
基于改进遗传神经网络的农业观光旅游竞争力评价
2022-02-15 02:33韩燕妮
湖北农业科学 2022年22期
韩燕妮
(咸阳职业技术学院财经学院,陕西 咸阳 712000)
国家产业结构调整和国民收入的逐步提升让旅游产业成为国民经济中的重要组成部分[1]。农业观光旅游作为一种面向现代城市人的新兴旅游方式,各级地方政府都对其投入了大量资源。面对农业观光旅游产业的发展,如何客观有效地对农业观光旅游景点进行竞争力评价显得尤为重要。戴湘毅等[2]从政策支持、经济情况、历史文化、基础设施建设、产业规模5 个角度来构建农业观光竞争力评价指标。冼炜轩等[3]通过SPSS 软件,运用最邻近距离分析法、核密度估计空间分析法和数理统计方法对密云区乡村休闲旅游的竞争力进行评价。Wardana 等[4]采用问卷调查法并使用SEM-PLS 进行数据分析,得出政策支持是乡村旅游竞争力的重要因素。Jia等[5]研究基于修正迈克尔波特钻石模型的城镇级乡村旅游经济力评价与发展分类模型。国内学者目前对农业观光旅游竞争力评价的研究大多数还处于比较初级的阶段,采取的方法也多是调查问卷和数理统计方法,旅游竞争力评价指标设计也大多采用传统旅游业的竞争力评价指标,不能展示农业观光旅游的特点。针对这些不足,本研究用一种改进的遗传神经网络来构建竞争力评价模型,并引入7 种综合指标来构建农业观光旅游竞争力评价体系,以期提高评价的客观性和准确性。
1 改进遗传神经网络模型的构建
1.1 遗传算法改进方案
遗传算法具备很强的随机性,在解决变量较多且混合整数非线性规划特征的问题时容易陷入局部最优解,收敛质量差,离散变量多次变化[6]。针对以上问题,本研究对传统遗传算法进行改进:扩大种群规模并提升种群多样性;采用自适应交叉、变异分布指数以提升算法收敛性;采用二阶段求解方式简化问题,降级计算难度。扩大种群数量可以有效提升种群多样性,改善算法收敛精度低和收敛速度慢的问题。首先对标准遗传算法所有个体变量进行归一化处理,见式(1)。在式(1)中,xmax、xmin分别为该变量的最大值、最小值。

此时整个种群的离散程度见式(2)。
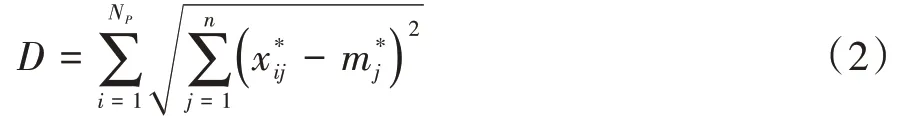
式(2)中,D是整个种群的离散程度,为归一化后变量x在j节点的权重,i、j分别是输入层和输出层的节点个数,x*ij是输入层到输出层的权重,n为变量的个数,NP是种群的数量。
设交叉分布指数为ηc,其取值和种群离散程度相关。由于初始种群是均匀分布的,此时种群离散程度D0最大,对应ηc,min,随后,ηc与D成反比。在极端情况下,全部个体都收敛于全局最优解,此时D=0,对应ηc,max,每次迭代都会对D进行更新,最终的自适应交叉分布指数见式(3)。
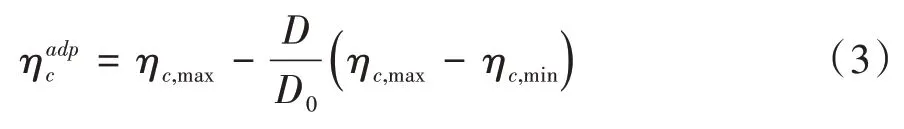
为了加大现有搜索范围,还要进行变异操作,变异分布指数见式(4)。

二阶段求解方法将时间划分为4 个相等的片段,在第一阶段,将时间片段1 和时间片段3 视为一个时间片段进行联立求解,得到第一阶段的最优解。以此来构建出时间片段2 和时间片段4 的初始种群,然后再将时间片段2 和时间片段4 视为一个时间段,以第一阶段的最优解作为初始种群进行联立求解,见式(5)。

