
机会网络中基于节点效用和能量的路由算法
2022-02-25 02:54袁培燕黄笑妍
郑州大学学报(理学版) 2022年2期
袁培燕, 黄笑妍
(河南师范大学 计算机与信息工程学院 河南 新乡 453007)
0 引言
传统网络中的节点在通信之前必须先找到一条端到端的通信链路,再完成数据包的转发任务,这意味着传统网络拓扑在大多数时间内是连通的,并且源节点和目的节点之间至少存在一条连通链路。在某些实际应用场景下,源、目的节点对之间通常不存在端到端的多跳链路,导致传统网络的路由策略无法有效运行。为了解决特殊环境下的通信问题,机会网络受到科研人员的广泛关注。机会网络利用节点移动过程中形成的相遇机会,采用“存储-携带-转发”的方式进行数据传输[1-2],对节点随机移动、分布密度不定、有限的通信范围等特性,具有较强的适应性。因此机会网络在车载设备所形成的车载网、野生动物信息收集、大型集会(如大型体育赛事现场、演唱会等)、偏远地区以及深空通信等领域具有广泛的应用前景。
机会网络的网络拓扑频繁变化且链路持续时间不确定,所以网络被划分成若干个不连通的子区域,又可称为“间歇性连接网络”[3]。在这样的网络环境中进行数据传输不能事先确定转发路径,需要采用边路由边传输的方式选择每一跳节点。数据包在经历多跳后,传送至目的地。路由决策问题一直是机会网络的研究重点,其实质是如何选择合适的中继节点协助完成数据传送任务。到目前为止,机会网络中的路由协议按照选择中继的方式可以分为两类:一类是零信息型路由,不需要依赖复杂的网络信息,仅利用节点移动产生的相遇机会完成数据传输;另一类是信息辅助型路由,需要依靠额外的信息才能做出转发决策,即根据节点信息计算节点的效用值,进一步选择高效用节点路由数据包,又称为效用路由。
零信息型路由没有考虑网络中节点的异质性,采用较为单一的路由方式完成数据包的交换和传递。信息辅助型路由是当前路由工作研究的重点,评估函数根据不同类型的参数信息对节点路由数据包的能力进行判断。这些信息可以分为节点的历史接触信息[4-6]、节点的社会性信息[7-11]、节点的位置信息[12-15]、节点能量信息[16-18]等。机会网络中的许多路由协议是互有交叉和联系的[9-10,14],最终目的是针对不同的网络环境,综合节点的多方面信息,衡量节点的转发能力以提高网络性能。为进一步提高网络的投递率和传输速度,在信息辅助型路由的基础上,研究人员提出了效用和冗余混合的路由方案,但该方案可能存在较高的网络开销。此外,数据包始终朝着高效用节点方向传输会造成高效用节点的能量过多消耗。特别是在能量有限的情况下,一旦高效用节点的能量消耗殆尽,将加剧网络间歇性,使得网络性能急剧下降。考虑到依靠节点的社会属性信息选择中继已经被证明可以取得较好的路由性能,本文利用节点的社会效用指导路由,进一步降低网络开销,均衡节点在数据传输过程中的能量消耗,以避免高效用节点能量消耗过快。
基于上述分析,本文提出了一种基于节点效用和能量(probability and energy,ProEnergy)的多副本路由算法,在保证较优网络性能的前提下充分利用节点的效用降低网络开销和均衡节点的能量消耗。
1 算法设计思路
1.1 路由设计思路
机会网络中的节点大多由人携带的智能终端构成,其表现出的社会活动可能遵循某些社会特征[19]。不同的路由协议利用节点的中心性、相似性、社区属性等不同的社会度量来选择合适的中继节点[20-22]。在以往的基于社会属性的路由工作中,忽略了节点关系的自身差异性和动态变化性对路由数据包的影响,所以本文提出新的效用指标衡量节点的社会关系。为避免多备份路由中出现过高网络开销的问题,该路由算法研究如何充分利用节点关系进一步降低网络开销。此外,为防止网络中高效用节点因过多的数据传输导致能量过快耗尽而加重网络的间歇性,在数据转发过程中,利用节点的社会效用和剩余能量共同判断节点的转发能力,以实现均衡节点能量的目的。
本文提出的路由算法的设计思路如图1所示,首先构建网络模型,维护节点的接触信息和信息更新机制,为数据转发工作提供充分的准备;其次,设计了基于节点效用和能量的路由方案,主要包括识别亲密节点、构建关系模型、路由决策三大步骤。

