
检测小篡改区域的U型网络
2022-01-26 13:10刘丽颖王金鑫曹少丽赵丽张笑钦
中国图象图形学报 2022年1期
刘丽颖,王金鑫,曹少丽,赵丽,张笑钦
温州大学, 温州 325035
0 引 言
数字图像由于其传播快和存储成本低的特点,被广泛应用到人们的学习和生活中。然而,随着Photoshop等图像编辑软件的不断发展,用户可以轻易地对图像进行修改,并且这些修改痕迹难以察觉,导致无法判断图像的真实性。更重要的是,图像经常被用来作为判断事件真相的依据。如果图像篡改技术被不法之人利用,会引发严重的社会问题。常用的图像篡改技术主要是复制移动(copy-move)和拼接(splicing),图像的复制移动指的是将真实图像的某一部分复制粘贴到原图像上;图像拼接是指真实图像的某一部分复制粘贴到另一幅图像上。并且,为了掩盖图像篡改的痕迹,使图像看起来更为真实,通常会在篡改之后再对图像进行压缩和高斯模糊等处理降低图像的清晰度。
为了区分真实图像和篡改之后的图像,诞生了图像取证这个领域,图像篡改区域检测与定位是图像取证领域的一个具有挑战性的任务。目前,对图像篡改区域的检测与定位技术主要分为两种:1)基于特征提取的传统篡改检测与定位;2)基于卷积神经网络的篡改检测与定位。
传统方法将注意力主要集中在图像本身的统计信息和物理特征上。对于进行过复制移动篡改操作的图像,篡改区域的特征会和其他某个区域的特征高度相似。基于这个特性,可以应用基于图像块特征匹配的方法来检测复制移动区域,主要方法有:穷举搜索(Fridrich等,2003)、主成分分析法(Popescu和Farid,2004)、像素匹配法(Luo等,2006)、离散小波变换和奇异值分解(Li等,2007)、相位相关法(Wang和Farid,2007)。由于基于块特征匹配的方法计算缓慢,Amerini等人(2013)以及Ardizzone等人(2015)提出了基于特征点的篡改检测方法来提高计算效率与检测效果。对于进行拼接篡改操作的图像,由于其篡改区域是来自于另一幅图像,所以篡改区域与其他区域之间会存在特征差异,这种差异性体现在各个方面。据此学者们分别从不同方面来进行拼接篡改操作的检测。例如:光照不一致性(Johnson和Farid,2007;Liu等,2011;李叶舟 等,2011)、噪声估计(Chen等,2008;Pan等,2011;卢燕飞 等,2012)和设备属性(Gou等,2007)。由于很多伪造者为了使得图像看起来更为真实,会利用中值滤波等操作模糊拼接区域边界来掩盖篡改痕迹,Bahrami等人(2015)通过提取中值滤波的特征来检测篡改区域。传统方法促进了图像取证领域的发展,但是其缺点也很明显,一个方法只能针对一种篡改技术进行检测,在不清楚篡改方式的情况下,检测效果较差。
卷积神经网络在计算机视觉任务上取得了巨大的成功(Zhang等,2021a,b),其能自适应提取特征的特点使得学者将其应用到图像篡改检测上来。Rao和Ni(2016)首次将卷积神经网络用于数字图像的篡改检测,但是该方法只能用于判断图像是否经过篡改,不能定位篡改区域。Zhang等人(2016)提出了基于图像块的篡改检测方法,其只能大致定位图像的篡改区域。
不同类型的相机所拍摄图像的噪声是不一致的。所以为了提高模型的定位精确度,Bondi等人(2017)通过卷积神经网络提取噪声不一致特征来检测图像的篡改区域。Cozzolino等人(2017)和Zhou等人(2018)选择利用空间丰富模型(spatial rich model, SRM)(Fridrich和Kodovsky,2012)增强噪声特征。上述方法在一定程度上提升了检测效果,但它们也存在明显的缺点。对于复制移动篡改方式产生的图像,其篡改区域的噪声特征和其他区域的噪声特征相似,这会导致只增强噪声特征的方法效果有限。为了应对这样的情况,RRU-Net(the ringed residual U-Net)(Bi等,2019)利用残差回馈机制自动选择要增强的特征,其对于不同的篡改方式都有较好的检测效果。但该方法在提取特征时,网络的每一层都需计算两遍,需要花费较多的时间。除上述的问题外,大多数图像篡改检测方法的注意力主要集中在如何利用网络更好地提取篡改特征,而忽略篡改区域太小产生的样本不平衡问题,影响了检测效果的进一步提升。网络模型经过训练之后可以判断各个像素点是否经过篡改,是一个像素水平的二分类问题。若将篡改区域的像素点当作正样本,将其他区域的像素点当作负样本,很明显,对于篡改区域小的图像,样本比例是不平衡的。
