
基于改进型生成对抗网络的图像去噪方法*
2022-02-16 08:32黄梦然
计算机与数字工程 2022年1期
黄梦然
(南京海康威视数字技术有限公司 南京 210000)
1 引言
图像去噪是计算机视觉领域提高图像质量的基本而又经典的问题,也是许多视觉任务的重要预处理步骤。根据图像退化模型y=x+v,图像去噪的目标是通过降低噪声v,将无噪声的图像x 从噪声图像y 中恢复出来,而消除图像中的噪声对提高用户的视觉体验具有重要的意义。许多现有的图像去噪算法多侧重于改进典型目标测度如峰值信噪比(PSNR),并以均方误差(MSE)作为损失函数训练网络,但这样去噪后的图像往往会丢失重要的图像细节或者在一些纹理丰富的区域变得过于平滑。本文利用SRDenseNet 作为生成对抗网络的生成器,并利用WGAN-gp 来加速网络的训练,同时用于解决原始GAN 训练困难的问题。为使图像细节得到更好的保留,对人眼敏感的感知损失被加入网络。
2 相关工作
通过最小化图像的MSE 来提高PSNR 是图像去噪的一种有效途径。然而,最小化MSE 通常会导致去噪图像在一些纹理丰富的区域丢失细节或变得过于平滑。为了解决这一问题,文献[1]提出了一种级联结构,将图像去噪网络连接到一个高级视觉网络,如图像分类网络。通过联合最小化图像重建损失MSE 和高水平视觉损失来训练去噪网络。在图像分类网络损失的指导下,去噪网络能够产生更具有视觉吸引力的输出,但去噪后的图像在视觉质量上还有待进一步提高。
在SISR 领域,为了在高分辨率图像中恢复更自然、更真实的纹理,文献[2]将GAN 引入到SISR工作中,并提出了感知损失项,包括内容损失和对抗损失。结果表明,该网络能较好地恢复高分辨率图像中的高频细节。由于图像去噪任务中细节的保留也是一个棘手的问题,本文将感知损失引入到图像去噪中。感知损失能很好地衡量去噪图像和地面真实图像(Ground Truth)之间的细节差异。
近年来生成对抗网络引起了极大的关注,并被提出用于解决生成模型估计的问题。GAN 相关的应用可以在文献[3~6]中找到。在这些工作中,GAN 显示出了学习复杂分布的潜力。然而,GAN的训练既复杂又不稳定。WGAN[7~9]克服了生成网络和判别网络间难以保持训练平衡的问题,更重要的是可以生成高质量的样本,同时,加入了梯度惩罚项的WGAN-gp 使得WGAN 网络的训练进程得到进一步加快。
3 去噪方法
本节首先介绍去噪问题的模型,其次介绍基于DenseNet设计的生成网络和判别网络模型,最后介绍相关的损失函数。
3.1 去噪问题模型
去噪问题在数学上可以表示为

