
面向GAN生成图像的被动取证及反取证技术综述
2022-01-26 13:09何沛松李伟创张婧媛王宏霞蒋兴浩
中国图象图形学报 2022年1期
何沛松,李伟创,张婧媛,王宏霞*,蒋兴浩
1. 四川大学网络空间安全学院, 成都 610065; 2. 上海交通大学网络空间安全学院, 上海 200240
0 引 言

然而,深度网络图像生成技术快速发展,给数字图像取证带来了全新的挑战。其中,生成对抗网络(generative adversarial network,GAN)所带来的影响最具代表性。Goodfellow等人(2014)首次提出GAN的概念。GAN主要由一个生成器(generator)和一个判别器(discriminator)构成,两者通过对抗训练的方式优化网络参数,最终达到判别器无法区分生成器的输出数据和真实数据的状态。GAN由于对复杂高维数据(例如:数字图像)分布具有强大的学习和表达能力,吸引了大量学者和技术人员的关注(王坤峰 等,2017;Creswell 等,2018;Cui等,2019;Gui等,2020),已经在多媒体领域的诸多应用中均取得了突破性进展,例如:1)内容编辑,利用GAN能够显著提升传统图像处理和计算机视觉应用的各项性能,如:图像超分辨率(Ledig等,2017)和图像风格迁移(刘哲良 等,2019);2)内容生成,利用GAN不仅能够在样本稀缺场景下进行数据扩充,增强样本多样性,进而提升模型的迁移能力(dos Santos Tanaka等,2019;Nabati等,2020),还可用于根据文字生成图像等模态转换问题(Reed等,2016)。GAN的提出及相关研究成果无疑为多媒体领域的发展带来了巨大推动力。
GAN在内容编辑与内容生成方面的强大性能也引起多媒体安全领域专家学者的关注。其中,最具代表性和影响力的事件为Karras等人(2018)在知名国际会议ICLR (International Conference on Learning Representations) 2018上提出的新型GAN结构和网络训练方式,名为PGGAN(progressive growing GAN)。PGGAN首次成功地从噪声向量生成分辨率高达1 024×1 024像素并且具有逼真画质的数字图像。该技术解决了早期GAN算法生成图像分辨率低且存在明显异常痕迹的缺点。GAN图像生成技术对数字图像完整性与真实性的潜在威胁也日渐凸显。不法分子可以利用该技术十分便利地制作虚假新闻或伪造电子证据。例如:近几年,DeepFake等深度伪造视频技术大量用于制作领导人演讲视频和名人色情视频(Agarwal 等,2019),严重损害社会稳定和公共安全,造成极大的负面影响。该软件的核心算法便是基于深度神经网络(例如GAN)的图像生成技术。深度网络图像生成技术提供了一种基于数据驱动的智能篡改方式,危害性更强。
从图像语义层面来看,GAN技术已在图像编辑与图像内容生成两方面都获得成功应用,并表现出优于传统方法的视觉效果,如图1所示。图1展示了多种GAN生成的伪造人脸图像和多个真实人脸图像数据集采集的样本(包括:Flickr-Faces-High Quality(FFHQ)数据集和CelebFaces Attributes-High Quality(CelebA-HQ)数据集)。然而,从图像信号层面来看,基于GAN的图像编辑或图像内容生成过程与传统方法存在显著差异。近年来,研究人员通过分析GAN中生成器特殊结构所留下的异常痕迹,已提出多种取证算法,并且针对简单场景下的GAN生成图像取得了良好检测性能。此外,GAN技术已经成功应用于实现数字图像的反取证。研究者利用GAN强大的图像内容生成能力隐藏图像采集或处理过程的痕迹,例如:JPEG压缩痕迹(Luo等,2018)等。

图1 GAN生成图像和真实图像Fig.1 GAN-generated images and real images((a)GAN-generated images;(b)real images)
GAN生成图像被动取证与反取证技术作为多媒体安全领域的新兴问题正受到国内外研究人员的广泛关注。上述问题的研究意义在于:1)面对基于人工智能的新一代图像生成和编辑技术,为保护数字图像内容的完整性与真实性提供新的理论技术,并对数字图像的形成过程进行溯源分析;2)可以从对抗生成角度,研究基于GAN的反取证技术对现有取证算法安全性和可靠性所构成的威胁。
GAN生成图像被动取证与反取证技术已取得一定的研究成果。经调研发现,国内外仍缺乏针对该领域的综述性文章。现有综述论文虽然对该领域内容略有提及(Verdoliva,2020;Tolosana等,2020),但存在诸多局限:1)所涉及的参考文献发表时间较早,内容不够全面;2)缺乏对相关取证技术和反取证技术的合理分类与系统性总结;3)没有探讨本领域方法在实际应用场景中所面临的挑战。针对上述问题,本文整理了面向GAN生成图像的被动取证与反取证技术的最新研究成果,形成系统性综述。为了描述简洁,将GAN生成图像简称为GAN图像,两者具有相同含义。从GAN生成图像的原理及异常痕迹、GAN生成图像的被动取证技术、基于GAN的反取证技术以及GAN生成图像被动取证技术面临的挑战等几个方面进行阐述,为本领域相关研究者进一步优化提升技术性能提供参考。
