
竞技二打一中玩家叫牌风格划分方法
2022-02-08 01:08:02赵煜霖沈强望李淑琴
重庆理工大学学报(自然科学) 2022年12期
赵煜霖,沈强望,李淑琴,孟 坤
(1.北京信息科技大学 计算机学院, 北京 100101;2.感知与计算智能联合实验室, 北京 100101)
0 引言
博弈游戏是检验人工智能发展水准的重要平台之一[1]。其中,竞技二打一游戏作为一种大众喜闻乐见的博弈游戏[2],具有非完全信息、动作空间巨大、决策过程复杂、多阶段对局等特点[3],众多学者便对其展开了动作空间降维[1]、手牌推测[4-7]、出牌决策[8-11]等多方面的研究,并且取得众多研究成果;同时,为了在有限轮对局内区分二打一游戏玩家的竞技水平,陈子鹏等[12]给出了一种计算初始手牌区分度的方法,并在实际测试中验证方法的有效性;然而,区分博弈竞技水平的竞技二打一比赛采用复式赛制,存在比赛作弊的问题,李淑琴等[13]对如何判定和选取具有同等牌力的初始手牌进行研究,提出用等级难度评估指标来计算初始手牌的难度,通过多个不同水平的二打一AI验证了该方法的可靠性。
叫牌阶段作为在二打一中首先进行的对局阶段,其叫牌结果会决定对局结束时的基础收益情况。为了能够尽可能提高最终的基础收益,需要针对不同的叫牌风格采取相应的叫牌动作。
现在对叫牌阶段的研究普遍集中在推荐叫牌模型上,也就是根据玩家手牌给出一个推荐的叫牌动作。Yuan等[14]针对竞技二打一博弈过程中的叫分策略进行研究,利用所构建的牌力和牌序特征自动学习内在隐含关联,并与支持向量机(support vector machine,SVM),长短期记忆网络(long short term memory,LSTM),文本卷积神经网络(text convolution neural network,TextCNN)分别进行对比实验,笔者提出的模型在召回率、精确率和准确率上均超过上述方法,均达到了80%以上。文献[6]通过使用多层CNN对手牌进行特征提取,并将叫分大小作为标签,训练出的叫分模型在真实人类玩家的数据集上能够与人类叫分结果达到76.5%的相似度。同时,笔者也考虑了玩家的叫分会受到其他玩家的影响,通过一种规则修正的方式来使得模型的叫分结果更贴近真人的行为。文献[15]分析了竞技二打一中叫分时会考虑的牌型和数量,选取了12种牌型组合方式作为弱分类器,使用AdaBoost算法进行训练,从而得到一个强分类器,最终在真实玩家的数据集上能够达到75%的准确率。
