
基于时空特征提取的智能网络切片算法
2022-02-11 09:32:24肖柏狄李荣鹏赵志峰张宏纲
无线电通信技术 2022年1期
肖柏狄,李荣鹏,赵志峰,2,张宏纲
(1.浙江大学 信息与电子工程学院,浙江 杭州 310027;2.之江实验室,浙江 杭州 311121)
0 引言
当前,5G网络已经成为数字社会发展不可缺少的关键一环,与4G网络相比,其提供的海量服务可以满足用户更广泛的需求,而其中大多数都是4G所不能实现的。
ITU为5G定义了3个主要应用场景:增强移动带宽(eMBB)、大规模机器类通信(mMTC)和超高可靠低时延通信(URLLC)[1]。其中eMBB凭借其高带宽主要应用于AR/VR等服务,mMTC则因为连接密度大而应用于物联网、智能家居等服务,而低时延和可靠性高的URLLC则可应用于自动驾驶、远程手术等服务。
为了适应5G多样化的服务,需要一个能够支持多种服务场景需求的网络,而这是4G这样单一物理网络难以做到的。网络切片作为5G的关键技术之一,能够将一个物理网络切割成多个虚拟网络切片,在相同的物理基础设施上建设具有不同特性的逻辑网络,每一个切片提供一种服务。5G网络切片也可分为核心网切片、承载网切片以及接入网切片三类[2]。
切片资源的管理也有多种分类,包括静态管理(硬切片)、半静态管理以及动态管理(软切片)[3]。在虚拟化的逻辑网络上对各切片进行资源的再次分配和调度,产生新的切片,这就是资源的动态管理。
另一方面,用户使用的服务类型会经常发生变化,用户的移动也会导致服务基站的变更,这就导致资源分配需要实时进行动态调整,预测难度也大大增加。因此,资源的动态管理是最符合网络切片理念的分配方法,具有很高的灵活性,但实现难度也是最高的。抓取这些变化中的时空特征,能够大幅提高动态分配的准确性,做到更好的预测。
目前,资源动态管理的研究仍处于起步阶段,业界也正在进行各种尝试,采用了包含机器学习方法在内的各类算法,其中较为可行的一类为强化学习算法[4-6]。
本文基于接入网切片,提出了一种使用时空特征提取的深度强化学习方法,从连续时间段内的用户信息中提取时间特征,学习用户的行为习惯,并通过提取基站的空间特征,学习在下行传输时各个基站相互之间的影响,最后通过深度强化学习的方法来进行切片资源分配的决策学习。
1 接入网智能切片
图1为多基站和多用户的接入网环境模型,接入网中的基站是以等间距的蜂窝网络的形式分布的。

图1 接入网切片Fig.1 Radio access network slicing
各基站可分配总带宽相同,支持的服务种类也相同,在其范围内的用户都属于自己。而每个用户所使用的服务种类也各不相同,并且会进行随机移动。
以dm={dm1,…,dmn,…,dmN}表示第m个基站中各切片的用户需求,也就是需要的数据包数量,wm={wm1,…,wmn,…,wmN}表示第m个基站分配给各切片的带宽,并使用系统效益J来对资源分配策略进行评估。J由频谱效率(Spectrum Efficiency,SE)和用户满意度(Service level agreement Satisfaction Ratio,SSR)的权重和决定。SE可以通过香农定理用传输信噪比得到,SSR定义为传输数据包的成功率。系统效益J的计算公式为:
wmi=c·Δ,∀i∈[1,2,…,N],
(1)
式中,c为整数;Δ为最小带宽分配粒度;α和β={β1,β2,…,βN}为代表权重的超参数。
因为该模型与强化学习的应用环境具有很高的相似度,因此可以将这个分配问题转化为马尔科夫决策问题(Markov Decision Problem,MDP)[7]。MDP的构成要素主要包含了状态空间S、动作空间A、转移概率P以及即时奖励r,这些都可以与接入网模型一一对应。



