
RDMA高速网络状态感知与度量指标体系研究
2022-02-19 10:23徐佳玮
计算机应用与软件 2022年2期
徐佳玮 严 明 吴 杰
(复旦大学计算机科学技术学院 上海 200433)(复旦大学教育部网络信息安全审计与监控工程研究中心 上海 200433)
0 引 言
近几年来,数据呈爆炸式增长。根据国际超级计算机500强排名的数据,基于TCP/IP的传统以太网是世界排名前500中最流行的互联方式,随着40 Gbit/s乃至100 Gbit/s网卡的出现,远程直接内存访问(Remote direct memory access,RDMA)技术已经在世界顶级超级计算领域独领风骚[1],成为目前主流的高性能计算机互连技术之一。RDMA技术将数据直接从一台计算机的内存传输到另一台计算机,它核心在于将网络层和传输层下移到服务器的硬件网卡中,使得数据报文在网卡上完成四层解析后直接到达应用层软件而无须CPU的干预。与传统基于TCP/IP协议的网络相比,RDMA网络通过将大多网络功能卸载到物理网卡上、绕开操作系统内核、零拷贝技术实现在提高吞吐量的同时降低时延和CPU占用率。
RDMA技术最早出现在IB(Infiniband)网络中,用于高性能计算集群的互联,后来业界厂商把RDMA移植到传统以太网上,推动了RDMA技术的普及,这样RDMA得以部署在目前使用最广泛的数据中心网络上。在以太网上RDMA又根据协议栈的不同,分为RoCE(RDMA over Converged Ethernet)和iWARP(RDMA over TCP/IP)两种技术。根据相关的性能测试,RoCE相对于iWARP吞吐量更高、时延更低[2]。RoCE分为RoCE v1版本和RoCE v2版本,RoCE v2相对于v1来说支持了IP路由,因此现在RoCE网卡大多使用RoCE v2版本。随着数据中心网络转发数据的增大,许多数据中心都在利用RoCE来加速网络传输。现在许多的框架、人工智能分布式模型训练场景、主流的数据库系统、并行存储文件系统的应用中,也广泛使用了RDMA技术[3-4]。另外,随着应用部署的复杂性增大,当出现故障时,非硬件故障性的网络问题不容易轻易复现,因此数据中心非常需要对RoCE网络进行实时度量。
然而,目前业界在针对RoCE网络的状态感知监控方案和TCP网络相比还不成熟,度量指标体系不够完善。首先,现有对RoCE网络的度量更多地是以依靠在本地网卡软件抓包之后离线分析或用昂贵的硬件设备分析为主,缺少针对RoCE深入到应用层业务流的基于软件实时状态感知系统。其次,从度量指标而言,目前RDMA还没有成熟的多维度、多层次、完善的指标体系,RoCE厂商只给出了系统上硬件统计故障诊断信息,从单节点角度,凭借现有的网卡错误项的累计值不足以了解RDMA网络状态和定位问题。另外,根据实验测试结果,采用本地抓包之后离线分析的方式,会对网卡的最大传输性能造成一定损耗。如图1的测试结果所示,若在服务器节点本地用tcpdump之类的开源工具进行流量捕获从而离线分析的方法,随着消息长度不断增大,当消息大小在256字节以上时,本地抓包使得单网卡的最大传输性能下降了10%~47%。且对于多节点的离线分析,需要汇总分析结果,二次分析的分析工作复杂。
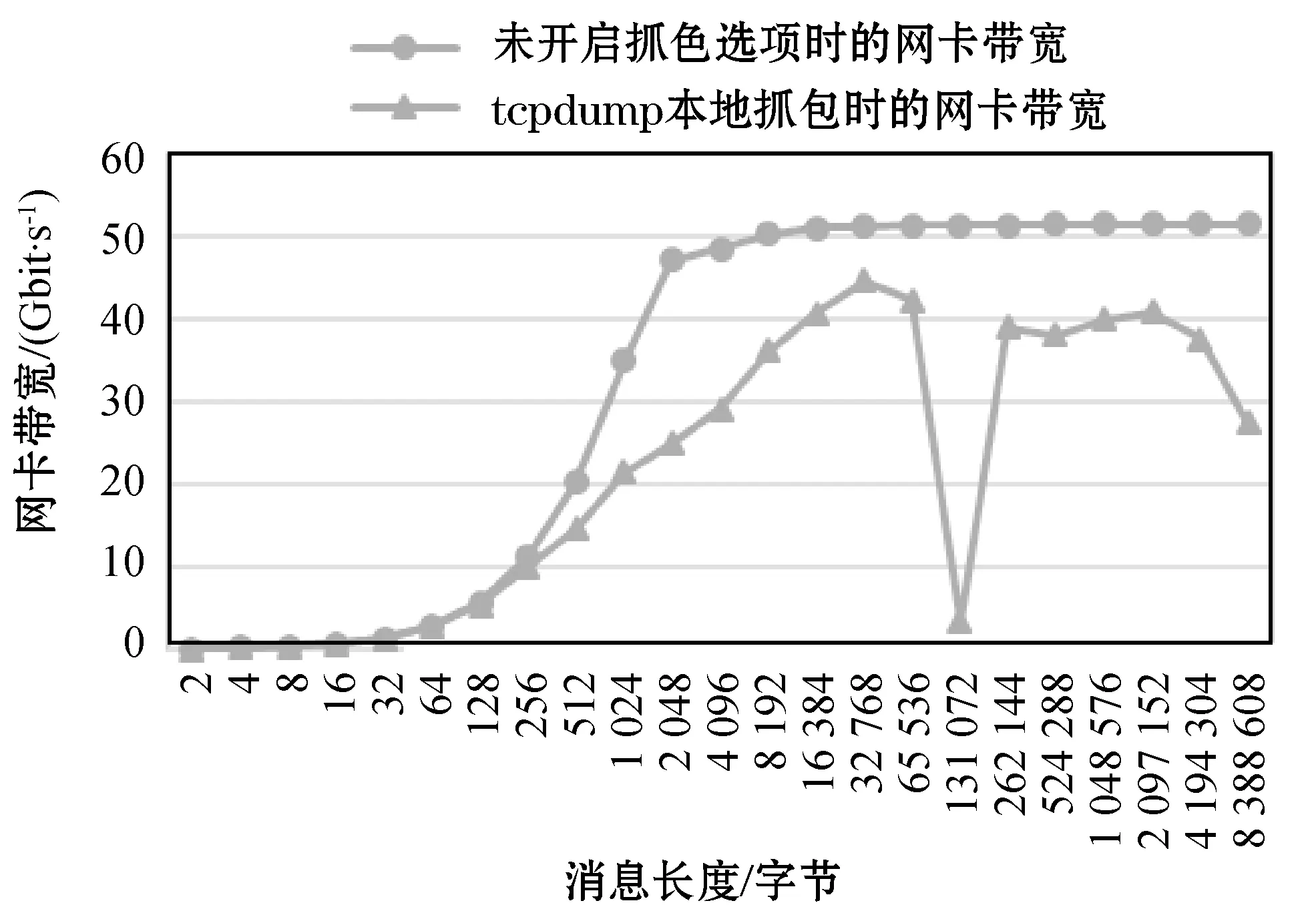
图1 未开启抓包选项和tcpdump抓包时的网卡带宽对比
