
临床研究中统计学方法的规范应用与典型案例解析
2022-02-14 02:26郑德强段明瑞李小春侯锐吴立娟王友信
中国卒中杂志 2022年1期
郑德强,段明瑞,李小春,侯锐,吴立娟,王友信
统计学为医学临床研究提供了数据分析的工具和方法,正确、规范使用统计学方法是开展高质量临床研究的重要保障,统计学方法应用正确与否直接关系到学术论文质量的高低。统计学方法的正确应用可以使研究成果具有科学性、代表性,如果使用不当或误用,会直接影响研究结果的质量,甚至会导致错误的结论。越来越多的医学工作者已经充分意识到统计学方法在临床研究中的重要性,但是在实际应用中可能会出现一些错误,相关文献报道医学类研究论文中统计学方法的误用率在25%以上[1-2]。本文主要针对临床研究中统计分析的4个方面——统计描述、统计推断、数据处理、结果解释,采用典型案例解析方式,对临床研究中统计学方法规范应用要点、常见误用进行总结分析,为临床研究规范统计分析提供参考。
1 统计描述方法的规范应用与典型案例解析
临床研究中,描述研究对象某种特征的指标称为变量(variable),如问卷调查中的“年龄”“性别”“职业”“学历”“收缩压”“空腹血糖”等。临床研究中,研究人群中不同个体变量测量值的数据集合称为资料,依据变量值的特点,将研究资料分为定量资料(如“年龄”“空腹血糖”测量值的集合)和定性资料(如“性别”“学历”测量值的集合)。
1.1 两种类型资料的统计描述
(1)定量资料:又称计量资料。根据其观测值是否连续,可分为连续型变量(如“身高”“体重”“血压”等)测量值的资料和离散型变量(如某医院每天的住院人数等)测量值的资料。当研究资料背后的变量符合正态分布时,以描述;当研究资料背后的变量不符合正态分布时,以M(P25~P75)描述[3]。如某研究比较某地某年城、乡中老年人群4种指标的差异,具体数据见表1。依据经验,临床研究中呈正态分布数据的标准差往往不会大于均数[3-4],而表1中空腹血糖、总胆固醇这两项指标标准差均大于均数,提示空腹血糖、总胆固醇的资料不符合正态分布的可能性较大,采用描述资料集中趋势和离散趋势的统计描述欠妥。
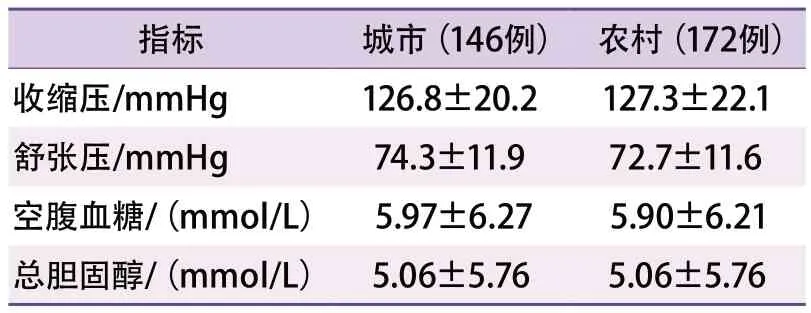
表1 某地某年城、乡中老年人群4种指标比较
(2)定性资料:包括无序定性变量(如“性别”“职业”“血型”等)测量值的资料和等级变量(如“学历”“疗效”“满意度”等)测量值的资料。常见的数据形式为绝对数,如某病的住院人数、治愈人数、死亡人数等。但绝对数往往不具有可比性,因此需要计算相对数。常用的相对数指标包括比、比例和率。如某研究回顾性分析了某医院神经内科2014年1月-2018年11月连续收治的急性脑梗死患者的临床资料,比较两组的临床资料,数据的规范统计描述如表2所示[5]。

