
基于极化关系表述与低维数据间关联学习的推荐模型
2022-02-21 04:43蔡晓东洪涛曹艺
华南理工大学学报(自然科学版) 2022年1期
蔡晓东 洪涛 曹艺
(桂林电子科技大学 信息与通信学院,广西 桂林 541000)
采用知识图谱来构建推荐模型可以充分利用图结构特性对商品及用户进行准确的刻画,从而提升推荐启动速度及准确率。Zeno等[1]首次采用知识图谱来解决冷启动问题并提升了推荐准确率,第三代推荐模型[2]由此开启了新纪元。不同于第一、二代推荐模型[2],第三代基于知识图谱的推荐模型具有更高的推荐准确率,并且能够以此为依托实现冷启动推荐[2]。第二代推荐模型主要解决的是数据稀疏问题,而第三代模型主要解决冷启动及准确推荐问题。
本研究所提方法本质是解决推荐准确率低和冷启动问题。杨志等[3]提出了一种间接交互与因式分解相融合的推荐方法,解决模型训练时间过长的问题。该方法为第二代推荐模型的最新研究,其基本思路借鉴了因子分解机(FM)[4]及协同过滤(CF)[5]模型,在训练时间上快于图注意力推荐网络(KGAT)模型。不同于传统研究(第一和第二代推荐模型),前沿方法不仅强调图谱信息的准确表述与挖掘,同时也注重对推荐过程的准确描述。Wang等[6]等提出的KGAT模型为相关领域在解决推荐过程准确表述问题上的前沿研究。
基于嵌入学习或网络表述学习的知识图谱表述及学习方法由于其轻便及节点不固定的特性受到了研究人员的青睐。Bordes等[7]提出了TransE分数策略模型,而后在推荐领域不断演进出了TransD、TransH、TransR[8- 10]。同样,在链接预测领域TransE的演进模型RotatE[11]也有不俗的表现。这里,本文所提的极化关系表述学习模型受RotatE和TransH的启发,通过酉空间特性[12]对节点间的关系进行表述,不仅考虑节点间的关系在实数域的表达,同时也充分利用其复数域。通过准确的模型表示,知识图谱中的有效信息可以得到更加充分的挖掘,从而使该过程获得更多的有效信息。
目前,实现利用知识图谱实现准确推荐的方法大致可以分为两种,一是在推荐过程中增加有效信息,PMN[13]、ATBRG[14]等算法都采用这一思路;二是减少推荐过程中的无效信息,但这一方法往往会和其他方法结合,如协同滤波[5]中就将滤波网络和特征机结合;同时类似DLALSTM[15]这类通过注意力学习的方式亦可粗略地看作是一种减少无效信息的方法。充分考虑低维信息是一种增加有效信息的方法,Rendle[4]就提出了FM模型解决低维信息挖掘不充分问题,但是该方法却不能很好的适用于图网络推荐场景。所以Zhang等[16]提出了一种多任务学习的方式解决上述问题,但是该方法却没能充分考虑知识图谱中的结构及属性信息。 Wang等[6]在2019年提出的KGAT模型能够高效地挖掘知识图谱中的结构有效信息,但是却没有对推荐过程中的低维数据信息以及节点关系信息进行进一步的挖掘,使得上述算法预测指标均未能到达一个最优值。
