
基于稀疏超高维非参数可加模型的条件独立筛选
2022-01-28 09:26:24钟思敏李斌斌熊文俊
广西师范大学学报(自然科学版) 2022年1期
徐 萍, 钟思敏, 李斌斌, 熊文俊
(广西师范大学数学与统计学院, 广西桂林541006)
随着科学技术的快速发展,人们获取并储存数据变得愈加简便,超高维数据在各研究领域中频繁出现。传统基于惩罚思想的变量选择方法,如LASSO、SCAD、MCP、Elastic Net等,面临计算效率、统计准确性和算法稳定性等挑战,已不再适用。针对这种情况,Fan等[1]提出了SIS方法,在全变量组中按皮尔逊相关系数将变量进行排序,筛选出前n/lnn个变量,再通过已筛选出的变量做变量选择及参数估计。皮尔逊相关用来衡量线性相关性,该方法在超高维线性回归模型中表现良好,在非线性情况下,为了同时衡量线性与非线性关系,Hall等[2]采用广义相关系数代替皮尔逊相关系数作为筛选指标;皮尔逊相关对重尾分布、异常值点比较敏感,秩相关是一种稳健测量2个随机变量之间关系的方法,Li等[3]提出基于秩相关性的变量筛选方法(RRCS),RRCS方法不仅筛选性质可靠,对异常值与强影响点也表现出强大稳健性;在广义线性模型下,Barut等[4]考虑已知某些重要变量集时,构建每次添加1个待筛变量进入重要变量集,并与响应变量建立边际回归模型,该方法可以大大降低伪变量错选概率;当变量是分组形式时,马学俊[5]提出组确定独立筛选(GSIS);当模型为广义线性模型时,Fan等[6]提出最大边际似然估计量(MMLE)排序筛选重要位点,只要自变量与因变量存在微弱相关,MMLE的边际信号强度就比随机噪声大;同时,Fan等[1]提出迭代版本的SIS(ISIS),它可以显著改进简单边缘筛选,选择边际较弱但仍然重要的预测变量,并删除伪相关预测变量,这些伪变量与重要变量强相关,展现出与响应变量虚假相关;Xu等[7]认为迭代过程增加大量计算成本和复杂度,提出了广义线性模型的稀疏约束(SRMLE)方法,并证明SRMLE不仅保留迭代过程的优点,而且计算更加简单。前面介绍的都是基于特定模型下变量筛选的方法,在实际应用中,参数化模型,如线性模型和广义线性模型可能会导致模型不规范。非参数模型在缺乏关于回归模型结构先验信息的情况下变得非常有用,并增强模型的灵活性,特别是对于检查模型假设有很大挑战的超高维数据。因此,非参数模型的变量筛选方法研究自然引起研究者们的极大关注,多名学者提出了一些非参数模型的变量筛选方法。如Fan等[8]基于可加模型提出非参数独立筛选(NIS)方法以及迭代版的INIS方法;Fan等[9]将可加模型的NIS扩展到变系数模型;Liu等[10]从不同角度提出另一种基于条件相关系数(CC-SIS)的超高维变系数模型的确定独立筛选方法;Li等[11]基于距离相关系数提出DC-SIS变量筛选方法等。
