2万条三元组。
基于上述构建的本体框架和从结构化信息中抽取出的三元组, 本文共构建了包含约10万条三元组的审计领域知识图谱, 并使用图形数据库neo4j框架为该知识图谱设计了一款具有可视化界面的审计知识图谱系统。 该系统包括图谱本体目录索引和图谱实体查询功能, 分别如图5和图6所示。
该审计知识图谱并非一次建成、永久不变。 由于被审计单位千差万别, 被审计单位的各项信息也在实时更新, 因此构建出的基础版知识图谱应具有动态更新、手动/自动添加三元组等功能。 具体而言: 使用者可在该图谱基础上动态更新图谱中节点/边的信息; 可将从其他文本/结构化数据中获得的审计三元组加入到本图谱中; 可在该图谱框架下导入其他领域知识图谱, 如地理信息图谱、企业投资图谱等, 以便应用于具体审计业务。
五、审计知识库应用探讨
在当前数字化审计方式中, 常采用“总体分析、发现疑点、分散核查、系统研究”的审计思路。 下文将以陈伟等[3] 讨论的扶贫审计为例, 探讨如何将审计知识库与上述审计思路相结合, 进一步提升审计线索挖掘的准确性和可解释性。
1. 审计领域词典在标签云分析中的应用。 审计领域词典是提高审计文本挖掘准确性的重要基石。 在对审计文本进行分词和剔除停用词时, 导入该领域词典可提高审计领域词汇分割的准确性, 为特征抽取与展示、文本分类/聚类、关联规则挖掘等任务提供基础保障。
以扶贫审计为例, 当获得某地扶贫审计相关数据后, 为快速了解被审计单位对扶贫政策的总体执行情况, 可对该单位相关扶贫项目文本文件进行关键词抽取, 并使用标签云方式展示[3] 。 在关键词抽取之前, 需要对文本进行分词, 若分词结构不合理, 即不能将审计领域专用名词识别出来, 则展示出的词标签往往具有一定的迷惑性。 例如, “道路硬化”→(“道路”“硬化”)、“危房改造”→(“危房”“改造”)。 因此, 一个可行思路是对审计文本进行分词时导入本文建设的审计领域词汇表作为分词软件的自定义词表, 从而提高分词结果的准确性和可解释性。
2. 词向量在审计关键词/文本相似性分析中的应用。 相似词汇可能使用不同的字符表达, 这在传统的词袋子模型下被认为是不同的特征, 进而增加了特征维度, 使得基于特征的文本分析算法准确性降低。 使用词向量度量词汇之间的相似性可将表达相似或含义相同的词汇归并为一个特征, 进而提高特征词抽取和文本相似度度量的准确性。 以扶贫审计标签云为例, 原始标签中出现的相似词汇, 如“活动室”和“活动场所”、“帮扶”和“扶持”可分别归并為一个词汇, 以进一步提高标签云可视化结果的可解释性和信息量。
在文本相似度度量方面, 引入词向量可将每个文本表达成特征空间中词向量的拼接或者在词向量基础上使用深度学习技术, 如循环神经网络、fasttext[17] 等, 构建文本向量, 再计算文本相似度, 将会提高相似度度量的准确性。
以了解被审计单位对扶贫政策的执行情况为例, 对每一年的扶贫项目文件进行相似度分析, 以检测扶贫项目的变化情况[3] 。 在计算文本相似度时, 一般以整个文本集的重要词语作为特征空间, 并以词汇的TF-IDF作为其在空间中的权重。 这样每个文本即表达成特征空间中的向量, 文本之间的相似性即为两个向量之间的欧氏距离或余弦相似度。 这种做法存在两个问题: 一是特征空间高维稀疏, 即一个文本只在若干个特征维度上有非零值, 而在其他维度上值为零; 二是特征相互独立, 某些相似的词汇依旧被认为具有两个不相干的特征。 这两个问题都会导致对文本相似度的计算不够准确, 使用词向量构建的句子向量来度量句子相似度将会提高其计算的准确性。
3. 审计知识图谱在审计实务中的应用。 知识图谱通过三元组这一简洁的知识表示形式, 既能提高数据表达效率, 又能通过图谱可视化提高数据表现能力。 使用审计知识图谱可辅助审计人员快速发现审计疑点以及这些疑点之间的关联关系; 此外, 基于审计知识图谱可构建更加精准的审计领域搜索引擎, 以便在审计工作中快速准确地搜索到与搜索词相关的审计/会计准则/法规、审计方法、审计底稿模板等信息。
以扶贫资金使用情况审计为例, 在通过关键词提取和标签云可视化分析后, 发现了相关疑点, 如扶贫资金使用方面包含“餐费”“高尔夫”“中介费”“烟酒”等支出。 那么, 如何从这些线索中快速找到审计证据? 一个思路是在已有的审计知识图谱的基础上, 从被审计单位的相关扶贫资金支出数据中抽取出包含上述线索词的三元组并整合到图谱中, 构建出当前被审计单位的临时知识图谱, 即可分析出这些费用的使用金额、报销人、收款单位/人、支出项目等情况。
以扶贫内容合理性审计为例, 在通过关键词获得扶贫项目内容中存在“制革”“有色”“冶炼”等关键词, 那么怎样快速判断被审计单位是否投资了高污染、高能耗等国家禁止的行业项目呢? 一个思路是利用词向量从被审计单位的相关投资文件中抽取出包含上述关键词或与上述关键词相似的命名实体, 以进一步确认被审计单位投资项目的具体名称。 若投资项目中确实包含国家禁止的项目, 则可在当前知识图谱的基础上接入企业投资关系知识图谱, 进一步确认这些投资项目的法定代表人、注册资本等信息。
六、结束语
