
基于潜在客户挖掘与提升的Logistic模型分析
2022-02-16 12:19赵宝利
无线互联科技 2022年23期
赵宝利,赵 博
(1.陕西邮电职业技术学院,陕西 咸阳 712000;2.中国邮政集团公司陕西省分公司,陕西 西安 710000)
0 引言
当前,在疫情防控的影响下,客户交易行为发生了根本性的转变,企业内外部的竞争日趋激烈。金融机构必须依托线上服务来维系客户,使得银行之间的竞争变得透明及扁平。如何掌握客户行为偏好,提前预判客户需求,快速准确提供针对性的金融服务及产品,是银行机构维持自身竞争力的根本。
本文使用某国有大型企业历年的客户数据,通过对客户的资产情况、资金分布、交易状况、典型客户属性等纬度的分析,使用皮尔逊相关性分析、箱形图法、Logistic计量经济模型[1],构建线性回归模型;将客户数据80%作为专家训练数据库,用于模型训练;余下的20%作为测试数据库,验证模型的分析[2]效果。通过利用机器算法挖掘高潜力的价值客户进行针对性匹配适合度最高的推荐产品,从而实现千人千面的客户精准营销,提高客户转化率,达到客户增值的目的。
1 研究设计
本设计运用某国有大型银行后台数据,包括储蓄逻辑集中系统、保险、理财、第三方支付系统、中间业务平台系统数据。数据时间为2021年1—2季度、2022年1季度。
VIP潜在客户:时点客户持有资产为5万~10万,资产尚未达到或未连续3个月达到10万以上的客户。
1.1 数据规范化
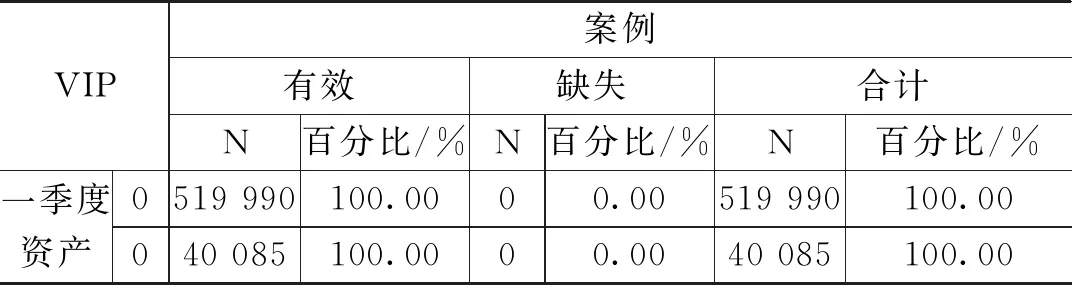
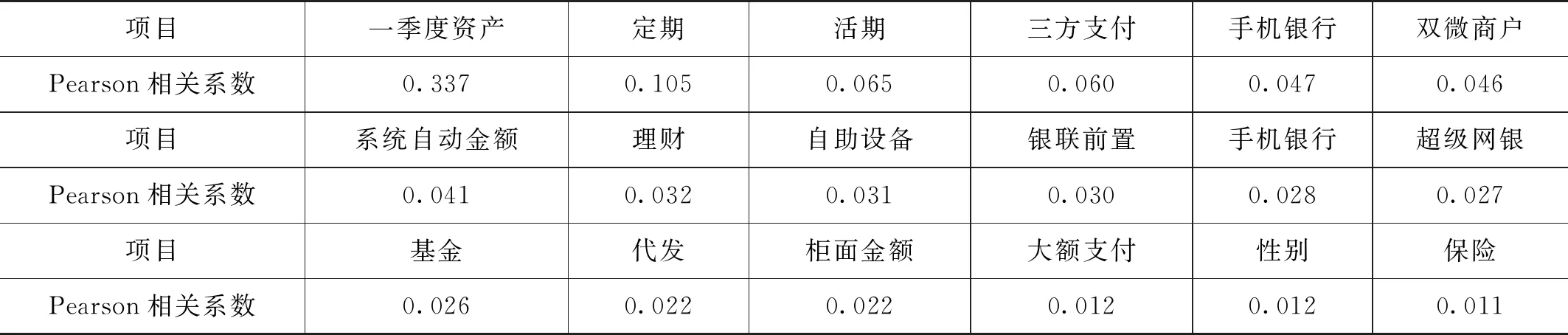
