
基于多级频域分解与伪造挖掘的深度伪造检测方法
2022-02-18 03:19王涛,许锟
兰州工业学院学报 2022年6期
王 涛,许 锟
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
近年来,随着深度生成模型的快速发展,人脸伪造技术逐渐成熟。先进的伪造技术让人类难以分辨出伪造人脸的真假,并且深度学习技术所具有的普适性和开源性,使得伪造人脸的技术门槛不断降低。因此,当人脸伪造技术被不法分子利用时,无疑会对国家安全和社会稳定造成极大威胁,DeepFake、DeepNude等不道德应用的出现就证明了这一点。所以,为降低人脸伪造技术造成的危害,众多基于深度学习的人脸伪造检测方法[1-2]被提出。
研究初期,一些经典的卷积神经网络,如ResNet、Xception[3]等被直接应用于人脸伪造检测,并且取得了令人满意的效果。但是这些网络并不是为人脸伪造检测而特殊设计的,因此对图片空域信息的提取能力有限,Qian[4]等人提出一种利用图片频域信息鉴别人脸真伪的检测方法,成功解决伪造图片经压缩后难以被检测的问题。但是该方法的数据依赖性高,对于不同压缩率的图片需要单独训练模型才能保证准确率。Sun[5]等人利用连续帧的面部关键点提取伪造视频的时域信息,在减少训练和预测所需时间的同时提高了在数据集内的检测精度,但是该方法的跨数据集的泛化表现不理想。Masi[6]等人将空域、频域和时域的信息进行融合,同时提高模型在数据集内和数据集外的检测精准度。但是这种方法的网络结构复杂,训练和预测也需要大量的时间。针对这一问题,姚昆仑[7]等人提出一种基于胶囊网络的深度伪造检测方法,减少了模型的参数和训练所需时间,但是检测精度有所下降。
因此,针对以上问题提出了一种基于多级频域分解与代表性伪造挖掘的人脸伪造检测方法FRNet,通过双流网络将空域信息与频域信息融合,提高检测方法的泛化能力;在空域流加入一种基于注意力的数据增强模块(RFM),对人脸的代表性伪造信息进行挖掘;通过在两个主流数据集上进行对比和消融实验,证明FRNet的优越性。
1 相关技术介绍
1.1 深度人脸伪造
目前的人脸深度伪造分为假脸生成和人脸操纵这两类。假脸生成是指基于生成对抗网络(GAN)的生成模型,通过学习训练集数据的分布,生成现实世界中不存在的人脸,如图1(a)所示。这类方法生成的人脸是随机的,因此没有较大的危害。人脸操纵通常针对成对的人脸进行,根据操纵目标的不同可将其分为人脸替换和面部重演。图1(b)示例了不同人脸操纵方法的生成结果,这类方法可以对特定的人脸进行替换和重演操作,因此对国家安全、社会稳定有较大威胁。

图1 人脸深度伪造方法示例
1.2 Xception网络介绍
Xception[3]网络在早期的伪造检测中表现出了优秀的特征提取能力,因此在现阶段经常被用作主干网络和对比的基线,本文提出的FRNet也将Xception网络作为主干网络。Xception是Google公司对Inception v3的一种改进,与传统卷积不同的是,该网络采用深度可分离卷积。Xception网络的框架如图2所示。
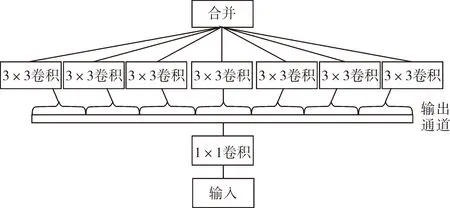
图2 Xception网络框架
2 模型设计


图3 FRNet框架
2.1 多级频域分解
已有的深度伪造检测方法虽然在数据集内表现良好,但是在跨数据集检测时却表现不佳。特别是伪造图片被高度压缩后,图片的视觉质量大幅下降,单从空域角度很难分辨出人脸的真假。幸运的是,YU N等的研究[8]表明伪造痕迹可以在频域中被捕获。以前大部分是通过固定权重的滤波器来挖掘频域中的伪造线索,这对于判别特征学习来说不是最佳选择。因此本文采用多级频域分解,通过一组自适应可学习的频率滤波器在频域中对输入图片进行划分,从而深入挖掘频域中的伪造信息。