式(5)中,βnt是0~1的随机数,xtn是第t个时间片段的第n个变量,σt是根据分布式变化大小设置的偏置变量,以保证初始种群能靠近最优解。此时再利用自适应遗传算法进行二阶段求解,即T2 和T4联立求解,最后将2 个阶段的解结合,就能得到最优解。二阶段求解方法将求解次数减少1/2,且在二阶段求解时能节约大量迭代时间,加速求解。根据整个改进算法流程,收敛条件的判断条件为迭代次数是否大于m代以及历史最优个体是否保持n代不变。由于在极端情况下,生成的某个个体会非常接近最优解,会导致在初始n次迭代都不能产生更加优秀的个体而结束流程,因此必须设置一个迭代次数m。将2 种收敛条件结合能够有效提升最优解的上限并能节约计算时间。增加遗传算法的种群数量能够增强算法的性能,但会大幅度增加计算时间,而二阶段求解法并不能完全解决这一问题。为了减少计算时间,还需要对遗传算法进行并行处理。遗传算法具有天然并行性,并行机也比较普及。常见的并行模型有主从模型、孤岛模型、领域模型和混合模型[7]。此次研究采用混合模型,对多核架构性能的评价主要是用加速比,求加速比的方式是用串行时间除以并行时间。目前的评价模型主要为固定任务模型和固定时间模型[8]。假设有p个并行机组成1个性能更高的并行化运行平台,每个运行节点的性能为1,p个节点所创建的串行性能为perf(p)。加速比见式(6)。

式(6)中,T1是串行计算机的时间,Tp是该算法在p个处理机组成的并行机上的运行时间,Sp为加速比。假设问题为w,每个计算节点执行任务的时间见式(7)。

并行化运行平台的基本执行时间见式(8)。
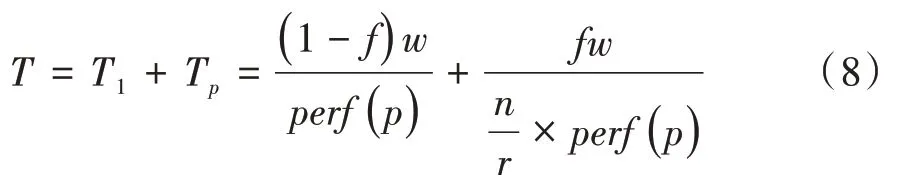
将式(8)代入到式(6),可得式(9)。

设perf(p)=c,c为常数,可得式(10)。

当c= 1 时,系统功效提高的程度和总时间及执行方式有关,见式(11)。

在式(8)至式(11)中,f是并行处理部分在整个系统的占比,1-f是串行处理部分在整个系统的占比。m是并行处理机数量,Speedup是加速比。主从模型的加速比呈现线性增长,在负载固定的情况下适用。当群体规模固定且子群体的规模和数量成反比时,孤岛模型的加速比和主从模型的加速比趋势相同。
1.2 农业观光竞争力评价指标体系构建
农业观光旅游产业竞争力指标体系的构建原则是要将旅游产业和农业的特点结合[9]。由于农业观光旅游产业具有时节性、区域性、独特性、市场性、不可复制性等特点,其竞争力综合性很高,“软”实力和“硬”实力都具备。因此,在选取评价指标时要遵循科学性、系统性、区域性和季节性、代表性和滚动型五大原则[10]。根据以上原则,确定了7 个指标,第1个指标是政策支持指数P,当某乡村的政府给予该地区旅游项目政策优惠时,P= 1,否则,P= 0。第2个指标是交通便利指数G,交通便利指数的计算公式见式(12)。
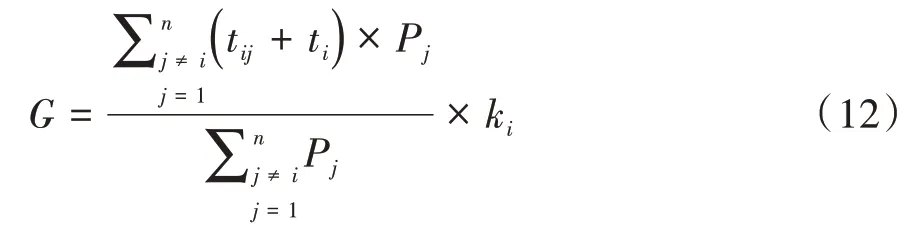
式(12)中,tij是乡村i到最近的城区j的最短时间距离,ti是城市内部交通阻力,Pj为当地人口总数。第3 个指标是旅游业影响指数A,指该地区旅游业在所有产业中的影响力。其计算公式见式(13)。

