
基于强化学习的网络数据流异常检测数学建模
2022-02-27 03:27董慧
电子设计工程 2022年4期
董慧
(西安明德理工学院,陕西西安 710124)
强化学习也称增强学习、评价学习或再励学习,作为机器学习范畴中最主要的应用方法之一,能够较好地描述智能体在网络环境中存在的数据信息处理能力,从而解决与特定信息目标相关的最大化应用问题[1]。强化学习算法主要沿用传统的马尔可夫决策思想,按照已给定的数值条件,将待处理信息参量分成已学习与未学习两部分,并分别对其进行指向性的操作与处理。在实际应用过程中,深度学习模型对于数据信息的记忆逐渐加深,并最终形成网络处理环境所需的强化学习模型。
网络数据流异常检测是一种常见的信息参量处理手段,可在维护网络应用安全的同时,对非常规数据信息进行剔除处理[2]。然而传统KNN 估算型检测模型在单位时间内所能检测的数据信息量有限,并不能较好屏蔽异常信息流对数据节点造成的实质性攻击。为解决此问题,引入强化学习理论,在PLVF-TD 学习框架、Storm 流式处理平台等结构的支持下,搭建一种新型的网络数据流异常检测数学模型。在确定分段线性值函数条件的同时,对异常数据特征的检测属性进行精准计算,从而实现对网络数据流传输环境的有效保护。
1 网络数据流的强化特性学习
网络数据流的强化特性学习包含PLVF-TD 学习框架搭建、分段线性值函数设计、局部节点泛化能力分析3 个处理环节。
1.1 PLVF-TD学习框架
PLVF-TD 学习框架可按照网络环境中数据流信息的传输需求,确定必要的数据格式转换条件,再借助存储型数据库建立分段线性值函数。一般情况下,PLVF-TD 格式必须满足网络数据流信息的转换需求,可在将信息参量存储于数据库结构体之中的同时,分别调取网络环境中的异常数据流与常规数据流。一方面按照信息参量的传输需求,计算分段线性值函数建立所需的各项数值量条件,另一方面也可使数据信息的网络传输环境得到较好的稳定与维护[3-4]。PLVF-TD 学习框架如图1 所示。
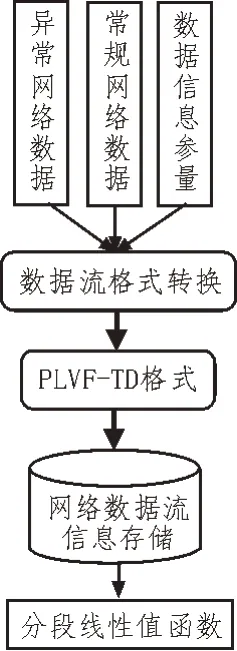
图1 PLVF-TD学习框架示意图
1.2 分段线性值函数
分段线性值函数是对网络数据流异常检测行为的约束性条件。一般情况下,相关参与变量的物理数值越大,最终计算所得的函数值条件越能清晰描述强化学习算法所具备的应用性能力[5-6]。规定i0代表最小的网络数据流信息线性分段系数,由于强化学习算法的影响,该项物理量指标始终不具备无线扩展的能力,相反会随传输数据量的增大,而出现适当的缩小变化趋势。x0代表网络环境中理想化的数据流传输行为参量,由于网络结构体具有多样性变化,该项物理量的数值水平始终不具备超过实际数据流传输行为参量x的能力。联立上述物理量,可将网络数据流的分段线性值函数条件定义为:
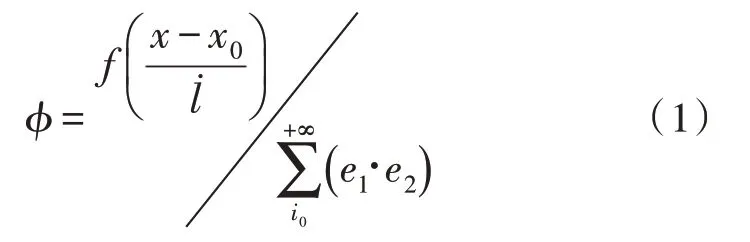
式中,f代表强化学习算法的应用系数值,代表网络数据流信息的异常性传输特征参量,e1、e2分别代表两个不同的数据信息强化系数。
1.3 局部节点泛化能力
