
基于深度学习的网络异常检测和智能流量预测方法
2022-02-11 09:32张娇阳
无线电通信技术 2022年1期
张娇阳,孙 黎
(西安交通大学 信息与通信工程学院,陕西 西安 710049)
0 引言
异常检测[1-2]和流量预测是无线网络数据分析和管理中的重要任务,有利于提高网络的智能化管理水平,实现网络资源的优化分配和按需调度。在边缘计算场景下,异常检测和流量预测任务在距离数据源更近的位置——基站进行计算,以减少移动业务交付的端到端时延,发掘无线网络的内在能力,从而提升用户体验。
现有的异常检测研究工作中,监督学习和无监督学习算法已被广泛应用于流量异常检测研究中。基于有监督学习的异常检测方法依赖于已标记网络正常行为的数据集,然而在实际应用中,没有异常的数据集非常罕见并且获得代价昂贵。无监督学习的异常检测方法中,K均值(K-means)聚类方法[3-4]由于其简易性,被广泛应用到异常检测任务当中。基于 K-means 聚类的异常检测方法通过将数据划分为正常流量集群和异常流量集群的方式来检测异常。但是,该异常检测的方法依然存在一些问题,直接利用聚类算法检测异常可以检测到高流量区域的异常,但会忽略低流量区域存在的异常。另外有基于流量模式的K-means聚类的异常检测方法[5],在大规模长时间序列检测问题中,存在处理区域数量有限、处理数据时长有限等缺陷。
现有的流量预测研究工作中[6],基于统计的方法将无线网络流量预测视为时间序列预测问题,其性能取决于利用哪一种统计模型进行建模,常用的模型包括回归移动平均(ARIMA)、α稳定模型等,但这些基于统计的模型无法同时建模多种因素的影响。为了挖掘无线网络流量数据中隐藏着的复杂依赖性关系,深度学习模型被应用到无线网络流量预测中。文献[7]提出了一种基于深度学习的混合模型进行时空流量预测,采用自编码器建模空间依赖性,同时采用长短期记忆网络建模时间依赖性。但是这种建模方式是有损的,而且需要对每个区域分别进行建模,无法同时获得预测结果。文献[8-9]采用卷积神经网络方法进行建模,可以实现用一个模型对无线网络流量进行预测。然而,空间依赖性不能只局限于与目标位置相邻的区域,以市中心的大学和郊区的大学为例,两个地区属于地理位置不相邻的同种功能区,流量模式存在强相关性,如果仅能学习相邻区域的相关性,会缺失如上例所述的非相邻但功能相同的区域间的重要信息,导致学习效果不佳。上述基于卷积神经网络的研究工作仅能捕获目标区域相邻的局部区域的相关性,不能捕获全局的空间依赖性。非局部神经网络(NLnet)预测方法对全局空间相关性进行建模,但是忽略了不同通信数据间的相关性。
