
电力高压设备高性能有限元电磁仿真方法综述与展望
2022-02-02 10:23邹军杨帅程启问
南方电网技术 2022年12期
邹军,杨帅,程启问
(清华大学电机系, 北京 100084)
0 引言
构建以新能源为主体的新型电力系统是实现中国“30·60”“双碳”战略目标的基础支撑。新型电力系统包含交流线路、直流线路、高压电力设备和大量新能源接入的电力电子装置。由于新型电力设备和电力电子装置的接入,电力系统中将存在大量时变的和非线性的“元件”,电力系统运行特性变得更为复杂[1-3]。为模拟电力系统的特性,亟须逐步从器件级、变换器级、系统级开展不同尺度建模和仿真,这些仿真的基础之一是对高压电气设备和装置的电磁行为特性进行高精度建模。
有限元方法是一种通用的偏微分方程求解技术,其对于任意几何形状和材料都能够稳定获得数值解,为实际工程实践提供定量化的指导[4]。科学和技术领域中对电磁建模的需求不断增长,催生了以有限元方法为基础的商业软件。商用电磁仿真软件具有友好的人机接口,可与计算机辅助设计(computer aided design,CAD和计算机辅助工程computer aided engineering,CAE)的软件结合,在实践中获得了巨大的成功。在电磁仿真领域,借助各种变换、因子分解和对角化技术,求解数十亿自由度的稠密矩阵已经成为可能。新型宽带求解器、等效方法和区域分解法等计算技术可以对多尺度问题进行全波分析,而不必对实际问题做过多的简化。有人认为数值计算机技术已经“完结”,无需研究新方法和技术,所有的电磁问题可以采用商业软件和集成更高算力的计算机/工作站最终得以解决。但是,由于新应用场景不断出现,例如纳米电磁学、手征材料和强非线性多物理耦合等场合,商业软件功能局限性日益突出,对于计算规模在数千万单元、瞬态、非线性和多物理场耦合问题,仿真能力和手段还非常有限。对于所仿真的系统往往通过增加硬件开销的方式采用蛮力进行计算,计算效率无法保证。因此,对有限元方法和加速技术的研究重新被学术和工业界人士所重视。
本文聚焦于有限元方法,从高性能有限元技术的发展路径出发,讨论有限元技术发展的方向和当前的瓶颈问题。同时,结合电力系统电磁仿真的特点,简要讨论了计算电磁学的关键技术问题和可能的发展路线图。
1 工程电磁场有限元方法回顾与挑战
在20世纪初,不同研究领域的科学家都曾独立提出了对微分方程的变分形式进行离散的求解思路[5],其中德裔美国数学家Courant的工作被认为是有限元方法的起源:Courant在分析轴的扭转问题时将轴的横截面离散成若干三角形单元,并用每个节点上未知量的线性插值表示截面上的应力分布。在20世纪50年代初,波音公司的工程师独立发展出了基于能量极小原理的“直接刚性方法”,并广泛应用于机翼结构的建模仿真[6]。20世纪年代初,为了突出在有限单元上进行积分运算的特性,Clough正式提出了“有限元方法”这一名词。作为Rayleigh-Ritz方法的一种形式,有限元分析开始被学术界广泛接受,不同领域的学者尝试在本领域中使用有限元方法,应用数学家也开始着手建立有限元方法的数学理论。1962年至1972年被称为有限元方法发展的黄金十年[7]:有限元的求解对象从椭圆方程拓展到双曲方程和抛物方程,应用场景从结构力学拓展到热传导和流体分析;经典的有限元技术诸如分片测试、协调单元和非协调单元、等参变换在这一时期被提出;针对有限元方法的误差分析和收敛性分析理论被建立;在这一时期也涌现了大量经典有限元计算程序,如NASA发展的结构有限元分析软件NASTRAN、John Swanon发展的通用有限元分析软件ANSYS等。为了解决传统变分理论的有限元方法在求解时出现的数值振荡问题,Zienkiewicz等人提出了基于迎风格式的Petrov Galerkin有限元方法[8];在此基础上针对暂态问题发展出了与波传播特征相结合的Taylor Galerkin有限元方法[9];1990年前后,Cockburn和舒其望等人提出了具有通量守恒特性的离散Galerkin有限元方法[10]。