图1 ProEnergy算法整体方案设计Figure 1 Overall scheme design of ProEnergy algorithm
1.2 基于社会属性的机会网络模型
本文利用具有时间属性的接触图Gt(V,E)构建具有社会特征的网络模型。假设网络中有n个节点,V={v1,v2,…,vn}表示节点集合,tx表示时间,相关定义如下。
定义1邻居节点集合。网络中任意两节点vi和vj的距离小于某个阈值d,则两节点互为彼此的邻居节点。节点vi在tx时刻下的邻居节点集合为Nb(vi),表示为
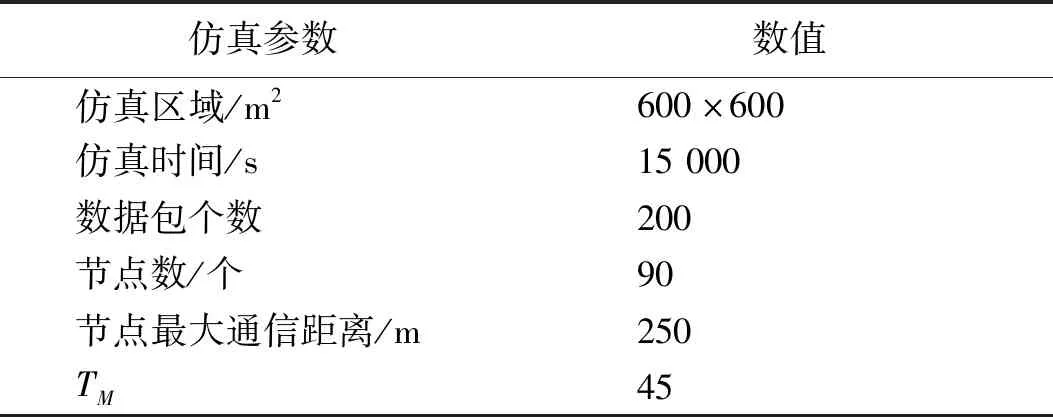
Nb(vi)={vj|D(vi,vj) (1) 其中:D(vi,vj)为节点vi和vj的通信距离;d为两节点可通信的最大距离。 (2) (3) 定义3节点的接触强度。在tx时刻,节点vi和vj的接触强度定义为两节点接触时长与断开时长之比。 (4) 定义4平均接触强度。节点vi在tx时刻下的平均接触强度表示为当前与历史通信节点的接触强度总和的平均,代表节点vi在网络tx时刻下接触的平均水平。 (5) 其中:N(vi)和|N(vi)|分别表示节点vi的历史接触的邻居节点集和历史接触邻居节点个数。N(vi)根据节点vi在tx时刻下的接触情况进行更新。 N(vi)=N(vi)old∪{vj|D(vi,vj) (6) N(vi)old表示节点vi在tx-1时刻下历史邻居节点集。所以节点的历史邻居节点集由前一时刻的历史邻居节点集与当前时刻新加入的邻居节点构成。 基于全局的时间可以较好地对比不同节点间接触强度,但并不能较好地反映单对节点间接触强度的瞬时变化。因此,挖掘单个节点对在短时间内接触强度的变化规律,预测两节点未来的接触强度,可更加有针对性地指导路由完成工作。本文采用GM(1,1)预测模型,该模型是一种小样本预测模型,可以利用少量的历史数据预测下一时刻的数据,对不确定性情况有较好的预测效果[23-25]。假设某节点对在当前时刻tx下是接触状态,而在未来的tx+1时刻其接触状态不确定,且与节点在过去tx-1、tx-2、…、tx-n时刻的接触或断开状态并无关联。节点运动在长时间下呈现突变性和不规律性,随着网络时间的增加,两节点在tx-n与tx+n时刻下的接触强度可能会发生较大变化。而节点在短时间内的接触强度变化浮动较小,可能呈现出某种规律性。因此,可以利用这种变化规律,对未来短时间内节点的接触强度进行预测。 GM(1,1)的接触强度预测过程如下。 1)获取当前时刻tx与其历史w-1个时刻节点的接触强度,共计w个时刻的接触强度,由此给出原始的接触强度序列, (7) (8) (9) 3)对累加后的接触强度序列建立GM(1,1)模型的一阶微分方程,其相应的白化微分方程为 (10) 其中:a称作发展系数;b称作灰色作用量,均为常数。采用最小二乘法求得a、b的值,满足等式 [a,b]T=(BTB)-1BTY, (11) 其中: (12) 4)将矩阵展开得到参数a、b的表达式: (13) (14) 5)求解微分方程,得到GM(1,1)模型的离散解, (15) 6)还原为原始数列,预测模型为 (16) 将式(15)代入得 接触强度的预测方法充分考虑节点的运动特性,以节点在较短时间内的运动规律为基础,挖掘节点间的接触强度随时间推移的动态特征,更适用于预测在未来短时间内节点间的接触强度。 节点依靠社会环境生存,而不是独立个体,每个节点都会存在相对亲密的社会关系。节点与其存在亲密关系的节点可能会存在较多的接触机会,所以我们认为节点与存在强接触关系的节点存在相对亲密的社会关系。