
基于层次聚类的生物网络全局比对算法
2022-02-24 05:06:20田盼盼
计算机工程 2022年2期
田盼盼,陈 璟,2
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122)
0 概述
近年来,随着高通量技术的发展,通过实验方法检测到蛋白质相互作用(Protein-Protein Interaction,PPI)的数量大幅增加,形成了越来越多的PPI 网络。发现并理解蛋白质之间的相互作用,是生物学领域内的重要课题之一[1]。对PPI 网络的分析能够增进对生物学过程的理解,不同物种间相互作用组的比对在蛋白质功能预测、保守功能成分检测、物种间知识转移等方面具有重要意义[2]。
网络比对按映射关系可分成局部比对和全局比对。局部比对旨在找到高度保守的小型网络区域,并生成多对多节点映射,例 如LePrimAlign[3]、LocalAli[4]、Pin-Align[5]。全局比对旨在找到较大的保守区域并生成一对一的节点映射,例如Isorank[6]、GRAAL[7]、H-GRAAL[8]、MI-GRAAL[9]、C-GRAAL[10]、L-GRAAL[11]、NETAL[12]、SPINAL[13]、PINALOG[14]、ModuleAlign[15]、PROPER[16]、AligNet[17]、IsoRankN[18]、BEAMS[19]、SMETANA[20]等,其中后3种算法属于多网络比对,其余为2个网络的比对。本文着重研究2个网络的全局比对。
在现有2 个网络的全局比对算法中,IsoRank 算法是先进的全局比对算法,其主要利用类似谷歌页面排序算法(PageRank)的方法计算节点相似性,并采用贪心算法进行比对。GRAAL 系列算法利用图形度标签相似性作为节点的拓扑相似度,结合其他搜索算法比对PPI 网络。NETAL 算法基于拓扑和生物相似性构建相似性矩阵,利用贪心搜索方法比对网络。SPINAL 算法首先基于二分图构建初始相似性矩阵,利用种子-扩展算法并基于迭代交换局部改进比对节点。PINALOG 算法首先利用聚类算法提取密集模块,计算模块间的相似度并通过模块匹配提取比对的种子集合,并将比对扩展至种子节点的邻域。ModuleAlign 算法基于输入网络的层次聚类计算蛋白质间的同源性得分,整合了序列信息以及局部和全局网络拓扑作为评分方案,通过迭代算法寻找一种在实现较好整体得分的同时最大化保守相互作用数量的比对方法。PROPER 算法首先根据序列信息设置阈值筛选种子集合,然后利用渗透图匹配(Percolation Graph Matching,PGM)算法[21]扩展种子。AligNet 算法是成对网络比对算法,其先将网络划分成多个重叠簇,再进行簇间的局部比对,最后将其组合扩展为全局比对。
