
合成语音检测方法的研究现状及展望
2022-01-28 08:07魏为民孟繁星
上海电力大学学报 2022年1期
魏为民, 刘 畅, 才 智, 孟繁星
(上海电力大学 计算机科学与技术学院, 上海 200090)
相比传统的身份认证,生物身份认证被认为是一种更加便捷有效的认证方案,这是由于生物的身份信息蕴含于自身且独一无二,因此不存在遗失的风险且不容易更改。声纹认证作为一种生物认证方式被越来越广泛地应用,如门禁、银行等。同时,由于互联网的飞速发展,用户的信息非常容易泄露,导致犯罪分子在获取用户的语音信息后,利用合成技术进行语音诈骗,威胁群众的财产安全。因此,开发针对语音识别系统的恶意欺骗的对策已经越来越重要。
使用合成语音对抗说话人验证系统(Automatic Speaker Verification,ASV)的欺骗问题是由MASUKO T等人在1999年首次发表的[1]。合成语音检测通常需要先提取语音信息特征,包括语音的信号处理等。在对语音信号处理时需要进行基音周期检测,以得到与声音振动频率吻合较好的基音周期变化轨迹曲线,这样才能高效地识别语音[2]。然后,针对语音信息特征建立分类器。融合了合成语音检测算法的说话人验证系统可以有效地抵抗合成语音的攻击。传统的合成语音检测方法包括利用频谱信息[3-4]、相位特征[5-6]、倒谱系数特征与相位信息结合[7-9]、余弦归一化相位和修正的群时延倒谱系数特征[10-11]、动态声学特征[12],而近年来机器学习算法[13-15]的发展使得语音识别得到了跨越性的提升,深度神经网络[16-17]和卷积神经网络[18-19]都被证明在合成语音检测方面有着很好的效果。
本文从基于前端特征的检测方法和基于后端分类器的检测方法两个方面,对常用的合成语音检测方法进行了介绍,并综合研究方法和研究现状对未来的研究方向进行了展望。
1 基于前端特征的检测方法
1.1 频谱特征
语音频谱是语音信号在频域中信号的能量与频率的分布关系。对于语音信号的频谱分析包括频谱、功率谱、倒频谱、频谱包络分析等。各种频谱包含着丰富的内容以及各自的特性,它们之间存在着相互关系,在语音信号处理领域被广泛应用。
频谱信息用于说话人验证,在2000年MASUKO T等人[20]的研究中就已经涉及,其中提出了一种利用音高信息和频谱信息的文本提示说话人验证技术,并测试合成语音能否被系统识别出。实验结果表明,对于合成语音还需要开发相应的技术来进行检测。
