
基于双注意力机制信息蒸馏网络的图像超分辨率复原算法
2022-02-26 06:58王素玉
计算机应用 2022年1期
王素玉,杨 静*,李 越
(1.北京市物联网软件与系统工程技术研究中心(北京工业大学),北京 100124;2.北京工业大学信息学部,北京 100124)
0 引言
图像的超分辨率复原技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像。近年来,深度学习在各种计算机视觉问题上表现优异,因此许多学者开始设计用于图像超分辨率复原的深度网络结构。2016 年Dong 等[1]使用一个简单的3 层超分辨率神经网络(Super Resolution Convolutional Neural Network,SRCNN)成功地将卷积神经网络引入到超分辨率重建中,同时证明卷积神经网络可以直接学习从低分辨率图像到高分辨率图像的端到端的非线性映射,在不需要传统方法所要求的人工特征的条件下就可以取得很好的效果。在图像超分辨领域,目前大多数最新的方法都是基于卷积神经网络(Convolutional Neural Network,CNN),网络的深度对算法性能的提高具有重要意义,但过深的网络却难以训练。信息蒸馏网络(Information Distillation Network,IDN)[2]有着轻量级的参数和计算复杂度,该网络模型中包含三个部分,即特征提取模块、堆叠的信息蒸馏模块、重建模块。信息蒸馏模块是该网络的核心,利用蒸馏模块逐渐提取大量有效特征来复原超分辨率图像,IDN 通过压缩网络中特征图通道维度的方式,在减小网络参数、提高速度的情况下,还保证了复原的结果。但是,该网络对不同位置和通道特征的差异化利用能力尚显不足,算法性能仍存在一定的提高空间。
本文在对现有工作进行全面分析和总结的基础上,设计了一种基于双注意力机制的信息蒸馏网络,在网络模型的基础上增加通道注意力(Channel Attention,CA)和空间注意力(Spatial Attention,SA)模块,可以有效地将通道注意力和空间注意力融合起来,使网络专注于更有用的信道并增强辨别学习能力,提升算法精度。此外,将L1 损失函数和多尺度结构相似(Multi-Scale Structure SIMilarity,MS-SSIM)损失函数结合起来构建混合损失函数[3],加速网络收敛,提高图像复原质量。通过提出的图像超分辨率算法得到最终的高分辨图像,在Set5、Set14、BSD100 和Urban100 测试集的实验结果表明,本文算法得到的高分辨率图像在客观指标和主观视觉上都有明显提高。
综上所述,本文的主要工作如下:
1)设计了一种基于残差注意力模块(Residual Attention Module,RAM)的信息蒸馏网络架构,使网络专注于更有用的信息并增强辨别学习能力,提升算法对高频细节的重建能力,通过考虑通道之间的相互依赖性来自适应地重新调整特征。这种机制允许网络专注于更有用的信道并增强辨别学习能力,提升超分辨率复原的能力。
2)设计了一种混合损失函数。MS-SSIM 容易导致亮度的改变和颜色的偏差,但它能保留高频信息(图像的边缘和细节)[4],而L1 损失函数能较好地保持亮度和颜色不变化,因此本文提出将L1 损失函数和MS-SSIM 损失函数结合起来构建混合损失函数,加速网络收敛,提高图像复原质量。
