
融合BERT与标签语义注意力的文本多标签分类方法
2022-02-26 06:57吕学强董志安游新冬
计算机应用 2022年1期
吕学强,彭 郴,张 乐,董志安,游新冬
(网络文化与数字传播北京市重点实验室(北京信息科技大学),北京 100101)
0 引言
多标签文本分类(Multi-Label Text Classification,MLTC)是自然语言处理(Natural Language Processing,NLP)研究领域的重要子课题之一。随着深度学习的发展与进步,多标签文本分类技术逐渐成熟,可以被应用到现实生活中的诸多场景,比如文本分类[1]、知识抽取[2]、标签推荐[3]等方面。不同于多类别文本分类(Multi-Class Text Classification,MCTC)任务,每条数据仅关联单个标签的表示方法;多标签文本分类为每条文本数据指定多个标签,从多个标签角度去概括与提炼文本主题中心。
在有限的计算资源下,多标签文本分类对构建高效且正确的分类器模型提出了巨大的挑战,如样本标签数量庞大、样本空间的不均衡等问题。目前,在解决多标签文本分类问题的可扩展性和标签稀疏性的方向上已经取得了很大的进展。
多标签文本分类的首要问题是如何高效地从文本中提取特征。在早期,自然语言研究者们主要是通过词袋模型即通过统计词在文中出现的次数以构成向量表示,然后将由词向量与标签组成的训练数据输入机器学习算法中,以训练分类模型。然而,传统的基于词袋模型或其变体方法,忽略了词的相对位置信息,无法充分捕捉文本的上下文信息和语义特征。
随着神经网络与词嵌入技术的发展与成熟,深度学习通过学习文本的向量表示方法取得了巨大的成功,其应用较为广泛的模型包括:有效结合上下文信息的Word2vec[4]、利用词语共现频率训练的GloVe(Global Vector)[5]、基于双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)神经网络[6]模型的ELMo(Embeddings from Language Models)[7]和具有注意力机制的Transformer[8]等。近年来,自然语言处理研究领域正在经历一个里程碑式发展,即基于预训练的深度语言表示模型 ——BERT(Bidirectional Encoder Representations from Transformers)[9]。BERT 在许多NLP 任务中都达到了最领先水平,如阅读理解[10]、文本分类[11]、情感分析[12]、信息抽取[13]等。然而,在多标签文本分类方向,利用BERT 模型在数据集中微调主要面临着以下挑战:首先,现有模型难以捕捉来自不同来源标签的依赖性与相关性,其次,由于额外的线性神经网络层会随着标签量级空间线性缩放,导致缺少扩展到大量标签数据的泛化能力。
对于上述问题,本文提出了TLA-BERT(Text Label Attention BERT)模型,用一个可扩展的深度学习方法解决多标签文本分类问题。首先,将文本输入到BERT 模块,BERT将学习到蕴含文本上下文信息的编码向量;同时,将标签输入到标签编码层,利用LSTM 的长短期记忆能力获取标签之间的内在关系;然后,将BERT 输出向量与LSTM 输出向量进行注意力机制操作,从而获取每个标签与文本的特定联系,注意力机制可以显性表现出每个文档与各个标签的突出关系;最后,利用Sigmoid 函数预测每个标签的独立分布,得出多标签的预测序列。实验结果表明,TLA-BERT 在有85 万条多标签分类的数据集上的表现优于目前主流的模型。本文的主要工作如下:
1)提出了TLA-BERT 模型,在多标签分类任务上应用大规模预训练语言模型,学习文本的深层句法语义信息;提出基于标签语义与文本特征融合的注意力机制,显性表达标签与文本的关系表示的特征权重,从而提升模型的效果。
2)提出的TLA-BERT 模型在5 万条数据的AAPD(Arxiv Academic Paper Datasets)[14]与80 万条数据的RCV1(Reuters Corpus Volume I)-v2[15]公开数据集上取得了较好结果,相较于其他基线模型方法,F1 值提升了2%~3%。
1 相关工作
对于解决多标签文本分类的任务,自然语言研究者们已经提出了许多有效的方法。根据词语特征的表示方法,一般可将其分为两类。一类是以传统的词袋模型作为特征,它包含三种不同的方法:一对多方法、基于词嵌入的方法和基于树模型的方法。另一类是深度学习方法,深度学习模型通过深度神经网络结构从原始文本中学习丰富的句法语义信息,并在不同的NLP 任务上取得了巨大的成功。
1)一对多方法。一对多方法将每个标签独立地处理为一个二分类问题,同时为每个标签单独学习一个分类器。一对多方法已经被证实可以达到很高的准确率,但是当标签的数量级非常庞大时,它们的准确性会受到复杂度计算的影响而有所下降。Yen 等[16]提出PDSparse(a parallel Primal-Dual Sparse method for extreme classification)为每个标签学习一个单独的线性分类器。在训练过程中,分类器通过优化标签分布从而区分每个训练样本的所有正标签和少量活跃的负标签。杨菊英等[17]提出一种基于划分子集的带标签隐含狄利克雷模型,通过对数据划分子集降低算法的时间复杂度。Jain 等[18]提出Slice 模型利用负值采样技术训练最容易混淆的负标签,针对性地解决了标签样本不均衡带来的问题。
2)基于词嵌入的方法。词嵌入模型通过利用标签的相关性和稀疏性将高维标签空间投影到低维空间。由于压缩阶段必不可少的信息损失,词嵌入的方法会在预测精度方面付出相应代价。姚佳奇等[19]基于标签语义的动态多标签文本分类算法,将标签语义转换为特征向量,然后通过近邻算法得出标签分类结果。檀何凤等[20]通过使用K近邻图作为弱监督方法来分割文本标签之前的关系,然后通过求得标签值的最大化后验概率来构造多标签分类模型,对新标签进行预测。
3)基于树模型的方法。基于树的方法通过构建一个树形的标签结构,将实例或标签划分到不同的组中,使相似的标签可以在同一组中。最初分配给根节点的整个标签集合,然后将集合分割成固定数量的k个子集,对应根节点的k个子节点。重复进行分割流程,直到所有标签被划分完成。在预测阶段,输入的实例沿着树向下传递,直到到达叶子节点。每个叶子节点代表一个标签,收集所有叶子节点的表示即可得到该实例的预测结果。对于实例树,预测是由在叶实例上训练的分类器所给出的。对于标签树,标签的预测是通过从根节点到叶节点的遍历节点而确定的概率。FastXML(a Fast,accurate and stable tree-classifier for eXtreme Multi-Label learning)[21]通过优化nDCG(normalized Discounted Cumulative Gain),在特征空间维度上学习树的结构模式,为每个内部节点训练一个二元分类器,最终预测出给定实例的标签分布。