为了解决上述问题,本研究提出了一种融合了知识图谱中结构信息以及推荐过程中的低维交互信息的推荐模型,使得推荐中低维信息及图谱中有效结构信息得到充分的挖掘,进而提高了推荐准确率。首先本文采用了KGAT的基本算法结构,与其不同的是本研究提出了一种基于极化关系的图网络表述方式,而非沿用TransH策略。该方法解决了知识图谱中节点间关系表述不充分而导致的推荐不准确问题。同时为了学习推荐过程中的低维信息,本研究增加并改进了一种图谱与低维推荐数据间的交互学习方式,同时提出了相应的分数策略,并且设计了相关损失函数。该过程有效挖掘了知识图谱及推荐过程中的低维信息,在Recall、NDCG等常见的推荐指标下较传统方法展现出了良好的性能。
1 基于极化关系表述与数据间关联学习的推荐方法设计
本研究定义的极化关系表述是一种嵌入的知识图谱表述方式,指的是嵌入向量在酉空间上的映射,使其在物理空间上能够更明显地区分。同时,本研究对知识图谱和推荐数据进行关联学习,进而挖掘推荐过程中的低维有效信息,以提升推荐准确率。
图1示出了基于极化关系表述与数据关联学习的算法过程。其中知识图谱学习是指对图中信息进行挖掘,并对其中节点间关系进行表述学习的过程。节点聚合方法采用GraphSage[17]模型,该模型能够对图网络中的用户和商品进行数学描述。推荐学习是一种得到用户与商品间关联特征的方法。交互指的是聚合节点与推荐过程中上一状态的信息交互及融合过程。
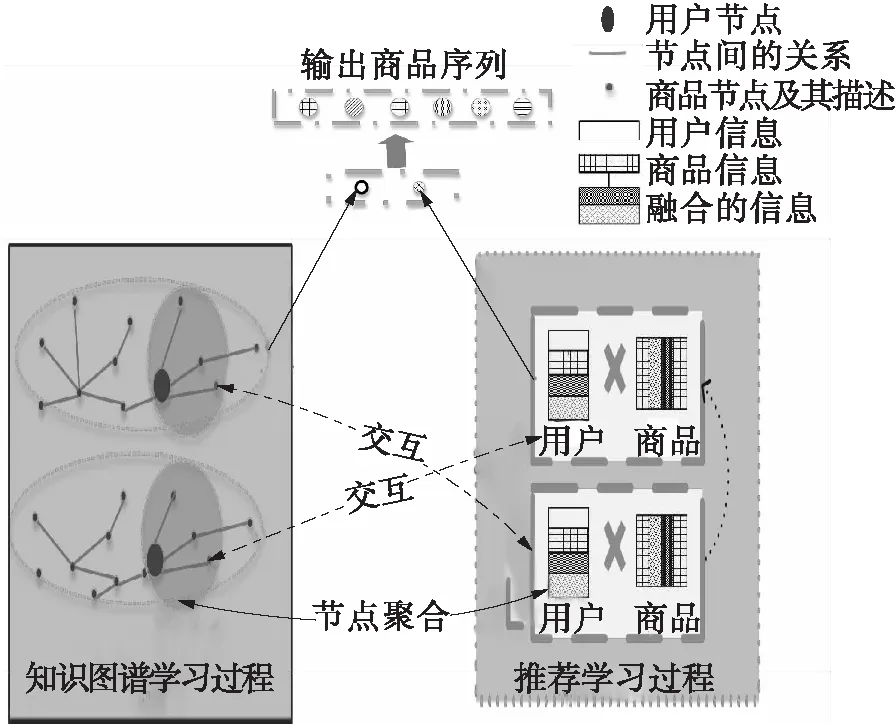
图1 基于极化关系表述与数据关联学习的算法过程Fig.1 Process of learning algorithm based on polarization relation representation and data association
1.1 极化关系表述
考虑到酉空间[12]特性,本研究提出了一种新的极化关系表述方法,它通过酉空间使得节点间的关系在物理空间上更易于区分,使节点间关系得到更准确的区分与刻画。与TransH[9]相比进一步利用了酉空间特性,丰富了关系表述中的有效信息量,与RotatE[11]相比,本研究提出的方法能够更好地凸显节点间高阶数据特性,使其能更加有效适应于知识图谱推荐中。