表2 两组急性脑梗死患者临床资料比较
1.2 统计表和统计图 临床研究中,对变量进行统计描述时,统计表和统计图是呈现数据分析结果的重要工具。统计表是将研究指标或统计指标及其取值以特定表格的形式列出,结果表达简单明了、层次清晰,便于进一步计算、分析和比较。统计图则是用点、线、面、体等各种几何图形形象化地表达和对比数据的工具,常用的统计图有直条图、累计频率分布图、箱式图、直方图、百分条图、圆图、线图、半对数线图、散点图和统计地图等。
绘制统计表的一般原则:①每个统计表都应有一个表号,按顺序列出。表题需概括表的主要内容,放于统计表上方中央。②纵表头和横表头分别对各行和各列内容或数字的含义进行概括和提示。③统计表线条通常用“三线表”,顶线和底线将表格与文章的其他部分分隔开来,横表头分割线将表头的文字和表格的数字分隔。表内不可出现竖线和斜线。④数字用阿拉伯数字表示。同一指标的小数位数应一致,表内不留空格,数字按照小数位对齐。无数字用“-”表示,缺失数字用“…”表示。⑤表中数字区不允许出现文字,如需对某个数字或指标加以说明,可在其右上方加“*”“#”等符号进行备注,在表下方进行说明。
绘制统计图的一般原则:①根据资料性质和分析目的选择最合适的统计图。描述定性资料或定量资料离散化的频率分布可选用直条图(图1)[6],描述定量资料的频率分布可选用直方图(图2)。②统计图均要有图号及图题,图号应按顺序排列,便于查找和文字中引用,图题要概括统计图资料的时间、地点和主要内容,一般放在图的下方中央,如图1所示。③统计图一般要有横坐标轴和纵坐标轴,对于有横、纵坐标轴的图,要标明尺度,纵坐标轴尺度自下而上,横坐标轴尺度由左至右,数值等距。直方图、累计频率分布图和直条图纵坐标轴的标值要从“0”开始,而横坐标轴的刻度只需表示出观测值的实际范围即可,如图1所示。如果数值差别过大,可以选择中间截断的统计图,如图3所示[7]。④在比较不同的事物和对象的统计量时,宜选用不同的线条或颜色表示,并附图例加以说明,如图4所示[8]。
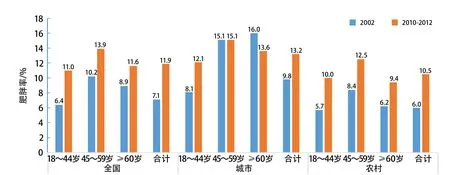
图1 中国成人按地区和年龄段划分的肥胖率直条图

图2 2011年某研究卒中患者年龄分布直方图

图3 美国不同年龄和种族成年人的平均血压值
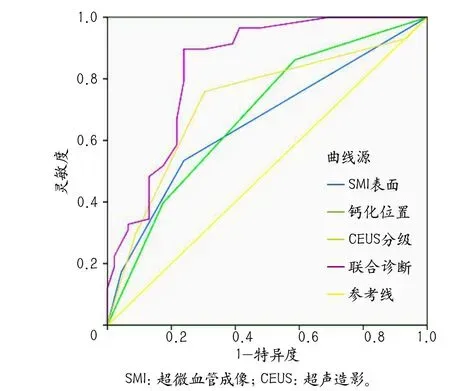
图4 联合诊断与单因素诊断ROC曲线
2 统计推断方法的规范应用与典型案例解析
临床研究中,统计推断是数据分析的核心统计推断所应用的方法,应与数据类型进行匹配。统计推断主要包括假设检验、点估计和置信区间,不同类型的数据对应不同的假设检验方法、参数估计方法,应避免不同类型数据套用或误用统计推断方法。
2.1 定量资料的假设检验 对于定量资料的假设检验,首先,需明确实验设计类型,如单样本、两样本或多样本等,单因素或多因素等;其次,对定量资料进行参数检验,包括独立性、正态性和方差齐性。两样本计量资料进行比较,如果两组资料均符合正态分布且方差齐,选择两样本t检验;如果两组资料符合正态分布但方差不齐,则选择校正的两样本t检验;如果其中一组或两组资料不满足正态分布,则选择Wilcoxon秩和检验。多组单因素计量资料进行比较,如果各组资料均符合正态性和方差齐性,选择单因素方差分析;如果某一组资料不满足正态性或者方差不齐,则选择Kruskal-Wallis秩和检验。如表2中的案例,年龄变量在青中年组和老年组之间的比较,使用两独立样本t检验进行分析,得P<0.001,说明两组年龄的差异是有统计学意义的。定量资料统计推断常见的错误包括多个样本均数的比较误用多个两样本t检验替代方差分析;配对样本t检验与两独立样本t检验相互误用等。
(1)多个两样本t检验与方差分析的误用:t检验适用于单因素一、二水平实验设计类型,每次只能比较两个均数。如果是单因素多水平或多因素多水平等实验设计类型,则不宜使用t检验,因为其会增加犯一类错误的概率。表3为3个年龄组不同性别收缩压水平,若用两样本t检验分别对46~55岁组、56~65岁组和>65岁组的均数两两进行比较,结论为各组之间在男女研究对象中的收缩压水平差异具有统计学意义。但是,应用此种检验方法会大大增加犯一类错误的概率,应选择单因素方差分析,当方差分析差异具有统计学意义的时候,再采用多重比较的方法。常用的多重比较方法有SNK-q检验法、LSD-t检验法、Dunnett-t检验法等[9]。

