
基于多异学习器融合Stacking 集成学习的窃电检测
2022-02-02 08:39游文霞李清清李文武吴泽黎
电力系统自动化 2022年24期
游文霞,李清清,杨 楠,申 坤,李文武,吴泽黎
(三峡大学电气与新能源学院,湖北省宜昌市 443002)
0 引言
电力的传输和分配涉及技术损耗(technical loss,TL)和非技术损耗(non-technical loss,NTL),而NTL 中绝大多数损失与欺诈和能源盗窃有关[1-2]。窃电通过对用电数据进行恶意的攻击,给供电企业带来了巨大的经济损失[3]。随着供电公司对窃电检测重视程度的增加,传统通过诸如线路窃听或电表篡改之类的物理攻击的检测方法难以有效检测出窃电的行为[4]。同时,智能电表和用电信息采集系统的普及使得越来越多的研究者可以更有效地采集用户用电数据,这是利用机器学习进行窃电检测的基础[5]。
目前,应用于窃电检测的技术主要分为3 种,即基于系统状态、基于博弈论和基于分类[6]。其中,基于系统状态的检测技术利用配电网状态估计与用户计量数据之间的矛盾进行窃电检测,但带来了附加的投资[7];基于博弈论的检测技术根据窃电者和检测者的行为分析相应的博弈均衡,但难以确定参与人的效用水平[8];基于分类的检测技术根据用户的电量以及用电曲线分布等特征采用数据驱动的方法进行窃电检测,目前已开展了广泛研究[9-17]。
对于窃电检测二分类问题,大部分都采用了单一学习方法[9-13]。而单一学习方法只能从单个角度观测用电数据,检测性能的提升空间有限。为了改善单一学习方法的局限性,近些年来在窃电检测中开展了集成学习方法研究。文献[14]采用日用电量为特征指标,提出一种基于稀疏随机森林(random forest,RF)的用电侧异常检测方法。文献[15]提出了一种采用决策树作为弱分类器的自适应提升(adaptive boosting,AdaBoost)树的窃电检测方法。文献[16]提出了一种特征工程的新框架,在该框架内应用梯度提升机(gradient boosting machine,GBM)算法进行窃电检测。文献[17]提出使用监督学习方法进行非技术损失检测,其中,极限梯度提升(eXtreme gradient boosting,XGBoost)树优于其他分类器。但是,这些集成学习方法一般采用投票法结合相同的学习器,不能体现出不同学习器的差异性。
上述研究为窃电检测领域提供了有效的解决方法,但依旧存在着以下不足:一是采用投票法作为结合策略的集成学习方法无法充分发挥不同学习器的优势;二是用户用电数据集中存在数据类别不平衡问题,导致分类结果出现偏倚。针对以上问题,本文提出一种利用元学习器融合多个不同初级学习器优势和差异的Stacking 集成学习方法。首先,采用合成 少 数 类 过 采 样 技 术(synthetic minority oversampling technique,SMOTE)算法处理类别不平衡的用电数据,实现训练数据样本分布均衡;然后,利用评价指标和多样性度量优选融合的不同初级学习器和元学习器,并采用K折交叉验证的方法对训练集进行划分以减小过拟合;最后,使用爱尔兰智能电表数据集验证模型的有效性。
