
基于LSTM的语言学习长期记忆预测模型
2022-02-03 13:12叶峻峣苏敬勇王耀威
中文信息学报 2022年12期
叶峻峣,苏敬勇,,王耀威,徐 勇
(1. 哈尔滨工业大学(深圳) 计算机科学与技术学院,广东 深圳 518055;2. 鹏城实验室 视觉智能研究所,广东 深圳 518055)
0 引言
在学习一门新的语言时,记忆词汇是绕不开的一环。为了记住外语词汇,学习者需要不断地复习,以巩固长期记忆。间隔重复是一种在语言学习中常见的记忆方法,与在短时间内反复记忆相反,通过适当地将多次复习分散到长期进行,能有效提高记忆效果。这一现象被称为间隔效应,最早由艾宾浩斯[1]在他的自我记忆实验中记录,并得到许多外显记忆任务研究的支持[2-3]。间隔重复使用抽认卡作为复习材料,以利用测试效应。在语言学习中,典型的抽认卡一面为单词,另一面为释义,以便学习者进行自我测试,这一行为也能加强学习者对词汇的记忆[4]。
大量记忆心理学实验发现,不同的复习间隔设置,会对长期记忆产生显著的影响[5]。而在间隔重复的传统实践中,学习者往往需要根据经验得出复习间隔,记忆纸质抽认卡。这种实践十分粗糙,也难以处理语言学习中遇到的大量词汇。近年来,随着在线学习的发展,出现了一批间隔重复软件,如Anki、Mnemosyne,它们以电子抽认卡为媒介,使用简单的启发式间隔重复模型,使得独立跟踪成千上万条词汇的记忆情况成为可能。已经有几项工作结合机器学习,提出了可训练的间隔重复模型,如半衰期回归[6](Half-life Regression,HLR),相较于传统的启发式模型,利用记忆行为数据训练的机器学习模型能对学习者的记忆情况进行更精确的预测。然而,这些模型缺少对时序信息的利用,而不同的间隔重复记忆安排对长期记忆造成的影响存在显著不同,利用时序信息才能学习到更精确的长期记忆规律。
本文工作中,我们提出了一种利用历史记忆行为序列的间隔重复模型LSTM-HLR,从流行的在线语言学习应用“墨墨背单词”中收集记忆行为数据,预测学习者的长期记忆。该模型对回忆概率的预测误差相较于最先进的HLR模型降低了50%。本文的主要贡献有:
(1) 收集90亿条记忆行为数据,并克服了领域内开源数据集缺失连续时序信息的问题。
(2) 使用行为序列对间隔重复中的长期记忆进行建模,考虑了不同复习间隔序列对长期记忆的影响。
(3) 通过对记忆行为数据按照序列信息聚合,得到记忆行为发生时的回忆概率特征,有效降低了预测误差。
本文组织结构如下: 第1节整理了间隔重复领域的相关研究;第2节重点介绍启发式模型的代表SM-2和目前表现最好的机器学习模型HLR;第3节描述LSTM-HLR模型的具体细节;第4节介绍数据集和评价指标,以及实验的结果和分析。
1 相关研究
在设计间隔重复模型方面,已经有大量的文献,涉及范围从最流行的启发式模型到最近的机器学习模型。
大多启发式模型是基于简单规则设计的。Leitner系统使用一系列大小不一的盒子来控制不同记忆程度的抽认卡的复习间隔[7]。超级记忆(SuperMemo,SM)系列模型[8-9]则基于个人实验收集的记忆行为数据,安排复习回忆概率接近特定阈值的抽认卡。近年来也有相关的工作基于Leitner系统[10]进行改进。
基于机器学习的模型可以追溯到MCM模型,建立以指数函数为基础的遗忘曲线模型,并应用神经网络进行学习[11]。在线语言学习平台Duolingo的研究者[6]提出了一个同样基于指数遗忘曲线的HLR模型,并有工作[12]基于该模型进行改进。
除了预测语言学习中的长期记忆之外,如何基于已知模型对学习者的复习效果进行优化也是该领域下的热门方向。MEMORIZE模型[13]以平衡学习者的复习压力和记忆保留率为优化目标,并使用HLR估计记忆材料的状态参数。也有研究工作[14-16]将HLR作为学习者模型之一,评估基于强化学习的间隔重复模型的功效。同样,也有使用贪心策略的间隔重复模型[17],用HLR为学习者模型提供必要的环境参数。
2 间隔重复模型
本节将首先介绍两种常见的间隔重复模型,然后尝试结合它们的优点,提出本文的LSTM-HLR模型。
2.1 SuperMemo模型
第一个面向消费者的间隔重复记忆系统软件是SuperMemo,其搭载了首个运行于计算机上的开源间隔重复模型SM-2。目前流行的间隔重复软件Anki也以此模型为基础。
SM-2的伪代码如算法1所示[8],其中,g表示学习者对此次复习的评分,范围为0~5,大于或等于3视为回忆成功。n表示学习者连续回忆成功的次数。I表示学习者复习的间隔。EF表示该记忆内容的简易程度。
根据SM-2模型,可以得出一个重复的间隔序列: 1天、6天、15天、38天……以此类推。如果学习者在复习过程中遗忘,间隔将重新从1天开始。并且由于简易度的下降,新的间隔序列整体短于上一次的序列,从而让学习者对每张抽认卡的回忆概率逐步提高,直到学习者能较大概率地回忆起这些抽认卡。
SM-2模型将学习者的复习间隔和回忆评分作为输入,引入简易度作为中间变量,通过硬编码的模型计算下一次间隔,实现了对不同抽认卡的独立跟踪和间隔安排。该模型的优点在于部分考虑了记忆行为的序列特征。其局限性在于,由于模型是根据经验硬编码的,不能定量地预测学习者的遗忘情况。并且模型对简易度的迭代调整较小,导致间隔的收敛速度也较为缓慢。
算法1 SM-2间隔重复模型