本文讨论了如何构建审计知识库, 探究了该知识库在审计实务工作中的示范应用。 本文所构建的审计知识库包括三部分内容, 分别是审计领域词典、审计领域词汇的词向量及训练词向量的领域文本语料、审计领域知识图谱。 该知识库的运用将有助于提升面向审计文本数据挖掘的准确性和可理解性。 未来可使用深度学习方法从非结构化文本中深入挖掘包含审计领域词汇的三元组信息, 以进一步扩充该知识图谱。 此外, 还应进一步将该知识库与审计应用实务有机结合, 例如在知识库基础上构建审计准则、审计方法等智能检索功能, 为审计业务查询提供便利。
【基金项目】国家自然科学基金项目(项目编号: 61802194、61902190、71972102);江苏省高等学校自然科学研究项目(项目
编号:19KJB520040);南京审计大学校级基金项目(项目编号:2021SZZD008、XG202103)
【作者单位】南京审计大学信息工程学院, 南京 211815
【 主 要 参 考 文 献 】
[1] 吕天阳,杨蕴毅,邱玉慧.审计大数据的提出、特征及挑战[ J].财会月刊,2018(5):142 ~ 150.
[2] 林海伦,王元卓,贾岩涛等.面向网络大数据的知识融合方法综述[ J].计算机学报,2017(1):1 ~ 27.
[3] 陈伟,勾东升,徐发亮.基于文本数据分析的大数据审计方法研究[ J].中国注册会计师,2018(11):80 ~ 84+3.
[4] 秦荣生.大数据、云计算技术对审计的影响研究[ J].审计研究,2014(6):23 ~ 28.
[5] 张志恒,成雪娇.大数据环境下基于文本挖掘的审计数据分析框架[ J].会计之友,2017(16):117 ~ 120.
[6] 杨兆群,蔡润柱,郭嘉玲.基于关键词检索的非结构化数据审计应用研究[ J].中国内部审计,2020(4):36 ~ 42.
[7] 武凯文.上市公司的关系网络和事务所审计行为——基于公司年报文本分析的经验证据[ J].上海财经大学学报,2019(3):74 ~ 90.
[8] 顾圣杰,王宸,刘涵璐等.基于知识图谱的审计风险点识别研究[ J].商讯,2021(4):138 ~ 139.
[9] Bollacker K.. Freebase: A collaboratively created graph database for structuring human knowledge[Z].International Conference on Management of Data,2008.
[10] Miller G. A.. WordNet: A lexical database for English[ J].Communications of the ACM,1995(11):39 ~ 41.
[11] 赵琛.审计对象关系网络构建方法研究[ J].审计研究, 2016(6):36 ~ 41.
[12] Harris Z. S.. Distributional structure[ J].Word,1981(2-3):146 ~ 162.
[13] Mikolov T., Sutskever I., Chen K., et al.. Distributed representations of words and phrases and their compositionality[A].New York: Proceedings of the 26th International Conference on Neural Information Processing Systems,2013.
[14] 刘知远,孙茂松,林衍凯等.知识表示学习研究进展[ J].计算机研究与发展,2016(2):247 ~ 261.
[15] Thomas R. Gruber. Towards principles for the design of ontologies used for knowledge sharing[ J].International Journal of Human-Computer Studies,1993(5-6):907 ~ 928.
[16] Han J., Xiang Y.. A survey on ontology building[ J].Computer Applications and Software,2007(9):21 ~ 23.
[17] Le Q., Mikolov T.. Distributed representations of sentences and documents[A].Beijing:Proceedings of the 31st International Conference on International Conference on Machine Learning,2014.
(責任编辑·校对: 喻晨 陈晶)
猜你喜欢
现代情报(2016年10期)2016-12-15 12:32:46
现代情报(2016年10期)2016-12-15 12:27:57
新教育时代·教师版(2016年33期)2016-12-02 22:26:31
智富时代(2016年12期)2016-12-01 16:28:41
中国远程教育(2016年9期)2016-11-19 12:21:26
中国教育信息化·基础教育(2016年9期)2016-10-18 02:29:50
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
