
萤火虫优化的异构集成学习网络入侵检测方法*
2022-01-26 08:35:22伍德军韩宝华
火力与指挥控制 2021年12期
伍德军,韩宝华
(1.四川交通职业技术学院,成都 611130;2.空军工程大学空管领航学院,西安 710051)
0 引言
随着大数据时代的到来,网络在人们日常生活中扮演着越来越重要的角色。给人们带来便利的同时其自身也面临着越来越多的安全威胁。入侵检测作为一种有效的主动安全防护方法,能够在网络受到危害之前进行快速响应和拦截,保障网络运行的安全稳定[1]。高精度的入侵检测方法能够有效降低网络攻击带来的危害,这也使得其一直是网络安全领域的研究热点的原因。
入侵检测,本质上可归结为关于网络行为正常/异常的一个二分类问题。目前,在入侵检测领域主要的研究方向是机器学习方法,一些典型的机器学习方法:K-近邻(KNN)、BP 神经网络(BPNN)、支持向量机(SVM)等都在该领域得到成功应用[2-7]。但是对于机器学习,要想获得一个比较理想的检测模型,无法回避的一个问题是模型的参数设置。虽然很多学者在参数选择上做了大量的工作,但是很难找出最优的参数,影响了检测效果,这也成为机器学习方法应用的一个瓶颈。近年来,集成学习算法得到越来越多的关注[8-10]。集成学习算法通过对多个基分类器的集成来提升整体算法的泛化性能。在集成学习中,要获得好的泛化能力,要求各个基分类器判决正确率比随机猜测要高,这个对于泛化能力较好的SVM、KNN、Bayesian 等方法几乎不需要考虑参数问题,就可满足要求,这样就避免了参数选择问题,可以突破目前的瓶颈问题。因此,本文选择集成学习,对入侵检测问题进行研究。
集成学习的过程主要包括两部分:基分类器的构建和多分类器结果的融合方法[11-13]。各个基分类器差异性越大,可以获得的总体性能越强。为了提高各个基分类器之间的差异性,本文采用异质集成和多采样结合的方法。除此之外,对于各个基分类器检测结果的融合方法也是影响检测模型的关键问题。目前最常用且效果比较好的方法是投票法和加权法。相较而言,加权法是对投票方法的一种改进,它依据不同基分类器分类性能的好坏对其决策输出结果进行赋权。但是具体赋的权值为多少,得到的结果是否最优,这又是一个问题。为了解决此问题,本文采用萤火虫优化算法[14]对各个基分类器的决策输出权值进行优化,找出最优的赋权结果,提高检测模型的精度。综上,本文以集成学习方法为核心检测算法,通过对基分类器构造方法和结果融合方法的优化改进,提高检测模型的精度。
1 GSO 的异构集成算法
为了提高集成学习的效果,本文采用异构集成学习方法,集成多种学习机器,并且从训练样本集着手,提高训练样本的差异性。通过这些方法来提高集成学习的泛化性,确保检测精度。
1.1 异质基分类器生成
集成学习是用有限个学习机器对同一个问题进行学习,在某输入示例下的最终输出是由构成集成的各学习机器在该示例下的输出共同决定。给出了集成分类器比个体分类器更加准确的充要条件:个体分类器是准确且多样的。对于目前泛化性较好的机器学习方法,在几乎不考虑参数条件的前提下能够较好地满足准确性要求。这里需要重点考虑的是如何提高基分类器之间的差异性。
根据基分类器自身分类算法的异同,集成学习分为同构和异构集成两种方式。同构集成中所有基分类器均采用同一种学习算法,只是算法选择的参数、样本不同;异构集成则采用不同的分类器,不同的学习算法能够有效保证基分类器之间的差异性,因此,本文采用异构集成,对入侵检测进行研究。
影响基分类器之间差异性除了上述的自身分类算法之外,还有构建基分类器时对数据集的选择。依据数据集选择的方式,可将集成学习分为基于不同重抽样技术的Pattern-Level 集成和基于不同样本特征的Feature-level 集成。Pattern-Level 集成是利用简单重复取样或者改变样本分布的方法,对原始数据集进行再抽样,使每一个基分类器得到不同的训练集,以提高它们之间的差异性。当前,常用的Bagging 和Boosting 方法都是Pattern-Level 集成。Feature-Level 集成主要针对特征较多的场景,选择反映该问题不同性质的特征子集来形成每个基分类器的训练集。网络入侵检测的样本维数往往较高,因此,在这里用Feature-level 的集成是可行的。为了提高基分类器的精度,使用Pattern-Level 和Feature-level 相结合的异质集成构造方式。
1.2 萤火虫算法权值优化
在获取多个基分类器输出的基础上,需要融合这些输出结果得到最终的检测结果。由于入侵检测是一个二分类问题,将各个基分类器的输出结果设为+1 和-1,分别表示正常和检测到入侵。假设有n个基分类器,第i 个基分类器的检测结果为yi,融合的权重为xi,则最终的检测结果y 为:

需要求出最优的x,以保证模型的检测精度最高,那么优化目标函数:

其中,acc 表示在不同权重xi下整个集成模型的测试检测精度。为了解决这一问题,选择萤火虫优化算法(GSO)对其进行求解。GSO 是一种典型的群体智能优化算法,它最初是由Krishnanand 在2005 年提出[15],其基本思想是模拟萤火虫群体活动中,亮度低的个体会向亮度高的个体靠拢,从而实现优化。相较于其他的一些群体智能算法,它具有算法简单,参数少且容易实现等优点,适合于决策层权值的确定。

1.3 算法流程
根据前面的分析,以及入侵检测问题的实际情况,本文采用异构集成,选择当前比较成熟的、泛化性能比较好的机器学习方法:SVM、KNN、Bayesian网络以及BP 神经网络(BPNN),作为基分类器的学习方法。同时,为了进一步提高基分类器之间的差异性,结合Pattern-Level 和Feature-Level 选择训练集方法,提出一种GSO 优化权值的集成学习检测算法。具体算法流程如图1 所示。

图1 算法流程
具体步骤为:
步骤1:依据Bagging 方法,对样本进行有放回的重采样,确定多个样本子集;
步骤2:采用Feature-level 方法,分别对前面获得的样本子集进行特征随机选择,获得特征子集;
步骤3:采用不同的学习方法对步骤2 获得的子集进行学习,其中,各个基分类器的参数采用简单的试凑方法,进而获得各个基分类器;
步骤4:对各个基分类器的结果进行加权综合。权值采用1.2 节中的萤火虫算法进行寻优获得,最终的检测结果通过符号函数输出。
2 算法验证
为了验证本文算法的有效性,首先将从算法的有效性入手,通过将算法应用于目前通用的数据集[15],考察算法的分类性能。这里分别选择German、Ionosphere、Image 以及Thyoid 这4 个数据集作为实验数据集。考察本文所提的算法与传统的分类方法之间以及Bagging、Boosting 集成算法之间的性能比较。文献[10]提出对于集成学习而言,集成的基分类器不宜太多也不宜太少,参考文献[10]选择40 个基分类器,分别基于本文方法、bagging 和boosting 构造基分类器。本文中在第1 层对样本采样,对每个样本分别进行5 次重采样,在此基础上,对各个子集进行两次随机的特征选择,特征选择比例为80 豫。这样就得到了10 个训练集。基于这10个训练集,分别对其采用SVM、KNN、Bayesian 网络以及BP 神经网络进行训练,得到40 个基分类器。采用多数投票法得到最终的分类结果。
首先比较单分类器和本文方法的分类效果。单分类器分别采用本文中的基分类器方法,即SVM、KNN、Bayesian 网络以及BP 神经网络。SVM 和BP神经网络均选择高斯函数作为核函数和激活函数,各个学习器的参数均通过5 折交叉验证和网格搜索方法确定。本文算法中各个基分类器的参数通过简单设定,未作专门处理。由于所选的学习机的学习能力都较强,因此,一般选择的参数均符合要求。在GSO 优化算法中,依据问题,设置萤火虫数目为50 个,荧光素挥发因子ρ=0.4,荧光素更新率γ=0.6,更新率β=0.08,邻域阈值=5,代次数为100 代。得到的实验结果如图2 所示。