2.2 Half-life Regression模型
HLR是运行于在线语言学习平台Duolingo的间隔重复模型[6],其主要思路是记录学习者对单词的反馈,引入回忆概率和记忆半衰期这两个变量来衡量单词的记忆状态,使用机器学习的方法,将抽取的统计特征和需要预测的半衰期进行回归,从而训练出能够预测学习者对词汇记忆情况的模型。
HLR使用指数函数对遗忘曲线进行建模,如式(1)所示。
p=2-Δ/h
(1)
其中,p表示本次复习的回忆概率,Δ表示距离上次复习的时间,h表示学习者对单词的记忆半衰期,即回忆概率从100%下降到50%所需的时间。其中,半衰期h的预测值被定义如式(2)所示。
(2)
其中,θ表示需要训练的权重向量,x表示一次反馈记录中选取的特征向量,定义如式(3)所示。
x=(right,wrong,bias,lex)
(3)
其中,right统计了学习者累计答对的次数,wrong统计了累计答错的次数,lex是词位标签,以独热编码的形式表示学习者记忆的单词。
HLR模型使用以下损失函数进行训练,如式(4)所示。
(4)
HLR模型对学习者的遗忘情况进行预测,提出记忆半衰期的概念并用于复习安排,使学习者的遗忘比例能够控制在一定范围之内。但是,HLR模型对特征的处理,丢失了学习者复习反馈历史的时间序列信息。本文的动机是设计一个更准确的模型,将记忆的历史行为以时间序列的形式考虑进来,以最小化对长期记忆预测的误差。
3 本文方法: LSTM-HLR模型
对于任意一个记忆行为,可以用一个四元组来表示,如式(5)所示。
e:=(u,l,t,r)
(5)
其含义是一个学习者u在时刻t回忆单词l并反馈r(回忆成功r=1;回忆失败r=0)。为了捕捉学习者对单词的回忆历史,本模型将历史特征加入其中,如式(6)所示。
ei:=(u,l,Δt1:i-1,r1:i-1,Δti,ri)
(6)
其中,ei表示学习者u对单词l的第i次回忆事件,Δt表示两次回忆事件之间的时间间隔。Δt1:i-1和r1:i-1分别表示第1次到第i-1次回忆的间隔历史和反馈历史。
在上述模型中,回忆是二元的(即要么完全记起一个单词,要么完全忘记一个单词),实践中通常需要模型能够预测回忆的概率。为此,本模型忽略学习者本身的影响,用相同记忆行为历史下该单词学习者的回忆成功比例nr=1/N作为回忆概率p,并将回忆概率序列作为特征,从而得到最终的数据实例,如式(7)所示。
ei:=(l,Δt1:i-1,r1:i-1,p1:i-1,Δti,pi)
(7)

(8)
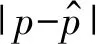
(9)
4 实验
4.1 数据集
本实验收集了3个月的墨墨背单词用户学习日志,其包含90亿条记忆行为数据。数据集构建过程如下:
(1) 一位用户对一个单词的一次复习将产生一条记忆行为数据。其字段包括单词id、用户id、时间戳、反馈。
(2) 当用户完成当日的学习任务后,当日所有的记忆行为数据将以日志的形式上传至服务器。
(3) 在服务器上,日志同步系统将用户学习日志结构化,写入数据库。
(4) 按照用户和单词进行分组,计算每次复习之间的间隔,并将每次的反馈和间隔按先后顺序拼接,得到反馈序列和间隔序列。
(5) 按照单词、反馈序列及间隔序列分组,计算不同间隔下的回忆概率,并将每次复习的回忆概率按先后顺序拼接,得到回忆概率序列。
为了获得每个单词在不同记忆行为历史下的半衰期和回忆概率,本实验对数据进行了聚合,最终得到7万条单词复习记录,其特征如表1所示,其数据分布情况如图1所示。

