
基于代价敏感半监督的跨项目软件缺陷数预测模型
2022-02-14 03:15:26高晶
沈阳工程学院学报(自然科学版) 2022年1期
高 晶
(烟台职业学院 信息工程系,山东 烟台 264670)
随着网络的蓬勃发展与日益普及,软件在社会工作与生活中起着至关重要的作用。若部署了含有缺陷的软件,极有可能引发不堪设想的后果。因此,精准预测出软件缺陷具有重要的现实意义。为了降低缺陷修复代价,应在项目开发初期就完成项目中潜在缺陷程序模块的识别,预测对象主要为模块中的缺陷、缺陷数及缺陷密度等。众多相关学者对软件缺陷预测技术展开研究,以满足更新换代较快的软件需求。
文献[1]提出基于文件粒度的多目标软件缺陷预测方法,通过对比无监督学习方法与有监督学习方法间的性能,设计了一种多目标优化的MULTI方法,基于FL-SDP 问题对两个不同的优化目标进行设定,采用Logistic回归方法完成预测模型训练,将FL-SDP 问题转换为经典的二元分类问题后,对模块是否存在缺陷实施判定。文献[2]研究了一种两阶段的软件模块缺陷数预测特征选择方法,FSDNP 方法中的阶段分为特征聚类与特征选择,前者采用密度峰聚类算法划分相关性较高的缺陷特征,后者通过启发式排序策略,对冗余、无效特征进行滤除。文献[3]则架构了一种基于深度自编码网络的软件缺陷预测方法,通过无监督学习采样策略,采集不同开源项目数据集,从而避免数据集出现类别不平衡,利用创建的深度自编码网络模型,降维数据集特征,经过连接3 种分类器对其进行训练,最终完成测试集预测。
由于上述方法多数是用于预测同项目软件缺陷,无法精准预测存在较大差异的源项目与目标项目数据集,所以本文设计了一种基于代价敏感半监督的跨项目软件缺陷数预测模型。依据选取的度量元集合,收集各版本源代码,应用搜索下载的方式,采集缺陷数据。经过在源代码中提取度量元,将其与缺陷信息一一对应,完成度量元矩阵构建,采用清洗、集成、规约及变换对数据进行预处理,随后设定属性复杂度的阈值为中位数,得到最终采样结果。利用设计的代价敏感半监督支持向量机,划分样本数据集,通过对预测模型实施训练学习,实现缺陷数预测。
1 代价敏感半监督下跨项目软件缺陷数预测模型设计
1.1 数据分析
1.1.1 数据采集