上述算法大多从拓扑和生物2 个角度考虑蛋白质的相似性,由于PPI 网络存在噪声,仅考虑拓扑特征可能对比对产生误导,而序列信息的不完全性使得仅考虑生物信息会影响比对的准确性,序列上相似不一定代表功能相似。此外,生物网络被观察到是高度模块化的[22],同一个功能模块中蛋白质相互连接密集,不同模块间蛋白质相互连接稀疏[23],部分算法利用层次聚类[24]、密度聚类[25]等模块检测技术从PPI 网络中提取出具有相似功能的蛋白质,将功能模块检测融入网络比对中,更准确地预测蛋白质功能,但通常需要借助同源信息。因此,利用较少的额外信息实现良好的拓扑与生物一致性的平衡,是需要进一步研究的问题。
本文基于种子-扩展算法和功能模块检测,提出一种生物网络全局比对算法JAlign。结合节点及其邻居节点的拓扑特征和序列信息构建目标函数,利用Jerarca 层次聚类算法[26]划分功能模块,并通过匈牙利算法从中提取种子,综合种子与邻居节点的连接关系、节点相似性和度,将比对从种子节点扩展至其邻居节点,同时对剩余节点再次进行加权二分图匹配,找到更多匹配节点,从而实现拓扑和生物一致性的平衡。
1 基于层次聚类的生物网络全局比对
1.1 问题描述
2 个PPI 网络分别用无向图G1=(V1,E1)和G2=(V2,E2)表 示,其中:V1、V2表示网络中的节点集 合;E1、E2表示网络中的边集合;节点表示蛋白质;边表示2 个蛋白质间的相互作用;N(i)表示节点i的邻居节点集合;N(j)表示节点j的邻居节点集合。全局比对f:V1→V2,是 将G1中的V1节点映射 到G2的V2节点上,形成一对一的映射关系,令f(V1)={f()v∈V2|v∈V1},f(E1)={(f(u),f(v))∈E2|(u,∈E1}。全局网络比对的目的是找到比对节点对相似性得分之和最大的映射关系。
1.2 JAlign 算法
本文提出JAlign 算法,利用功能模块检测和种子-扩展算法实现全局比对。该算法主要分为3 个阶段,分别是种子筛选阶段、扩展阶段和局部优化阶段。在种子筛选阶段,先基于拓扑和序列信息构建目标函数,再利用层次聚类算法划分功能模块并进行模块间的比对,从模块对中提取高相似度节点对作为种子节点。在扩展阶段,先根据种子节点计算其邻居节点的相似性,再迭代比对高得分的节点对,逐步将比对扩展至所有可比对的节点。在局部优化阶段,先对剩余节点构建二分图,再利用最大加权匹配比对剩余节点,将比对节点对合并到比对集合。
1.2.1 种子筛选阶段
种子筛选阶段包括目标函数构建、功能模块检测及种子筛选2 个部分。
1)目标函数构建
目标函数用于衡量节点间的相似性,是后续比对的重要依据,结合序列信息与拓扑特征可避免仅考虑生物信息或拓扑信息对比对结果产生的误导。节点i和节点j的序列相似性根据BLAST bit-score值[27]计算,如式(1)所示:
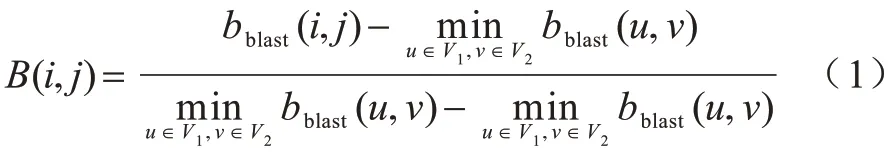
其中:bblast(i,j)表示节点i、j之间的BLAST bit-score 值。
若2 个节点的邻居节点拓扑相似,则这2 个节点拓扑相似的可能性更高,通过同时考虑邻居节点的拓扑相似性和节点本身的相似度计算节点对的拓扑相似性,能够更全面地衡量节点间的拓扑特征。计算节点i、j拓扑相似性得分T(i,j)的过程如下:首先初始化T0(i,j)=1;然后构建二分图GB=(VB,EB),其中VB由N(i)节点和N(j)节点的2 个不相交集合组成,EB中的边(i′,j′)由N(i)、N(j)中节点所有可能的连接组成,i′∈N(i),j′∈N(j),边的权重w(i′,j′)=最后利用贪心算法,每次选中权重最大的边添加到匹配集合,遍历完所有边后得到GB的匹配集合M,计算该匹配M对应的值。计算公式如式(2)所示:
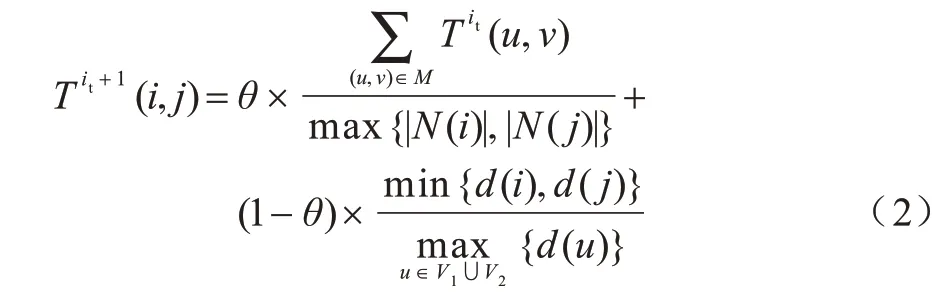
其中:|N(i)|、|N(j)|表 示节点i、j的邻居节点 数;d(i)、d(j)表示节点i、j的度表 示G1、G2中节点度的最大值;it是迭代次数;θ是平衡邻居节点和节点本身拓扑相似性比重的参数,0≤θ≤1。经过多次迭代后,矩阵T的最终值为节点的拓扑相似性。
在计算序列和拓扑相似性之后,可得到节点的相似性得分,如式(3)所示:
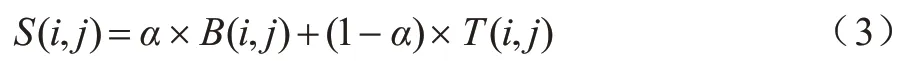
其中:α是平衡拓扑和序列权重的参数,0≤α≤1;B(i,j)和T(i,j)分别是序列得分和拓扑得分。
2)功能模块检测及种子筛选
生物网络的模块化特征使得具有相似生物功能的蛋白质连通密集,功能模块检测将功能相似的节点划分为同一模块。从功能模块中筛选种子,将功能信息融入到比对中,相较于在整个网络内筛选种子节点,缩小了种子节点的选择范围,通过对高质量的种子进行扩展,提高了比对结果质量。种子筛选阶段的算法流程如图1 所示。首先利用Jerarca 聚类算法划分输入网络中的功能模块,构成模块集合,结合匈牙利算法先进行模块内比对,计算模块间相似性;然后模块间比对,得到模块间的最佳匹配结果;最后从中筛选出高相似性的节点对作为种子节点,其中Jerarca 聚类算法通过节点间距离划分模块,使得在聚类时不会遗漏一些常规的不完全连通的功能模块,也不需要GO 文件辅助划分模块,从而减少了输入信息。
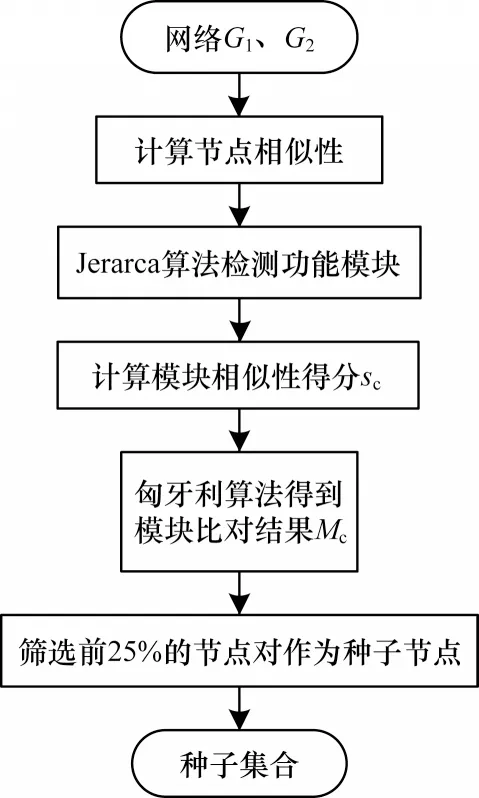
图1 种子筛选流程Fig.1 Procedure of seed selection
种子筛选阶段伪代码算法1 所示。
算法1SeedSelect 算法

种子筛选阶段的具体过程如下:
1)根据式(3)计算节点间的相似性得分S(u,v)。
2)利用Jerarca 聚类算法检测G1、G2中的功能模块,并将模块信息分别存入集合C1、C2中。
3)计算模块间的相似性得分(算法1 第4 行和第5 行)。利用匈牙利算法进行模块内比对,得到模块内节点间的最佳映射关系MH,计算比对模块的相似性得分sc,如式(4)所示:
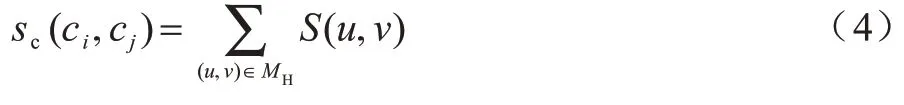
其中:ci、cj分别表示C1、C2中第i、j个模块;MH是通过匈牙利算法得到的ci、cj内节点的比对集合。
4)根据模块间的相似性得分sc,采用匈牙利算法得到模块间的匹配结果MC,依据相似性得分值分布的第3、4 分位数,筛选出前25%的节点对作为种子继续扩展(算法1 第6 行和第7 行)。
1.2.2 扩展阶段
种子筛选阶段能够将部分重要节点比对上,但仍存在多数节点未涉及。为了将比对从种子节点扩展至整个网络,本文提出一种新的扩展方法,基本思路是某一对节点的邻居节点相似性越高,则这对节点比对上的概率越高,即比对上的邻居节点数越多,该节点对越可能被比对上。以种子节点为中心,遍历其邻居节点,将比对逐步从种子节点扩展至周围节点,但仅依靠节点间的连接关系确定比对节点也不全面,会存在多对节点满足扩展条件,而每步节点对的选择都会对后续节点的比对产生影响,从多角度考虑可以得出较为全面的结果。本阶段通过综合考虑节点间的连接关系、度特征、节点相似性,更全面、谨慎地确定扩展节点,产生更优的比对结果。
扩展阶段伪代码如算法2 所示。
算法2Extension 算法

扩展阶段的具体过程如下:
1)将种子节点对添加到比对集合M(算法2第1 行)。
2)计算种子的邻居节点间的结构相似性(算法2第2 行和第3 行)。遍历种子节点的所有邻居节点,计算每一对邻居节点在已比对节点集合中的公共邻居节点数作为邻居节点的结构相似性得分sstru,如式(5)所示:

3)综合邻居节点结构相似性sstru、度、节点相似性S选择扩展节点对(算法2 第5~15 行)。首先对所有结构相似性从高到低排序,将得分最高的节点对添加到集合N,若N中存在多个得分最高的节点对,计算节点间的度差值,保留集合N中度差值最小的节点对,若N中存在多个最小度差值节点对,则根据式(3)中相似性得分S选择节点对,将相似性得分最高的节点对添加到比对集合中。
4)每有一对新的节点比对成功,更新其邻居节点的相似性得分(算法2 第2 行),重复上述过程,直至没有可选择的节点对。
1.2.3 局部优化阶段
扩展阶段只是将比对从种子节点扩展到节点的邻域,这对于种子节点的选择非常重要,而模块检测是从网络中提取出连通密集模块并从中筛选出种子,因此,选择的种子节点多数是在连通密集的子图中的,对于较为离散或连通度不高的子图,比对上的概率很低,而这一部分子图中可能有部分节点是重要节点。为了解决这一问题,局部优化阶段对剩余节点进行局部优化比对,通过二分图的加权匹配比对剩余节点,使得孤立节点也能参与比对,将比对覆盖至整个网络。具体过程如下:
1)查找出G1、G2网络中未比对上的节点,构建二分图Gb,所有边的权重为该节点对的相似性得分S。
2)选择权重最大的边合并到比对集合M中。
3)删除步骤2 中选中的节点对及其相关的边。
4)重复步骤2、3,直至图中没有边存在。
如图2 所示,先选中权重最大的边(a,d),若a、d节点均未在比对集中出现过,则将节点对(a,d)添加到比对集合中,删除a、d节点及其相关的边,再从剩余边中选择权重最大的边,选择的边是(b,e),确定b、e节点未出现在现有比对集合中,将(b,e)添加到比对集合,删除b、e节点及其相关的边,此时,Gb中无可匹配节点对存在,比对结束,将节点对(a,d)、(b,e)合并至比对集合,得到最终比对结果。
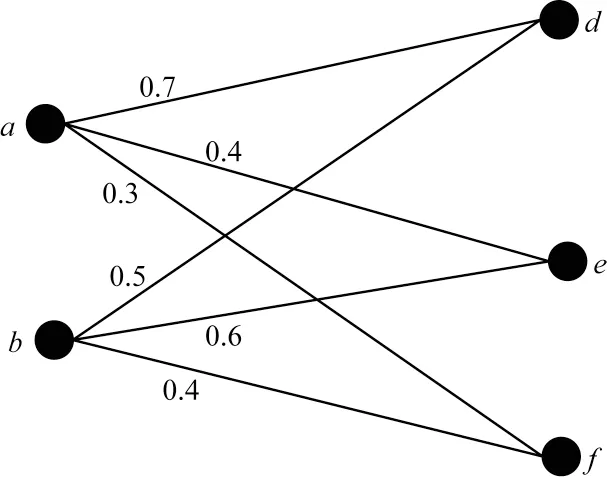
图2 剩余节点匹配示例Fig.2 Example of the matching for remaining nodes
1.3 时间复杂度分析
令n=max{|V1|,|V2|},m=max{|E1|,|E2|}。第一阶段是种子筛选,计算节点相似性的时间复杂度为O(n2),聚类算法划分模块的时间复杂度为O(n2logan),匈牙利算法的时间复杂度是O(n2),因此,第一阶段的时间复杂度为O(n2logan);第二阶段是扩展比对,种子节点对最多有n对,每个种子节点的邻居节点最多有m个,因此,复杂度为O(nm2);第三阶段是剩余节点比对,剩余节点最多有n个,因此,第三阶段的时间复杂度为是O(n2)。至此,本文算法总的时间复杂度为O(n2logan+nm2)。在生物网络普遍性假设中,m≈nlogan,所以,本文算法的时间复杂度为O(nm2)=O(n3logan)。
2 实验与结果分析
2.1 实验数据
实验所用数据来自Isobase[28]数据库的真实网络数据和NAPAbench[29]合成网络数据,真实网络数据包括Caenorhabditis Elegans(CE)、Saccharomyces Cerevisiae(SC)、Drosophila Melanogaster(DM)、Homo Sapiens(HS)等4 个物种,合成网络包括Crystal Growth(CG)、Duplication Mutation Completion(DMC)、Duplication with Random Mutation(DMR)。生物网络的节点和边信息见表1,其中真实网络的数据均经过预处理,排除了自循环、重复的边和节点。
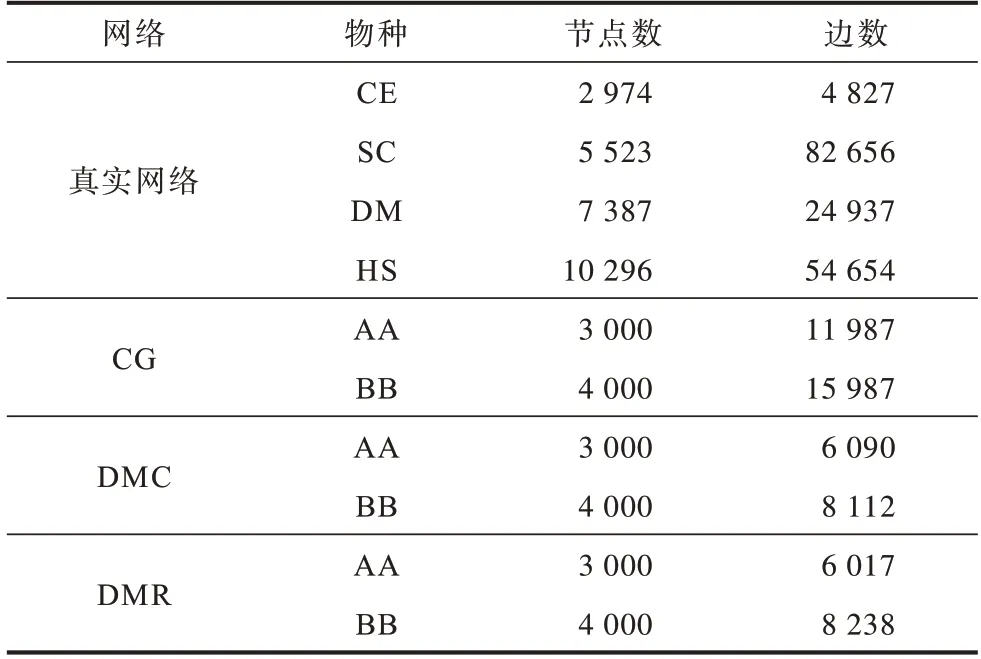