本文根据上述问题提出了一个基于区域损失的小篡改区域检测U型网络。具体贡献如下:
1)提出异常区域特征增强机制,将与图像背景差异较大的区域定为异常区域,并对其进行特征增强。
2)提出区域损失,增强模型对篡改区域框内像素的判别能力,解决篡改区域过小产生的样本不平衡问题,进一步提升模型性能。
3)本文方法在CASIA2.0(CASI-A image tampering detection evaluation database)(Dong等,2013)、NIST2016(NIST nimble 2016 datasets)(Guan等,2016)、COVERAG(a novel database forcopy-move forgery detection)(Wen等,2016)和COLUMBIA(Columbia uncompressed image splicing detection evaluation dataset)(Hsu和Chang,2006)这4个图像篡改标准数据集上取得了更优的性能。
1 本文方法
本文提出了一个基于区域损失的小篡改区域检测U型网络,首先构建了一个异常区域特征增强机制,将与图像背景差异较大的区域定为异常区域,对其进行特征增强,然后利用U型网络进行特征的提取与融合。为了解决篡改区域过小的问题,本文提出了区域损失,利用候选区域生成机制找到图像的篡改区域框,计算篡改区域框内图像的损失来增强模型对篡改区域框内像素的判别能力。
1.1 异常区域特征增强
对于大多数的篡改图像,篡改区域通常与图像背景之间存在差异,可将与图像背景相差较大的区域定为异常区域。借鉴ManTra-Net(manipulation tracing network)(Wu等人,2019)中使用的局部异常检测网络。首先对输入图像进行计算,然后将得到的差值张量与升维后的图像进行拼接,增强输入图像异常区域的特征。利用这种方法,只需在图像输入时计算一次,比RRU-Net中使用的残差回馈机制能节省更多的训练时间。本文用像素点的值表示这个像素的局部特征,像素点周围区域内的平均值表示该像素点的显著特征。
显著特征由区域内像素的平均值计算为
(1)
式中,μ表示像素的平均值,F[i,j] 表示位置为(i,j)的像素值,Hr和Wr分别表示区域的高和宽。
计算局部特征与显著特征之间的差值张量D,即
D[i,j]=F[i,j]-μ
(2)
标准差σ计算为
(3)
差值标准化计算为
(4)
为了更加准确地找出异常区域,本文使用了不同的区域范围计算显著特征。首先是以整幅图像作为一个区域,将所有像素的平均值作为显著特征,然后还分别利用了11×11、7×7和3×3的平均池化来找这3个区域的的显著特征,差值张量计算的具体过程如图1所示。
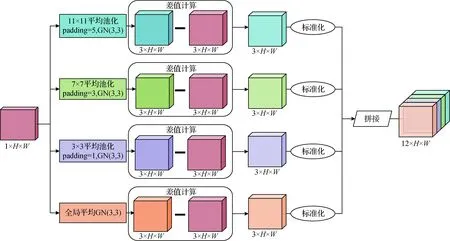
图1 差值张量计算图Fig.1 Differential tensor calculation
ManTra-Net将该方法应用于局部异常特征检测,将与显著特征差异较大的局部特征定为异常区域,然后对其进行异常检测分析。但是,ManTra-Net存在两个问题:1)局部异常特征检测之前的篡改特征提取网络会造成图像空间信息的丢失;2)其局部异常检测网络无法从潜在异常特征中准确判别真正的异常特征。本文方法直接对输入图像进行局部异常检测之后与图像进行拼接,可在保留完整的图像空间信息的同时对潜在的异常区域进行特征增强,增强网络对这些区域的学习,得到更加精确的检测结果。
1.2 网络结构
本文的网络结构借鉴了U-Net(Ronneberger等人,2015)的网络结构。U-Net由下采样的压缩路径和上采样的扩展路径组成,关键点在于对称的U形结构可以在扩展路径进行上采样时融合压缩路径中的特征,避免上采样过程中图像空间信息的丢失。本文的网络同样由下采样网络和上采样网络组成,下采样网络提取图像特征,上采样网络恢复图像空间信息,如图2的网络结构所示。图中k为卷积核大小,s为步长,p为输入特征图四周补零的情况,d为空洞卷几率,o_p为输出特征图四周补零的情况。

图2 网络结构图Fig.2 Network structure
在ManTra-Net的研究中,对比了几种主流的骨干网络,发现VGG(Visual Geometry Group) 网络更适用于篡改区域特征的提取,所以本文下采样网络选择VGG-16。本文的任务是找出图像的篡改区域,将其分割出来,需要在图像进行下采样的时候保留图像中物体的位置信息,故对下采样的VGG-16做了如下改动:1)去掉最后的3个FC(fully connected)层;2)删掉VGG-16的最大池化层;3)每个下采样块最后一个卷积层的步长设置为2。
