
基于层次标签数据的模糊决策树构造算法
2022-02-25 02:54折延宏
郑州大学学报(理学版) 2022年2期
王 忠, 折延宏, 郑 逸
(1.西安石油大学 计算机学院 陕西 西安 710065;2.西安石油大学 理学院 陕西 西安 710065)
0 引言
不确定性在现实世界中几乎无处不在,而模糊性是人们对一些概念无法给出清晰明确的界限而产生的不确定性[1]。由于无法对这些概念给出清晰的边界,它们的定量计算就会变得复杂。Zadeh[2]和Atanassov[3]最早提出了模糊集理论,将定性的信息定量化,来表达人们的定性决策信息,为模糊概念和模糊推理奠定了数学基础。由于数据信息模糊的原因,最终决策并不是完全精确的,但也加强了决策的可行性和可信性,为不同领域提供了一种新的思路。
模糊决策树具备传统决策树所有的优点,是数据挖掘中一种高效实用的方法。模糊决策树算法结构清晰,能从具有模糊条件属性和模糊决策属性的模糊决策表中归纳模糊决策树[4],适用于大规模数据学习问题,能够较好地处理数据中存在的不确定信息,并能生成可理解的模糊决策规则,以良好的计算速度运行。然而,在目前现实世界的诸多复杂场景中,数据的标签具有层次结构。如:在图书馆应用中,需要把图书文档信息组织成层次的主题;在网站页面管理中,海量的网页需要组织为层次目录的类别,方便用户快速检索。传统模糊决策树在处理标签具有层次结构的数据时有一定的不足。针对这类问题,本文提出一种可以从标签具有层次结构的数据中获取知识的层次模糊决策树。在此类数据中,底层的标签代表更加具体的概念,分类难度较大,随着层次的提高,标签类别更加抽象,但是分类难度降低[5]。此时,如果单独使用层次结构的某一层标签分类,可能会导致分类准确率降低或损失相当一部分精度。这表明在构造算法过程中不能只考虑分类是否准确,还要在标签具体程度和分类准确率之间进行权衡。为了便于理解,预先定义标签的具体程度为标签的精度。本文提出的层次模糊决策树算法,在计算最优划分属性时,充分考虑了标签本身具有的层次结构,并在确定叶结点类别标签时,通过选择不同层次的分类标签来权衡分类的准确率和标签的精度。通过实验发现,与传统模糊决策树进行对比,本文提出的算法能做到在分类准确率尽可能高的情况下,同时层次标签尽可能具体。
1 定义与问题描述
1.1 模糊决策树
模糊决策树是对传统决策树的推广,同时具备决策树的算法思想和模糊集理论对处理不确定信息的优势。通常模糊决策树在处理属性是连续值的分类时,需要使用分割点对属性进行离散化和模糊化。模糊决策树可以按图1流程构建。

图1 模糊决策树构建流程Figure 1 Construction process of fuzzy decision tree
通常模糊集合可以使用Zadeh表示法:
A={(u,A(u))|u∈U}。
定义2三角隶属函数[7]。三角隶属函数是一种分段函数,用于对数据进行模糊化处理,各个模糊语义值的隶属度函数如下:
定义3对于一个模糊数据集D,dq为模糊类别,定义Ddq为D中类别为dq的模糊子集,1≤q≤Q,Q为模糊类别的数量。则模糊数据集D关于所有模糊类别的模糊熵定义为[8]
(1)


(2)

定义5条件属性Ak相对于D的模糊信息增益定义为
GAk,D=FEntrD-FEntrAk,D。
(3)
1.2 类别层次树
定义6类别层次树(class hierarchical tree,CHT)是一种父标签节点的概念能覆盖其子标签节点概念的树状结构[9]。令CHT={L1,L2,…,Lh},其中:Li为CHT的第i层;h为CHT层数。L1是最抽象的一层,L2,L3,…,Lh所指代的标签逐渐具体,Li={Li,j|i=1,2,…,h且j=1,2,…,mi},Li,j指第i层的第j个类标签,mi表示第i层的类标签总数。
例如岩石分类,父标签〈岩石〉的概念将覆盖其子标签〈岩浆岩〉、〈沉积岩〉、〈变质岩〉,而〈沉积岩〉标签也会覆盖〈石灰岩〉、〈砂岩〉子标签,三层标签从上至下指代信息逐渐具体。岩石类层次树如图2所示。