表1 网络数据信息Table 1 Network data information
2.2 评价指标
对于网络比对算法的性能,从拓扑质量和生物质量2 个方面进行评估。
1)拓扑质量度量
边正确性(Edge Correctness,EC)[7]是衡量网络比对拓扑质量最常用的指标,通过计算f映射下保守边在源网络中的比例来评估比对的质量,不能惩罚将稀疏网络映射到密集网络的比对。EC 计算公式如式(6)所示:

其中:|E1|表示G1网络的边数;|f(E1)|表示以f映射方式覆盖到G2中的边的边数。
诱导保守子结构得分(Induced Con-served-structure Score,ICS)[30]计算保守边与诱导边的比例,克服了EC 的问题,但不能惩罚将密集网络映射到稀疏网络的比对。ICS 计算公式如式(7)所示:

对称子结构得分(Symmetric Sub-structure Score,S3)[31]针对源网络和目标网络,既能惩罚稀疏到密集的比对又能惩罚密集到稀疏的比对。S3的计算公式如式(8)所示:
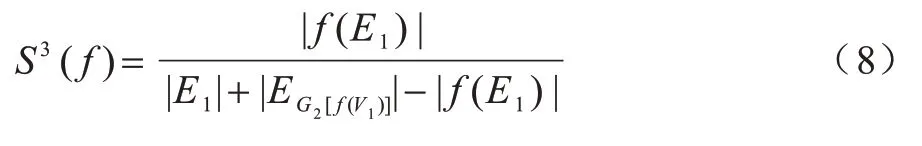
其中:分母表示根据比对f将G1和G2诱导子图重叠得到复合图计算图中唯一边的数目;|E1|表示G1网络中的边数。
2)生物质量度量
生物质量使用功能一致性(Functional Coherence,FC)[32]来衡量,FC 利用GO 术语测量比对蛋白质的功能一致性。GO 术语描述蛋白质的生物特性,包括分子功能(Molecular Function,MF)、细胞成分(Cellular Component,CC)、生物过程(Biological Process,BP)[33]。通常认为具有相似GO术语的蛋白质其生物功能相似。FC 计算公式如式(9)和式(10)所示:
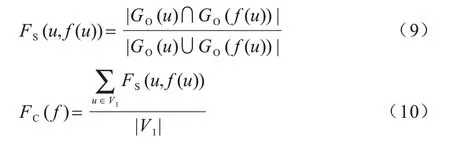
其中:GO(u)和GO(f(u))表示节点u和f(u)被注释的GO 集合。
2.3 结果分析
本文将JAlign 算法与L-GRAAL、SPINAL、ModuleAlign 算法进行比较,在参数设置上,拓扑相似性计算中θ设置为0.5,迭代2 次,总相似性中α设置 为0.4。Jerarca 聚类中选 择RCluster[26]迭代算法,迭代3 次,层次树构建使用UPGMA[26]算法。其他算法的参数设置参照原文设置,具体参数设置如表2所示。

表2 3 种对比算法的参数设置Table 2 Parameters setting of three alignment algorithms
2.3.1 合成网络比对结果分析