1 相关理论介绍
1.1 SMOTE 算法
用户用电数据集大多存在数据倾斜方面的问题,即窃电用户所占比例远低于正常用户。为达到少数类和多数类样本的平衡,提高检测窃电用户的性能,本文采用SMOTE 算法进行无重复的新的少数类样本的生成[18]。
供电企业进行窃电检测的目的主要是识别窃电用户,采用SMOTE 算法可以增加窃电用户的数量,使正常用户和窃电用户的比例为1∶1。
1.2 Stacking 集成学习
1.2.1 集成学习的结合策略
集成学习的思想就是利用多个学习器来解决某一问题,使用不同的学习器和不同的结合策略会产生不同的集成学习方法[19]。其中,结合策略是集成学习中最为关键的部分。
针对分类问题,常用的结合策略有投票法和学习法。其中,投票法又包括多数投票法和加权投票法,而它们仅是简单地对学习器的预测结果进行逻辑加工,通过某种特定的方式为学习器寻求权重,并未有效利用数据空间。因此,一种更为强大的结合策略是学习法,即通过另一个学习器进行结合[20]。
1.2.2 Stacking 结合策略
Stacking 是学习法的典型代表,可利用某一学习器来集成不同学习器的分类结果,其中,不同学习器的多样性通过学习器的差异性来保证。它是一种有层次的集成学习,其层数可自由设置,但从各个领域的研究和应用来看,一般两层结构的Stacking 既能强化学习效果又不至于造成模型过于复杂[21-22]。因此,本文以两层的Stacking 集成学习为例进行说明。
Stacking 第1 层中的学习器称为初级学习器,第2 层中的学习器称为元学习器。其基本思想是:首先,根据合适的比例,将原始的数据集依次划分为训练集、验证集和测试集;然后,在平衡训练集D上,采用K折交叉验证法训练不同的初级学习器,将它们的分类结果输入元学习器,而D的初始标记作为元学习器的标记,结合起来形成新的训练集来训练元学习器;最后,由元学习器输出最终的分类结果,如图1 所示。
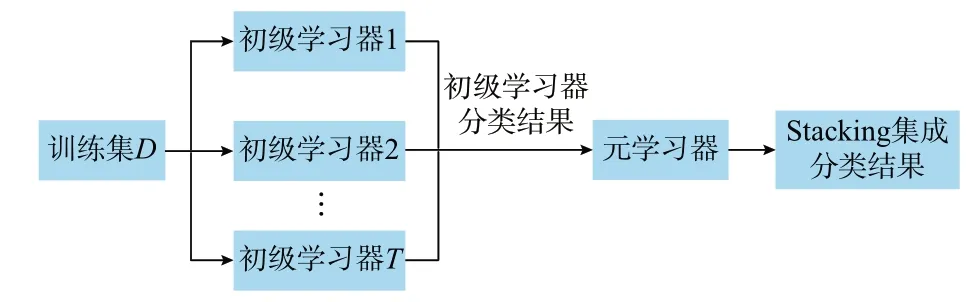
图1 Stacking 结合策略示意图Fig.1 Schematic diagram of Stacking combination strategy
2 Stacking 结合策略下融合多异学习器的窃电检测
用电用户包括正常用户和窃电用户。基于分类的窃电检测机理是利用机器学习中分类问题的相关方法来学习用户历史用电数据中蕴藏的规律,并以该规律来拟合大量未知的用电数据。
用户用电行为和用来判别异常的特征指标项是窃电检测的核心问题。在正常情况下,用户用电所形成的用电曲线分布具有较强的相似性。但是,在实际系统中,居民的用电行为更为多样化,由于住户旅游度假、改换工作、房屋更换租客等情况都可能导致用电行为习惯的突变。因此,本文在分析用户用电行为的基础上,从居民用户一天的用电量特征中提取出最大值、最小值、平均值和标准差这4 个综合特征用于辅助模型进行窃电行为的判别[23-24]。