随着计算电磁学研究对象越来越复杂,模型越来越精细,有限元离散后生成的代数方程组规模愈来愈大,这对现有有限元方法提出了新的挑战。以高电压工程中的流注发展问题为例,受限于CFL条件,迭代的时间步仅为数皮秒,实际仿真中需要进行上千步迭代,而每一个时间步需要求解一个涉及上亿自由度的问题[11];在仿真计算高压绝缘子表面电位时,绝缘子的几何尺度远小于杆塔的几何尺度,导致整个计算区域离散后产生数百万个节点[12];大地电阻率反演问题中,采用精细的像素级剖分后将产生数百万待反演参数,在反演过程中需要使用有限元方法反复求解正问题[13]。由于特高压工程的推进,大量超常规的高压设备也需要重新进行设计:大容量电力电子器件中电-热-力三种物理场相互耦合,共同决定了开关性能;针对高压套管中电场优化需要解决分层介质导致的多重尺度问题;在电力变压器中各类软磁材料引入的强非线性对数值仿真的稳定性和精度提出挑战。总结来看,电力系统高压设备电磁仿真中存在大量三维、时域以及非线性问题亟待解决,为此,中国学者提出了“计算高压学”的概念,而有限元是其核心支撑技术之一。在新型电力系统中,有大量电力电子设备的应用,考虑到整个系统的电磁特性,计算空间尺度可能会跨越3个数量级以上,目前还不能完全采用场的方法仿真。
2 高性能计算有限元方法的应用进展
2.1 高性能计算硬件发展
高性能计算,即使用尽可能多的硬件资源完成特定问题的计算。将一个串行计算程序转化成并行程序并移植到高性能计算机上运行,涉及两类操作:分解和映射[14]:将计算任务分解成一组按照任务依赖图并行执行的任务,然后映射到各个计算单元上执行。为了在最短运行时间内执行完相关任务,需要根据实际计算单元特点将任务分解成特定粒度的子任务,同时最小化单元间通信开销,减少不同计算单元之间的交互。由此可见,高性能计算技术的应用依托于计算平台本身。
在处理器发展早期,计算性能的提升主要靠提升主频和处理器内部的隐式并行[15]:提升主频,即缩短处理器的时钟周期,从而提升单位时间内浮点数运算能力;处理器内部隐式并行则是通过流水线技术结合超长指令实现指令级并行,提高硬件利用率,进而提升计算性能。由于单个处理器计算性能低,内存小,为了获得更高算力,需要将大量处理器通过高速通信网络连接,构成大规模并行处理机(mas parallel processor, MPP)[16]。在这一阶段,主要是通过区域分解法将大规模问题分解成若干小规模的子问题并分配给各个结点进行计算,再通过结点间的通信传递不同子问题间的相互影响,最终实现对原问题的求解。区域分解法本质上是通过牺牲计算时间,使用有限计算资源求解大规模计算问题,当问题规模较小时,使用区域分解法将带来近十倍的耗时增长[17]。
随着芯片制造工艺发展和指令集的更新,单核处理器性能逐渐逼近理论上限,为进一步提升处理器性能,多核(multi-core)构架应运而生:处理器由多个独立的计算核心构成,各个计算核心通过共享高速缓存与多线程技术相结合,实现更高计算性能。多核构架受限于高速缓存一致性,随着核数增加,缓存信息的维护成本越来越高,难度越来越大。为进一步提升处理器计算性能,在多核构架基础上发展出了众核(many-core)构架,即放弃高速缓存一致性,通过堆叠更多计算核心来提升算力。典型的众核处理器有通用图形处理器(GPU)、志强协处理器(Xeon Phi)等。基于不同设计理念的构架具有完全不同的特性,相应的处理器适用于处理不同的问题[18]:1)多核处理器:适合顺序执行复杂指令,串行计算性能高;由于线程切换开销大,并行计算性能较弱。2)众核处理器:适合执行单指令多数据(single instruction multi-data,SIMD)或单指令多线程(single instruction multi-thread,SIMT)操作,并行计算性能高;由于每个核上寄存器数量较少,不适合执行复杂指令。