传统以太网对TCP流的分析可以帮助数据中心网络管理员优化网络管理,类似地,对RoCE网络进行类似业务流的分析也可以对网络中系统的服务调用和数据传输的流量分布有进一步的认识。随着RoCE的普及,对数据包的进一步分析是很有必要的。对传输类型以及基于流等方面的统计度量,有利于进一步研究流控机制、拥塞控制、优化资源调度,也有助于数据中心的网络管理员了解网络情况,进行故障定位和网络规划,有助于指导应用服务的研发人员优化和加速应用。
针对上述问题,本文设计了一种基于软件的RDMA网络状态感知与度量系统并针对RoCE网络进行实现和实验评估。本文的主要贡献如下:
(1) 提出了一个多角度、多维度、多层次的RoCE网络指标度量体系,全方位分析网络状态,弥补了现有工作只有硬件统计的错误累积数据、缺失应用层和业务流方面指标而无法全方位感知网络状态的不足;
(2) 设计了一种基于软件的RDMA实时网络状态感知和度量系统,采取旁路分布式捕获流量的方式并同时采用Sketch流抽样算法对RDMA的业务流进一步分析,成本低,易于部署,可扩展性和灵活性高,且对原传输节点的影响较小;
(3) 针对RoCE网络实现并模拟网络场景进行实验评估,实验结果显示,本文系统能够在较低的误差范围对RoCE网络进行客观的度量,从多角度展现网络状态和问题,能够对数据中心的故障定位和应用服务调度提供一定指导。
1 相关工作
目前工业界和学术界针对RDMA的度量主要有三种类型,分别是基于硬件的流量捕获抓包方式、基于软件的流量捕获离线分析方式及针对链路的带宽时延基准性能测试工具。
文献[5]介绍了ibdump,它是Mellanox公司官方提供的OFED驱动的一个抓包组件,其缺陷是当流量速率很高时会丢包,只适用于Mellanox的硬件设备,只能作为软件运行在传输节点上,它的最大捕获能力依赖于主机上的RAM或者磁盘空间,且随着流量增大会发生无意识无规律的丢包。另外,根据Mellanox最新的OFED驱动文档,ibdump仅支持Connect-X3和Connect-X3 Pro[6],不支持之后的网卡版本。ibdump只具有抓包功能,而不具有任何流量分析的功能。
文献[7]的CatC是LecCroy公司的一个硬件分析器。它在部署时必须串联在一条IB链路中,部署繁琐,价格昂贵,并且它抓包存储下来的.ibt文件只能通过本公司的专用IBTracer软件打开,此外CatC只适用于SDR (8 Gbit/s) 的速率且只有2 GB的存储容量。
文献[8]的tcpdump是一个常用的流式网络数据采集分析工具,从OFED3.2版本、Connect-X4网卡开始,配合libpcap 1.9.0-lp150.76.3[9]及以上版本,tcpdump可以支持捕获RDMA数据包[10],它对截获的数据并没有进行彻底解码,更适合使用简单的过滤规则保存到文件中,然后再使用其他程序进行离线解码分析。tcpdump在大流量下受性能和存储容量的影响不适合长期在线实时监测。
文献[11]的Perftest和文献[12]的qperf是用于各种RDMA通讯类型的性能测试应用程序。Perftest是Mellanox OFED驱动中的基准测试程序包,可以用于调优和功能测试。qperf由Linux操作系统默认自带,以用来测试两个节点之间的带宽和延迟,可以用来测试RDMA传输的指标。它们都是基于单点的链路角度的测量带宽时延的工具,不涉及对业务数据流的度量。