④ 即时奖励r以及折扣系数γ:基站Bm在当前时刻t会根据系统环境得到一个即时奖励r,由式(2)决定:
(2)
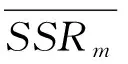
进一步地,将深度学习和强化学习结合在一起,通过深度强化学习进行决策学习可以得到更好的效果。
2 智能网络切片的深度强化学习算法
旨在解决上述问题,本文提出了基于时空特征提取的智能网络切片算法。该算法采用深度强化学习进行带宽分配的决策学习,使用了深度Q网络(Deep Q-Network,DQN)。为了对输入数据进行预处理从而获取其更深层的特征,算法也采用了机器学习的方法来进行时空特征提取,其中利用图注意力网络(Graph Attention Network,GAT)学习基站的空间特征,利用长短期记忆网络(Long Short-Term Memory,LSTM)学习用户的行为习惯。
2.1 图注意力网络(GAT)
如图1所示,将接入网中的基站看作节点,相邻基站之间的联系看作节点之间的边,蜂窝网络就是图结构。因此,可以将图注意力网络应用在输入数据的预处理上,来学习基站相互之间的影响。
GAT用于图结构处理中[8-9],属于图神经网络(Graph Neural Network,GNN)的一类变种。
以图2为例,假设图结构中N个节点对应的特征向量为h1,h2,…,hN,向量的长度都为F,GAT先将特征向量都乘上权重矩阵W,映射为维度更高的向量,例如i节点对应的Whi以及j节点对应的Whj,对应的长度为F′。利用自注意力机制,可以得到i节点和j节点之间的注意力因子:
eij=a(Whi,Whj),
(3)
式中,a为单层的前馈神经网络。

图2 图注意力层的结构Fig.2 Structure of GAT layer
通过eij可以得知j节点对于i节点的重要性。利用softmax进行归一化,可以进一步得到标准化的注意力因子:
(4)
式中,Ni为i节点的邻点集合。
最后,以注意力因子作为权重,就可以得到每个节点对应的新的向量作为输出:
(5)
式中,σ为激活函数。
还可以使用多头注意力机制(Multi-head Attention),利用K个相互平行独立的图注意力层对特征向量进行处理,最后取平均。
(6)
2.2 长短期记忆网络(LSTM)
LSTM属于循环神经网络(Recurrent Neural Network,RNN)的一种,用于处理序列,提取其中的时间特征,常用于自然语言处理当中[10]。
LSTM单元的核心由3个门组成:记忆门it、遗忘门ft以及输出门ot。在当前的LSTM单元中,将上一个单元得到的历史综合信息Ct-1和特征向量ht-1与当前单元的输入向量xt进行一系列运算,可以选择删除或者添加综合信息中的信息,对信息进行记忆和遗忘,提取出信息的时间特征,如图3所示。

it=σ(Wi·[ht-1,xt]+bi),
(7)
ft=σ(Wf·[ht-1,xt]+bf),
(8)
(9)
随后,利用公式(7)~(9)得到的结果更新综合信息Ct,并利用输出门ot计算综合信息中与当前信息相关的部分,输出ht。
(10)
ot=σ(Wo·[ht-1,xt]+bo),
(11)
ht=ot⊙tanh (Ct)。
(12)
式中,Wi、Wf、Wo、WC、bi、bf、bo、bC是该层的权重矩阵,即待训练的网络参数,tanh为激活函数。

图3 LSTM单元的结构Fig.3 Structure of LSTM unit
2.3 深度Q网络(DQN)
深度强化学习是强化学习和深度学习的结合,也就是使用神经网络来进行深度学习,提升强化学习的感知能力,以DQN及其各个变种为代表[11-12]。
如图4所示,将系统当前的状态s输入到DQN中,DQN就能够通过多层全连接层进行学习,并输出在状态s下采取动作a所对应的奖励,用Q值也就是Q(s,a)来表示:
Q(s,a)=Es′,a′[r(s,a,s′)+γQ(s′,a′)],
(13)
式中,s′和a′分别代表下一个状态及其采取的动作。