1 GAN生成图像的原理及异常痕迹
首先介绍GAN模型的基本原理和几种代表性结构,然后与自然图像采集过程进行对比,阐述GAN图像生成过程所产生的异常痕迹。
1.1 经典GAN结构的简要介绍
在信号处理和统计学领域,如何构建真实世界中数据的显式或隐式特征表达,并在特征空间中进行概率密度估计是一大难题,特别是以数字图像为代表的高维数据。2014年,Goodfellow等人(2014)首次提出GAN的基本网络结构与训练方法,为了叙述简便,将上述GAN结构简称为标准GAN。GAN模型主要包括生成器和判别器两部分,两者以对抗形式进行训练,最终实现对高维数据分布的隐式估计,如图2所示。具体地,生成器试图拟合真实图像的概率分布,使得判别器最终无法区分真实图像和生成图像。GAN模型通过计算生成图像和真实图像分布的相似性对生成器和判别器的参数进行优化更新。根据GAN模型对图像的生成方式,将GAN模型主要分为两类,即非条件GAN(unconditional GAN)和条件GAN (conditional GAN)。上述两类GAN模型,分别用于图像生成和图像编辑两方面的任务。将从GAN模型的网络结构和训练策略等角度出发,介绍几种具有代表性的GAN模型,如图3所示。
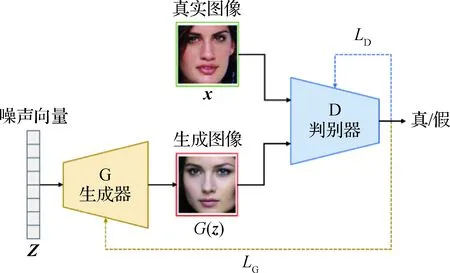
图2 非条件GAN模型Fig.2 The diagram of the unconditional GAN
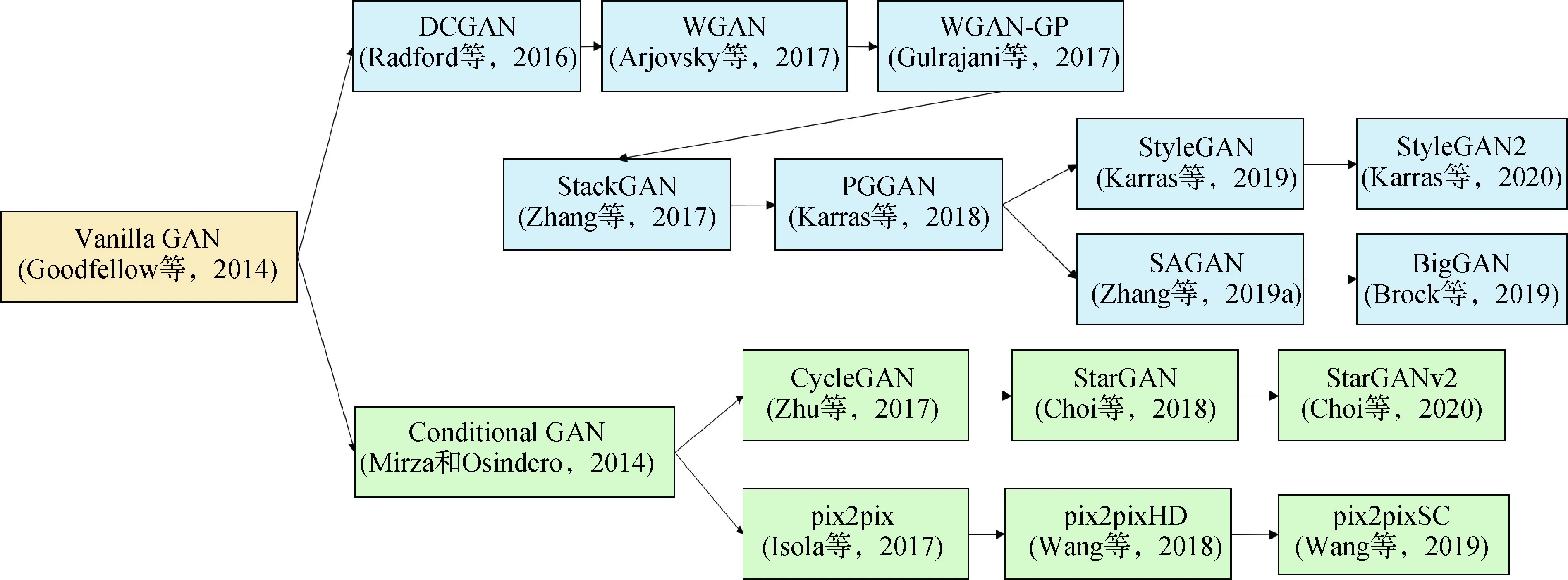
图3 代表性GAN模型发展过程图(主要分为:非条件GAN和条件GAN)Fig.3 A road map of representative GANs (roughly divided into unconditional GAN and conditional GAN)
1.1.1 非条件GAN模型
标准GAN的提出吸引了大量研究人员关注基于GAN的图像生成技术。GAN通过对噪声向量采取逐层上采样操作实现图像生成过程。近年来,研究人员分别从网络结构、损失函数和训练策略对GAN模型进行优化,显著提升了GAN模型的训练稳定性、收敛速度以及生成图像质量。
1) DCGAN:卷积结构与GAN的首次结合。标准GAN的生成器和判别器均采用全连接网络结构,这样的框架设计使得模型难以处理数字图像相关问题。Radford等人(2016)成功地将卷积结构与GAN结合,提出了一种新的GAN模型DCGAN(deep convolutional GAN)。卷积结构的引入对于解决数字图像相关问题带来巨大贡献。DCGAN相比于早期GAN进行了许多重要改进,例如:(1)生成器和判别器分别采用反卷积操作和卷积操作代替所有池化操作;(2)对较深的网络层,不再使用全连接结构;(3)使用批处理归一化(batch normalization,BN)和Leaky ReLU激活函数加速模型的收敛。实验结果表明,DCGAN能够从图像数据中学习到层次化的特征表达,将其应用于图像分类任务能够取得良好的性能。此外,DCGAN引入的全局均值池化层和BN层一定程度上缓解了早期GAN训练不稳定的问题。
2) WGAN:Wasserstein损失函数改善训练稳定性。对于标准GAN,当判别器参数达到阶段性最优时,生成器的损失函数可用真实数据与生成数据的JS散度(Jensen-Shannon divergence)表示。生成器通过最小化JS散度逐步达到拟合真实图像分布的目的。然而,当两个分布没有重叠部分时,JS散度将变为常数,从而导致生成器梯度消失引起模型崩塌。由于图像数据具有高维分布,容易出现分布不重合的情况。针对上述局限性,Arjovsky等人(2017)提出了Wasserstein GAN(WGAN),WGAN利用Wasserstein距离构成判别器的损失函数,替代早期GAN使用的KL散度(Kullback-Leibler divergence)和JS散度。Wasserstein距离提供了一种可靠的训练进程指标,能够反映生成样本的质量是否提高。此外,Gulrajani等人(2017)采用梯度惩罚(gradient penalty)技术对WGAN中Wasserstein距离的实现方法进行改进,缓解了梯度消失和梯度爆炸问题。
3) PGGAN:逐步扩增的训练方法实现高分辨率图像生成。由于高分辨率图像容易引起判别器训练过程的梯度问题,早期GAN模型仍难以生成高分辨率图像。对此,英伟达研究人员Karras等人(2018)提出了PGGAN,首次生成了1 024×1 024像素高分辨率图像。PGGAN首先利用分辨率为4×4像素的图像训练生成器和判别器,再使用平滑层方法逐步添加网络层并提高图像分辨率,最终生成1 024×1 024像素分辨率的图像。这种逐步扩增的训练方法使得生成器的低分辨率层首先能学习图像的轮廓信息。当低分辨率层达到收敛时,引入新的网络层级,进一步细化图像中的细节信息。在生成器的设计中,PGGAN不再使用反卷积操作完成上采样,而改用最邻近滤波结合卷积操作的方式避免引起棋盘效应(checkboard artifact)(Odena等,2016)。