实际应用中存在已知部分变量显著与响应变量相关,忽略这些信息显然不明智,因此,Barut等[4]提出条件独立筛选方法(CSIS),该方法只对特定参数模型,如线性模型、广义线性模型有效。本文基于非参数可加模型提出条件非参数独立筛选(CNIS)方法,该方法针对非参数模型情形有很好表现。
1 主要结果
1.1 可加模型
设(Yi,Xi),i=1,…,n独立同分布于总体分布(Y,X),其中Y是响应变量,X=(X1,…,Xp)T为p维已知协变量。根据Stone[12]定义如下非参数可加模型
(1)
式中:μ是截距项;fj(·)为未知光滑函数,假定已中心化,即Efj(Xj)=0,j=1,…,p;εi是均值为0方差有限为σ2的随机误差。在超高维数据中,基于稀疏性假定,大部分f(·)≡0,研究目的是找出这些函数中非零部分。
对可加模型的非参数函数,直接估计fj的表达式困难,故采用B样条多项式进行函数近似拟合,以此估计fj。Riesenfeld[13]提出B样条曲线,通过一组标准B样条基函数有效逼近上述非线性函数。假设所有Xj都在区间[a,b]上,α=η0<η1<…<ηK-1<ηK=b将区间[a,b]分割为K个子区间,IKt=[ηt,ηt+1],t=0,…,K-2表示前K-1个子区间,IKK=[ηK-1,ηK]。对第k个子区间,其h次样条基函数φk,h定义如下
其递推公式为
假设Sn为h次多项式样条空间,{φjk}是定义在Sn上的一组标准基向量
(2)
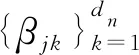
(3)

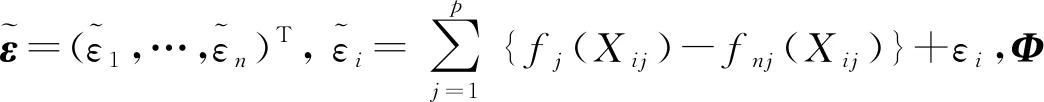
此时,模型(1)筛选非零函数问题转变为对数据进行估计的线性回归问题,不同于普通线性模型,该问题的协变量为已分好的组变量。
1.2 条件非参数独立筛选
为简便起见,假设XC=(X1,…,Xc)T为已知与响应变量Y显著相关的变量,对应的待筛选集合记为XQ=(Xc+1,…,Xp)T。条件筛选目的是在给定XC集合情形下,从XQ集合中筛选出剩余的重要变量。因此,可以构建如下联合回归方程
(4)
其含义为每次都从XQ中取一变量与XC变量集做关于Y的联合回归,并估计出fj。将式(4)转化为如下Adaptive Group Lasso惩罚线性回归
(5)

Φj≡Φj(Xj)=(φj1(Xj),…,φjdn(Xj));φjk(Xj)=(φjk(X1j),…,φjk(Xnj))T,k=1,…,dn,
对集合XC,对应的变化后“设计阵”ΦC=(Φ1,…,Φc)。因此,式(5)可改写为如下矩阵形式
(6)
接下来将给出条件非参数独立筛选具体步骤。
第1步: 变量筛选过程。将XQ中的每个变量都采用式(6)的最小化得到p-c个边际残差平方和,记为Lj,j=c+1,…,p,然后根据Lj从小到大排序,取
Mγ={c+1≤j≤p∶Lj排序前[γn]个},
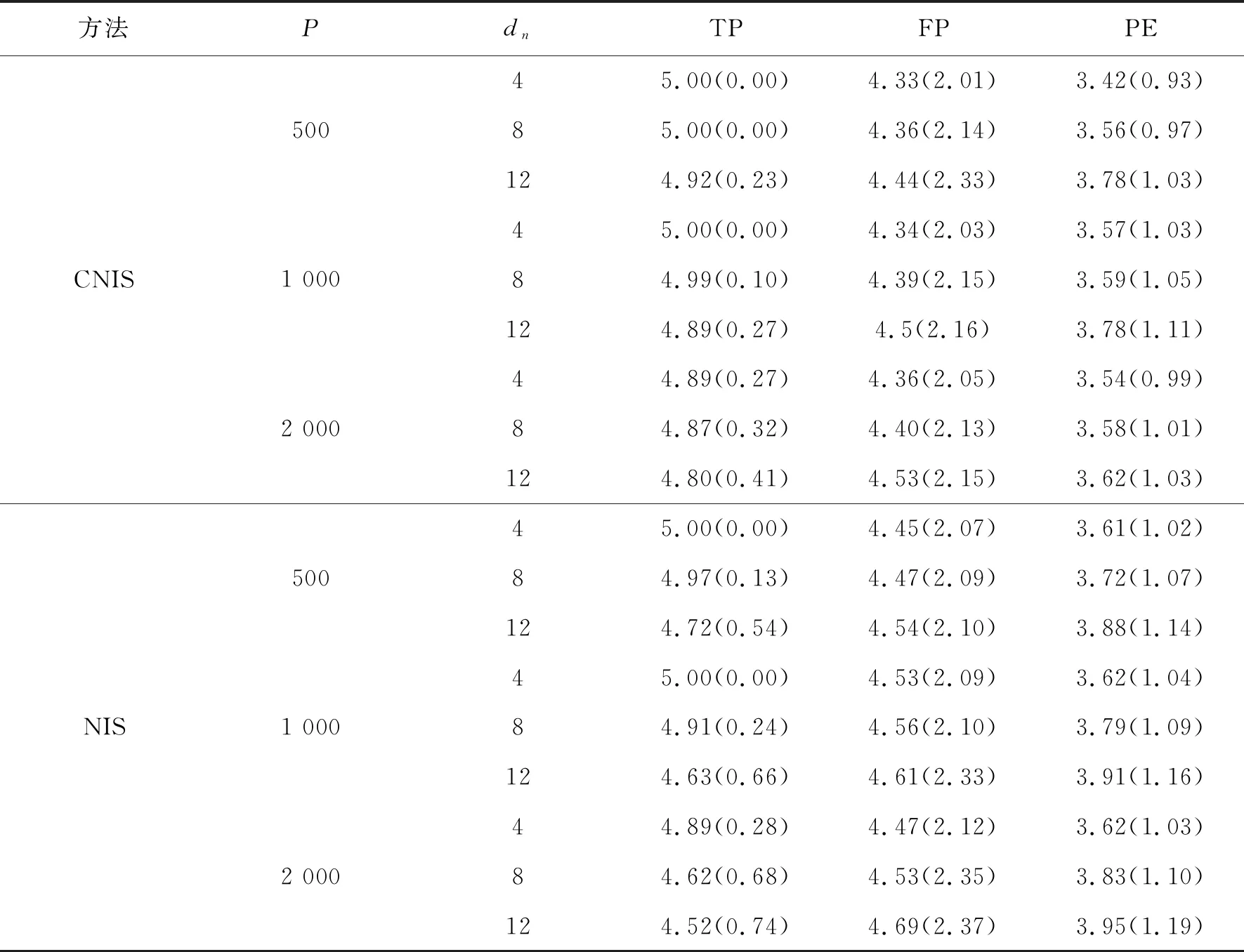
