
基于线上教学群聊文本的问句抽取模型
2022-02-22 22:05李沛哲张征王燕舞陈虹秦肖臻
中国教育信息化·高教职教 2022年1期
李沛哲 张征 王燕舞 陈虹 秦肖臻



摘 要:教学过程中产生的群聊文本往往包含着学生对于课程的思考。通过提取分析群聊文本中学生的提问,能够了解学生的学习情况,也能结合具体内容对学生进行指导。该研究旨在通过构建问句抽取模型,对群聊文本中与课程相关的提问进行提取。实验首先针对教学过程中产生的群聊文本进行收集,并结合课程相关教材进行数据清洗工作;然后针对类别分布不均匀问题,在Text-CNN模型的基础上提出了两种优化方式:引入注意力机制和使用平衡交叉熵损失函数。实验结果表明,优化后的模型能够达到91.95%的正确率,比原有模型增加了1.04%,而问句的F1-score表现为0.72,在原有模型的基础上提高了0.06。该模型能够运用到实际教学中,将群聊文本中与教学相关的学生提问抽取出来,再与线下教学相结合,提高教师的分析效率,进一步改善教学效果。
关键词:群聊文本;自然语言处理;卷积神经网络;人工智能教育应用
中图分类号:F407.67;G434 文献标志码:A 文章编号:1673-8454(2022)01-0070-08
一、 引言
随着网络技术的迅速发展,目前的教学形式已经不再局限于传统课堂,越来越多的人把目光聚焦于在线教学。在线教学能够提供更优质、更丰富的资源,并且具有随时可以观看的特点,备受广大学生的青睐。在线教学让学生在课堂之外也能够有便捷的途径学习自己感兴趣的内容,同时开阔眼界、增长学识。受疫情影响,我国各大高校开展了大规模在线教学,而如何提升在线教学的效果成为学界关注的焦点。
在线教学是一种基于网络平台的教育教学实践,师生之间的互动是时空分离的。这一点与传统教学有所不同。在传统课堂教学模式中,学生与教师之间的互动能够及时的反馈。学生可以根据教师课堂上讲解的内容实时提出问题,而教师则可以根据学生的问题强化知识点讲解,从而形成一个互相促进的学习过程。在线上教学模式中,存在的一个缺陷是缺少实时性以及学习者与传授者之间面对面的情感交流,导致这种依赖于实时反馈的学习过程的效果不能充分展现出来。
为了有效地将线上线下教学结合起来,许多学校充分利用学生喜欢在网络社交平台发言的特点,通过建立课程相关的群聊,一方面能够发布信息进行统一管理,另一方面也能从交流中获取学生对于课程的看法以及思考。由于群聊用户众多、内容繁杂,如果仅仅依靠人力从中筛选信息,会导致效率较低。在智能化时代背景下,利用人工智能相关方法,能够有效地从社交软件中提取有用信息,帮助教师自动收集与课程相关的提问并进行分析。
针对教学过程中产生的群聊文本,本文提出了一种问句抽取模型,并结合课程使用的教材文本,将学生发言内容中的提问抽取出来,从而有效地帮助教师了解学生的学习情况,提高教师的分析效率。
二、研究现状
(一)教学中的互动内容
大数据和人工智能技术的应用,为教育提供了更全面更系统的教学信息,大大提升了教育的智能化程度[1]。同时,学生参与线上教学过程中的一些学习行为也能够被量化记录,如观看视频时长、课后作业完成情况、学习笔记等。江波等的研究表明,行为记录能够反映学生的学习情况[2];杨丽娜等也提出,通过采集、分析和处理学生学习过程中的行为记录,能够对学生的知识学习能力进行诊断[3]。借助行为记录的诊断结果,教师能够直观有效地了解学生的学习情况,针对性地对学生进行指导,促进师生间的情感交流,从而提高学生的学习积极性,进一步提高教學效果。