其中x和y分别代表噪声和干净(不带噪声)图像,D代表噪声矩阵,噪声矩阵会使图像质量退化。通过对噪声矩阵求逆可以得到干净图像y,计算去噪图像y的公式为
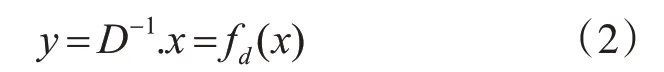
其中fd是去噪函数。
3.2 网络体系结构
生成对抗网络(GAN)[10]由Goodfellow 等提出,目的是通过训练生成器网络G 来骗过判别器网络D,使后者无法区分生成数据和真实数据。G 和D是两个相互竞争的网络,前者通过接收噪声图像作为输入来产生和地面实况图像无法区分的生成图像,后者接收地面实况图像和生成图像并尝试区分两者。生成器G 和判别器D 之间的竞争由式(3)给出:
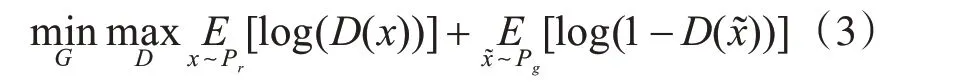
其中Pr代表真实数据x 的分布,Pg为生成器转换的样本分布,定义为x~ =G(z),输入噪声变量z 的分布为P(z)。生成对抗网络的训练是困难的,因为判别器训练越好,生成器梯度消失[11]越严重。因此在训练期间要注意G 和D 两者之间的平衡,否则很容易失败。针对GAN 的缺陷,Arjovsky 等将EM(Earth-Mover)距离代替了JS 散度,去掉损失中的对数函数同时在鉴别器D 中也去掉了sigmoid 层,由此提出了WGAN。WGAN的结构足够精巧简单,克服了原始GAN 训练易失败的问题,但还是存在训练困难,收敛速度慢的问题。WGAN-gp 网络通过在WGAN 中添加梯度惩罚项,进一步提高了收敛速度。其中,判别器中用于衡量生成图像和地面真实图像间距离的EM 距离可以看成与生成样本质量高度相关的重要指标。因此,本文使用WGAN-gp来指导训练进程。
3.3 生成网络
生成网络是GAN 的核心部分,生成样本质量的高低直接关系到去噪的质量。本文基于SRDenseNet[12]设计生成网络的结构,网络结构如图1 和图2 所示。生成网络包含一个卷积块,八个密集 块(DenseBlocks),一 个 瓶 颈 块[13](bottleneck block)和一个输出块,每个块包含一个批归一化层,一个Relu 激活层[14]和一个卷积层。网络使用跳跃连接[15]向每一层提供所有之前的层,这有效缓解了梯度消失/爆炸的问题,增强了深度网络中特征的传播。生成网络的第一个卷积层从输入的噪声图像中提取低阶特征。在此基础上,采用八个密集块来学习高阶特征,网络的最后加入瓶颈层。1×1 卷积层非常适合于减少输入特征图的数量,这使得以较小的计算成本进行特征融合。最后一部分是3×3 的卷积层用来构造输出图像,生成器网络学习噪声图像与地面真实图像间的残差校正,有助于加快训练速度。

图1 生成器G网络结构

图2 判别器D网络结构
3.4 判别网络
判别器网络的作用是鉴别输入图像是真实的还是生成器生成的,这有助于提高去噪图像的质量。因此,判别器网络要尽可能使分配给真实图像数据的概率值接近1,而使生成的图像数据值接近0。
本文的判别器网络结构参考SRGAN 的网络结构并做相应的改变。首先,由于WGAN-GP 的存在,batchnorm 层被替换为layernorm 层[16],包含有3×3 内核的8 个卷积层。最后两层是全连接层[17],给出了来自生成器网络图像或地面真实图像的概率。最后一层由于使用了WGAN-GP[18],因此没有使用Sigmod激活[19]。
3.5 损失函数
MSE是最广泛使用的图像去噪损失函数,通过最小化MSE 可以使得去噪后的图像具有较高的PSNR。这种像素级的MSE计算公式为
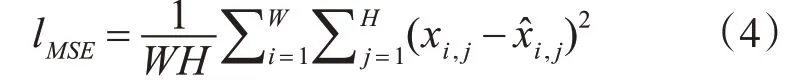
其中W 和H分别为图像的宽度和高度。然而,在使得PSNR 很高的同时,使用MSE 来解决问题会使得在图像纹理丰富的区域丢失一些重要的细节或过于平滑。
本文提出的改进损失的思想为根据高级特征额外引入感知损失来更好地表征图像的主观质量。感知损失包含两部分:内容损失lcon和判别损失lgen,其中判别损失来源于GAN,内容损失通过计算经过预处理的19层VGG网络中提取的特征图之间的欧式距离距离得到。由于这些更深层次的特征图只关注于内容,因此在去噪过程中最小化这些内容损失有助于保留细节。
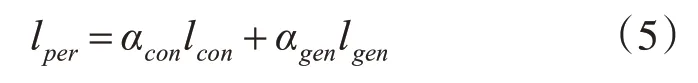
其中αcon和αgen分别是各自损失的权重。
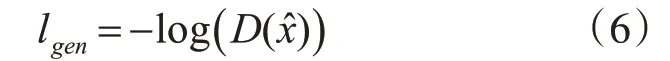
其中D(·)代表判别器网络,x^ 代表去噪图像。
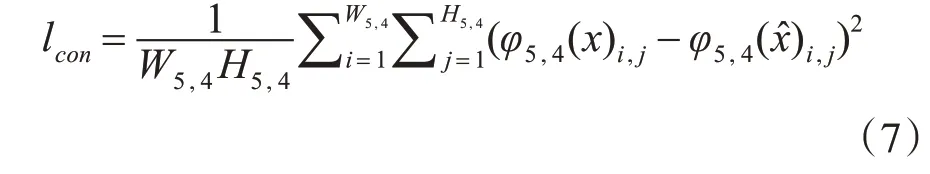
其中φ5,4(·)表示VGG19 网络中第5 个最大池化层之前的第4次卷积(激活后)得到的特征图,W5,4和H5,4分别代表特征图的宽度和高度。文献[9]证明了从这一层提取的特征图可以更好地恢复纹理细节。
为更好指导网络的训练及图像的生成,本文加入WGAN-gp 作为判别损失。WGAN-gp 的判别器损失为