针对异常检测和流量预测任务面临的上述问题,本文提出一种基于特征降维的异常检测方法和多数据集联合预测的移动网络流量预测方法。基于特征降维的异常检测方法首先在全局范围内提取所有区域流量特征,利用特征数据锁定可疑异常出现的网格,再分别对出现可疑异常警报网格中的原始流量数据使用K-means聚类方法进行局部异常检测,本方法可以快速准确检测大规模流量数据的可疑异常,更适用于规模大、持续时间长的蜂窝网络数据。在多数据集联合预测的移动网络流量预测方法中,引入注意力机制学习各个时刻不同业务间的相关性,并利用循环神经网络记忆这种相关性,进一步提高了流量预测的准确度,适用于对历史数据量少、相关业务数据多的活动进行预测。
1 系统模型和数据集描述
1.1 系统模型
系统模型由边缘计算网络架构组成,如图1所示[10],边缘计算架构分为终端设备、边缘、云端三层。终端层由各种设备组成,主要完成收集原始数据并上报的功能,以事件源的形式作为应用服务的输入。边缘计算层由网络边缘节点构成,广泛分布在终端设备与计算中心之间,边缘计算层通过合理部署和调配网络边缘侧的计算和存储能力,实现基础服务响应,边缘计算层的上报数据将在云计算中心进行永久性存储。本文的异常检测和流量预测功能依托边缘计算下沉到基站完成。

图1 边缘计算网络架构Fig.1 Edge computing network architecture
1.2 数据集描述
本文使用的蜂窝流量数据集由意大利电信移动公司提供[11],该数据集是大数据挑战赛的一部分。原始数据集收集了整个米兰城市内每隔10 min的手机活动记录(62天, 300百万条记录,大约19 GB)。米兰市的面积为550 km2,根据基站分布情况,被划分为100 × 100正方形网格。每个正方形网格的大小约为0.235 km×0.235 km,在本节中每一个正方形网格被称为网格或网格区域。米兰市的部分网格区域如图2所示。
在原始数据集中,每条手机流量活动记录均由以下条目组成。
① 网格编号(Square ID):对已划分网格的编号;
② 时间戳(Time-stamp):每一条手机流量活动的时间戳;
③ 接收短消息活动量(SMS-in Activity):某一特定网格内每10 min内接收的短消息活动流量值;
④ 发送短消息活动量(SMS-out Activity):某一特定网格内每10 min内发送的短消息活动流量值;
⑤ 接听电话活动量(Call-in Activity):某一特定网格内每10 min内接听的电话活动流量值;
⑥ 拨打电话活动量(Call-out Activity):某一特定网格内每10 min内拨打的电话活动流量值;
⑦ 互联网活动量(Internet Activity):某一特定网格内每10 min内互联网接入活动流量值;
⑧ 国家代码(Country Code):电话国家代码。