4) StyleGAN:引入风格控制提升逼真度。在PGGAN的基础上,Karras等人(2019)提出了基于风格的GAN模型(即StyleGAN),改进了信息输入生成器的方式。为了实现对生成图像语义特征的控制,Karras等人(2019)设计了一种用于风格控制的自适应归一化方法(adaptive instance normalization,AdaIn),通过学习仿射变换使生成器参数考虑风格信息。然而,近期研究发现AdaIn操作会对不同特征图的均值与方差进行独立的归一化,可能破坏特征之间的相关信息,从而导致StyleGAN生成图像存在水珠状痕迹。针对上述问题,StyleGAN2(Karras等,2020)在StyleGAN的基础上进行改进,通过简化训练流程、优化AdaIn方法以及模型结构,进一步提升了StyleGAN生成图像的质量。
5) 其他进展。为了提升对图像信息的长距离依赖表征能力,Zhang等人(2019a)提出了一种基于自注意力机制的GAN模型(self-attention generative adversarial network,SAGAN),将自注意力模块引入GAN模型。自注意力机制能够更好地捕捉全局信息,并且保持良好的运算效率。Brock等人(2019)在SAGAN的基础上引入正交正则化的思想,提出了一种新的GAN模型,即BigGAN。BigGAN增加了批大小和网络宽度(即特征图通道数量),显著提升生成图像的真实性评价指标。综上所述,研究人员从模型结构与训练策略两方面不断对GAN模型进行优化,其生成图像的逼真程度与分辨率越来越高。
1.1.2 条件GAN模型
非条件GAN模型经过不断发展已经能够生成逼真的高分辨率图像,但生成图像内容具有较大随机性,难以控制其语义类别。Mirza和Osindero(2014)通过改变GAN模型的输入,提出了一种能控制生成样本语义类别的方法cGAN(conditional generative adversarial network)。cGAN的核心操作是将类别信息输入生成器和判别器中。具体地,cGAN将噪声向量与类别标签(例如:目标图像的属性类别)进行拼接作为生成器的输入,而将生成图像与语义标签共同输入判别器。尽管cGAN仅对标准GAN进行了简单修改,但其对生成内容的控制能力具有良好的应用价值。
1) pix2pix:引入重构误差提升风格迁移性能。由于cGAN具备在内容生成过程中考虑类别信息的特点,研究人员很自然地将其用于图像风格迁移任务。然而,当生成图像内容具有明显形态变化时,只要生成图像仍具有相似的语义信息,cGAN模型的判别器就会判定为真实图像。针对上述问题,Isola等人(2017)提出pix2pix模型,将语义类别信息从输入标签向量改变为输入另一种风格的图像样本。同时,在损失函数设计上,pix2pix选择结合L1损失和cGAN损失,以达到同时提高生成图像清晰度并保留原始图像语义信息的目的。在pix2pix的基础上,研究人员进行了模型和训练策略的改进,分别提出了其他更先进的框架,如Wang等人(2018)和Wang等人(2019)等。
2) CycleGAN:循环一致性实现非配对数据的风格迁移。虽然pix2pix在风格迁移领域已取得良好效果,其训练过程要求使用配对数据(paired data),例如:同一场景下的昼夜图像。然而,在实际应用中,风格迁移任务往往难以获得大量的配对数据。同年,Zhu等人(2017)所设计的CycleGAN实现利用非配对(unpaired)数据进行风格迁移。Zhu等人(2017)提出循环一致性(cycle consistency)的约束条件,通过计算输入图像进行风格迁移后再次还原的重构误差,指导CycleGAN模型进行训练。
3) StarGAN:高效的多风格迁移策略。CycleGAN成功实现了使用非配对数据进行图像风格迁移。然而,CycleGAN只能解决单风格迁移,无法进行多风格迁移。Choi等人(2018)提出StarGAN来解决多风格图像相互转换的问题,在生成器的输入中不仅附加了标签信息,还通过提出掩码向量(mask vector)使得模型可以对多个数据集进行训练。Choi等人(2020)对StarGAN进行优化改进,提出StarGAN2。StarGAN2通过映射网络和风格编码器等组件进一步提高生成图像多样性和模型的可拓展性,同时提升了生成图像的视觉质量。
总体来说,基于GAN的图像生成技术和图像编辑技术近年来正在高速发展,早期GAN模型生成图像的视觉质量缺陷得到不断改善,并且视觉质量仍具有较大优化空间。学术界和工业界因其突出的图像生成能力给予广泛关注和研究,已成功应用于计算机视觉等相关领域。
1.2 GAN生成图像的异常痕迹
1.2.1 自然图像采集与GAN图像生成过程的区别
在介绍GAN生成图像被动取证技术之前,简要分析自然图像采集与GAN图像生成过程在信号处理层面的差异。由于DCGAN是GAN与卷积操作的首次结合,也为后续GAN模型发展提供了基本思路,因此选取DCGAN为例进行说明。图4和图5分别展示了自然图像采集过程和DCGAN图像生成过程。