数据的采集阶段不仅是预测跨项目软件缺陷数的基本,也是预测模型设计的重要环节。在软件开发阶段,相关数据一般为软件源代码[4]、开发人员沟通历史记录、有关文档和缺陷追踪信息等。其中,软件缺陷主要存在于软件源代码信息与历史缺陷信息中。跨项目软件缺陷数据的采集共分为以下5个阶段:
1)度量元集合的合理选取
作为软件缺陷预测模型的输入部分,度量元可以实现源代码缺陷信息的挖掘。因为度量元数量会随着数据信息量的提升而增多,所以由较多度量元所组建的模型将具有更理想的预测精准度。但是,当度量元增加到一定数量时,高维数据就会引发过拟合问题,降低预测性能。因此,为了使预测模型性能达到最佳状态,应通过斯皮尔曼等级相关系数[5]的选择方法对合适的度量元进行选取。
已知X=(X1,X2,…,Xn)与Y=(Y1,Y2,…,Yn)为两个变量,经过排列Xi与Yi的顺序,获得xi与yi,则采用下列公式对斯皮尔曼等级相关系数进行运算:
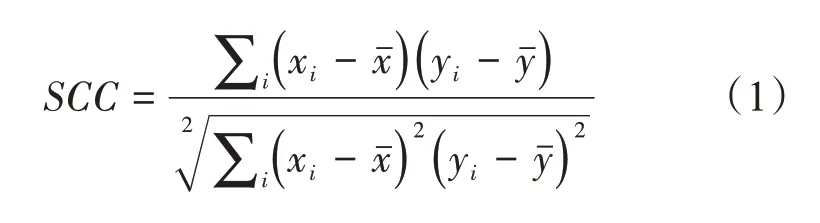
其中,xi与yi的均值分别为xˉ和yˉ。由式(1)可以看出,度量元和缺陷数量的关联性与斯皮尔曼等级相关系数成正比,依据斯皮尔曼等级相关系数降序排列度量元,所选取的度量元集合由序列中前N个度量元架构而成。
2)源代码收集
由于大部分项目的源代码均被储存于代码仓库,以便于项目协作与代码管理,所以开发人员只需运用版本控制工具,就可以完成每个版本的源代码收集任务。控制工具的选取主要由项目数据托管平台种类决定。
3)缺陷数据采集
收集源代码数据后,要从Bugzilla 与Jira 的Bug跟踪系统里采集与源代码相对应的缺陷信息。因为两系统性能相似,所以数据提取方法也大致相同,通过搜索下载就能够完成,最后将获取的缺陷数据与软件源代码文件进行联立。Bugzilla开源缺陷跟踪系统的缺陷信息统计如表1所示。
表1 缺陷信息统计表
4)度量元提取
静态分析统计源代码就是度量元的提取过程,可以通过诸如OOMeter、semmle等提取工具完成。
5)度量元矩阵架构
各矢量均为代价敏感半监督支持向量机的输入,分类标签则是缺陷信息,依据取得的度量元与缺陷信息,将两者进行一一对应后,即可得到度量元数据矩阵。
1.1.2 数据预处理
预处理阶段由清洗、集成、规约及变换组成。在软件模块内,提取的标签值主要用于缺陷存在判定,采集的度量属性如表2 所示。若数据有属性值缺失现象,则利用属性期望值进行填充。