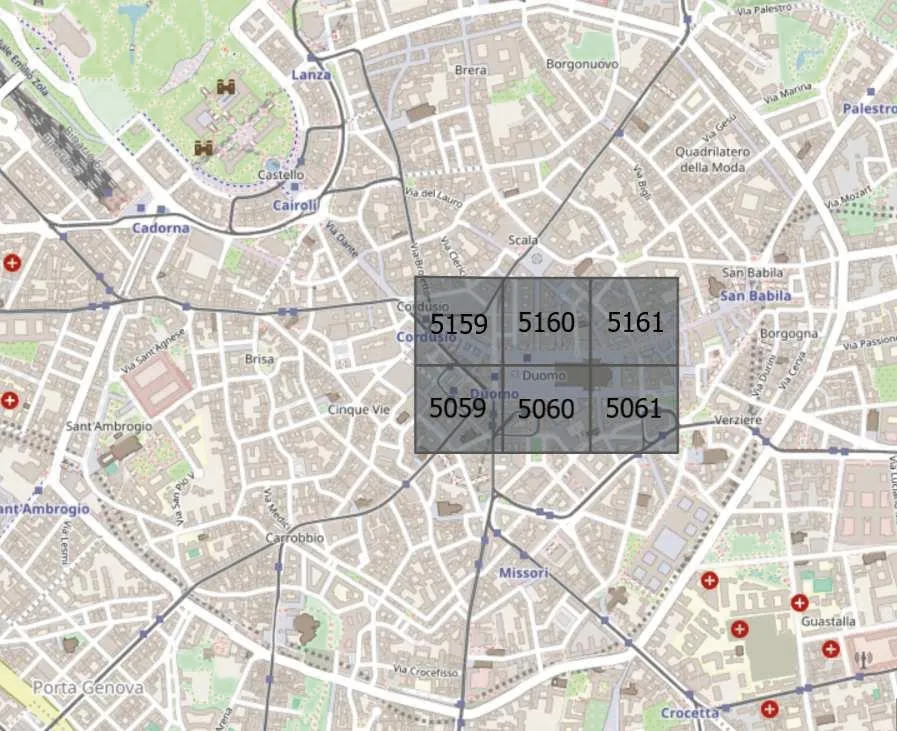
图2 米兰部分网格区域Fig.2 Part of the grid area in Milan
2 基于特征降维的网络流量异常检测方案
2.1 基于长短期记忆自编码器的流量特征提取与异常网格标识
在大规模蜂窝数据异常检测任务中,由于数据收集覆盖范围大,流量数据持续时间长,直接在全局范围对原始数据进行异常检测会花费大量时间,消耗计算机资源。所以在全局范围内异常检测前需要对流量数据进行合理的降维处理,提取高维流量数据的特征,便于获取全局范围内的异常信息。
蜂窝流量数据记录了不同时刻各个网格的流量值,相邻时刻流量值具有强相关性,为了有效提取这种相关性,这里使用长短期记忆(Long Short Term Memory,LSTM)自编码器对原始蜂窝流量数据提取流量特征,使用这一模型可以更好地学习历史时间序列的相关性,同时提取蜂窝流量数据的流量特征,模型框图如图3所示。

图3 LSTM自编码器结构Fig.3 LSTM autoencoder structure
其中,LSTM的网络结构是链式循环的结构[12],能够用来处理长时依赖的问题,一个方块代表一个时刻的LSTM单元,包括3个门:输入门、遗忘门、输出门。输入门控制着网络的输入,遗忘门控制着网络的记忆单元,决定之前的哪些记忆将被保留,哪些记忆将被去除,输出门控制着网络的输出。
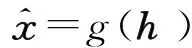
(1)
式中,N代表x的维度,下标i代表向量的第i个分量。
为了保证隐变量h中信息的有效性,在构建自编码器时,通常限制隐变量h输入的维度小于输入数据x的维度,这使得编码器能够完成数据压缩的任务。
经过LSTM自编码器可以得到蜂窝流量数据的低维特征,在新的低维空间找到与整体数据样本表现出来的特点不一致的数据点标记为可疑异常,锁定可疑异常出现的网格,下一步对所有可疑异常出现的网格进行局部异常检测。
2.2 异常流量检测
通过上一步使用LSTM自编码器获得新的蜂窝流量特征,在新的特征空间发现可疑异常出现的网格。获取到所有异常可能出现的网格后,在每个可疑异常出现的网格中对原始数据进行聚类检测异常,将聚类结果中流量值大且同一类中样本数少的样本标记为异常数据。
这里选择K-means[13]进行异常检测,与其他聚类方法相比,K-means算法的时间复杂度更低,占用的计算资源更少,因此,这里选用 K-means算法检测可疑异常。应用该算法时,首先采用戴维森堡丁指数(DBI)确定聚类集群的最佳数目,DBI定义为:
(2)

(3)
mi,j=‖ai-aj‖2,
(4)


(5)
