
基于两阶段粒子群优化算法的新型逐步分解集成径流预测模型
2022-02-15 07:14郭田丽宋松柏王慧敏
水利学报 2022年12期
郭田丽,宋松柏,张 特,王慧敏
(1.西北农林科技大学 水利与建筑工程学院,陕西 杨凌 712100;2.西北农林科技大学 旱区农业水土工程教育部重点实验室,陕西 杨凌 712100)
1 研究背景
径流预测可为各类涉水工程的规划设计、运行管理以及水资源管理提供依据。由于全球气候变化和高强度人类活动的双重作用与影响,径流序列表现出复杂的非线性和非平稳性,加大了径流预报工作难度[1]。
现有径流预测模型可分为过程驱动和数据驱动两大类。相比于过程驱动模型,数据驱动模型可操作性强,无需考虑径流发生的物理机制,仅需对时间序列进行数学分析,建立输入变量和输出变量之间的函数关系。近年来,机器学习因其强大的学习能力,在水文领域得到了长足的发展,并广泛应用于径流预测工作中[2-3]。其中,支持向量机(Support vector machine,SVM)模型具备结构简单、容错性强、能克服维数灾以及过拟合问题等优点,在大量径流预测研究中得到成功应用[4-6]。但由于径流序列呈现出高度复杂的非平稳性、非线性和不确定性,单一预测模型的预测能力受限。耦合奇异谱分析、集合经验模态分解、小波分解和变分模态分解(Variational modal decomposition,VMD)等数据分解方法与机器学习模型来建立分解集成模型可有效改进单一机器学习模型的预测精度[7-9]。其中,VMD方法能够控制中心频率混叠现象和噪声水平,更易于提高分解集成模型的预测性能[10-12]。
建立分解集成模型来提高径流预测精度已成为当前研究热点之一[13-15]。但是,这类模型首先将整个径流序列分解成若干个子序列,再将这些子序列划分为训练期和验证期,这种先分解后划分法会导致研究者在训练模型之前,提前使用了验证期数据,难以满足实际预报需求[16]。对于单变量分解集成模型,模型是将当期预测径流和前期径流作为预测模型的下一步预报因子,显然在验证模型的预测性能时,当预测径流需要依靠预测模型预测。若将上述先分解后划分法用于构建单变量分解集成模型,会导致验证期内的预报因子数据被视为已知数据处理。Du等[17]和Fang等[18]对比分析了多种分解集成水文预测模型的结果,发现将验证期内预报因子数据当作已知数据去构建分解集成模型会得到“虚假”的高精度预测结果。分解集成模型的正确构建过程需先将实测序列划分为训练期和验证期,再将训练期数据进行分解建模,但其预测精度相对降低[19]。为此,Fang等[18]提出一种逐步分解采样技术来构建正确的分解集成模型,以期提高正确分解集成模型的预测精度。该逐步分解采样技术可作为分解集成模型的替代采样技术,但使用该技术构建的分解集成模型的预测精度依旧较低。因此,如何正确构建能应用于现实径流预报工作中的较高精度分解集成径流预测模型尚需深入研究。
上述研究均旨在提高和改进模型的点预测性能,但点预测结果仅为一个确定数值,难以描述由于径流序列随机性和波动性而导致的预测不确定性。把握未来径流数据的波动范围和预测的不确定性,有助于研究者做出更加科学合理的分析、评估和决策。区间预测可通过参数或非参数密度估计方法估计点预测误差的分布特性,进而构建一定置信水平下的预测区间,可在一定程度上体现预测的不确定性。与参数估计模型相比,非参数核密度估计(Kernel density estimation,KDE)方法不需提前假设误差样本服从的分布函数,避免因误差分布选取错误导致出现较大预测误差问题[20]。KDE方法已广泛应用于区间预测研究中,例如,Li等[21]提出了基于分数阶灰色模型与KDE方法的混合模型,并将该模型用于农业用水量预测,Guo等[22]构建了基于自激励自回归模型与KDE方法的地下水埋深区间预测模型,王晓东等[23]将分位数回归、长短记忆神经网络与KDE方法进行结合,构建了风电功率概率预测模型。这些研究结果均表明,KDE方法可通过结合适宜的点预测模型产生较高精度的区间预测结果。
本文提出一种可同时进行点预测和区间预测的VMD-SVM-KDE逐步分解集成模型,并提出两阶段粒子群优化(TSCPSO)算法来优化模型参数。该模型可解决现有分解集成预测模型错误使用验证期内预报因子数据的问题,并能提高分解集成模型的预测精度。VMD-SVM-KDE-TSCPSO模型可有效解决传统分解集成模型被错误开发和预测精度较低的问题,拓展该类模型在实际预报业务中的可应用性。
2 方法
2.1 变分模态分解方法VMD分解方法是一种新型自适应、完全非递归的数据分解方法[24]。该方法通过搜索约束变分问题的最优解,将原始信号x分解为一系列固有模态函数(Intrinsic mode functions,IMFs)。