局部节点泛化能力是强化学习算法所具有的特殊执行能力,可在网络环境中对常规数据流与异常数据流进行有效区分,从而降低后续检测指令执行的复杂化程度[7]。由于强化学习算法的影响,局部节点所具备的泛化能力不宜过强,仅需满足网络环境对于常规数据流信息的调取需求即可。若待检测的网络数据流信息量过大,不仅会对分段线性值函数造成抑制性影响,也会使网络环境中数据信息参量的传输稳定性大幅下降[8-9]。设r0代表强化学习算法作用下的最小网络节点泛化条件,β代表网络数据流信息的局部泛化系数。在上述物理量的支持下,联立式(1),可将网络环境中的局部节点泛化能力表示为:
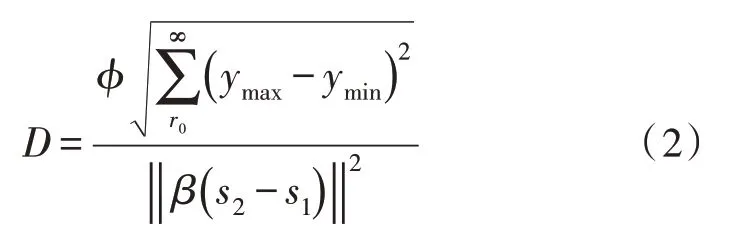
其中,ymin代表最小的数据流信息传输特征值,ymax代表最大的数据流信息传输特征值,s1、s2分别代表两个不同的网络局部节点泛化指标。
2 网络数据流的异常检测数学模型
在网络数据流强化特性学习条件的支持下,按照Storm 流式处理平台搭建、网络数据流特征选取、异常数据特征检测属性量计算的处理流程,实现网络数据流异常检测数学模型的顺利应用。
2.1 Storm流式处理平台
Storm 流式处理平台负责对网络数据流信息进行整合与处理,并可借助强化学习算法,实现对局部节点泛化特征与泛化能力的有效维护[10-11]。在网络传输环境中,常规数据流信息只能由边缘节点位置向着中心节点位置反馈,并可根据信息参量的实际传输需求,将这些数据流文件妥善安置于合适的网络节点位置处。一般情况下,Storm 平台所承担的数据信息检测需求量越大,异常数据流对于网络环境的攻击能力也就越强。因此,为保证网络传输环境中数据信息参量的应用稳定性,需要在维持Storm 流式处理平台连接可靠性的同时,对数据流信息参量进行均分化处理[12-13]。Storm 流式处理平台示意图如图2 所示。
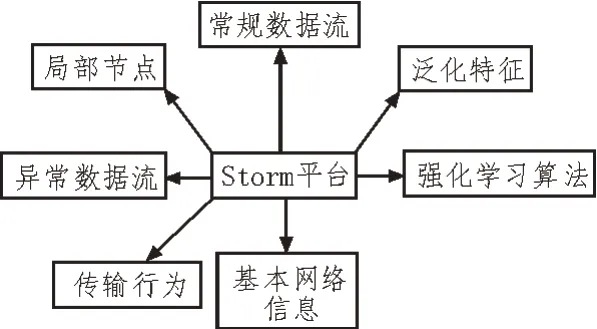
图2 Storm流式处理平台示意图
2.2 网络数据流特征选取
网络数据流的异常检测应以已选取的数据流特征作为基础参考条件,并遵照强化学习算法的实际应用需求,对Storm 流式处理平台的执行能力进行判断。若平台执行能力可与网络数据流特征匹配,则认为现有数据流异常检测制度有效;若平台执行能力并不能与网络数据流特征匹配,则认为现有数据流异常检测制度无效[14]。在发生异常数据流攻击行为时,一个局部节点往往需要同时对应多个IP 地址端口,且随着攻击行为强度的增大,若继续维持现有数据流传输形式,则会导致虚假数据包的快速复制。设k0代表网络数据流信息的最小复制条件,kn代表网络数据流信息的最大复制条件,n代表网络数据流信息的实际迭代次数,联立式(2),可将网络数据流特征选取结果表示为:
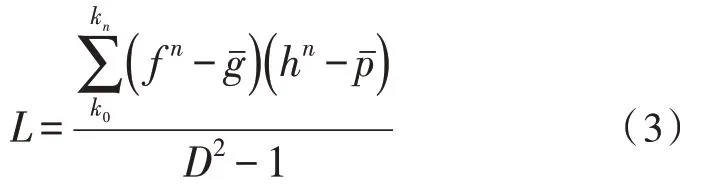
式(3)中,f代表网络数据流信息的异常检测行为指标,h代表网络数据流信息的常规检测行为指标,代表网络数据流信息的异常传输均值,代表网络数据流信息的常规传输均值。
2.3 异常数据特征的检测属性量
