
基于大数据的个性化英语教学策略
2022-02-21 10:42叶砾陈剑乐海平
微型电脑应用 2022年1期
叶砾, 陈剑, 乐海平
(肇庆医学高等专科学校,公共基础部,广东,肇庆 526020)
0 引言
利用大数据的个性化英语教学,主要通过考试成绩判别学生的个性化学习成绩,然后出自因材施教的理念,对学生进行针对性的教学设计。这一工作需要分为2个实现部分:一是构建题库,对词汇、语法、句式、听力、写作等知识点进行归类;二是构建动态课件,对其薄弱环节进行补强,对其优势环节充分强化训练。该系统属于应试教育的典型实现模式,可以应用于初高中基础英语教育,也可以应用于高校英语教育中的四六级、专八、雅思、托福等相关教育。
苏布德提出了高校英语教学中的对分课堂模式并开发了其基于大数据的人工智能英语教学系统[1];王辰针对高职英语教学开发了基于大数据的英语教学系统[2];陆志慧针对英语写作能力教学提出了大数据技术在英语教学工作中的应用策略[3];阮娅丽及周谨平从不同开发思路研究了英语教学的相关教学辅助软件的开发过程[4-5]。
这些英语教学设计,适用于非学校平台的英语教育,属于专业全民英语教育服务系统的开发范畴。
1 个性化英语教学大数据系统开发需求分析
1.1 数据交互需求及数据来源设计
该个性化英语教学大数据系统的核心是其大数据工程架构的开发,主要包括4个核心数据来源,分别为知识点题库来源、知识点课件来源、知识点得分来源、学生对课件的浏览数据来源,其结构如图1所示。

图1 大数据系统应用模式图
在图1中,上述4个数据来源的数据汇总到数据库中,在数据实时挖掘系统中,对教师的侧重点做出评价,对学生的学习侧重点做出评价,同时根据学生学习课件的侧重点与其学习成绩做出教师到学生的关联性评价。根据该关联性评价和学生的知识储备和得分能力,对学生推荐匹配度较高的教师编辑的学习课件,同时根据学生的知识储备和得分能力,推荐测试试题[6-7]。
该系统的核心亮点是对教师和学生之间构建匹配模型,为学生推荐匹配度较高的老师。
1.2 教师推荐模型设计需求
教师推荐模型共包含以下几个判断标准。
(1)学生参与的课件学习记录中,提取课件的关联知识点、课件上传教师ID、学习时长等信息。
(2)学生参与的考试成绩记录中,提取每道试题的关联知识点、得分情况,将该得分情况与学生参与该知识点学习的课件学习记录进行对应,分析学生在该知识点的学习时长记录、学习课件量,关联到相关课件的上传教师ID。
(3)如果学生对某知识点的学习时间长于其他知识点,且该知识点得分高于其他知识点得分时,减少对该类试题的推荐量。
(4)如果学生对某知识点的学习时间短于其他知识点,且该知识点得分低于其他知识点得分时,增加对该类试题和课件的推荐量。
(5)如果学生对某知识点的学习时间短于其他知识点,且该知识点得分高于其他知识点得分时,该学生对相关课件教师的关联度指标提升,认为该教师编制的课件适用于该学生的学习习惯,在推荐其他知识点课件时,增加该教师编制的相关课件的推荐量。
(6)如果学生对某知识点的学习时间长于其他知识点,且该知识点得分低于其他知识点得分时,该学生对相关课件教师的关联度指标下降,认为该教师编制的课件不适用于该学生的学习习惯,向学生推荐关联度较高的教师课件,同时在推荐其他知识点课件时,减少该教师编制的相关课件的推荐量。
该模型基于一个教育学基本原理,即教师与学生匹配度较高时,学生可以在更短时间内获得更佳的学习成果,反之,学生会额外消耗更多的学习成本且无法获得满意的学习成果[8-9]。
2 教师推荐模型的人工智能实现模式
根据前文分析,发现教师/学生关联分析模块的主要输入数据来自学生学习模块,主要包括以下输入数据。
(1)学生学习数据:该数据来源如表1所示。

表1 学生学习数据的构成模式
该数据主要用于构建2个链接:① 学生与知识点学习成本之间的链接;② 学生+知识点与教师之间的链接。
(2)学生考试数据:该数据来源如表2所示。

表2 学生学习数据的构成模式
该数据主要用于构建1个链接,即学生对知识点掌握程度链接。
根据前文列出的教师推荐模型基本算法,要计算出学生对各知识点的学习时长与学习分数之间对应关系,即以知识点ID为控制变量i,分别统计学习时长T(i)与得分R(i)。且使用min max投影法,对T(i)和R(i)进行分别投影,如式(1),
(1)
式中,max、min分别为该式处理的T(i)或R(i)的最大值及最小值,Xi、Yi分别为输入数据和输出数据。
此时,根据处理过的T(i)和R(i)依照表3中模糊矩阵进行策略选择。