(1)
式中:K为IMFs的个数;{μk(t)}={μ1,μ2,…,μK}为第k个模态分量;μk(t)为第k个模态分量在第t时刻的值;{ωk}={ω1,ω2,…,ωK}为第k个模态分量对应的中心频率;t为时间;∂t为函数对时间t的一阶偏导数;δ(t)为单位脉冲函数;j为虚数单位;⊗为卷积运算。
利用增广拉格朗日函数得到式(1)变分问题的最优解,如式(2)所示。
(2)
式中:α为二次惩罚因子;λ为拉格朗日乘子。λ(t)为λ在第t时刻的值;x(t)为x在第t时刻的值。利用交替方向乘子迭代算法求解式(2)的鞍点。
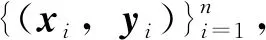
y=wφ(x)+b
(3)
式中:w为权重向量;φ(x)为映射函数;b为偏置向量。
根据结构风险最小化原理,式(3)的求解可转化为求解以下最小化问题:
(4)
式中:C为惩罚因子;e=[e1,e2,…,en]T为误差变量。
引入拉格朗日函数和对偶理论,并用核函数代替式(3)的映射函数,可得到:
(5)
核函数的选取对SVM的计算精度至关重要。常用的核函数有线性核函数、多项式核函数、径向基(Radial Basis Function,RBF)核函数和Sigmoid函数。RBF核函数对于大小样本都具有较高的计算精度,学习能力强,参数也相对较少。因此,本文选用RBF核函数,如式(6)所示。
(6)
式中γ为RBF核函数参数。
因此,对于SVM模型,主要的待求参数有惩罚因子C和核函数参数γ。
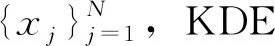
(7)
式中:N为样本长度;h为带宽;K2(·)为核函数。
核函数和带宽的选择对KDE计算影响较大。本文选用高斯核函数,公式为:
(8)
对应的带宽公式为:

(9)
式中S为样本的标准差。
3 模型构建
本文提出的VMD-SVM-KDE-TSCPSO模型的总体框架如图1所示。基于TSCPSO优化算法的VMD-SVM-KDE逐步分解集成(VMD-SVM-KDE-TSCPSO)模型的构建步骤包括以下两步。第一步,根据VMD-SVM模型获取点预测结果。具体步骤为:将径流序列划分为率定期、测试期和验证期,使用VMD方法逐步分解率定期和测试期的径流序列获得子序列,根据这些子序列确定SVM模型的输入输出序列,并用TSCPSO优化算法综合求解VMD-SVM模型的未知参数,最后,根据VMD-SVM模型计算点预测值。第二步,根据点预测误差,采用KDE方法计算区间预测结果。VMD-SVM-KDE-TSCPSO模型的具体构建步骤如下。

图1 VMD-SVM-KDE-TSCPSO模型框架
3.1 数据划分首先,将径流序列x(t)(t=1,2,…,N)划分为训练期xT(t)(t=1,2,…,T)和验证期xv(t)(t=T+1,T+2,…,N),其中N为整个径流序列长度x(t)的长度,T为训练期序列xT(t)的长度。为防止模型过拟合,进一步将训练期xT(t)划分为率定期xc(t)(t=1,2,…,c)和测试期xt(t)(t=c+1,c+2,…,T),其中c为率定期序列xc(t)的长度。率定期、测试期和验证期径流序列长度依次占整个数据的比例为60%、20%和20%。

