
联合语义分割与注意力机制的行人再识别模型
2022-02-24 05:06周东明张灿龙唐艳平李志欣
计算机工程 2022年2期
周东明,张灿龙,唐艳平,李志欣
(1.广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004;2.桂林电子科技大学计算机与信息安全学院,广西桂林 541006)
0 概述
行人再识别是指判断不同摄像头下出现的行人是否属于同一行人,属于图像检索的子问题,广泛应用于智能视频监控、安保、刑侦等领域[1-2]。由于行人图像的分辨率变化大、拍摄角度不统一、光照条件差、环境变化大、行人姿态不断变化等原因,使得行人再识别成为目前计算机视觉领域的研究热点和难点问题。
传统的行人再识别方法侧重于颜色、形状等低级特征。随着深度学习技术的快速发展,以端到端的方式学习图像特征,然后进行三元组损失、对比损失、改进的三元组损失等[3-4]的度量与计算。该方式能够很好地学习图像的全局特征,但是并没有考虑图像的局部特征和空间结构。行人在不同的摄像头下由于低分辨率、光照条件、部分遮挡、姿态变化等诸多因素使得视觉外观发生显著变化,主要表现为行人部分特征被遮挡导致不相关上下文被学习到特征图中,姿态变化或者非刚性变换使得度量学习[5]变得困难,高相似度的外貌特征在基于全局特征学习的模型中不能得到有效识别,区域推荐网络所产生的不精确的检测框会影响特征学习等方面。为解决上述问题,研究人员开始关注图像的局部特征,通过图像的局部差异性分辨不同的行人。对于行人的局部特征进行提取,主要是通过手工的方式将图像分成若干块。文献[6]提出对图像进行分块,将行人图像平均分成6 份大小相同的区域,对每个区域施加标签约束,然后分别提取图像的局部特征进行学习。文献[7]在全局特征的辨识模型中引入局部特征损失来影响全局特征表达,在局部网络中使用无监督训练自动检测局部人体部件,增加了模型对于未见过的行人图像的判别能力。但是,已有研究主要将注意力集中在人体的局部特征学习上,忽略了非人体部件的上下文线索对整体辨识的重要影响,因此模型在不同数据集中的鲁棒性较差。本文使用行人语义分割代替手工设计的分块框,快速提取图像的局部特征。首先训练一个行人语义分割模型,该模型通过学习将行人分成多个语义区域,将非人体部分作为背景。然后通过局部语义区域进行分块,分块后再进行辨识比对。在此基础上提出一种局部注意力机制,计算非人体部分潜在部件的相似度,依据输入图像和查询图像像素之间的差异来辨识是否属于同一行人,以解决非人体部分潜在的原始信息辨识问题。
1 行人再识别模型
本文提出一种基于局部对齐网络(Partial Alignment Network,PAN)的行人再识别模型,通过行人解析模型对齐人体部分特征以及使用局部注意力机制对齐非人体部分的上下文线索[8]。局部对齐网络结构如图1 所示,通过将分块后的行人语义特征与注意力特征相融合得到最终的辨识特征,其中:Lpar表示人体语义解析网络分支;Latt表示局部注意力网络分支,先学习捕获基于不同像素之间的部分差异,再计算潜在的局部对齐表示。
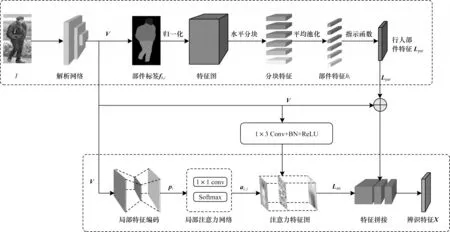
图1 局部对齐网络结构Fig.1 Structure of partial alignment network