在一般相机设备的采集过程中,颜色滤波阵列(color filter array,CFA)是获取图像颜色分量的重要操作之一(Gunturk等,2002)。CFA是图像传感器上的一层薄膜。当光信号进入时,CFA会选择性允许光信号的某种分量通过然后到达图像传感器。换言之,图像传感器对每个像素的输出仅包含一种颜色分量(红、绿或蓝)。因此,每个像素的其他两种颜色分量是由图像传感器的输出经过插值得到的(该过程也称为去马赛克过程,即demosaicing process)。以基于核的插值方法为例,每个颜色通道的去马赛克过程可表示为

图4 自然图像采集过程的示意图Fig.4 The acquisition process of natural images
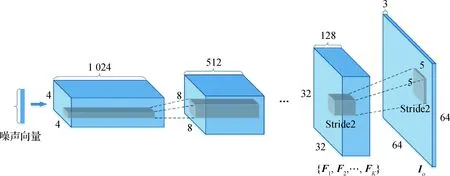
图5 DCGAN图像生成过程的示意图Fig.5 The generation process of images by DCGAN
(1)

另一方面,对于GAN图像,以DCGAN为例,说明其在生成过程中经历的主要操作。GAN模型的生成器通过将输入噪声向量进行上采样逐层扩大分辨率。不同的GAN模型可能使用不同的上采样方式,例如:DCGAN采用反卷积操作(也称为转置卷积操作)完成上采样,而PGGAN则先进行最邻近插值然后使用卷积操作。在大多数GAN模型中,最终生成图像的3个颜色分量将在生成器最后一层(第L层)进行处理,其过程可以描述为前一层(第L-1层)多个特征图的加权组合,即
Io=f(F1,F2,…,FK)
(2)
式中,f(·)表示生成网络最后一层的处理函数,K表示输入第L层的特征图总数。接着将针对两类图像在颜色与纹理方面的差异进行分析,说明GAN图像具有的异常痕迹。
1.2.2 GAN图像异常痕迹的特点
观察式(1)和式(2)可知,自然图像和GAN图像经历了截然不同的生成过程,存在诸多差异:

2) 生成器上采样操作导致的特殊纹理。研究人员不断对GAN模型网络结构进行优化改进,例如:SAGAN引入了自注意力机制模块等,GAN模型的生成器主要通过转置卷积和最邻近插值法等方式实现上采样过程(Zhang等,2019b)。上述操作均会在生成图像中产生特殊纹理。此类特殊纹理具有以下特点:
(1)邻近像素相关度高。当使用转置卷积层进行上采样时,生成结果往往由多个像素点加权得到。而使用最近邻插值法进行上采样时,生成像素的取值直接受到邻近像素值的影响。
(2)上采样操作难以建模图像全局信息。使用转置卷积时,由于内存限制,卷积核的大小相对较小。另外,在使用最邻近插值法时,生成器所采用的滤波核尺寸也相对较小。因此,生成图像中会存在全局语义异常。例如:在生成的人脸图像中存在左右不对称的情况,如图6(a)第1行所示。已有研究人员根据GAN模型训练和框架设计上的缺陷,对GAN生成图像进行鉴别。
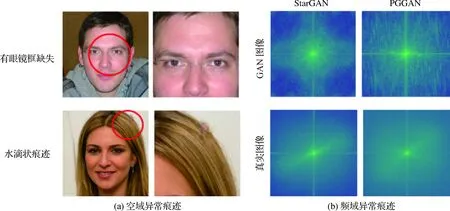
图6 GAN生成图像的异常痕迹Fig.6 Abnormal artifacts of GAN-generated images((a) artifacts in the spatial domain; (b) artifacts in the frequency domain)
(3)图像生成过程未考虑频域信息的分布。由于判别器在对生成图像进行判别时,通常只依据空间域信息,这使得生成器在拟合真实图像分布时只关注图像的空间域信息,无法还原真实图像频率域信息的分布,如图6(b)所示。
3)训练数据集和训练策略存在的局限。GAN模型通过生成器与判别器的对抗博弈过程,实现对高分辨率图像的生成。由于训练数据集、模型网络结构和训练策略等方面的限制,现有方法仍存在以下局限性:
(1)训练数据的概率分布无法完整描述真实图像的概率分布,存在偏差。
以GAN生成人脸图像为例,现有算法主要采用CelebA, CelebA-HQ和 FFHQ等数据集。其中,CelebA-HQ数据集是Karras等人(2018)在CelebA数据集的基础上进行去JPEG痕迹以及超分辨率操作得到的高质量图像。由于收集方法的限制,数据集往往存在内容上的偏向性。例如:CelebA数据集主要包含名人图像;FFHQ数据集从Flickr网站爬取,相比基于名人图像的数据集CelebA-HQ包含了更多的图像内容。然而,网站图像本身存在的内容偏向性仍难以避免。
不仅如此,在创建数据集的过程中,研究人员往往对训练集数据进行了统一处理,例如:人脸居中对齐等操作(Karras等,2018,2019)。上述操作虽然使GAN能够更容易捕捉真实图像的概率分布特征,同时也导致生成图像具有相似的人脸五官位置。
此外,已有研究表明现实世界中的数据往往具有长尾效应(long-tailed effect)(Liu等,2019)。然而在数据收集过程中,数量占比少的样本难以被考虑。因此,目前GAN图像的数据集与真实图像的实际概率分布差异较大。