γ为取值(0,1)的常数,Fan等[1]建议取前n/ln(n)个变量,实际情况中满足[γn] 上述方法称为CNIS-aglasso方法。该方法第1步采用CNIS方法将变量降低到一个合适维度,第2步通过Adaptive Group Lasso进行变量选择及模型建立,第2步也可以采取其他组惩罚的估计方法。 2)fj|C表示XC条件下第j个变量的函数形式; 为简便计算,假设所有Xj,j=1,…,p都在区间[a,b]上,并给出如下几个假设条件。 F={f(·)∶|f(r)(s)-f(r)(t)|≤K|s-t|α,s,t∈[a,b]}, 式中:K是大于零的常数;r是非负整数;α∈(0,1],且满足d=r+α≥0.5。 (B)对于常数K1、K2,有Xj的边际密度函数gj在区间[a,b]上满足0 定理1条件(A)、(B)、(D)、(E)满足时以下结论成立: ① 对任意a2>0,存在正常数a3、a4,使得 ②如果条件(C)、(F)也满足,取υn=a5dnn-2k,式中a5≤a1ξ/2,则 本章通过Monte Carlo模拟比较方法有效性,函数如下: f1(x)=x,f2(x)=2x-1,f3(x)=sin(2πx)/(2-sin(2πx)), f4(x)=0.1sin(2πx)+0.2cos(2πx)+0.3sin2(2πx)+0.4cos3(2πx)+0.5sin3(2πx), 设置样本量n=400,协变量维数p=500、1 000、2 000,dn=4、8、12,假定X1、X2为已知重要变量,进行500次模拟并计算,表1给出了CNIS-aglasso与NIS-aglasso方法筛选效果的比较。根据表1结果,基函数个数过多会导致筛选结果变差。等样本与协变量的情况下,基函数为4、8的情形明显比12的筛选效果要好。比较CNIS与NIS筛选结果,同等条件下CNIS方法略优于NIS方法。 表1 CNIS-aglasso与NIS-aglasso变量筛选结果 在证明定理1前,先给出以下5个引理,其证明详见文献[8]。 引理2[8]假定独立随机变量Y1,…,Yn取值区间为[-M,M],且均值为0,则对∀υ≥var(Y1+…+Yn), 有P(|Y1+…+Yn|>x)≤2exp{-x2/(2(υ+Mx/3))}。 引理3[8]假定独立随机变量Y1,…,Yn均值为0,且对∀m≥2(所有i),存在常数M和υi,满足E|Yi|m≤m!Mm-2υi/2,则P(|Y1+…+Yn|>x)≤2exp(-x2/(2(υ+Mx)))对∀υ≥υ1+…+υn成立。 引理4[8]假设条件(A)、(B)、(D)满足,则∀δ>0,存在2个正常数a6、a7,使得 式中:k=1,…,dn;j=1,…,p。 引理5[8]条件(A)、(B)满足时,对∀δ>0, 此外,对任给常数a4,存在正常数c8,使得 下面证明定理1。 