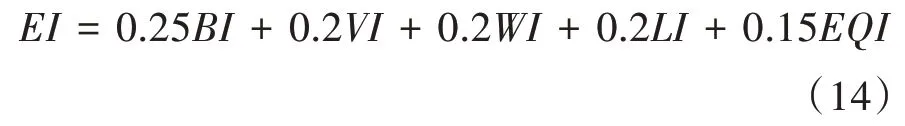
式(14)中,BI、VI、WI、LI、EQI分别为生物丰富程度、植被覆盖率、水网密度、土地退化程度、环境质量指数。第6 个指标反映了该地区在线旅游的发展情况,用T表示,该数据在中国在线旅游发展的大数据报告中查看。第7 个指标是人文和历史资源指数,用H表示,它采用官方公布的历史文化旅游资源评价体系进行计算,通过对该地区历史文化资源进行加权计算得到。具体评价体系见表1。

表1 历史文化旅游资源评价体系
由表1 可知,此评价体系给历史文化体系定下3个指标,分别是固有价值、旅游价值和历史文化感。固有价值是资源本身具有的价值,例如存在的时间够长,具有文化、民族或地域特点,有一定科研价值。而旅游价值指游客能够通过欣赏该资源获得的满足,从美学角度、体验角度和教育角度3 个角度来评价。历史文化感指赋予给该资源的主观看法,主要从地区的整体风貌格局、历史文化和传统文化3 个角度来诠释其具有的文化感。
2 改进遗传神经网络的训练和预测
2.1 遗传神经网络参数设置
通过搜集中国已经投入运营的农业观光旅游景点的数据,随机筛选出100 个景点样本作为神经网络的训练样本,仔细挑选5 个样本作为预测样本,预测样本数据如表2 所示。使用的数据来源于中国统计局发行的各省份《统计年鉴》和各省市政府官网公布的相关数据,通过上述的评价体系计算得到最终值。
由表2 可知,样本1—3 号具备政策支持,而4—5 号没有政策支持;在交通便利指数上5>1>4>2>3;在地区旅游业影响指数上,1、3、5 号样本具有较高影响力,都占据40%以上,2 号样本不到30%,而4 号样本几乎没有;在特色产业规模指数上,3 号样本为1.2%,而1 号样本只占0.2%,2 号和5 号样本为0.4%左右,4 号样本有0.6%;在生态环境指标上,由于选取的样本都属于开发程度不高的乡村,差距都不大,1 号和2 号样本具备较大的优势;在线旅游发展指数上,1—3 号样本发展较好,4—5 号较差;历史资源指数方面,除5 号样本几乎不具备历史资源,其他4 个样本都有一定的历史资源。

表2 预测集样本数据
当研究的对象不是线性问题时,在选择传递函数时多采用Sigmoid 函数,该函数在预测分类问题时只需要一个隐藏层。因此神经网络层数的隐含层为一层。神经网络的输入样本为100 个,每个样本由7个节点(即农业观光的7 个评价因素),最终输出有5个节点,分别为极优(1,0,0,0,0)、优(0,1,0,0,0)、良(0,0,1,0,0)、中(0,0,0,1,0)、差(0,0,0,0,1)。深度堆叠神经网络是目前的主流,在进行相关研究时通常使用三层网络结构,隐含层节点设定不能太多也不能太少,太多会导致神经网络泛化能力差,太少会导致无法产生足够的连接权组合。根据Kolmogorve 原理及类似研究的试验成果[11],本研究的隐含层节点数设置为14 个。由于数据经过归一化处理,本研究的输出值被限定在(0,1),输出层的传递函数最好是logsig 函数,隐藏层的传递函数最好是正切函数tansig 函数[12]。设置的最大迭代次数为10 000,目标误差设置为0.001。种群数量为50,交叉概率为0.6,变异概率为0.05,中间结果周期为50。常用的神经网络训练函数有Traingd 函数、Traincgf函数、Trainlm 函数和Traingdx 函数等,依次采用这4种训练函数进行训练。根据训练结果,Traincgf 函数和Trainlm 函数在迭代300 次左右趋于收敛,收敛后波动较小,具备较强的收敛性,但它们在收敛后陷入了局部最优解,迭代10 000 次结果无法达到期望的误差值;Traingdx 函数无论是收敛性和最终结果都不如其他3 种训练函数。Traingd 函数收敛性较低,但误差下降速度很快,且在9 000 多次迭代后达到预期的误差。经过综合考虑,本研究选择Traingd 函数作为神经网络训练函数。至此,模型需要数据和参数都准备完毕。
2.2 改进遗传神经网络的实际应用
将100 个训练数据归一化处理后,用Traingd 函数对改进遗传算法和标准遗传算法进行训练,选取适应度作为评价指标,统计50 个中间结果周期的性能追踪曲线,改进遗传算法由于扩大了种群规模,在10 个周期前的适应度是低于标准遗传算法的。在经过多次迭代后,在10 个周期左右反超,且在15 个周期前就趋于稳定,能搜索到更优的权值阈值,而标准遗传算法趋于稳定的周期在20 个周期左右。相比标准遗传算法,改进遗传算法适应周期缩短30%左右,适应度提升10%左右。由于训练样本的7 种指标的量级和单位差别很大,在进行计算时会影响网络的收敛性,所以需要将数据进行归一化处理,以节省神经网络训练时间。将训练样本的100 个数据分别输入标准遗传神经网络和改进遗传神经网络,将竞争力评价分为极优、优、良、中、差5 个等级,100个训练样本的结果如图1 所示。