随着众核处理器的出现,有限元方法能够进行更细粒度的分解,实现单元级并行,即单个核心(或单个线程)处理一个单元。随着问题规模增大,GPU的显存成为限制求解规模的主要瓶颈[19]:以2020年最新发布的A100显卡为例,其最大显存仅为40 GB。为解决这一问题,研究人员提出了多GPU联合仿真的解决方法。如图1所示,将整体刚性矩阵分块,每块GPU负责一块子矩阵的生成和装配;求解矩阵方程时,各个GPU并行完成矩阵-向量乘法,将计算结果传递给CPU,再由CPU进行组装并分发给各个GPU。多GPU联合仿真时,由于引入了CPU进行收据收集和分发,需要考虑由此产生的CPU-GPU通信开销:随着并行GPU的数量增加,从CPU向GPU分发数据时会造成数据总线阻塞,相应地通讯开销会成倍增长。如表1—2所示,当GPU数量从2块增长为4块时,从CPU向GPU分发数据的时间从4 ms增长为8 ms[20]。
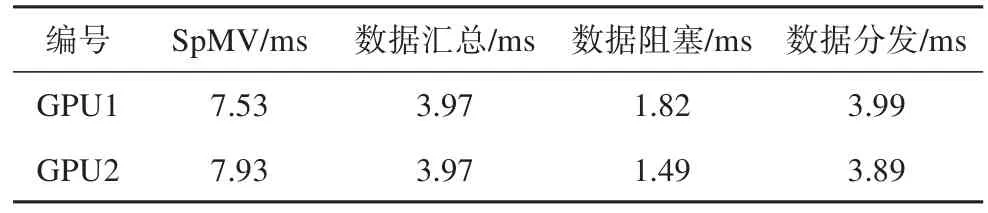
表1 块GPU联合仿真时各类操作的耗时 (GPU数量为2)Tab.1 Time-consuming of various operations in block GPU co-simulation (the number of GPU is 2)

图1 多GPU联合仿真模式Fig.1 Multi-GPU co-simulation mode
目前主流服务器、工作站往往同时提供多核处理器和众核处理器,而在上述提到的研究中,计算任务完全由GPU执行,CPU只起到居中协调的作用。为了进一步提升算力,需要让闲置的CPU也参与计算。为实现CPU和GPU联合的异构计算,需要设计合理的任务分配机制。研究人员提出了两类任务分配策略:静态分配——在任务开始前将任务分配给各个计算单元;动态分配——在任务执行过程中将任务分配给各个计算单元。

表2 块GPU联合仿真时各类操作耗时 (GPU数量为4)Tab.2 Time-consuming of various operations in block GPU co-simulation (the number of GPU is 4)
如图2所示,由于CPU向GPU的通信开销以及GPU的准备时间,在问题规模较小时使用CPU执行的耗时要小于GPU执行的耗时。基于此,文献[21]制定了静态的任务分配策略:当问题规模小于设定阈值时,只使用CPU;随着问题规模增大,将大部分任务转移到GPU上执行,余下少量任务留在CPU上执行。在特定问题规模之下,这种静态分配策略比仅使用GPU的策略快1.5倍。

图2 不同问题规模下CPU和GPU计算时间对比Fig.2 Comparison of CPU and GPU computing time under different problem scales
文献[22]在利用时域有限元仿真时采用了动态任务分配策略:根据上一个时间步的各个计算单元的计算耗时,调整下一个时间步各个计算单元的任务量,从而实现动态负载均衡。最终计算结果如表3所示,可以看到在动态任务分配机制下,CPU+GPU的异构计算性能优于仅使用CPU或GPU的计算模式。

表3 不同硬件平台上,GPU-CPU联合仿真加速比Table 3 GPU-CPU co-simulation speedup ratio on different hardware platforms