其中lMSE代表感知损失,αMSE代表MSE 损失的权重,lper代表感知损失,lWGAN-gp代表判别器损失。
4 实验结果与分析
4.1 数据集
生成器网络以RGB 图像作为输入并输出去噪图像。在训练过程中,噪声图像的噪声为均值为零的独立同分布高斯噪声,并使用DIV2K数据集[20]作为训练数据集。DIV2K 数据集是用于图像恢复任务的高质量(2K 分辨率)彩色图像数据集。DIV2K数据集包含800张验证图像、100张验证图像和100张测试图像。本文将提出的去噪网络与其他取得先进结果的去噪方法在不同的噪声水平上进行比较,结果证明了本文方法的优越性。
4.2 训练细节
本文所用的实验环境为NVIDIA TITAN XP GPU,对于每个小批量数据集采用从高分辨率训练数据集中随机选取的16 个分辨率为100×100 的子图像。本文将输入噪声图像的范围缩放到[0,1],并将地面真实图像(不含噪声的图像)缩放到[-1,1]。因此,MSE损失是根据强度范围[-1,1]的图像计算出来的。本文使用β1=0.9 的参数进行Adam算法[21]优化。训练分为两个阶段。在第一阶段,先预训练生成器网络并使用值为1 的MSE 作为损失函数来指导优化。生成器网络以10-4的学习率和4×105的更新率进行训练。在每2×105次迭代后将学习率除以10。在第二阶段,使用最小化的细节损失来优化生成器网络。内容损失和对抗损失的权重分别为0.007 和0.002,MSE 损失的权重为0.002。整个网络的初始学习率为10-4,更新率为2×105。
4.3 评估
图3 为本文网络的主观去噪效果结果图,测试图像为Kodak数据集中随机选取的4张图像。可以看出取得了良好的去噪结果,去噪结果与地面基准图像几乎没有差别,取得了相当良好的实验结果。表1 显示了在峰值信噪比(PSNR)通常用来衡量图像的去噪性能。表1 比较了本文提出的去噪网络和几种当今优秀的去噪网络的去噪性能,分别与CBM3D、MCWNNM、DnCNN 和DeepDenoising 网络进行比较,使用的测试数据为Kodak 数据集,加粗字体为结果较好的数据值。从表1 可以看出,本文提出的去噪网络在不同的噪声水平上显示出一定的优越性。