以上这些工作的研究成果都十分出色,但都只是根据手牌的特征进行叫分动作的分类任务。笔者认为,如果可以对其他玩家叫牌风格进行划分来推测会采取的叫牌动作,则可以通过自己的叫牌动作进行诱导,使自己能够获得更高收益,故将对玩家叫牌风格的划分方法进行研究。
1 叫牌风格划分方法的设计与实现
本文主要通过2个部分设计并实现对玩家叫牌风格的划分:首先是对于基准叫牌模型的设计与实现,该模型主要通过使用卷积神经网络对玩家手牌进行特征提取并结合当前叫牌情况实现对于玩家手牌动作的分类;然后,使用统计学方法计算玩家叫牌动作与基准模型之间的差异,通过查表的方式实现对于玩家叫牌风格的划分。
1.1 手牌特征的表示方式
考虑到竞技二打一所使用的纸牌是由红色Joker、黑色Joker(后面分别叫用X,D表示)以及13种不同点数(3、4、5、6、7、8、9、10、J、Q、K、A、2)且每个点数各有4张纸牌(在竞技二打一中同点数之间不区分花色)共计54张纸牌构成,由于大部分点数的纸牌都是4张,故玩家点数3到2的手牌采用如图1所示的0-1矩阵进行表示,矩阵中每列1的个数代表各个点数手牌的数量;对于玩家手牌中的大小王则分别用一个0-1特征进行表示。
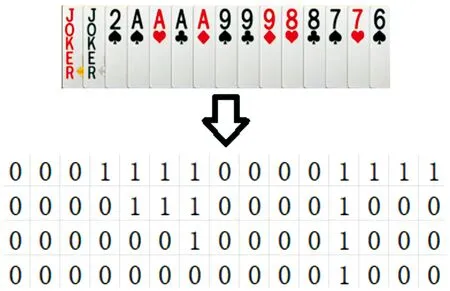
图1 手牌为67788999AAAA2XD的特征矩阵表示
1.2 基准叫牌模型的设计
基准叫牌动作是由玩家手牌和其他玩家的叫牌情况共同决定的。本文受文献[14]启发,对TextCNN[16]进行修改,设计了如图2所示的基准叫牌模型。该模型主要分为2个部分——提取连续牌特征的卷积网络部分和融合叫牌情况、强力牌特征的叫牌网络部分。
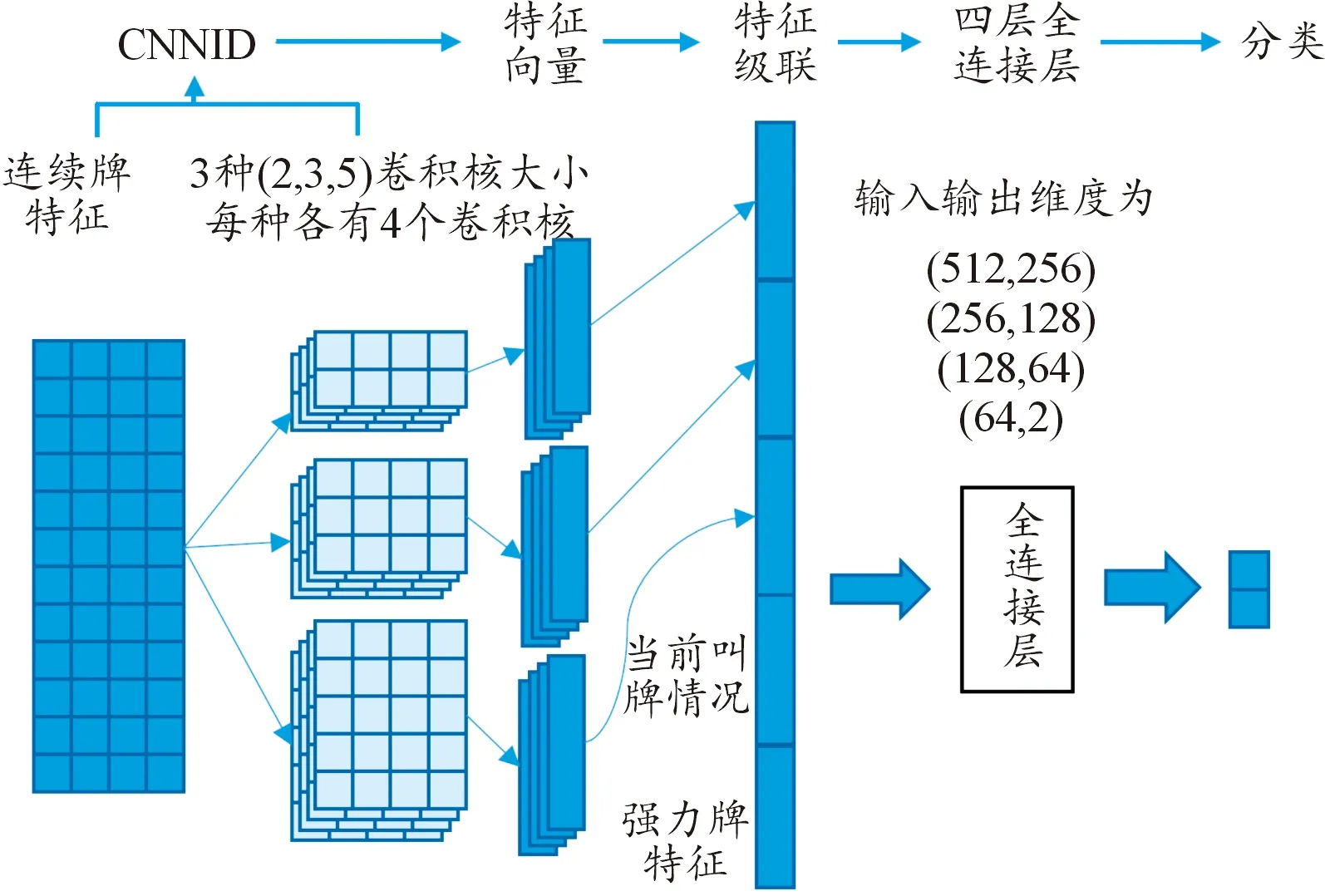
图2 基准叫牌模型结构