最大池化层会改变图像中物体的位置信息,如图3所示,图3(a)是下采样时保留最大池化层之后得到的候选区域框生成的图像,很明显图像下采样之后物体的位置信息发生了变化,得到的篡改区域中心位置并不是真正的篡改区域中心位置;图3(b)是去掉了最大池化层之后得到的候选区域框生成图,可以看出,图像中物体的位置信息被保留了下来。
下采样网络中有5个下采样块,分辨率缩小为原图像的1/32,故上采样网络中同样需要5个上采样块。每一个上采样块都是由1个反卷积层加1个卷积层组成。反卷积层将特征图的分辨率扩大两倍,卷积层进行特征提取。上采样路径中传递的特征信息需要与对称的下采样路径传递的特征信息相融合,以避免上采样过程中信息的缺失。最后再用一个1×1的卷积层进行降维,将其通道数变为1,得到检测结果图。

图3 候选区域框生成图Fig.3 Generating of candidate region boxes ((a)with the maxpool layer;(b)without the maxpool layer)
1.3 区域损失
本文方法的关键点在于利用区域损失来解决样本比例不平衡的问题。首先应用候选区域框生成机制生成候选区域框,接着从中选出篡改区域框,生成过程如图4所示。然后计算该篡改区域框内图像的BCELoss(binary cross entropy loss),将其作为第2阶段训练的辅助损失。其能解决样本比例不平衡的原因在于将篡改区域框内的BCELoss作为辅助损失,相当于增强了篡改区域框内部图像特征的学习,一定程度上平衡了样本比例。
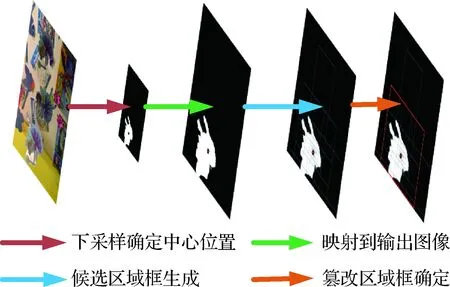
图4 篡改区域框的生成图Fig.4 Process of forgery region box selection
1.3.1 篡改区域中心点的确定

找出特征图的中心点之后,将其中心点位置映射到输出图像中,即
(5)
式中,(αic,βic)表示图像中心点的位置,(αfc,βfc)表示下采样之后特征图的中心位置,n表示下采样之后分辨率缩小的倍数,本文中设置n为32,具体过程如图2的右下部分所示。
1.3.2 候选区域框的生成
候选区域框的生成首先要确定基础框的大小,然后求出候选区域框的高和宽,即
(6)
式中,h和w分别表示候选区域框的高和宽,ξ是基础框的大小,κ表示基础框扩张的尺度,γ表示宽和高的比例,ξ、κ和γ都是根据需求来自行设定。
然后求出候选区域框的左上角和右下角位置,即
(7)
式中,(αl,βl)和(αr,βr)分别表示候选区域框左上角和右下角的位置,Himg和Wimg分别表示图像的高和宽。
1.3.3 篡改区域框的确定
区域损失机制需要从候选区域框中找到样本比例最为平衡的候选区域框作为篡改区域框。所以被选取的候选区域框要满足两个条件:1)候选区域框要包含所有的篡改区域;2)候选区域框内篡改区域与非篡改区域的样本比例接近于1 ∶1。如图3所示,红色框就是被确定的篡改区域框。然后计算其区域内图像的BCELoss作为第2阶段的辅助损失,解决样本不平衡的问题。
1.3.4 损失函数
在网络的训练中,所使用的损失函数都是BCELoss。BCELoss是由交叉熵变形得到的,更适用于二分类的问题,数学表达形式为
(8)
式中,ti表示第i个像素点的目标值,oi表示第i个像素点的预测值,H和W分别表示高和宽。
本文训练第1阶段的损失函数是整幅图像BCELoss,第2阶段训练的损失函数Ls计算为
Ls=(1-ε)×Limg+ε×Lbox
(9)
式中,Limg表示整幅图像的BCELoss,Lbox表示选定的篡改区域框内的BCELoss,ε设置为0.05。
2 实验结果与比较分析
2.1 实验设计
2.1.1 参数设计
实验中,第1个阶段训练的epoch为400,第2个阶段训练的epoch为200。学习率应用了CyclicLR的衰减策略:周期的上升部分中,训练迭代的次数设置为8;第1阶段训练的初始学习率设置为0.001,学习率上限设置为0.05;第2阶段的训练的初始学习率设置为0.000 1,学习率上限设置为0.001。本文实验均在Tesla V-100 GPU设备上进行,python版本为3.6,pytorch版本1.4.0。
