
基于适应度函数的联锁软件测试用例生成仿真
2022-02-09 02:05王新强
计算机仿真 2022年12期
刘 明,王新强
(天津中德应用技术大学软件与通信学院,天津 300350)
1 引言
联锁软件的可靠性影响着系统的安全,其错误输出可能会导致重大事故。但开发过程中,软件缺陷是难以避免的,通常由软件说明不够详细造成的错误、开发人员考虑不周引发的失误两种。软件测试是确保其安全的关键方法,但传统人工测试会过度依赖测试员经验,测试质量不能得到保障。因此,研究一种可靠的软件测试用例生成方法对确保联锁系统安全具有现实意义。
不同学者从以下角度探究如何生成测试用例:王微微[1]等人基于遗传算法,将种群并行化计算应用到用例生成中,设计线程池与逻辑结构,实现种群个体在软件上的覆盖计算,高效生成测试用例。徐鹏[2]等人利用神经网络算法,通过样本训练网络结构特征,结合随机变异算法构建自动生成模型,有效改善测试模型结构复杂等缺陷。但是在联锁系统中,软件功能类型众多,测试内容复杂,且部分软件功能根本无需测试,如果测试全部功能,不仅增加执行成本,还会浪费时间,占用较多的系统内存。因此,为了更好地反映系统实际使用情况,本文利用日志挖掘算法获取用户端的日志信息[3],分析用户实际操作需求,针对这些需求通过遗传算法生成测试用例[4]。这样不但减少测试开销,还能提高测试效率。遗传算法可准确模仿生物进化过程,可以很好地处理非线性问题[5],在每一次进化过程中都能及时调整变异率,优化搜索方向,在测试用例生成过程中有较强的适用性。
2 联锁系统软件结构分析
软件是联锁系统的“大脑”,可接收各方面的反馈信息,结合信息内容传输指令,进而控制联锁系统。联锁软件具体结构如图1所示。

图1 软件结构组成示意图
由联锁软件具体结构可知,其主要执行的功能有:
1)信息显示:利用大屏幕显示器显示所有操作信息、设备运行信息、系统工作情况以及故障预警信息。
2)联锁控制:列车线路安排、完成闭锁与解锁道岔、自动关闭和开启信号灯。
3)保存用户操作记录:联锁软件具备强大的储存功能,且可随时提供用户历史操作记录[7]。
3 基于日志挖掘的联锁软件测试用例生成
3.1 日志挖掘过程