1.1.1 极化关系表述的可行性分析
基于知识图谱的推荐系统一般是异构网络,即头节点h和尾节点t所代表的实体是不一样的,故h和t可相互转换。在建模过程中通常将h代表用户,h代表商品。当采用TransH时,由于向量的方向性以及高维映射的结果,使其能够很好地凸显h和t的不同,但在较大的知识图谱中由于采用向量相减的形式,使得节点间的关系在映射空间上很难被准确区分。而RotatE的实现则依靠h和t的相互转换,其比较适合于同构图。本研究提出的方法结合上述优点,引入复数空间,使得即使采用向量相减的分数策略,也能通过角度特征对节点间的关系加以区分,使得其表述得更加准确。由此可得图2,即3种表述方式在物理空间上的对比。
1.1.2 节点关系组极化过程
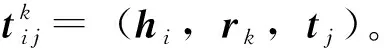
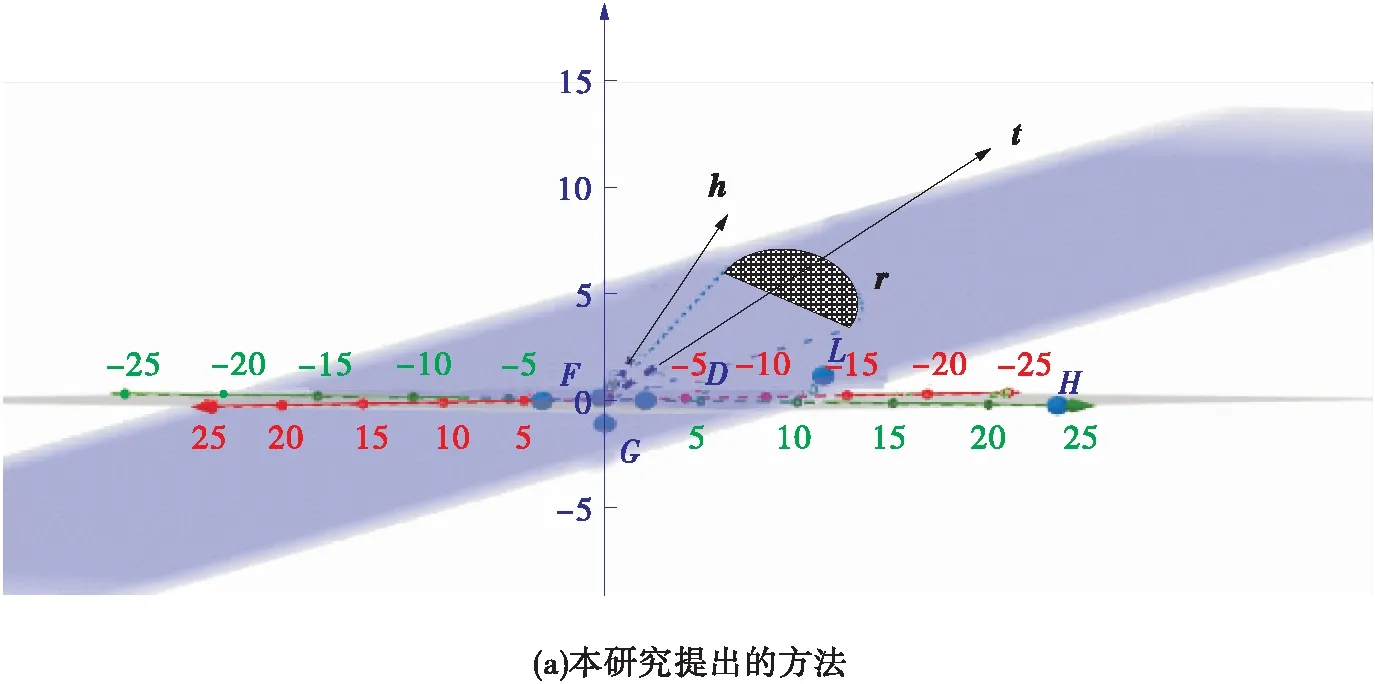
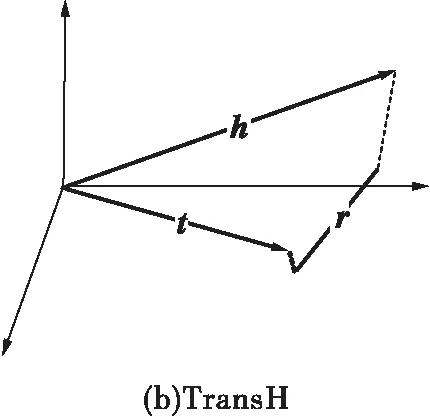
图2 极化关系的三维空间表示及对比Fig.2 Representation of polarization relations with three dimension and comparison with others
输入:ζ={(e1,r1,2,e2),(e1,r1,3,e3),…,(ei,ri, j,ek)}
输出:极化后的h、r、t
定义变量和常量:
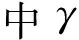
定义极化函数:
fori= 1,2,…,k;j=1,2,…,kandj!=ido
hi=Ρ(ei)
ti=Ρ(ej)
ri=Ρ(rij)
Ω={(h1,r1,t2),(h1,r2,t3),...,(hi,ri,tk)}
end for
Return
Ω
其中Ω是(头节点,关系,尾结点)三元组合的集合。参考[11]将ε和ω分别设置为24、2.0。
1.1.3 基于极化关系表述的分数策略
极化的目的是得到具有酉空间特性的向量表述,为了学习节点间的关系特性,在关系学习过程中采用分数策略来对节点间的关系进行描述。这里本研究定义了节点间的权重矩阵W,其可以理解为用高维特征表示节点,然后通过映射将低维信息进行表示,该过程降低了不必要升维而引起的计算量的增加。极化后节点间关系的分数策略如下:
ζ=‖WCeiθh-eiθr+WCeiθt‖
(1)
其中,C为向量模长,eiθh、eiθr、eiθt分别表示h、r、t的复数形式,且有
eiθ=sinθ+icosθ
(2)