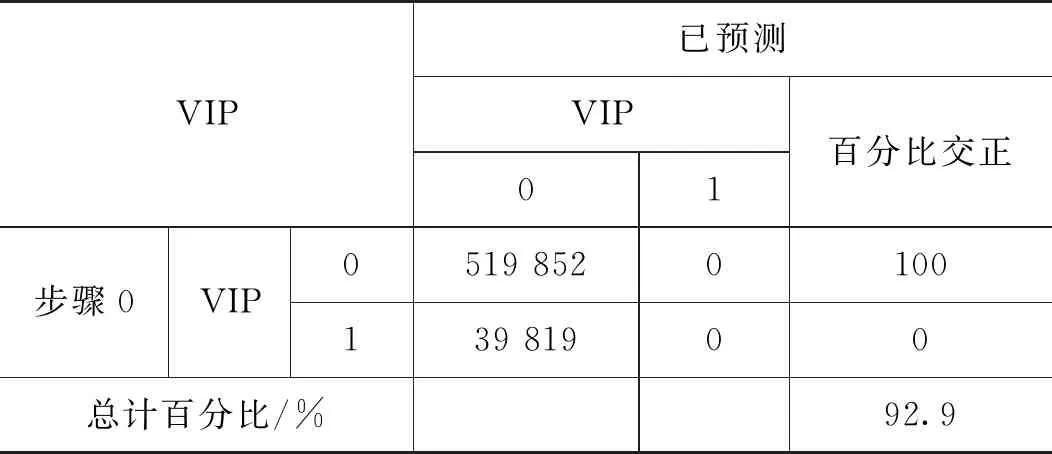
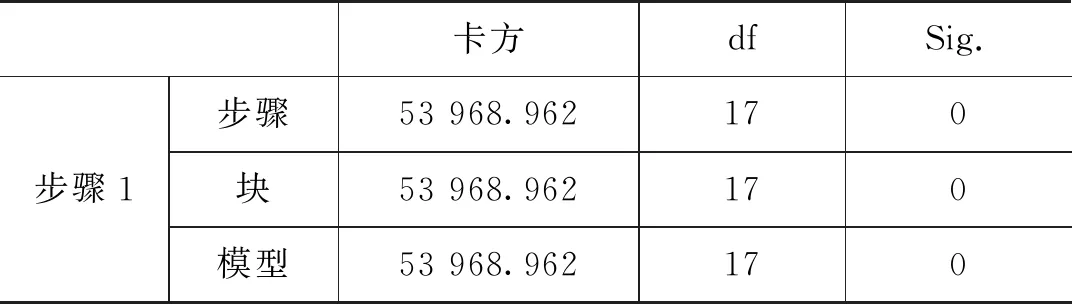
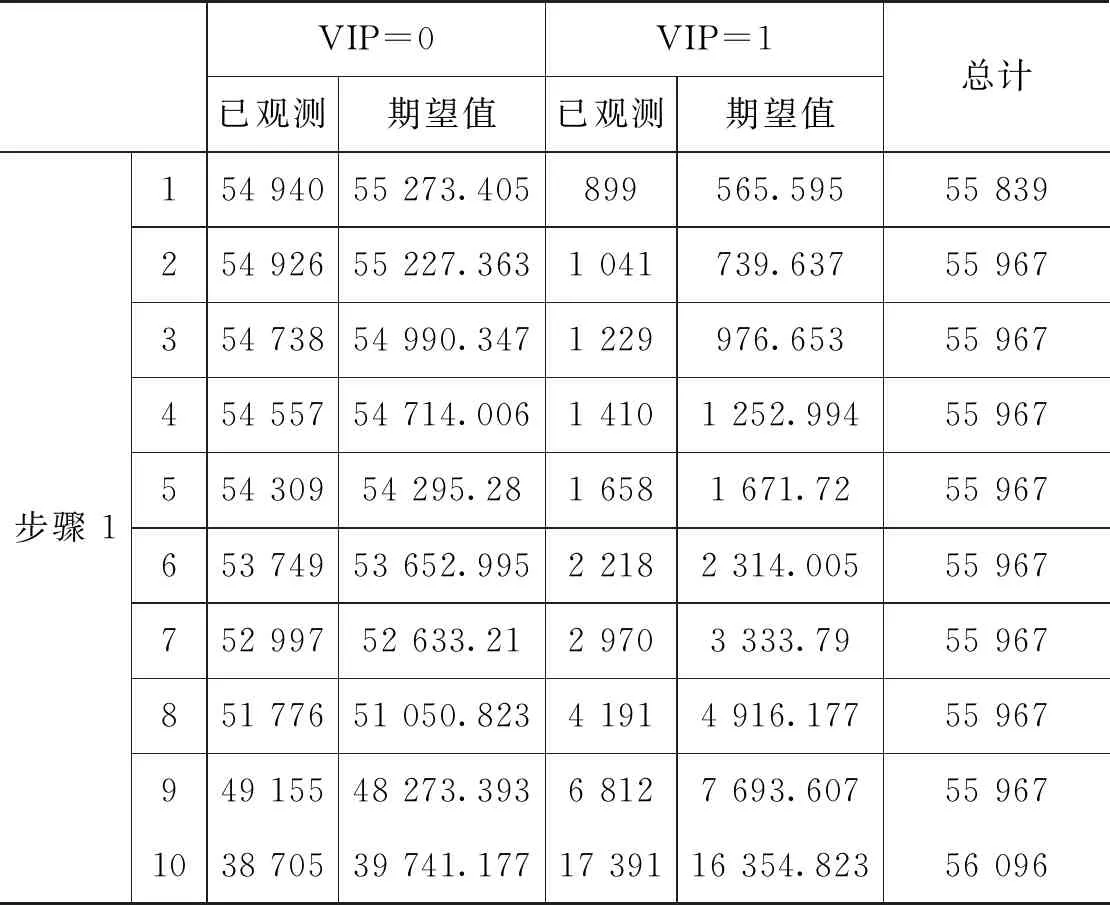
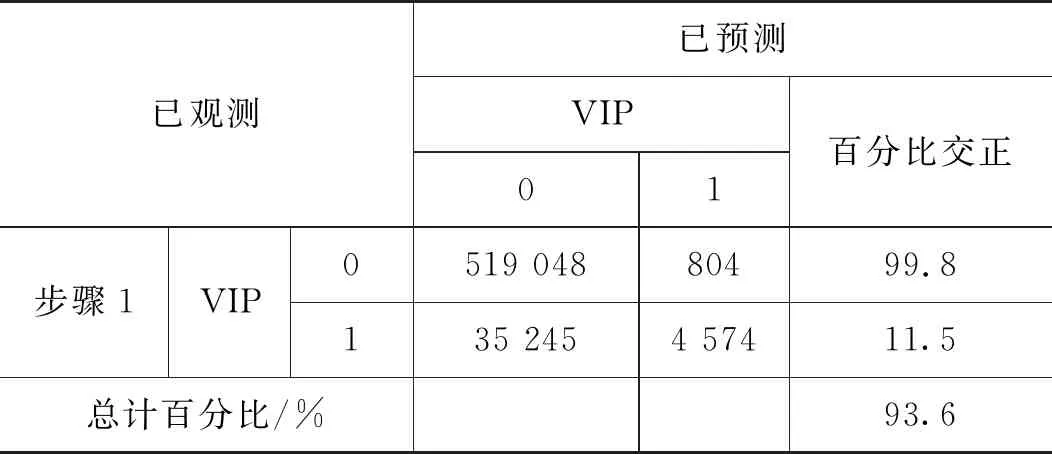
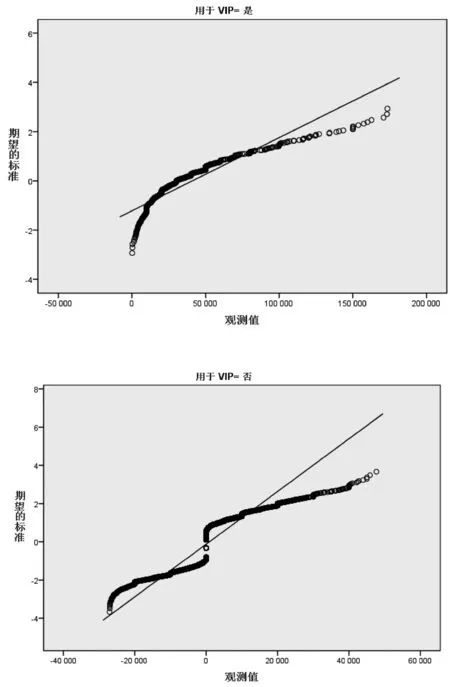
为便于模型分析,将数据进行一系列的规范化处理。如:将客户性别、是否第三方支付客户、是否代发客户、是否手机银行客户等字符串型的客户属性进行数值化处理,替换为该特征的浮点类型。利用箱型图去掉年龄异常值(0 1.2.1 基本模型—Logistic回归模型 Logistic回归模型是一种广义线性回归分析模型[3],常用于数据挖掘、疾病诊断、经济预测等领域。针对研究目标,建立二分类的Logistic回归模型,来分析客户持有资产种类及占比对客户成为VIP客户意愿的影响。 Logistic回归属于概率型非线性回归,假设在多个自变量的作用下,客户成为VIP客户发生概率为P(0≤P≤1),则Logistic回归模型为: logit(P)=In(P/1-P)=β0+β1X1+ β2X2+…+βnXn 其中,发生概率与不发生概率之比为p/(1-p),β为回归系数。 1.2.2 皮尔逊相关性分析 皮尔逊相关性系数是广泛用于度量两个变量X和Y之间的相关程度(线性相关)[4],其值介于-1与1之间。两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商: 按照已知数据,2021年一季度“非VIP客户:VIP客户≈13∶1”的实际比例,选取了2021年70万条VIP临界客户数据,按照8∶2的比例分成了两部分。