1 相关工作
1.1 传统方法
超分辨率复原是图像处理领域的经典任务之一,近年来得到了广泛的研究。典型的算法包括基于频域和空域的算法等。2010 年Yang 等[5]开创性地将稀疏表示理论应用于图像的超分辨率复原,通过学习的方式建立高低分辨率图像间一一对应的冗余字典,实现图像中高频细节的重建。随后,Zeyde 等[6]在Yang 的基础上进行改进,利用主成分分析对训练样本进行降维,并使用K-SVD(K-Singular Value Decomposition)算法进行字典训练,进一步提高字典训练的效率,从而获得具有更高质量的重建图像。
1.2 基于CNN的方法
传统学习方法利用训练集隐式地学习图像的某些先验知识,但是难以学习图像深层次的纹理特征,在图像纹理细节比较丰富的地方会出现模糊的现象。而深度学习的方法,可以利用卷积神经网络(CNN),主动地学习图像中的特征以及高分辨率图像和低分辨率图像之间的映射关系。从卷积层提取特征的可视化结果可以看出,通过卷积,可以将图像浅层的纹理信息和深层的复杂结构信息提取出来。所以,基于深度学习的超分辨率复原方法,具有比传统学习方法更好的复原细节的能力。
Dong 等[1]在简单的3 层卷积神经网络模型(SRCNN)基础上,设计更深层的网络,但并未发现较好的性能,因此他们得出深层网络并不会导致更好的性能的结论。Kim 等[7]提出了一个20层的基于VGG网络的深层卷积网络预测残差图像,并且验证了随着层数的增加,模型性能会得到很大的提升。尽管这些方法有效地改善了复原后图像的质量,但是对图像中存在的边缘信息丢失等问题考虑得不够充分。图像边缘是重要的结构性信息,人的视觉系统也对它相当敏感。边缘特征可以为图像的超分辨率复原提供有价值的导向。Noh 等[8]提出了用于语义分割的反卷积网络(DeconvNet),通过在VGG卷积网络后使用一个多层的反卷积网络产生输入图像的逐像素(pixel-wise)预测,实现目标边缘的精准预测,可以有效地解决目标边缘细节丢失等问题。Lim 等[9]设计了一种增强的深度超分辨率复原网络(Enhanced Deep ReSidual network for single image super-resolution,EDSR),通过堆叠更多的网络层构造更深层的卷积网络,并且从每层取更多的特征以复原图像。现有研究表明,在图像超分辨率领域,卷积神经网络的深度非常重要,但过深的网络却难以训练,随着网络的深度和宽度增加,基于CNN 的超分辨方法面临着计算和内存的问题。为解决这个问题,Hui 等[2]提出一个深但简洁的卷积网络IDN,直接从原始的低分辨图像来复原高分辨图像。IDN在保证模型精度的基础上,明显提高了网络执行速度;但是,低分辨率的输入以及包含丰富特征的低频信息,却在通道间被平等对待,制约了网络的表示能力。
鉴于对上述研究的深入分析,本文基于信息蒸馏网络(IDN)模型,设计了一种基于RAM 的信息蒸馏网络,通过引入注意力模块RAM,将在信息蒸馏模块生成的大量有效信息区别对待,从而进行更加自适应和有效的训练。在此基础上,为了提高网络的收敛速度和图像复原质量,设计了一种基于MS-SSIM 和L1 相结合的混合损失函数。本文设计的网络结构有效地提高了图像超分辨率复原的能力。