这里i为复数。
1.2 低维数据间的关联学习方法设计
引入知识图谱,能够深度挖掘数据中的非欧式特征。但往往知识图谱所提取信息中并不包含推荐过程中完备的低维信息。本研究借鉴Zhang等[16]提出的低维数据间关联学习方法,通过在图谱与推荐间建立一个分数策略使图与推荐数据产生关联,然后通过本研究定义的策略进行关联学习。本方法改进了图谱与推荐过程的数据交互学习方式,解决了基于知识图谱的推荐方法中低维信息挖掘不充分的问题;同时,采用KGAT中的方法,聚合学习知识图谱中节点间的结构及属性信息,最后将交互信息、用户信息、商品信息、知识图谱信息进行融合,得到一个更加准确的预测表述模型。该过程尽可能多地增加推荐过程的有效信息,进而加速了推荐过程的启动,并提高了推荐准确率。
本研究定义了推荐用户集U={u1,u2,…,uk};以及商品集I={i1,i2,…ij},其中用户及商品节点u和i与图谱中节点e存在对应关系。为使推荐数据与图谱数据更好的区分,本文定义了一个图谱S=(eu,et,r),其中eh指的是图谱中的用户节点;商品及其描述节点包含于et即ei∈et,r指的是图谱中各个节点间的关系。
1.2.1 用户节点特征聚合
为了解决图谱信息挖掘不充分的问题,本研究采用了KGAT[6]对节点信息的学习方法,通过对用户节点和商品节点的聚合学习,有效地挖掘用户节点和商品节点中的结构和属性信息,从而对其进行准确的刻画,进而为推荐过程提供更多的图谱有效信息,表达式如下:
yg=σ(W1(e+ek))+σ(W2(e·ek))
(3)
(4)
(5)
(6)
(7)
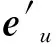
1.2.2 推荐过程

(8)
eu+1=κ*WVV+κT*WEV
(9)
ei+1=κ*WVE+κT*WEE
(10)
其中:κ表示两个嵌入向量的乘积;{eu,ei}∈e,e表示节点的集合,包括用户节点和商品节点;V表示u分量;E表示i分量。为了更好地将节点间的信息进行交互学习,本文设计了如下策略:
(11)
(12)

在低维数据间关联学习中,本方法融合了知识图谱中的结构信息和属性信息以及推荐过程中的低维信息,使得该过程有效信息得到进一步丰富。推荐表达式如下:
(13)
其中,σ为Sigmoid函数,f为内积函数。
1.2.3 损失函数的设计
本方法由两个部分组成,即图谱学习和推荐过程。这里本方法的损失设计对应算法过程的组成分为两部分,即图损失和推荐损失,表达式如下:
(1-yui(u,i+))lg (1-yui(u,i+))
(14)
(15)
α=α+β
(16)