表1 数据样例

图1 数据分布情况
为了获取半衰期,可采用式(10)估计,以符合HLR模型。
(10)
领域内唯一的开源数据集是由Duolingo公布的,本实验尝试在该数据集上进行训练,但由于该数据集缺少连续的时序关系,无法提取出 LSTM-HLR 所需要的特征。并且,实验表明时序特征非常重要,考虑时序特征能超过目前最先进的模型。因此,本实验没有使用开源的数据集进行评估。
4.2 对比模型与评估指标
本实验采用了两个指标进行综合比较。
(1) MAE(p): 计算预测的回忆概率与实际统计的回忆概率之间的绝对误差。其中,回忆概率p是一个落在区间[0,1]中的连续值,MAE越小,预测越准确。
(2) MAPE(h): 计算预测的记忆半衰期与实际半衰期之间的绝对百分比误差。
之所以对记忆半衰期不使用MAE而使用MAPE评估,是因为考虑到半衰期的现实意义。偏差10%和偏差10天,对于1天的半衰期和100天的半衰期而言,前者更符合实际。
本实验对比三类间隔重复模型及其变体。LSTM-HLR,我们在第4节所描述的模型。为了进行消融实验,本实验考虑了4种变体: 有和没有Δt1:i-1特征(+t),以及有和没有p1:i-1特征(+p);HLR,遗忘预测模型的对比基线,考虑两种变体: 有和没有单词特征(+lex);SM-2,传统的启发式模型,与算法1中描述一致。
4.3 结果
本实验随机抽取20%的数据用于训练,最终确定了以下参数: 迭代次数=250 000,学习率=0.000 5, 权重衰减系数=0.000 1,隐藏层节点数=128。HLR模型的参数使用相同的数据进行训练,确定了以下参数: 迭代次数=7 500 000,学习率=0.001,α=0.002,λ=0.01。SM-2模型不需要训练。对于剩余的80%数据,使用5次重复的2折交叉验证[18]进行评估。表2展示了SM-2、HLR、LSTM-HLR以及对应消融实验的结果。图2展示了各模型的预测分布情况。

表2 模型对比结果

图2 实验结果
图2(a)至图2(f)分别展示了各模型的MAPE(h)分布。其中,柱状图表示数据集中记忆半衰期的分布情况,可以看到半衰期主要集中在10天以内;折线图表示各模型的MAPE(h)在不同半衰期区间的大小。
通过观察表2我们可以看到,带有p1:i-1特征的LSTM-HLR +p模型表现最好;带有Δt1:i-1特征的LSTM-HLR +t模型略差于仅使用r1:i-1特征的LSTM-HLR模型。并且,使用时序特征的所有模型在所有指标上都优于只使用统计特征的HLR。我们认为这样的结果是基于一个事实: 一个学习者连续记住同一内容三次再连续遗忘同一内容三次,与先连续遗忘三次再连续记住三次,这两个过程是截然相反的。HLR仅考虑了历史累计正确次数和遗忘次数,无法区分这两个过程,只能在训练过程中给出折衷的预测,误差较大。

关于p1:i-1特征为何能降低预测的误差,我们认为这与心理学中记忆的提取强度与存储强度有关。较难提取的记忆经回忆会得到更多的强化[19]。在我们的模型中,历史的回忆概率可以反映出每次回忆的提取强度,而半衰期则类似于存储强度。因此,回忆概率历史对预测半衰期是有用的。
每次复习之间的间隔也是一个重要的信息。以(0-2-4-6-8)的间隔复习,与以(0-5-5-5-5)的间隔复习,效果会有显著的不同[5]。但出乎我们意料的是,在本实验中,Δt1:i-1特征并没有给模型带来显著的性能提升。通过观察数据集发现,本实验收集的间隔序列特征变化太少,特别是在短半衰期区间,反馈序列和间隔序列之间存在大量多对一关系,即不同的反馈序列对应了相同的间隔序列。这表明间隔序列没有提供有效信息,从而干扰了模型的预测。
5 总结
本文提出了一个预测语言学习中长期记忆的模型,使用行为序列对长期记忆建模,在HLR模型的基础上引入历史时序特征,使用LSTM网络进行训练,并对损失函数进行了调整。本文将记忆行为历史中的反馈历史、间隔历史和回忆概率历史纳入考虑,提升了回忆概率的预测精度,超过了传统模型和目前最先进的基于机器学习的模型。
LSTM-HLR模型在预测记忆方面有了较大的提升,在模型预测记忆的基础上,可进一步研究优化学习者复习时机的调度算法。LSTM-HLR模型不仅可用作强化学习中的学习者模型,也可用于研究记忆行为历史对记忆半衰期的影响。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
数学小灵通(1-2年级)(2020年11期)2020-12-28
小学生学习指导(低年级)(2019年3期)2019-04-22
长江丛刊(2016年33期)2016-12-12
图书与情报(2015年2期)2015-11-21
图书与情报(2014年4期)2014-12-03
读写算·小学低年级(2014年4期)2014-07-24