(2) 判别器的隐式评估方法存在不足。现有GAN模型大多采用基于卷积神经网络(convolutional neural network, CNN)结构的判别器,存在感知野受限、对全局信息的表征能力不足等问题。例如:当生成图像具有全局信息缺损或异常时,判别器无法进行有效判断。此外,早期GAN模型的判别器没有引入残差捷径(residual shortcut)(He等,2016)等先进的网络模块。直到StyleGAN2才将残差捷径引入判别器,但仍存在判别能力不足的问题。因此,现有GAN模型对真实图像概率分布的隐式评估能力仍有较大提升空间。
综上所述,虽然GAN技术在图像生成与图像编辑等任务中显著提升了输出图像的视觉质量,但由于其生成过程与自然图像采集过程存在显著差异,从信号处理角度分析,两者在颜色和纹理信息上具有不同的统计特性,可将其作为GAN图像被动取证的重要线索。当然,式(1)和式(2)仅反映了两类图像生成过程的部分操作,在实际应用场景中,待测图像还可能经历多种后处理操作,例如:社交网络平台的转码与增强等操作。此外,GAN图像还可能由未知GAN模型生成,情况更加复杂。
1.3 GAN生成图像数据集
在研究面向GAN图像的被动取证技术过程中,研究人员主要考虑几种典型GAN模型进行分析,具体细节如表1所示。上述GAN模型大多开源了相关代码,并提供训练模型使用的真实图像数据集,例如:Large-scale Scene Understanding(LSUN)数据集,CelebFaces Attributes Database数据集(CelebA),Radboud Faces Database数据集(RaFD),Animal Faces-High Quality(AFHQ)数据集和Common Objects in COntext-stuff(COCO-stuff)数据集等。部分文献还公布了预训练的网络模型参数,研究人员可自行生成GAN图像。

表1 GAN生成图像数据集Table 1 The datasets of GAN-generated images
2 GAN生成图像的被动取证技术
GAN作为一种新型的图像生成和编辑技术对数字图像的真实性与完整性带来巨大威胁。由于GAN图像采用端到端网络模型生成,其取证问题具有诸多不同于传统图像取证的特点。接着从以下方面介绍GAN图像的被动取证技术,包括:GAN生成图像检测算法、GAN模型溯源算法和其他GAN生成图像取证问题。
2.1 GAN生成图像检测算法
GAN图像检测算法旨在鉴定待测图像是否由GAN模型生成,可看做一种二分类问题。其研究重点在于提取对GAN图像与真实图像具有显著区分度的特征。根据特征提取时使用的信息类别,主要分为基于空间域信息和基于频率域信息两类算法。
2.1.1 基于空间域信息的GAN图像检测算法
GAN生成图像在成像原理上与真实图像存在明显差异,并且由于GAN生成器的限制,GAN生成图像在空间域上存在着特定的异常痕迹。因此,针对GAN生成图像检测问题,研究人员围绕空间域信息提出了多种算法。根据特征提取的方式,可将检测算法再分为基于手工特征和基于卷积神经网络两类。
2.1.1.1 基于手工特征的检测算法
在GAN图像检测算法研究的早期阶段,研究人员使用在传统图像取证和隐写分析领域已广泛应用的统计特征或其改进版本,结合分类器(例如:支持向量机等)进行检测。基于手工设计特征的检测算法主要考虑了GAN图像和自然图像之间纹理与颜色两种信息的统计特性差异。
一方面,针对GAN图像与自然图像在细微纹理信息上的差异,Marra等人(2018)直接使用基于富模型(rich model)的隐写分析特征进行GAN图像检测。实验结果表明当不进行有损压缩时,隐写分析特征能取得较好的检测性能。然而,当测试图像经过JPEG压缩处理后,基于隐写分析特征的检测算法出现明显的性能下降。
另一方面,针对GAN图像颜色分量的异常统计特性,Li等人(2020a)提出了一种基于颜色分量差异的检测方法。该方法提取不同颜色空间色度分量的高频残差,然后计算基于共生矩阵的检测特征并结合集成分类器得到最终检测结果。实验结果表明该算法在大部分情况下能够取得较好的检测准确率,但当测试样本来自未知GAN模型时性能将出现下降。McCloskey和Albright(2019)通过分析GAN图像颜色分量生成过程的理论模型,提出一种红绿双变量直方图和一种异常曝光像素比例的取证特征。上述特征结合支持向量机等分类器进行GAN图像检测。实验结果表明该算法在缺乏训练样本的情况下性能不理想。
2.1.1.2 基于卷积神经网络的检测算法
卷积神经网络不仅在计算机视觉领域获得广泛应用,也成功应用于多媒体取证相关问题。相关研究成果已证实卷积神经网络在有监督学习过程中能够表征图像信号层面的细微变化。因此,研究人员很自然地将卷积神经网络应用于GAN生成图像检测问题,其通用检测框架如图7所示。
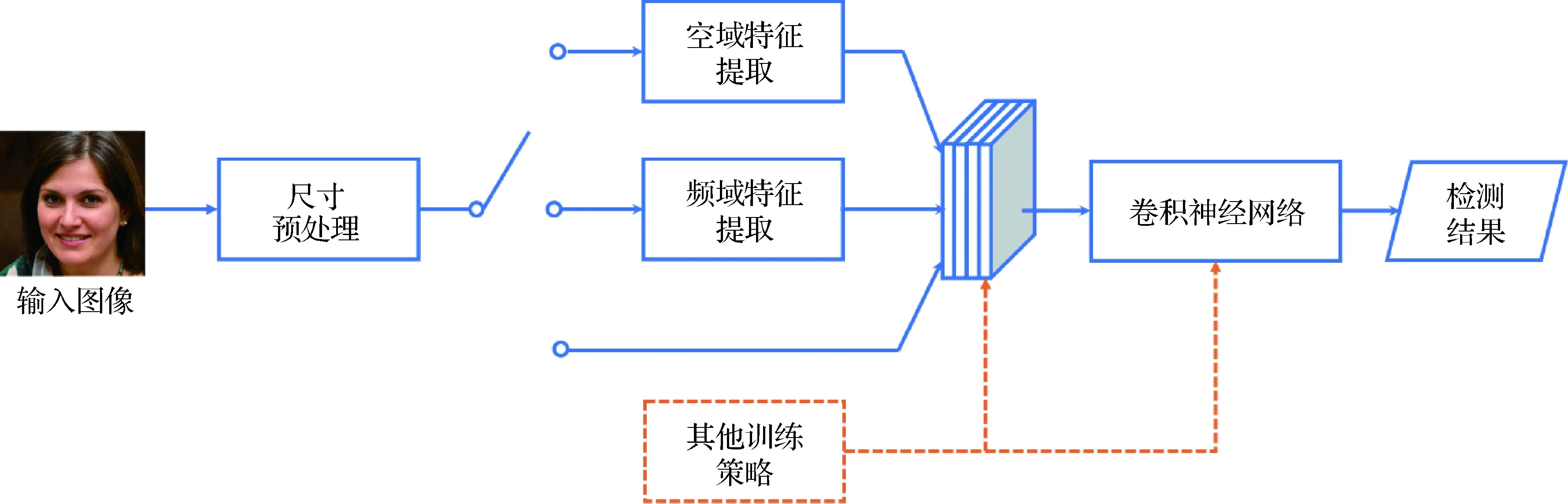
图7 基于卷积神经网络的GAN图像检测算法通用框架Fig.7 The general framework of CNN-based detection method for GAN-generated images