2.1 窃电模式分析
窃电是指非法使用电能的行为。窃电用户会通过破坏智能电表来发起窃电攻击,使电量减少或不计[25]。在用户计量准确的情况下,用户电量主要与电压、电流、功率因数和用电时间有关,窃电用户可以根据这4 个影响电量的因素来进行窃电。窃电方法通常可分为5 种:欠压法窃电、欠流法窃电、移相法窃电、扩差法窃电以及无表法窃电[26]。欠压法窃电通过减小电表电压线圈上两端的电压而使电量减少;欠流法窃电以减小电表电流线圈上的电流来进行窃电;移相法窃电通过改变电压与电流之间正常的相位使有功功率减少从而实现窃电;扩差法窃电改变电表内的构造使电表的误差发生变化从而使电量少记;无表法窃电绕开电表直接从供电企业的公共线路上接线来实现窃电[27]。根据现有窃电的方法[28],可模拟为以下6 种窃电模式。
1)按照固定比例α减小t时段的电量wt,可通过欠压法、欠流法和扩差法来实现。函数表达式为:
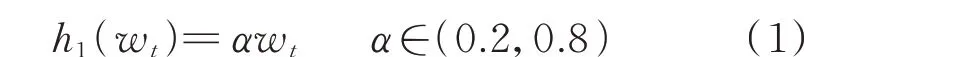
2)按照随机阈值γ削减电量wt,高于阈值γ的电量固定为γ,可通过扩差法实现。函数表达式为:
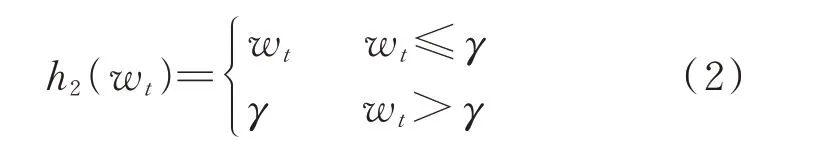
3)将随机时间段(t1,t2)内的所有电量wt置0,可通过欠压法、欠流法和无表法实现。函数表达式为:

6)取一天各时段用电量w的平均值,可通过欠流法、欠压法和移相法来实现,函数表达式为:
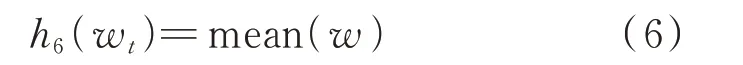
式中:mean(·)表示求平均值。
2.2 窃电检测模型
基于多异学习器融合Stacking 集成学习的窃电检测本质上是将用户历史用电数据作为输入,正常用户或窃电嫌疑用户作为输出的二分类模型,如图2 所示。

图2 基于多异学习器融合Stacking 集成学习的窃电检测Fig.2 Electricity theft detection based on multiple different learners fusion based on Stacking ensemble learning
2.2.1K折交叉验证
模型在训练集上表现良好,但在测试集上表现却不理想,表明模型可能出现了过拟合。对于训练集D={(xm,ym),m=1,2,…,N},其中xm为第m个示例,ym为对应示例的标记,N为示例总数。如果将该数据集同时用来训练初级学习器和元学习器,就会因用电数据被两层的学习器重复学习而造成很高的过拟合风险,导致对居民用户的用电行为判别不准确。因此,需要对平衡训练集D进行K折交叉验证。
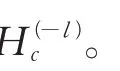
2.2.2 初级学习器和元学习器的选择
初级学习器的选择不仅可以从不同的空间和结构角度对居民用户历史用电数据进行数据挖掘,也会在实际的窃电检测中针对用电数据类别不平衡以及模型易陷入过拟合等问题实现不同学习器之间的优势互补,提高模型在窃电检测中的适应性。而相比于初级学习器的选取,单个元学习器的选取更加偏向于其分类过程中全方位的优化。附录A 阐述了不同学习器在窃电检测中的分类机理以及优缺点。