卷积网络部分的输入是12×4大小的连续牌特征矩阵,其中的连续牌指的是可以组成例如单顺、对顺和三顺等连续点数牌型[17]的点数牌,12表示从3到2共12个数的手牌,4代表持有的张数。将特征矩阵输入到3组卷积核大小分别为2、3、5,输出通道数均为4的一维卷积神经网络进行卷积运算。考虑到池化运算会改变特征之间的相邻关系,故本模型所使用的卷积神经网络去除了池化过程,最后再通过Relu激活函数得到12个卷积后的特征向量。
手牌中强力牌情况(例如手牌中是否有大小王、2的个数和炸弹个数)和当前叫牌情况特征也是决定叫牌动作的重要因素,故将上述影响因素按照用0-1编码进行特征表示,如图3所示。然后将这些特征与12个连续牌卷积后的特征向量连接在一起作为融合网络部分的输入,经过多层全连接层进行前向传播,最后输出模型的叫牌动作。

图3 抢地主阶段、叫牌次数为1的当前叫牌情况和手牌中持有2XD和一个炸弹的特征表示
为了保证模型具有较强的学习能力,对提取到的特征进行升维;同时,为了保证模型具有较强的泛化能力,在各全连接层之间使用dropout函数会让某些神经元随机“失活”,使模型不会依赖于局部特征,从而避免过拟合。
1.3 叫牌风格划分方法的设计
玩家会根据自己的叫牌风格采取不同的叫牌动作。为了量化叫牌风格之间的差异,本部分将设计玩家叫牌风格的划分方法。
本文提出的玩家叫牌风格类别的划分方法是根据玩家的叫牌动作进行设计,故首先对玩家的叫牌动作进行分析。在叫分阶段会存在着0,1,2,3这样4个可选择的叫牌动作,在抢地主阶段会存在着加倍和不加倍2种动作。根据对实验数据的统计发现,多数玩家的叫分动作多数趋向于0和3,使叫分阶段的叫牌动作退化成2个,与抢地主阶段的叫牌动作数量一致,故本文把2个阶段的叫牌动作都统一成0和12个动作。考虑到玩家的叫牌动作与基准模型之间的差异会随着玩家叫牌数据的不断扩充逐渐收敛一个平面点,故按照对手牌的高估程度μ和叫牌动作偏离程度σ2个指标把玩家叫牌风格划分为以下6种——保守理性型、保守非理性型、风险理性型、风险非理性型、激进理性型、激进非理性型。
为了能够对真实玩家的叫牌风格进行划分,本文采用以下步骤对手牌的高估程度μ和叫牌动作偏离程度σ2个指标进行数值量化:使用基准叫牌模型M计算N副玩家手牌hi应该采取的叫牌动作SMi,计算出玩家p叫牌动作Spi与模型叫牌动作之间的差值Si,把差值大于0的手牌hj看作玩家对hj的高估,统计玩家p高估手牌的局数m和采取叫牌动作1的局数n,利用式(1)计算出玩家对手牌的高估程度μ;利用式(2)计算出玩家叫牌动作的偏离程度σ。