由于语音信息中的高维特征优于低维特征,TIAN X H等人[21]检测了高维特征的使用,其中采用了6种高维特征,对每种特征分别提取原始高维特征、对应的低维特征、原始高维特征的低频和高频区域来进行评估。实验结果表明,高维特征对欺骗攻击检测是有用的。
上述研究证明了频谱信息可用于合成语音检测,但是否还具有更健壮的特征来检测此类欺骗攻击仍未可知。
1.2 梅尔倒谱系数特征
在语音识别和说话人识别方面,最常用的语音特征就是梅尔倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC)。该方法是在1980年由DAVIS S B和MERMELSTEIN P提出的,是一种在自动语音和说话人识别中广泛使用的特征。MFCC特征提取包含梅尔频率分析和倒谱分析两个关键步骤。对于人类听觉感知的实验表明,人类听觉的感知只聚焦在某些特定的区域,而不是整个频谱包络,而梅尔频率分析就是基于这一实验结果。梅尔刻度的滤波器组在低频部分的分辨率较高,与人耳的听觉特性相符,此为梅尔刻度的物理意义。梅尔刻度描述了人耳频率的非线性特性,与频率f的关系为
(1)
倒谱分析可用于信号分解,将乘性信号转化为加性信号。首先将输入的时域信号进行离散傅里叶变换得到信号频谱,取其对数后得到信号的对数谱,再进行离散傅里叶逆变换即可得到倒谱。
提取MFCC特征的流程如图1所示。
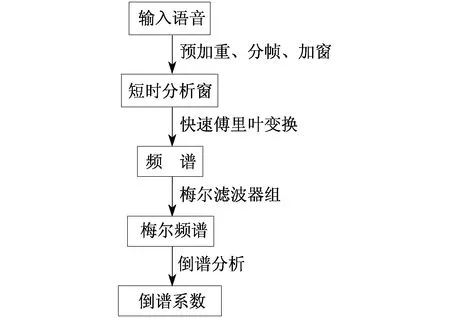
图1 提取MFCC特征的流程示意
一般来说,基于模块的MFCC系统为经典方法,通常被用作基准。在基准系统上,研究人员提出了不同的策略以探究算法的优势。AKAGAWA S等人[22]将传统的基于MFCC的说话人识别方法与相位信息相结合,与传统的MFCC的特征提取方法相比较,可以提高识别准确率。PATEL T B等人[23]提出将人工耳蜗过滤系数和瞬时频率变化与MFCC特征相融合,同样取得了不错的性能。
1.3 修正的群时延倒谱系数特征
群时延是指系统在某频率处的相位(相移)对于频率的变化率,可用来衡量相频谱的非线性程度。其定义为
(2)
式中:XR(k),Xl(k)——傅里叶变换XDFT(k)的实部和虚部;
YR(k),Yl(k)——傅里叶变换YDFT(k)的实部和虚部;
X(k)——连续时间信号中的傅里叶变换。