(10)
式中:xnorm为样本的归一化结果;xmin和xmax分别为样本的最小值和最大值。

(11)
求出未知参数(L,K,C,γ)后,保存训练好的分解集成模型等待预测。
3.3 模型预测令k=T,重复3.2小节中的分解步骤,直至k=N-1。不同于训练期的是,只需将预测因子输入训练好的混合模型中,然后获得验证期的所有预测值,也就是点预测值。
区间预测的构建步骤为:首先计算训练期的误差,然后根据KDE方法计算误差的概率密度函数,并积分得到相应的累积密度函数,据此获取一定置信水平a的分位数值F1-(1-a)/2(t)和F(1-a)/2(t),最后根据式(12)可得预测区间[xlow(t),xup(t)]。
(12)
式中:xlow(t)和xup(t)分别为t时刻预测区间的下限和上限;F1-(1-a)/2(t)和F(1-a)/2(t)为累积密度函数的分位数;给定的置信水平a也称为名义置信水平。
3.4 模型评价为了验证VMD-SVM-KDE模型的预测优势,将VMD-SVM-KDE与SVM-KDE模型进行比较。同样,为了验证TSCPSO优化算法的优势,将TSCPSO算法与传统的一阶段PSO优化算法进行比较,传统PSO算法没有将训练期进一步划分为率定期和测试期。具体地,首先将PSO优化的SVM(SVM-PSO)模型、TSCPSO优化的SVM(SVM-TSCPSO)模型、PSO优化的VMD-SVM(VMD-SVM-PSO)模型以及TSCPSO优化的VMD-SVM(VMD-SVM-TSCPSO)模型进行对比,分析评价模型的点预测性能。然后将PSO优化的SVM-KDE(SVM-KDE-PSO)模型、TSCPSO优化的SVM-KDE(SVM-KDE-TSCPSO)模型、PSO优化的VMD-SVM-KDE(VMD-SVM-KDE-PSO)模型以及TSCPSO优化的VMD-SVM-KDE(VMD-SVM-KDE-TSCPSO)模型进行对比,分析评价模型的区间预测性能。
模型的点预测性能均由平均相对误差(MAE)、最大均方根误差(RMSE)、确定系数(R2)和纳什效率系数(NSE)4个误差指标进行评估。MAE和RMSE越小且R2和NSE越大,表示模型的点预测性能越好。区间预测性能由预测区间覆盖率(PICP)、预测区间平均宽度(PINAW)和区间平均偏差(INAD)3个误差指标进行评估[25]。PICP小于预测区间名义置信水平时,说明区间预测结果不可信。在PICP达到预测区间名义置信水平的前提下,PICP越大且PINAW越小代表区间预测性能越好。当不同模型的PICP和PINAW值相差不大时,可用INAD进行比较择优。INAD越小代表模型性能越好。
4 实例应用
4.1 数据分析为验证文中模型的适用性,选取黄河流域民和、兰州、白马寺和黑石关4个水文站的月径流数据进行预报模型研究。各水文站月径流数据资料均来源于水利部黄河水利委员会,其统计特征如表1所示。由表1可知,兰州站的月径流量均值依次小于民和站、黑石关站和白马寺站,离差系数依次大于民和站、黑石关站和白马寺站。各水文站月径流数据的偏度系数均为正数,民和、兰州和白马寺3站月径流数据的峰度系数均小于3,表明曲线峰值比正态分布低,而黑石关站的峰度系数大于3,表明曲线峰值比正态分布高。按照整个径流序列长度的60%、20%和20%及时间先后顺序依次划分率定期、测试期和验证期。因此,民和、兰州和黑石关3站的率定期长度为30 a,白马寺站率定期长度为31 a,测试期和验证期长度均为10 a。

表1 月径流数据的统计特征
4.2 模型的点预测结果将SVM-PSO、SVM-TSCPSO、VMD-SVM-PSO和VMD-SVM-TSCPSO这4种模型分别记为模型1、模型2、模型3和模型4,表2为以上模型的参数识别结果。由表2可知,各站SVM模型参数C和γ以及模型的输入参数L随着模型种类变化。对于模型的输入参数L,模型1在各站中的识别结果均为10,模型2在民和、兰州和黑石关站的识别结果分别为80、69和94,模型3在兰州站的识别结果为18,模型4在黑石关站的识别结果为50。除此之外,其余结果都大于100。对于VMD分解个数的识别结果,除了模型4在兰州站为5之外,其他均为4。