(1)
(2)
式中:SMi与Spi取值范围均在[0,1];差值Si的取值范围在[-1,1];μ取值范围在[0,1]。在计算μ和σ过程中N的取值大小影响风格划分精度,本文认为在N不小于10时玩家的叫牌风格才能进行较为准确的划分,然后给出表1中各玩家叫牌风格中2个指标的取值范围,实现对玩家叫牌风格的划分。

表1 玩家叫牌风格划分
2 基准叫牌数据的预处理
2.1 原始数据格式说明
实验所使用数据的来源是国内某知名在线游戏平台提供的竞技二打一游戏真实数据。原始数据中记录了游戏过程中3位玩家的脱敏处理后的 ID、手牌记录、底牌信息、叫分情况、出牌记录,以及牌局最终的胜负结果。原始数据以文本文件的形式进行存储,各记录之间的分隔符使用的是 ASCII 码中的SOH(0x01)与STX(0x02)。原始数据样例形式如图4所示。

图4 部分原始数据样例
以数据样例中标记号为10的记录为例,对各记录进行如表2所示的详细说明。
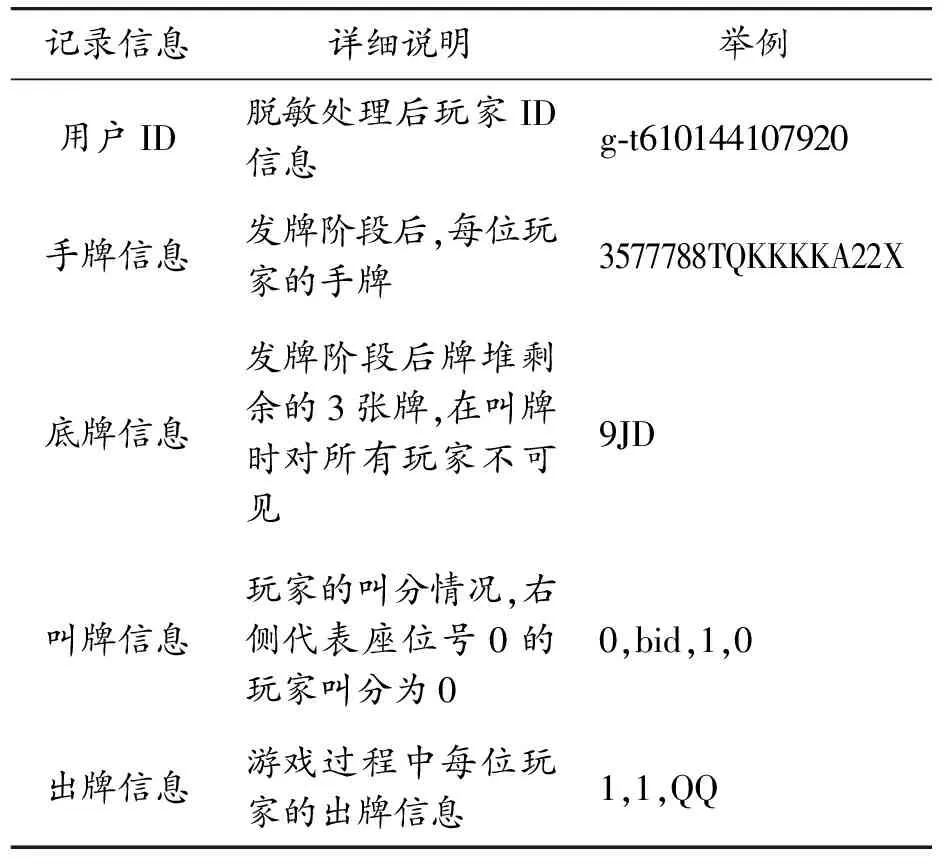
表2 原始数据格式和记录说明
2.2 高水平玩家id的筛选
在原始数据中存在部分异常对局记录,如玩家掉线,牌局未完成等情况。同时,部分水平较低和游戏总局数过少玩家的对局信息对模型训练会带来较大的偏差。一副手牌是否可以叫牌不仅依赖于手牌的好坏程度,还与拿到该副牌的玩家水平有关。因此,需要对玩家id进行筛选。
为了能够获得高水平玩家的id字段,就需要统计原始数据中每名玩家的获胜局数和总局数,并计算各玩家的胜率。本文认为,若玩家的胜率越高,则说明玩家的博弈水平越高,故高于平均胜率的玩家的叫牌动作更具有参考价值。筛选出这部分玩家的id信息,并进行存储。部分有效玩家经过脱敏处理的id信息如图5所示。

图5 部分有效玩家id
2.3 原始数据的清洗
原始数据记录的是完整对局信息,包括玩家信息、手牌信息、叫分信息、出牌信息,而本文针对竞技二打一博弈玩家风格问题只需要摘取其中的部分有效信息,避免数据集中的无效数据过多,导致模型训练效果与预期产生偏差。本实验将所有有效玩家的对局数据信息经过以下方式进行处理,成为可供后续网络模型输入的数据集形式:
1) 读取高水平玩家文件,得到高水平玩家字段;
2) 读入原始数据中每一局的对局信息;
3) 通过SOH字符分割开一场对局中每个阶段的信息;
4) 通过STX字符分割开每个阶段中每位玩家的具体操作信息;
5) 依次读入叫分阶段每位玩家叫分信息,最后一位叫分玩家的位置记为地主;
6) 判断第一个出牌的玩家位置是否是5)操作的记录值,若是,则为有效对局,进行下一步操作;
7) 读取每位玩家的叫牌信息,并判断获胜玩家是否为高水平玩家,若不是则直接舍弃;反之,若获胜玩家为地主,则把地主的叫牌数据标记为1,若获胜玩家为农民,则农民叫牌数据的标记根据叫牌动作进行标记——叫牌标记为1,不叫牌标记为0。
8) 由7)中处理后的数据存在相同叫牌情况下的不同叫牌动作,为了避免模型训练震荡,本文考虑统计相同叫牌局面和相同手牌下的标记之和与总标记数量的比值大小决定当前手牌的叫牌动作,避免训练震荡。具体决定方式为:若比值大于0.5,则在当前叫牌局面和手牌下,标记为1;否则,标记为0。
按照上述方法,从500余万条原始数据中筛选出约10万条用于训练模型的基准叫牌数据。具体数据保留格式如图6所示,以逗号进行分段:第一段数据代表叫牌阶段——0表示叫分阶段,1代表抢地主阶段;第二段数据代表当前叫牌值大小——共有0,1,2共3个值;第三段数据代表玩家手牌;第四段数据代表该条数据的标签值,也就是应该采取的叫牌动作。

图6 部分基准叫牌数据保存格式
2.4 基准叫牌模型的训练算法
将筛选出的数据划分为约8万条数据的训练集和约2万条数据的测试集,使用第1章设计的模型进行训练,训练过程如算法1所示。
算法1
输入:叫牌数据集D,待训练的叫牌模型M,学习率r
输出:训练好的叫牌模型M′
将D拆分成训练集X和测试集C
测试集准确率acc ← 0.0
for 训练轮数 = 0,1,2,…,100:
将X随机拆分成NX个大小为B的小批量数据集DX
采取正确叫牌动作的样本计数tx← 0
for 小批量数据集编号xi= 0,1,2,…,NX:
用CrossEntroyLoss计算DX[xi]的损失值,更新M的网络参数