目前的线上学习平台中记录了大量基于文本的课程互动内容,如何挖掘这些文本中隐含的有效信息,受到众多研究者的关注[4]。文本挖掘的一个重要研究方向是情绪分析——对文本中所蕴含的学生学习情绪进行量化分析,以此来优化教学方式。除了学习情绪之外,文本内容通常还包含学生对于课程的思考和疑问,因此如果能找到一个合适的方法对这部分内容进行抽取,将值得重点关注的内容提取出来,一方面能够更好地体现学生对于课程内容本身的需求,另一方面也能够减少教师分析工作的强度,辅助其优化课程设计,对教学过程进行反思。
(二)文本分类
线上教学群聊文本中的问句抽取问题可以转化为对句子进行分类。而在句子分类问题的研究上,传统词袋法主要是通过特征选择筛选出跟类别相关度最高的N个词,然后计算每个句子的特征权重,进而将句子用N维向量表示,并选择合适的分类器对数据进行训练,最终得到所需的句子分类模型。但是中文句子在语义、词义和歧义等方面存在问题[5],而传统词袋法过多地关注于词语的局部特征,很难从句子整体去分析理解,因此在句子分类问题上的应用有一定缺陷。
为了改善上述不足,有研究者提出句法分析的方法[6]。该方法的主要思想是结合人为提取的规则自动识别句子以及句法单位,并按照规定输出识别结果。这种规则很大程度上依赖于相关人员的语言知识,工作量较大,灵活性较低。
随着机器学习的发展,很多研究者将大量机器学习方法用于分类问题中,并表现出较好的性能。其中神经网络的应用较广,能够涉及很多方面,所以使用该方法进行句子分类的研究越来越多。李超等构建了基于卷积神经网络(Convolutional Neural Network,简称CNN)和长短期记忆网络(Long Short-Term Memory,简称LSTM)的混合神经网络的训练模型,提取了句子的深度特征,同时也表现出更优秀的性能[7]。有研究者探究了问题分类特征提取的3种方法:第1种是使用聚类信息获取问题的特征向量;第2种是利用word2vec方法和TF-IDF加权的方式;第3种方式基于序列的数据类型[8]。随后基于Attention机制的改进网络模型也在NLP中被广泛运用。赵云山等搭建了一个包含4个Attention CNN层的A-CNN文本分类模型,用Attention机制生成非局部相关度特征,用普通卷积层提取局部特征,然后将两类特征结合起来,最终在文本分类任务获得了较高的精度以及通用性[9]。苏锦钿等将句子中单词的词性与Attention机制相结合,提出一种面向句子情感分类的神经网络模型PALSTM,准确率获得了一定提升[10]。
基于上述研究,本文提出一种基于线上教学群聊文本的问句抽取模型。该模型以Text-CNN为基础,针对数据分布不均匀的问题,利用注意力机制和平衡交叉熵损失函数进行改进,最终得到优化后的问句抽取模型。
三、数据集获取与处理
(一)相关文本介绍
本文所研究的数据主要分为两个部分:一部分是教学过程中产生的群聊文本,主要以对话形式存在;另一部分则是相关课程所使用的教材文本。群聊文本在一定程度上能够反映学生的学习状态。通常来说,如果学生在学习中遇到问题,在群里求助是一种较为常见的方式。所以根据这一学习特点,教师可以利用群聊文本中学生提出的一些问题,分析他们的学习情况,从而进行指导。而教材文本则是学生在学习过程中必备的指导书,其包含的专业术语能够为群聊文本的处理带来一定帮助。
群聊文本主要以短文本为主,通常由多方交互信息构成[11]。与长文本不同,群聊文本具备非正规性、不完整性及稀疏性三个特点[12]。非正规性指表达方式更接近于口语,同时还会包含很多的表情和图片;不完整性指由于文本长度较短,句子成分通常不完整;稀疏性指由于短文本仅包含较少的字词,在整个群聊文本中,所占比重较小。