为了进一步分析节点关系,以帮助减少网络开销,首先利用节点接触关系来建立节点关系矩阵。 定义6关系矩阵。根据节点的平均接触强度维护一个n×n的关系矩阵R, (17) (18) (19) Apriori算法由Agrawal于1994年提出,该算法是经典的挖掘数据关联规则的算法[26-27]。图2给出了该模型的工作流程,主要分为两大步骤:第一步是发现频繁项集,目的是从数据集中找出频繁出现的项集;第二步是发现关联规则,即在频繁项集中利用条件概率求出关联规则,利用潜在规律进行预测。Scan称为数据集选择过程,主要作用在于支持度过滤,删除不满足最小支持度的项集,保留满足最小支持度的项集。 图2 基于Apriori算法的关系挖掘模型Figure 2 Relationship mining model based on Apriori algorithm 针对本文提出的网络环境,结合Apriori算法建立关系模型,节点的关系矩阵R作为模型输入,最终获得节点的社会转发效用,帮助路由做出转发决策。模型根据输入的关系矩阵R,将每个节点存在的亲密关系保存在关系事务样本Ω相应的记录中。候选项集C1、C2和频繁项集L1、L2中的每个元素都是一个集合,且集合中元素为网络中的节点。C1、L1中每个元素称为1-项集,C2、L2中每个元素称为2-项集。1-项集和2-项集又统一称为项集。 由图2可知,根据Ω产生候选1-项集,则C1={{v1},{v2},…,{vn}},其包含事务样本中所有的节点项,即共包含n个1-项集。Scan过程的最初阶段为计算项集频度,该阶段是以候选项集C为基础进行计算。假设项集用I表示,在网络当前时间tx下,项集I的频度定义为 (20) (21) 其中:F(I,k)表示网络中第k个节点和项集I中所包含节点的关系函数。项集I又分为1-项集I1和2-项集I2。当I=I1,计算1-项集频度,最终获得该节点在tx下存在亲密关系的数量。假设I1={vi},其中vi为网络中的第i个节点,则函数F(I,k)=F(I1,k)且k≠i,其取值情况为 (22) 当I=I2,计算2-项集频度,最终获得项集中两节点在tx时刻下存在共同亲密节点的数量。假设I2={vi,vj},则函数F(I,k)=F(I2,k)且k≠i或k≠j,其取值情况为 (23) (24) (25) (26) 在ProEnergy路由方案中将节点能量的初始值设置为500,假设节点在接收和转发数据包时均会消耗1个单位的能量。根据节点的剩余能量来决定是否参与数据的转发,当节点的能量小于某个阈值时,其只接收需要传送到该节点的数据包。只有当节点的能量大于该阈值时,则需综合节点的社会转发效用和剩余能量共同计算节点的转发能力, (27) (28) 其中:Cmin表示网络中节点能量剩余的最小值;Cmax表示网络中节点剩余能量的最大值。在对能量进行标准化处理后,依据节点的剩余能量和社会效用共同计算中间节点的转发能力,并指导路由工作的完成。为了较好地平衡网络性能和资源消耗问题,权重因子λ的取值会在实验部分给以详细说明。 本文提出的ProEnergy路由算法主要步骤如下。 输入:M是数据包,dM是M的目的节点,tx是网络运行的当前时刻,GM(1,1)保存了tx-5到tx-1时刻下节点间接触强度 输出:M是否转发 1)for 任意节点a、b、dM∈Vdo 2) ifa和b相互通信且M由a携带 then 4) ifb没有携带M的副本 then 5) ifa和b的能量大于50 then 6) ifb是M的目的节点 then 7) 更新包信息,a转发M给b 8) else 11) ifP(a,dM) 12) 更新包信息,a转发M副本给b 13) end if 14) end if 15) end if 16) end if 17)end if 18)end for 为了性能评估,本文实验基于移动机会网络模拟器平台[28]。