AttentionXML(label tree-based Attention-aware deep model for high-performance eXtreme Multi-Label text classification)[22]利用PLT(Probabilistic Label Tree)[23]结构训练一个浅层且宽广的标签概率结构树,以减少大量标签对训练过程带来的计算负担,同时,AttentionXML 利用BiLSTM 来捕捉词语之间的长距离依赖性,利用注意力机制以突出表示文本与标签相关联部分。
4)深度学习方法。相较于简单的词袋模型作为文本表示,将原始文本编码成词向量的技术已经开始在深度学习模型中有效利用。神经网络通过学习高纬度的文本表示向量,以捕捉文本上下文的语法和语义信息。SGM(Sequence Generation Model)[14]基于Seq2Seq 的方法使用一个循环神经网络(Recurrent Neural Network,RNN)对给定的原始文本进行编码,并使用一层新的RNN 作为解码器,依次生成预测标签。这种序列生成的缺点也非常明显,后续生成的标签正确与否过于依赖上一个时间序列的结果,导致标签的预测结果会相互影响。肖琳等[24]提出了一种基于标签注意力的多标签文本分类方法,通过文档和标签之间共享单词表示,利用注意力机制捕获重要单词的方法提升模型效果。王敏蕊等[25]利用BiLSTM 与注意力机制构建了基于动态路由的序列生成模型,该模型利用动态路由聚合层参数的全局共享减弱了累积误差产生的影响。
2 TLA-BERT
本文提出的模型TLA-BERT 的框架主要由三部分组成:BERT 模块、标签嵌入层、多标签注意力层,如图1 所示。受注意力机制的启发,由于注意力机制利用权重比可以有效引导文本信息进行分类,本文提出了基于标签语义与文本特征融合的注意力机制,利用标签语义信息学习不同标签对应数据文本的重要性权重,最终利用Sigmoid 函数预测每个标签的独立分布,得出多标签的预测序列。
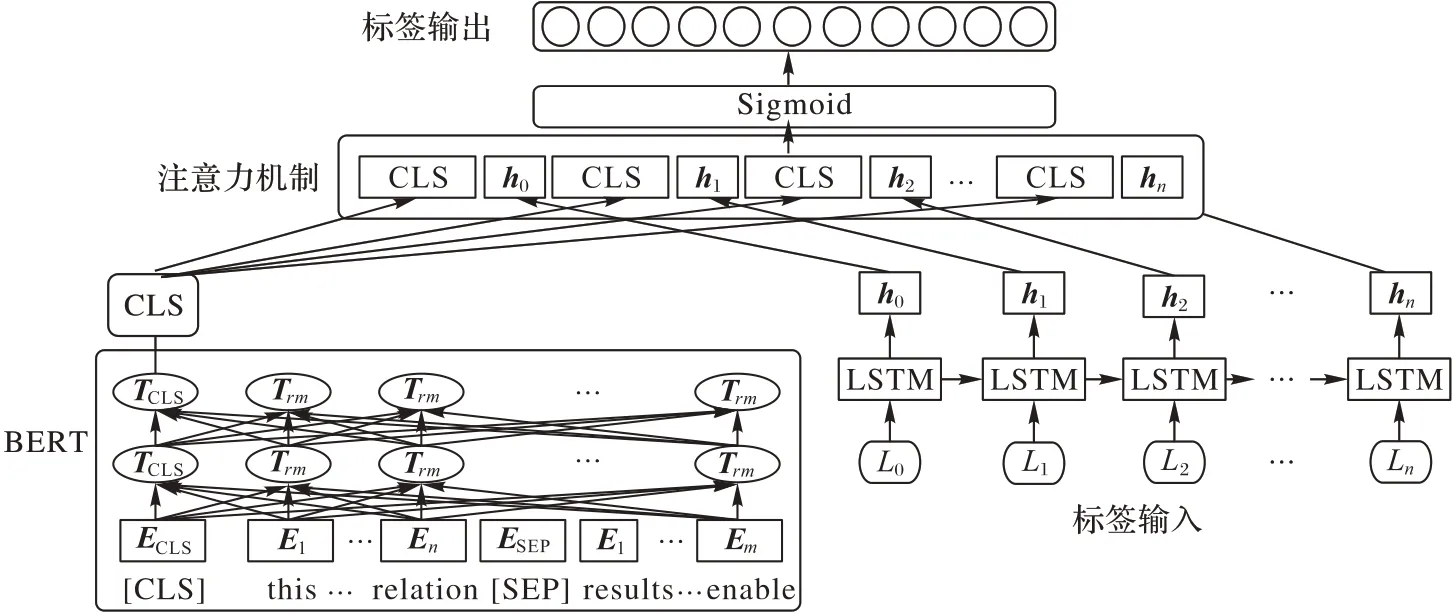
图1 TLA-BERT模型结构Fig.1 TLA-BERT model structure
2.1 BERT模块
预训练语言模型在自然语言处理任务上取得了显著进展,首先在无监督目标下对海量文本进行预训练,然后在特定任务数据上进行微调。语言模型是指通过给定文本的上下文来预测下一个词的任务,在训练过程中模型可以有效地学习文本潜在的深层语义、语法信息。BERT 通过自动随机掩码机制来预测文本中的缺失词,同时利用上下句预测(Next Sentence Prediction,NSP)任务来联合表达文本的语句序列表示。BERT 通过最大化预测词的似然函数进行训练[26],似然函数计算公式如式(1)所示:
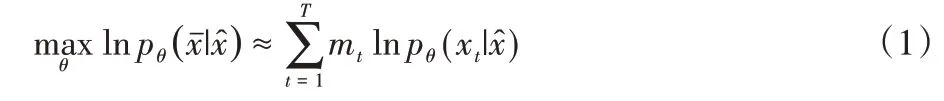
其中:θ表示模型参数,为被预测目标词,表示目标词的上下文。当mt=1 时,表示该词被掩码,将被“[MASK]”标记替换。