将数据集中的样本划分为若干不相交的子集,每个子集为一个“簇”,通过这样的划分可以寻找出异常数据对应的簇。最后,因为异常流量值与正常流量值有很大的差异,所以异常流量样本将组成单独的集群,将具有最少样本数量且流量值数量级别最高的集群认定为异常。
3 基于注意力机制的多数据集联合预测方案
本节使用经过上述方法剔除异常后的5种数据,包括互联网数据、接听的话音业务数据、拨打的话音业务数据、接收的短消息业务数据和发送的短消息业务数据,然后利用互联网数据和其余业务数据的相关性预测未来的互联网数据。预测模型如图4所示,首先将各类业务分别输入相同的循环神经网络中,记录各时刻的输出,然后将同一时刻所有业务数据在循环神经网络(RNN)单元的输出输入到注意力单元中,计算当前时刻其余业务与目标业务的相关性,各个时刻依次进行相同操作,最后一个时间节点目标业务的输出即为流量预测的结果。
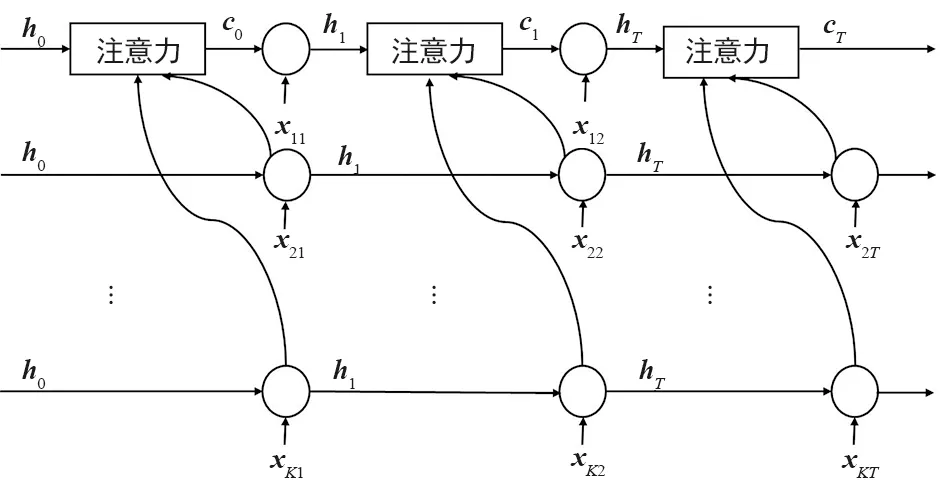
图4 基于注意力机制的多数据集联合预测方案Fig.4 Multi-data set joint prediction scheme based on attention mechanism
以第一个时刻为例,注意力单元内部结构如图5所示。
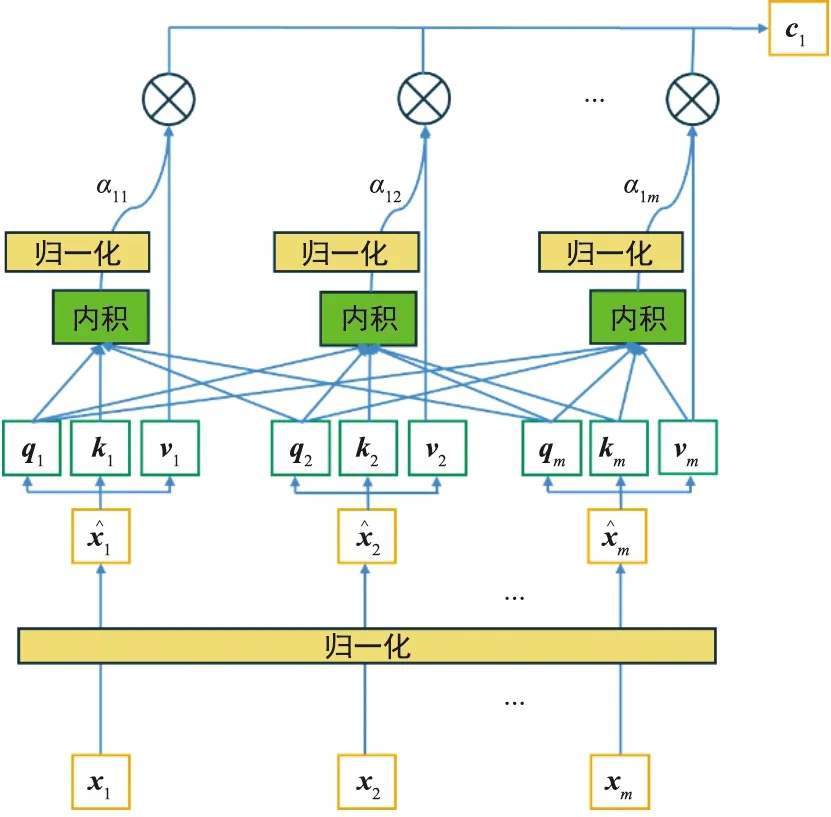
图5 注意力模块内部结构Fig.5 Internal structure of attention module
为保证模型训练正确,将输入模型的数据分别进行归一化,接下来生成查询张量qj、键张量kj、值张量vj,考虑到预测目标是互联网数据,所以仅需要对互联网数据生成查询张量qj。然后根据查询张量qj和键张量kj计算不同数据的相似度α1m。
(6)
最后使用相似度张量和值张量做乘法得到自注意力机制的输出。
4 实验结果
4.1 数据预处理
流量数据根据数据集可知,每个流量活动值(SMS-in Activity,SMS-out Activity,Call-in Activity,Call-out Activity,Internet Activity)表示某一网格在10 min内所有用户的通信强度。在实验中,为了避免数据稀疏,首先将每条流量活动记录的5种活动值相加为一个值,该值描述一个网格内所有用户的总活动量。然后,将数据时间间隔由10 min汇总到1 h。因此,本文中所需检测的异常确切指代高于正常模式的流量值。
4.2 评估指标
为全面评估不同的异常检测算法,将本文异常剔除方案与其他异常剔除方案进行流量预测对比。流量预测过程中,采用了2个评价指标进行评价。
第一个是均方根误差(RMSE),这是度量模型预测值和真实值之间平方差的指标。定义为:
(7)
第二个是平均绝对误差(MAE),这是度量预测值与真实值之间绝对误差的指标,定义为:
(8)
4.3 基准方法
为了证明所提出异常检测效果优越性,将基于特征降维的异常检测方法、经典K-means聚类方法以及基于流量模式的异常检测3种方法进行性能对比。分别对经过3种异常检测方法剔除异常后的流量数据分区域进行预测,输入历史记录中168 h的流量预测未来84 h的流量值,在预测过程中,采用如下的基准方法。
(1) 线性回归模型
回归问题中最简单的模型,模型的具体表示形式如式(9):
y=wTx,
(9)
式中,x代表输入的历史流量数据,w代表要学习的参数。
(2) 支持向量回归模型
支持向量回归(Support Vector Regression,SVR)[14]是支持向量机一个重要分支,其思想在于寻找一个超平面使得所有样本点到其距离最小。
(3) 长短期记忆网络
LSTM网络是深度学习常用模型之一,通过加入门机制解决传统循环神经网络中梯度爆炸和梯度消失的问题,常用于解决有关序列预测和分类的问题。
以上所有模型均取在测试集上表现最好的结果和本文所提出的方法进行比较。
4.4 结果及讨论
4.4.1 异常检测结果
特征降维后的数据可视化结果如图6所示,可以看到异常蜂窝网络数据的特征向量会与正常蜂窝网络数据的特征向量分离,分别记为异常簇和正常簇。

图6 特征空间样本分布Fig.6 Feature space sample distribution
可视化异常簇中出现的网格中的流量数据,以网格3667、3983、4181、4621为例,结果如图7所示。可以看到流量数据整体呈现周期性分布,部分时刻会出现与常规模式不一致的极大值。将这些网格区域标记为可疑异常网格。然后对所有异常网格中的数据使用K-means算法,检测可疑网格中异常出现的具体时刻,结果如图8所示,检测到了可疑网格中出现的流量突增异常。

(a) 网格3667
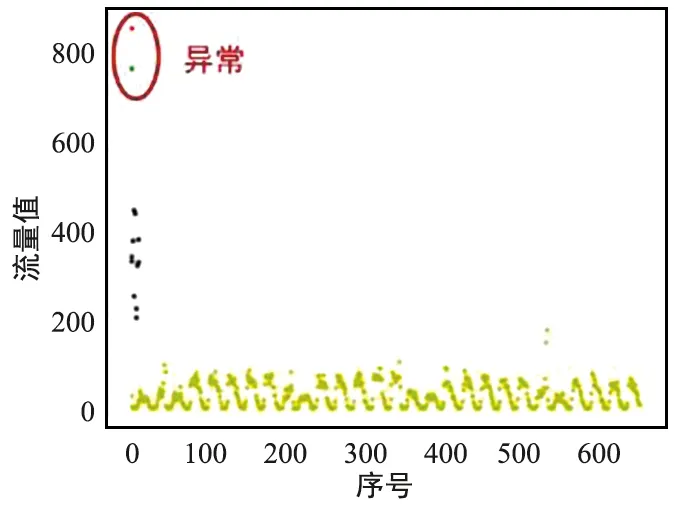
(a) 网格3667
获得异常网格和异常出现的具体时刻后,为了验证异常检测的准确度,对通过该方案剔除异常后的数据进行流量预测,与使用其他异常检测方法剔除异常后的流量预测效果进行对比,结果如表1所示。
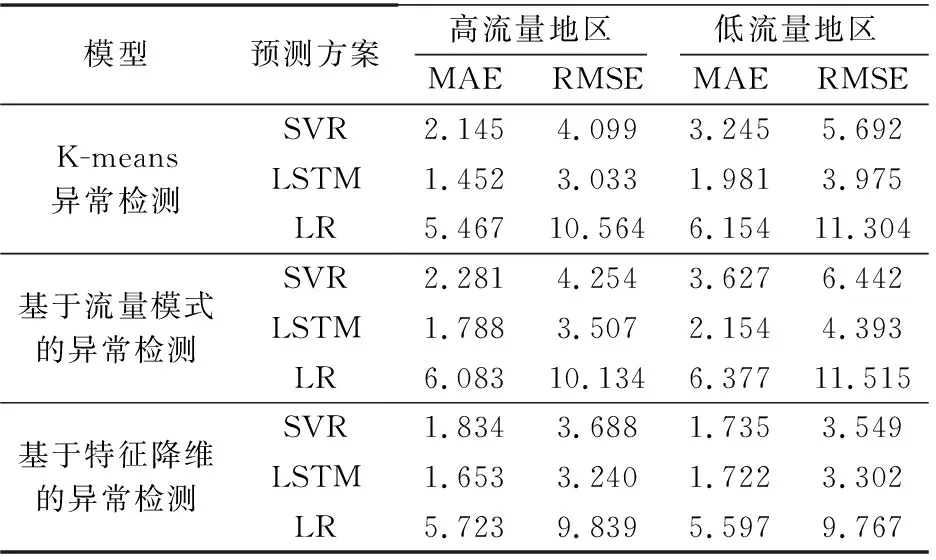
表1 3种异常检测方法在高、低流量区域内性能比较
经典的K-means算法将均值最大的簇标记为异常样本,这些异常样本中也包含部分未发生异常的高流量网格,所以使用该法剔除异常后的数据预测误差在高流量地区小,在低流量地区大。基于流量模式的异常检测方法在高、低流量地区异常检测性能均不是最佳。基于特征降维的异常检测方法通过训练得到特征向量,可以排除虚假异常,快速、准确检测到不同流量地区的异常。总而言之,在高流量区域,所提方案可以有效检测出可疑异常,在低流量区域本方案可以以更高的准确度进行流量预测。