通过分析联锁软件组成结构可知,其能保存用户操作数据,生成对应日志信息。本文正是通过日志挖掘来生成测试用例的,经过采集、预处理和模式识别等过程[8],挖掘用户行为模式与联锁系统功能的使用情况,掌握用户操作行为,根据挖掘结果确定测试项目,提高软件用户友好度,生成更加有针对性的测试用例,大大减少测试开销。日志挖掘过程主要包括以下几个步骤:
1)日志采集
在联锁系统的磁盘中,随机采集初始日志数据,此步骤是日志挖掘的必然前提。
2)数据清洗
初始日志数据无法直接进行挖掘,其中包括大量冗余信息,为提高日志质量,本文利用支持向量机算法辨别日志,删除冗余数据。具体做法为:假设存在某日志样本训练集合{(x1,y1),(x2,y2),…,(xn,yn)},其中xi表示输入向量,yi代表类别标志,如果前t-1个样本属于正例集合P,其它样本组成没有标注的数据集合U。结合支持向量机相关原理[9],将数据分类过程表示为
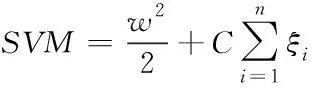
(1)
该分类过程的约束条件如下
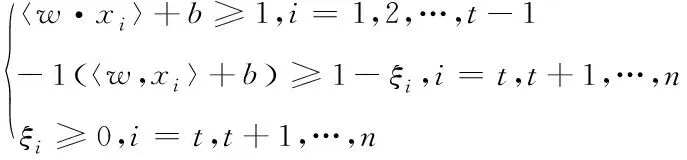
(2)
式中,w属于一个参量,该值越大说明分类界限越明显,ξi代表松弛变量,b⊆R表示偏置,C为惩罚系数,C值越大,边界越小。经过上述处理后初始日志数据被分为有用和冗余两类,删除冗余数据,将剩余数据作为日志挖掘目标,提高日志挖掘质量。
3)频繁模式挖掘
经过数据处理后,利用频繁模式发掘算法完成日志挖掘。该步骤的目的是构建频繁路径和测试用例之间的相对关系[10],同时赋予测试用例相关支持度。日志挖掘过程描述如下:
假设I={I1,I2,…,In}表示一系列日志项集,事务集合为T={t1,t2,…,tn},其中ti∈I(1≤i≤n),n表示某事务集内含有项的个数。针对随机事物T,都有T∈I。TDS={T1,T2,…,Tn}代表事务数据流,且T1与Tn分别描述最早和最近产生的事务。
在T中,随机选取某数据项ti,令其出现概率为pi,表现为二元组形式为〈ti,pi(T)〉,如果pi=0,说明T中没有数据项ti。
如果H={〈hi,pi(T)〉|1≤i≤k|}表示由k个数据项构成的集合,则认为H是k-项集。如果H⊆Ti,则项集H在Ti上的理想支持度如下[11]

(3)
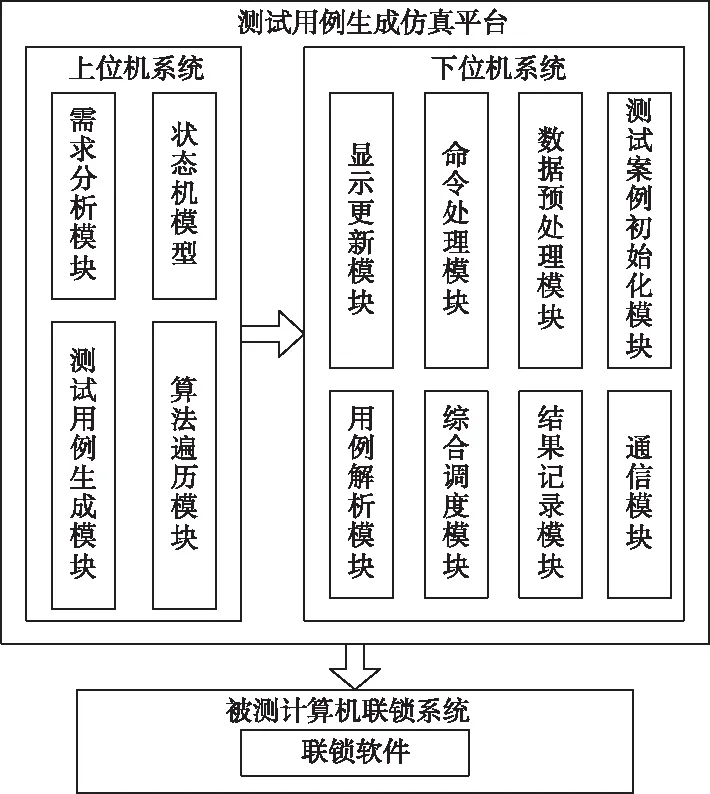