图2 岩石类别层次树Figure 2 A class hierarchical tree of rock
定义7部分层次树(partial hierarchical tree,PHT)是CHT的最小子树,包含了某一个节点所有数据的标签[9]。
当某一节点数据不包含类别层次树全部标签时,就可使用PHT来代替CHT,用来减少计算复杂度。如某一节点v中只包含〈砂岩〉、〈板岩〉、〈片岩〉时,可以构建图3的部分层次树。
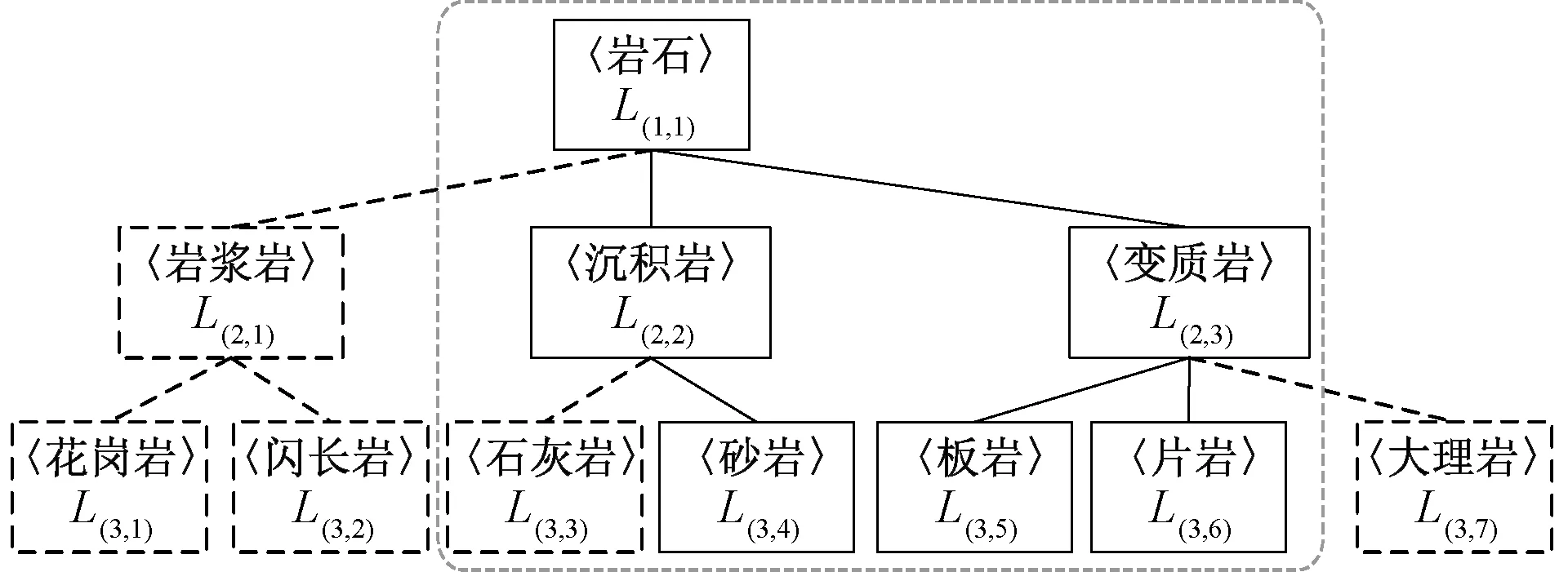
图3 岩石的部分类层次树Figure 3 A partial hierarchical tree of rock
1.3 问题描述
在模糊决策树算法中,模糊熵被用来判断当前节点在构建决策树时是否恰当,但是模糊熵并不能很好地在构建模糊决策树过程中处理标签具有层次结构的数据,下面用一个例子来说明。假设表1和表2分别为两个节点a和b的数据。表1属性A包含a1、a2两个属性值;属性B包含b1、b2两个属性值,表中的数值是隶属度,代表属性取某一属性值的隶属程度。表2同理,d1、d2、d3、d4代表决策属性,如d1代表〈石灰岩〉、d2代表〈砂岩〉、d3代表〈花岗岩〉、d4代表〈板岩〉。
通过计算模糊熵发现,节点a和b的模糊熵都为1,而且无论给当前表中的数据分配哪个标签,节点a和b的分类准确率最高只能达到50%。这表明模糊熵度量方式无法判断两个节点谁更恰当。但如果把表中标签组织为标签树时,部分层次树见图4、5,表1决策属性d1、d2属于第二层标签〈沉积岩〉。表2决策属性d3属于第二层标签〈岩浆岩〉,d4属于第二层标签〈变质岩〉,同时〈岩浆岩〉和〈变质岩〉属于第一层标签〈岩石〉。假设给节点a分配〈沉积岩〉标签,节点b分配〈岩石〉标签,此时两个节点准确率都达到100%,但节点a比节点b分配的标签更加具体。故在准确率相同的情况下,节点a的标签树的分布优于节点b,节点a更加适合节点划分。