1) 卷积神经网络的初步引入。在PGGAN提出的同年,Mo等人(2018)首次将卷积神经网络用于检测GAN图像,搭建了一个浅层卷积神经网络(CNN)进行检测,并探讨了模型层数和激活函数类型等网络结构对性能的影响。实验结果表明该方法能够有效检测PGGAN生成的图像。当引入高通滤波器对生成图像进行预处理再输入CNN时,检测准确率得到进一步提升。Mo等人(2018)没有测试对未知GAN模型生成图像检测的泛化能力。
直接使用卷积神经网络进行检测存在一定的局限性。同时,卷积神经网络的可解释性仍是研究人员致力攻克的难题。为了进一步提高卷积神经网络分析空间域信息的能力并提高模型的可解释性,研究人员开始引入取证特征作为预处理操作并采用更先进的神经网络结构。
2) 引入基于取证特征的预处理。如1.2节所述,GAN模型生成器中的上采样操作会使生成图像局部像素之间产生异常相关性。在传统图像取证与隐写分析领域,共生矩阵是一种广泛使用的统计特征,用于表征局部像素之间存在的相关性。受到传统取证算法的启发,研究人员尝试将共生矩阵等取证特征作为卷积神经网络的输入,而非直接将图像像素值作为网络输入,以提升算法的检测性能。
Nataraj等人(2019)提出一种基于共生矩阵及卷积神经网络的GAN生成图像检测方法,该方法首先分别提取输入图像RGB三通道的共生矩阵,再将共生矩阵按通道维度进行堆叠,输入一个浅层卷积神经网络得到最终检测结果。采用类似的思路,Goebel等人(2021)将图像三通道提取的共生矩阵输入经过网络结构修改的XceptionNet中,从而实现对GAN图像的检测。除此之外,Goebel等人(2021)还通过改进网络结构中的激活函数及部分结构实现对GAN图像生成模型的溯源。
上述算法仅考虑在单一颜色通道中提取共生矩阵,而忽略了不同颜色通道之间的相关性对检测GAN图像也包含有用信息。在Nataraj等人(2019)的基础上,Barni等人(2020)设计了一种跨颜色通道共生矩阵的计算方法,并将其结果作为卷积神经网络的输入构成Cross-Net。其中,跨通道共生矩阵的计算会考虑RG,RB和GB三种跨颜色通道组合形式。实验结果表明,相比于仅利用单一颜色通道信息,Cross-Net能够进一步提升检测算法对常见后处理操作的鲁棒性。
除了共生矩阵,研究人员也考虑将其他传统取证技术中的预处理方法引入GAN生成图像检测。Guo等人(2021)受到隐写分析算法的启发,如SPAM(subtractive pixel adjacency model)(Pevny等,2010)和SRM(spatial rich model)(Fridrich和Kodovsky,2012),提出一种高频残差自适应提取的网络结构,能够通过预处理操作抑制图像内容信息的干扰,增强篡改痕迹。
总体而言,相较于直接将图像输入CNN进行检测,引入取证特征的目的在于:借助取证领域先验知识,增强篡改痕迹的特征表达鉴别力,减少图像内容信息的干扰。
3) 引入先进的网络结构。除了研究预处理方法,研究人员还通过修改网络结构,引入新的网络模块,进一步提高对GAN生成图像异常痕迹的提取与表征能力。
前文提到GAN图像检测算法已将提取共生矩阵作为一种有效的预处理方法。除此之外,研究人员还根据共生矩阵的原理设计新型网络模块,用于增强GAN生成图像的纹理特性表征能力。Liu等人(2020)采用灰度共生矩阵对输入图像的全局纹理统计特征(global texture statistics)进行分析。但与早期方法不同的是,Liu等人(2020)将ResNet18作为骨架网络,在下采样层之前加入Gram-block模块,将全局图像纹理信息引入不同的特征层级。其中,Gram-block模块包含了卷积层和Gram矩阵计算层。Gram矩阵计算层通过忽略特征图中的空间和内容信息,达到提取纹理稳定特征描述的目的。实验结果表明,全局纹理统计特征对于部分常见后处理操作,具有良好的鲁棒性。同时,引入Gram-block模块还能够提升检测模型对未知GAN模型生成图像的泛化能力。
为了更有效地利用图像不同频率分量之间的互补性,Fu等人(2019)提出一种基于双通道卷积神经网络的GAN图像检测算法,分别采用高斯低通滤波器和高通滤波器计算其低频分量与高频残差,将两者分别输入两个浅层卷积神经网络分支,然后进行拼接融合,再输入全连接层得到最终检测结果。实验表明,使用双通道网络结构进行特征融合能够提升对部分后处理操作的鲁棒性,但仍难以抵抗JPEG压缩造成的干扰。
由于GAN模型中的生成器缺乏对全局信息的表征能力,某些GAN生成图像包含了具有缺陷的全局语义信息。为了更有效地利用全局信息,Mi等人(2020)提出通过引入自注意力机制(self-attention mechanism)来进行GAN图像的检测。自注意力机制能够有效提升卷积神经网络的感知野,使其具备更好的全局信息提取和表征能力,能够缓解传统卷积神经网络存在的空间距离问题。实验结果表明,该方法能够有效检测PGGAN生成的图像,并且对常见后处理操作具有较好的鲁棒性。
4) 其他训练策略。GAN图像检测在实际应用中会面临两方面挑战,即:后处理操作干扰和未知GAN模型生成图像的威胁。针对上述场景,研究人员除了从预处理操作和网络结构两方面进行改进外,还引入其他机器学习和计算机视觉领域的思想进行算法优化。