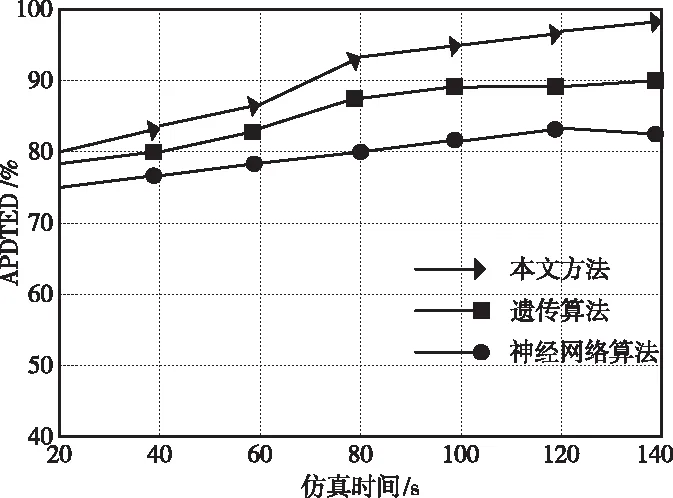
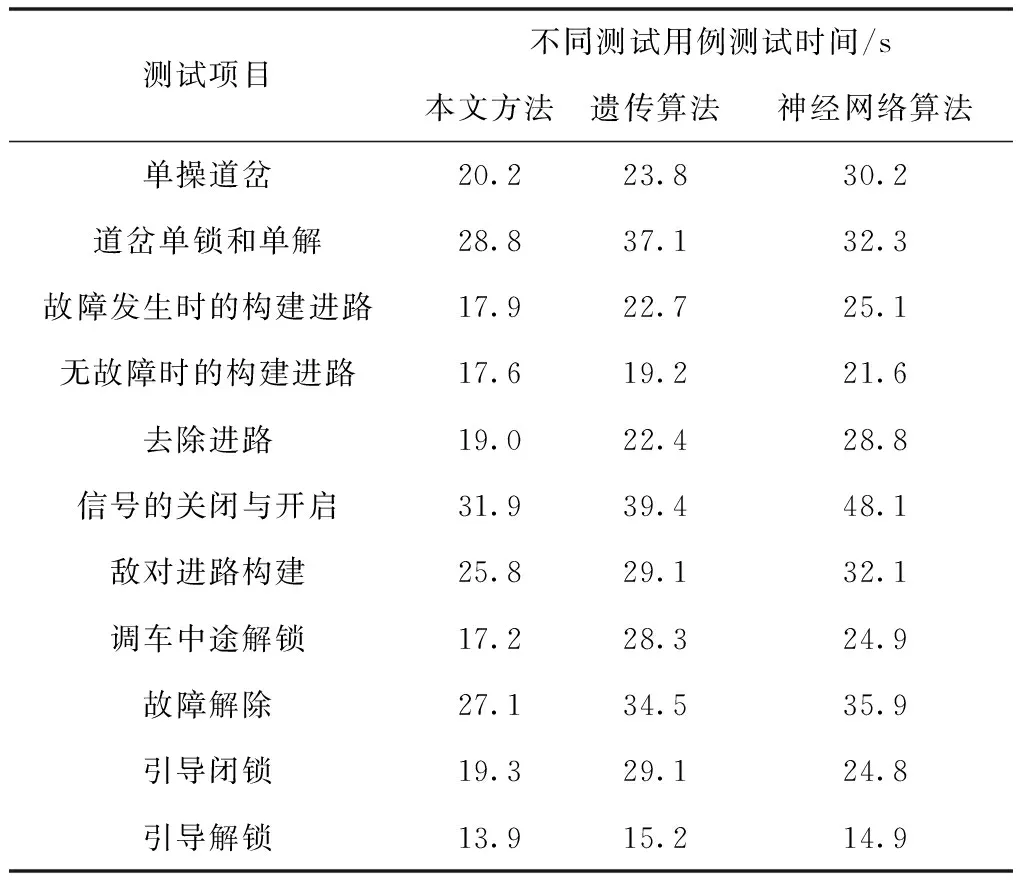
分析不确定样本流特征,设定滑动窗口[12]为τ=(τ1,τ2,…,τn),如果仅挖掘最近窗口内的频繁项集,则窗口中最新与最旧事务分别表示为Tv、Tu,且满足u (4) 已知最小理想支持度阈值κ,∀H⊆I,如果Sup(H,τ)<δ,则项集H即为窗口中的频繁项集。 经过上述频繁模式挖掘,获取联锁系统用户的操作行为,根据挖掘结果可确定需要测试的项目。 测试用例的主要作用就是完成联锁系统中各项操作项目的性能测试以及结果分析。通过日志挖掘,现阶段测试项目主要包括的内容如表1所示。 表1 测试项目表 如表1所示,测试项目共包括11项内容,这些项目都对联锁系统的安全性起决定性作用。因此,为提高测试用例的覆盖率,需要制定覆盖准则[13],保证测试的充分性。 1)语句覆盖 该标准代表生成的用例集合,可以被测试样本中全部可操作的语句均执行一次,其覆盖程度可通过覆盖率描述 (5) 式中,Sexe代表被覆盖的语句集合,Si为全部无法执行的语句集合,Stot描述被测目标中全部语句集合。 2)分支覆盖 此准则是在满足语句覆盖基础上制定的,将被判定为真或假的分支再继续执行一遍,避免出现漏检现象,覆盖率表达式如下 (6) 式中,Dexe代表被操作覆盖到的分支集合,Dtot为全部分支总和,Di是没有经过判定的集合。 基于上述测试准则,根据日志挖掘获取的测试项目,利用遗传算法遍历所有样本集合,生成测试用例。主要过程如下。 1)编码方式 通过遗传算法解决实际问题时,需构建编码策略,其影响着交叉算子结构,决定着遗传操作性能。本文使用二进制编码方式,将0和1当作构成基因的单元,生成二进制位串描述基因型。 假设某参数β满足的取值条件为{β|βmin≤β≤βmax},此时存在2L种编码策略,L代表位串长度,则不同编码方式存在如下映射关系 (7) 式中,λ表示编码精度。与编码策略对应的解法方式为 (8) 2)适应度函数选取 适应度函数[14]选取是否科学影响着搜索性能,遗传算法利用优胜劣汰的个体筛选思想,必须对所有个体作适应性评价。本文通过目标函数转化方式得到适应度函数。 目标函数的极大值优化问题表示为 (9) 式中,Cmin属于一个系数,通常为g(x′)进化时出现的极小值。 