图3 kodak不同测试图像的去噪结果
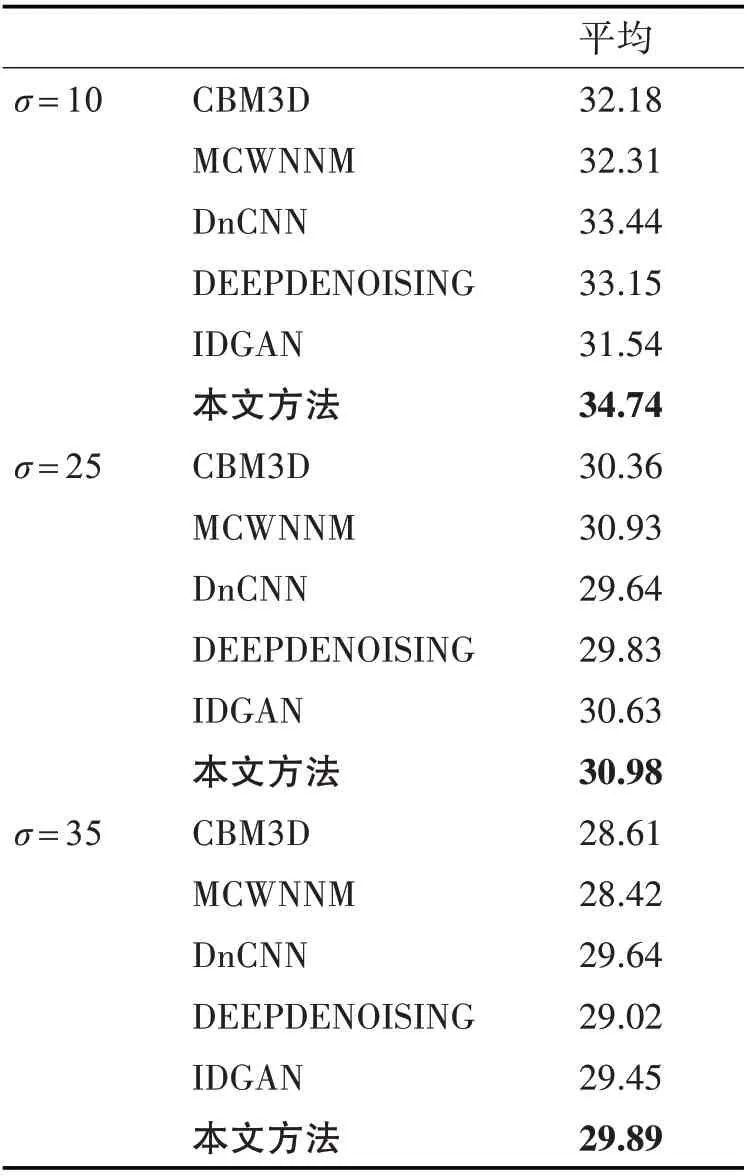
表1 不同方法在Kodak数据集上的PSNR
图4为来自Kodak数据集的图像去噪效果。其中图(a)为地面基准图像。图(b)为CBM3D 针对图(a)白框部分的去噪结果,图(c)为DnCNN,图(d)为DEEPDENOISING 去噪结果,图(e)为IDGAN 去噪结果,图(f)为本文网络的去噪结果。在图4可以观察到,在细节上本文网络去噪后的图像更加清晰,虽然经其他深度去噪处理后的图像在细节上与本文的去噪网络一样清晰,但细节更像高频伪影。相比之下,本文网络去噪细节在清晰的同时更有真实感。

图4 去噪效果对比图

5 结语
本文采用改进型生成对抗网络用于图像去噪。该网络生成器采用SRDenseNet,使得生成的去噪数据更具真实感。同时WGAN-gp 的采用加速了训练进程,使得训练过程更为稳定。本文提出的损失函数可以很好地衡量去噪图像与地面真实图像间的细节差异,同时损失函数的最小化使得处理后的边缘图像变得清晰,纹理丰富区域的细节得到更好的保留。在去噪过程中,如何应对真实环境下的复杂噪声,是本文今后要做的重点工作。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
电脑报(2022年24期)2022-07-01
计算技术与自动化(2022年1期)2022-04-15
舰船科学技术(2021年12期)2021-03-29
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·二年级语数英综合(2019年10期)2019-11-08
中国新通信(2017年9期)2017-05-27
饮食科学(2016年7期)2016-07-27
读者·校园版(2015年19期)2015-05-14