其中,α表示推荐损失,i+和i-分别表示正负样本,σ是Sigmoid函数。β表示交互损失,由正负样本数据得到
θ=‖∑φ(-(ξ--ξ+))‖
(17)
其中:θ表示基于知识图谱的损失;ξ-、ξ+分别表示正负样本的值;φ表示Softplus损失函数,表示权重值。由上可得总损失值:
Γ=Wweight1*α+Wweight2*θ
(18)
2 实验结果及分析
本实验采用容天超算服务器SCS4850完成,硬件上采用GTX1080显卡进行运算,软件上采用Ubuntu18.04系统,并采用Python3.6进行开发,采用开发框架Tensorflow1.12.0完成相关实验。
2.1 实验数据集及参数设置
本次实验采用Amazon-book、Last-FM数据集完成相关实验,具体的数据集参数见表1。

表1 数据集基本信息Table 1 Basic information of datasets
其中Amazon-book是亚马逊书城的购买记录数据,采用该数据的原因为:该数据集具有足够多的用户节点和商品节点以及商品描述信息,该数据集是以商品为中心的,并具有节点间数据特性,在现实中有比较多的应用场景。Last-FM是其APP统计出来的用户音乐播放数据,采用该数据集能模拟线上商城的推荐方式。
2.2 实验结果及分析
由于本方法主要在解决冷启动推荐下实现准确推荐的问题。故本实验主要围绕相同数据集下相关研究是否能够提升推荐启动速度或收敛速度,以及是否能够提升推荐准确率两个问题进行论证分析。本实验由算法整体性能、极化关系有效性、低维数据间的关联学习有效性等3部分分析构成。本实验采用召回率和归一化累积增益作为算法衡量指标。同时本实验所采用的指标都是在@20(即输出20个商品,正确结果在其中的概率)的基础上得出的。除了上述指标外,本实验还在图表分析中引入了Hits@20(输出20个预测结果,正确结果在其中的概率)以及精准率等指标来对本方法进行评价。同时,为了进一步论证本方法在解决冷启动问题上的有效性,本实验还将对训练过程中的损失值进行对比分析。实验结果及对比见表2。
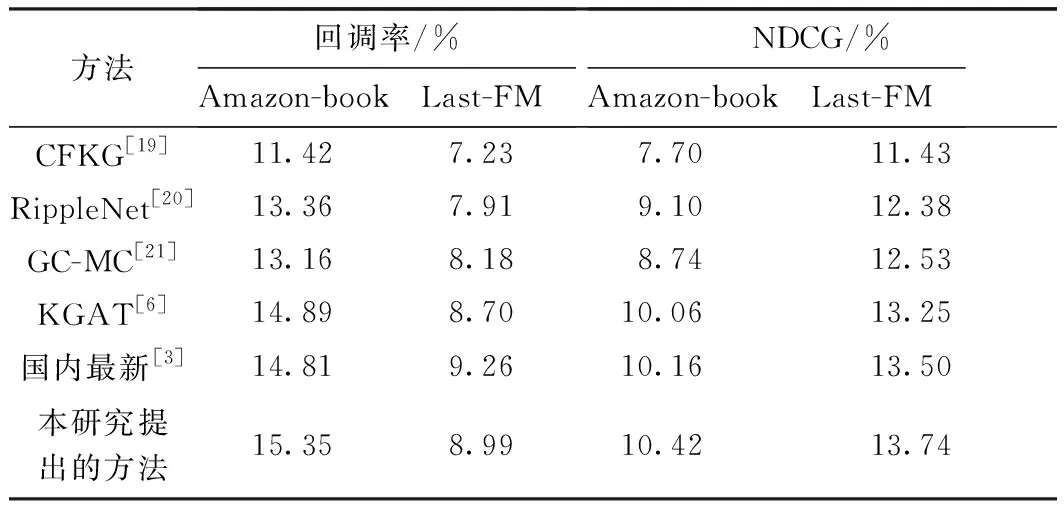
表2 实验结果整体性对比Table 2 Overall comparison of experimental results
2.2.1 算法整体性能分析