2.3 窃电检测流程
采用Stacking 集成学习融合多异学习器的窃电检测流程如下。
步骤1:根据“好而不同”的原则确定模型的初级学习器。初级学习器中的单一学习器初步考虑为分别来自机器学习里符号主义、连接主义和统计学习中常见的5 种单一学习器k-最邻近(KNN)[9]、逻辑回归(LR)[10]、决策树(DT)[13]、反向传播(BP)[12]和支持向量机(SVM)[11]。集成学习器初步考虑为分别来自集成学习中用于降低方差的Bagging 并行集成方式和用于减小偏差的Boosting 串行集成方式为代表的4 种集成学习器RF[14]、AdaBoost[15]、梯度提 升 树(GBDT)[16]和XGBoost[17]。在 包 含 正 常 样本和窃电样本的多个测试集上使用评价指标和多样性度量对比分析这9 个学习器,充分考虑预测能力较强和差异度较大的学习器,确定最终的初级学习器。
步骤2:在步骤1 的基础上,将以上9 个学习器分别作为元学习器进行对比分析,确定最终的元学习器。
步骤3:基于步骤1 和步骤2 确定最终用于融合的初级学习器和元学习器,训练出基于多异学习器融合Stacking 集成学习的窃电检测模型。
步骤4:在训练好的模型中输入用户用电数据,输出正常用户和窃电用户的分类结果。
2.4 评价指标和多样性度量
本文采用混淆矩阵衍生出来的准确率eACC、F1分数eF1和受试者工作特征(ROC)曲线下面积eAUC对模型的性能进行对比分析[1],见附录B。同时,利用成对度量指标——双误(double failure,DF)度量和Q 统计量从不同的角度衡量集成中学习器的多样性[30],见附录C。
3 算例分析
3.1 数据集
本试验数据集采用爱尔兰智能电表数据集,其中包括爱尔兰地区6 000 多户居民和企业用户长达535 d 的连续用电数据,每条数据以30 min 为单位记录了用户一天中48 个时段的用电量[31],单位为kW·h。从剔除了异常数据和缺失数据后的数据集中选取具有良好数据质量的1 000 名居民用户的用电数据进行实验。由于每个用户家中都装有智能电表,并且愿意提供他们的用电数据以用作研究,本文认为所有的用电数据均为正常数据。
为提供足够的窃电数据,按照2.1 节中的6 种窃电模式将随机选择10%的正常数据修改为窃电数据。将生成的这6 种窃电数据分别与正常数据进行混 合,得 到ET1、ET2、ET3、ET4、ET5 和ET6 共6 种混合数据集,数据样本已共享。同时,从中任意选取正常数据和窃电数据混合,得到MIX 混合数据集(即包含6 种窃电数据)。本文提出的窃电检测方法适用于包含这6 种窃电模式的数据集。