群时延特性与MFCC功能互补,在语音识别方面应用前景良好。2009年PADMANABHAN R等人[24]证明了基于群时延的特征对语音处理的鲁棒性,即使是在噪声中,群延迟函数仍然保留了共振峰结构,并与传统的MFCC特性做了比较,实验证明基于群时延特性的说话人验证系统的错误率更低。但群时延的数值型可能会遭受很大的变化,具有不确定性。同年,KUA J M K等人[25]用最小二乘正则化来减少群时延特征中的可变性,且将此系统与基于MFCC的基线系统融合,使得系统的相对效率有所提高。WU Z Z等人[26]提出了基于余弦归一化相位和修正群延迟函数相位谱的特征来区分虚假语音和真实语音。2017年,PAL M等人[27]提出了全极群延迟函数与常数Q倒谱系数和基频变化的积分级融合前端特征检测方法,在已知和未知攻击方面均取得了很好的性能。
1.4 常数Q倒谱系数特征
近年来,为了保护自动说话人验证系统免受欺骗干扰,研究人员提出了一种新的合成语音检测方法——基于常数Q变换的欺骗检测。与短时傅立叶变换一样,该方法是重要的时频分析工具,特别适用于音乐信号的分析。基于常数Q变换所产生的频谱最大的特点是其频率轴为对数标度而不是线性标度,且窗口长度会随着频率的改变而改变。基于常数Q变换与传统的倒谱分析相结合,被称为常数Q倒谱系数(Constant Q Cepstrum Coefficient,CQCC)。该方法提供了频谱的一种可变分辨率、时频表示,能够捕捉到更经典的特征提取方法所没有的详细特征,对于欺骗干扰的检测非常有用。
CQCC的特征提取过程如图2所示。
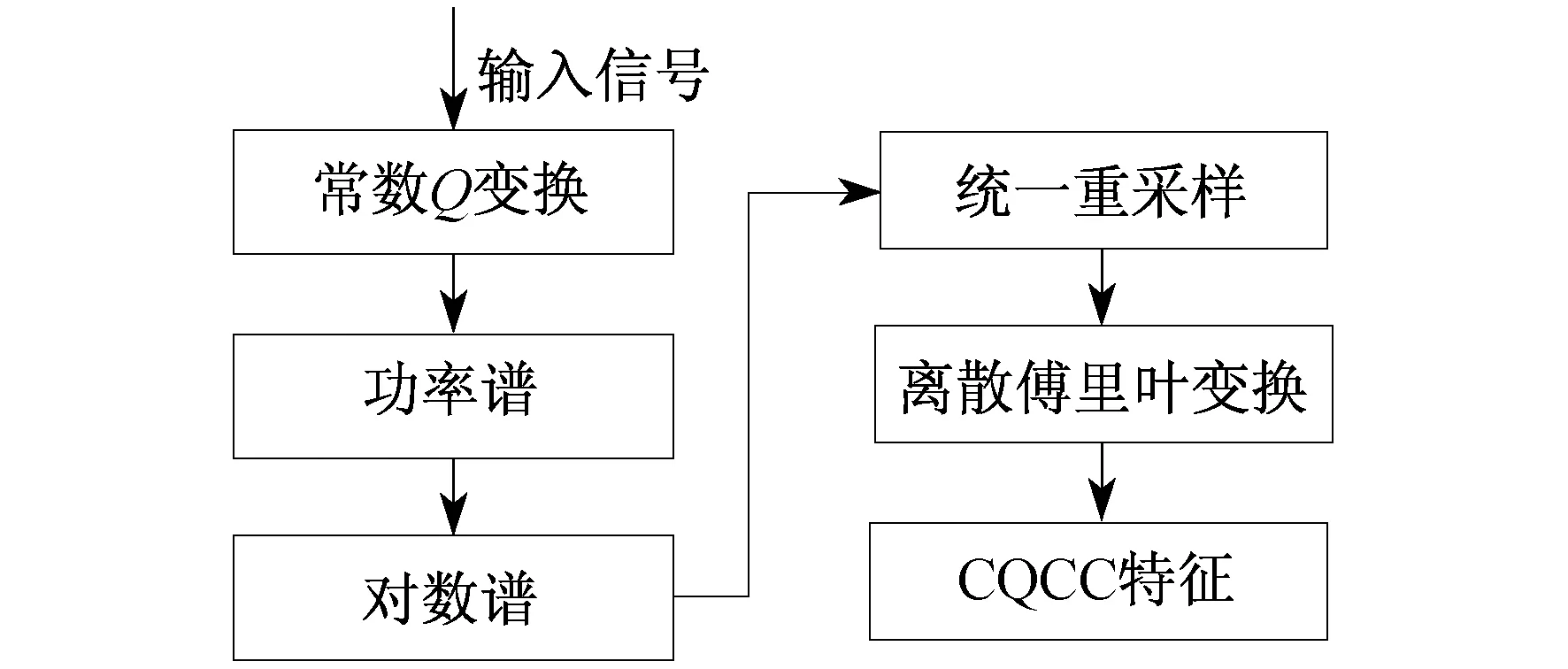
图2 CQCC特征提取过程示意
传统倒谱特征提取使用的是傅里叶变换,而CQCC使用的是常数Q变换(The Constant Q Transfrom,CQT)。CQT是指中心频率按指数规律分布,滤波带宽不同,但中心频率与带宽比为常数Q的滤波器组。CQT在一定程度上对傅里叶变换有弥补作用。其频谱的横轴频率不是线性的,而是以log2为底,可以根据谱线频率的不同改变滤波窗的长度,对于短时平稳的信号可以获得更好的性能。此外,傅里叶变换在低频缺乏频率分辨率,在高频缺乏时间分辨率,CQT对此分别都有很好的补充。
2016年,TODISCO M等人[28]将CQCC与基于高斯混合模型的分类器相结合,在标准数据库上进行评估时,CQCC特征在欺骗检测方面胜过所有现有的方法。基于此结论,2017年,TODISCO M等人[29]进行了进一步的拓展,对3个不同数据库的CQCC推广评估,证明了它们在每个案例中都能提供最先进的性能。