将BERT 模型应用到TLA-BERT 中来学习文本的向量表示,再通过微调的方法适应多标签文本分类任务模式。BERT 首先将句子通过“[CLS]”与“[SEP]”分隔同时输入到模型中表示为En,每个词的嵌入维度为768,再通过12 层Transformers Encoder 结构将每个词转换成富含句法语义特征的Tn,取其中特殊的TCLS特征向量以表示句子的全局上下文信息。“[CLS]”标识不代表文本中某个特殊的字或词,它将与句子中的每个词进行自注意力操作,因此可以学习到句子每个词的上下文语义信息,将其作为分类依据体现一定的公平性与合理性。
2.2 标签语义编码层
在标签编码层,首先,将标签文本信息进行嵌入编码,以获取标签的向量表示;然后,通过LSTM 结构的记忆力机制以获取标签之间的关联性;最后,融合BERT 的输出层进行联合注意力机制,其计算式如式(2)(3)所示:

其中,E∈Rl×e(l为标签数量,e为词向量维度);Hi∈Rl×h(h为LSTM 隐藏层维度)。标签编码的作用在于将所有标签特征通过LSTM 提取,扩大标签的向量维度,为后续的注意力机制提供计算的便捷性与可解释性;同时,利用LSTM 的长短期记忆力结构特征可以学习到不同标签之间的内在连续特征,比如:标签之间含有包含关系或者层级关系等。
2.3 多标签注意力层
TLA-BERT 将BERT 模型的CLS 输出层与标签的LSTM隐藏层进行分离注意力融合操作,将得到CLS 向量与每个标签的权重,再将权重分配给CLS 向量,其计算式如式(4)、(5)所示:

其中,αti∈Rh为BERT 模块的CLS 输出层,通过αti与Hi进行注意力操作,可以得到“[CLS]”与每个标签编码的相对应关系。注意力机制可以有效地突出文本特征与标签之间的显性表达,最终通过Sigmoid 函数映射到标签维度,得到每个标签的预测结果,其结构如图2 所示。该结构的优点在于使得模型可以分别预测每个标签的独立分布,同时将概率分布映射到0~1,降低标签数量所带来的计算维度增长。
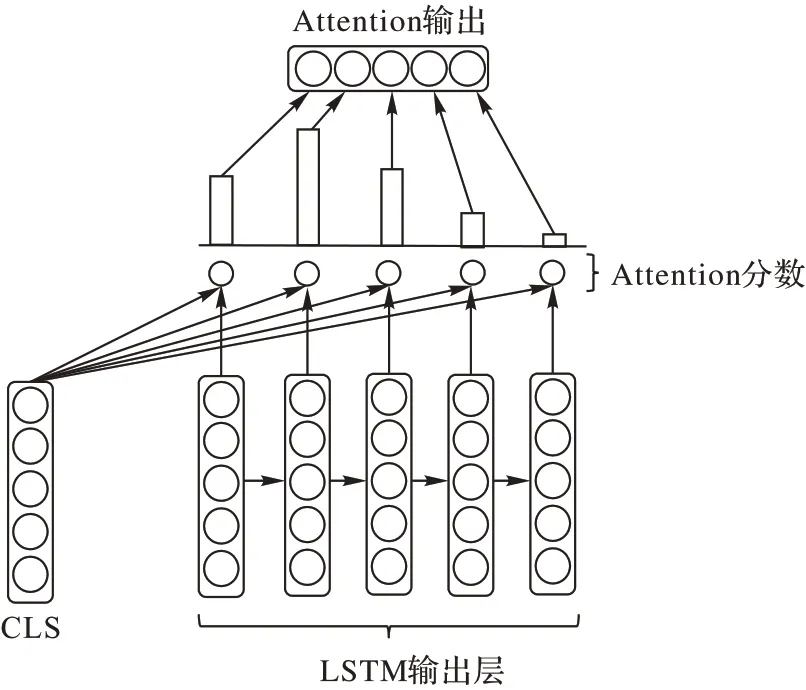
图2 多标签注意力层Fig.2 Multi-label attention layer
2.4 损失函数
不同于多类别分类的归一化输出,多标签分类由于每个实例的标签数量不同,模型将不对预测的概率进行归一化处理。假设在标签进行排列后,{Lk}k=1,2,…,K表示标签的索引。在给定实例xn,第k个标签的概率为p(yk|xn),其计算式表示如式(6)所示:
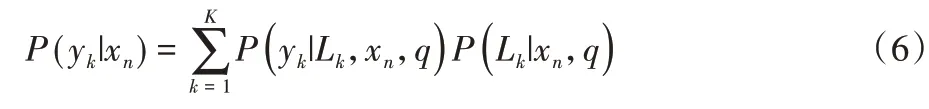
3 实验与结果分析
在两个公开数据集上对提出的TLA-BERT 性能进行评估。首先介绍了数据集、评估指标、实验细节和所有基线对比模型;然后将TLA-BERT 与基线模型进行比较;最后对实验结果进行了分析与讨论。
3.1 数据集
1)AAPD 数据集。该数据集为北京大学大数据研究院提供的公开英文数据集(2018 年),数据集主要包括从网站上收集的55 840 篇计算机科学领域论文的摘要与相对应的主题。一篇论文摘要可能包含多个主题,总计54 个主题词。多标签文本分类的目标是根据摘要内容预测学术论文所对应的主题。
2)RCV1-v2 数据集:该数据集是由Lewis 等[15]提供的公开英文数据集(2004 年),由路透社有限公司为研究人员提供的800 000 多条人工分类的新闻通讯报道组成。每篇新闻报道文章包含多个主题,总计103 个主题。数据集详细信息如表1 所示,其中70%划分为训练集、15%划分为验证集,15%划分为测试集。同时对每条文本根据数据长度进行截断,阈值为512;词库以外的词(Out-of-Vocabulary,OOV)将被“UNK”替换。