对于以上7 个混合数据集中的每一个数据集,将其中的全部数据按6∶2∶2 的比例划分为训练集、验证集和测试集。采用SMOTE 算法对用电数据进行过采样,使正常用户和窃电用户两个类别的用电数据平衡,再用平衡的训练集训练模型,用验证集调整参数,而用测试集进行模型的评估。附录D 为验证采用SMOTE 算法前后基于多异学习器融合Stacking 集成学习的窃电检测模型在MIX 混合数据集上的对比分析,由结果可知,采用SMOTE 处理不平衡数据集可使窃电检测性能得到提升。同时,从居民用户一天48 个用电量特征中提取最大值、最小值、平均值和标准差4 个综合特征。附录E 所示为最终基于多异学习器融合Stacking 集成学习的窃电检测模型在增加这4 个综合特征前后的性能变化,模型性能提升得到了验证。
本文采用的样本数据以及研究分析结果数据已共享,见支撑数据。
3.2 初级学习器的选取
为构建基于多异学习器融合Stacking 集成学习的窃电检测模型,需要利用评价指标和多样性度量从初步考虑的初级学习器中选出最终用于模型融合的初级学习器。因此,首先考虑上述9 个学习器在7 个混合数据集上的eACC、eF1和eAUC值,如图3 所示。图4 为这9 个学习器在MIX 混合数据集上的ROC曲线。其中,eTPR和eFPR分别为命中率和误检率,具体含义见附录B。
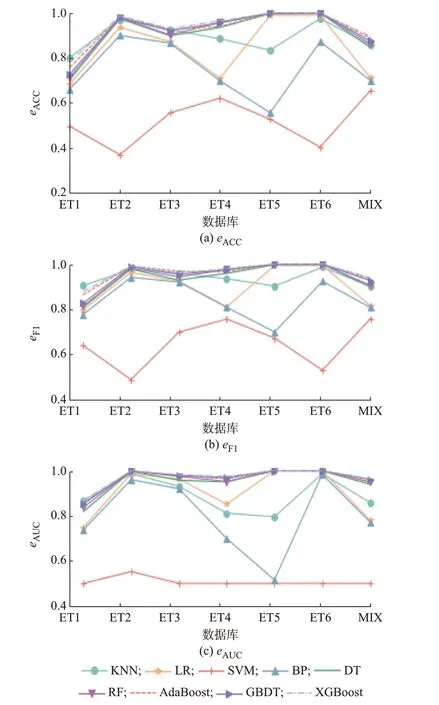
图3 9 个学习器在7 个混合数据集上的评价指标Fig.3 Evaluation indices of nine learners for seven mixed data sets
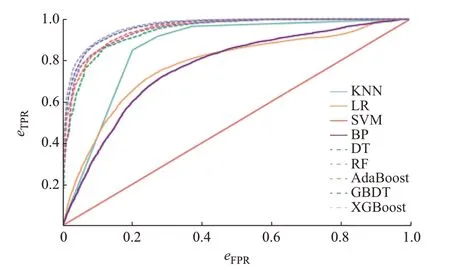
图4 9 个学习器在MIX 混合数据集上的ROC 曲线Fig.4 ROC curves of nine learners on MIX data set
从图3(a)和(b)可明显看出,SVM 在7 个混合数据集上表现最不佳,其eACC和eF1在部分数据集上低于0.5,而其余8 个学习器的eACC和eF1均超过了0.5。同 时,除SVM 外,BP 的eACC和eF1均 最 小。从图3(c)可知,SVM 在7 个混合数据集上的eAUC均不高(在0.4~0.6 之间)。而BP 的eAUC在7 个混合数据集上的浮动很大,在ET5 上甚至低于0.6,说明其在这7 个数据集上表现不稳定。此外,由于MIX 数据集包含了6 种类型的窃电样本,故相对于只含一种类型的窃电样本数据集而言,其观测结果更具说服力。因此,通过在MIX 混合数据集上的ROC 曲线可知,SVM 的ROC 曲线几乎与对角线重合,而其余8 个学习器的曲线都在对角线上方,这说明SVM 的性能与随机猜测的学习器的性能基本无异。
综上所述,SVM 和BP 识别窃电用户的效果差,既会将窃电用户判别为正常用户,又会将正常用户判别为窃电用户,即误判的概率很大,这样不仅会遗漏窃电用户而且会干扰正常用户。因此,初步考虑的初级学习器首先排除SVM 和BP。
其次,对于Stacking 集成学习来说,不同学习器的差异程度越大,元学习器可以改进的地方就越多,因此模型的分类性能就越好。所以在选出分类性能优异的学习器后,还需考察各个学习器的多样性,尽可能选择差异性大的学习器。图5 是7 个学习器在MIX 数据集上的DF 值和Q 值。