由于杨志等[3]主要在解决相关模型训练时间长的问题,而非本文所要解决的冷启动及推荐准确率提升问题,故在本研究中将主要以表2中KGAT模型为参照进行实验分析。由表2可知,本方法在Amazon-book、Last-FM两个数据集中的回调率和NDCG指标相比近些年提出的同类算法均有明显提升。其中在Amazon-book中的回调率较KGAT的提升了3.09%,NDCG较其提升了3.58%。同时,在Last-FM数据集中,本研究提出的方法较KGAT在回调率、NDCG上分别提升了3.33%和3.70%。在Amazon-book这类节点多、关系复杂、商品数与用户数的比值相对小的数据集中有明显的提升,特别地在NDCG值的提升上达到了3.58%。在Last-FM数据集中,本研究提出的方法NDCG提升明显,故本方法相对于商品节点与用户节点比值较大的数据集,其推荐准确率有明显的提升效果。
为验证上述分析,本研究采用图3、图4对上述过程进行了进一步验证分析。图中,每个训练批次有1 024条数据,回调率为每20次回调数/总次数,精准度为每20次中准确预测数/总次数,链接搜索率为每20次响应总数/总次数,归一化折损增益为每20次增益总值/总次数。由图可得,本方法在各项指标上均明显优于KGAT算法。在第100批次后,由于对数据间的低维信息进行了挖掘,本方法在后续的训练中一直表现出了缓慢上升的态势。即使采用了动量优化,训练过程在第400个批次时仍未停止。由此可得,本研究提出的方法在上述实验过程中受数据量的限制,所得实验指标未达到最优值。为了证明本方法在Last-FM数据集的稳定性及有效性,采用损失值与KGAT进行对比,结果如图4所示(由于起始批次损失值过大,这里的取值起点为第2个批次)。本方法的损失收敛速度明显快于对标,同时,在收敛值上也明显优于对标。综上可得,本研究提出的方法能有效地提升推荐准确度和获得更快的收敛速度,特别是在节点多、数据量大的知识图谱中。即本方法与相关领域前沿研究相比,具有更快的启动速度同时能够实现更准确的推荐。
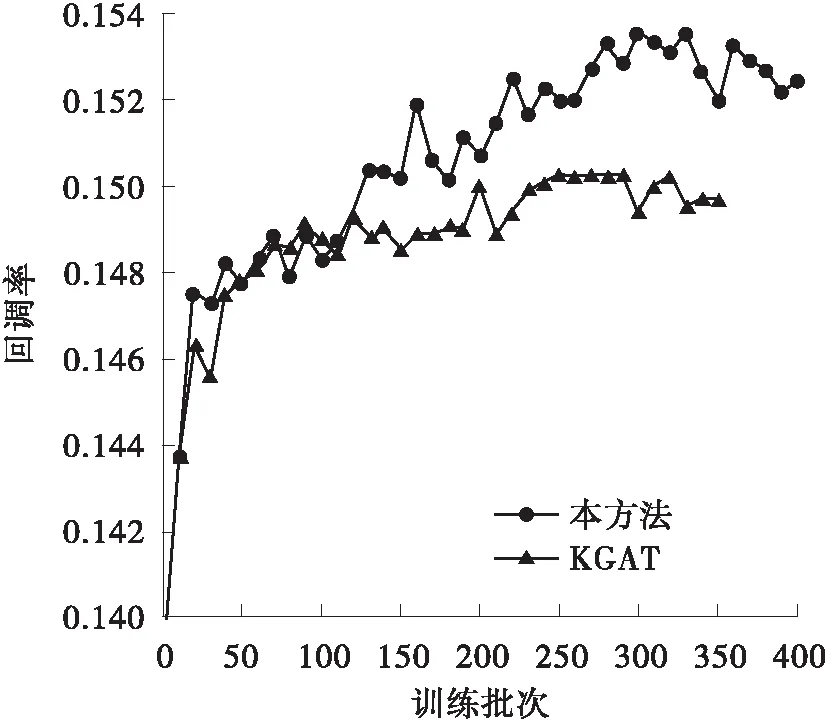
(a)回调率对比
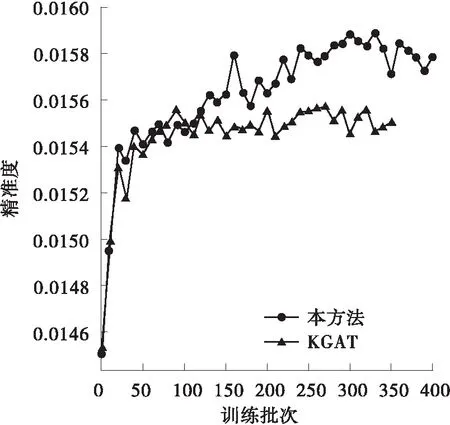
(b)精准度对比
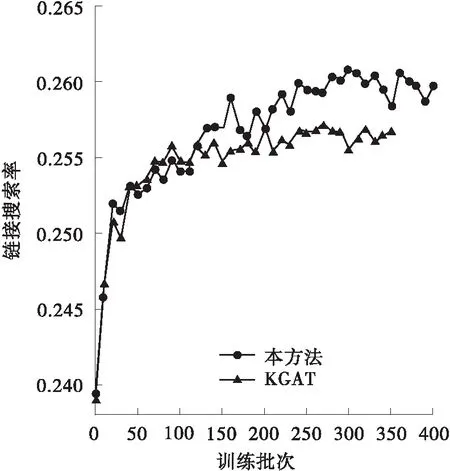
(c)链接搜索率对比

(d)归一化折损增益对比图3 在Amazon-book数据集中本方法与KGAT的对比Fig.3 Comparison of the proposed method with KGAT in Amazon-book datasets
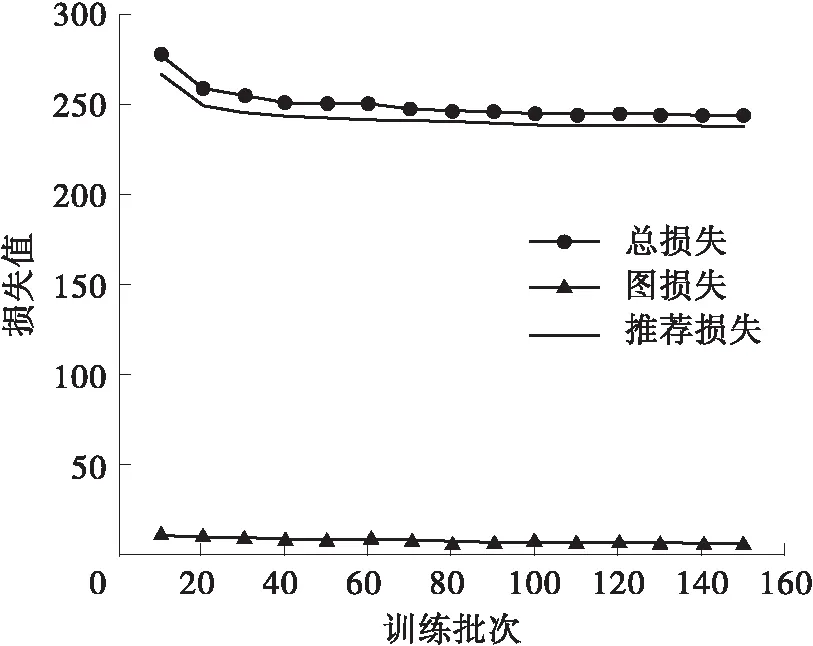
(a)Amazon-book中KGAT的损失值
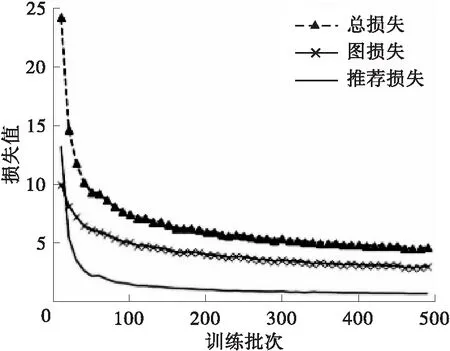