现有关于RoCE度量的研究工作和工具,在基于硬件的流量捕获方面,虽然在性能和精度方面较有优势,但是部署时需要在链路中部署专用硬件,成本较高,灵活性不强;在基于软件的RoCE流量度量方面,厂商自产的抓包工具只有抓包功能,开源的抓包分析工具对业务维度方面没有进一步的统计,只有简单的带宽时延测试,缺乏业务数据的分析。并且,基于软件的工具在传输节点上捕获流量时需要开启RoCE网卡的sniffer模式,这会带来性能损失[13],影响原本的传输性能。另外,在RDMA度量体系来讲,RoCE厂商除了一些基于硬件上统计信息外,并不关注传输内容和事务本身,RDMA还没有完善的度量指标体系。
2 RDMA度量指标体系设计
度量指标体系的层次设计以面向应用业务需求为目的,主要关注应用层的指标,用以指导应用加速优化和网络规划调度,辅以部分网络层面指标和硬件故障统计信息来展示RoCE网络状态,用以指导网络问题和故障定位。
原有厂商提供的硬件统计指标只能从单个物理主机节点角度获得某个RDMA网卡一些错误信息总体的累计统计值,未细分RDMA操作和连接。而当需要进行网络状态感知、服务故障定位,对采用RDMA加速的服务进行优化调度时,单从整体统计值上难以判定具体问题,需要分析RDMA数据包协议内容,结合应用层面的指标一起联合分析。
如图2所示,度量指标体系总体上从网络状态感知和业务应用状态感知两个大层面进行划分。网络状态感知层包括针对节点可用性、连接可用性、网络负载状态。业务状态感知层包括针对RDMA操作相关的指标和基于业务流的分析指标。各层次之后从表征的网络模型角度再向下细分,分为链路层、系统层、网络层、应用层。所有单项指标从指标意义角度,分为运行状态指标和负指标。运行状态指标指的是除负指标这类关于软硬件错误和故障信息的指标的其他指标。负指标根据方向的不同,又分为作为发送端检测到的和作为接收端检测到的两个角度。

图2 度量指标体系层次图
2.1 节点可用性指标
节点可用性考虑的是针对网络和服务性能下降时,关于RDMA节点方面的状态感知。
(1) 指标内容。节点可用性指标内容如表1所示。
(2) 指标来源。链路层指标通过读取Linux系统下的/sys/class/infiniband/的统计文件获取后计算得出[14],连同系统资源统一在本地收集。
2.2 连接可用性指标
连接可用性指标从网络层数据包角度表征网络状态。
(1) 指标内容。连接可用性指标内容如表2所示。
(2) 指标来源。负指标通过读取Linux系统下的/sys/class/infiniband/的统计文件获取后计算得出。
2.3 网络负载指标
网络负载指标主要针对网络规划和网络拥塞发现两个角度。
(1) 指标内容。网络负载指标内容见表3。
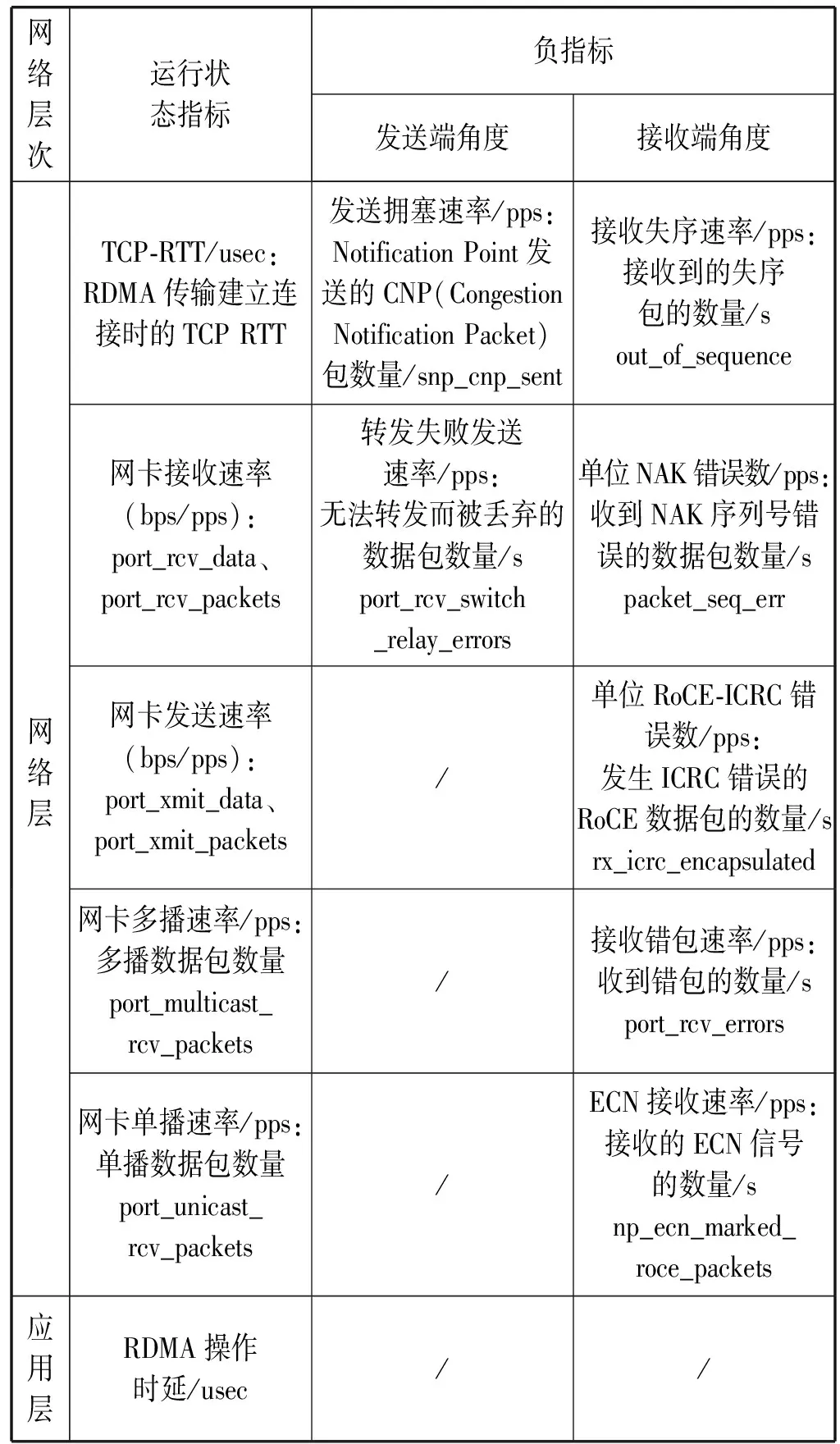
表3 网络负载指标
尽管传统RDMA的应用场景多以高速传输为主,但随着RDMA技术在企业应用服务中的应用,RDMA调用前的连接建立时间对于服务吞吐量也变得尤为重要,因此选用建立RDMA连接的TCP RTT作为指标,计算请求端进行握手时发出SYN包到发送ACK的多个连接的平均值作为该连接的RTT。
(2) 指标来源。RTT通过度量系统进行在线实时分析计算得出, RDMA操作时延通过在节点发送探测包计算得出。其余指标通过读取Linux系统下的/sys/class/infiniband/的统计文件获取后计算得出。
2.4 RDMA操作相关流量指标
RDMA操作相关指标旨在发现网络中各种服务调用中RDMA操作类型的分布,从而了解网络中真正关键操作,发现性能瓶颈,指导基于RDMA的应用的优化方向。RDMA各Opcode类型流量速率、RDMA消息吞吐量、Queue pairs的消耗量可以为研究时延敏感型、吞吐量敏感型、带宽敏感型的应用之间的互相竞争分析提供依据。