表1 数据集简介Tab.1 Dataset description
3.2 评估方法
与其他多标签分类方法使用的评价指标相同,采用二元交叉熵损失(Binary Cross Entropy Loss,BCELoss)与Micro-F1[27]来评估模型的准确性与泛化能力。
1)BCELoss:或称对数损失,衡量一个分类模型的性能,该模型的输出是0 和1 之间的概率值,交叉熵损失随着预测概率与实际标签的偏离而增加,其表示如式(7):

其中:xn为训练训练数据,yn为标签,wn为模型参数。因此,当实际观察标签为1 时,预测概率非常小,会导致损失值很高;一个完美的模型其损失为0。
2)Micro-F1:可表示为精度和召回率的加权平均值,它是通过统计总的真正例TPc(预测正确的标签数据),假负例FNc(正确标签但模型预测错误的数据)和假正例FPc(模型预测错误的正确标签数据)得到。其计算式表示如式(8)~(10)所示,其中N为样本数。
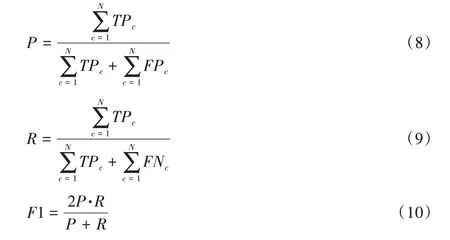
3.3 结果分析
3.3.1 对比实验
为了充分验证本文方法的有效性,选择以下多标签文本分类算法进行对比实验。
BR(Binary Relevance)[28]:由Boutell 等2004 年提出的多标签文本分类模型,其主要是思想是将多标签分类分割成多个二分类,然后训练多个二元分类器进行标签预测。
CC(Classifier Chains)[29]:由Read 等于2011 年提出的链式分类模型,将多个标签用链式分类器连接,并将高阶标签分配较大的权重,以提高模型正确率。
LP(Label Powerset)[30]:由Tsoumakas 等2006 年提出,将多标签分类标签问题转换为多类别问题,用一个多类分类器对所有独特的标签组合进行整合训练。
CNN(Convolutional Neural Network)[31]:由Kim 等2006 年提出,利用卷积神经网络(CNN)获取文本的局部语法语义信息,并且使用多个卷积核提取多维特征,最后对多标签分类的损失函数进行软边界优化。
CNN-RNN(Convolutional Neural Network-Recurrent Neural Network)[32]:2017 年由Chen 等提出,同时利用CNN 与RNN 捕获文本的长短期依赖关系,最后将标签与文本进行混合解码。
SGM[14]:2018 年由Yang 等提出,将多标签分类任务转化为一个序列生成问题,并应用具有新型结构的解码器来解决序列生成模型的标签依赖关系问题。
MAGNET(Multi-label Attention-based Graph neural NETwork)[33]:2020 年由Pal 等提出,利用BiLSTM 提取文本的上下文特征,然后使用图神经网络构建各标签之间的内在联系。
文本提出的TLA-BERT 利用预训练语言模型BERT 提取文本上下文的深层句法语义特征,将其投影映射到标签维度,随后与使用LSTM 编码后的标签维度进行注意力机制融合,显性地突出表示文本与标签的特征关系。
本文实验在以下环境进行:NVIDIA TESLA V100-32G 显卡,Pytorch 1.4,Python 3.8。