图4 DQN的结构Fig.4 Structure of DQN
DQN要做的就是找到最适合状态s的动作a*,也就是Q值最大的动作:
(14)
同时,DQN同时训练两个网络,一个用于产生Q值的目标值,也就是目标Q网络,一个用于实时的参数更新和Q值计算,也就是当前Q网络。每进行T步训练,当前Q网络的参数都会复制给目标Q网络。因此,训练的目标就是使两个Q网络所预测的Q值尽可能地接近,从而使Q值收敛。参数更新使用的损失函数如下:
(15)
2.4 算法整体框架
综合以上3种网络,提出了基于时空特征提取的深度强化学习算法,其框架如图5所示。

图5 算法整体框架Fig.5 Architecture of the algorithm

算法1 基于时空特征提取的智能网络切片算法输入:系统的状态stm以及对应的奖励rt输出:切片对应的带宽分配动作atm1:对模型参数和经验回放的缓存器F进行初始化;2:设定LSTM的时间步长T和训练总次数N;3:从t=1到N/5:4: 从系统中获取当前状态stm并随机地选取动作atm;5: 从系统中观测到奖励rt以及st+1m;6: 将(stm,atm,st+1m,rt)存储到F当中;7:从t=N/5到N:8: 从系统中获取当前状态stm并生成状态序列Stm={st-T+1m,st-T+2m,…,stm};9: 将stm输入到嵌入层当中得到Htm={ht-T+1m,ht-T+2m,…,htm};10: 将htm输入到第一层图注意力层当中得到Gtm={gt-T+1m,gt-T+2m,…,gtm};11: 将gtm输入到第二层图注意力层当中得到Gtm'={gt-T+1m',gt-T+2m',…,gTm'};12: 将gtm和gtm'输入到LSTM当中,分别得到ltm'以及ltm″;13: 将ltm'和ltm″拼接在一起,即ltm=ltm'||ltm″,输入到DQN中,使用ε-贪婪算法并选择动作atm,其中ε∈[0,1],并随着训练的进行增大:atm=argmaxa∈AQ(ltm,a;θu),概率为ε随机选取,否则 ;14: 观测到奖励rt和下一时刻的状态st+1m;15: 将(stm,atm,st+1m,rt)存储到F当中;16: 从F当中随机选取一批数据进行训练并更新参数。