其中,80%的数据作为专家训练数据库,用于模型训练;余下的20%作为测试数据库,验证模型的分析效果。 用Logistic回归模型构建出以56.0万条真实数据训练出的VIP专家模型样本,模型数据如表1所示。 表1 模型数据摘要 采用皮尔逊相关性分析,对因变量和自变量之间的相关系数进行运算,根据相关性系数高低界定因素,对变量进行排列,结果如表2所示。 表2 Pearson相关性系数矩阵分析结果 选取的相关分析样本数据,为海量数据样本,因此不能仅仅以统计学在小样本上的相关系数区间作为相关程度的判断依据,应该结合模型分析结果的相关显著性业务理解,综合对相关系数结果进行解读。 (1)一季度资产的高低与是否成为VIP客户有直接关系。 (2)在客户持有资产种类中,定期持有较高的客户更有可能成为VIP客户,其他资产种类相关系数从高到低依次为:活期、理财、基金和保险。 (3)VIP客户的保险资产在总资产中的占比最低,即客户的保险资金在总资产中占比越高,越不容易成为VIP。 (4)VIP客户标签中,第三方支付客户的相关系数最高,是否开通第三方支付与是否意愿成为VIP高度相关,其次为手机银行客户、双微客户;代发客户相关系数最低。 (5)VIP临界客户中,女性客户期望成为VIP的意愿高于男性。 通过Logistic回归模型和关键因素相关性研究,笔者对2021年一季度金融VIP客户数据结构和关键因素依赖性有了清晰的了解,此时通过归纳VIP客户关键特征,选取自变量构建VIP客户基本识别模型。 