对于已抓包的网络数据流异常信息来说,特征检测属性量计算能够在确定数学建模条件的同时,将已提取的信息参量划分成多个可供选择的应用系数指标,从而实现对网络信息传输环境的有效保护。在不考虑其他干扰条件的情况下,异常数据特征检测属性量仅受到数据流传输总量、异常行为系数两项物理量的直接影响[15-16]。数据流传输总量可表示为ξ,在既定检测时长内,该项物理量始终具备较强的累积变化能力。异常行为系数可表示为λ,受到强化学习机制的影响,该项物理量的变化能力有限,且可随检测数据流信息量的增大而出现逐渐递增的变化状态。联立上述物理量,可将异常数据特征的检测属性量计算结果表示为:

3 实用能力分析
为验证基于强化学习的网络数据流异常检测数学模型的实际应用能力,设计如下对比实验。在图3所示检测环境中,以网络数据库作为信息参量的核心输出主机,将这些数据信息文件分别输入检测主机中,其中检测主机1 搭载基于强化学习的网络数据流异常检测数学模型(实验组),检测主机2 搭载KNN 估算型检测模型(对照组1),检测主机3 不搭载任何检测模型(对照组2)。
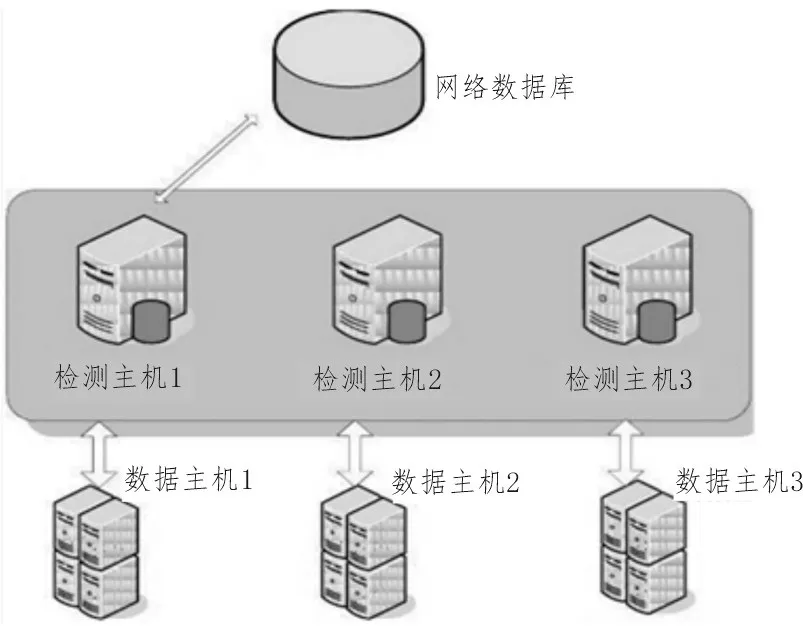
图3 网络数据流异常检测环境
PSU 指标能够描述异常信息流对网络数据节点的攻击性强度,一般情况下,PSU 指标数值越大,异常信息流对网络数据节点的攻击性强度就越高,反之则越低。PSU 指标数值变化如表1 所示。

表1 PSU指标数值对比表
分析表1 可知,实验组PSU 指标在整个实验过程中始终保持不断上升的数值变化趋势,但实验后期的上升幅度明显小于实验前期;对照组1 的PSU指标则在一定时间的稳定状态后,开始出现小幅度的上升;对照组2 的PSU 指标则始终保持明显上升的数值变化趋势。随着基于强化学习的网络数据流异常检测数学模型的应用,PSU 指标数值的上升趋势得到有效控制,可较好抑制异常信息流对网络数据节点的攻击性强度水平。
DLP 指标可描述网络主机对于常规信息参量的提取精度水平,一般情况下,DLP 指标数值越大,网络主机对于常规信息参量的提取精度也就越高。DLP 指标的变化情况如表2 所示。
分析表2 可知,实验组DLP 指标在整个实验过程中维持先上升、再稳定的数值变化趋势;对照组1的DLP 指标始终保持相对稳定的波动性变化状态;对照组2 的DLP 指标则基本保持上升与下降交替出现的数值变化趋势。随着所设计网络数据流异常检测数学模型的应用,DLP 指标的表现数值水平得到了有效促进,能够持续增强网络主机对于常规信息参量的提取精确度水平。

表2 DLP指标数值对比表
4 结束语
在强化学习理论的作用下,新型网络数据流异常检测数学模型可针对常规信息参量捕获精确性较差的问题进行改进,且随着PLVF-TD 学习框架、Storm 流式处理平台的应用,局部节点的泛化能力得到大幅增强,不仅能使网络环境免于遭受异常数据流的攻击,也可实现对异常数据特征检测属性量值的准确计算。
猜你喜欢
现代建筑电气(2022年6期)2022-12-16
检验医学(2022年3期)2022-05-05
数据与计算发展前沿(2021年5期)2021-11-30
计算机时代(2021年9期)2021-10-08
汽车维修与保养(2020年10期)2021-01-22
空间科学学报(2020年3期)2020-07-24
汽车维修与保养(2020年11期)2020-06-09
现代职业教育·高职高专(2020年10期)2020-01-05
物理学报(2019年24期)2019-12-24
计算机技术与发展(2018年1期)2018-01-23