表3 教师推荐模型的核心模糊矩阵设计
表3中,针对教师学生匹配度,共给出了4种策略,如表4所示。

表4 策略执行模式设计
该人工智能实现模式为一种基于模糊矩阵的大数据+人工智能实现模式,其原理如前文分析为增加教师与学生的匹配度,使学生可以跟随匹配度更高的教师学习,以提高学习效率。
3 学生画像模型的人工智能实现模式
系统中的学生画像模型分为前台画像和后台画像。前台画像主要供学生对知识点掌握情况进行自我认知,与传统的考试分数式评价方法相比,该方法可以更显著反映出学生的学习情况;后台画像主要用于系统内部对学生进行知识点匹配,用于推荐算法。
3.1 后台画像模型
后台画像数据的本质是前文中表1数据和表2数据的整合,对学生在不同知识点索引下的学习时长、测试得分数据进行描述,同时对学生的学习次数、测试次数等数据进行描述,其数据量较大,但可以归纳成图2形式。
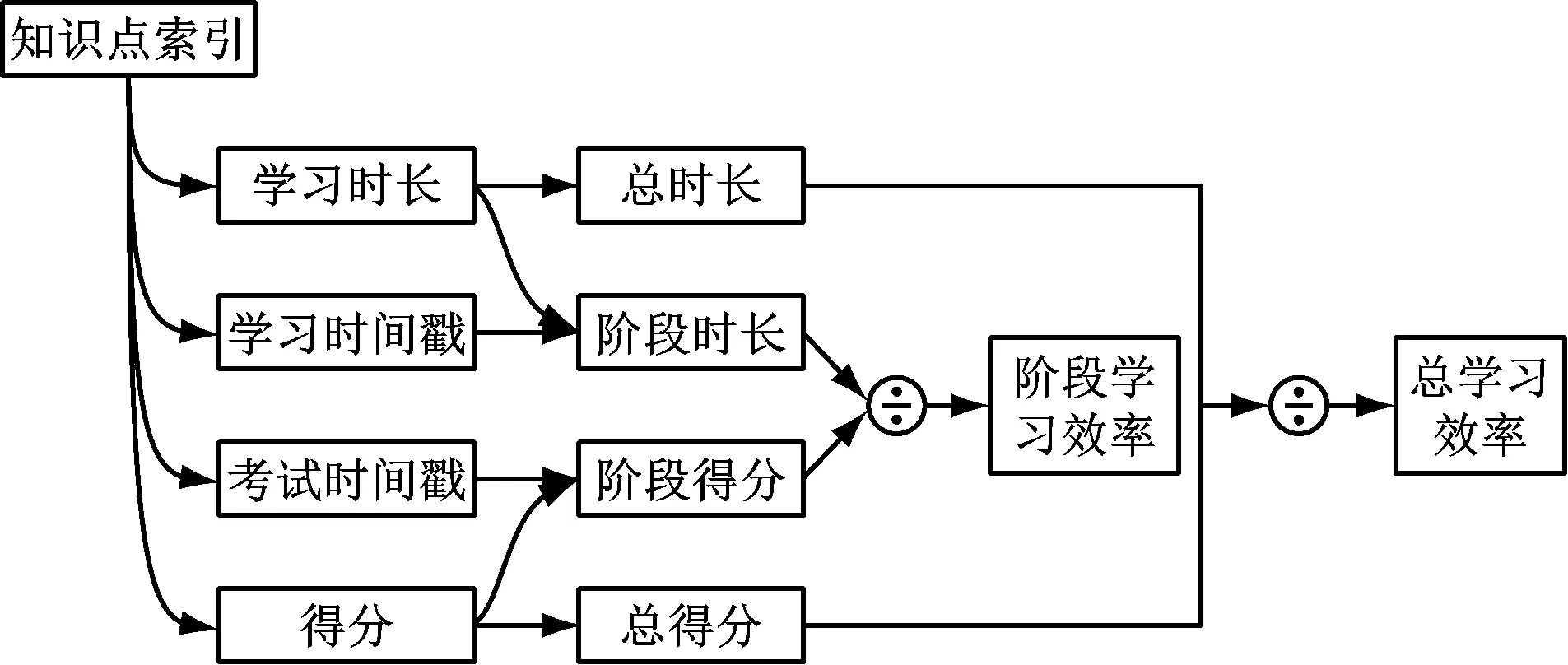
图2 后台画像数据结构示意图
图2中,后台画像数据主要包括2部分:一部分是当前总时长与总得分以及二者计算所得的总学习效率的实时数据;另一部分是每次测试到该题目之间的时序序列[10]。
3.2 前台画像模型
前台画像模型来自对后台画像模型的汇总过程,将英语学习中的数千个知识点索引进行汇总,得到词汇(动词、名词、介词、副词、词组、固定搭配)、语法、英语文化等知识点的汇总情况,包括实时成绩汇总数据、学习效率数据等,形成雷达图。同时评价学生的词汇量,给出可能通过四六级、专八、雅思、托福等相关英语考试的可能性评价。软件前台画像运行界面如图3。