此外,该算法还使用了两项技术,通过经验回放来存储过去的状态、动作及对应的奖励,在参数更新时随机选取存储过的状态,解决了输入样本依赖性过高的问题。同时,算法利用ε-贪婪作为经验回放的辅助,在训练初期偏向于随机选取动作,尽可能地遍历动作空间中的动作。
3 实验结果和分析
算法的测试基于图1的模型,也就是一个包含19个基站的蜂窝网络,大小为160 m×160 m,一共包含了2 000名使用者。每个基站的总带宽设置为10.8 MHz,分配给3种不同的服务:VoLTE、eMBB以及URLLC,最小带宽分配粒度为0.54 MHz。其他具体的参数设置如表1所示[13-14]。
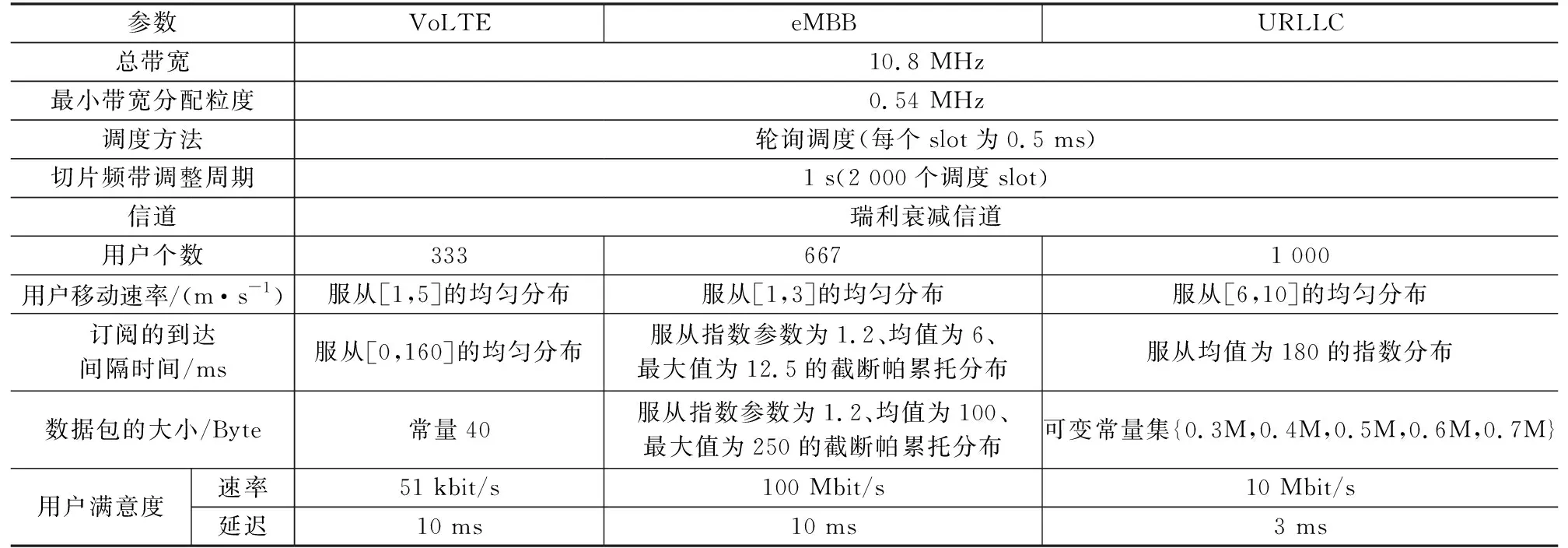
表1 具体参数设置
该算法的测试将一些传统算法和人工智能算法进行对比,其中LSTM-A2C将LSTM与A2C结合,是使用时间特征提取的强化学习算法;GAT-DQN将GAT与DQN结合,为使用空间特征提取的强化学习算法[15-16]。以式(1)中的系统效益作为系统评价指标之一,将α设置为0.01,β设置为[1,1,1]。实验中算法的训练迭代次数都是10 000次,采用采样和滑动平均进行结果的处理。
在相同环境下,本文对各种方法进行了多个指标上的比较,得到了以下结果,其中图6为系统效益曲线,图7为频谱效率曲线,图8为URLLC的用户满意度曲线。
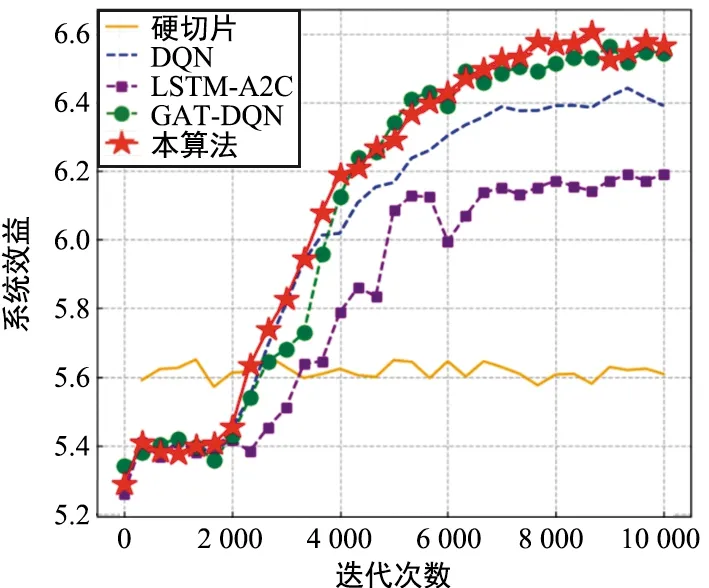
图6 各方法的系统效益(Δ=0.54 MHz)Fig.6 System utility of each method(Δ=0.54 MHz)