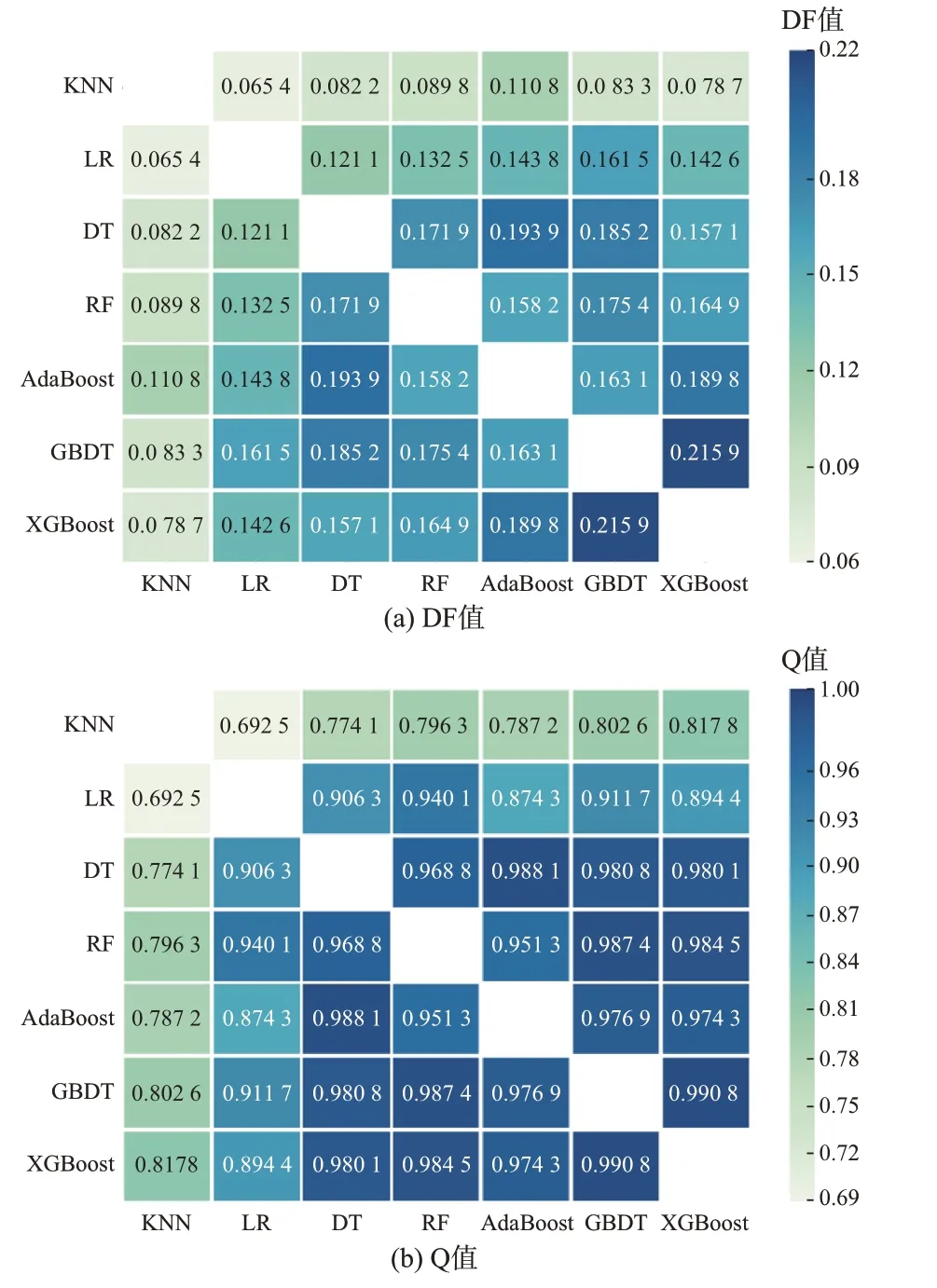
图5 7 个学习器的多样性度量Fig.5 Diversity measurement of seven learners
由于KNN 和LR 与其他学习器的训练机理差距较大,从而相关性较小,因此它们的DF 值和Q 值较其他学习器要小得多。并且对于单一学习器而言,虽 然DT 的eACC、eF1和eAUC值 大 部 分 都 为 最 高,但是它的DF 值和Q 值也最高。同时,与RF、AdaBoost、GBDT 和XGBoost 集成学习器相比,DT的分类性能相对较差。因此,单一学习器中选择KNN 和LR 作为模型的初级学习器。
RF、AdaBoost、GBDT 和XGBoost 这4 种集成学习器都是以DT 作为基学习器,数据观测方式存在较强相似性,所以DF 值和Q 值都较高。其中,RF 使用了用于减少方差的并行集成方式,AdaBoost、GBDT 和XGBoost 使 用 了 用 于 降 低 偏 差的串行集成方式。从图3 至图5 来看,XGBoost 的预测性能和多样性表现的都比AdaBoost 和GBDT 要好,故集成学习器中选择RF 和XGBoost 作为模型的初级学习器。
综上所述,DT 在识别窃电用户的效果不如其他集成学习器的同时相关性也很高,而AdaBoost 和GBDT 在相关性高的同时分类性能也不如XGBoost,这样容易造成融合后的模型多样性较低从而不能更加准确地识别窃电用户。因此,基于多异学习器融合Stacking 集成学习的窃电检测模型最终采用了KNN、LR、RF 和XGBoost 作为初级学习器。表1 为选择性集成前后各个学习器和系统的多样性度量指标值的表现情况。
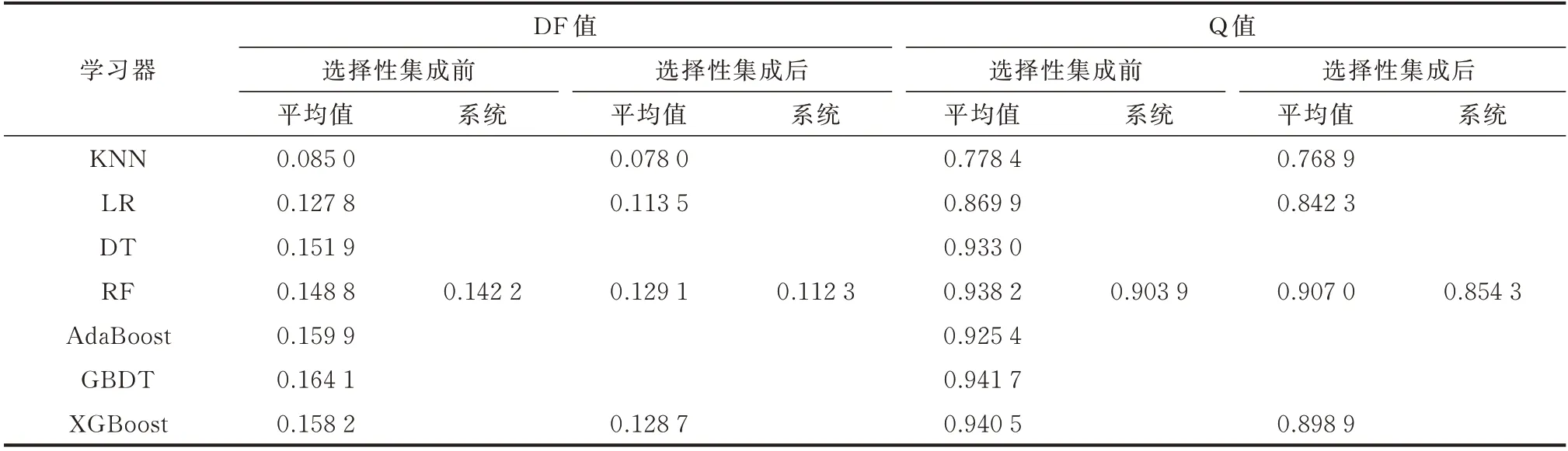
表1 选择性集成前后各个学习器和系统的多样性度量指标值Table 1 Diversity measurement indices of each learner and system before and after selective ensemble
由表1 可知,KNN、LR、RF 和XGBoost 这4 个学习器在选择性集成后的DF 值和Q 值较之前均有所减小,即选择性集成后的多样性程度更大。因此,通过评价指标和多样性度量优选好而不同的初级学习器能够使基于多异学习器融合Stacking 集成学习的窃电检测模型更加有效地从多个视角开展窃电识别。
3.3 元学习器的选取
Wolpert 早在提出Stacking 时就认为元学习器的类型非常重要,因为元学习器既可以改善各个学习器的偏差,又可以保证一定的泛化能力以缓解过拟合。所以针对窃电检测二分类问题,需要选择用于结合多异初级学习器的元学习器。
由于初级学习器的预测各不相同且各有优缺点,这时需要选择合适的元学习器才能使最终Stacking 集成学习的分类效果达到最优。因此,本文在选定的初级学习器的基础上,将最初进行对比的9 个学习器分别作为元学习器进行训练,验证训练得到的模型在7 个混合数据集上指标eACC、eF1、eAUC的平均值和平均运行时间,结果见表2。