除了本身具有的非正規性、不完整性及稀疏性这三个特点外,这类在教学过程中产生的群聊文本往往还会包含很多专业性较强的词汇。可以利用这一特点,结合教材文本进行分析,强化专业术语对后续分析结果的影响,从而解决群聊文本中可能存在的一些杂乱短文本所带来的问题。
(二)教材文本
由于群聊文本信息杂乱,存在较多与教学内容无关的对话。如果直接对其进行处理,有可能导致最后的结果不佳。因此,为了保证结果与教材内容具有一定程度的相关性,需要结合相关课程的教材文本,计算群聊文本和教材文本两者之间的相似度。相似度越高,说明该文本越贴合教学内容,值得重点关注;相似度越低,说明该文本与教学内容无关的可能性越大,有可能会干扰最后结果。以此为依据进行后续群聊文本的数据清洗工作。获得作者授权后,本文选取自动控制原理类课程采用的教材《自动控制原理(第三版)》作为参考,进行关键词提取工作。
教材中通常包含许多专业性较强的词汇,如果使用传统的词库对其进行处理,有可能无法选取出具有代表性的词语,从而导致最后清洗效果不佳。为了解决这一问题,本文选择使用TF-IDF方法对教材进行关键词提取,从中筛选出具有课程特点的专业词汇。将提取出来的结果利用正则匹配进行处理,去除其中的数字、字母和空元素以及一些特殊字符,最后得到的关键词利用wordcloud进行可视化后处理,结果如图1所示。
通过wordcloud生成的词云中,词语大小和权重有关。因此TF-IDF值越大的词语在词云中显示越明显。结合图1,可以较明显地看出“系统”“传递函数”“开环”等提取出来的词语代表着教材的文本特征,而实际教学中,这些词语也符合自动控制原理类课程的特点。
(三)群聊文本
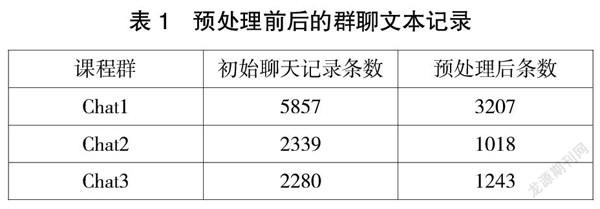
通过对自动控制原理类课程相关群聊文本的收集和整理,最终得到了三个教学群的聊天记录,分别包含5857、2339、2280条。本文首先使用了开源的Python第三方库jieba中文分词系统对聊天记录进行分词处理。经过中文分词处理后,再结合聊天记录和教材关键词训练word2vec模型构建词汇表,并且利用训练好的词汇表模型为每句话构建向量。
然后分别计算教材关键词向量和每条聊天记录向量的余弦相似度,并且根据余弦相似度的大小判断该聊天记录与教材之间的相关性。通过分析余弦相似度结果,发现以下两种情况需要考虑:一是计算出来的值较小,这部分内容视为与教材文本相关性较低;二是某种值出现多次,考虑到群聊天不仅存在大量表情、图片,甚至还有很多系统消息,这部分内容之间的相似度极高,因此会导致与教材文本的余弦相似度值非常接近。以上两种情况均会对最后结果产生影响,所以在数据清洗的时候,这两部分内容都应考虑在内,进行适当去除。
预处理前后的群聊文本记录对比如表1所示。从表1可以看出,经过预处理后,很大部分聊天记录被去除,保留下来的聊天记录则是与教材内容相关性较高,同时也更加具有研究意义的数据。
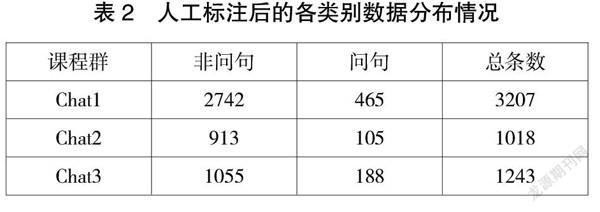
数据清洗后结合实验目的对其进行标注。本实验的目的是将群聊文本中的问句抽取出来,进而帮助教师了解学生在学习过程中碰到的问题,因此文本类别分为两类:第一类是问句,第二类则是非问句。标注采用人工标注的方法,一共标注了三个群聊文本,数据清洗后共5468条聊天记录。统计全部数据中两个类别的数量,具体分布如表2所示。
从表3可以分析得出,两类数据分布不均匀,群聊文本中只有少部分聊天记录是用户的提问。这些问题体现了学生对于教学内容的思考,接下来的实验会围绕如何将这些问句尽可能准确地提取出来开展。