图4 节点a的部分类层次树Figure 4 A partial hierarchical tree of node a

表1 节点a样例集Table 1 A sample set of node a
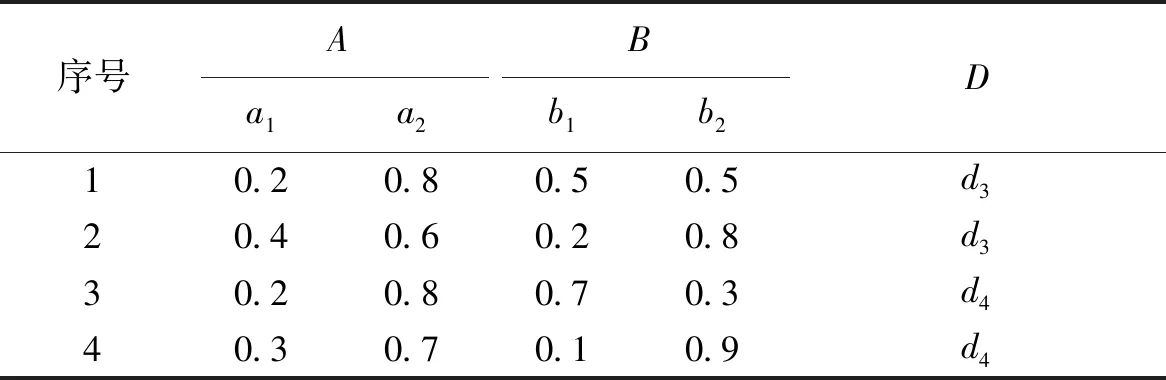
表2 节点b样例集Table 2 A sample set of node b
上述例子说明,当标签分布是层次结构时,传统模糊熵不能很好地衡量节点适当性。
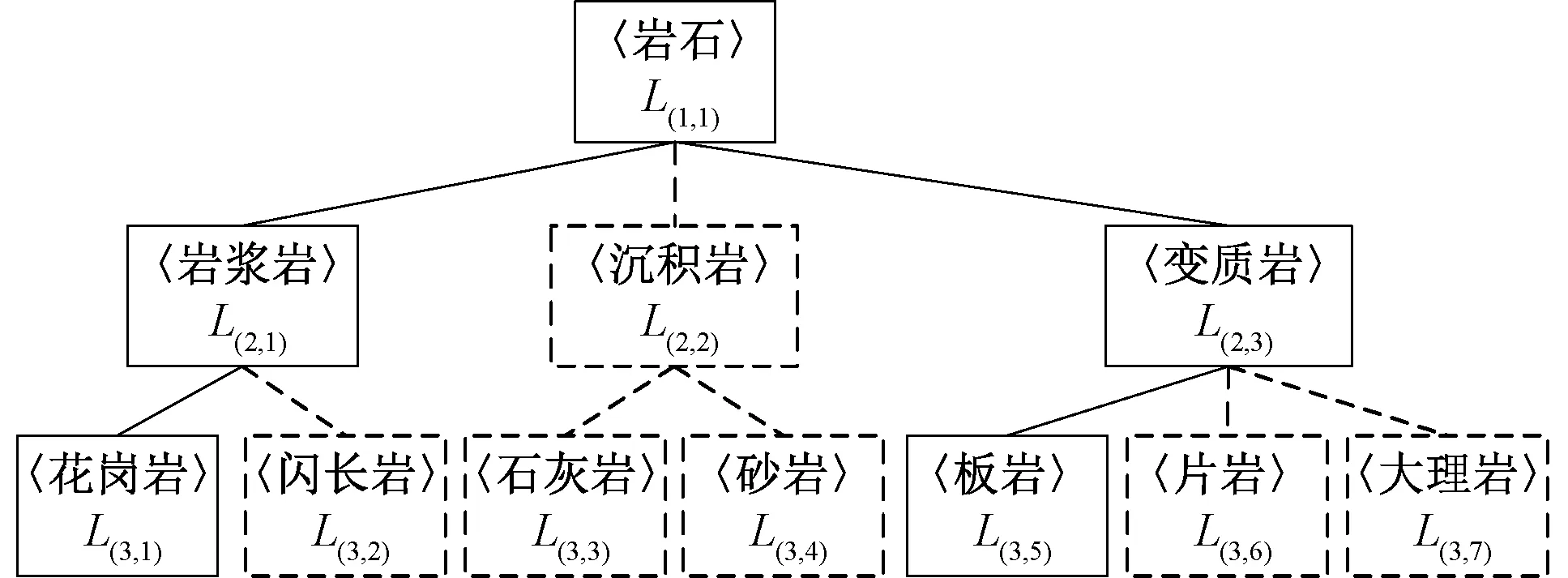
图5 节点b的部分类层次树Figure 5 A partial hierarchical tree of node b
2 层次模糊决策树算法
在模糊决策树算法设计中,属性选择有很多启发式方法,通过不同的启发式能计算出最能区分当前节点的属性。常用的启发式有三种:1)模糊熵。模糊ID3算法使用模糊熵作为启发式。2)最小分类不可指代性。Yuan等[10]提出的启发式使用最小分类不可指代性来选择扩展属性。3)属性对于分类贡献重要度。Wang等[11]基于属性对于分类贡献重要度给出一种新的启发式来选择扩展属性。其中模糊ID3算法的计算复杂性最低,实际应用比较广泛,是学习精度较高的启发式。
标签具有层次结构时可知,属于某一个类别的样本,也自动的归属于它在CHT中的所有超类[12]。根据层次熵的思想[9],在选择最优扩展属性时,不仅要计算数据集关于底层标签的熵,还要计算数据集关于底层标签的所有超类的熵,最后根据权重求和得出数据集关于整个标签树的层次熵。