(1) 面向后处理操作的数据增强。针对检测算法对后处理操作鲁棒性较差的问题,Wang等人(2020a)将数据增强方法引入GAN图像检测。该方法采用ResNet50作为骨架网络,并使用PGGAN生成的高分辨率图像作为训练集。该方法考虑了5种数据增强的策略:无数据增强、高斯模糊、JPEG压缩、以50%概率进行高斯模糊和JPEG压缩以及以10%概率进行高斯模糊和JPEG压缩。Wang等人(2020a)期望通过数据增强策略最终得到一个通用型检测器,对不同网络结构、不同数据集以及不同训练方法对应的GAN图像都具有良好的检测能力。此外,样本在输入检测模型前会进行裁剪及随机翻转。实验结果表明,数据增强对于泛化性能有提升作用;数据增强能够提升GAN图像检测模型对部分后处理操作的鲁棒性;增加训练样本的多样性对提升检测性能有益处。
Wang等人(2020a)考虑数据增强策略,提升了对GAN图像检测的鲁棒性,这使得研究人员开始关注后处理操作对GAN图像检测的影响。Mandelli等人(2020)进一步探究了JPEG压缩对GAN图像检测性能等问题的影响。该论文考虑了JPEG重编码时8×8网格对齐与非对齐的情况,以及不同量化因子对检测性能的影响。Mandelli等人(2020)发现在图像取证任务中,卷积神经网络对JPEG压缩带来的干扰十分脆弱。在模型训练阶段,如果未考虑JPEG压缩或仅考虑单一类型的JPEG网格非对齐情况,则在测试阶段,检测模型对存在未知JPEG压缩操作的GAN图像检测准确性明显下降。
(2) 提升检测泛化能力的学习策略。随着GAN模型的快速发展,越来越多网络结构和训练方法相继提出,极大程度增加了GAN生成图像固有“指纹”的多样性。为了提高检测性能,训练阶段需要收集大量的真实图像和GAN生成图像。然而实际应用中,攻击者可能使用在训练阶段未出现过的GAN模型生成图像。因此,现有GAN图像还存在对未知GAN模型生成图像泛化性不足的局限。
针对上述问题,Zhang等人(2019b)构建了具有生成器一般性网络结构(例如:上采样模块)的GAN模型,称为AutoGAN。AutoGAN可以生成图像样本来模拟GAN图像的异常痕迹。该模型考虑了反卷积和最近邻插值法等上采样模块。当AutoGAN与目标GAN模型的上采样模块等网络结构一致或相似时,使用AutoGAN生成图像进行训练的检测模型能够取得较好的检测性能,对未知GAN模型具有一定的泛化能力。
此外,Marra等人(2019a)采用了增量学习(incremental learning)技术来提高GAN检测模型的泛化能力。增量学习旨在避免神经网络中的灾难性遗忘(catastrophic forgetting)(Kirkpatrick等,2017)。当引入新的数据时,算法会调整网络的参数以及各个类别的范例。实验结果表明,该模型在加入新的训练数据时,能够提升对未知GAN模型生成图像的判别能力,并且保持之前所习得任务的检测性能。
研究人员发现,通过分析基于深度神经网络人脸识别系统(如VGG(Visual Geometry Group)-Face)的神经元行为可以检测GAN生成图像。Wang等人(2020b)提出一种基于神经元覆盖率(neuron coverage)分析的检测算法。该方法利用平均神经元覆盖率标准计算检测特征向量,并结合分类器判断输入图像是否由GAN模型生成。
2.1.2 基于频率域信息的GAN图像检测算法
GAN图像具有与自然图像不同的生成过程,其中反复使用的上采样操作在生成图像中留下周期性痕迹。上述痕迹不仅可以从空间域进行分析,同时也在频率域呈现异常特性。频谱分析是表征信号周期特性的常用方法,因此,近期已有学者开始研究基于频域率信息的GAN生成图像检测算法。
Frank等人(2020)指出,不同的上采样过程均会让GAN图像中相邻像素具备特定的相关性,导致生成图像在频率域具有异常中高频分量。将GAN生成图像变换到频率域(例如:离散余弦变换(discrete cosine transform,DCT)),可以观察到中高频分量存在明显的尖峰。基于上述发现,Frank等人(2020)设计了一种基于DCT频域变换以及卷积神经网络的检测方法。具体地,将输入图像经过DCT变换得到频谱,并在对数尺度下进行归一化,然后输入卷积神经网络。实验结果表明,将归一化频谱作为卷积神经网络的输入,能取得更好的检测结果。类似地,Agarwal等人(2021)提出了一种基于颜色通道频谱及胶囊网络的GAN图像检测算法。
通过分析图像像素间的回归关系,Bonettini等人(2021)发现GAN图像的生成过程可以看做一组有限脉冲响应滤波器进行的信号处理。Bonettini等人(2021)通过DCT系数的首位数字分布表征GAN图像的异常痕迹。首位数字定律(first digital law)(或本福特定律(Benford law))可用于表征真实世界中大部分自然量的分布,例如:在图像取证领域中,量化DCT系数首位数字分布便符合上述定律(Li等,2008)。当图像由非自然采集过程获得或者经历其他编辑处理时,上述规律将被破坏。