2 双注意力信息蒸馏网络
2.1 整体网络结构
本文所提网络直接从原始的低分辨图像来复原高分辨图像,其基本网络结构如图1 所示。
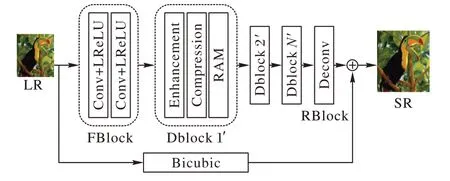
图1 基于RAM的网络结构Fig.1 RAM-based network structure
本文所提网络是在信息蒸馏网络的基础上,引入注意力模块,整体网络结构中包含三个部分,即特征提取模块、堆叠的信息蒸馏模块(DBlockN′)和重建模块。首先通过特征提取模块(FBlock)从低分辨率图像中提取特征。然后经过信息蒸馏模块对所提取的特征进行筛选,每个信息蒸馏模块中包含一个提升单元和一个压缩单元:提升单元主要包括两个浅层卷积网络,用于混合两种不同类型的特征;而压缩单元利用1×1 卷积来实现压缩机制,将提升单元的输出送至1×1 卷积层,用于提取更有用的信息。信息蒸馏模块(DBlockN′)中包含一个RAM 双注意力模块,在提取更多残差信息的基础上,通过考虑通道之间的相互依赖性来自适应地重新调整特征。最后重建模块(RBlock)聚集所获得的高分辨率图像残差表示来生成残差图。通过残差图与上采样后的低分辨率图进行元素间的相加操作,得到最终的高分辨率图像。
2.2 残差双注意力机制(RAM)
大多数基于CNN 来进行图像超分辨的方法都是在内部同等地处理所有类型的信息,这可能无法有效地区分详细特征间的差异性(例如低频和高频信息),即网络选择性地使用特征的能力有限。为此,本文引入了一种注意力机制。注意力机制是各种计算机视觉问题中值得注意的网络结构之一,它允许网络重新校准提取的特征图,从而可以进行更加自适应和有效的训练。网络中引入注意力机制后的特征提取效果如图2 所示。
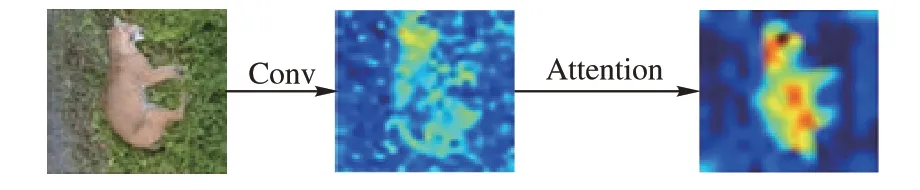
图2 注意力机制提取效果Fig.2 Extraction effect of attention mechanism
与传统图像分割和目标检测任务不同,超分辨率复原过程旨在恢复图像中损失的高频成分,因而利用通道的高频特性来学习注意力更加合理。基于此,本文采用残差注意力模模块(RAM)该模型针对超分辨率复原过程的特点,采取方差池化的方法预测通道注意力图[10],空间注意力则通过不同的滤波器提取图像中的边缘和纹理信息,从而使网络专注于更有用的信道并增强辨别学习能力,提升算法精度,生成更高质量的图像。模型结构如图3所示。
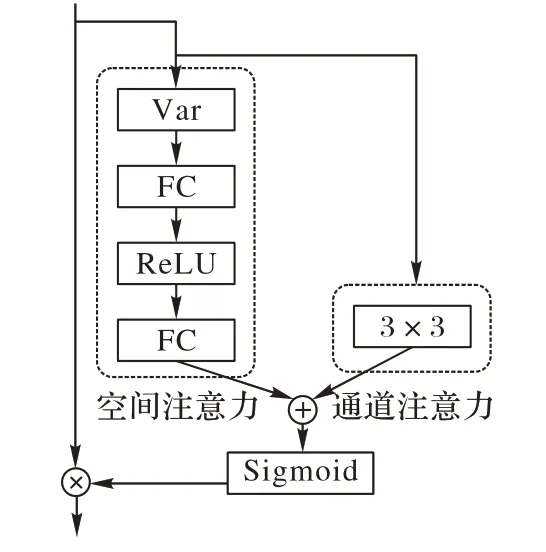
图3 RAM模型结构Fig.3 RAM model structure
如图3 所示,RAM 由通道注意力(CA)和空间注意力(SA)两部分组成,其中:CA 部分采取方差池化,求得每个通道大小为W×H的特征图的方差,然后通过两层神经网络来预测注意力图;在SA 中,每个通道代表着一种滤波器,不同的滤波器负责提取图像的不同特征,并且采用深度可分离卷积,针对每个通道的特征分别卷积得到注意力图。最后,将通道注意力图和空间注意力图相加后,经过一个Sigmoid 函数再与原特征相乘,与残差网络结合便得到RAM 结构[10]。
2.3 混合损失函数
损失函数的设计是影响网络性能的关键因素之一,超分辨率复原网络中常用的损失函数有L1 和L2 两种,分别定义如式(1)、(2):