图7 各方法的频谱效率(Δ=0.54 MHz)Fig.7 Spectrum efficiency of each method(Δ=0.54 MHz)
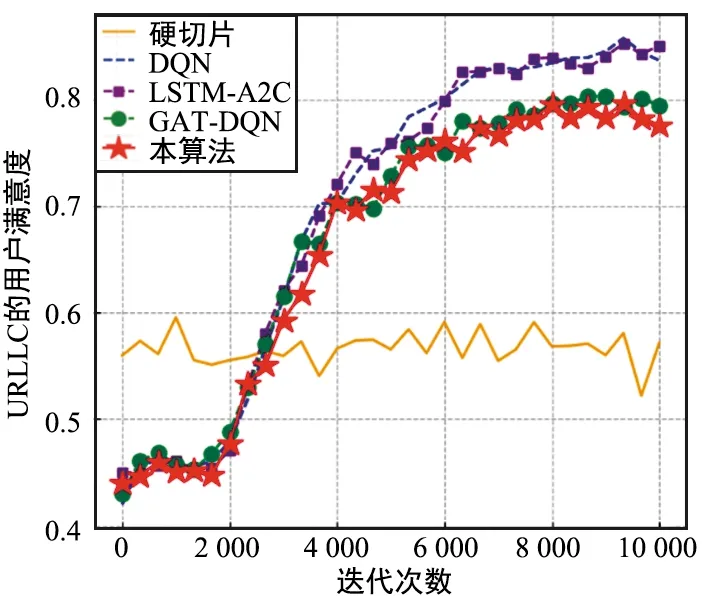
图8 各方法的URLLC用户满意度(Δ=0.54 MHz)Fig.8 Service level agreement Satisfaction Ratio of each method(Δ=0.54 MHz)
对于系统效益,本算法在收敛速度以及效益值上都是最优的。对于不使用ε-贪婪所得到的系统效益,本算法达到了6.72左右,而DQN的最终系统效益约为6.42,只使用时间特征提取的LSTM-A2C的最终系统效益约为6.19,只使用空间特征提取的GAT-DQN的最终系统效益约为6.62。由此可见,加入了时空特征提取相较于LSTM-A2C和GAT-DQN能够得到一定的性能提升,相较于DQN更是有5%左右的提升。
对于频谱效率,本算法在收敛速度和频谱效率上也是最优的。对于不使用ε-贪婪所得到的频谱效率,本算法达到了390左右,相较于LSTM-A2C的约335以及DQN的约360都有较为明显的提升,而GAT-DQN约为380,与之相比也有了一定的提升。
URLLC的服务需求最难满足,各方法的差异也更容易体现出来。对于URLLC的用户满意度,本算法在收敛速度和用户满意度上性能有所下降。对于不使用ε-贪婪所得到的用户满意度,本算法达到了0.82左右,GAT-DQN约为0.83,LSTM-A2C和DQN都为0.88左右。因此,对于用户满意度,进行时空特征提取并没有做到性能上的提升,反而有了一定的下降。
4 结束语
本文提出了一种基于时空特征提取的深度学习算法,通过使用GAT和LSTM整合蜂窝网络中各基站的时空特征,并加入DQN来得到能够实现智能网络切片的资源分配策略。
实验的分析和结论说明,在接入网环境下,相比于只使用LSTM进行时间特征提取或只使用GAT进行空间特征提取的的深度强化学习算法,二者结合进行时空特征提取可以达到更好的资源分配效果,强化了对用户行为以及资源需求变化的预测,并且在用户满意度优秀的同时,增加了对频谱的利用率,综合性能也有了一定的提升,更适合网络切片的智能资源分配。
猜你喜欢
电子制作(2018年19期)2018-11-14 02:37:08
通信电源技术(2018年3期)2018-06-26 06:33:50
自动化学报(2017年11期)2017-04-04 02:52:58
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
中国当代医药(2015年17期)2015-03-01 02:03:38
噪声与振动控制(2015年4期)2015-01-01 07:08:21
中国交通信息化(2014年1期)2014-06-05 03:03:50
河南科技(2014年10期)2014-02-27 14:09:00
河南科技(2014年4期)2014-02-27 14:06:59
