
基于Hadoop的网络舆情关键字监控体系分析
2022-02-16 12:10张晓飞
无线互联科技 2022年23期
张晓飞
(遵义师范学院,贵州 遵义 563000)
0 引言
互联网使用具有随意性、便利性及隐蔽性,已成为民众间接或直接表达观念的首选。特别是微信、微博社交平台的兴起,人们热衷于在网络上对某件事表达看法、立场与态度。不乏消极舆论通过网络传播,如果引导不善,可能会威胁社会秩序与稳定性。加强互联网舆情监控,利用Hadoop作为分布式处理框架处理海量数据,设置监控网络关键字,可以有效减轻网络舆情数据分析工作量。
1 系统需求分析
互联网相关的人工智能、云计算、大数据等技术迅速发展,已经融入网民生活,使得信息技术成为生活生产要素重组、改变竞争格局、重塑经济结构的重要力量。根据统计可知,我国截至2021年网民规模达到10.32亿人,相比2020年网民增加4 296万人,互联网普及率是73.0%。网民数量快速增长,多数网民在互联网中发表过言论观点,因此,必须提高网络舆监控力,以免由于消极论断引发社会动荡[1]。Hadoop平台是分布式系统,利用编程模型处理庞杂数据,子项目是HDFS,借助HDFS能够存储大型数据,容错性及数据吞吐量高,可实现大规模数据访问。在网络舆情监督中,管理人员需结合网监部门及网络发展要求,提取舆情关键字,从而实现敏感话题监测、传播途径监测、舆情态势分析、重点话题自动关注,有效筛选网络舆情热点,识别敏感话题。在此过程中,系统能够根据热点话题进行跟踪,生成统计报告;对于微博评论、新闻评论、论坛跟帖等也能做到数据精准抽取、准确挖掘、合理分析。按照设计要求,该舆情分析系统的热点筛选准确度需超过90%,涉及社会稳定的舆情内容筛选准确度需达到100%。
2 系统设计方案
2.1 系统框架
Hadoop网络舆情系统设计采取MVC架构,系统利用web爬虫处理网页URL及其联结数据,经过去重、分类、除缀等操作,结合不同类别信息,采集相应网页。URL原始地址是使用eTools元搜索引擎,搜索某些关键字,返回搜索结果枝系统,成为网络爬虫URL初始采集列表,且URL可以将列表划分为若干信息数据类型,下发至不同采集节点[2]。网络爬虫经过深度迭代与广度迭代,采集互联网网页信息。在提取信息时,利用抽取信息模块处理爬虫采集数据,筛选网页内容,采取去重技术清理数据,能够有效获取舆情纯文本信息。在存储数据时,用户先根据关键字内容范围抽取网页信息,将其存储至相应HDFS文件系统之后,处理基础数据。具体步骤为:开发人员先应用Mahout开源算法库,通过机器学习与数据挖掘算法,处理存储于HDFS系统网页数据;再寻找舆情热点,检测敏感话题,提取关键字,追踪舆情发展态势;最后生成专题,分析网络舆情。系统架构如图1所示。
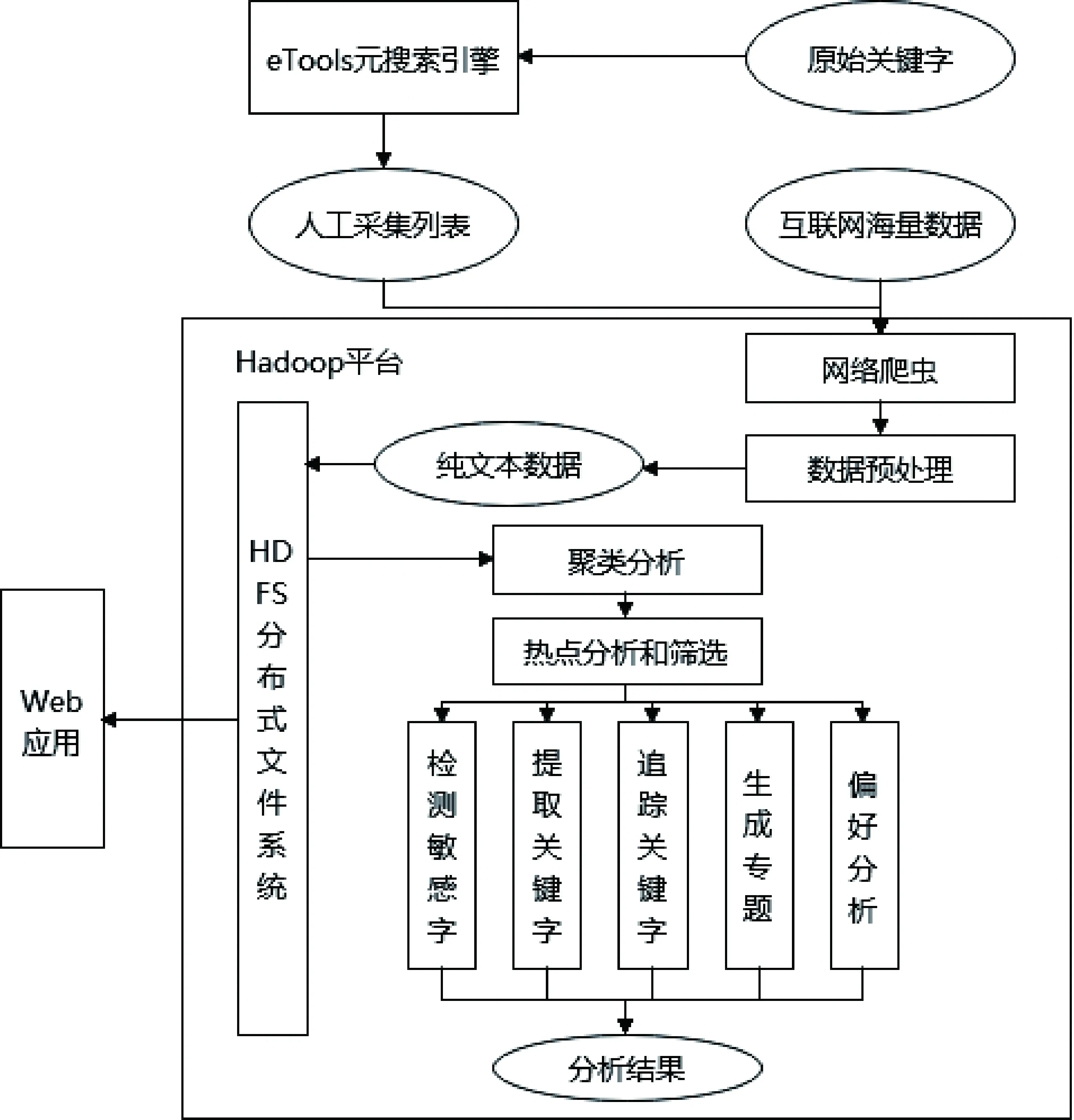
图1 系统架构
在系统实施中,借助网络爬虫提取互联网数据后,用户方能对网页预处理,提取网页内容、标题关键字,做到去重、消噪、分词。系统部署运算的框架是Map/Reduce模型,该模型立足于B/S架构,能保证系统开发的安全性。
2.2 数据收集模块
