
基于Transformer 的融合用户负反馈的重排序推荐方法
2022-02-07 09:20:30胡德敏
智能计算机与应用 2022年12期
胡德敏,光 萍
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
随着互联网规模和数字信息资源的增长,信息数量呈几何级数激增,使得人们难以快速、准确地从海量的信息资源中寻找所需的信息。推荐系统是可以有效解决信息过载问题的重要技术手段,通过对用户行为数据分析和建模,预测并推荐用户可能感兴趣的产品。Top-n推荐作为推荐系统的场景之一,利用用户对物品做出的反馈记录,为用户推荐一个可能感兴趣的包含n个物品的列表,如学术头条对论文的推荐、网易云课堂对课程的推荐,其少量准确的推荐更符合用户的选择习惯,因此近年来Top-n推荐已逐渐成为推荐领域内的研究热点。
Top-n排序模型基于学习排序(Learning to rank,LTR)的思想,分为单文档方法、文档对方法和文档列表方法,分别从不同角度综合考虑多个排序特征,来对若干物品进行排序,其中心问题是如何有效准确地捕捉用户兴趣,以提高推荐物品列表的排名质量。大多数现有的Top-n推荐模型将用户的正反馈信息,即用户-物品交互中点击或购买的行为序列作为输入,却忽略了用户负反馈信息,即更加丰富的未点击曝光物品,最终生成的推荐列表趋于同质化和趋热化,损害了用户体验。在完整的用户反馈信息中,未点击的物品占相当大的份额,能够作为辅助信息补充点击行为。
一些研究建模物品之间的相互影响,再次调整Top-n排序模型给出的候选列表,被称为重排序方法。各种重排序模型[1-2]基于Transformer 网络结构,应用自注意力机制和可并行计算的特点,实现了在常量距离内高效建模列表中任意物品之间的相互影响。受这些重排序研究的启发,本文基于Transformer 编码器,将Top-n推荐生成的候选列表作为部分输入,首次在重排序过程中额外集成用户负反馈信息,构建一个重排序推荐模型(Re-ranking recommender integrating user negative feedback,NRR),用来解决现有的Top-n模型忽略用户负反馈信息的问题。
1 相关工作
各种Top-n推荐模型[3-4]分为单文档方法、文档对方法[5-6]和文档列表方法[7-9]三类。其中,单文档方法将推荐任务视为一个二元分类问题,借助手工特征工程,全局学习给定的用户-物品对的评分函数,但忽视了候选物品集合中不同物品之间的差异和相互影响,为了解决这一问题,文档对方法模型和文档列表方法模型的研究逐渐受到多方关注。文档对方法将2 个物品之间的先后顺序关系纳入研究,但没有考虑物品在整个排序列表中的位置信息和相关物品的数量差异。而文档列表方法的思想是对所有训练实例进行训练得到最优的评分函数,对于一个新的查询请求,评分函数会对每一个物品进行打分并重新做排序。虽然文档列表方法弥补了单文档方法与文档对方法的不足,但现有的文档列表方法通常只依赖用户的正反馈信息进行推荐。
近年来,一些研究者提出重排序模型,通过调整上述Top-n模型生成排名列表。Ai 等人[10]使用单向GRU[11]将整个列表的信息编码到每个物品的表示中。Zhuang 等人[12]使用LSTM[13]不仅对整个排名列表信息进行编码,而且还通过解码器生成重排序列表。对于使用GRU 或LSTM 对物品相关性进行编码的方法,存在编码空间的长距离依赖性的问题,Pei 等人以及Chen 等人提出基于Transformer[14]的PRM 模型和BST 模型,应用自注意力机制和并行计算的优势,高效地学习用户兴趣。
2 NRR 重排序推荐模型
2.1 Top-n 推荐模型与重排序模型的任务描述
Top-n推荐的任务是根据历史记录中的用户与物品的交互序列,从中学习用户的兴趣偏好,挑选出用户可能感兴趣的包含n个物品的推荐列表。研究中,Top-n推荐通过对候选物品集合中的每个物品进行评分来输出一个有序列表,并使用式(1)的损失函数来训练整个Top-n推荐模型:

其中,R是所有用户的查询集合;Ir是对应某次查询r∈R的候选物品集;xi是物品i的特征向量;yi是对应物品i的标签(点击与否);p是基于Top-n模型的所有参数θ计算出的点击物品i的概率;l为该次计算的损失。
而本文的重排序推荐模型则是额外利用用户的负反馈信息,对Top-n推荐生成的初始列表的物品重新排序,即给定Top-n推荐生成的候选列表Sinit =[i1,i2,i3…,in],通过本文的重排序模型NRR,将其调整为最终列表Sre-rank =[j1,j2,j3…,jn].本文NPRR 模型的全局损失函数定义为:
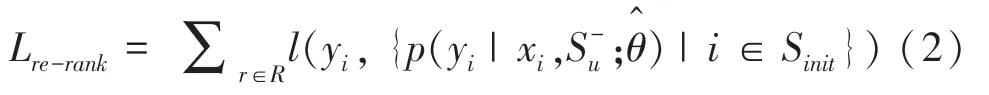
其中,表示包含用户负反馈行为序列,表示重排序推荐模型的参数集合。
2.2 NRR 模型总体架构
NRR 模型的体系结构如图1 所示。由图1 可知,该模型包含特征融合模块、Transformer 模块和预测模块三个部分,可将Top-n推荐生成的候选列表作为输入,输出重新排序的列表。对此拟展开研究分述如下。

图1 NRR 模型整体框架图Fig. 1 Overall framework diagram of NRR model
2.2.1 特征融合模块
特征融合模块的工作是获取初始推荐列表的特征嵌入、用户负反馈行为特征嵌入,并进行特征融合,得到完整的用户行为特征嵌入。文中给出各流程步骤的阐释解析如下。
(1)用户正反馈行为特征。大多数传统Top-n推荐方法基于用户的正反馈行为,在t时刻输出一个特定长度为n的推荐列表Sinit提供给用户。本文选取某种基于用户正反馈的Top-n推荐模型作为基础推荐器(Basic Recommender,BR),输入推荐列表Sinit,获取对应的表示用户正反馈行为的特征矩阵:
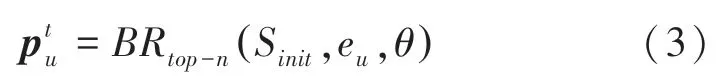
其中,eu是用户嵌入向量,θ表示Top-n模型的所有参数。
(2)用户负反馈行为特征。本文使用门控图神经(GRU)网络提取用户负面偏好。相比传统的序列模型RNN,GRU 解决了RNN 的梯度消失和梯度爆炸问题,同时相对于LSTM,GRU 的参数数量更少,训练收敛速度更快,本文选择GRU 抽取用户负反馈行为特征。GRU 结构如图2 所示。

图2 GRU 单元图Fig. 2 Diagram of GRU unit

(3)特征融合。特征融合的目的是不同角度的用户行为中提取的特征,合并成一个具有更精准判别能力的特征。Lv 等人[15]提出一种融合门(fusion gate)单元来融合用户的长短期偏好特征进行推荐,受该研究启发,本文基于门单元思想构建一个特征融合单元,来结合用户负反馈特征与负反馈特征,获得完整的用户行为特征表示,特征融合单元结构如图3 所示。

图3 特征融合单元结构图Fig. 3 Diagram of feature-fusion unit structure
具体来说,给定用户正负反馈行为特征,首先使用一个带Sigmoid激活的门控向量来控制两者的权重,见公式:

其中,eu为用户嵌入向量;b为偏置项;W1,W2,W3为权重矩阵。
基于门控向量,得到完整的用户行为特征:

2.2.2 Transformer 模块
考虑到交互序列中物品的顺序性,即当前时刻推荐给用户的物品列表排名位置会对用户下一时刻交互的物品产生影响。本文使用Transformer 网络来集成物品位置信息与完整的用户行为特征。
首先本文将完整的用户行为特征与物品位置信息pet连接,作为Transformer 网络的输入向量E':

这里,pet可由如下计算公式来求取:
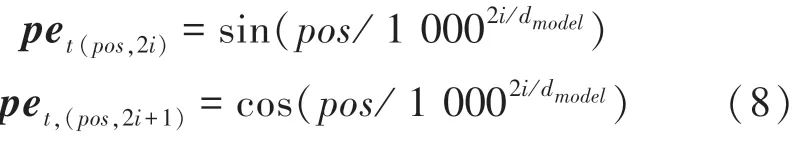
其中,pos是物品在推荐列表中的位置;i是物品维度;dmodel是物品嵌入向量的维度大小。
本文构建的Transformer 模块包含N块并行的Transformer 编码器(encoder),Transformer 编码器结构见图4,每个编码器包含一个注意力层和一个前馈网络(FFN)层,使用的注意力函数如下:
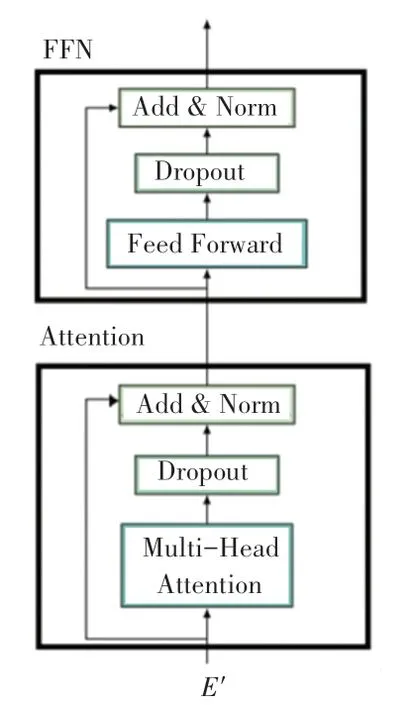
图4 Transformer 编码器结构图Fig. 4 Diagram of Transformer encoder structure