表2 数据集度量元统计表
为了避免发生对0 取对数的情况,通过引入极小值方法,完成属性值的对数化预处理,其计算式如下所示:
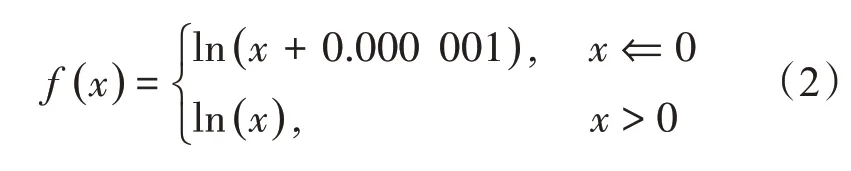
式中,x为属性值。
1.1.3 数据采样
由于缺陷预测数据呈不均匀分布状态,只有部分数据存在缺陷,所以基于源代码度量元与缺陷之间的潜在相关性,制定理想的采样策略。通过观察缺陷数据与非缺陷数据的度量元数值可知,存在缺陷的模块度量元数值相对更高。将属性中位数作为衡量属性复杂度的阈值,通过保证所选样本不存在过低的缺陷率,使模型性能得到提升。图1 所示为数据采样流程。
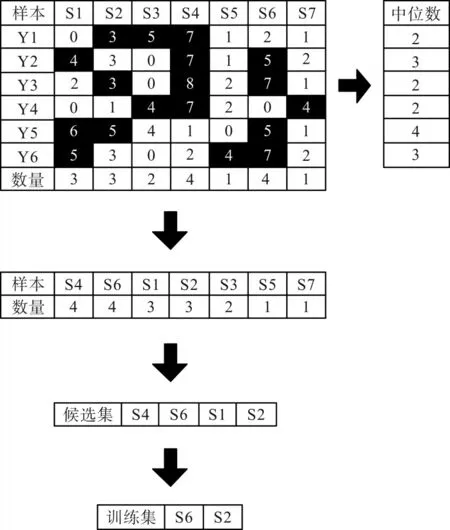
图1 数据采样流程
图1 中,软件样本属性值为Y1~Y6,样本集合为S1~S7。如果待采样的带标签样本[7]有N个,则采样步骤描述如下:
1)对所有模块的属性中位数进行求解;
2)针对各样本属性值,若大于该属性中位数,则称之为高属性值;
3)将高属性值个数降序排列,得到新的样本列表;
4)选取列表的前2N个样本构成候选集;
5)对候选集内的N个样本进行随机抽取,并将其作为最终的采样结果。
1.2 代价敏感半监督支持向量机
通过寻求一个代价敏感半监督支持向量机的超平面,最小化分类整体代价,该方法通过代价敏感[8]学习思想的引入,实现半监督支持向量机的算法扩展。已知一个含有带标签样本与无标签样本的数据集:带标签样本呈独立分布,设为{(x1,y1),…,(xl,yl)},l表示带标签样本的数量;无标签样本属于同一分布,表示为{(xl+1,yl+1),…,(xl+u,yl+u)},u为无标签样本数量,分类标签y∈{± 1} 。假设Il={1,2,…,l} 为带标签样本,Iu={l+1,l+2,…,l+u}为无标签样本,错误地将有缺陷样本划分为无缺陷样本的代价为c(+1),把不存在缺陷样本划分为存在缺陷的代价为c(-1),则代价敏感半监督支持向量机的代价矩阵如表3所示。
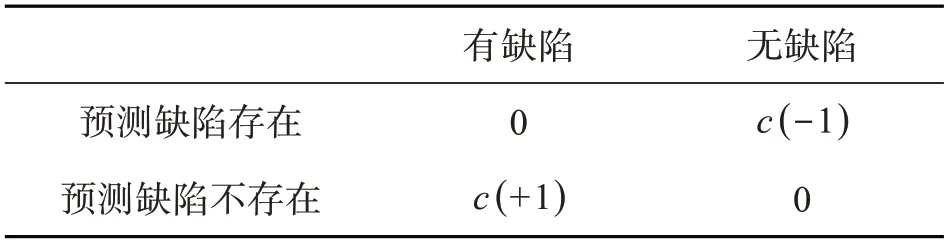
表3 代价矩阵
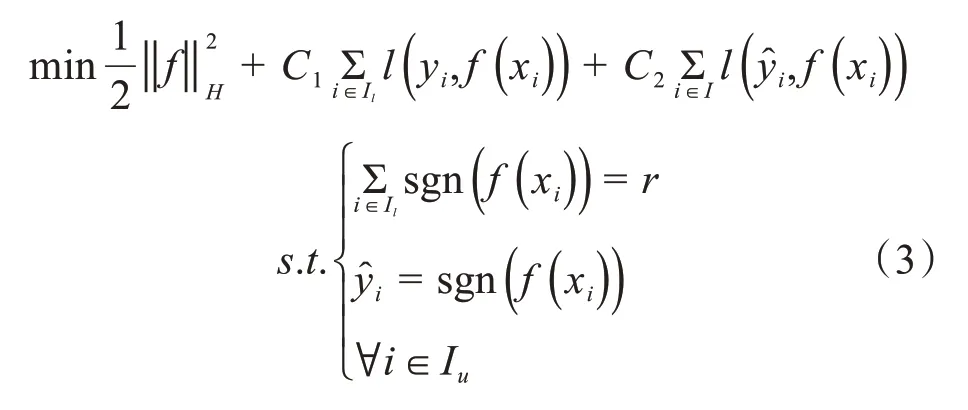
式中,H为核函数k产生的再生核希尔伯特空间;l(yi,f(xi))为加权损失函数[9];C1与C2为正则化参数;r为模型设置参数,主要是为了避免将训练集全部无标签样本划分至一个类别里。