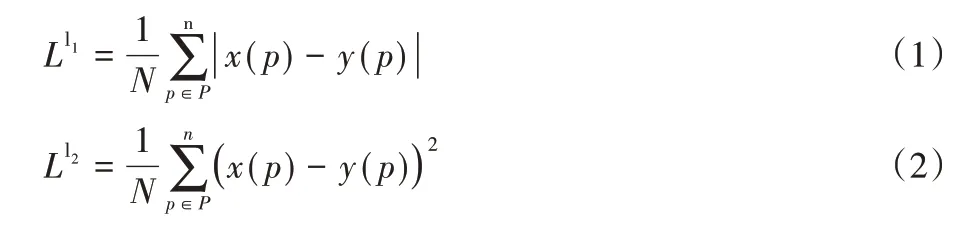
二者都能够准确计算每个像素的损失,其中L1 损失函数对两张图差异的惩罚要弱于L2 损失。有研究表明,L1 可以较好地保持颜色亮度特征。在很多情况下,利用L1 损失函数可以获得较好的图像质量。在IDN 中用L1 损失函数来度量预测高分辨率图像和对应的真实图像之间的差值。
L1 和L2 损失函数都是基于逐像素比较差异,没有考虑图像的结构性信息,虽然可以获得较高的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)指标,但与人类的主观感知尚存在一定偏差。结构相似度(Structural SIMilarity,SSIM)指标考虑了亮度、对比度和结构等指标,更重视人类视觉感知。一般而言,将SSIM 作为损失函数,得到的结果会比L1、L2 的结果更有细节,但是会生成更多的伪信息,PSNR 值会稍差一些。
本文在传统损失函数L1 的基础上引入MS-SSIM 指标,MS-SSIM 是多尺度结构相似性损失函数,容易导致亮度的改变和颜色的偏差,但能保留图像的边缘和细节等高频信息,而L1 损失函数能较好地保持亮度和颜色不变化。MS-SSIM+L1 混合损失函数的定义如式(3):
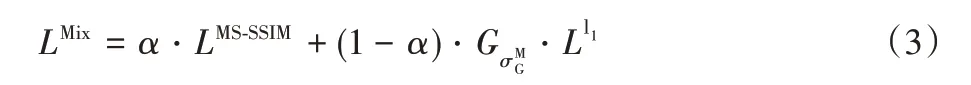
其中:α为0.84,由实验[4]得出;G为高斯分布参数。
所以,将MS-SSIM+L1 混合损失函数作为网络模型的损失函数,可以加快网络的收敛,进一步提高网络性能。
3 实验与结果分析
3.1 评价指标
为了客观评价算法的性能,本文采用PSNR 和SSIM 作为客观评价标准。
3.2 实验设置
3.2.1 数据集
本文的 训练集 是291 数据集,包 含T91 数据集[5]和BSD200 数据集[11],共291 张图片。为了充分利用训练数据,在训练之前,本文使用了3 种数据增强方法:1)将图像旋转90°、180°和270°;2)水平翻转图像;3)图像下采样,下采样因子分别为0.9、0.8、0.7 和0.6。为了得到高分辨率和低分辨率图像对,对原始高分辨率图像进行下采样,通过双三次插值的方法,得到对应的低分辨率图像。在公共测试集Set5、Set14、BSD100 和Urban100 上进行测试,得到本文实验结果。
3.2.2 参数配置
本文中的网络是使用Tensorflow 框架完成的。学习率初始设置为1E-4,在微调阶段每次减为原来的1/10。考虑到执行时间和复原质量的平衡,本算法构建了一个31 层的网络。网络中包含4 个DBlocks′,提升单元中每个block 的参数分别设置为64、16 和4。为减少网络参数,每个提升单元的第二层和第四层利用4 个分组卷积。此外,转置卷积采用17×17 大小的滤波器为所有的尺度因子。LReLU 的negative scope 设为0.05。初始化权重时,偏置都设为0,利用Adam优化,mini-batch 大小为64,权重衰减为1E-4。
3.3 消融实验
为测试分析本文设计的基于双注意力的信息蒸馏网络模型的性能,设计如下实验,对所提出的方法进行了比较和分析。
1)注意力机制。