4 种算法在合成网络上的比对结果如表3 所示,其中,加粗的数据为最佳结果,加下划线的数据为次优结果,下同。在拓扑指标上,JAlign 算法的结果明显优于其他3 种算法;在生物指标FC 上,JAlign 算法仅次于SPINAL 算法,L-GRAAL 算法表现最差。总体而言,JAlign 算法在合成网络上表现最好,在保证了较好的生物特性的基础上实现了最好的拓扑质量。
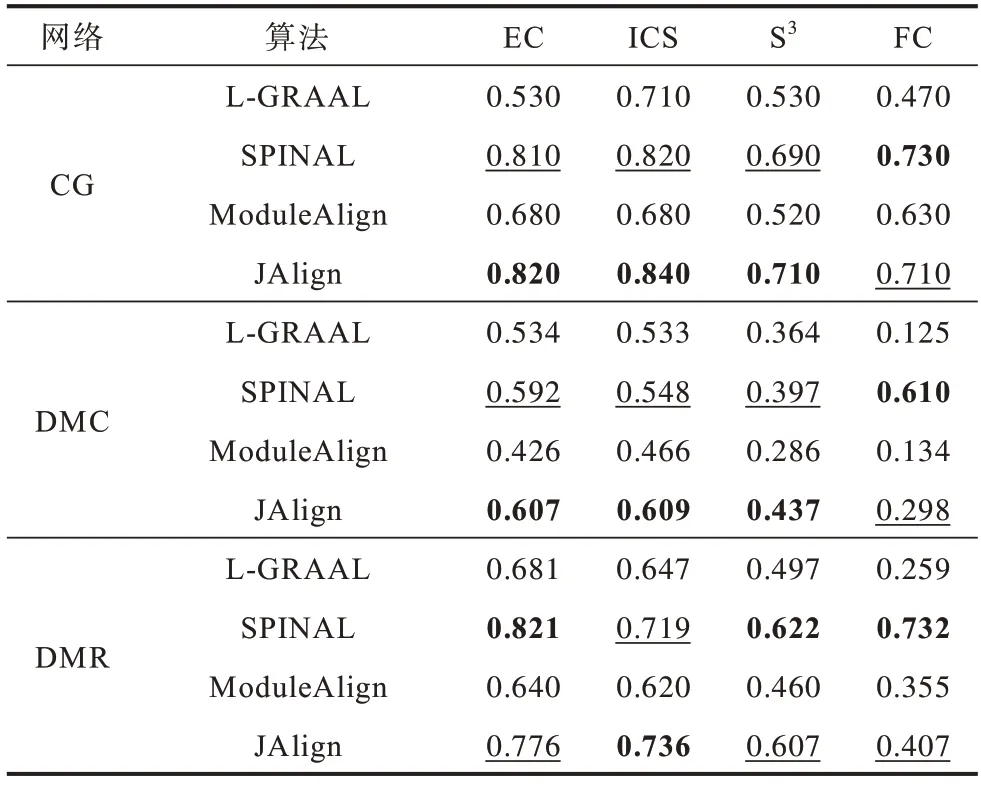
表3 合成网络比对结果Table 3 Alignment result for synthesis networks
2.3.2 真实网络比对结果分析
在真实网络上,分别从EC、ICS、S3、FC 这4 个方面对比4 种算法,4 种算法在EC 指标上的结果如表4所示。实验结果表明:在CE-SC、CE-HS、DM-HS 中,ModuleAlign 算法表现最 好;在SC-HS、SC-DM 中,JAlign 算法表现最好。
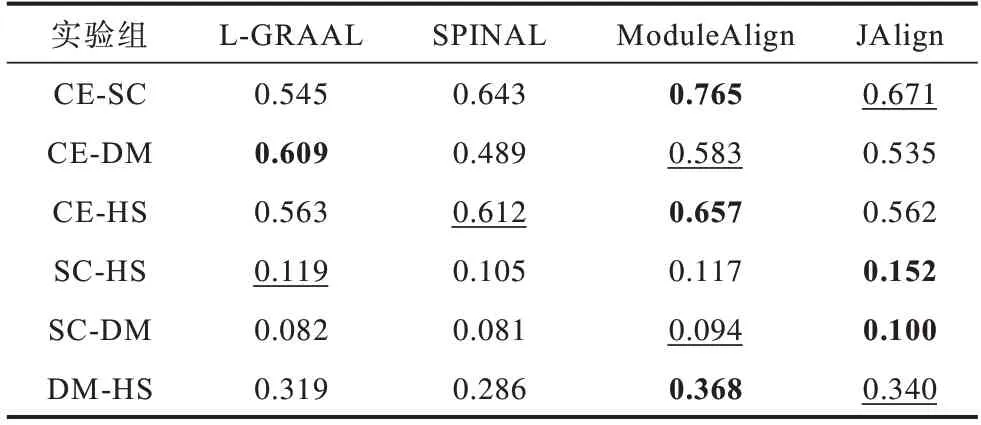
表4 不同算法在不同物种上的EC 指标Table 4 EC index of different algorithms for different species
表5 是不同算法在ICS 指标上的对比结果。实验结果表明:L-GRAAL 算法在CE-SC、CE-DM、CE-HS、DM-HS 实验中结果最好;JAlign 算法在这4 组实验中表现仅次于L-GRAAL 算法,在SC-HS、SC-DM 实验中结果最好;SPINAL 在各组实验中结果最差。
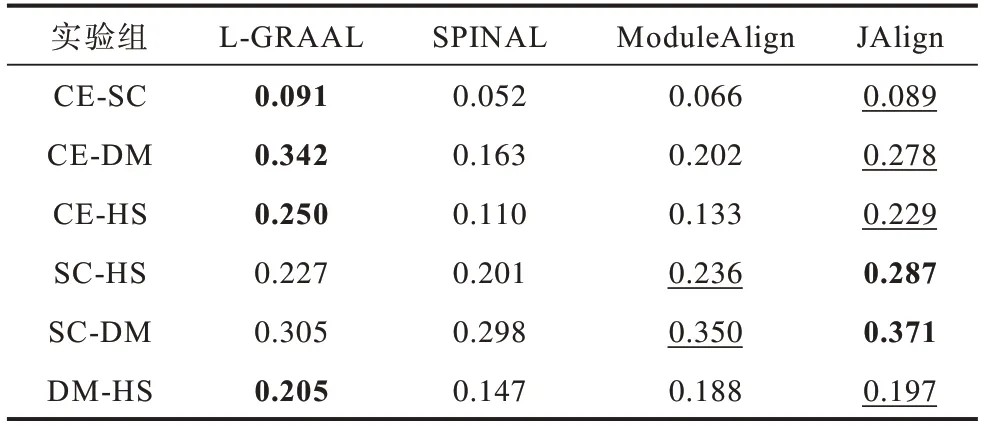
表5 不同算法在不同物种上的ICS 指标Table 5 ICS index of different algorithms for different species
表6 是不同算法在S3指标上的对比结果,S3是从源网络和目标网络2 个方面度量拓扑特征,能够更全面地分析算法的拓扑质量。实验结果表明:JAlign算法在网络规模较大的物种上,相较于其他算法表现最好,也较为稳定;L-GRAAL 算法仅次于JAlign,且在小网络上结果较好。总结上述结果,JAlign 算法在拓扑质量上可以得到稳定、最好的实验结果,L-GRAAL 算法整体表现仅次于JAlign 算法。

表6 不同算法在不同物种上的S3指标Table 6 S3 index of different algorithms for different species
表7 是不同算法在FC 指标上的对比结果。从生物指标角度来看,SPINAL 算法和JAlign 算法结果相近,L-GRAAL 算法表现最差。
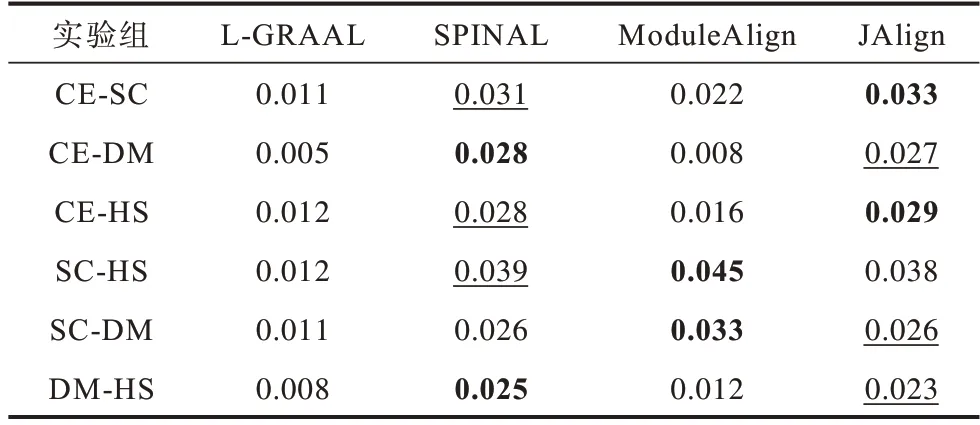