节点的移动轨迹使用RealTrace-KAIST数据集[29],其他的仿真参数如表1所示。利用Apriori算法计算关联概率时,最小支持度TM设置为45。本文使用数据包的投递率、传输时延、网络开销、总能量消耗、能量消耗标准差5个指标来评价路由算法的性能,并与Prophet算法、PageRank算法、GeoSocial算法进行对比。 表1 实验参数设置Table 1 Setting of experimental parameters 首先分析λ对网络性能的影响。图3(a)给出了λ取值范围在0.5~0.8下的投递率情况,观察可知4种情况下的投递率走势相似,从λ=0.8到λ=0.5的投递率依次下降,是因为节点的社会效用影响逐渐减小。ProEnergy采用多副本的路由方式,所以在不同λ取值下均获得较高的传递概率。图3(b)给出了传输延时情况,观察可知λ=0.7时其传输时延最低;当λ=0.5时其传输时延较高,是由于当λ值较小时,因数据包被较多传送到能量相对较高、但关联概率较低的节点上,从而导致时延增大。图3(c)给出了网络开销情况,观察可知取λ=0.5~0.8,节点的网络开销依次减小。当λ增大,那些关联概率较小,但能量较高节点携带数据包的机会就越小,所以造成网络副本数有所降低。通过综合的对比分析,当λ=0.7时,路由可以获得最优的网络性能。 图3 不同 λ下的实验结果Figure 3 Experimental results with different λ 图4(a)给出网络中90个节点的总能量消耗情况。可以看出4个算法的能量消耗随仿真时间的运行而增加。仿真时间在3 200 s之前,ProEnergy算法总能量消耗大于Prophet算法,是由于仿真初期节点的接触次数有限,Prophet算法只计算通信范围内节点的效用。而ProEnergy算法是根据历史通信记录计算节点的社会效用,由于在网络初期节点间的接触情况不稳定,且节点能量充足,使较多的节点参与数据转发工作,而造成较高的能量消耗。但随着实验进行,ProEnergy算法消耗的总能量趋于稳定,而Prophet算法却不断增加。仿真结束时,PageRank算法的能量消耗达到35 000 J左右,是路由算法中消耗最高的。GeoSocial算法的能量消耗达到34 000 J左右,Prophet算法消耗达到29 000 J左右,而ProEnergy算法为21 000 J左右。 图4(b)给出了节点能量消耗标准差随仿真时间增加的变化情况。每隔600 s就对90个节点的剩余能量进行一次输出,再经计算最终得出90个节点在每600 s内能量消耗的标准差。从图4中可以看出,所有算法在仿真初期(0~3 000 s),标准差的起伏变化较大,这是因为消息在网络中分布不均匀造成的,3 000 s后可以明显看到ProEnergy算法的标准差小于其他3种路由算法,说明ProEnergy算法能够均衡节点的能量消耗,在数据传输时不过度利用某一个节点进行数据转发,避免某些高效用节点因能量耗尽过早死亡。 图4 能量实验结果Figure 4 Energy experiment results 4种算法的投递率如图5(a)所示,4种算法均以多副本的方式完成路由工作,所以都获得较高的投递率。可以看出,仿真实验在7 000 s之前PageRank算法明显高于其他三种算法。当仿真实验结束时,PageRank最终投递率为0.98,GeoSocial为0.97,ProEnergy为0.96,三者投递率接近,Prophet算法投递率较低,为0.89。