表2 模型参数结果
表3列出了各模型在训练期和验证期点预测性能的评价结果。在整个训练期,民和站各模型拟合精度由高至低依次为:模型1、模型3、模型4、模型2;兰州站各模型拟合精度由高至低依次为:模型1、模型2、模型4、模型3;白马寺站各模型拟合精度由高至低依次为:模型1、模型4、模型3、模型2;黑石关站各模型拟合精度由高至低依次为:模型1、模型3、模型2、模型4。由此可见,研究区各站均是模型1的拟合性能最优,且模型1的R2和NSE值均接近于1,MAE和RMSE值也非常小,而其余三种模型的拟合性能在研究区水文站点表现各不相同。进一步比较两种单一模型的拟合性能发现,对于各站径流序列均是模型1的拟合性能优于模型2。对比混合模型的拟合性能发现,对于民和和黑石关站,模型3优于模型4,而在兰州和白马寺两站,模型4的拟合性能则优于模型3。
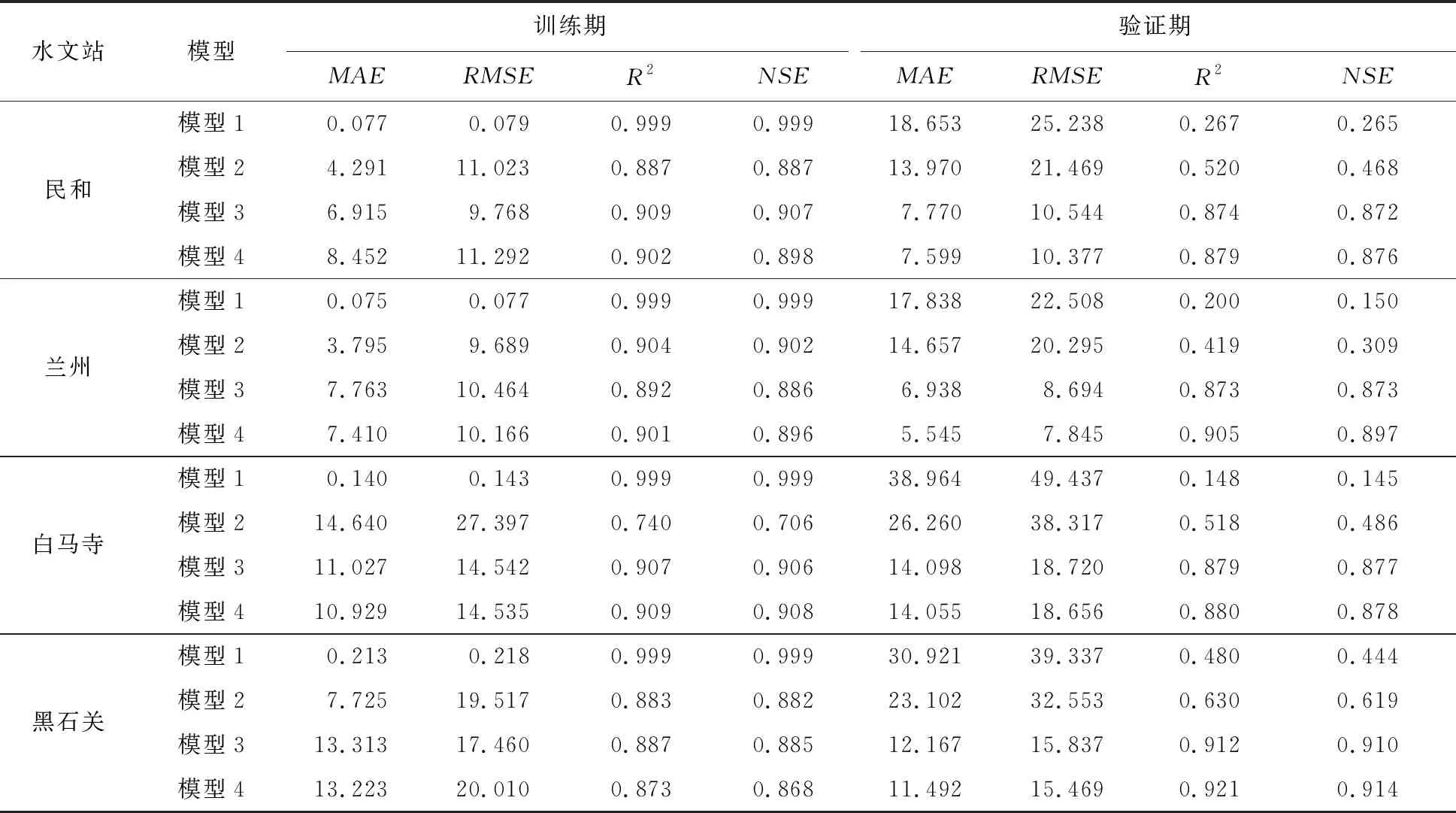
表3 各模型在训练期和验证期的点预测评价结果
表4为TSCPSO优化模型在率定期和测试期的模型精度评价结果。在率定期,模型2在民和、兰州和黑石关三站均优于模型4,而白马寺站则相反。模型2在民和、兰州和黑石关站的R2和NSE值均接近1,且MAE和RMSE值较低。在测试期,模型4在各站的性能均优于模型2。而在训练期,模型4在民和和白马寺两站均优于模型2,而在兰州和黑石关站则相反,表明TSCPSO优化模型(模型2和模型4)在率定期、测试期和训练期对于各站的性能表现存在差异。