4.4.2 流量预测结果
使用上节所述方法,对5种业务数据分别剔除异常后,采用基于注意力的多数据集联合预测方法和RNN预测方法进行对比试验。表2为这两种方法在RMSE和MAE上的预测效果。图9(a)~图9(c)为基于注意力机制的多数据集联合预测方法对不同时长的流量数据的预测结果图,图9(d)~图9(f)为基于RNN预测方法对不同时长的流量数据的预测结果图。橙线为真实数据,蓝线为预测数据,可以看到RNN预测方法可以准确预测流量数据周期性等大体趋势,但是无法精准预测流量的细节,缺少对具体时刻流量值的信息预测。采用基于注意力的多数据集联合预测方法的预测结果不只显示数据的周期信息,而且在峰值处可以更准确地预测数据,对未来48 h、72 h、168 h的流量数据预测结果对比均显示了该方法的有效性。
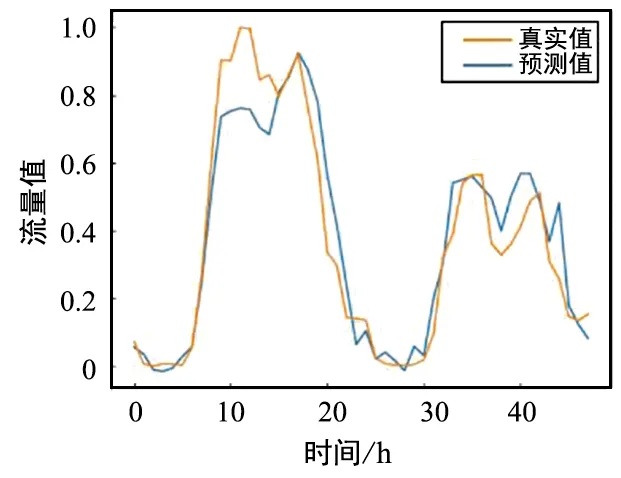
(a) 多数据集联合预测模型预测未来 48 h流量值

表2 两种预测方法对不同时长数据的预测性能比较
由于训练时长为168 h,所以当预测时长小于168 h时,多数据集联合预测模型预测误差在RMSE和MAE两个指标上均小于RNN。利用注意力模块可以学习目标业务数据与其余业务数据的相关性,充分利用业务间的相关性辅助目标业务预测,不仅可以预测流量数据变化周期,还可以更精准预测不同时刻流量值。
5 结束语
针对大规模蜂窝流量数据异常检测中直接对原始数据进行检测存在的数据冗余和计算冗余的问题,为减少移动业务交付的端到端时延,实现网络资源的优化分配,提出了基于特征降维的蜂窝流量数据异常检测方法。该方法利用LSTM自编码器提取流量数据低维特征,再对新的特征空间进行理论分析,选取异常特征参数挖掘异常数据,实现针对大规模高维流量数据的异常检测功能。该方法可以更好地检测出高、低不同活跃度区域内的漏报异常;针对流量预测中存在的忽略不同通信数据间相关性的问题,提出基于注意力机制的多数据集联合预测方案,将提出的流量预测方法与基准预测方法在不同时长预测任务中进行对比实验,所提出的流量预测方法在RMSE和MAE性能指标上都获得了最好的性能表现,从而证明了所提出方法的有效性。
猜你喜欢
黄河之声(2022年10期)2022-09-27
玩具世界(2022年2期)2022-06-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
作文新天地(初中版)(2019年6期)2019-08-15
北京航空航天大学学报(2017年6期)2017-11-23
电子制作(2017年23期)2017-02-02