第2阶段求中心位置时,基础框宽和高的比例设置了3个值分别为0.25、1和4,基础框的扩张尺度有6个值分别为2、4、8、16、32和64,故每幅图像可生成18个候选区域框。然后根据不同的数据集中图像的大小设置不同的基础框的大小。在CASIA2.0和COVERAGE数据集上训练时,基础框的大小设置为8;在NIST2016和COLUMBIA数据集上训练时,基础框的大小设置为16。确保得到的候选区域框中存在能包含整幅图像的候选区域框。
2.1.2 评估指标
本文主要利用平衡F分数(F1 score)作为评价指标,计算为
(10)
式中,TP表示预测为正,实际是正的样本数量,FP表示预测为正,但实际是负的样本数量,FN表示预测为负,但实际是正的样本数量。p表示精确率,r表示召回率,F1表示F1 score。
2.2 数据集
2.2.1 数据集介绍
在CASIA2.0、NIST2016、COVERAG和COLUMBIA这4个数据集上训练测试了本文方法,并与其他方法进行比较。
CASIA2.0数据集提供了复制移动和拼接两种篡改方式的图像。该数据集里面图像的篡改区域小而复杂,这让其更具挑战性。NIST2016数据集包含了复制移动、拼接和移除3种篡改操作所得到的篡改图像,该数据的篡改区域较小。COLUMBIA和COVERAGE数据集也提供了复制移动和拼接两种篡改方式的图像,但是两者的图像数量都比较少,COLUMBIA数据集上的图像篡改区域大而简单。以上4个数据集都提供了篡改图像的真实标注。
2.2.2 数据增强
分别从各个数据集选取了不同数量的图像进行训练和测试。首先设置每个数据集中80%的图像为训练集,20%为测试集,并调整了图像的大小。为了提高本文方法在高斯模糊和JPEG压缩这两种后处理方法上的鲁棒性,每个数据集都额外复制了一份进行JPEG压缩和高斯模糊等处理,其每幅图像有50%的概率进行压缩,压缩质量因子在0到100之间随机选择;有50%的概率进行高斯模糊处理,在1、3、5、7和9这几个数字中随机抽取作为高斯核大小。然后,还对COLUMBIA和COVERAGE这两个较小的数据集的图像进行旋转和镜像翻转操作进一步扩充数据集。旋转角度分别为10°、45°、90°、135°和180°,翻转操作包含上下翻转和左右翻转,这样CASIA2.0和NIST2016数据集大小变为原来的2倍,COLUMBIA和COVERAGE数据集大小变为原来的16倍。具体情况如表1所示,AUG表示数据增强之后的数据集效果。

表1 数据集图像处理表Table 1 Image processing tables for datasets
2.3 实验结果与比较
2.3.1 与其他方法的比较
为了检测本文方法的性能,选取了一种基于传统的特征提取的检测方法DWT(discrete wavelet transformation)(Mahdian和Saic,2009)和3种基于卷积神经网络的检测方法RRU-Net、U-Net和ManTra-Net与本文方法进行比较。
检测结果如表2所示,分析表2的数据,可知本文方法在4个数据集上测试的F1值均高于其他方法,说明本文方法的性能优于其他方法。其中,在CASIA2.0数据集上的F1值比排名第2的U-Net高了2.17%。原因在于CASIA2.0数据集中图像的篡改区域小而复杂,样本比例失衡严重。其他基于卷积神经网络的篡改检测方法忽略了该问题,导致其在CASIA2.0数据集上表现较差,同时说明了本文区域损失机制的有效性。
为了更加清楚地看到模型的检测效果,本文从CASIA2.0数据集中选取了多幅图像进行效果检测并对测得的图像篡改区域进行了放大处理。从图5可以看出DWT完全检测不出篡改区域,ManTra-Net的检测效果较差。原因在于DWT只针对单一的篡改方式进行设计,难以在包含多种篡改方式的数据集上达到较好的效果。ManTra-Net的异常检测网络的深度不够,无法从潜在异常特征中准确判别真正的异常特征。U-Net和RRU-Net的检测效果较好,但有些较细微的地方检测效果不是很好。本文方法的检测效果最佳,异常区域特征增强机制和区域损失机制使其能精确地分割出篡改区域。

表2 5种算法在不同数据集上的F1值结果Table 2 F1 score of five algorithms on different datasets

图5 CASIA2.0检测结果Fig.5 Detection results on CASIA2.0((a)test images;(b)DWT;(c)ManTra-Net;(d)U-Net;(e)RRU-Net;(f)ours;(g)ground truth)