图3 软件前台画像运行界面
4 软件效能实测
2020年1月3日至2020年12月15日,该软件进行了小范围内测,内测期间,共服务学生客户3 275人,引入英语教师182人,实测包括软件对学生考试通过率与学生实际参加考试通过率的对比、教师与学生的匹配度、学生及教师对软件做出的主观评价等。
4.1 考试通过率预测能力实测
所有参加内测用户中,最短使用该系统学习时间为397小时,最长使用该系统学习时间为2 192小时,平均使用该系统学习时间为1 294±108(均值±方差)小时。所有3 275名学生用户中,参加四级考试1 029人,占31.4%;参加六级考试438人,占13.4%;参加专八考试102人,占3.1%;参加雅思考试43人,占1.3%;参加托福考试38人,占1.2%。比较上述参加内测的学生用户在实际考试过程中的通过率与该系统根据用户画像给出的考试成功率预测值,得到该软件实际效能评价结果对比数据,如表5所示。
表5中,所有考试的学生实际通过率均高于软件给出的预测考试通过率,但偏差值均小于10个百分点。标志着该系统对学生考试通过率的画像预测结果略显保守,特异度较低,但敏感度较高。

表5 考试通过率预测能力
4.2 教师推荐量实际分布状态实测
该系统共引入英语教师182人,内测期间上传各类课件48 932条,在前文设计的教师匹配算法下,教师与学生之间的匹配度指标在理论上应处于幂次分布状态,所以对该算法的头部效应进行计算,如图4所示。
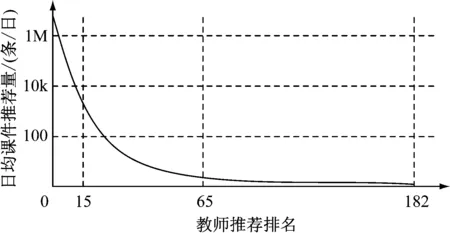
图4 教师推荐量实际分布状态实测图
在图4中,182名教师中有65人提交的课件能确保每天被推荐至少10条,有15人日推荐量在7 000条以上,但推荐量最高的教师,日推荐量达到216 296条,日推荐量超过1万条的教师,为13人。这说明该推荐模式可以确保经过筛选的“大V”级教师可以达到总教师比例的7.1%。该平台软件对教师的推荐结果,符合头部效应。
4.3 用户评价结果
要求3 275名学生内测用户和182名教师用户给出感性评价,分为1星至5星,其评价结果如表6所示。

表6 用户评价结果表
在表6中,学生用户给出的评价远高于教师用户,这一结果与该软件面向学生的服务目标有关,学生用户将在该软件中保持较友好的服务体验,但教师用户给出的评价较低。学生用户中,给出5星、4星评价的用户共占比为87.0%,给出2星、1星评价的用户仅占3.1%。而教师用户中,大部分用户给出了4星、3星评价,共占67.0%。
但应看到,虽然该系统的教师头部效应决定了只有约7.1%的教师提交资料会被系统推荐,但有17.6%的教师用户给出了5星评价。该5星评价量虽然远低于学生用户给出的58.8%的5星评价比率,但仍表现出更多教师用户因为该软件利于学生学习而给出较高评价。
该软件在内测过程中,遇到教师评价低于学生评价的情况,这需要在后续设计中,给教师用户更多其他激励,以提升教师用户的黏性。而对激励措施考量并未在该软件核心算法设计任务中,故不多做论述。
5 总结
本文研究中设计的基于大数据的个性化英语教学系统的核心优势,在于增加教师与学生的匹配度,使学生可以匹配到更适合自己的教师设计的课件资料,以增加其学习效率。且该软件将英语学习知识点划分成数千个知识点,并针对学生对知识点的掌握情况,对其进行有计划有目的的精准推送,使学生的学习过程可以根据其对知识点的掌握情况作出个性化的配置。通过学生对各知识点的掌握情况,该系统整合学生的学习大数据,分析该学生通过常规考试的预期通过率,且该预期预测结果,拥有较高的敏感性,略低于学生实际参加考试时的实际通过率。内测过程中,学生用户给出的评价结果远高于教师用户给出的评价结果,这与教师推荐算法的头部效应有关,所以在后续开发中,应针对教师用户提出更新的激励政策,以增加教师用户的黏性。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
小哥白尼(神奇星球)(2022年3期)2022-06-06
昆明医科大学学报(2022年1期)2022-02-28
非公有制企业党建(2020年10期)2020-10-27
成长·读写月刊(2018年8期)2018-08-30
瞭望东方周刊(2017年7期)2017-03-01
东方教育(2016年11期)2017-01-16
考试周刊(2016年19期)2016-04-14
人间(2015年16期)2015-12-30
延河(下半月)(2014年1期)2014-02-28