基于CQT,但不局限于CQCC特征,YANG J C等人[30]研究了基于长期CQT特性的高频信息。2019年,YANG J C等人首先利用离散余弦变换对倒倍频功率谱和倒倍线性功率谱分别推导出两个新的特征,即倒倍频常数Q系数和倒倍频常数Q倒倍频系数。在此基础上,利用重叠块变换与离散余弦变换相结合的方法进行了扩展,避免了从全频段提取的特征在某些特定频段容易受到局部噪声的影响。结果表明,基于CQT的新特征在ASVspoof2015、嘈杂的ASVspoof2015及ASVspoof2019逻辑访问语料库上都表现出了最好的性能。
新特征CQCC的优点来自可变的光谱-时间分辨率,与大多数自动说话人验证系统使用的分辨率不同,但同样可靠地捕获了欺骗迹象。
1.5 数据库及评估结果对比
ASVspoof数据库为谷歌发布的合成语音数据库,包括来自45名男性和61名女性的真实和虚假样本。该数据库中的攻击由10种不同的语音合成和语音转换算法生成。训练集和开发集包括5种类型的攻击(S1~S5),评估中有10种类型的攻击(S1~S10)。其中,S1~S5为已知类型,S6~S10为未知类型。一般评估准则使用等错误率(Equal Error Rate,EER)进行评估,即误报率与错报率相等时的阈值。EER的值越小说明系统性能越好。
在同样的数据库和评估准则下,基于MGDC,MFCC,CQCC特征的说话人验证系统的等错误率值如表1所示。
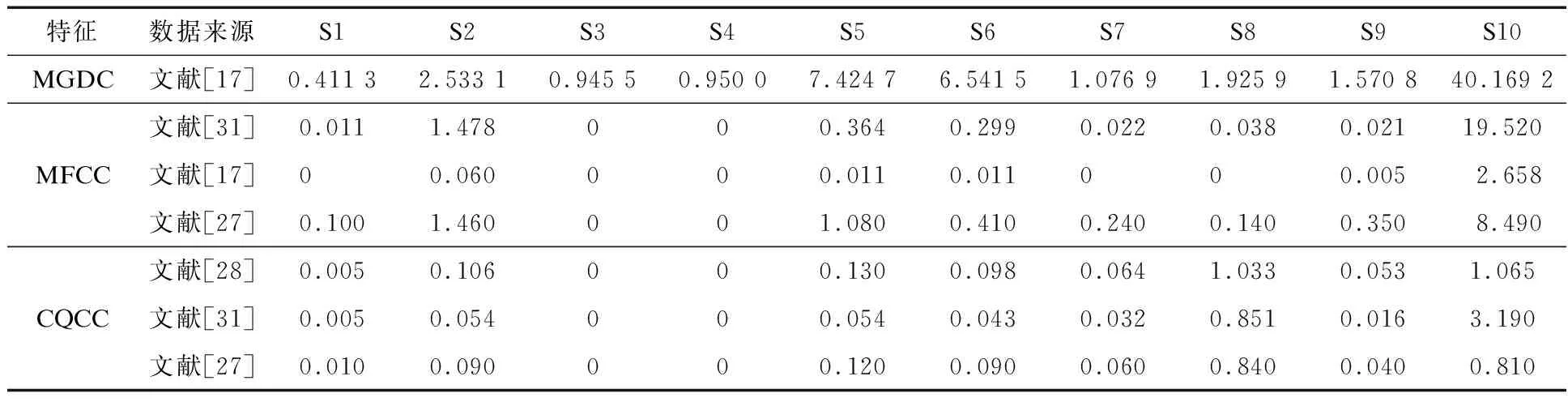
表1 基于3种不同特征的说话人验证系统的等错误率值对比
表1中每行数据基于相同的数据集和评估标准,分别取自不同的文献进行结果对比。由表1可知,基于MGDC特征的检测方法的等错误率值较另外两种高出很多,MFCC作为经典基准系统表现良好,CQCC作为近年来新研究的特征表现相对更好。在以后的研究中,可以基于基准系统进一步研究CQCC的性能。
2 基于后端分类器的检测方法
深度学习是机器学习领域中一个新的研究方向,学习样本数据的内在规律和表示层次。这一过程中获得的信息对文字、图像和声音等数据的解释有很大的帮助。深度学习是一种复杂的机器学习算法,在语音和图像识别方面取得的效果远超过先前的相关技术。 深度学习使机器模仿视听和思考人类的活动,解决了很多复杂的模式识别难题。深度学习在语音识别上的应用将会成为未来的主流趋势。
2.1 深度神经网络