表4 TSCPSO优化模型(模型2和模型4)在率定期和测试期的评定结果
为更好分析各模型在验证期的预测性能,图2展示了实测值和预测值的散点图,图中黑色线条和红色线条分别代表1∶1线和线性拟合线。对比模型1和模型2在验证期各站预测结果可知,模型2的散点分布较1∶1线更紧凑,线性拟合线偏离1∶1线也更近,MAE和RMSE值更小,R2和NSE值更大,且模型2将模型1的MAE值由17.838~38.964降低至13.970~26.260,RMSE值由22.058~49.437降低至20.295~38.317,R2和NSE值由0.145~0.480提升至0.309~0.630,表明TSCPSO优化的SVM模型性能优于普通PSO优化的SVM模型。对比模型3和模型4的预测结果可知,模型4将模型3的MAE值由6.938~14.098降低至5.545~14.055,RMSE值由8.694~18.720降低至7.845~18.656,R2和NSE值由0.872~0.912提升至0.876~0.921,表明TSCPSO优化的VMD-SVM模型性能优于普通PSO优化的VMD-SVM模型。以上结果表明相较于普通PSO算法,TSCPSO算法可以提高单一模型和分解集成模型的点预测精度。与两种单一模型(模型1和模型2)相比,混合模型(模型3和模型4)在各站均表现出更高的NSE和R2值及更低的MAE和RMSE值,且混合模型将各站单一模型的MAE值由13.970~38.964降低至5.545~14.098,RMSE值由20.295~49.437降低至7.845~18.720,R2和NSE值由0.145~0.630提升至0.872~0.921。

图2 各站径流序列的预测结果散点图
从图2可以进一步看出,两种单一模型的散点分布分散,散点拟合线偏离1∶1线较远,表明模型的整体预测能力较差,尤其是对极值的预测能力。而两种混合模型的散点分布集中,拟合线距离1∶1线较近,整体预测与极值的预测结果均表现较好,表明混合模型较单一模型的预测性能有较大提升。整体来看,各模型预测性能由高至低依次为:模型4、模型3、模型2、模型1;其中,模型4在各站的预测精度最高,R2和NSE值均为0.9。
分析模型在训练期和验证期性能可知:模型1对训练期径流数据拟合度较高,误差较小,但该模型在验证期的预测精度较低,表明模型存在过拟合问题。模型2在训练期的拟合性能较差,但验证期的预测精度却优于模型1,而模型3和模型4的预测精度也表现出类似的规律,表明相比PSO算法,TSCPSO算法可以改善模型过拟合问题,进而提高模型的预测性能。
4.3 模型的区间预测结果表5列出了各模型在90%置信水平下的区间预测评价结果。图3进一步给出了模型的点预测和区间预测结果,图中蓝色散点代表实测径流值,黑色线条代表预测值,灰色区间为预测区间。