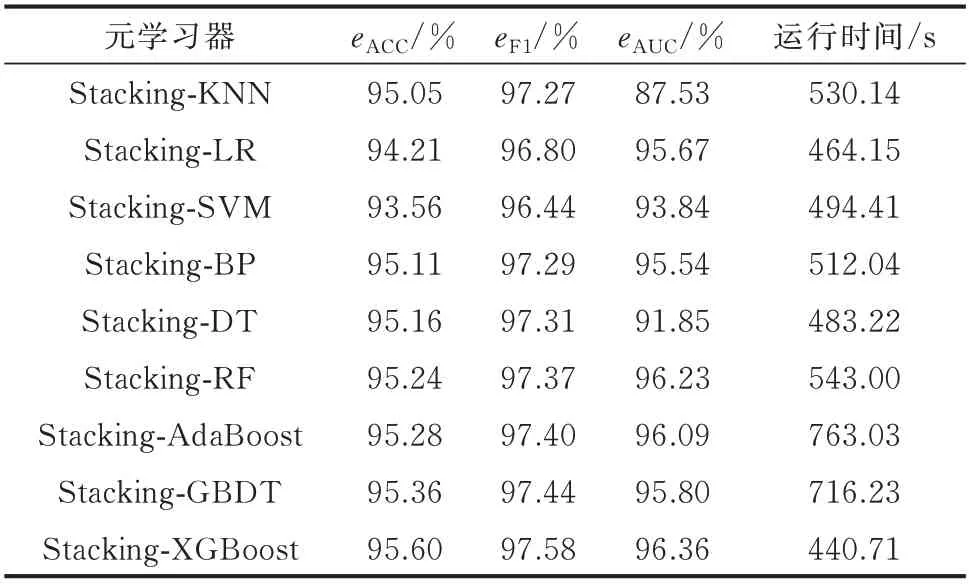
表2 9 个学习器分别作为元学习器在7 个混合数据集上指标的平均值Table 2 Averages of indices on seven mixed data sets by using nine learners as meta-learner respectively
在选定初级学习器后,当元学习器分别为KNN、LR、SVM、BP、DT、RF、AdaBoost、GBDT 和XGBoost 时,Stacking 融合后的eACC和eF1值都超过了0.93,由此可见元学习器可以充分发挥不同学习器的优势。但是针对窃电检测二分类问题,为了使初级学习器的优势发挥至极致,元学习器应选择使最终的融合结果达到最佳的学习器。由表2 可知,当元学习器为XGBoost 时,Stacking 集成模型表现最好,其eACC、eF1和eAUC值最高。
由表2 可以看到,除了XGBoost 外,集成学习器作为元学习器的运行时间都比单一学习器的要长,特别是以AdaBoost 和GBDT 作为元学习器的运行时间都超过了700 s,这是因为集成学习器的内部结构比单一学习器要复杂。但当XGBoost 作为元学习器时,运行时间仅有440.71 s,这比将单一学习器作为元学习器时的运行时间还要短,证明了当XGBoost 作为元学习器时,模型的复杂程度被降低。所以,基于多异学习器融合Stacking 集成学习的窃电检测模型最终采用XGBoost 作为元学习器。这样不仅能最大限度地避免误判和漏判,还能快速精准检测出窃电用户,减少供电公司的经济损失并提高检测效率。因此,通过选择最优的元学习器可以使基于多异学习器融合Stacking 集成学习的窃电检测模型的分类性能达到最优,从而辅助供电企业进行用电稽查工作。附录F 为在保证“好而不同”的条件以及元学习器不变的基础上,当初级学习器的数量分别为2、3 和4 时不同初级学习器组合方式在MIX 混合数据集上的对比分析。由结果可知,本文所提出的方法能够使模型的检测性能得到较大的提升。
3.4 对比分析
为了验证Stacking 结合策略下融合多异学习器的有效性,对于每种窃电方式将Stacking 集成学习方法分别与采用多数投票法(majority voting,MV)、加权投票法(weighted voting,WV)和改进加权投票法(improved weighted voting,IWV)[28]作为结合策略的集成学习方法进行比较,结果如表3 所示。
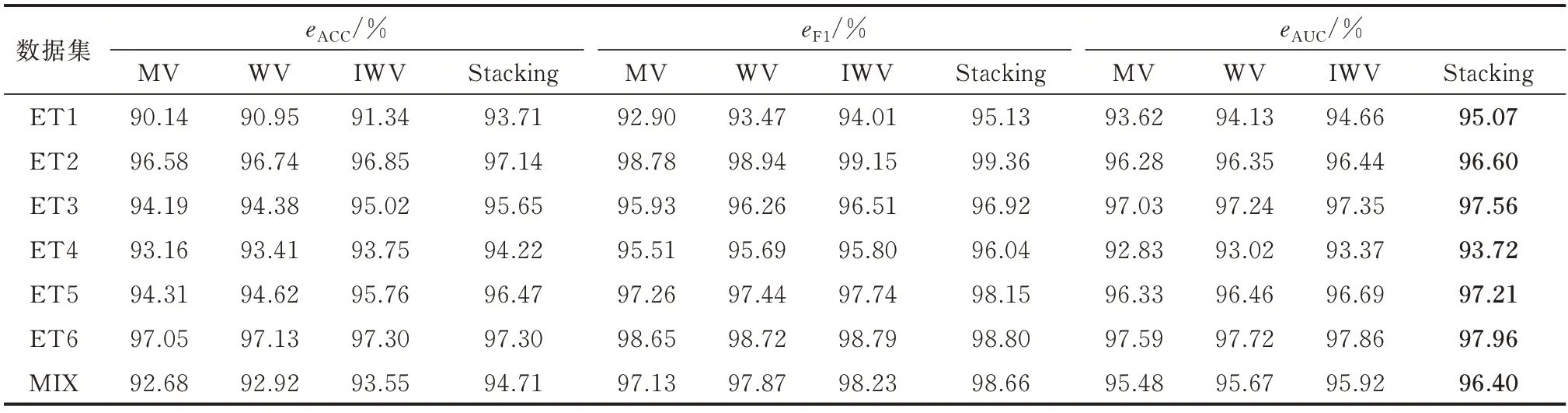
表3 不同结合策略的对比Table 3 Comparison of different combination strategies