四、模型设计及结果分析
(一)问句抽取框架
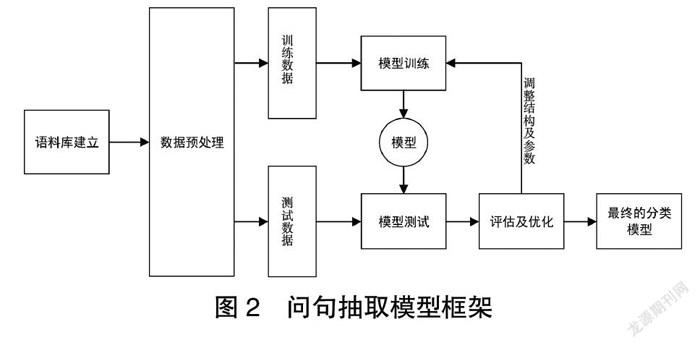
基于线上教学群聊文本的问句抽取模型框架如图2所示。该框架主要包括语料库建立、数据预处理、划分训练集和测试集、模型训练、模型测试和评估及优化六个步骤。①语料库建立:将收集到的群聊文本按照一定格式要求进行保存。②数据预处理:结合教材文本对群聊文本进行一定的数据清洗工作。③划分训练集和测试集:将预处理后的群聊文本数据按照3∶1∶1的比例划分为训练集、验证集和测试集。其中验证集和训练集代表训练过程中的表现,可以据此调整网络结构以及参数,而测试集能够评判最后得到网络模型的优劣。④模型训练:将训练数据的词向量输入到网络模型进行训练,并且每一轮次输出在训练集和验证集上的性能,保存最好结果。⑤模型测试:将训练好的模型应用到测试集中,根据最终结果分析出问题,进而针对这些问题提出进一步的优化策略。⑥评估和优化:通过训练过程中训练集和验证集的表现调节网络超参数,优化网络结构;通过模型在测试集上的表现结果对网络进行评估,判断该模型性能的好坏。
经过上面六个步骤,即可得到最终的分类模型。将最终的分类模型运用到未标注数据中即可进行预测,从而自动将群聊文本中的问句抽取出来,帮助教师分析学生的学习情况,总结问题并适当做出解答。
(二)Text-CNN模型
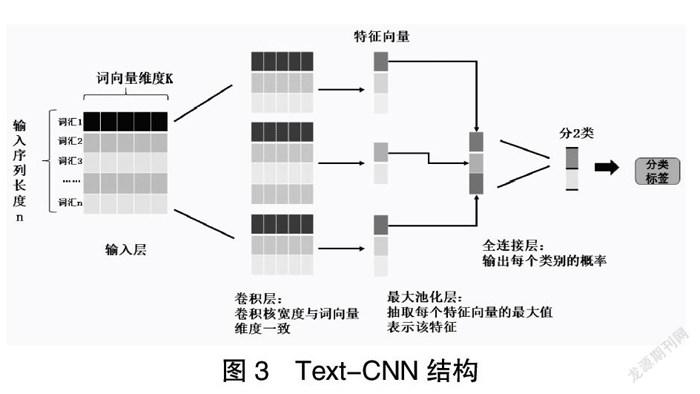
Kim Y提出的Text-CNN是一种利用卷积神经网络对文本进行分类的算法[13]。在Text-CNN中,输入到CNN中的不是图片某个区域的像素值,而是用矩阵表示的句子。矩阵的每一行代表着每个词的词向量,因此在利用CNN做文本分类的任务时,还需要对句子中的单词进行向量化处理。
Text-CNN主要由四部分构成:输入层、卷积层、池化层、全连接层。由于输入层要求输入一个定长的文本序列,因此,在实际应用中,输入文本和输入层之间还具有一个隐藏层——嵌入层。嵌入层的主要作用是指定维度,并且产生能够代表句子语义信息的特征词向量。
经过嵌入层后,最终进入输入层的则是长度一定的句子特征向量,接着就可以利用卷积层的卷积操作对这些向量进行特征提取。通过定义不同尺度的卷积核,以滑动窗口的形式对指定长度文本进行卷积运算,再使用激活函数进行计算,最后就可以提取出不同的特征向量,构成卷积层的输出。
不同尺度卷积核抽取不同长度的文本片段進行卷积运算,最后每一组会产生一个特征值向量并输入到池化层中。池化层通常采用最大池化层(1-Max池化),即从每个滑动窗口产生的特征向量中筛选出一个最大的特征,然后将这些特征拼接起来构成向量表示。该层不仅能够减少模型的参数,使模型复杂度下降,同时也保证了特征的位置不变性。不同长度句子在经过池化层后都能变成固定长度输入到全连接层中。
最后进入全连接层,输出每个类别的概率,实现分类。概率越大说明最终将预测结果定为这一类的误差较小。模型的损失函数采用分类任务中常使用的交叉熵,它能反映模型与实际结果的差距,从而在训练的时候调整参数,以尽可能使损失函数值减小。Text-CNN简化的模型结构如图3所示。
(三)模型优化
1.注意力卷积模型
Attention机制的提出主要源自于人类注意力。人在看到大量信息时,往往不会每个信息都去重点关注,而是根据判断快速筛选出对自己最有价值的信息,然后忽略其他无价值的信息。在句子分类的问题上,该机制的思想是在导出句子向量时将注意力集中在特定的重要词语上。