tx←tx+neqneq:对于DX[xi]中数据M给出的输出与其标签值一致的数量
将C随机拆分成NC个大小为B的小批量数据集DC
采取正确叫牌动作的样本计数ct← 0
for 小批量数据集编号ci= 0,1,2,…,NC:
tc←tc+neqneq:对于DC[ci]中数据M给出的输出与其标签值一致的数量
当前准确率acc_tmp←tc/C中样本个数
ifacc_tmp>acc:
M′ ←M
acc←acc_tmp
3 叫牌风格划分的实验与分析
3.1 系统环境及模型参数设置
本文所使用的系统环境配置如表3所示。

表3 硬件和软件配置
训练过程中所使用的优化器为Adam优化器,损失函数使用CrossEntroyLoss函数,学习率设置为1×10-4,dropout层的p值设置为0.5。
3.2 实验结果与分析
3.2.1基准叫牌模型训练效果与分析
使用第2章得到的基准叫牌数据进行100轮训练后,模型在训练集和测试集上损失函数值和准确率变化如图7和图8所示。
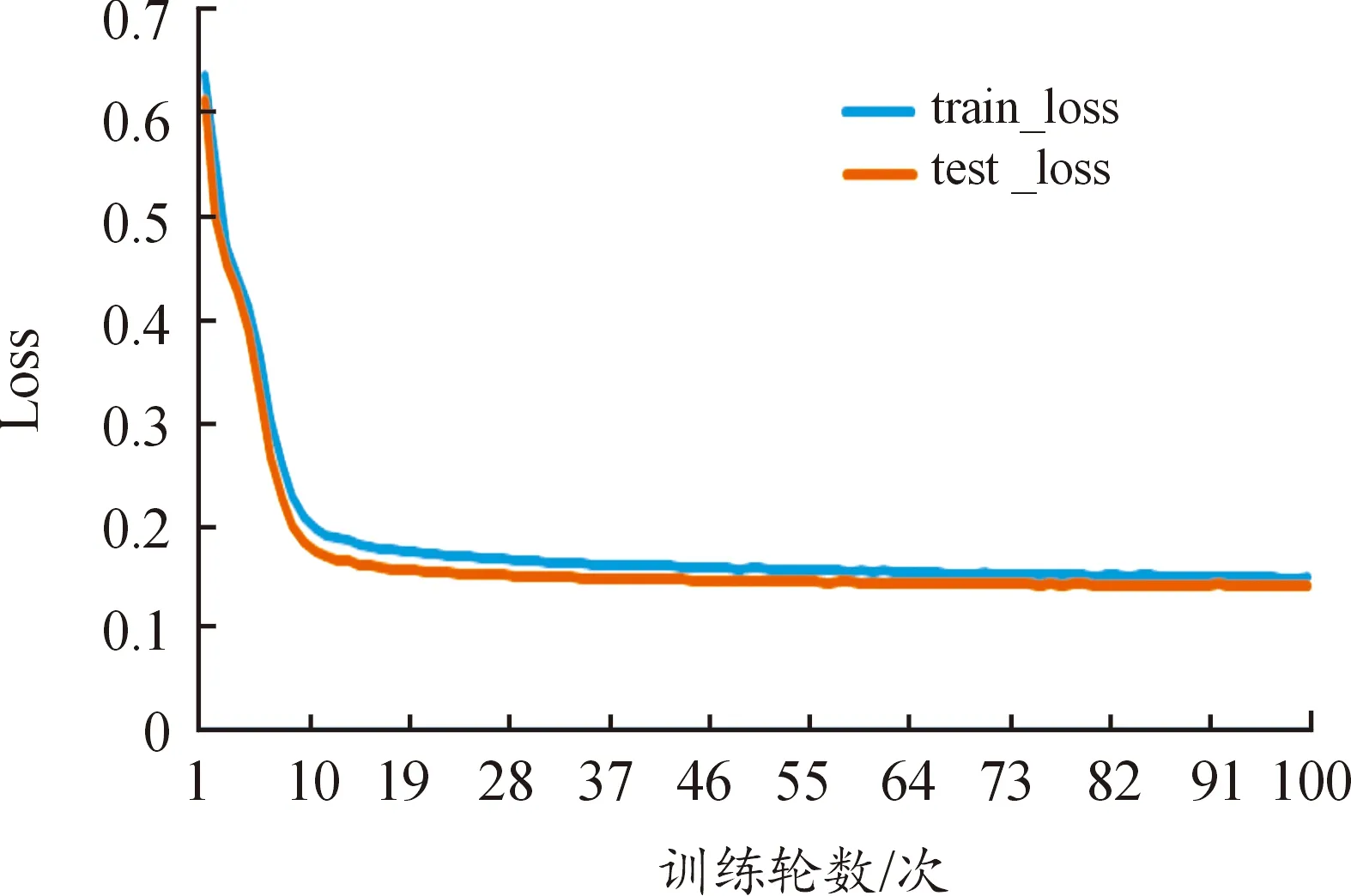
图7 模型在训练集和测试集上损失函数值的变化

图8 模型在训练集和测试集上准确率的变化
在前7轮训练中,损失函数值下降,但准确率却几乎不变,本文认为是标签为叫牌的样本数据在一开始的loss中占据了主导优势,使得模型在此时错误学习到两类数据的比例结构,导致了上述异常状况的出现。
在后续的训练中,模型对叫牌类型的样本拟合达到一定程度后,该类样本对loss的贡献度相较于不叫牌的样本的影响降低,模型开始对不叫牌的样本进行拟合,最终达到收敛状态。
同时,本文也对引入模型的强力牌特征和叫牌情况特征分别进行消融实验,得到如图9和图10的结果。实验结果表明2种特征对于模型性能的提升均有较大提升,验证了本文引入的这2种特征的有效性。
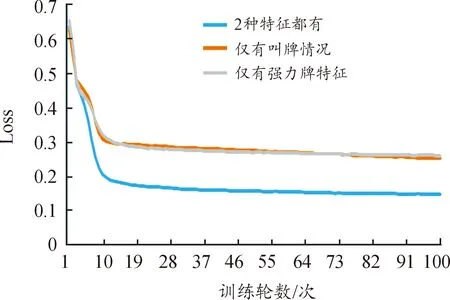
图9 模型在去除部分特征后损失函数值的变化

图10 模型在去除部分特征后准确率的变化
3.2.2玩家叫牌风格划分结果与分析
叫牌风格划分所用的数据来自另一份真实玩家数据,将这部分数据中的叫牌信息按照玩家id分别进行存储。为保证叫牌风格划分的准确性,本实验剔除了少于10次叫牌动作玩家的样本数据。