表3 各年龄组不同性别收缩压水平[单位:mmHg]
(2)两独立样本t检验与配对t检验的误用:配对设计的t检验有自身配对和异体配对之分。表4为自身配对的范例,对急性缺血性卒中患者进行阿替普酶静脉溶栓治疗,治疗前后测得各患者血压值。该资料数据为自身配对设计,有学者把该资料当作两独立样本数据,直接将治疗前后的资料按照完全随机设计定量资料的t检验进行比较,得到t收缩压=5.451,P收缩压<0.001;t舒张压=5.007,P舒张压<0.001,推断患者在治疗前后血压值的差异具有统计学意义。但这种方法与设计类型不匹配,应选择配对设计的t检验,计算各配对数据的差值,比较差值的平均值与“0”之间差异是否具有统计学意义。其统计分析结果为t收缩压=6.842,P收缩压<0.001;t舒张压=8.788,P舒张压<0.001,说明对急性缺血性卒中患者进行阿替普酶静脉溶栓治疗,治疗前与治疗后患者血压差值的差异具有统计学意义。

表4 急性缺血性卒中患者阿替普酶静脉溶栓治疗前后血压水平[单位:mmHg]
2.2 定性资料的假设检验 定性资料的假设检验一般以各个处理组的频数为计量单位,以列联表的形式来表示。一般用于比较两个或多个独立样本频率或独立样本频率分布,配对设计两样本频率分布,单样本分布的拟合优度等。四格表χ2检验需注意其应用条件:样本总数(n)≥40,理论频数(T)≥5。如果n≥40,但某个格子1≤T<5,需进行校正。但是如果n<40或T<1时,使用校正的χ2检验也不正确,此时可以使用Fisher确切概率法检验。如表2所示,男性在两组中所占比例的比较使用独立样本2×2的χ2检验,两组中文化程度的比较使用多个独立样本R×C列联表的χ2检验,P<0.05说明差异有统计学意义。
某研究使用MRI 和CTA 两种方法鉴别急性缺血性卒中,数据见表5。该资料是配对资料,应采用配对四格表χ2检验,由于b+c=12+17=29<40,故需要校正,得到结果=0.552,P=0.458。如果使用独立样本四格表χ2检验,结果为χ2=15.78,P<0.01,则会得出错误的结论。
某研究比较两组神经性头痛的总体有效率,数据见表6,该例中有一个格子的理论频数>1而<5,故不宜直接采用独立样本四格表χ2检验,应使用四格表校正χ2检验或Fisher确切概率法。故该研究的正确结果应为:χ2=3.88,P=0.049。如果使用独立样本四格表χ2检验,结果为χ2=15.78,P<0.01,得出错误的结论。

表6 两组神经性头痛患者的总有效率比较
2.3 回归分析 临床研究中,经常使用相关分析或回归分析来研究两变量之间的相关关系或依存关系,但在应用过程中会出现多种错误,常见错误有直接使用分类的编码数字进行分析,需将分类变量转换为哑变量进行分析,如表7所示。某研究进行卒中后抑郁状态影响因素的logistic回归分析[10],纳入自变量时:将年龄分为4组,以<50岁为参照,其余3组转变为哑变量进行分析;将BMI分为4组,以正常组(18.5~23.9 kg/m2)为参照,其余3组转变为哑变量进行分析。

表7 卒中后抑郁状态影响因素的logistic回归分析
重复测量设计是指对同一受试者的同一观察指标,在不同时间点或不同条件下进行多次观测的设计,由若干受试者得到的多次观测结果称为重复测量变量。由于数据不再满足独立性的特点,故不能直接采用普通的t检验或方差分析进行比较,一般需采用重复测量设计变量的方差分析。但是此种分析方法存在很大局限性,不允许数据缺失,所以,对于更普遍的重复测量数据(如存在少量的缺失值等),分析方法包括广义估计方程、多水平模型等[11]。
某研究比较TIA患者及非神经系统疾病患者入院后7 d、1个月、3个月认知功能评分的变化,数据见表8。该资料设计类型为两因素重复测量设计的定量资料,其中“组别”是试验分组因素,“测定时间”为与重复测量有关的试验因素,误用析因设计进行分析的结果见表9,得到两组之间认知功能差异有统计学意义(P<0.001),但是不同时间的认知功能差异无统计学意义(P=0.100),组别与时间交互差异无统计学意义(P=0.334)。正确的统计推断应采用重复测量方差分析,结果如表10所示,两组之间认知功能差异有统计学意义(P=0.011),不同时间的认知功能差异亦有统计学意义(P<0.001),由于不同组别和时间的认知功能差异均有统计学意义,所以组别与时间的交互作用显著(P<0.001)。

表8 TIA组与对照组MMSE评分变化[单位:分]