图2 不同数据集的GSO 寻优结果
从图中可以看出,在初始时各个数据集的分类精度相较而言都比较高,这说明集成学习算法能够达到比较好的学习结果,而且整个算法是稳定的。在不同数据集上,算法都快速收敛,说明GSO 算法的收敛性是比较好,各个算法最终都稳定在一个比较高的分类精度上。接下来将本文结果与其他几种单分类方法进行比较,表1 给出了分类结果。

表1 通用数据集实验精度比较
从实验结果可以看出,在这些算法中KNN 的分类精度基本上是最低的,相较其他学习方法,KNN 算法简单,运行效率最高,但是它所能提取的分类信息也是最少的。SVM、Bayesian 以及BPNN 获得接近的分类效果,这3 种方法采用不同的学习机制从不同的角度对样本进行学习,它们均能较好地处理非线性分类问题。本文提出的方法能够获得最优的分类精度,这是由于通过对各个分类器的集成可以将一些个体分类器的错、漏判由其他个体分类器所弥补,这种集成学习方式使整体分类的泛化能力进一步提升。这也是集成学习的优势。
接下来再分析本文方法与传统的集成学习算法之间的性能。传统的集成算法选择经典的Bagging、Boosting 集成算法,集成的基分类器个数也为40 个。基分类器之间的差异度能够反映集成学习的效果。文献[17]给出差异度的定义。
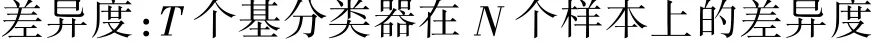

从表2 可以看出,总体上Bagging 和Boosting 集成的方法差异度不是特别大,相较而言本文方法的平均差异度明显高于前面两种方法。这是由于本文方法采用的是异构集成。下面从比较几种集成算法的分类精度考察它们的泛化性能,这里重点考察本文的GSO 优化和仅采用投票方式融合决策结果,表3 给出了这4 种方法的分类精度。