1.1 行人语义分割模型
输入一张行人图片I,经过残差网络的特征提取得到特征图V,将行人与分割后的标签映射进行缩放[9],使其特征映射和V维度相同。第i个像素的表征为ri,本质上是V的it,h行。像素i经过缩放后行人部分类别的标签可表示为δi,δi有N个人体部件的值和1 个背景类别。将得到的人体特征标记的置信度图记为fk,每一个人体部件类别和背景均与局部特征置信度图相关[10]。当预测i个行人部件标签时:
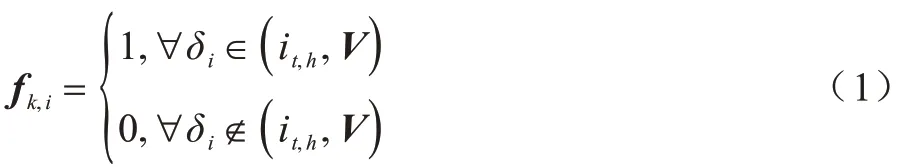
在得到第i个像素的标签图fk,i后,本文使用L1正则化对每个行人标签的置信度图进行归一化处理[11],L1 正则化可表示如下:

其中:λ∈[0,+∞]是用来平衡系数的稀疏性和经验损失的超参数,λ越大系数的稀疏性越好,但经验损失就越大;ri是输入的第i个像素特征;y是图像的标签;w是在训练中学习的超参数;Lemp()是目标函数。对式(2)中的w求导,使得偏置值∇w J(w;ri,y)目标函数取得最小值以产生稀疏模型,防止过拟合现象[12]。此时,行人部分的特征hi可以表示如下:

其中:hi表示的是第i个像素的行人部件特征,通过指示函数[δi≡N]即可得到人体部分的特征图Lpar。Lpar可以表示如下:

其中:Lpar本质上是图片中行人预定义标签的语义表示。在本文模型中,行人语义主干网络每次激活输出一个带标签的置信度图,而不是使用全局平均池化[13]输出置信度图。与全局平均池化[14]相比,置信度图的激活发生在空间区域。
1.2 局部注意力网络
将ResNet50 提取到的特征图V输入局部注意力网络中[15],局部注意力网络学习预测K个非行人标签置信度图Q1,Q2,…,QK。局部注意力网络中的置信度图学习与行人解析网络中第i个像素有关的潜在知识,第i个像素的注意力编码向量可表示如下:
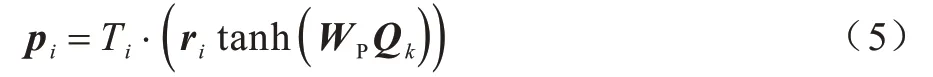
其中:Ti是第i个像素的特征编码长度;WP是在训练中学习的超参数;tanh()是双曲正切函数,在得到注意力编码向量的特征表示后,计算注意力网络中i个像素特征 图的权重ai,j。ai,j可以表示如下:
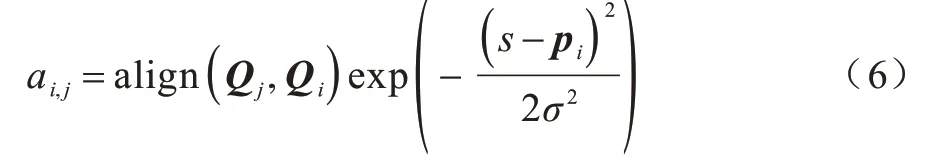
其中:ai,j是Qi的第jt,h行的置信度图权重;s表示输入序列的位置;σ表示局部注意力关注区域和标签之间的方差。本文在计算特征图权重时,添加高斯分布使得对齐权重在第i个像素对靠近pi的标注时予以更多的影响力。遵循局部注意力机制,首先正则化align(Qj,Qi),然后计算输入和查询图像之间关于像素i相似性的总和。局部注意力网络中的两个变换函数是为了更好地学习相似性,其实现使用的是1×1的卷积核,能更好地对小目标予以检测和关注。
潜在的局部注意力特征图可表示如下:

其中:ψ(·)是用来学习更好表征的函数。在实现细节上,使用的是1×3 的卷积核和批量归一化以及Sigmoid 激活函数[16]。
将潜在的局部注意力网络对齐表示和人体语义解析网络对齐表示进行融合,得到最终的辨识特征X:

2 实验与结果分析
2.1 数据集和评价指标