本文实 验分别 对SE(Squeeze-and-Excitation)、CBAM(Convolutional Block Attention Module)、RAM 三种不同的注意力机制进行比较,特别针对空间和通道维度,通过实验比较分析了空间注意力和通道注意力接入方式的影响。SE 注意力中包括压缩模块和提取模块,提取的特征图与每个通道的重要性进行相乘得到全新的特征图[12];CBAM 注意力包括空间注意力和通道注意力两部分,相比SE 机制,CBAM 在空间层面上也需要网络能明白特征图中哪些部分应该有更高的响应[13];RAM 注意力同样包括空间注意力和通道注意力两部分,但与CBAM 不同的是,CBAM 将空间注意力和通道注意力串行接入,而RAM 将两部分并行接入,并和残差结构结合,使网络专注于更有用的信道并增强辨别学习能力。三种算法的实验结果如表1 所示,加粗字体表示最优结果。
从表1 中可以看出,注意力模块的加入能够从不同程度提升算法性能,其中双注意力模块CBAM 和RAM 的效果优于普通注意力模块SE 的效果,验证了空间注意力和通道注意力结合的网络比只有通道注意力的网络效果更好。RAM双注意力模块将空间注意力和通道注意力并行组合,可以看出并行的方式对特征辨别学习能力更加有效,因此RAM 残差双注意力机制是本文算法的最佳选择。

表1 不同注意力模块结果对比Tab.1 Comparison of results of different attention modules
2)损失函数。
本文实验分别对传统损失函数L1 和多尺度结构相似性损失函数MS-SSIM 及混合损失函数(MS-SSIM)+L1 进行比较,三种损失函数的实验结果如表2 所示,加粗字体表示最优结果。

表2 不同损失函数结果对比Tab.2 Comparison of results of different loss functions
本文实验表明,多尺度结构相似性(MS-SSIM)损失函数能保留图像的边缘和细节等高频信息,SSIM 值较高。L1 损失函数能较好地保持亮度和颜色不变化,PSNR 值较高。两者相结合得到的MS-SSIM+L1 混合损失函数在提升SSIM 指标的基础上,尽可能地保证PSNR 的指标不下降,甚至在个别实验结果中还有所提升。因此,MS-SSIM+L1 混合函数是本文算法的最佳选择。
3)RAM/((MS-SSIM)+L1)消融对比。
本文实验对性能较好的注意力机制(RAM)和混合损失函数((MS-SSIM)+L1)分别进行实验,最后再组合实验。实验结果如表3 所示,加粗字体表示最优结果。

表3 RAM/((MS-SSIM)+L1)消融对比Tab.3 Ablation comparison of RAM/(MS-SSIM)+L1
实验结果证明,单独使用注意力机制(RAM)时,PSNR 值较高;单独使用混合损失函数((MS-SSIM)+L1)时,SSIM 值较高。两者结合后的实验结果可以看出,在明显提升SSIM 值的基础上,整体PSNR 值能够较好地保持。因此可以得出结论,注意力机制(RAM)和混合损失函数((MS-SSIM)+L1)相结合的方案是最佳选择。
3.4 算法整体性能测试与分析