图11的最后2列分别展示了在相同情况下某玩家的叫牌记录和模型给出的基准叫牌动作。根据1.3节提出的叫牌风格划分方法,计算得到该玩家对手牌的高估程度为0.500 004,对叫牌动作的偏离程度为0.738 548,查表1可知该玩家的叫牌风格属于激进非理性型。

图11 相同叫牌情况下某玩家的叫牌记录和基准叫牌动作
观察图11可以发现,数据项1中无任何强力牌特征,数据项3、7、12中存在大量不能构成连续牌特征的点数牌,但玩家仍采取叫牌的动作,以此判断该玩家在叫牌过程中比较激进随意,可以认为其叫牌风格属于激进非理性型。由此认为本文设计的玩家叫牌风格划分方法对于高估手牌的部分能够正确判别,具有一定的可行性。
4 结论
为了提高自身在对局中的收益,本文以竞技二打一的玩家叫牌风格作为切入点,研究了一种融合深度学习卷积神经网络和统计学方法的玩家叫牌风格划分方法,该方法能够对玩家的叫牌风格进行正确划分。
在基准叫牌模型训练开始时出现准确率不能提升的问题,笔者认为可能是样本比例不均衡造成的,如果能够找到一种合适的平衡样本比例的算法,会使模型的性能得到进一步提升。
本文训练出具有较高准确率的叫分基准模型,并能依据叫分基准模型对玩家的叫牌风格进行分类划分,未来将会设计带有多阶段叫牌博弈算法接口的平台对本文的方法增加对局收益的效果进行验证。
猜你喜欢
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
小朋友·聪明学堂(2016年12期)2017-03-31 20:59:04
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
棋艺(2016年6期)2016-11-14 05:12:03
公民与法治(2016年19期)2016-05-17 04:18:15
少儿科学周刊·少年版(2015年4期)2015-07-07 20:56:37
读者·校园版(2015年7期)2015-05-14 13:11:40
棋艺(2014年7期)2014-09-09 08:43:54
河南科技(2014年15期)2014-02-27 14:12:35