(b)Amazon-book中本方法的损失值

(c)Last-FM中KGAT的损失值
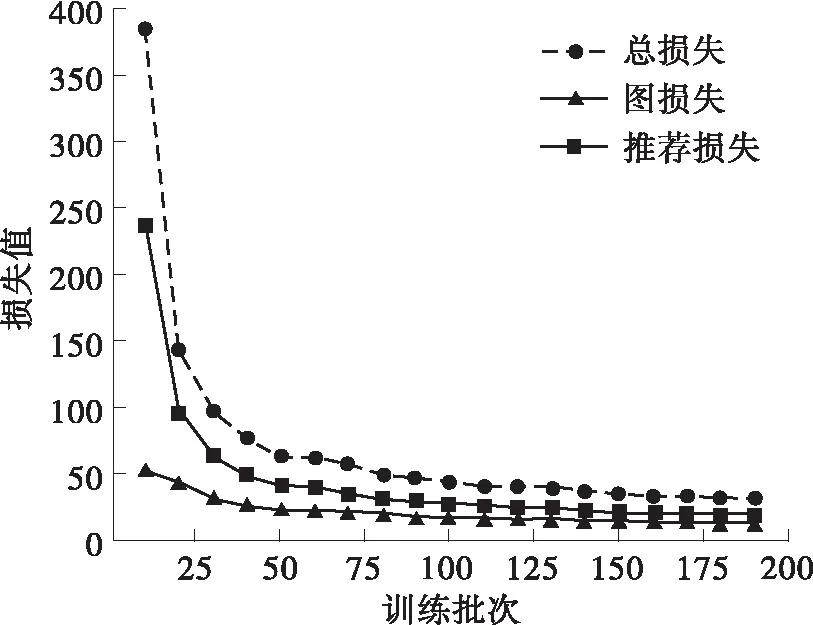
(d)Last-FM中本方法的损失值图4 在Amazon-book和Last-FM数据集中本方法的损失值与KGAT的对比Fig.4 Comparison of the loss value between the proposed me-thod and KGAT in Amazon book and Last-FM datasets
2.2.2 极化关系表述的有效性分析
为验证本研究提出的极化关系表述方法的有效性,将KGAT中的TransH分数策略换成本研究提出的极化表达方法,并与之进行了对比及分析。如表3所示,本研究提出的方法在Amazon-book、Last-FM两个数据集中的回调率、NDCG均明显优于对标。为了更好地进行对比和分析,本研究取了120批次以前的数据进行分析,这样可以更加清晰明了地将本方法与KGAT的实验特性展现,如图5所示。由图可得,本方法在各项指标的表现上均优于KGAT中采用TransH时的表现,且具有较快的收敛速度。同时也可以看出,本方法在Last-FM这个节点相对少且关系少的数据集中表现并不明显。其可能的原因是,在该数据集中原有的TransH策略已经能够基本准确地表述该图谱。综上可得,本研究提出的极化关系表述方法是有效的,特别是在节点多、关系多的数据集中。

表3 本方法的极化关系表述与KGAT的对比Table 3 Comparison of polarization relation representation of the proposed method with KGAT
2.2.3 低维数据关联学习有效性分析
为了验证本研究提出的低维数据间的关联学习方法的有效性,在不采用极化关系表述方法的情况下,将本方法与KGAT进行了对比,结果如表4及图5所示。值得注意的是,在Amazon-book及Last-FM数据集中虽然本方法在回调率及NDCG指标上没取得明显的优势,但其收敛速度明显高于对标。由此可得,采用低维数据关联学习方法在提升收敛速度上是有效的。同时,当单独采用该方法时虽然没有提升实验准确性,但由整体性分析可得,本方法在结合极化关系表述后,其推荐准确率相比采用上述表述方法时的回调率和NDCG有明显的提升。

表4 本方法的低维数据关联学习与KGAT对比Table 4 Comparison of low-dimension data association learning of the proposed method compared with KGAT