对训练集合内带标签样本与无标签样本的错分率与复杂度进行权衡,加权损失函数如图2 所示。如果c(+1)=c(-1),则该函数为标准对称函数,此时的代价敏感半监督支持向量机转换为半监督支持向量机模型;若c(+1)≠c(-1),损失函数值将呈现连续性。
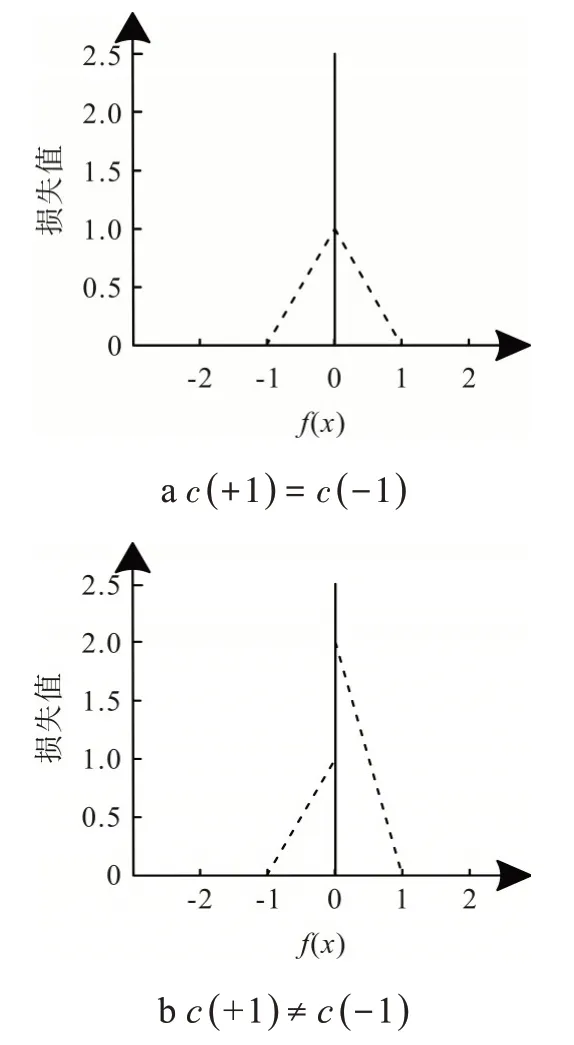
图2 损失函数
新参数代价比率的引入实现了代价添加对预测模型性能的影响评估,下式即为参数代价比率表达式:
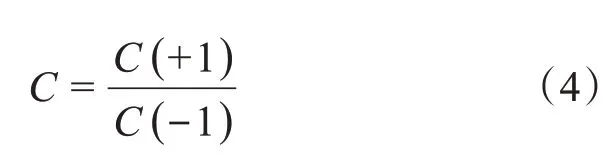
C取不同值,得到相应的预测性能数据,从而评估性能发挥程度。
1.3 跨项目软件缺陷数预测模型架构
基于代价敏感半监督支持向量机的最小化分类代价目标,创建跨项目软件缺陷数预测模型,流程共分为以下5个步骤:
1)通过分析缺陷数据特征,对合适的度量元进行选取;
2)按照清洗、规约等顺序,预处理所得数据集;
3)标记采样的数据样本,并将任意选取的无标签样本与带标签样本进行组合,得到训练样本;
4)合理设定模型参数值;
5)对预测模型实施训练学习,利用学习到的模型对测试集所含的缺陷数实施类标签预测。
基于代价敏感半监督的跨项目软件缺陷数预测模型架构流程如图3所示。

图3 预测模型架构流程
2 仿真实验
2.1 实验环境
仿真实验环境的硬件部分为英特尔酷睿i5-3337U1.8GHz 处理器,运行内存为6 GB,操作系统为64 位Windows10,软件部分是Matlab R2013a 版本[10]。
实验数据集由5 个开源项目的16 个版本所构成,各项目含有11 个静态代码特征与类别标注,将类作为程序模块的粒度。
预测模型仿真过程中,选取查全率recall与查准率precision对软件模型性能进行评估,计算公式如下所示:
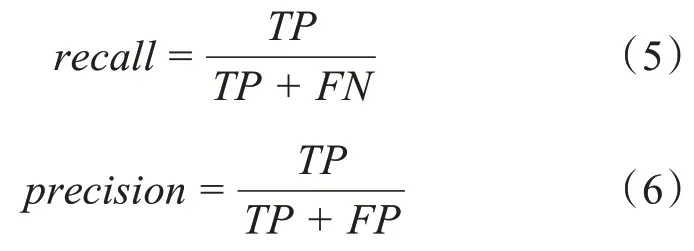
式中,TP表示实际存在缺陷且分类正确;FP表示实际不存在缺陷且划分正确;FN则表示实际不存在缺陷但分类错误。
查全率是指所有缺陷被预测正确的占比,查准率是指预测为缺陷的数量与实际缺陷数的比值。
由于两指标的评估效果比较片面,所以采用F1 指标将其进行综合,以有效达成模型性能评价,计算公式如下:
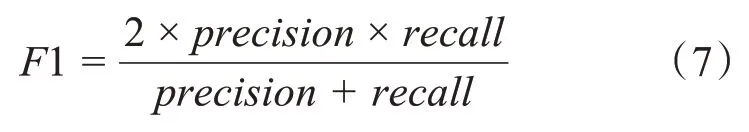
由式(7)可知,模型性能与F1值成正相关。
2.2 性能对比分析
为了验证本文模型的通用性与有效性,分别利用静态软件缺陷预测方法与本文模型,对数据集进行一对一形式与多对一形式的跨项目缺陷数预测模拟实验。实验数据均为独立操作5 次的运行结果均值,两者的比较曲线如图4和图5所示。
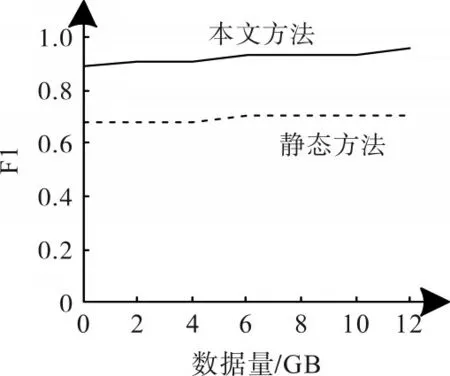
图4 一对一形式下跨项目预测对比
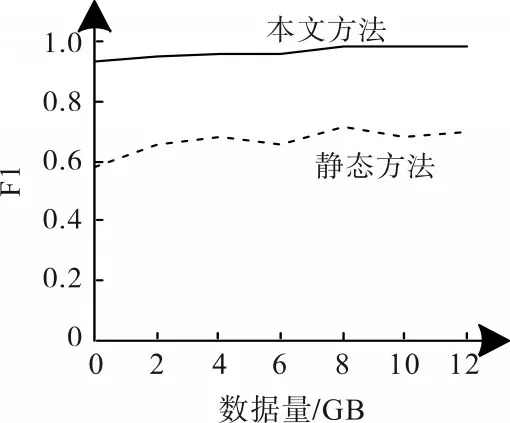
图5 多对一形式下跨项目预测对比
通过图4 可以看出,本文模型的F1 均值相比静态预测方法增加了28.5%,且曲线走势一直位于较高水平。
根据图5 可知,基于多对一形式的跨项目预测,对比静态预测方法,本文模型的F1均值大幅度提升,增幅约为30.7%,波动状态较为平稳,说明本文模型的预测性能具有显著的稳定性。
3 结论
针对新启动的软件项目,搜集理想的缺陷预测数据集是一项挑战。所以,本文创建一种基于代价敏感半监督的跨项目软件缺陷数预测模型。根据度量元对软件源代码信息与历史缺陷信息的数据进行采集,经过预处理,分析非缺陷数据与缺陷数据的度量元值关系;采用中位数阈值完成数据采样,依据代价敏感半监督支持向量机的超平面,对样本存在的缺陷情况进行分类;通过整合带标签样本与无标签样本,架构训练样本,从而使测试集缺陷数预测得以达成。该模型为未来的研究工作奠定相关理论基础,提供重要数据资料,具有广阔的应用前景与重要的实践价值。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
现代信息科技(2021年21期)2021-05-07 21:44:50
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
中国司法鉴定(2018年4期)2018-07-30 06:08:26
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
中国房地产业(2016年8期)2016-03-01 01:25:55
中学生(2015年12期)2015-03-01 03:43:53