单个计算机的算力有限,为了进一步提升计算能力,基于多机互联的分布式计算应运而生:大量由通信网络连接的计算机构成一张网络,通过任务分配调用网络中闲置的计算资源,实现巨大算力的使用,这便是网格计算;而由特殊的高速通信网络和同构计算机互联形成的则是计算集群如常见的超级计算机。随着虚拟化技术的发展,网格计算进一步发展为如今的云计算,“计算”作为一种资源以越来越便捷的方式提供给客户。
2.2 有限元方法加速技术
对于非线性问题和时域问题,通过线性化、时域离散后都可化简为若干稳态问题的求解。使用有限元方法求解稳态问题可分为3步:单元矩阵生成、整体矩阵装配以及线性方程组求解。在实际计算中这3步都可能成为瓶颈。如图3所示,对于非线性色散介质中电场仿真,随着计算规模增长,单元矩阵分析和装配耗时占总计算时长的99%[23];而在电磁辐射场仿真中,表4结果指出线性方程组的求解耗时在总计算耗时中占主导地位[20]。下面,将分别介绍单元矩阵生成、装配和线性方程组求解这3步的加速技术。

图3 不同计算规模下整体刚性矩阵生成耗时在总计算时间中占比Fig.3 Proportion of the overall rigid matrix generation time in different calculation scales in the total calculation time

表4 矩阵装配和求解环节的计算时间对比Tab.4 Comparison of calculation time between matrix assembly and solution
2.2.1 单元矩阵生成
单元分析时仅用到各个单元自身信息,可以进行逐单元并行:对于低阶单元,往往使用单个线程(或单个核心)来生成对应的单元刚性矩阵[24];对于高阶单元,单元刚性矩阵规模较大,需要分配更多计算资源来生成一个单元矩阵[25]。由于不同单元在分析过程中都需要读入相关单元的节点信息,大量的内存读写操作使得这类传统的并行方法效率提升有限。另一种加速思路是将单元分析过程进行张量化改写。
2.2.2 整体矩阵装配
获得各个单元的局部刚性矩阵后,需要装配形成整体刚性矩阵。由于一个节点的所有邻接单元矩阵对这一结点均有贡献,在装配时的归并操作将导致内存的冲突读写。为解决这一问题,一种常见的解决思路是染色法:对计算区域内单元进行染色,使得相邻单元不同色。每次将具有相同颜色单元的局部刚性矩阵装配至整体刚性矩阵中,从而避免了竞争冲突;另一种解决方法是将矩阵装配环节和后续的线性方程组求解环节相结合,如逐单元(element by element)有限元[26]、节点分解(nodal domain decomposition)有限元[27]等,这些免装配方法实际上都可视为多波前方法的变种[28]。
2.2.3 稀疏线性方程组求解
通过单元矩阵生成和装配后,原偏微分方程被离散成大型稀疏线性方程组。如何求解稀疏线性代数方程组一直是高性能计算领域的核心议题。针对大型稀疏线性方程组的解法可以分为两类。
第一类是基于高斯消去法的直接求解器。直接计算方法可分为填充元优化、符号分解、数值分解、消元回代4步。其中填充元优化是对矩阵进行重排序,在保证数值稳定性的同时,使得后续矩阵分解时产生尽可能少的填充元,从而提高计算效率。常见的方法如最小度算法、重复剖分算法以及多重剖分算法。而符号分解则是现代快速直接解法特有的技术,通过使用消去树这一数据结构,确定分解因子矩阵的非零元位置,指导分解路径,如基于一般消去树的多波前方法和基于超节点消去树的多元最小度方法等。直接解法的优点是计算稳定可靠,因此也成为大量通用有限元计算软件中的默认求解器;其缺点是计算过程中产生的分解因子、波前矩阵等中间变量规模不定,随着问题规模增大,超出内存容量后超出部分只能存储在硬盘中,硬盘的I/O操作成为计算瓶颈制约了直接解法的性能。