在训练过程中,本文方法采用“bert-base-uncased”预训练模型,其BERT 模型结构包含12 层Transformers,隐藏层维度为768,Head 数量为12。对于标签编码层,标签嵌入维度为256,LSTM 隐藏层维度为768。另外,本文采用Adam[34]优化器来加速神经网络的训练过程,其初始学习率为α=3E-5,动量参数β=0.9,衰减学习率ε=1× 10-5。同时,在文本与标签编码层,采用Dropout[35]正则化技术以防止网络过拟合,其Dropout 概率为0.5。
对比实验结果如表2 所示。实验结果表明,本文提出的方法在主要评价指标中获得了最好的结果。在AAPD 数据集上,TLA-BERT 的正确率与召回率相较于其他深度学习模型的最优值有一定提升,F1 值提升了1.7 个百分点;在RCV1-v2 数据集上,TLA-BERT 的F1 值相较其他方法中的最优模型提升了0.6 个百分点。在所有模型中,本文提出的TLA-BERT 标签注意力机制模型在两个数据集上都取得了总体最好的召回率与F1 值。CNN 模型相较于其他模型有着最好的正确率,究其原因在于其模型基于字符级别的模型结构,利用CNN 特点细粒度地抓取标签与字符文本的关联,一定程度上提高了模型的正确率。

表2 AAPD与RCV1-v2数据集上的对比实验结果Tab.2 Experimental results of comparison on AAPD and RCV1-v2 datasets
3.3.2 消融实验分析
为了验证本文提出的文本与标签编码联合注意力方法的有效性,将标签编码“TLA 模块”作为实验的消融变量。“BERT-noTLA”表示将文本输入到BERT 模型中,再通过全连接层映射到标签维度,最后通过Sigmoid 分别对每个维度计算所有标签的分布。消融实验结果如表3 所示,TLA-BERT 相较于未融合标签编码的“BERT-noTLA”方法,在两个公开数据集中均有所提升,这进一步证明了全局嵌入标签编码内容能够帮助模型更准确地预测多标签序列。
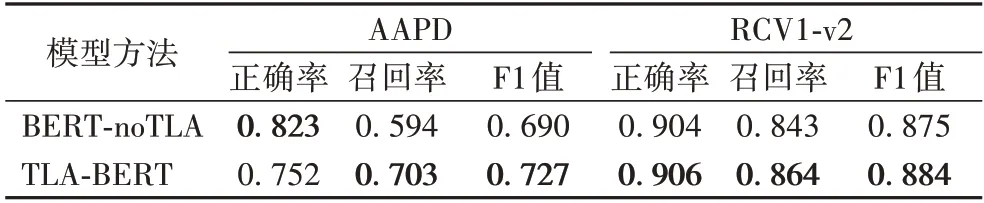
表3 AAPD与RCV1-v2数据集上的消融实验结果Tab.3 Experimental results of ablation on AAPD and RCV1-v2 datasets
4 结语
本文提出了一种融合BERT 与标签语义注意力的文本多标签分类方法。该方法通过预训练语言模型BERT 学习文本的深层句法语义特征表示,有效地融合文本的上下文信息;利用注意力机制充分学习多个标签与文本的概率分布特点,从而提升模型在多标签分类任务上的性能。实验结果表明,本文方法在两个公开基准数据集上取得了较好结果,同时通过实验分析得出:本文方法不仅能够捕捉到标签之间的相关性,而且注意力机制可以通过融合标签与文本的内在关系来提升模型效果。在未来的工作中,将在多标签文本分类任务上考虑不同粒度的注意力机制结合方式,期望通过不同的注意力结合以获取更为丰富的文本、标签的语义表示内容,从而高效准确地预测标签序列。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
海峡姐妹(2018年3期)2018-05-09
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
长江学术(2015年1期)2015-02-27
中学英语之友·高一版(2008年10期)2008-12-11