(1)

(2)

(3)
式中:D表示离散余弦变换(DCT);D-1表示逆离散余弦变换;⊙表示逐元素乘积。
因为DCT具有良好的频率分布,本文采用DCT将RGB图片转换到频域,通过DCT得到的频域低频分布在左上角,而高频分布在右下角。并且近期的图片压缩算法大部分是基于DCT的,因此应用这种转换方式可以让方法更具有普适性。
2.2 代表性伪造挖掘
基于频域的伪造检测方法在不同质量的数据集上均有较好的表现,但这类方法在数据集外检测的精准度方面依然存在问题。因此,本文选择保留输入的RGB图片,并通过双流网络实现图片空域信息与频域信息的互补,如图3所示。此外,针对文章中提到的卷积神经网络倾向于从有限区域中检查伪造痕迹这一问题,本文在双流网络的空域流中加入了代表性伪造挖掘(RFM)。通过这种基于注意力的数据增强方法,让鉴别器可以关注到整个面部。RFM的整体流程可具体分为两步:①为每个最小批次中的原始图片生成伪造注意力图xatt。②基于得到的伪造注意力图,对原始图片进行伪造擦除得到增强后的原始图片xmask,然后将其传入检测器进行训练。伪造注意力图是指检测器最敏感的区域,也就是对检测结果产生关键影响的区域。将原始图片x输入鉴别器网络,可以得到用来衡量x真假的两个分数Oreal和Ofake。因为对原始图片x的任何扰动都会改变Oreal和Ofake,所以可以利用这两个分数来计算检测器的敏感区域。具体来说,用∇IOreal和∇IOfake表示扰动对x分数的影响,然后计算∇IOreal和∇IOfake之间的最大绝对差值来表示扰动对检测结果的影响。通过这种方式,让伪造注意力图xatt中的每一个数值都精确的表示检测器对图片对应像素的灵敏度,具体可表示为:
xatt=max(abs(∇IOfake-∇IOreal)).
(4)
式中:abs(·)表示绝对值函数;max(·)表示最大值函数。得到xatt后,可以通过xatt计算检测器的Top-H敏感区域。先对xatt中的坐标值进行排序,然后按照顺序将每个像素视为锚点。对于每个锚点,使用随机整数组生成一个矩形块进行遮挡。循环这个操作直到图片被H矩形块遮挡时,就可以得到增强后的图片xmask。
3 实验检验
3.1 相关数据集
在实验过程中,用到了两个常见的伪造检测数据集:FaceForensics++[9]和Celeb-DF[10]。FaceForensics++数据集是一个取证数据集,由1 000个原始视频和5 000个人脸操纵视频组成。数据来源于977个YouTube视频,所有视频都包含一个可跟踪的正面人脸,这使得自动篡改方法能够生成逼真的伪造。并且每个视频都有原始(Raw)、低压缩率(LQ)和高压缩(HQ)3种版本可以选择。
Celeb-DF数据集是用于伪造取证研究的大规模人脸数据集,包含590个来自YouTube的原始视频和5 639个对应的人脸伪造视频。该数据集在实验中常作为测试集,用来评估模型在跨数据集检测时的表现。
3.2 实施细节与评估指标
与以前检测方法的设置相同,本文采用FaceForensics++中建议的数据分割方式。将数据集中72%的视频用于训练,14%用于测试,剩下14%用于验证。其中每个视频中截取10帧,并通过人脸对齐和裁剪,将每一帧裁剪为224×224大小的人脸图片。此外,本文使用在ImageNet上预训练过的Xception网络作为主干网络,通过Adam进行加速,学习率设为0.000 2,超参数N=4,H=3,批量大小设置为8,每个模型训练约20k次迭代。
在定量比较中采用准确率(Acc)、受试者工作特征曲线下的面积(AUC)和预测一张图片真假所需的时间(FPS)作为度量指标。准确率表示检测器预测正确的样本数占总样本数的比重,具体可以表示为式(5),即
(5)
式中:TP、TN、FP和FN分别表示真正例(鉴别器将伪造图片判断为假的样本数)、真反例(鉴别器将真实图片判断为真的样本数)、假正例(鉴别器将伪造图片判断为真的样本数)和假反例(鉴别器将真实图片判断为假的样本数)。
AUC是受试者工作特征曲线(ROC)下的面积,ROC曲线的纵轴和横轴分别是真阳性率(TPR)和假阳性率(FPR)。所以AUC可以表示为式(6),即