图1 标准遗传神经网络和改进遗传神经网络训练数据对比
由图1 可以看出,标准遗传神经网络在训练集中的评价和实际评价有较大差距,明显误差在15%~20%,甚至有个别评价和实际评价出现评级差距。而改进遗传神经网络对于训练集样本的评价基本符合实际评价,即使有少部分存在误差,但没有产生评级差距。为了进一步展示2 种遗传网络的差距,使用“2.1”中仔细挑选的5 个样本作为预测集,使用训练后的2 种遗传网络进行竞争力评价。结果如图2 所示。
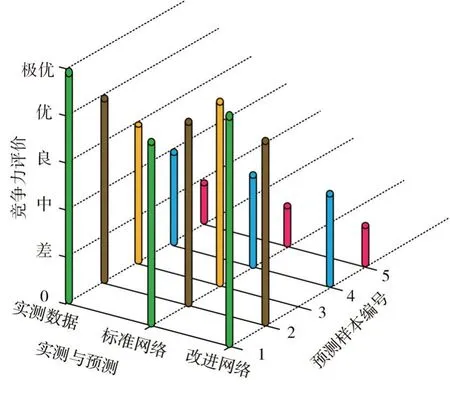
图2 标准遗传神经网络和改进遗传神经网络预测数据对比
由图2 和表2 可以看出,样本1、2、3 号的7 种指标各有优劣,且数值差距不大,此时,标准遗传神经网络无法对它们的旅游竞争力进行客观评价,只能将它们分到同一级,而改进遗传神经网络评价和实际评价相同。4、5 号样本和1、2、3 号样本存在明显差距,且4、5 号之间的侧重点也有明显差异,所以2种遗传神经网路都能将它们正确分类。
3 小结
在中国推进供给侧结构性改革的浪潮下,农业观光旅游作为旅游业的新宠却在竞争力评价指标上问题频出。本研究将深度学习引入农业观光旅游竞争力评价,并构建出一种综合考虑自然、人文、经济、政治等多方面的评价体系,让旅游竞争力评价更加客观准确。在遗传算法优化方面,通过遗传算法并行的方式解决扩大种群规模后遗传算法效率降低的问题,整体效率相较于标准遗传算法提升30%。并采用二阶段求解方法,改进遗传神经网络的权值,有效规避遗传神经网络陷入局部最小值的困境。重新设定遗传网络的阈值,提高了遗传神经网络在处理分类问题上的性能。本研究的不足之处在于选取的训练样本数量较少,样本地域相对集中,不能代表全国的情况,在以后的研究中,应增加样本的数量和地域范围,以期获得更好的结果。
猜你喜欢
南方农机(2023年18期)2023-08-28
河南科技(2023年1期)2023-02-11
Chinese Physics B(2022年5期)2022-05-16
黑龙江交通科技(2020年5期)2020-01-13
有机氟工业(2019年2期)2019-08-12
重庆行政(公共人物)(2018年4期)2018-09-11
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
智能系统学报(2015年4期)2015-12-27