模型起始状态如表3所示,即模型库中,VIP客户与非VIP客户比例为13∶1,此时对一个客户是否会成为VIP客户的预测成功率是92.9%。 表3 初始预测百分比校正 Logistic模型系数的Hosmer-Lemeshow检验如表4所示,是判断模型拟合优劣程度的关键综合检验。伴随概率(Sig)小于0.05,则证明模型拟合度优良。Sig值越小说明拟合程度越好,其检验结果如表5所示。 表4 模型系数的综合检验 表5 模型系数的Hosmer检验结果 表4、表5中“模型系数”一行输出了Logistic回归模型中所有Sig参数是否为0的拟合检验结果。小于0.05则表示本次拟合模型纳入的变量中,至少有1个变量的OR值有统计学意义,即模型总体有意义。 拟合Logistic回归后,对于每一个自变量组合,均可以得到一组事件发生的概率。如果事件发生的概率大于或等于0.5,Logistic回归判断为VIP;如果可能性小于0.5,则判断为非VIP。因此,与真实情况相比,就可以评价Logistic回归模型的预测效果。 在结果预测中,2022年一季度99.8%的金融客户研究对象被模型预测成为二季度非VIP客户,11.5%金融客户研究对象被模型预测二季度可以转化为VIP客户;拟合Logistic回归模型能够将93.6%(“总体百分比”取值)的观测值正确分类,即综合判断准确率达到93.6%,是理想的预测模型结果,如表6所示。 表6 模型预测分类结果表 将2022年一季度建立好的VIP临界客户目标数据(78.7万),导入已建立的VIP专家模型中,完成本次Logistic回归模型预测。模型在已有的2022年一季度VIP临界客户中,自动挖掘并识别了约9.5万名潜在的可转化为VIP的目标客户。 