(1) 指标内容。RDMA操作相关指标内容见表4。
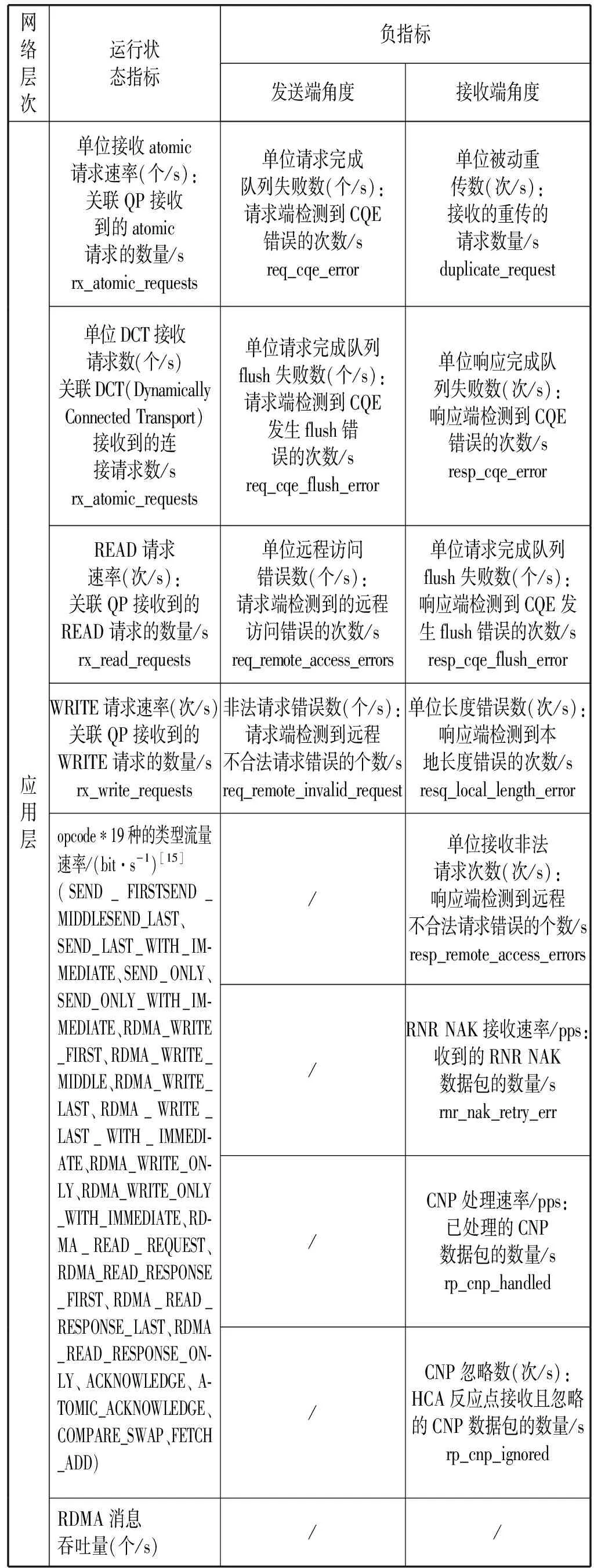
表4 RDMA操作相关指标
(2) 指标来源。负指标通过读取Linux系统下的/sys/class/infiniband/的统计文件获取。
opcode流量速率指标通过度量系统Sketch算法进行在线实时分析计算得出。RDMA消息吞吐量通过系统解析opcode中的“LAST”来标记一条消息的结束,从而统计得出。其余指标通过读取Linux系统下的/sys/class/infiniband/的统计文件获取后计算得出。
本文目前针对RoCE使用最广泛的Mellanox的RoCE v2协议,其支持ConnectX-3 Pro及以上版本的网卡。
如图3所示,RoCE在以太网数据包中封装了IB。RoCE v2(Layer 3)运作在UDP/IPv4或UDP/IPv6之上,采用专用端口4791。

图3 RoCE v2 报文格式[16]
① 操作码(8 bits):该字段表示IBA数据包的类型。例如CNP数据包的操作码是0x81(10000001b),Reliable Connection(RC)-SEND First的操作码是0x00。该字段可以从数据包角度将RDMA的操作类型的统计细化到消息和opcode层面。
② Solicited Event(SE)(1 bit):该字段表示responder方是否应该产生一个事件。
③ Pad Count(PadCnt)(2 bits):该字段表示将多少额外字节添加到有效负载以对齐4字节边界。
④ 传输层报头版本(TVer)(4 bits):该字段表示IBA传输层报头的版本。
⑤ 目的Queue Pair(DestQP)(24 bits):该字段表示了目的方的Work Queue Pair(QP)的序号,例如0x0000d2=210。
⑥ 确认请求(A)(1 bit):该字段用来表示需要responder回复一次确认。
2.5 业务流指标
网络流量测量除了捕获之外需要对流量进一步的解析和分析,从而掌握网络运行状态,提取行为特征。
Queue pairs可以唯一表示RDMA操作,因此定义RDMA的流是同一个Queue pairs的包序列号连续的所有RDMA消息,即SrcQP+DstQP或源IP+目的IP+UDP源端口的消息。RDMA流的大小的定义是一条流在时间窗口内的messages的字节长度总和。在TCP网络中,基于流的分析是很有意义的,本文借鉴TCP网络中的定义,对RDMA流的大小超过配置文件中设定的阈值的RDMA流称为大流,小于阈值的为小流。大流一般对于带宽较为敏感,小流一般对于时延较为敏感。
RDMA流维度的相关指标包括RDMA流总个数、RDMA流速率大小、RDMA大流个数、流抖动率、小流时延。
3 RDMA状态感知度量系统总体架构
系统框架如图4所示,系统总体分为度量系统和Agent。度量系统运行在网络中独立的一台服务器上,网络流量由交换机镜像口镜像,可经过分流器分流,连接到多个度量系统所在的服务器上,捕获流量的网卡是以太网网卡。部署环境要求在被镜像出的流量在进入服务器之前的链路不发生丢包且不存在重复流量。
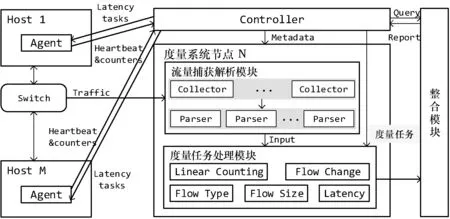
图4 系统架构图