表2 基分类器平均差异度比较

表3 集成算法分类精度结果
从实验结果可以看出,几种集成算法相较单种学习方法在分类精度上都有了一定的提升。在本文构建基分类器的条件下,投票融合的分类精度相较传统的Bagging 和Boosting 更高,这也是由于基分类器差异增大后整个集成效果得到提高,相较简单的投票方法,通过GSO 优化的方法能够获得最高的分类精度,说明本文的方法确实能够进一步提高集成学习的性能,为其在入侵检测中的应用打下基础。
3 算法在入侵检测中的应用
上面的实验验证了本文所提的GSO 优化集成学习算法,在处理二分类问题上是可以得到较好的精度的。本节将算法应用于入侵检测中,入侵检测数据集选择CSE-CIC-IDS2018。该数据集由加拿大通信安全机构(Communications Security Establishment,简称CSE)和加拿大网络安全研究所(Canadian Institute for Cybersecurity,简称CIC)联合发布。该数据集是基于50 台攻击主机,对一个企业内5 个部门的420 台计算机和30 台服务器进行攻击的网络流量和系统日志,总共包括7 种攻击类型:Bruteforce,Heartbleed,Botnet,DoS,DDoS,Web 和Infiltration。相较传统的KDD99 数据集[17],CSE-CIC-IDS 2018 能够更好地模拟企业的网络环境,它包含了较多网络协议和新的攻击方式。原始的数据集非常庞大,其中,正常样本和入侵样本比例大约为4∶1,在本实验中,按4∶1 的比例选择训练样本。从训练集中随机选择正常样本4 000 条,入侵样本1 000 条(包括所有的选择7 种攻击类型)。测试样本为1 000 条正常样本,攻击样本250 条。分别采用基于单个机器学习方法(这里选择SVM),集成学习算法bagging、boosting,以及本文方法进行检测实验,其中,bagging 和boosting 算法集成的基分类器均为SVM,比较几种算法的误检率、漏报率和整体的检测精度这3 个指标。表4 为检测结果。
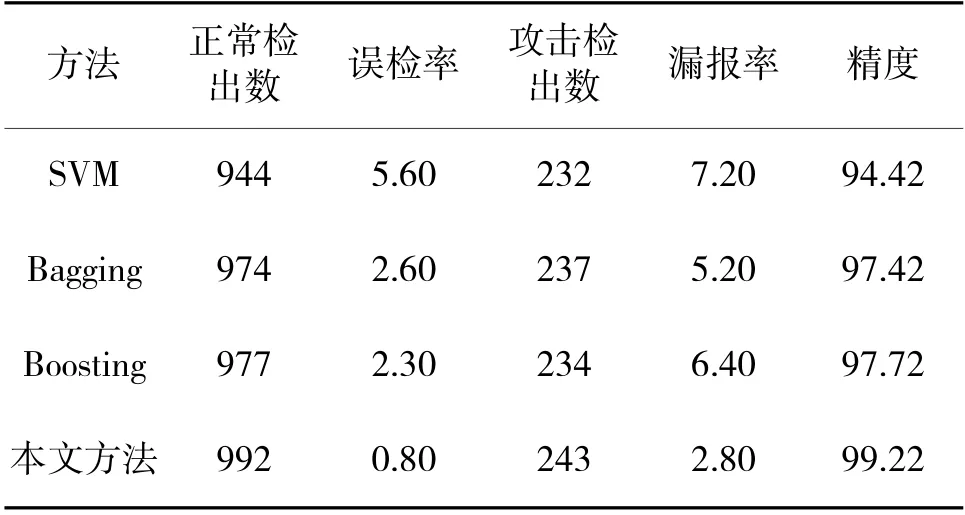
表4 入侵检测实验结果
从表4 得到的检测结果可以看出,仅用SVM 算法进行入侵检测的误报率和漏报率相较后面的集成算法均比较高。从这个结果也可以看出集成学习的优势。而在3 种集成算法中,本文提出的算法能够获得最好的检测效果,这也和我们在UCI 数据集上得到的实验结果是一致的,通过对基分类器差异性的增大,提高了算法的泛化性能。具体统计对不同攻击方法的检测情况,我们可以发现,提出的算法对Botnet、DoS、DDoS 以及Web 等攻击类型的检测率基本达到了100 豫,主要的错误判断集中在Brute-force 和Infiltration 两种攻击类型上。对这两种攻击的数据进行分析,发现异常样本中存在着部分正常流量数据,在特征上与异常流量具有相同的数值。比较几种方法在这两个易错分数据集上的表现,本文提出的方法能够大大提升检测算法对这两类攻击的检测精度。
接下来从接受者操作特性曲线(Receiver Operation Characteristic Curve,ROC)[18]来分析检测算法的性能。通过ROC 曲线判断模型好坏时,主要从曲线形态和AUC(Area Under Curve)两个方面考察。如果曲线形态上越靠近左上角,模型的检测效果越好;相反,则说明该模型的检测效果越差。AUC 指的是ROC 曲线下方的面积,其大小可以反映检测模型的诊断价值,AUC 值越接近1,说明模型的性能越好。图3 给出了几种算法的ROC 曲线:

图3 几种入侵检测算法ROC 曲线
从图3 中可以看出,整体上前面采用的几种算法的ROC 曲线形态上均比较偏向左上角,说明都是比较好的检测器。其中,本文提出的算法偏向最好,明显优于其他几种检测方法。从AUC 方面,本文方法的线下面积更大,达到了0.992,高于其他3种方法。综上,从ROC 曲线可以看出本文提出方法的优势。
在现实中,对于网络的攻击往往不是持续性的,可能在某一些时段攻击事件比较多,有些时段攻击事件比较少。对应到数据集中,表现为正常样本和攻击样本的比例。这也对训练数据集采集过程提出一些挑战。理论上,数据集越大,得到的模型检测效果越好,但是也可能在检测的初期,采集到的攻击事件数目比较少,在这种情况下,检测模型的效果如何?这里,考察不同的攻击强度(攻击样本数与正常样本数的比值)下,各种检测模型的检测效果分别以5 豫,10 豫,15 豫和20 豫模拟不同攻击强度下的样本,以这4 种攻击样本训练得到检测模型,其在不同学习模式下的检测精度如图4 所示。
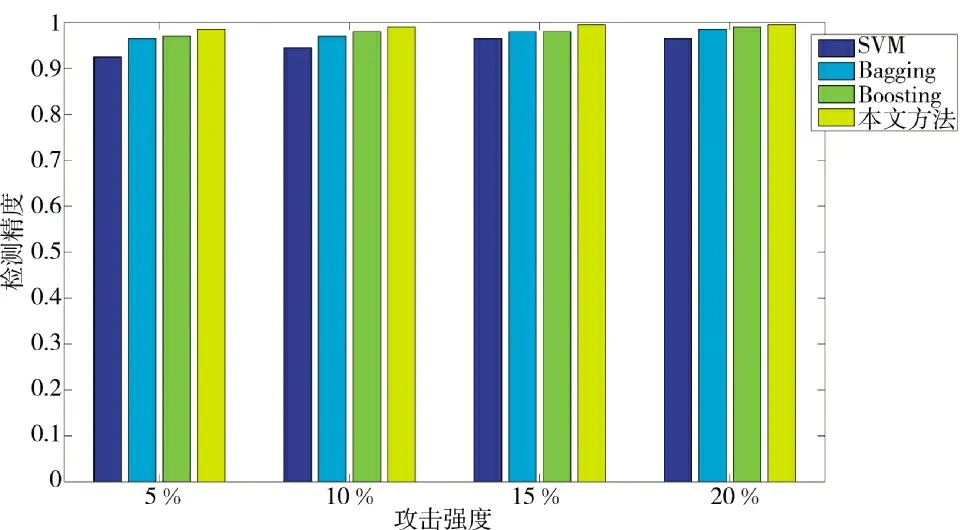
图4 不同攻击强度下的检测精度
从图4 可以看出,在不同的攻击强度下,经过训练得到的检测模型均能较好地检测出入侵事件。在攻击强度较少,即训练样本中,攻击样本条数比较少的情况下(攻击强度5 豫),SVM 的检测精度为91.5 豫,并且其漏检率比较高,这主要是因为样本的不均衡,使得SVM 的分类面偏移造成。从实验结果也可以看出,样本的不均衡会影响机器学习效果。相较其他几种算法,本文方法在检测精度上能够一直维持在一个比较高的水平(最低为96.6 豫),说明本文算法是稳定的,在样本不均衡的情况下同样能够得到比较好的检测效果。
4 结论
网络入侵检测问题是一个典型的二分类问题,单个学习机器整体的检测精度不高,为此采用了异构集成学习的方法。通过对基分类器中训练集和训练方法两个方面的差异增大,提高整体集成的效果。同时,为了进一步提高检测的精度,对集成学习的结果融合部分进行了改进。通过GSO 算法优化找出最佳的基分类器权值,通过加权得到最终的检测结果。实验结果说明本文提出的方法是稳定、准确的。因此,本方法在网络入侵检测的实际应用中具有一定的实用价值。在面对训练样本不均情况时,依然有可以改进的地方,这也是后期我们的研究侧重点。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
电子制作(2018年11期)2018-08-04 03:25:38
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2018年1期)2018-04-18 11:52:35
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