深度神经网络(Deep Neural Net,DNN)可以理解为有很多层隐藏层的神经网络,有时也称为多层感知机。DNN内部的神经网络层可以分为输入层、隐藏层和输出层3类,层与层之间采用全连接的方式。其框架如图3所示。
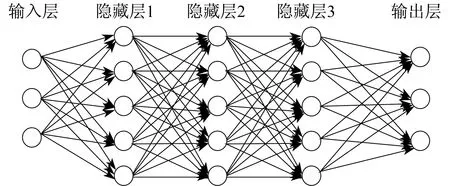
图3 DNN框架示意
2015年,自动说话人验证欺骗干扰挑战赛(ASVspoof2015)中,VILLALBA J等人[32]提出了基于DNN与谱的对数滤波器组和相移特征的分类器输入方法,试验使用了DNN后验来确定测试的真假,以及将DNN的瓶颈特性作为一个单类支持向量机的输入两种方法。实验证明,DNN的表现比支持向量机好,且在光谱特征方面,DNN相对于高斯混合模型基线有显著改善。虽然不同的分类器融合在一起最后取得了可观的效果,但是此方法依赖于声码器,因此仍有后续工作要做。在此基础上,QIAN Y M等人[13]基于神经网络的特征提出了3种模型结构,分别为叠加自编码器、欺骗判别深度神经网络和多任务联合学习深度神经网络。其中欺骗判别神经网络更适用于欺骗检测任务。将基于深度神经网络与基于循环神经网络的深度特性相结合实现了更好的系统性能。经研究,将前端动态声学特性作为特征来训练DNN欺骗检测分类器,也具有不错的性能[14]。
由于DNN特殊的深层结构以及有数千万参数需要学习,导致其训练非常耗时,因此如何加速DNN的训练过程是未来需要研究的方向。
2.2 卷积神经网络
卷积神经网络(Convoluntional Neural Net,CNN)是一种深度学习模型,类似于人工神经网络的多层感知器。该方法包括数据输入层、卷积计算层、ReLU激励层、池化层和全连接层。数据输入层主要对原始输入数据进行预处理;卷积计算层是根据深度、步长、填充值进行卷积计算;ReLU激励层对卷积层输出结果进行非线性映射;池化层夹在连续的卷积层中间,用于压缩数据和参数的量,进行特征降维;全连接层通常在卷积神经网络尾部,整合卷积层和池化层的分类特征并加以区分。
CNN示意图如图4所示。
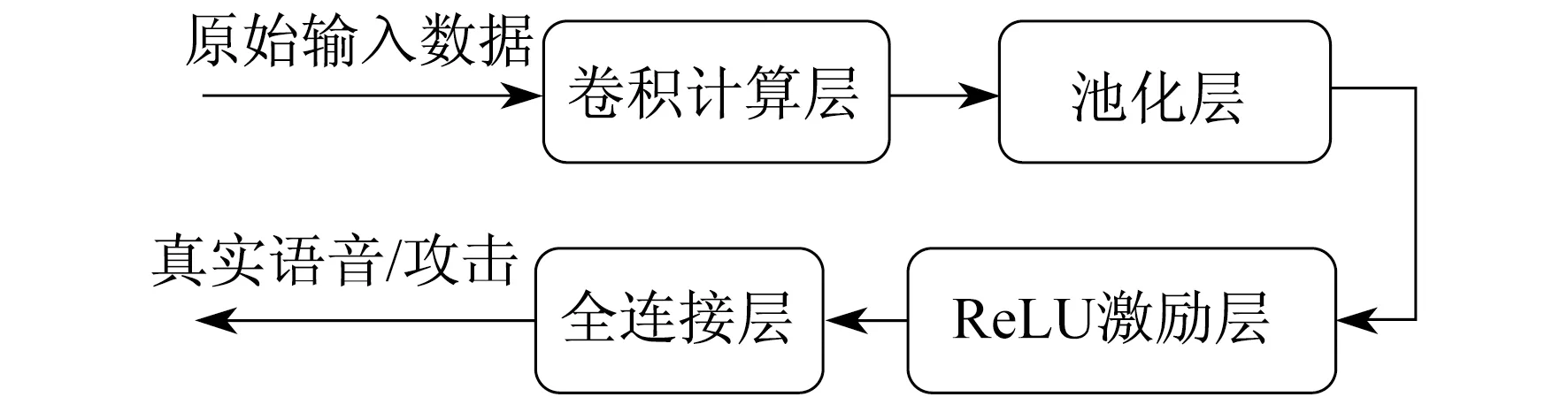
图4 CNN示意