如表3 所示,虽然在ET6 数据集上采用IWV 的集成学习方法的eACC与Stacking 集成学习方法一样,但是在其余数据集上其eACC和eF1都比Stacking集成学习方法要低。针对每种窃电方式,分别采用MV、WV 以及IWV 的集成学习方法,各方法对应eACC、eF1和eAUC的大小关系均为:IWV>WV>MV。由此看来,对于窃电检测分类问题,IWV 比MV 和WV 效果更好。
同时,由于Stacking 是利用元学习器XGBoost将不同学习器的优势发挥至极致,既能归纳并纠正不同学习器对于用电数据的偏置情况,又能保持较高的泛化能力来防止过拟合。所以,采用XGBoost作为元学习器的Stacking 集成学习方法在除ET6 外的6 个数据集上的eACC、eF1和eAUC都比采用MV、WV以及IWV 的集成学习方法要高,即有Stacking>IWV>WV>MV。特别地,对于采用IWV 的集成学习方法而言[28],本文所提出的Stacking 集成学习方法不仅可以充分发挥不同学习器的优势,还可以利用另一个学习器有效地综合这些优势。因此,通过选择最优的融合方式可以使不同学习器的优势发挥至极致,从而提升模型的检测性能。
综上所述,针对窃电检测二分类问题,本文所提出的利用Stacking 集成学习融合多个不同学习器的窃电检测模型有以下几个方面的优势:一是对于数据而言,通过SMOTE 算法平衡用电数据以避免分类结果出现偏倚;二是对于模型构建而言,采用K折交叉验证方法训练各个学习器以防止模型出现过拟合;三是对于融合对象而言,利用评价指标和多样性度量选择好而不同的多个学习器可以使模型能从多个视角识别窃电用户;四是对于融合方式而言,采用Stacking 集成学习方式可以利用优选的元学习器有效融合多个不同的学习器以充分发挥它们的优势,提升模型检测性能。
4 结语
本文提出了一种基于多异学习器融合Stacking集成学习的窃电检测模型。针对用电数据类别不平衡以及采用投票法作为结合策略的集成学习方法无法充分发挥多个不同学习器优势等问题,本文利用SMOTE 算法构造平衡的数据集,并采用Stacking结合策略融合多个不同学习器的优势和差异。在爱尔兰智能电表数据集上进行了验证,算例表明该模型可有效解决类别不平衡问题,且能够充分发挥不同学习器的优势。进一步将研究以下问题:一是窃电检测中的数据质量问题;二是利用电压等新特征开展窃电检测;三是当正常用户的用电行为模式和按窃电模式生成的用户用电模式相似时所造成的误判问题。
支撑数据和附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·中考版(2020年12期)2021-01-18
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
活力(2019年15期)2019-09-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
唐山师范学院学报(2018年6期)2018-12-25
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