使用3 个公开的大规模行人再识别领域的Market-1501[17]、DukeMTMC-reID[18]和CUHK03[19]数据集评估本文模型的性能。Market-1501 数据集有1 501 个行人,共32 688 张图片。DukeMTMCreID 数据集有1 404 个行人,共36 411 张图片。CUHK03 数据集有1 467 个行人,共14 096 张图片。这些图片由5 个高分辨率的摄像头和1 个低分辨率的摄像头拍摄,且每个行人至少出现在2 个不同的摄像头中。CUHK03 数据集的数据格式和另外两种数据集格式稍有不同,提供了两种类型的数据,包括手工注释的标签(Labeled)和DPM 检测的边界框(Detected)[20],其中第二种类型的数据检测更困难,因为DMP 检测的边界框存在比例失调、杂乱背景等现象的发生。利用累计匹配特征(Cumulated Matching Characteristic,CMC)和平均精度均值(mean Average Presicion,mAP)两种评价指标来评估PAN 模型。所有实验均使用单查询设置。
2.2 参数设置
模型基于PyTorch 框架,在开始训练前将数据集中图片大小调整至384 像素×128 像素,通过随机遮挡进行数据增强。实验中使用的3 个数据集预先使用CE2P 模型进行人体语义解析[21],每张图片定义20 个语义类别,其中,19 个行人类别,1 个背景类别。实验共训练100 个批次,每个批次的大小设置为128。初始学习率设置为0.02,在经过60 个批次后学习率降为0.002。
2.3 定量比较与分析
将PAN 模型与基于注意力的行人再识别模型(RGA[22]、HOA[23])、基于行人语义解析的行人再识别模型(SSM[24])和基于局部对齐方法的行人再识别模型(SCSN[25]、GSRW[26]和DSA[27])进行性能评价测试与对比,对应的实验结果如表1 所示,其中,在Market-1501 和DukeMTMC 数据集中分别测试了Rank-1、Rank-5、Rank-10 和mAP 评价指标,在CUHK03 数据集中测试了Rank-1 和mAP 评价指标。实验结果表明:PAN 模型在3 个数据集中均取得较好的结果,通过观察可以发现,本文构建的人体语义解析网络有效地解决了分块后特征不对齐导致的匹配失败问题;将PAN 模型与HOA 模型在没有使用多分类Softmax 损失函数[28]的条件下进行比较,可以发现PAN 模型的Rank-1 和mAP 评价指标上有明显提升,分别提高了5.4 和6.8 个百分点。
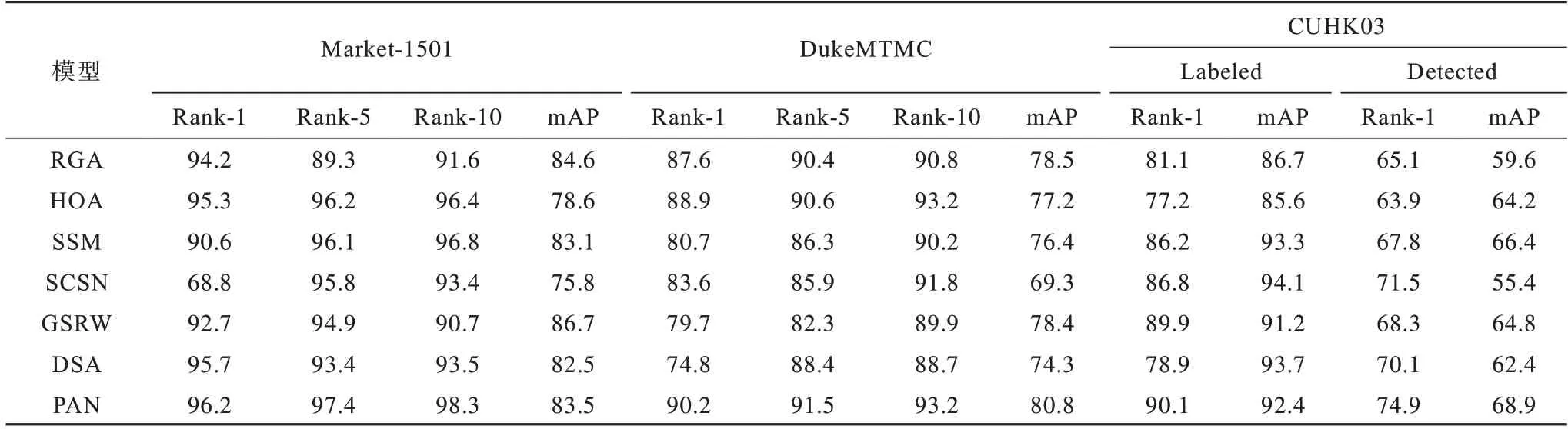
表1 在单查询设置下PAN 模型和其他模型在Market-1501、DukeMTMC 和CUHK03 数据集上的实验结果对比Table 1 Comparison of experimental results of PAN model and other models on Market-1501,DukeMTMC and CUHK03 datasets under the single query setting %
2.4 定性评估