表7 不同算法在不同物种上的FC 指标Table 7 FC index of different algorithms for different species
表8 给出了不同算法运行时间的比较,实验计算机使用Inter Core i7-10510U 2.30 GHz 处理器,内存16 GB,算法在Linux Ubuntu 环境下运行。实验结果表明,在时间效率上JAlign 算法也具有一定优势,SPINAL、ModuleAlign 算法运行时间较长。

表8 不同算法的运行时间Table 8 Running time of different algorithms
结合拓扑质量度量结果分析,虽然SPINAL 算法在生物指标上表现很好,但在拓扑指标上表现较差,而L-GRAAL 算法则与之相反,其在牺牲一定生物质量的基础上实现了较好的拓扑质量,4 种算法中只有JAlign 算法同时实现了最佳的拓扑度量和生物度量。进一步分析实验过程可知,JAlign 算法在目标函数中添加了拓扑特征并降低了序列特征的比重,在聚类算法中也仅依靠节点的结构信息来划分模块,但随着序列信息所占比例的降低,其在生物指标上表现仍优于大部分算法,这说明JAlign 算法可以实现生物一致性和拓扑特性的良好平衡。
3 结束语
本文提出的生物网络全局比对算法JAlign。基于种子-扩展算法,利用层次聚类算法检测功能模块并进行模块匹配,根据目标函数从模块中筛选种子节点。在此基础上,结合邻居节点与种子节点间的连接关系将比对扩展至种子节点的邻居节点,并对剩余节点构建二分图进行最大加权匹配,使得孤立节点也有机会被比对上。实验结果表明,该算法能够全面地考虑比对过程,实现拓扑质量与生物质量的良好平衡,相较于其他3 种对比算法,其在拓扑和生物角度同时达到了最优的比对结果。为优化JAlign 算法的效率,进一步提高算法在生物功能方面的性能,下一步将对功能模块检测部分做并行化处理,并将模块检测应用到目标函数计算和种子的扩展阶段。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
河北画报(2020年8期)2020-10-27 02:54:20
电子测试(2017年15期)2017-12-18 07:19:27
软件导刊(2016年9期)2016-11-07 21:35:42
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
通信电源技术(2016年5期)2016-03-22 01:09:49
石油知识(2016年2期)2016-02-28 16:20:16
智能系统学报(2015年4期)2015-12-27 09:38:39
自动化仪表(2015年11期)2015-04-01 01:02:40
电子设计工程(2015年6期)2015-02-27 12:04:53