第二类是迭代解法。预计于Gauss消去法的直接解法不同,迭代解法是在特定的解空间中不断寻找更接近真解的元素,其中最常见的是基于krylov子空间的迭代方法:如先验共轭梯度迭代算法(preconditioned conjugate gradient,PCG)方法、双共轭梯度(biconjugate gradient,BiCG)方法等。在迭代求解过程中需要不断进行稀疏矩阵向量乘法操作(sparse matrix-vector multiplication,SpMV)来获得当前解对应的残差,并基于此进行修正。如何高效地执行SpMV操作成为该类解法的研究重点。研究人员通过调整稀疏矩阵的存储格式来实现内存的合并读写,优化SpMV操作的性能。常见的存储格式可分为两类:行主元的COO格式、CSR格式、CTO格式以及列主元的ELL格式,Sliced ELL格式等[29]。针对硬件配置选择特定的存储格式,在存储空间最小化同时通过缓存的合并读写实现时空效率的最大化。
迭代求解器中另一个关键技术是预条件处理。随着问题规模增大,刚性矩阵的条件数越来越大,通过预条件处理能够显著提升迭代算法的收敛性能。在并行求解器中,刚性矩阵往往是分块存储,如何根据局部矩阵信息生成预条件矩阵是并行求解器研究的热点,目前发展的并行预条件矩阵有:不完全LU分解预条件子,分块Jacobi预条件子,最小二乘多项式预条件子以及多重网格预条件子等。相较于直接求解器,迭代求解器计算过程中对存储的需求固定,借助区域分解方法容易实现稀疏矩阵-向量乘法操作的并行化,适合求解较大规模问题;而迭代解法的缺点也非常明显:无法保证收敛、生成性态优良的预条件矩阵较为耗时。
纵观有限元发展历史,求解器经历了迭代方法(Gauss-Seidel方法)、直接方法(变带宽方法)、PCG方法再到多波前等直接解法的螺旋式发展[30]。如今直接解法能够有效求解百万自由度的有限元方程,而迭代解法多用于更大规模问题[31]。无论是直接解法还是迭代解法,性能的提升都是通过发掘稀疏矩阵自身结构并与计算机硬件相结合来实现,随着计算机硬件发展,如何利用多核和众核处理器实现高效求解成为新的问题。
3 高性能有限元技术发展现状与展望
3.1 从工业软件角度重新认识电磁仿真软件
随着物联网(internet of things,IoT)技术的成熟,实时获取设备运行过程中的各种参数成为可能。为了有效利用这些参数对设备全生命周期进行预测和控制,数字孪生(digital twin)这一概念被提出。由于实际设备的物理模型过于复杂,传统数值仿真往往采用简化模型:如使用集总参数模型、将非线性时变的材料特性线性化等。仿真模型和实际模型间存在较大的差异,极大地限制了仿真结果的准确性,因此传统数值仿真仅作为优化设计的辅助工具。大量设备内部参数的出现使得数值仿真模型能够深入设备内部,尽可能真实地还原实际运行工况,在此基础上得到的仿真计算结果准确度大大提高,基于此能够进行对设备运行过程中出现的故障进行检测、定位以及预测。
数字孪生概念的出现极大地拓宽了电磁场数值仿真的应用场景,同时也提出新的挑战:精细的模型往往兼具时域、三维、非线性等特征,某些复杂的问题还涉及热场、流场、应力场等多物理场耦合。如何利用边缘计算、云计算等新兴技术实现稳定高效地求解是一个亟待解决的问题。
3.2 借力国际开放资源