将VIP客户资产增长预测结果趋势用标准分布Q-Q图来描述,如图1所示,变量数据分布的分位数与所指定分布的分位数之间的关系曲线均为正态分布,且Q-Q图上的点近似地在一条直线附近,该直线的斜率为标准差,截距为均值,所以该预测数据完全满足验证标准。 图1 VIP资产增长标准分布Q-Q (1)对于普通客户能否成功晋升VIP模型的预测成功率是92.9%,且模型拟合度优良,模型总体有意义。在拟合Logistic回归模型预测2022年晋升VIP客户时,该模型能够将93.6%的观测值正确分类,即综合判断准确率达到93.6%,是理想的预测模型结果。(2)对于未成功晋升VIP客户的潜在客户模型,因为客户人数较多,可按当月存款区间从高至低分批次落实客户二次挖掘工作。1.2 模型设定与相关性检验
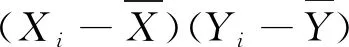
2 构建模型
2.1 关键因素相关性分析
2.2 相关性因素解读
2.3 建立基本模型
3 模型的评价预测与检验
3.1 模型整体评价
3.2 结果预测
3.3 预测结果正态性检验
4 结语
猜你喜欢
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
中学生数理化·七年级数学人教版(2018年11期)2019-01-31
娃娃乐园·综合智能(2018年23期)2018-12-26
科学与财富(2018年16期)2018-08-10
娃娃乐园·综合智能(2018年3期)2018-03-22
中国照明(2016年6期)2016-06-15
自动化博览(2014年12期)2014-02-28