度量系统主要负责流量的旁路捕获和分析。Agent作为度量系统的信息收集辅助工具运行在每个RDMA传输节点上,主要负责监听传输节点的硬件网卡自带的网卡、端口统计,辅助探测链路的时延,并发送给Controller,对本地节点的影响很小。对于需要测量时延的节点,Controller将指令发送给其上的Agent,之后Agent发送探测数据包得到节点之间的时延发送给Controller。
采用旁路分布式全量捕获流量和Agent辅助收集基础信息相结合的方式的优点是实现了在高流量场景下,在减轻观察者效应的同时,可以从网络和应用两个角度,兼顾实现多维度指标的收集。
度量系统从架构上分为控制平面和数据平面。
1) 控制平面。控制平面是Controller控制模块。Controller模块主要负责配置相关元数据信息、添加度量处理任务、进行相关网络状态的查询操作,它还负责和节点上的Agent交互,检测Agent的心跳,接收Agent上报的节点上的RDMA端口、错误信息和时延相关数据。元数据包括服务器网卡IP端口、流处理的任务和类型、统计间隔,以及Agent采集信息的频率和Sketch算法的参数如时间间隔、黑白名单、任务类型、大小流阈值等一系列可配置项。配置文件使用YAML格式进行描述。
2) 数据平面。数据平面分为流量捕获解析模块、度量任务处理模块、整合模块。
(1) 流量捕获解析模块。Collector从网卡中全量捕获流量,Parser根据RDMA协议格式解析数据包各个字段,提取有效信息。服务器每个网卡对应一个Collector,之后由多个Parser并行进行数据包的解析处理。
(2) 度量任务处理模块。根据配置中新建若干度量任务,每个任务都会利用流量捕获解析模块的输出使用不同的Sketch算法进行统计,将统计结果输入到整合模块。
(3) 整合模块。整合模块汇总整合各个分布式度量节点处理的结果,对于某个指标,累计分流到的节点的计算数值,并提供给Controller查询统计值的接口或者输出成离线文件。
4 系统主要功能具体实现
4.1 流量捕获方法
基于硬件的流量捕获方式有精度和性能的优势,但是不易部署且价格昂贵。本文采用软件旁路方式进行分布式流量捕获,采用软件方式比较轻量,可以根据配置和网络情况指定过滤规则,以插件方式添加流量分析处理任务,使得指标显示可组合,分析更加灵活。
流量捕获解析模块中,Collector使用零拷贝技术,根据配置文件全量捕获设定的时间窗口的数据包。度量系统根据流量大小和服务器资源情况可以是一个或多个,当需要处理的流量很大时,可将总流量分成交换机的多个端口镜像再经过分流器基于IP规则、方向、RoCE中的序列号字段过滤出分散的无重复的流量,再输入到分布式度量服务器的多个网卡中并行处理。采用多网卡分布式抓包后整合的方式实时分析流量,整合模块汇总显示各网卡的统计结果。
4.2 RDMA流维度的指标度量方法
在数据中心中,更关注流量的分布和趋势,没有必要使用hash table类型的计数器统计获取非常精确的数值。采用基于概率统计理论的Sketch算法统计RDMA流维度指标虽然会产生一定误差,但是其误差在可以接受的范围之内,足以获取需要的流量分布和趋势特征[17]。此外,sketch的内存占用更小,降低了设备的成本。
如图5所示,度量任务类型根据Controller配置文件下发。流量捕获分析模块采用纯软件方法解析出发送端、接收端、操作码、Queue Pair、数据包大小之后,判断数据包所属的流是否是新流,更新时间窗口内的流总个数和流大小。对于高于一定阈值的大流来讲,判断大流的抖动情况;对于小于一定阈值的流来讲,进一步向Agent发送信号,示意Agent定期发送时延检测数据包,最后Agent将结果返回给Controller。