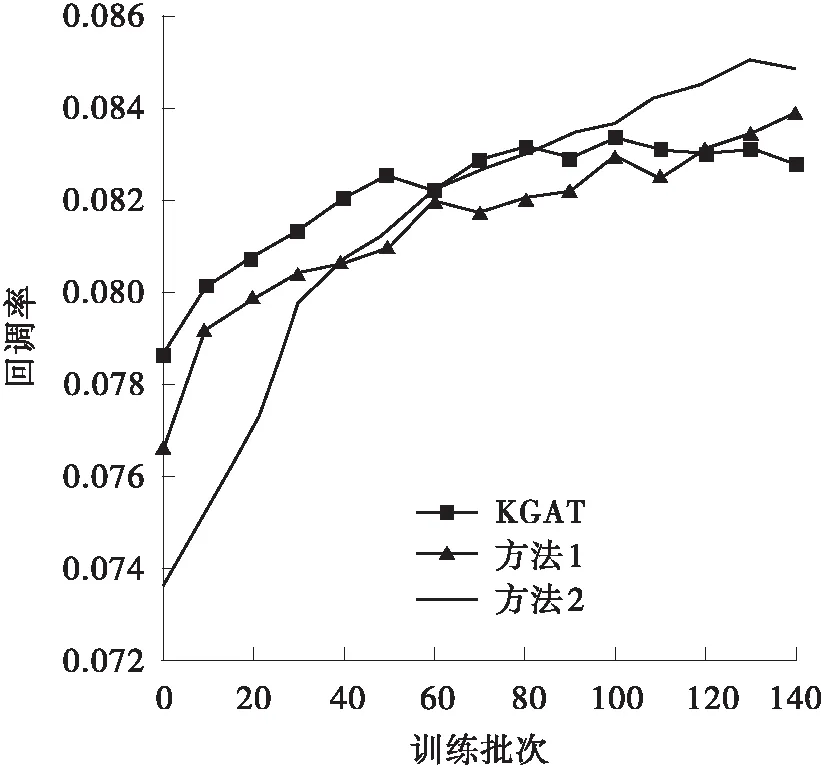
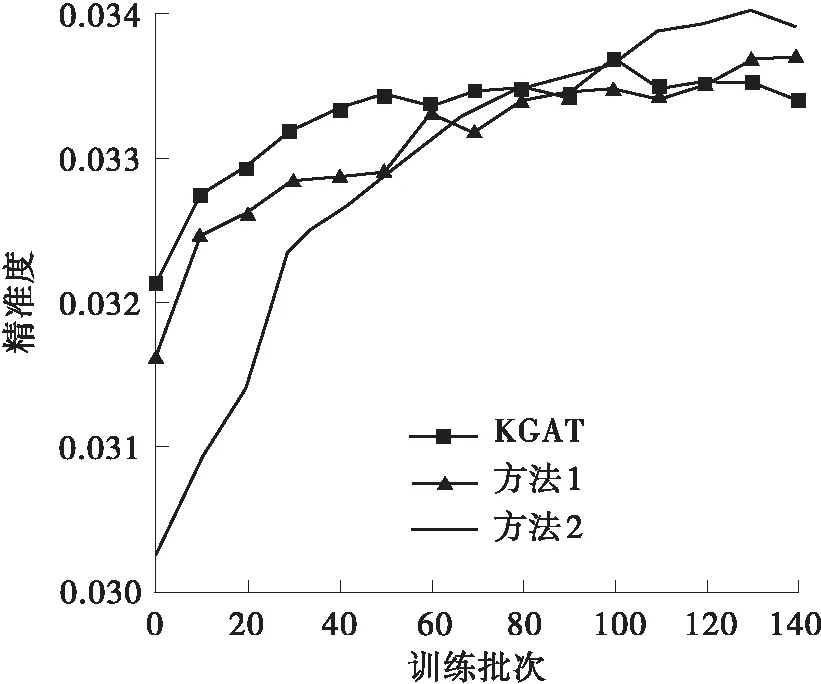

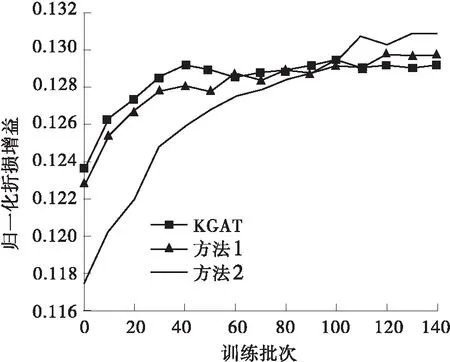
(a)Amazon-book中的对比试验

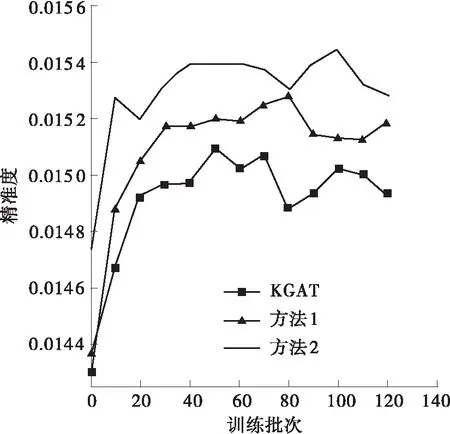

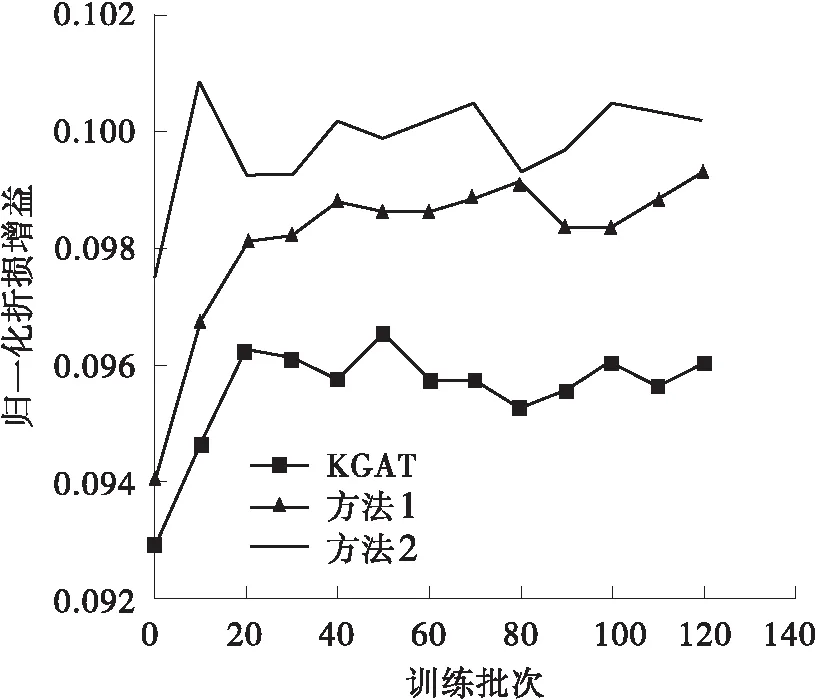
(b)Last-FM中的对比试验图5 以KGAT为参照在Amazon-book及Last-FM数据集上的对比试验Fig.5 Comparative experiments in Amazon-book and Last-FM datasets with KGAT as the reference
同样值得注意的是,图5中的数据为本文对KGAT复现所得结果,实验所得数据由于软硬件及参数原因可能并未达到最优值。故在对比实验中,本研究提出的低维数据关联学习方法在两个数据集中的回调率、NDCG均优于对标。
3 结语
实验结果与分析表明,本研究提出的基于极化关系表述与低维数据关联学习推荐方法是有效的,特别是在Amazon-book这类用户节点数与商品数比值大的数据集上。由于对节点间的关系更丰富的表述并挖掘了低维推荐信息,使得其准确率有着明显的提升。但在研究过程中观察到本方法在节点、关系多的数据中,由于相对数据量不足、有效信息挖掘不充分等原因,其推荐准确率还有待提升。所以为了提升推荐准确率,降低用户消费记录、知识图谱数、用户及商品数量大小等因素对推荐的影响。在后续研究中可以考虑解决知识图谱不完备而导致其有效信息未充分被挖掘,进而引起的推荐不准确问题。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
导航定位学报(2022年4期)2022-08-15
民族文汇(2022年23期)2022-06-10
航天电子对抗(2022年2期)2022-05-24
现代电子技术(2022年4期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
计算机应用与软件(2021年10期)2021-10-15
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
智富时代(2018年5期)2018-07-18