在构建模糊决策树模型之前,先要对数据表进行离散化和模糊化的预处理。对于数据表中的连续属性,采用Kohonen聚类算法[7]对其进行离散化,生成k个中心点,把属性划分为对应数量的模糊语义值,然后使用三角隶属函数,利用生成的模糊语义值完成对数据的模糊化,得到模糊数据集。
使用模糊ID3算法构建模糊决策树首先要计算模糊数据集关于所有模糊类别的模糊熵,其次计算属性Ak相对于数据集的模糊熵,最后可求得属性Ak的模糊信息增益。因此在计算具有层次标签的模糊数据集D关于所有模糊类别的模糊熵时,依据层次熵的思想,不仅要计算D关于底层模糊类别的模糊熵,还要计算D关于底层模糊类别的所有超类的模糊熵,然后通过CHT不同层次的权重ωi,得到D关于整个类层次树的模糊熵,称为层次模糊熵HFEntrD。按同样的思路可计算出属性Ak相对于D的层次模糊熵HFEntrAk,D,进而求得属性Ak相对于D的模糊信息增益,称为层次模糊信息增益HGAk,D。最终根节点选择max{HGAk,D},1≤k≤n。按上述思想构造的算法称为层次模糊决策树算法,用以解决具有层次标签数据的模糊决策树分类问题。算法遵循决策树归纳的标准框架[13],在层次模糊决策树构建好之后,可以把决策树抽象为多组模糊规则,从树的根节点到任意一个叶结点所形成的路径就构成一组模糊规则,模糊规则可定义为if条件then结论的形式[14]。上述算法所提概念计算步骤如下。
1)模糊数据集D的层次模糊熵HFEntrD定义为
(4)