图5 RDMA流维度度量流程
(1) RDMA流总个数估计。流总数估计任务使用Linear Counting(LC)算法[18]估计一个时间窗口内不同的流的个数。LC算法是一种计数估计算法,假设一个哈希函数结果服从均匀分布,结果空间为{0,1,…,m-1}的m个值。再有一个长度为m的bitmap,每个比特都是初始化为0。对流式数据里每个元素,也就是RDMA流的标识,LC算法先通过哈希函数将标识映射到bitmap的某个比特x上,如果第x个比特为0,那么将第x个比特设置为1。查询时,根据1的个数和比例得到关于RDMA流的总数的估计。
(2) RDMA流大小估计、RDMA opcode大小估计。流大小估计任务和RDMA opcode大小估计任务使用Count-Min(CM)算法[19]获得任意流在某时间窗口内的大小估计值,即RDMA流速率,从而在下一阶段针对不同类型的流进行进一步的分析。CM算法是一种概率数据结构,维护一个长度为i的数组,每个数组对应j个计数器和一个对应的哈希函数,初始化每个计数器为0。面对流式数据里每个新的事件元素,计算每个元素在每个数组中根据哈希得到的值,作为数组的位置索引,然后将数组对应位置索引下的计数器加一。当需要查询某个元素时,返回这个元素在不同数组中计数值的最小值。
根据Controller的配置,判定RDMA流大小大于设定阈值的流为大流,小于设定阈值的流为小流,分情况进行下一步度量。
(3) 大流抖动检测。抖动检测是针对大流,估计在两个相邻的时间窗口内,流的大小变化是否超过一定的阈值。使用与Count-Min类似的数据结构,通过比较两个时间窗口的值的偏差和上一个时间窗口的值的比值,检测流量大小是否发生抖动。
(4) 小流检测。对于网络中大小超过一定阈值的小流,进一步探测传输节点之间的时延。Controller查询当前时间窗口流大小前p小的流对应的传输节点,将信号发送给节点上的Agent,每个Agent都可以当做Server和Client。在下一个时间窗口内,Agent以一定频率连续发送10个时延探测包。在时间窗口结束后,将时延探测平均值返回给Controller。
5 实 验
5.1 物理实验环境
本文使用了四台服务器与一台交换机,实验环境如图6所示,其中三台服务器用于传输数据且部署Agent,另一台服务器用作运行度量系统。
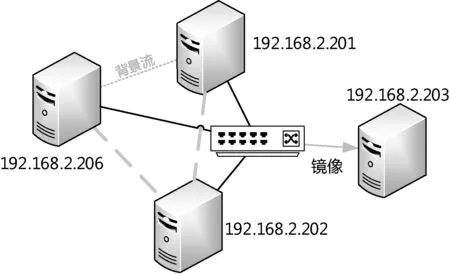
图6 实验环境拓扑图
四台服务器使用RoCE 100G ConnectX-5网卡,服务器系统上安装的网卡OFED驱动版本为MLNX_OFED_LINUX-4.0-2.0.0.1,交换机型号为Mellanox SN2100,服务器具体规格如表5、表6所示。
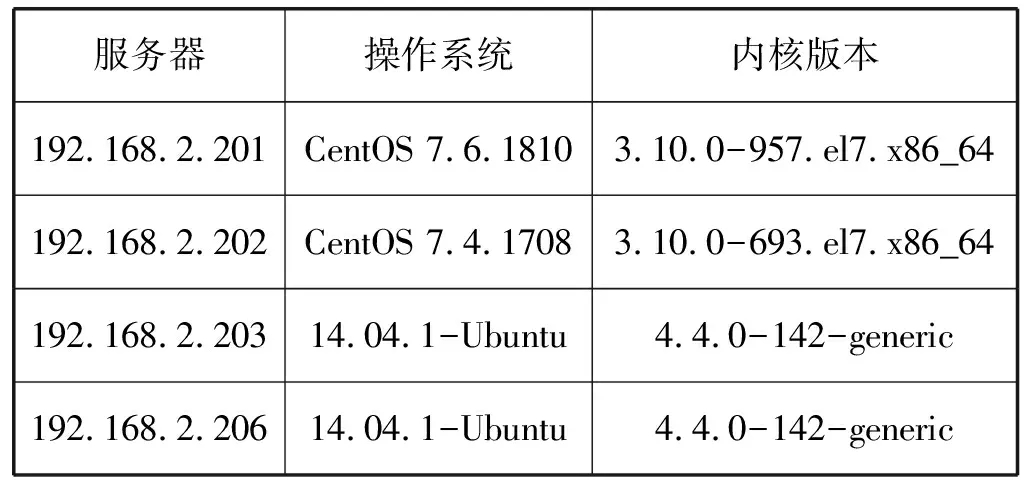
表5 服务器操作系统和内核版本

表6 服务器CPU和内存
传输节点之间使用官方的Perftest基准性能测试工具,以及用RDMA ibverbs标准库函数编写的程序,模拟客户端和服务端发送流量。
5.2 指标验证
本节利用状态感知度量系统指标讨论不同网络状态下的指标特征变化情况。实验过程中,单节点度量系统服务器CPU占用率平均约为64%,Agent对服务器的CPU占用率基本低于2%,对原传输节点的资源影响非常小。