本文给出了SRCNN[14]、VDSR(Very Deep convolutional network for image Super-Resolution)[7]、DRCN(Deeply-Recursive Convolutional Network)[15]、LapSRN(Laplacian Super Resolution Network)[16]和IDN[2]共5 种 算法,在Set5、Set14、BSD100 和Urban100 数据集上分别使用2 倍、3 倍和4 倍放大因子复原图像的PSNR 和SSIM 指标结果。对比本文算法,结果如表4 所示,加粗字体表示最优结果。
通过表4 中实验结果可以看出,近年来SRCNN、VDSR、DRCN、LapSRN、IDN 等超分辨率网络,在客观指标上不断提升,信息蒸馏网络(IDN)和其他网络相比有不错的表现。本文算法在IDN 的基础上引入双注意力机制和混合损失函数,从实验结果可以看出,本文算法复原图像的PSNR、SSIM 相比前几种算法均有所提高,和效果较好的IDN 相比,PSNR 值平均提高0.02 dB,在个别指标上,略低于IDN。而且,因为引入MS-SSIM+L1 混合损失函数,所以在SSIM 指标上明显优于IDN,SSIM 值平均提高了1%。整体上,本算法的性能指标优于其他算法。
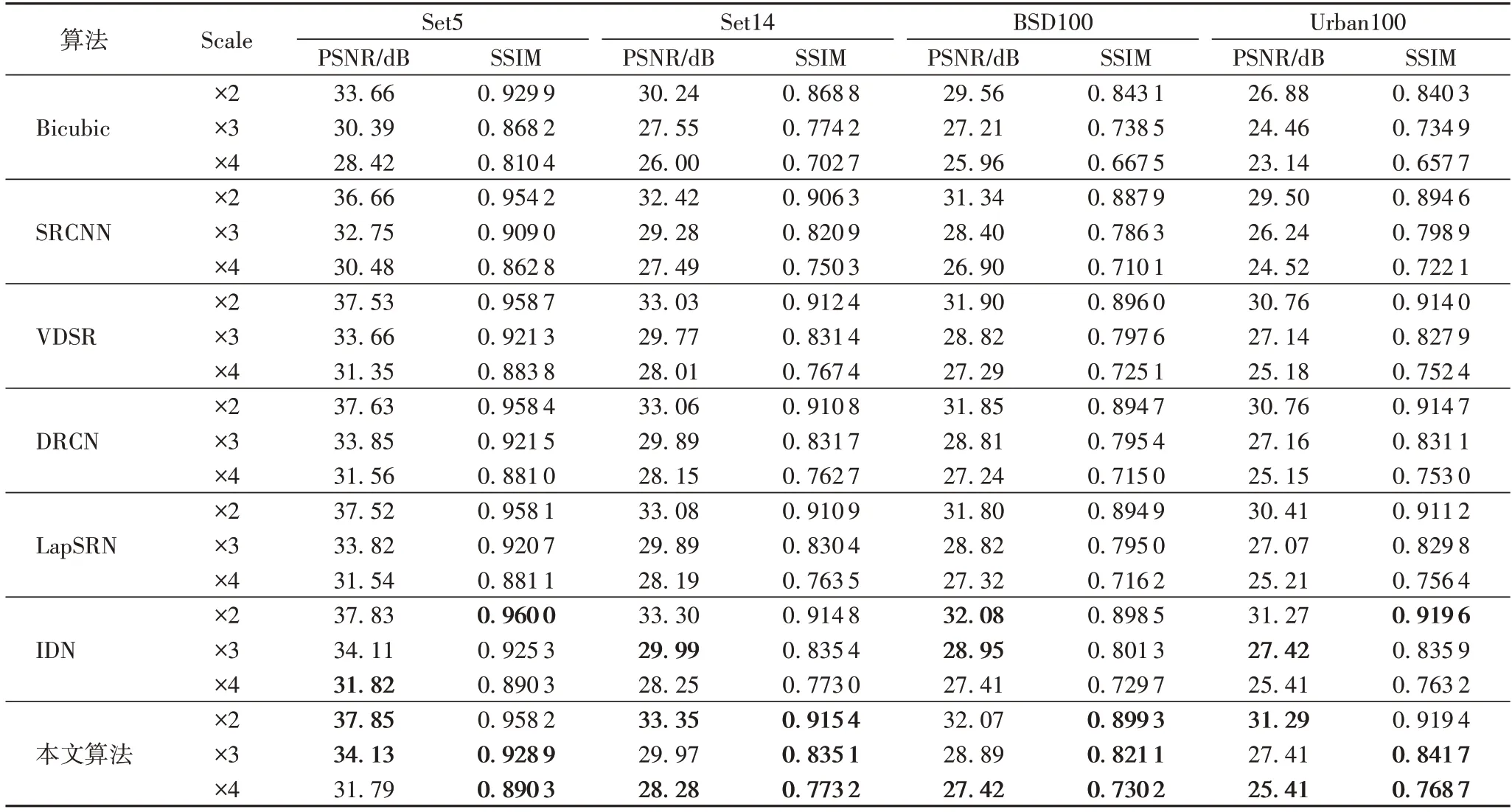
表4 六种算法对比结果Tab.4 Comparison results of six algorithms
3.5 主观结果分析
PSNR 和SSIM 作为评价超分辨率质量的传统指标,两者仅依赖于像素间低层次的差别,不能完全代表人类的视觉质量。为了表明本文算法相较于其他算法在主观视觉上的差异,本文选择了具有代表性的算法作为对比参考,各种算法复原的结果如图4 所示。
如图4 所示,图4(c)、(d)和(e)分别为比较先进的超分辨率方法复原得到的图片,图4(f)是本文设计的网络复原的图片。可以看出,本文设计的网络可以更好地恢复边缘信息,在图像纹理丰富的地方表现更佳。整体上,使用本文方法重建的高光谱图像边缘更加清晰,与原始图像更为相近。

图4 主观效果对比Fig.4 Comparison of subjective effect
4 结语
为了解决超分辨率复原技术面临的计算速度慢和边缘信息丢失的问题,本文基于信息蒸馏网络(IDN),设计了一种双注意力信息蒸馏网络的图像超分辨率复原算法。本文算法首先在保持较好精度的轻量化信息蒸馏网络模型基础下,引入RAM,该机制允许网络重新校准提取的特征图,增强网络的辨别学习能力,有效地提升算法精度。此外,利用一个混合损失函数来提高网络的收敛速度,提高图像超分辨率复原的能力。通过大量的消融实验,验证了所设计模块的有效性。该网络模型在保证网络精度的基础上,较少增加网络计算速度的压力,保证计算的实时性。后续工作将考虑残差网络以及构建更深层次的网络来进一步提高超分辨率复原效果。
猜你喜欢
疯狂英语·新悦读(2022年8期)2022-09-20
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小天使·二年级语数英综合(2021年4期)2021-06-15
河南科技(2021年35期)2021-04-25
科技知识动漫(2017年11期)2018-03-07
CHIP新电脑(2016年3期)2016-03-10
微型计算机(2009年4期)2009-12-23