定理1的证明由最小二乘性质有 则 (7) 注意到 (8) 由引理4和联合概率有界性质,得 (9) 回顾引理5的结论,对于任意给常数a4,存在正常数a8,使得 (10) 由式(8)~(10)和联合概率有界性质,得 (11) 现在对S2进行控制,注意到 (12) 由条件(D), (13) 由式(8)、(9)、(10)、(13)以及联合概率有界性质,得 (14) 最后对S3进行限制, (15) (16) (17) (18) 由式(10)、(13)、(16)、(17)和联合概率有界性,得 (19) 由式(19)和联合概率有界性,对于正常数a10、a11和a12, (20) 至此,定理1得证。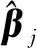
1.3 主要结论

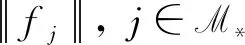


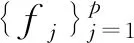
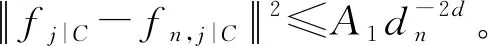



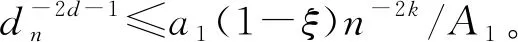
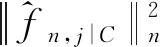
2 数值模拟
3 定理1的证明
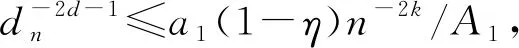




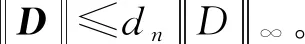
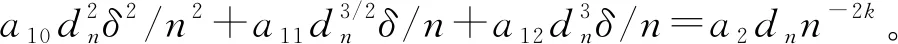
 猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48数学物理学报(2022年4期)2022-08-22 04:08:00安徽师范大学学报(自然科学版)(2022年3期)2022-07-14 03:54:42中学生数理化·高一版(2021年2期)2021-03-19 08:32:06中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34制造技术与机床(2017年7期)2018-01-19 02:30:00软件(2017年6期)2017-09-23 20:56:27计算机测量与控制(2017年6期)2017-07-01 16:24:14北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48数学物理学报(2022年4期)2022-08-22 04:08:00安徽师范大学学报(自然科学版)(2022年3期)2022-07-14 03:54:42中学生数理化·高一版(2021年2期)2021-03-19 08:32:06中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34制造技术与机床(2017年7期)2018-01-19 02:30:00软件(2017年6期)2017-09-23 20:56:27计算机测量与控制(2017年6期)2017-07-01 16:24:14北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