在网络关键字监控中,由于舆情数据来源于各大网络平台,包括新浪微博、网易新闻、西瓜视频、搜狐新闻等,系统数据收集作为重要的初始环节,需结合数据来源,选择恰当的收集模式。以新闻数据为例,Nutch由非分布式、分布式构成,在实际运行中,分布式系统由于稳定性、运行效率均优于非分布式系统,所以可使用分布式Nutch[3]。收集数据步骤如下:用户利用元搜索引擎检索关键字,添加URL列表至系统内,在URL列表创建Fetchlist,通过内容解析器分析舆情数据,提取全新URL,更新CrawIDB,完成数据收集。数据信息源于微博网站,管理人员利用API接口完成数据采集,在这一过程中需先保证客户端获得微博平台的真实授权,再完成开放工作。
2.3 数据处理模块
网络数据处理,主要是利用URL去重、建立索引、网页分词等,网页分词先用汉语词法分析系统,它具有分词效果好、系统功能成熟的效果。在系统采集数据中,抽取网页URL地址,收集互联网数据,不同网页URL地址相同,网页爬虫为避免多次爬取相同网页,增加系统负荷,降低爬取网页速度,需考虑判重URL地址,进行重复URL地址过滤[4]。在URL驱虫中,系统使用Bloom Filter算法能够识别某元素是否处于集合内,实现去重效果。Nutch爬虫在爬取网页URL内容时,能够维护2个URL库,分别为即将抓取与已抓取URL地址库。在爬取关键字时,开发人员需要用到Bloom Filter算法,判断URL地址是否已经抓取,存在则放弃爬取;不存在则需添加至地址库内。由于利用舆情分析系统爬取的URL数量较大,为加快该进程,本设计使用拆分Bloom Filter算法。具体表现为:先通过s×m位串矩阵V表达数据集合,即Data={d1,d2,…,dn},算法将s长度作为m位串及h+1散列函数,确定其映射范围后,查询1个位串是否处于集合内。
2.4 数据存储模块
在Hadoop舆情关键字监控系统中,数据存储作为重要部分,能够存储网页源数据,包括网页URL、网页标题、建立时间、浏览网页数量、品论数量等,以XML文件模式存储。存储结果数据,包括中间结果与分析结果数据,前者是网页预处理信息,后者是舆情统计信息,提取舆情关键字,筛选舆情热点,追踪舆情结果。存储系统参数,包括角色权限、密码、用户名、运行系统日志等,包括采集网页日志、提取数据日志等,配制主要系统参数[5]。在数据存储中,系统采取HDFS文件存储。经过网页预处理后,数据中如果存在图片内容,则大小低于10 MB;如果收集的数据中无图片内容,则数据大小在2~64 k范围内。为提高该系统的存储效率,设计人员以key存储序列化文件,以value存储真正文件,将多个小文件进行合并,汇集成大文件后存储至HDFS。此种方法使得用户访问文件时,可利用Index了解文件key信息,快速访问后面的数据信息。
2.5 舆情分析模块