其中,Q、K、V分别表示查询、键和值,d是矩阵K的维数。
为了模拟更加复杂的物品交互影响,本文中自注意力层将最终嵌入矩阵E'作为输入,通过线性投影操作将其转换为3 个矩阵,输入到多头自注意力层,如式(10)所示:

其中,WQ,WK,WV∈Rd×d为3 个投影矩阵,h为多头自注意力的头数。
接下来,本文利用point-wise 式前馈网络FFN的非线性特性,来增强模型的效率,见下式:

为了避免过拟合,本文同时在注意力层和FFN中使用dropout和LeakyReLu激活函数,注意力层和前馈网络的输出分别为:
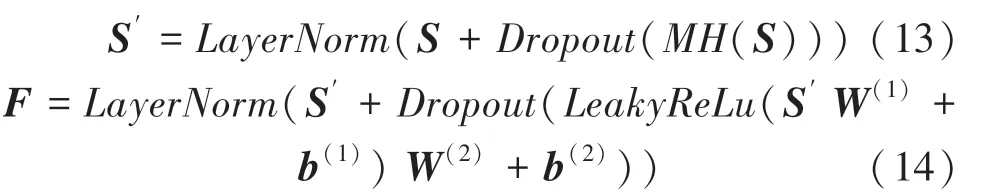
其中,W(1),b(1),W(2),b(2)为可学习的参数矩阵。
为了建模交互序列背后的复杂信息,至此本文并行堆叠N块Transformer 编码器来提升计算效率。其中,第b块的定义见下式:
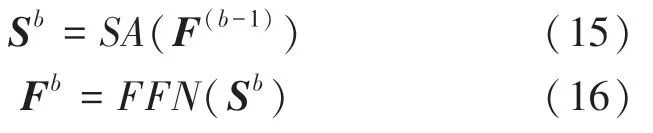
2.2.3 预测模块
预测模块的任务是为初始推荐列表Sinit中的每个物品重新生成一个分数,获得重排序列表Sre-rank。由图2 可看到,本文使用一个softmax层计算输出每个物品的点击概率p(yi,pet |θ'),作为其最终的分数,研究推得的数学公式可写为:

其中,F(N)是第N块Transformer 编码块的输出;bF是偏差项。为进行模型训练,本文使用交叉熵损失:
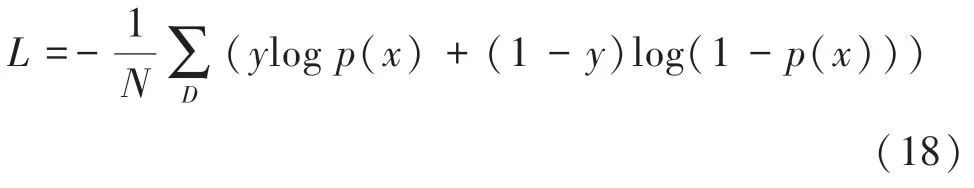
其中,D表示样本空间;y∈(0,1)为用户是否点击物品的标签;p(x)是softmax层的输出。
3 实验
3.1 数据集实验细节
本文采用Movielens-100k 数据集进行实验。Movielens-100k 数据集包含链接、电影、评分和标签四个主要文件,其中评分文件包含了每位用户对若干部电影打出的评分,时间段为1997-09~1998-04,本文基于每位用户的交互数据,按照时间顺序,以80%作为训练集,20%作为验证集,并使用训练集中的后10%作为测试集来评估模型的推荐效果。
本文使用AdaGrad 作为优化器,初始学习率设置为0.001,衰减率设置为0.9.对于长度相似序列批量大小batch size设置为128,更新迭代次数为100次,每25 个epoch后学习率衰减。实验中各种输入数据的处理、融合网络以及Transformer 编码器的构建均采用Python 语言来实现。具体硬件环境为:CPU 选用Intel Xeon E5-2669 v3,内存选用32 GB,显卡选用NVIDIA Geforce GTX 2060 Ti 两张,Window10 系统。
3.2 未点击物品的筛选规则
推荐系统每一时刻向用户展示一个可能感兴趣的物品列表,其中未被用户点击的物品包含了用户的负反馈信息。在数据收集过程中,一个关键的任务是筛选合适的未点击物品,未点击物品的数量通常比点击物品大得多,本文使用以下定义的过滤规则来挑选未点击数据,具体如下:
(1)选择在过去3 天内展示给用户、但未被点击的物品。
(2)在上述未被点击的物品中,只保留向用户公开超过k(本文取k =1)次的未点击物品。
本文选择这些物品作为每位用户的负反馈序列,未点击序列的最大长度被设置为50。
3.3 评价指标
本文使用Precision@k和AUC两个指标来评估模型推荐性能。可做重点阐述如下。
(1)Precision@k。表示在Top-n推荐的所有测试样本中,每检索k个物品,包含相关物品数量所占的比例,数学计算公式具体如下:

其中,R是测试数据集中所有用户请求的集合;Sr是重排序模型给出的有序物品列表;函数I用来判断第i个物品是否被用户点击。
(2)AUC。衡量了模型对样本正确排名的能力,其值越大,说明模型的排名能力越好,数学计算公式具体如下:

其中,insi表示第i条样本;M和N分别表示正样本个数和负样本个数;positiveclass表示正样本类别。
3.4 消融对比实验
在本文中为了进一步验证一些拟议模块的有效性,进行了消融对比实验。首先使用Wide&Deep 模型作为基础推荐器,生成初始推荐列表,接着设计3种对比结构,训练 50 个epoch,并在AUC和Precision@k(k =5,10)指标上比较性能。各结构的内容表述见如下。
(1)对比结构A:本文模型NRR。
(2)对比结构B:本文模型NRR 去除物品位置信息pet,考虑户负反馈信息nu,用NRR-pet表示。
(3)对比结构C:本文模型NRR 去除用户负反馈信息nu,考虑物品位置信息pet,用NRR-nu表示。
消融对比模型性能评价结果见表1。由表1 分析可知,忽视用户负反馈信息后,本文模型的性能大大降低,在Precision@5 上的降幅是最显著的,达到10.43%,这表明将用户负反馈信息纳入NRR 模型的重要性。当去除物品位置信息时,3 项指标略微降低,由此则表明考虑物品位置信息也能在一定程度上提升模型的性能。

表1 消融对比模型性能评价表Tab.1 Performance evaluation table of ablation comparison models
3.5 模型对比实验
本文实验将NRR 模型与主流重排序模型在AUC和Precision@k(k =5,10)进行了对比,用于生成初始推荐列表的Top-n模型有GRU4REC 和Wide&Deep 两种,用于对比的重排序模型分别为MIDNN、DLCM 和PRM,下文是对5 种模型的简要介绍:
(1)GRU4REC[16]:基于会话的采用多层GRU单元小批量地学习用户偏好。
(2)Wide&Deep:结合简单模型的“记忆能力”与深度神经网络的“泛化能力”。
(3)MIDNN:利用复杂的手工特征提取输入列表信息。
(4)DLCM:首先采用GRU 将输入的排序列表编码为一个局部向量,然后将全局向量和每个特征向量相结合,学习一个全局评分函数,用于重排序列表。
(5)PRM:应用自注意力机制,捕获输入排名列表中物品之间的相互影响。
各对比模型的性能评价结果见表2。表2 显示,与3 种基线模型相比,本文的NRR 模型实现了显著的性能改进。基于GRU4REC 生成的候选列表,与3 种基线模型相比,NRR 在AUC上平均提升5.58%,在Precision@5上平均提升8.75%,在Precision@10 上平均提升6.68%;基于Wide&Deep生成的初始列表,与3 种基线模型相比,NRR 在AUC上平均提升7.72%,在Precision@5 上平均提升9.59%,在Precision@10 上平均提升6.70%。

表2 对比模型性能评价表Tab.2 Performance evaluation table of comparison models
4 结束语
本文提出了基于Transformer 的融合用户负反馈的重排序推荐方法来对传统的Top-n推荐方法生成的初始列表进行重新排序。在NRR 重排序模型中,本次研究中建模用户未点击的物品序列来丰富用户行为特征表示,并使用Transformer 编码器整合用户特征和物品的位置信息。实验表明,NRR 模型与几种流行的重排序模型相比有显著的性能提升。
用户负反馈信息尽管较为丰富,但是存在一定的噪声。如何对负反馈进行降噪处理来提升NRR模型的性能将是未来工作的研究重点。
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
四川大学学报(自然科学版)(2021年1期)2021-01-26 07:39:14
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
电子制作(2019年23期)2019-02-23 13:21:36
信息安全研究(2016年4期)2016-12-01 06:06:54
河北软件职业技术学院学报(2015年3期)2016-01-01 07:29:50
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