2.3.2 鲁棒性检测
在对图像进行篡改之后,为了掩盖篡改痕迹,通常会用JPEG压缩和高斯模糊等操作降低图像的清晰度。为了对模型进行鲁棒性测试,分别从 CASIA2.0和NIST2016数据集中随机抽取了20%的图像,然后对抽取出来的图像进行JPEG压缩和高斯模糊处理;为了验证本文方法的优越性,选取了U-Net和RRU-Net这两个性能较好的模型与本文方法进行比较。
分别用20、40、60、80和100这5种不同的质量因子对图像进行JPEG压缩处理。质量因子越小图像越模糊。分别用1、3、5、7、9这5种不同尺寸的高斯核对图像进行高斯模糊处理,高斯核尺寸越大图像越模糊。
鲁棒性测试结果如图6所示。对于JPEG压缩处理,3个模型的F1值都随着质量因子的降低而有不同程度的下降。在CASIA2.0上,RRU-Net的稳定性差。在NIST2016数据集上,U-Net的效果较差。对于高斯模糊处理,3个模型的F1值随着高斯核的增大而减少。同样,在CASIA2.0上,RRU-Net的检测效果不佳。在NIST2016数据集上,U-Net的结果较差。在应对JPEG压缩和高斯模糊这两种攻击时,本文模型的F1值一直维持在一个较高的水平,在两个数据集上的平均F1值最高,鲁棒性最佳。

图6 鲁棒性测试图Fig.6 Robustness test((a)F1 value of jpeg compression on the CASIA2.0;(b)F1 value of jpeg compression on the NIST2016; (c)F1 average value of jpeg compression on the CASIA2.0 and NIST2016; (d)F1 value of gaussian blur on the CASIA2.0; (e)F1 value of gaussian blur on the NIST2016;(f)F1 value of gaussian compression on the CASIA2.0 and NIST2016)
2.3.3 消融实验
本文方法较其他方法的优势在于对图像的异常区域进行特征增强并且提出区域损失解决篡改区域较小的问题。为了验证这两个机制的有效性,本文通过设置消融实验对比不同模型的F1值,定量验证结果如表3所示。
分析表3中的数据可以看出,具有异常区域特征增强机制的方法在4个数据集上的F1值均有提升。对于篡改区域过小的问题,使用区域损失的模型在4个数据集上的F1值均有提升;此外,在篡改区域占比最小的CASIA2.0数据集上F1值提升最多,这进一步说明了区域损失能够较好地解决篡改区域过小产生的样本不平衡问题,且篡改区域占比越少,性能提升越明显。

表3 消融实验结果Table 3 F1 score of ablation study
3 结 论
本文提出了基于区域损失的U型篡改区域检测网络。该方法主要解决现有的基于卷积神经网络的方法在特征增强和篡改区域过小上的问题。本文方法利用局部特征与显著特征的差值张量与升维后的图像拼接作为网络的输入,来增强图像异常区域的特征;同时利用区域损失机制增强对篡改区域框内特征的学习,一定程度上缓解了正负样本比例不平衡的问题。由实验结果可以看出,本文方法的网络性能明显高于其他方法;对JPEG压缩和高斯模糊这两种常见的掩盖篡改痕迹的方法,展现出了更强的鲁棒性;本文方法中的图像异常区域特征增强机制和区域损失机制能有效提高模型的性能。
本文利用区域损失来解决篡改区域过小的问题。这个方法有效的原因有两个:1)在第1阶段训练之后得到的模型精确度较高,能够在第2阶段训练时定位到篡改区域;2)图像的篡改区域都是集中的,可以找到正负样本比例较为平衡的篡改区域框。目前出现的图像篡改数据集中的图像数量较少,缺少像ImageNet那样图像数量庞大的数据集,这导致大多数模型的泛化能力都不强。需要大的图像篡改数据集构建泛化能力更强的网络模型。本文只选取一个篡改区域框对于篡改区域小而分散的图像篡改数据集的提升效果有限。未来工作中,将继续研究如何构建泛化能力更强的网络模型和解决篡改区域分散的问题。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机应用与软件(2022年5期)2022-07-07
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
新课程学习·中(2013年3期)2013-06-14