2)属性Ak相对于D的层次模糊信息熵HFEntrAk,D定义为
(5)
3)由步骤1)~2)计算出属性Ak的层次模糊信息增益HGAk,
HGAk=HFEntrD-HFEntrAk,D。
(6)
假设模糊数据集D,如表3所示,给定类别层次树(CHT)如图6所示。

表3 模糊数据集DTable 3 A fuzzy data set D

图6 模糊数据集D的类别层次树Figure 6 The CHT of fuzzy data set D
第一步:计算模糊数据集D的层次模糊熵。先要计算D关于CHT每一层标签的模糊熵,使用公式(1)计算可得如下结果。
第三层:
第二层:标签〈1〉、〈2〉属于第二层标签〈5〉;〈3〉、〈4〉属于标签〈6〉。
由公式(4)可知模糊数据集D的层次模糊熵HFEntrD为

第三层:
第二层:
按照权重计算:

HFEntrA,D=0.479 3+0.632 9=1.112 2。
按公式(6)可计算属性A的层次模糊信息增益为
使用以上公式便可求得HGB、HGC,选择层次模糊信息增益最大的属性作为根节点。
算法伪代码见算法1。
输入:模糊数据集。
① 初始化决策树T。
② 按照公式(4)~(6)确定根节点。
③ 按节点停止分配标准判断当前节点是否为叶结点。
if当前节点为叶结点
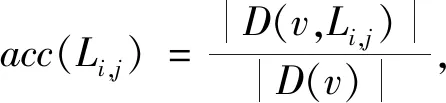
else
选择层次模糊信息增益最大的节点作为扩展属性,并划分模糊数据集,产生子节点。
end if
④ 递归执行步骤③,得到一颗完整的层次模糊决策树。
输出:层次模糊决策树T。
其中|D(v,Li,j)|表示在节点v中标签是Li,j的样本数量。pre(Li,j)可表示为标签的精度,用于衡量标签的抽象程度。越接近底层,标签的精度越高,标签越具体。
节点停止分配标准为:1)没有可用扩展属性。2)当前节点某个分类的相对频率pi,j大于等于给定阈值β0。3)节点样本数量为0或所有样本都属于同一类。
3 实验分析与评价
3.1 实验数据及预处理
论文实验数据来源于UCI公开数据集Glass。此数据集包含214个样本,数据集有Mg、Ba、Ai、Fe、Ri、Na等9个属性,样本标签可以组织成一个4层的类别标签树;第四层标签有〈1〉、〈2〉、〈3〉、〈4〉、〈5〉、〈6〉、〈7〉;第三层标签有〈FP〉(包括子标签〈1〉,〈3〉)、〈NFP〉(包括子标签〈2〉,〈4〉);第二层标签分布〈WG〉(包括子标签〈FP〉,〈NFP〉)、NWG(包括子标签〈5〉,〈6〉,〈7〉);顶层为〈ALL〉。实验选取70%的数据作为训练集来构造层次模糊决策树,剩余30%的数据作为测试集用于验证结果。
对于数据集中的连续值属性,首先需要对数据离散化。实验使用Kohonen算法确定k个中心点,把属性划分为对应数量的模糊语义值。本实验将中心点k设置2,学习率设置为0.5。所求中心点部分计算结果如表4所示。