把注意力机制和Text-CNN结合起来,可以构建一个基于注意力机制的卷积神经网络[14]。与传统的卷积神经网络相比,该网络在输入层和卷积层之间新增了一个attention层。通过新增的attention层为句子中的每个词语创建一个新的上下文向量。新向量再与原来的词向量进行拼接,从而构成新的特征表示。利用注意力机制能够确定哪些词语受关注度更高,进而对词语进行加权和组合。
ATT-CNN模型的具体训练过程如下:①设定模型的初始参数。②将长度一定的句子特征向量经过输入层后输入到attention层中。③通过attention层提取出来的特征与原来的词向量进行拼接,构成句子新的特征表示。将句子的新的特征向量经过卷积层提取特征,并且输入到全连接层中。④全连接层输出结果经由定义的损失函数计算得到训练误差,再利用误差的反向传播对网络权重进行更新。⑤重复2~4步直至训练效果不再提升或者满足设定的epoches次数。
2.损失函数优化
通过对前面数据集的标注情况进行分析,发现两类数据分布不均匀。在群聊文本中,用户的提问占比仅为15%左右,出现了严重的数据不平衡问题。因此,为了得到更好的训练效果,避免最后的分类结果全部偏向于多数容易分类的数据上,需要对模型进行优化调整。
Text-CNN模型中通常使用的损失函数是交叉熵。在本实验中,由于存在大量负样本,会对模型的性能造成一定程度损害,使得训练效率低,甚至有可能造成模型退化。为了解决数据不平衡这一问题,本文选择针对模型中的损失函数提出优化策略,使用平衡交叉熵,通过加入一个权重因子减少正负样本不平衡带来的影响。使用该方法无需对样本进行过抽样或者下采样等额外处理,仅需对模型中的参数进行修改即可。
该方法的核心思想是通过赋予正负样本不一样的惩罚权重,对少数类样本赋予较高权重,而多数类样本赋予较低权重。通过这种方式能够使模型集中在对少数样本的正确分类上,一定程度上减少多数样本对训练带来的影响。平衡交叉熵函数(balanced cross entropy)计算公式如下:
<D:\2022年\2022年中国教育信息化\信息化2022-1\TP\公式.tif>(1)
其中,α表示权重因子,且α∈[0,1],大小根据正负样本的分布进行设置。N代表样本总数,m和n分别表示正样本和负样本个数,即问句和非问句的数量。为预测概率的大小。
(四)评价指标
由于本文所使用的数据集正负样本不平衡,因此仅仅使用分类正确率(Accuracy)评估最后得到的训练模型的好坏不具有代表意义。除了准确率以外,评估模型分类效果所使用的评价指标还包括:精确率(Precision,PR)、召回率(Recall,RC)、F1分数(F1-Score)。它们在计算评价指标时常使用的分类示意图如表3所示。
其中,T和F分别代表预测结果的正确与否,即True和False;P和N代表着预测结果为正样本还是负样本,即Positive和Negative。在本实验中,TP、FN、FP、TN分别代表的实际含义如表4所示。
根据表4可以得出精确率、召回率的公式分别为:
P=(2)
R=(3)
从公式(2)、公式(3)可以看出,精确率表示在所有被判别为问句的样本中,真正问句样本所占的比重;而召回率则表示真正问句样本中被正确预测为问句样本所占的比重。在实际教学中,一方面期望能够尽可能多地将学生的提问全部提取出来,另外一方面又期望能尽量减少错误分类对教师分析学习情况造成的影响。综合考虑以上因素,使用精确率和召回率的调和平均值F1-score作为评估指标,其计算公式如下:
F1-score=(4)
(五)结果对比分析
1.模型结果对比