系统舆情分析模块需提取舆情关键词,构建Map/Reduce模型,实现多层次、多角度的舆情分析。在模块集群中,利用Master控制运行环境,完成资源调度与进程调度,通过节点Node提交舆情分析表申请后,系统即可根据预先定义的环境进行工作。Map/Reduce模型中,由于CPU工作流程相同,仅数据不同,可将作业划分为若干独立单元,将独立单元分配至处理器处理。任务分配过程,即为mapper过程,处理任务是reduce过程,由reduce进程与mapper进程执行,处理多种数据,还能组合处理后数据,Reduce任务唤醒Reducer执行操作,结果输出后存储于系统内。
2.5.1 提取关键字
在舆情关键字中,文件集关键词和文档关键词属于包含关系,关键词词频越高,表明受关注度越高。通常,舆情关键词是信息量较高的命名实体,在提取过程中,增加命名实体权重,能够准确提取关键词。文档中出现关键词位置,对于文档也有一定的影响。计算权重公式如下:
W(t.d)=
(1)
其中,W(t.d)是指t词在d文档中权重;N是文档集内文档数量;tf(t,d)是频率;nt是文档中t词出现数量;W(POS(T))是t词词性权重;|d|是文档向量长度;W(Position(t,d))是文档中t位置系数。根据公式,关键词权重计算如下:
(2)
其中,Wt是候选关键字t权重;f(t)是文档中有候选关键字t的数量;N是全部文档数量;d是候选关键字集中关键词数量。
2.5.2 热点分析
在进行网络热点分析时,用户首先随机选取网页样本,通过聚类分析的方式,获得热点网络舆情簇;然后选择1个舆情簇提取关键词特征,将热点关键词作为二次聚类依据,可以将纯文字文本向量化。系统自动将计算文本传递至TF-IDF模块,获得结果后返回至向量模块,再通过第一与第二聚类,获得有关分类,根据类别话题数量,筛选热门话题。
2.5.3 生成专题
生成专题是专题舆情、热点舆情进行抽取简报;生成专题过程,就是计算文本向量权重维度,将维度文本摘要、整理相关信息,以简报方式提供用户,迅速识别热点舆情。
3 系统测试
在系统测试中,为准确监测网络关键字,本设计使用6台服务器作为系统硬件,应用64位Cent0S6.4及jdkl.7为软件设施,评估网络舆情监测情况。本设计以漏报率与误报率为指标,对高校网络数据进行抓取,得出关键字有就业、考研、兼职、旅游、饮食等。测试结果表明,漏报率与误报率较低,系统准确性较好。
4 结语
综上所述,随着互联网发展,产生海量、动态、异构新闻数据,人们难以高效、迅速地寻找到感兴趣的新闻。为监控网络舆情,相关人员需要挖掘此类数据,对新闻话题进行舆情预测与持续追踪。为此,本文立足于Hapood软件平台框架,使用MVC架构,系统利用web爬虫处理网页URL及有关联结数据,设计了数据收集、处理、存储及舆情分析模块,提取舆情关键字,生成舆情专题,便于监控网络舆情。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
华人时刊(2022年1期)2022-04-26
现代信息科技(2021年21期)2021-05-07
动漫界·幼教365(大班)(2019年10期)2019-10-28
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
电子测试(2015年18期)2016-01-14
计算机与网络(2014年7期)2014-03-25