表4 数据中心点Table 4 Center point of data
由于中心点参数k设置2,每个属性会离散化为两个模糊语义值,为了表述方便,这里把每个属性的模糊语义值统一抽象为more和less。用这两个模糊语义值就能描述连续值属性。然后使用定义2的三角模糊隶属函数对数据集进行模糊化处理。模糊化后的部分数据如表5。

表5 部分模糊数据集Table 5 Part of fuzzy data set
3.2 决策树的构建
得到模糊数据集后,使用第三节提出的层次模糊决策树算法构建出决策树,并分配好类别标签,由于分配标签时,考虑了CHT的不同层次,所以生成的决策树中可以分配到除CHT底层标签外其他层次的标签。
如图7所示,边框加粗的叶子标签即为CHT的上层标签,决策树左分支属性值为more,右分支属性值为less。
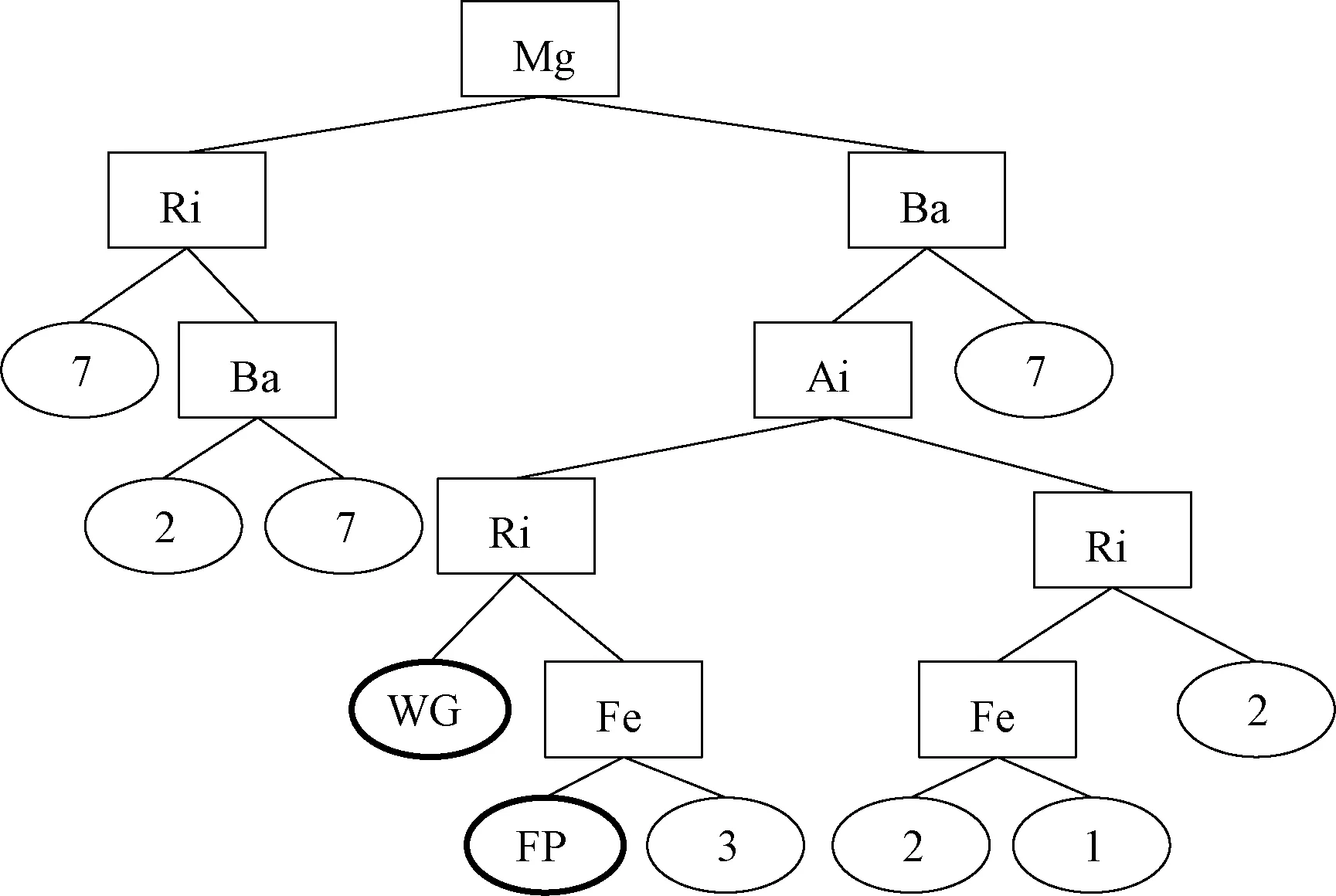
图7 层次模糊决策树Figure 7 Hierarchical fuzzy decision tree
3.3 实验结果与分析
实验使用两个评价标准对模型性能进行评价:分类准确率和标签精度。标签精度数值越大说明样本所分配的层次标签越具体。为了更好地说明实验结果,使用模糊决策树中模糊ID3算法和基于最小分类不可指定性(Min-Ambiguity)算法为参照。由于传统模糊决策树(FDT)不能直接处理层次标签,需要分别把CHT每一层的标签当成模糊决策树的分类标签,然后去计算模糊决策树的标签精度和分类准确率,由于数据集的标签树有4层,使用模糊决策树算法就会有4个分类准确率数值和4个标签精度数值。而层次模糊决策树(HFDT)算法在构建决策树过程中就考虑了标签的层次结构,所以算法的标签精度和分类准确率是一个固定数值[5]。计算结果见表6。