本实验分别使用CNN、ATT-CNN模型以及优化后的平衡交叉熵损失函数(Balanced CE)对经过人工标注的测试集进行预测。表5是上述几种模型的实验结果对比。
从表5可以看出,无论是使用注意力机制还是平衡交叉熵损失函数进行优化,都在基础的Text-CNN模型上有一定提升。对比基础模型的实验结果,加入注意力机制后测试集的acc增加了0.32%,而在问句的F1-score表现上也增长了0.01;使用平衡交叉熵损失函数对Text-CNN进行改进,测试集的acc增加了0.96%,问句的F1-score表现增加了0.04,可以认为减小了两类数据不平衡所带来的影响;将注意力机制和平衡交叉熵损失函数综合应用到Text-CNN后,测试集的acc增加了1.04%,而问句的F1-score表现也增加了0.06。
另外,从测试集的acc表现可以得出,在尽可能提升问句预测准确度的同时,非问句的预测准确度也并未受影响而下降。所以使用注意力机制和平衡交叉熵损失函数能够在一定程度上提高Text-CNN模型在群聊文本中的分类性能,从而较好地实现从群聊文本中抽取问句的目的,方便教师进行收集分析,进而将结果应用到实际教学中。
2.实例展示
实验最后对提取出来的问句进行了可视化展示,具体结果如图4所示。图中仅展示了某个群中的部分问句内容,从图中可以较为直观地看出,提出疑问的用户除了教师之外,更多是学生。前者能够说明教师对于学生学习生活的了解情况;后者说明了学生在学习过程中对内容或者教学方式的疑问。通过对这些内容进行提取,教师能够针对问题进行分析,作出针对性解答;学生也能够从提问中查缺补漏,反思自己对知识点的掌握情况,从而进一步巩固学习成果。
五、 结语及未来展望
本文针对线上教学群聊文本内容繁杂、结构化低以及教师分析工作效率较低等问题,提出一种优化的群聊文本问句抽取模型。研究结合课程相关教材进行了关键词提取处理,并以此为基础,针对教学过程中产生的群聊文本进行数据清洗工作。然后使用人工标注的方法对三个群的数据集进行类别标注,标注类别为问句和非问句。在标注过程中发现存在两类数据分布不均匀的问题,于是在Text-CNN模型的基础上提出了两种优化方式:引入注意力机制和使用平衡交叉熵损失函数。从最后的结果可以得知,优化后的模型分类性能在原有模型上有一定程度的提升。
本研究依托“子曰”学习平台,以自动控制原理类线上课程中产生的群聊文本为例,建立分类模型对问句进行提取,并且将优化后的模型运用到实际教学中,一定程度上缓解了时间和人力的浪费。教师通过重点分析提取出来的问题内容,能够作用于以下方面:①整体把握学生的学习情况。当类似问题被提出多次时,一定程度上反映了学生对于相关知识点的掌握不够充分。因此教师能够根据问题的出现频率,分析学生的具体学习情况,进而及时调整教学内容,集中讲解共性问题,加深学生对知识点的理解。②针对性地对学生进行指导。不同问题揭示了学生在学习过程中存在个体化差异的现象。因此,教师能够通过分析每个人的问题来发现对应的知识薄弱点,从而对症下药,有针对性地进行教学指导,使学生较快地弥补不足,继而投入到新的学习进程中。
在后续研究中,可以适当扩充数据集,将其他课程教学过程中产生的群聊文本内容也归入其中,以提高不同领域中问句的识别性能。另外,教师往往更倾向于关注那些内容较为完整、突出并且有效的问题,所以也可针对这些问题的完备性或者有效性进行进一步抽取,这样能节约教师更多时间,也能够促使学生进行更多思考,提出具有价值的问题。
参考文献:
[1]卓文秀,杨成,李海琦.大数据与教育智能——第17届教育技术国际论坛综述[J].终身教育研究,2019,30(3):62-67.