2016年,TIAN X H等人[33]发现,与基于全连接神经网络的分类器相比,基于时态CNN的分类器能够有效地提高基于单位选择的欺骗攻击检测性能。2017年,MUCKENHIRN H等人[31]以端到端的方式学习原始语音信号的相关特征和分类器,该方法可以作为对线性判别分析分类器方法的补充。2018年,KORSHUNOV P等人[34]的研究也表明CNN是比基于传统方法更好的选择,但对于跨数据库场景、何种结构最适合语音欺骗攻击以及如何找到这种结构等问题还需要进一步的研究。2019年,ALZANTOT M等人[35]在CNN的基础上研究了残差卷积网络(ResNet),成为当前应用最为广泛的CNN特征提取网络,对比结果表明模型取得了一定的改进成果。未来的研究方向仍是提高模型对未知攻击的泛化能力。
2.3 结果对比
表2为基于DNN和基于CNN的检测方法的等错误率值对比。

表2 两种方法的说话人验证系统等错误率值对比
由表2可以看出,基于CNN的合成语音检测方法优于基于DNN的方法,但神经网络作为近年来语音识别最热门的方向值得深入研究。比如,CNN分层提取特征,后面叠加长短时记忆网络或深层神经网络,同时结合多种机制,是否可以优化如今的基于神经网络的方法;或者由于对CNN的研究局限在训练集或数据差异较小的任务上,在未来是否可以通过叠加卷积网络的方式来优化性能,或利用与图形处理器结合的方式来优化运算时间等。
4 结 语
本文对合成语音检测方法从前端特征和后端分类器两方面进行了综述,传统手工方法可以在欺骗攻击方面有不错的表现,但深度学习的发展也为语音检测提供了新的方向。随着人们隐私意识的增强,欺骗语音检测面临着更高的要求和更强的挑战。
在接下来的研究工作中,合成语音检测技术的发展方向主要有以下几个方面:现有的合成语音检测方法大多是基于无噪的环境,因此有必要开发在噪声条件下的检测方法;深度学习方面的进展促进了直接输入原始波形的说话人验证系统的设计,即不再局限于某一特定特征,而是提取话语层面的特征,端到端输入原始波形的深度神经网络为合成语音检测提供了全新的可能;神经网络被应用于合成语音算法中,各种新型的合成方法层出不穷,专用方法检测当然是一种选择,但如何进一步增强算法的泛化性能,检测各种方式的攻击,以及检测方法与说话人验证系统的融合也是未来研究的方向。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2021年6期)2021-03-09
计算机系统应用(2021年2期)2021-02-23
电子制作(2019年13期)2020-01-14
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
移动通信(2017年3期)2017-03-13