表5 各模型的区间预测性能评价结果

图3 各站径流序列的预测结果图
对于单一模型,SVM-KDE-TSCPSO模型的PICP值远大于SVM-KDE-PSO模型,而PICP均小于名义置信水平,表明单一模型的区间预测结果不可信。对于混合模型,仅VMD-SVM-KDE-PSO模型在白马寺站的PICP值小于名义置信水平,其区间预测结果不可信,而其余PICP值均达到名义置信水平,且混合模型的PICP值均大于单一模型,说明混合模型提高了单一模型的区间预测覆盖率,且混合模型将单一模型的INAD值由0.046~95.844降低至0.005~0.034。对比混合模型的PICP和PINAW值可知,VMD-SVM-KDE-TSCPSO模型的PICP和PINAW值均大于VMD-SVM-KDE-PSO模型,表明VMD-SVM-KDE-TSCPSO模型的覆盖率略高于VMD-SVM-KDE-PSO模型,但区间宽度却略宽于VMD-SVM-KDE-PSO模型。由此可见,两种模型的区间预测性能相近。进一步比较混合模型的INAD值可知,VMD-SVM-KDE-TSCPSO模型在各站的INAD值均为最小,范围为0.005~0.014,说明VMD-SVM-KDE-TSCPSO模型的区间预测结果最优。
以上分析结果也表明:相较于传统的一阶段PSO算法,TSCPSO优化算法有效提高了单一模型和分解集成模型的区间预测精度,并将普通PSO算法优化模型的INAD值由0.007~95.844降至0.005~0.195,其中将单一模型的INAD值由48.813~95.844降低至0.046~0.195,将分解集成模型的INAD值由0.007~0.034降低至0.005~0.014。
4.4 讨论Du等[17]和Fang等[18]的研究表明:将验证期内预报因子数据当作已知数据,构建分解集成模型会导致“虚假”的高精度预测结果,使该类模型难以满足实际预报工作。而本文提出的VMD-SVM-KDE-TSCPSO模型先将径流序列分解为率定期、测试期和验证期,然后逐步分解径流序列得到子序列,最后根据率定期和测试期的子序列数据,应用TSCPSO优化算法训练模型的4个未知参数。由此可见,该模型在训练模型时并未使用验证期数据,这说明该模型可解决传统分解集成预测模型存在的错误使用未来预测因子数据的问题。并且,本文构建的VMD-SVM-KDE-TSCPSO模型在正确开发的基础上,在各站的R2和NSE值均达到约0.9,且预测区间覆盖率高,宽度窄,说明该模型具有较高的点预测和区间预测精度。因此,可将VMD-SVM-KDE-TSCPSO模型应用到实际预报工作中。
5 结论
为提高径流预测精度并量化预测结果的不确定性,本文提出一种新型VMD-SVM-KDE逐步分解集成模型和新型TSCPSO优化算法进行径流的点预测和区间预测。选用黄河流域4个水文站的月径流数据对模型性能进行评估。通过对比SVM-PSO、VMD-SVM-PSO、SVM-TSCPSO和VMD-SVM-TSCPSO模型的点预测结果,以及SVM-KDE-PSO、VMD-SVM-KDE-PSO、SVM-KDE-TSCPSO和VMD-SVM-KDE-TSCPSO模型的区间预测结果,研究结果表明:(1)VMD-SVM-KDE模型将单一SVM-KDE模型的R2和NSE值由0.145~0.630提升至0.872~0.921,INAD值由0.046~95.844降低至0.005~0.034,说明VMD-SVM-KDE模型可以显著改进单一SVM-KDE模型的点预测和区间预测性能;(2)相较于传统的一阶段PSO算法,TSCPSO优化算法将单一模型的R2和NSE值由0.145~0.480提升至0.309~0.630,INAD值由48.813~95.844降低至0.046~0.195,将分解集成模型的R2和NSE值由0.872~0.912提升至0.876~0.921,INAD值由0.007~0.034降低至0.005~0.014,说明TSCPSO优化算法可以克服SVM的过拟合问题,并能提高单一模型和分解集成模型的预测精度;(3)VMD-SVM-KDE-TSCPSO有效解决了传统分解集成预测模型存在的错误使用验证期内预报因子数据的问题,并在各站的R2和NSE值均约为0.9,INAD值的范围为0.005~0.014,具有更高的点预测和区间预测精度,可为分解集成水文预测模型的正确建立提供参考,也可为非平稳非线性水文序列的实际预报工作提供依据。
猜你喜欢
水利水电快报(2022年8期)2022-11-23
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
黑龙江大学自然科学学报(2022年1期)2022-03-29
一重技术(2021年5期)2022-01-18
品牌研究(2020年32期)2020-08-09
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中国外汇(2019年13期)2019-10-10
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
人民珠江(2019年4期)2019-04-20
电子制作(2018年11期)2018-08-04