表6 FDT和HFDT的分类准确率和标签精度Table 6 Accuracy and label precision of FDT and HFDT
从表6和图8可以看出,当所有数据都归于CHT第一层的单个标签时,传统模糊决策树的两个分类算法准确率最高,但是,标签精度最低,这样的分类并没有意义。当所有数据分别归于CHT的二、三、四层的标签时,标签精度逐渐提高,相应地,模糊ID3算法和Min-Ambiguity算法分类准确率也随之降低。其中模糊ID3算法在CHT除第一层外所有层次的分类准确率均优于Min-Ambiguity算法。这充分说明传统的模糊决策树分类器不擅长处理标签具有层次结构的数据,导致平衡标签精度和分类准确率的能力不佳,也说明选取CHT其中一个层次的标签去分类数据并不合适,而层次模糊决策树模型在选择最优扩展属性时就考虑到了标签的层次结构,从图8折线图可以清晰看出,本文所提算法的标签精度和分类准确率与其他两个算法相比较,都保持在一个较高的数值,能做到在分类准确率尽可能高的情况下,同时层次标签尽可能具体。因此可以说明,本文提出的算法优于传统的模糊决策树算法。

图8 FDT和HFDT折线对比图Figure 8 Line chart between FDT and HFDT
4 结束语
模糊决策树是对传统清晰决策树在模糊理论上的扩展,具有决策树本身的优点,而且融合了模糊理论的优势。然而在处理标签具有层次结构的数据时,模糊决策树存在一定不足,本文提出的算法在构造过程中充分考虑到了标签的层次结构,使得分类准确率和标签精度都达到一个较高的水准,能有效处理这类问题,为决策者提供更加可信的信息。
猜你喜欢
少儿画王(3-6岁)(2020年4期)2020-09-13
科学与信息化(2019年28期)2019-10-21
东方教育(2018年20期)2018-08-22
科学与财富(2016年32期)2017-03-04
科技创新与应用(2017年3期)2017-02-18
电脑知识与技术(2016年25期)2016-11-16
无线互联科技(2015年11期)2016-03-04
企业导报(2015年9期)2015-05-18
决策与信息·下旬刊(2013年1期)2013-03-11
微型计算机(2009年4期)2009-12-23