目标函数的极小值优化问题描述为 (10) 式中,Cmax同样是一个系数,表示g(x′)进化时出现的最大值。 上述适应度函数综合了多方面考虑,能够提高搜索效率和全面性。 3)遗传算子选取 将所有个体的适应度值当作一个圆形轮盘,利用随机轮盘赌方式选取扇形区域个体[15]。如果种群规模是Q,其中个体o的适应度值表示为fo,则该个体被选中继续参与遗传过程的概率ρo为 (11) 综合上述所有步骤,建立如图2所示的测试用例生成模型。 图2 测试用例生成模型图 由图2可知,算法搜索过程即为测试用例生成过程,在每次进化中,不断调整交叉与变异率,优化搜索方向。 为分析该方法的优势和不足,搭建仿真平台。通过在控制器上安装仿真软件,与联锁软件共同组成实验平台的下位机,同时在操作层增加测试设备,形成上位机。在仿真系统中,上位机的任务是控制系统流程,下位机则需实现现场信号的仿真。仿真系统结构如图3所示。 图3 仿真系统结构示意图 首先,选取一个大规模联锁软件,分别向两个软件中植入错误程序,不同测试时间植入的错误数量不同(10秒10个、20秒15个,30秒20个,40秒25个,50秒30个)。利用本文方法、遗传算法与神经网络算法生成测试用例,分析不同类型联锁软件下有效检测出错误程序的次数。仿真结果如图4所示。 图4 不同算法检测结果图 分析图4可知,针对同一个联锁软件,利用不同算法生成的测试用例对其错误程序检测,当错误注入数量较少时,三种方法都能全面检测出错误程序。随着仿真时间的增加,错误数量越来越多,只有本文方法始终保持较高的检出率,其它两种方法均存在漏检现象。这是因为本文方法适应度函数设置合理,提高算法搜索能力,能够更加全面地测试出软件中的错误。 当算法对于软件注入的错误检出率相同时,将检测出的错误重复次数百分比(APDTFD)作为评价指标,累计发现重复错误次数越多,表明算法性能越好。该指标计算公式如下: (12) 式中,N表示测试用例总数,Nk代表用例k检测出的新错误程序数量,Dk指用例k重复发现错误的次数,F描述用例检测出全部错误的次数,既包含新错误,也含有重复错误。 在实验条件相同的情况下,上述三种算法的APDTED指标的仿真结果如图5所示。 图5 不同算法APDTED指标性能对比图 如图5所示,随着仿真时间的增加,注入的错误数量也随着增加,不同方法的APDTED指标均呈现上升趋势。