[2]江波,高明,陈志翰,等.基于行为序列的学习过程分析与学习效果预测[J].现代远程教育研究,2018(2):103-112.
[3]杨丽娜,魏永红,肖克曦,等.教育大数据驱动的个性化学习服务机制研究[J].电化教育研究,2020,41(9):68-74.
[4]冯翔,邱龙辉,郭晓然.基于LSTM模型的学生反馈文本学业情绪识别方法[J].开放教育研究,2019,25(2):114-120.
[5]胡金凤.中文问答系统中的问题分析与答案抽取[D].石家庄:石家庄铁道大学,2016.
[6]夏艳辉,聂百胜,胡金凤.中文开放域问答系统的问题分类研究[J].价值工程,2019,38(16):147-149.
[7]李超,柴玉梅,南晓斐,等.基于深度学习的问题分类方法研究[J].计算机科学,2016,43(12):115-119.
[8]RAZZAGHNOORI M, SAJEDI H, JAZANI I K. Question classification in Persian using word vectors and frequencies[J]. Cognitive Systems Research, 2018(47):16-27.
[9]趙云山,段友祥.基于Attention机制的卷积神经网络文本分类模型[J].应用科学学报,2019,37(4):541-550.
[10]苏锦钿,余珊珊,李鹏飞.一种结合词性及注意力的句子情感分类方法[J].华南理工大学学报(自然科学版),2019,47(6):10-17,30.
[11]周园林,邵国林.基于群聊文本的分类研究[J].现代计算机(专业版),2019(8):22-28.
[12]王媛媛,范潮钦,苏玉海.面向聊天记录的语义分析研究[J].信息网络安全,2017(9):89-92.
[13]KIM Y. Convolutional neural networks for sentence classification[C]// Proceeding of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha,Qatar: EMNLP, 2014:1746-1751.
[14]ZHAO Z, WU Y. Attention-Based convolutional neural networks for sentence classification[C]// Interspeech, 2016.
作者简介:
李沛哲,华中科技大学人工智能与自动化学院硕士研究生;
张征,华中科技大学人工智能与自动化学院副教授,通讯作者,邮箱:10444440@qq.com;
王燕舞,华中科技大学人工智能与自动化学院教授;
陈虹,华中科技大学人工智能与自动化学院教师;
秦肖臻,华中科技大学人工智能与自动化学院副教授。
The Question Extraction Model Based on Group Chat Text of Online Teaching
Peizhe LI, Zheng ZHANG*, Yanwu WANG, Hong CHEN, Xiaozhen QIN
(School of Artificial Intelligence and Automation, Huazhong University of Science and Technology, Wuhan Hubei 430074)
Abstract: The group chat text generated in the teaching process generally incorporates the thoughts of students regarding the course, thus, extract and analyze students’ questions in the group chat text can help teacher get a better understanding of the students’ learning progress and guide students according to the learning content. This article aims to extract questions related to the course in the group chat text by constructing a question extraction model. Specifically, the group chat content generated during the teaching process is collected in the first step, and then, by employing course-related materials, the data cleaning is conducted. To tackle the problem of uneven categories, two optimized methods are proposed based on the Text-CNN model, i.e., the attention mechanism and the balanced cross-entropy loss function. The experimental results show that the optimized model achieves the correct rate of 91.95 percent which increases 1.04 percent than the original model. Meanwhile, the F1-score of the question sentence is 0.72, which is higher than the original one by 0.06. The results provide the evidence that this model can be applied to the actual teaching to extract those questions related to the teaching process from the group chat text, to combine the offline teaching process, to improve the efficiency of the teachers' analysis work, and further to improve the learning effect.
Keywords: Group chat text; Natural language processing; Convolution neural network; AI education application
編辑:王晓明 校对:李晓萍
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年10期)2016-06-16
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