(6)
式中:TPR表示所有伪造图片中被检测器正确分类为假的比例;FPR表示所有真实图片中被检测器错误分类为假的比例。
3.3 同类方法比较
FRNet法与其他不同人脸伪造检测方法的定量比较如表1所示,测试集为FaceForensics++(HQ)和Celeb-DF数据集。从表1中可以看出,FRNet在数据集内具有可以媲美其他方法的Acc和AUC分数。同时,FRNet在跨数据集检测时的AUC分数达到了0.774,高于其他方法。这表明FRNet法在数据集内保持高检测精度的同时对数据集外的图片也拥有着良好的检测效果。

表1 不同人脸伪造检测方法的定量比较
为了进一步验证所提方法的有效性,分别在Xception和ResNet50两种主干网络上进行了实验,对比效果如表2所示。从表中可以看到本文方法在两种主干网络上均有较高的AUC分数,说明该方法的普适性和有效性。虽然以ResNet50为主干网络会导致方法的AUC分数偏低,但是可以大幅提升预测图片时的速度。不同主干网络上的定性表现如图4所示,从ROC曲线中可以更直观的看出使用不同主干网络时,FRNet在数据集内和数据集外的优势表现。

表2 不同主干网络上的定量比较

图4 不同主干网络上的定性比较(ROC曲线)
3.4 消融实验
为了评估FRNet方法中每个模块的有效性,需进行消融实验,度量指标为AUC,实验结果如表3所示。通过比较模型1(基线)与模型2(加入MFD的双流网络),可以发现加入频域后数据集内和跨数据集检测的AUC分数都有所上升。这说明空域信息与频域信息的融合,可以提高检测模型的鲁棒性。在空域流加入代表性伪造挖掘(RFM)后得到模型3,与模型2相比,模型3拥有更高的AUC分数,表明基于注意力的数据增强方法RFM可以进一步提高检测模型的鲁棒性。

表3 所提出方法FRNet的消融实验
此外,通过定性比较可以更直观的展示包含不同模块时模型的检测效果。图5展示了FaceForensics++(HQ)数据集下模型1、模型2和模型3的ROC曲线。从图中可以看到,随着各模块的加入,ROC曲线下所包含的面积不断增加。这说明随着各模块的加入,检测器的鲁棒性越来越好,从而证明了FRNet方法中各模块的有效性。

图5 FRNet方法的定性消融研究ROC曲线
4 结论
1) 通过双流网络融合图片的空域信息与频域信息,可以缓解单一信息域检测方法跨数据集泛化能力弱的问题。
2) 在空域流加入基于注意力的数据增强模块(RFM),可以使检测器更全面的挖掘面部的伪造痕迹。
3) 与其他方法相比,本文所提的FRNet人脸伪造检测方法,在数据集内和数据集外均有更高的检测精准度,详细的消融实验也验证了方法中每个模块的有效性。
未来可以通过多模态信息的融合(如图片和文本信息的融合、图片和音频信息的融合等),实现更高精准度的人脸伪造检测。事实证明,被动防御只能做到伪造图片的事后取证,基于对抗样本的主动防御才能有效杜绝人脸识别图片的伪造。
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
军民两用技术与产品(2021年10期)2021-03-16
动漫星空(2018年9期)2018-10-26
雷达学报(2018年3期)2018-07-18
北京航空航天大学学报(2017年3期)2017-11-23
西南交通大学学报(2016年4期)2016-06-15
海峡科技与产业(2016年3期)2016-05-17
中国农业文摘-农业工程(2016年5期)2016-04-12