(1) RDMA RC-Write/Send/Read操作时延随流量变化情况。图7显示了单流情况下基于RDMA可靠传输Write/Send/Read操作随流量增长的变化情况,Write操作的操作时延一般性低于Send和Read操作,符合RDMA的特征,并且度量系统分析的结果和通过tcpdump抓包后离线分析呈现同样的结果。
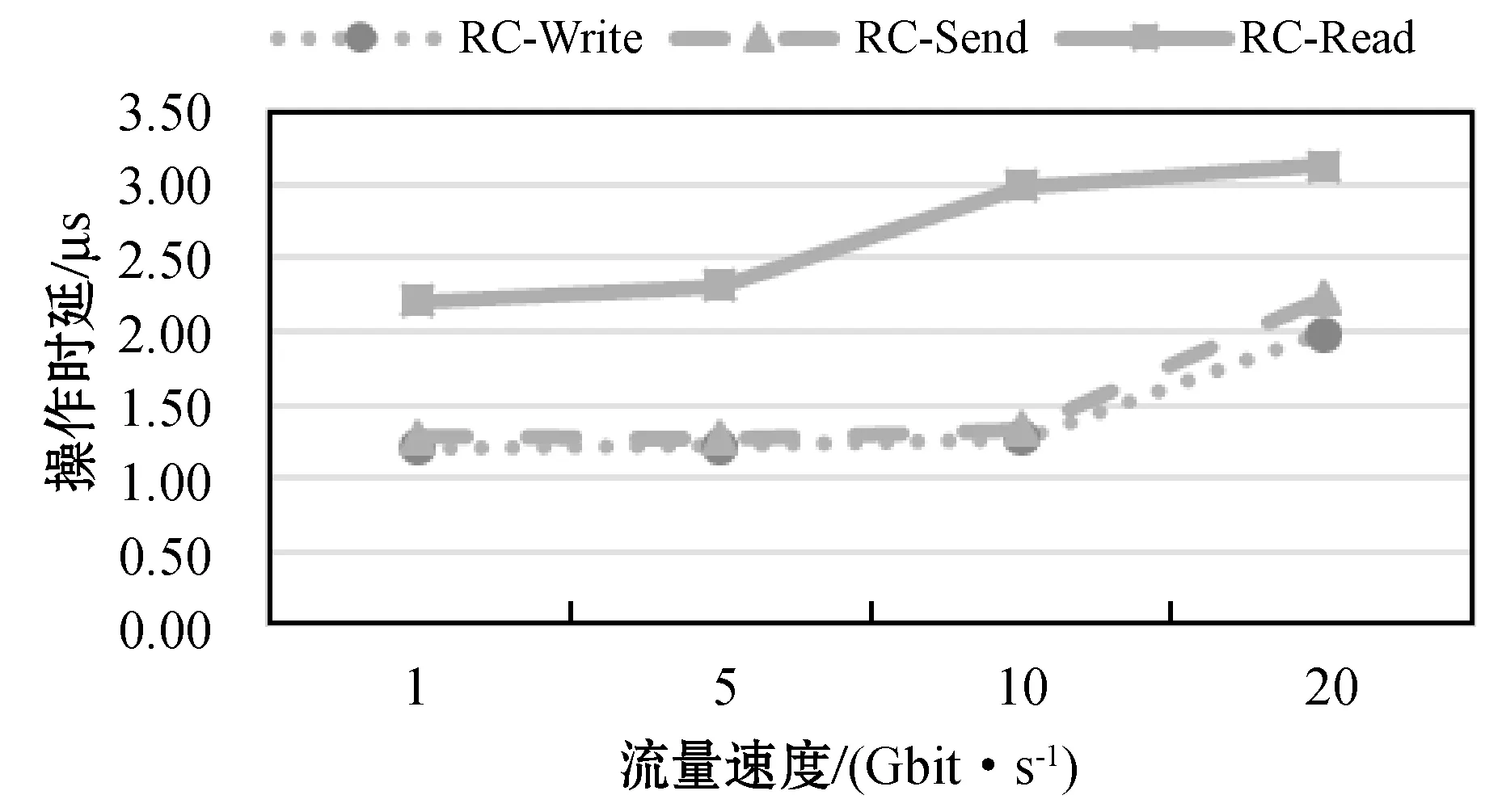
图7 负指标数值的增长情况
(2) 建立连接时TCP RTT随流量变化情况。如图8所示,实验测量了两个传输节点单流情况下随着流量不断增大,再次建立RDMA连接时的TCP RTT平均时间。当流量在10 Gbit/s以上时,建立连接时的网络时延有明显增大。度量系统分析的结果和通过tcpdump抓包后离线分析呈现同样的结果。
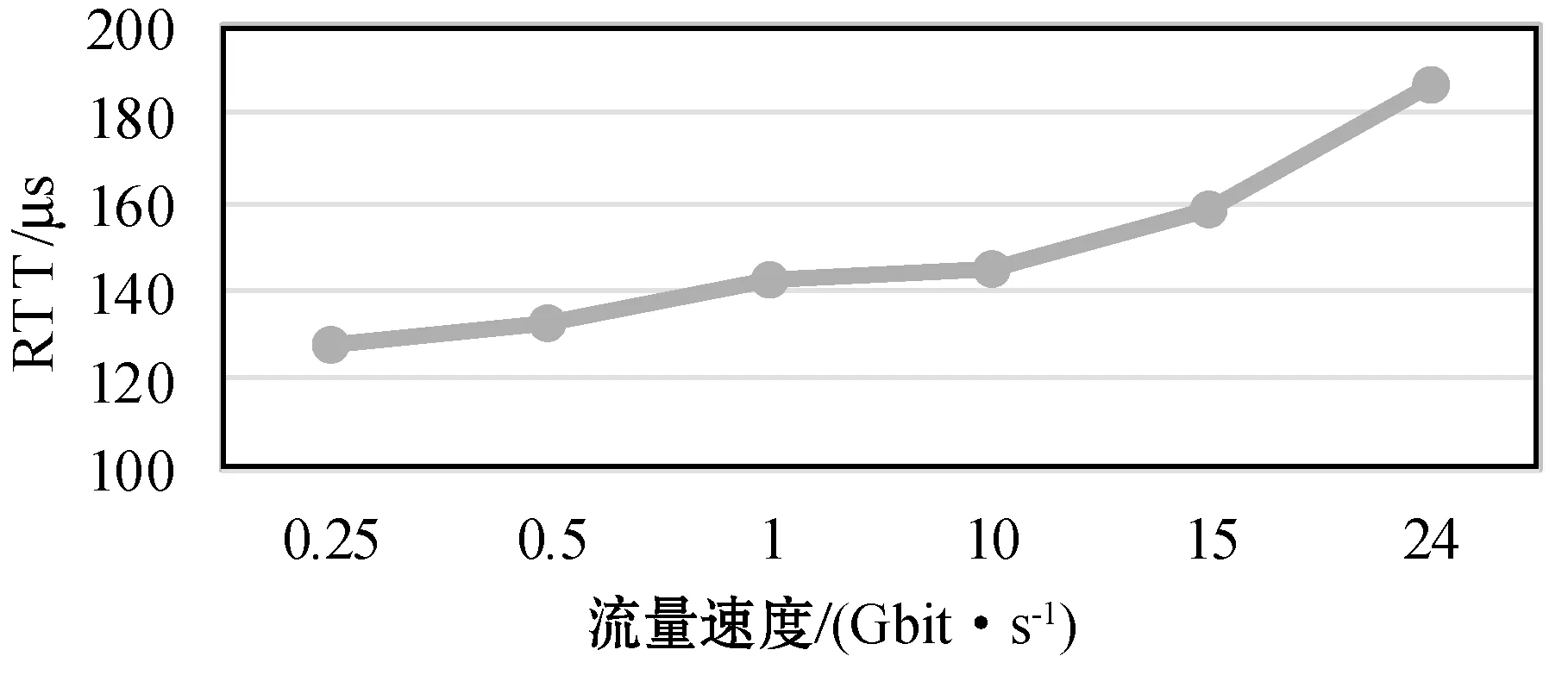
图8 建立连接时TCP RTT随流量变化
(3) RoCE流个数与流大小指标验证。本节测试多节点多流时的流大小和个数分布情况,在192.168.2.201服务器和192.168.2.20之间产生的10条速率小于5 Mbit/s的稳定RDMA背景流,另外在三台服务器上产生四条速率分别为1/3/4/6 Gbit/s的流。多流分布情况如图9所示,接近横坐标轴的实线部分的流flow1-flow10是背景流。系统可以客观显示网络中的流分布情况。
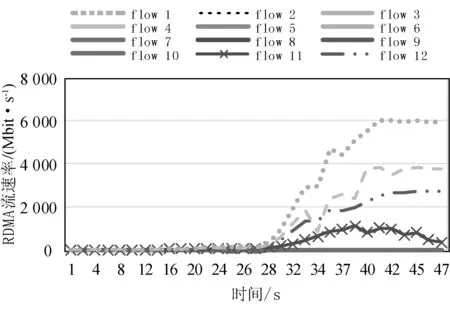
图9 多流流大小分布情况
(4) RDMA 操作的相互影响。在192.168.2.206和192.168.2.202之间产生25个QP用来进行RC-Send/Write/Read、UD/UC-Send、UC Write操作传输流量,所有操作同时开始,模拟多操作并存时的流量相互影响情况,同时作为下一节网络拥塞场景模拟的流量来源。
如图10所示,在流量传输过程中,Read操作程序产生访问远程地址错误日志,而状态感知系统可以客观显示由于流之间存在相互影响,Read操作先占用了大部分资源,导致其他操作在建立连接时略微滞后。
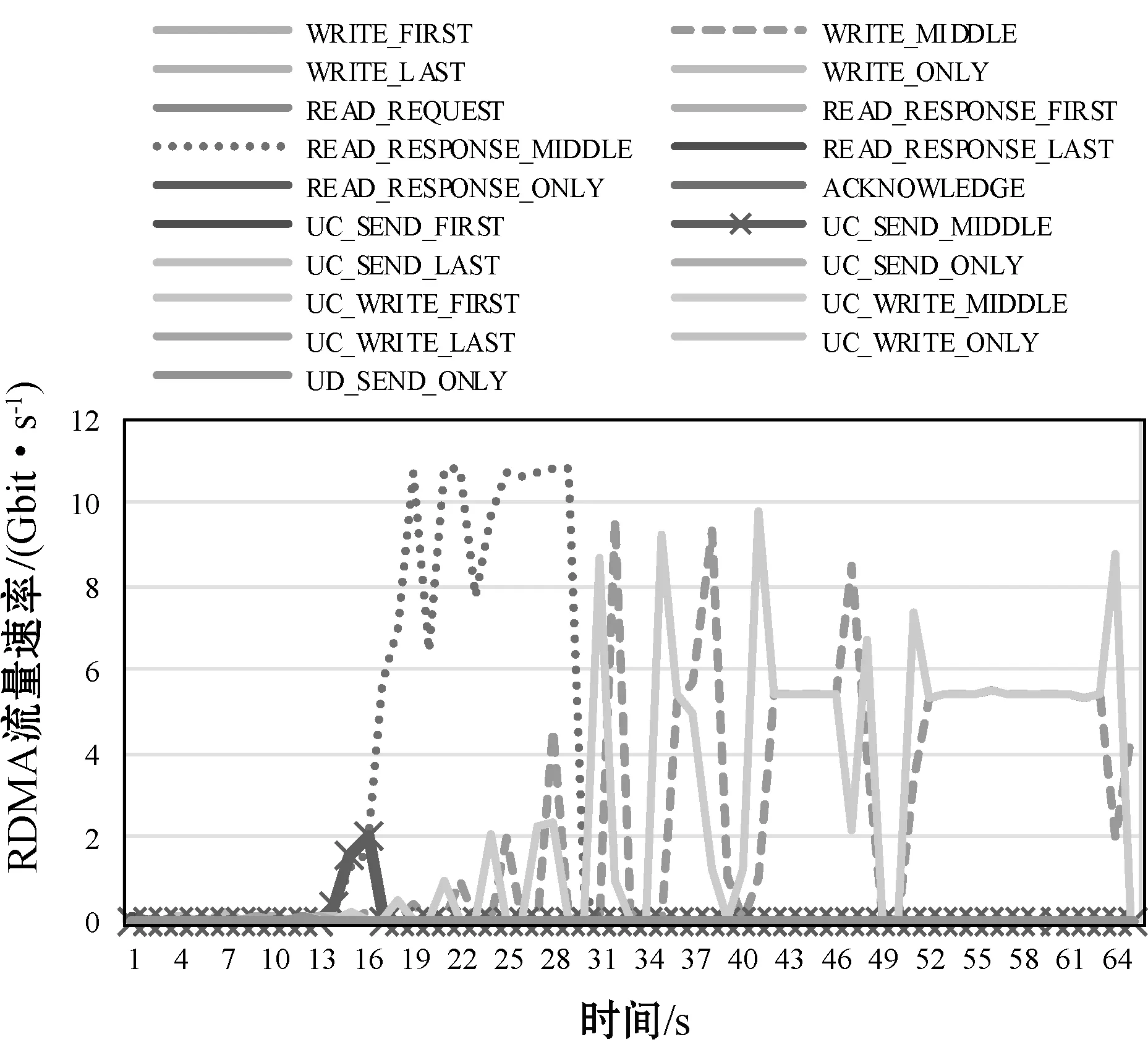
图10 多流RDMA操作的流量大小分布情况
5.3 RDMA常见场景问题验证
1) 场景一:当传输过程中接收端程序断开导致连接断开的情况模拟。模拟在进行RC-Send传输中接收端程序突然中止的情况,RDMA操作相关指标变化累计和如图11所示。

图11 场景一RDMA操作相关指标变化
发送端的Ack超时错误的次数、请求端检测到CQE错误的次数、请求端检测到CQE发生flush错误的次数都同时增长。但网卡与链路的状态无任何异常,节点可用性指标、连接可用性指标、网络负载指标正常,排除网络拥塞造成的传输故障,表征了接收端的应用程序存在着故障。
(2) 场景二:网络拥塞模拟。使用如图10所示的同样的流量生成方法,模拟单节点发送网络拥塞的场景。如图12、图13所示,当Read操作程序产生访问远程地址错误日志时,RDMA操作时延较正常情况下增加了9.1%~87.7%,同时发送端和接收端的网络负载相关指标同时变成非零,并且接收端的CNP信号(responder-rp_cnp_handled)数量较其他指标在传输时段的累积和更多,因此可以说明是发送端节点导致的网络拥塞。
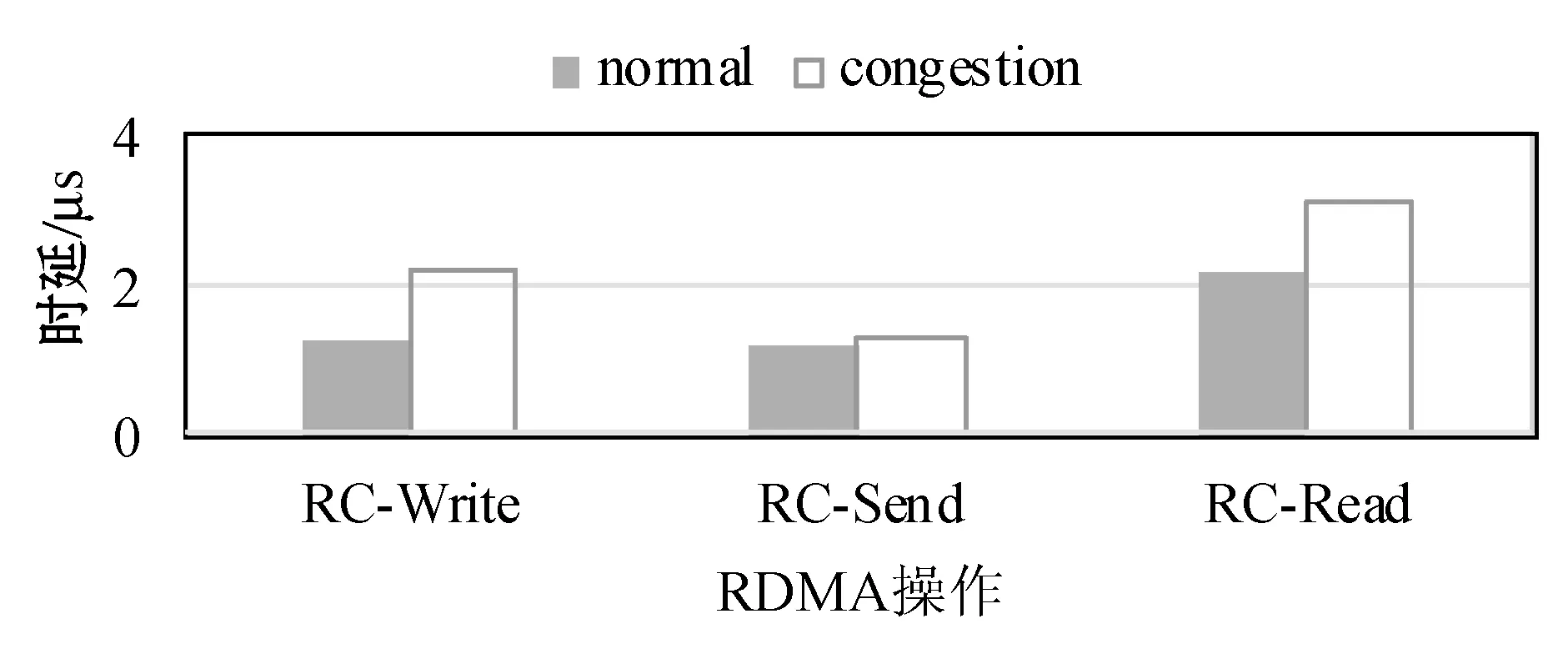
图12 RDMA RC操作时延的前后对比
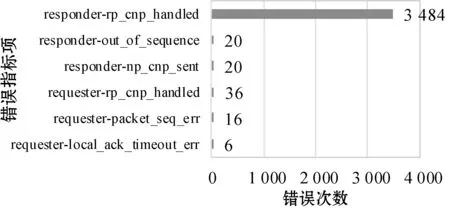
图13 场景二网络负载相关指标数值在传输阶段的累计