本文探究了不同的行人部件分割数量N对PAN 模型的影响,实验结果如图2 所示。由图2 可以看出,当N=5 时,行人部件被分为头部、上部分、下部分、脚部、背景等5 个部分,整个模型的再识别成功率最高,这表明精细的行人部件分割有效地克服了行人姿态变化的差异性问题,通过上下文信息对行人再识别产生了重要影响。考虑到计算时间开销和硬件支持[29],本文默认将N设置为5,即每张图片的行人部分分割为5 个小区域。
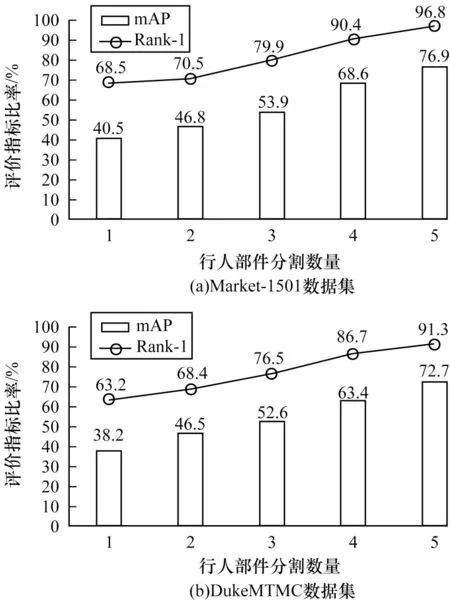
图2 PAN 模型选取不同行人部件分割数量时的实验结果对比Fig.2 Comparison of experimental results when the PAN model selects different number of pedestrian components
在使用三元组损失的基础上[30],通过消融实验来深入研究PAN 模型中各分支的贡献,其中:Baseline 表示基线模型,在此基础上进行改进;PAN/Lpar表示仅使用人体语义解析网络分支的模型;PAN/Latt表示仅使用局部注意力网络分支的模型;PAN/Lpar+Latt代表同时使用局部注意力网络和人体语义解析网络分支的模型。实验结果如表2 所示:联合人体语义解析和局部注意力网络可以提升3 个主流数据集的整体性能;PAN/Lpar和Baseline 模型相比可以发现,Baseline 模型只是将图像进行分块提取特征,当出现姿态变化过大和高相似度外貌特征时并不能取得良好的实验结果;PAN/Latt和Baseline 模型相比可以发现,局部注意力网络在出现遮挡情况时,显示出了非行人部件上下文线索的重要性。
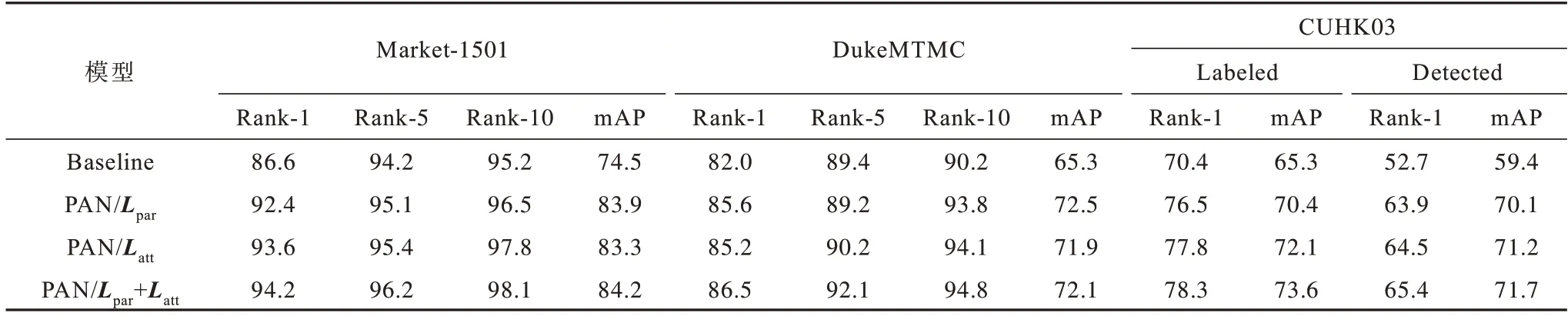
表2 行人再识别模型消融实验结果Table 2 Results of ablation experiment for pedestrian re-identification models%
3 结束语
本文提出一种基于行人语义分割和局部注意力机制的行人再识别模型。使用行人语义分割模型对行人的局部特征进行更精细的分割,避免了对图像进行分块后局部特征不匹配现象的产生。利用局部注意力机制,解决了行人语义分割模型将非人体部件识别为图像背景的问题。通过行人部件信息和背景遮挡信息的互补,增强了模型的可迁移性。实验结果表明,该模型能充分利用行人部件信息和局部视觉线索中隐藏的语义信息,有效解决了行人姿态变化过大、特征分块后不对齐等问题。后续将研究PAN 模型在基于视频序列的行人再识别中的应用,通过将视频中的每一帧图像进行分割得到行人部件特征,根据行人部件特征之间的比对增加识别粒度,并设计图卷积网络挖掘视频序列中行人潜在的语义信息,进一步提高识别精度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
河北大学学报(哲学社会科学版)(2022年1期)2022-02-17
意林(2021年5期)2021-04-18
汽车维修与保养(2020年11期)2020-06-09
开放教育研究(2020年2期)2020-03-31
小学语文教学·会刊(2019年2期)2019-09-10
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
长江学术(2016年4期)2016-03-11