表9 析因设计分析结果

表10 重复测量方差分析结果
3 数据处理方法的规范应用与典型案例解析
3.1 离群值的处理 临床研究中,数据离群值的处理对分析的科学性、全面性非常重要。一组数据中往往会出现个别观测值与其他数值相比差异较大,这样的数据称为离群值。只有当有充分理由认为该数据为离群值时,才可以将其删掉进而进行后续统计分析。尤其是当观测数据量较少时,如果未查明离群值产生的原因,直接将其删掉是不合适的,可能会对分析结果产生较大影响。
识别离群值的方法有以下几种:①通过直方图判断。如果观测值落在图形两端并远离均数可能是离群值。②通过箱式图判断。观测值距离箱式图底线(P25)或顶线(P75)的距离为箱体高度(IQR)的1.5~3倍时,被视为离群值;距离>3倍,则被视为极端离群值。③通过统计检验判断。检验观测值偏离程度是否超出随机误差所能解释的上限,超出均值±6倍随机误差的值可能是离群值。④结合其他相关变量信息判断。如青春期儿童生长发育调查中,可以根据儿童身高和体重的线性回归方程判断其体重是否在正常范围内,如果对应身高的体重超出预测值99%置信区间,可认为是离群值。
离群值的处理方法:①如果确定数据有明显逻辑错误,或者因测量或记录过程中出现错误而导致,可直接剔除该数据。如某数据中观测的收缩压280 mmHg(1 mmHg=0.133 kPa),显然是一条错误记录,应予以删除。②如果确定数据无逻辑错误或者排除具有明显逻辑错误的数据后,在数据分析过程中对离群值删除前后分别进行一次统计分析,若结果不矛盾,则不删除;若结果矛盾,需要删除,并予以充分合理的解释。
3.2 缺失值的处理 数据缺失是统计资料中最常见的问题,如果不对其进行处理往往会损失信息甚至导致结果误读,所以对缺失值的识别和处理是数据预处理中最关键的步骤之一。数据缺失主要有3种,包括完全随机缺失、随机缺失和非随机缺失。
缺失值的处理方法:①明确少数个体存在缺失值,且该变量不是分析的主要变量,可以考虑直接删除存在缺失的个体值或者变量。②填补缺失值。常用的随机缺失填补方法有均值填补法、回归值填补法、末次访视观测值向前结转法和多重填补法等。某研究使用中国健康与退休纵向队列数据,评估中国中老年人群中抑郁症状和心血管疾病发病率之间的关系,采用链式方程的多重填补法对缺失数据进行了填充[12]。一项随访18年的队列研究探讨休闲活动与痴呆发病风险之间的关系,在敏感性分析中对休闲活动相关变量的缺失进行了多重填补[13]。
4 结果解释方法的规范应用
在统计分析之后,科研人员在对统计结果进行解释时需注意以下事项:①根据相关要求和统计规范,应明确表示出所用统计分析方法的名称(如配对样本t检验、随机区组设计方差分析、配对四格表资料的χ2检验等)、统计量的具体值(如t=10.29,F=13.21,χ2=5.68等),尤其对于P值,需给出具体的数值(如P=0.003),而不是仅仅指出P<0.05。②P值的定义为在零假设成立的条件下,出现现有样本统计量以及更不利零假设数值的概率。所以当P<0.05时,不能直接下结论说“差异显著”,正确的说法为“差异有统计学意义”。如抑郁状态组的睡眠质量较非抑郁状态组差,差异有统计学意义(P<0.001),但两组的睡眠时长差异无统计学意义(P=0.405)[10]。③在涉及总体均数或总体率时,除了给出显著性检验结果之外,还应给出95%置信区间。如某研究纳入患者共3000人,其中治愈人数为289人,则治愈率为9.63%(8.78%~12.45%)。④最终给出统计结论时要慎重,横断面研究中与因变量显著相关的变量不能称为风险因素,只有在明确时间顺序下才能称为风险因素,如队列研究中高血压与卒中发生风险增加存在关联,不能将关联关系理解为因果关系[14]。
综上所述,在临床研究中应用统计学方法时:首先,要对数据进行正确的预处理;其次,要根据数据的类型选择恰当的统计描述方法;再次,根据临床研究设计类型和数据类型,按要求选择合适的统计分析方法,切忌盲目套用,甚至误用;最后,给出统计分析结论时,要对结果进行正确解读。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
意林(2019年11期)2019-06-30
领导决策信息(2018年16期)2018-09-27
诗选刊(2018年7期)2018-07-09
数学学习与研究(2017年3期)2017-03-09
阅读(中年级)(2016年4期)2016-11-19
计算技术与自动化(2014年1期)2014-12-12
新高考·高二数学(2014年7期)2014-09-18
西南学林(2011年0期)2011-11-12
福建中学数学(2011年9期)2011-11-03