在国际科学计算社区中不同研究团队分别提出并发布了用于偏微分方程求解的高性能数值计算库:Gmsh提供二维、三维结构的网格剖分;METIS则能够对网格编号进行重排、分解;针对大型稀疏代数方程组,MUMPS提供了基于多波前方法的直接求解器,Hypre、AGMG等软件则提供了基于代数多重网格方法的迭代求解器;可移植可拓展科学计算工具箱PETSc专门用于求解偏微分方程;Trillinos使用面向对象的软件框架,通过调用各个组件实现大规模复杂多物理场求解;另外还存在大量基于上述计算组件二次开发的有限元计算软件,如Deal.Ⅱ、FENICs、MFEM等。这些开源的高性能计算软件是当前偏微分方程数值解研究的重要基础,在计算流体力学、计算力学等领域都得到广泛的应用,但在计算电磁学领域未见报道。
3.3 结合人工智能技术的数值计算方法
近年来,大数据和人工智能技术突飞猛进,深度神经网络技术给传统科学计算带来新的诠释。神经计算框架之下,科学计算问题可分为3类[32]:第1类问题是完全由数据驱动的问题,常见的如对风、光等自然资源的实时预测。由于实际模型未知,往往直接简化为黑箱模型进行处理,采用神经网络对数据进行拟合、挖掘;第2类问题则是基于部分物理机理和少量测量数据的不确定性模型,常见的如逆散射问题,即控制方程已知,根据测量数据反演出待求的模型参数。这一类问题往往可以写为PDE约束下的优化问题,借助神经网络这一优化求解器进行求解;第3类问题是基于已知模型的确定性问题,经典计算电磁学问题往往属于这一类。有限元过程可以等价改写为神经网络的形式(FEA-net),即每个神经元的输入为单元几何信息,输出为单元刚性矩阵[33]。应用神经网络技术求解上述3类问题具有两个显著优势:一是借助各类演化算法能够处理复杂的非线性优化问题;二是神经网络本身是对计算任务的细粒度分解,能够实现高性能计算。将经典的计算电磁学问题与如今蓬勃发展的神经计算相结合,也是未来的发展方向之一。
3.4 发展异构计算和跨平台的高性能计算方法
高性能计算技术的发展与高性能计算机的发展是密切相关的,基于高性能计算技术的有限元方法在计算电磁学中的应用经历了从最开始只有单核CPU,发展到多核处理器,再到多核处理器和众核处理器并存的异构计算环境。随着硬件平台在不断更新换代,单位计算资源的成本越来越低:1997年,提供1TFlops计算能力的硬件需要花费4 600万美元,而在2017年,使用相同的计算资源仅需要30美元[34]。相较于发展精巧的计算方法,高效利用“廉价”的硬件资源求解复杂的电磁学问题更为重要,也更加有效。
在目前高性能有限元计算方案中,还存在以下问题:其一,现有研究针对特定硬件的加速技术,这些技术往往受限于特定的问题或特定的计算平台,尚缺乏一款具有可移植性、可拓展性以及较高硬件利用率的计算程序;其二,除多核与众核处理器外,张量处理器 TPU[35]、神经计算单元 NPU[36]、量子处理器[37]等新兴的计算单元也在不断发展,有限元方法与这些硬件的结合也是一个亟待解决的问题。
4 结语
有限元方法作为一种通用的数值求解技术,以其强大的计算能力,在电磁仿真领域获得巨大成功。由于新应用场景的出现,电力系统高压设备电磁仿真对有限元方法提出了新的需求。从技术路径发展上,高性能有限元技术是上述问题的一个可能的解决方案。本文介绍了高性能有限元方法的主要技术要点,讨论其相关的发展途径,希望对高性能有限元方法在电力系统高压设备仿真的应用有所推动。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
上海节能(2020年3期)2020-04-13
电子制作(2017年19期)2017-02-02
山东工业技术(2016年15期)2016-12-01
汽车实用技术(2015年8期)2015-12-26
汽车维护与修理(2015年1期)2015-02-28
汽车零部件(2014年8期)2014-12-28
汽车零部件(2014年1期)2014-09-21
船海工程(2013年6期)2013-03-11
微型计算机(2009年17期)2009-05-19