但所提方法的指标值最高,说明生成的测试用例有很好地重复发现错误的性能,这会大大降低误检率,因为当更多的测试用例都检测出某程序存在错误时,表明该程序一定为错误程序。因此,所提方法的检测结果更具科学性。 最后,利用上述三种生成的测试用例测试相同联锁软件,对于软件中的不同测试项,不同方法的测试时间如表2所示。 表2 不同测试用例测试时间对比表 表2显示,对于全部测试项目而言,利用本文方法测试联锁软件性能时,可减少测试时间,能在更短时间内获取测试结果。这是因为本文利用了日志挖掘算法,了解用户需求,更加快速地生成测试用例,使检测更具有针对性,减少不必要的测试过程,降低时间开销。 为满足联锁软件安全性能极高的要求,本文将日志挖掘与遗传算法相结合,生成软件测试用例。通过日志挖掘分析用户需求,减少非必要的测试项目生成,利用遗传算法,设置目标函数,经过全局搜索,生成测试用例。仿真结果表明,所提方法不但漏检率低,还能减少时间开销。但本文只研究了如何生成测试序列,并没有生成测试脚本。因此,将测试用例变换为可执行脚本是下一步研究的主要方向。
3.2 测试项与测试准则确定
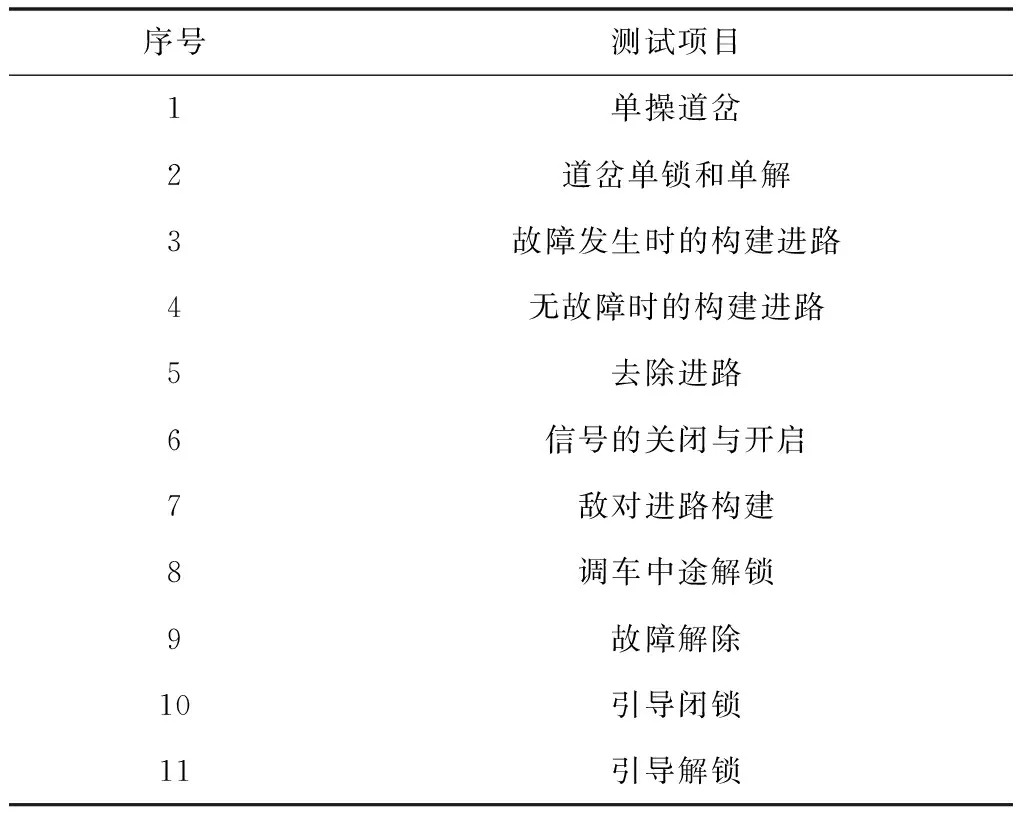


3.3 测试用例生成


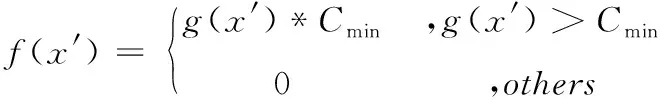

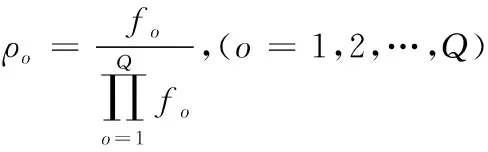

4 仿真数据分析与研究

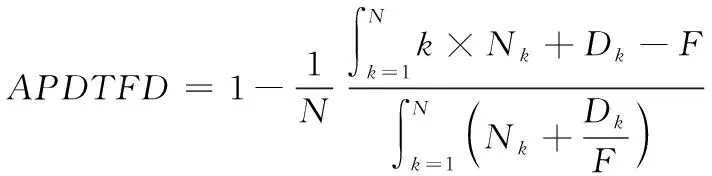
5 结论
猜你喜欢
大理大学学报(2022年11期)2022-12-26
华人时刊(2021年13期)2021-11-27
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
心声歌刊(2020年4期)2020-09-07
甘肃教育(2020年8期)2020-06-11
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
中国纤检(2015年17期)2015-11-16
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