(3) 场景三:大流抖动模拟。针对带宽敏感的应用场景,模拟在大流出现抖动的情况,同样产生如图9中的10条背景RDMA流,另外产生流量趋势随机变化三条高速率的RDMA流,设定大流阈值为5 Gbit/s,抖动阈值为2.5 Gbit/s,抖动窗口为1秒。如图14所示,度量系统可以准确识别出三条流的大小抖动变化。
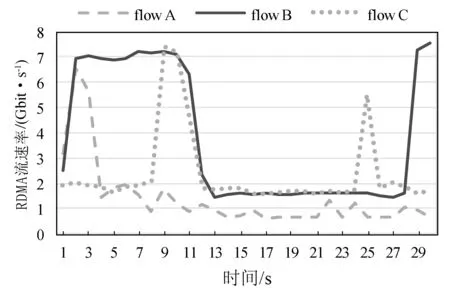
图14 场景三大流抖动检测
5.4 误差评估
本文选取识别、检索、分类、翻译等领域常用评估指标:平均绝对误差、平均相对误差和准确率。
(1) 平对绝对误差。平均绝对误差是所有流某个指标测量值和实际值偏差的绝对值和实际值的比值的平均。对于流的大小的估计和Opcode流量速率估计将使用平均绝对误差来评估误差。
(2) 相对误差。相对误差是绝对误差和测量值的平均值的比值的平均值,通常用绝对值。对于总的流个数的估计使用相对误差来评估误差。
(3) 准确率。准确率是系统正确识别的指标项个数和应当被识别出的指标项个数的比值的平均值。
除从系统上收集的文件数据外,其余所有指标的真实值采用RoCE官方的Perftest基准性能测试工具以及用tcpdump同步抓包离线分析的结果,和系统计算出的各项指标进行误差计算。
(1) RoCE流个数估计误差。网络中的总的RoCE流个数采用相对误差验证,在三个节点之间随时间变化产生共1~72条流量速率范围在0.5 Mbit/s~20 Gbit/s的流,估计值和真实值的相对误差小于2.7%。
(2) 流大小估计和Opcode操作流量估计的误差。流大小分布估计和RDMA操作流量估计采用平均绝对误差,流量模拟分别采用5.2节(3)、(4)中的流量产生方法,测试时长为2分钟,每两秒计算一次,两者的平均绝对误差分别为4%和11.3%。
(3)大流和流抖动识别误差。产生5条流量速率小于0.5 Gbit/s背景RDMA流,5条速率在1~5 Gbit/s的RC-send RDMA流,与离线文件对比,大流阈值设定梯度为1.5/2.5/3.5 Gbit/s,抖动阈值设置为2 Gbit/s,流量速率大小分别变化4次,测的大流和抖动识别准确率平均值为95%。
经过误差分析,该状态感知度量系统可以客观地反映网络状态的变化趋势。
6 结 语
本文设计、实验并评估了一个可扩展、低成本、面向多点网络的RDMA网络在线实时状态感知度量系统,设计了多维度多层次的RoCE网络度量指标体系,在RoCE网络中针对不同类型和大小的流量对RDMA的特征数据进行估计,由此给出一些可供参考的故障诊断意见。结果显示,系统可以在较低误差下多方位展现网络状态。
下一步工作将细化RDMA的操作,将更多的指标变化的含义和网络错误匹配,另外考虑增加系统对iWARP和IB网络场景下的适用支持。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
计算机与数字工程(2022年3期)2022-04-07
电脑爱好者(2021年4期)2021-02-27
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
物联网技术(2018年8期)2018-12-06
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2016年2期)2016-03-11
电脑爱好者(2015年15期)2015-09-10
网络与信息(2009年7期)2009-07-11