当高效用节点能量不充足的时,ProEnergy算法让社会关系较小且能量充足的节点也能够优先发送消息,相比Prophet算法,在相遇时根据接触信息更新节点效用获得了更好性能,避免数据包在节点缓冲区中过久存储而造成包丢弃的情况出现。 4种算法的平均传输延时如图5(b)所示,可以看出随着仿真时间的增加,算法的传输延时增大。在仿真初期(0~3 200 s),GeoSocial算法的传输延时最大,但之后,Prophet算法随着仿真时间的增加,传输延时不断增大,是由于Prophet算法在节点接触时更新节点效用,且由高效用节点携带数据包,没有考虑节点的能量问题,将节点传递给高效用节点后,高效用节点可能因过多能量消耗,加重网络间歇性,导致较高的传输延时。在仿真结束时,Prophet的时延最大,大约为2 050 s,GeoSocial大约为1 400 s,而ProEnergy略高于PageRank,PageRank大约为800 s,ProEnergy大约为870 s。ProEnergy算法相比Prophet和GeoSocial算法可以有效避免因关键节点能量过早耗尽而减小传输时延。 4种算法的平均网络开销如图5(c)所示。平均网络开销表示网络中产生的所有数据包副本数与数据包总数的比值。仿真实验在3 200 s之前,ProEnergy算法网络开销大于Prophet算法,但之后ProEnergy算法网络开销逐渐平稳,其原因与能量类似。实验结束时,PageRank、GeoSocial、Prophet算法的副本数高于ProEnergy。 图5 网络性能实验结果Figure 5 Experimental results of network performance 本文提出了一种基于效用和能量的机会路由算法。首先,对节点关系进行分析,构建网络模型,引入Apriori算法建立关系模型,计算节点的社会转发效用。其次,添加能量因子以均衡节点的能量消耗,优化路由性能。最后,对提出的算法进行仿真。实验结果表明,在保证较高投递率和较低平均延时的同时,有效降低了网络开销,并均衡了节点的能量消耗,为今后多备份路由算法的研究提供了参考。


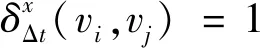
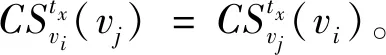
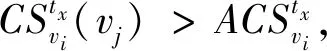
2 关系模型
2.1 预测接触强度



2.2 构建关系样本



2.3 关系模型




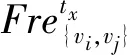

3 ProEnergy路由方案
3.1 能量权重因子


3.2 ProEnergy路由算法
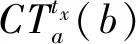


4 仿真实验
4.1 仿真环境与参数设置

4.2 实验结果分析


5 总结
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21计算机应用与软件(2022年7期)2022-08-10体育科技文献通报(2022年3期)2022-05-23计算机与数字工程(2022年3期)2022-04-07哈尔滨理工大学学报(2021年4期)2021-10-07计算机应用(2021年8期)2021-09-09民用飞机设计与研究(2020年4期)2021-01-21作文中学版(2020年1期)2020-11-25物联网技术(2018年8期)2018-12-06