与Frank等人(2020)的频率域分析结果类似, Durall等人(2020)通过GAN图像的DFT(discrete Fourier transform)频谱也发现在中高频分量存在异常峰值。针对现有GAN模型在生成图像过程中无法拟合自然图像频谱分布的局限,Durall等人(2020)提出了一种频谱正则化方法,通过计算生成图像频谱的方位积分,使其与自然图像频谱的方位积分尽可能接近。将频谱正则化项与GAN模型生成器采用的常规损失函数进行加权组合得到最终的损失函数。由于考虑了频率域特性,生成的GAN图像在频率域具有更强的抗分析能力。然而,引入频谱正则化项一定程度地降低了生成图像的画面质量。如何让GAN生成图像同时在空间域(像素域)和频率域的统计特性均与自然图像尽可能接近仍是一个开放性问题。
综上所述,本节总结了现有GAN图像检测方法。通过归纳总结发现,现有算法主要从空间域和频率域两个方面挖掘GAN图像所具有的异常痕迹,通过设计手工检测特征或采用卷积神经网络两类技术提取检测特征。现有方法在简单取证场景下均具有良好检测性能。然而,当测试样本经历后处理操作或由未知GAN模型生成时,检测性能将出现明显下降。
2.2 GAN模型溯源算法
在传统的图像被动取证研究中,PRNU(photo-response non-uniformity)噪声(Lukas等,2006)被用做一种可靠的源设备鉴定信息。研究发现,GAN图像也具有类似的“指纹”信息。不同模型生成的GAN图像“指纹”信息具有不同的统计特性,能够用于鉴别GAN图像由何种模型生成。GAN模型溯源算法为分析者提供了GAN图像可能的生成过程相关信息。
Marra等人(2019b)借鉴了PRNU噪声的提取方法,设计了一种提取GAN图像“指纹”信息的算法。该算法首先利用去噪声滤波器提取一组参考图像的噪声残差;然后对这组噪声残差进行逐像素平均消除随机噪声的影响;最终得到具有准周期性(quasi-periodical)的GAN图像“指纹”。通过计算GAN图像“指纹”与待测图像的噪声残差的归一化交叉相关性(normalized cross correlation),判断待测图像是否使用了生成参考图像的GAN模型。实验结果表明,对于几种常见的GAN结构,其GAN图像均包含鉴别力较强的指纹信息。
针对GAN模型溯源问题,Yu等人(2018)提出基于数据驱动的端到端神经网络,对GAN图像包含的“指纹”信息特性进行分析,并考虑了多种常用的GAN模型结构。作者认为GAN图像的生成过程会受到GAN网络结构等因素的影响。利用预池化(pre-pooling)卷积神经网络和后池化(post-pooling)卷积神经网络两种结构进行GAN模型溯源。当不存在后处理操作时,上述两种网络结构均能取得较高的检测准确率。实验结果表明,不同网络结构的GAN模型生成的图像具有差异明显的“指纹”信息。为了进一步提升溯源准确性,Goebel 等人(2021)考虑将图像不同颜色分量的共生矩阵作为卷积神经网络的输入进行GAN模型溯源。与GAN图像检测算法类似,研究人员发现,GAN图像在频域中频和高频分量存在的异常尖峰也能够用于GAN模型溯源任务。据此,Joslin和Hao(2020)提出一种基于频谱相似性的GAN模型溯源算法。利用GAN图像的RGB三个通道分别进行DFT变换,得到目标GAN模型的频域“指纹”。由于GAN模型溯源问题可以看做是一种多分类问题,研究人员表示,用于GAN图像检测的方法经过扩展也可以用于GAN模型溯源,例如Frank等人(2020)。
2.3 其他与GAN生成图像相关的取证问题
GAN模型已成为当前图像内容生成及图像编辑处理的主流方法。这也推动了新一代视频内容篡改技术的飞速发展,例如:能够实现对视频中人脸区域的自动修改。这使得国内外社交网络上出现了大批“换脸”视频制作软件,如DeepFake和ZAO等。现有深度伪造视频技术种类繁多,其具体实现细节也不尽相同。但基本制作流程均包含一些具有共性的步骤。这里以DeepFake(Perov等,2020)为例,简要归纳总结其基本流程:
1)人脸区域的定位和提取。通过计算机视觉相关技术识别并定位人脸区域,然后计算人脸区域关键点。将提取的人脸区域通过几何变换进行矫正。
2)人脸区域的内容生成。将经过几何变换的人脸区域输入到已完成训练的GAN模型,生成用于人脸替换的内容。
3)人脸区域的调整和拼接。根据步骤1)中的几何变换对GAN模型的输出进行相应的反变换。将反变换得到的人脸拼接到目标视频帧的合适位置。
4)生成篡改视频压缩文件。对目标视频逐帧进行步骤1)—3)的篡改操作。所有视频帧完成篡改后,将篡改帧序列进行压缩编码生成最终的篡改视频文件。
从上述流程可知,DeepFake等深度伪造视频技术会利用GAN或自编码器等深度神经网络进行人脸区域的内容生成。与第1节所述的GAN图像内容生成不同,深度伪造视频技术是一种局部篡改操作。因此,所产生的篡改痕迹具有多种特点,包括:
1)深度伪造视频中的人脸区域存在异常痕迹,例如:若采用GAN模型进行人脸区域内容生成,则存在由上采样操作引起的异常纹理,这与1.2节的分析类似。
2)在人脸区域的拼接过程中,拼接边缘会产生内容不连续,并且导致拼接区域和背景区域在分辨率和画面质量等方法上存在不一致性。上述痕迹与传统图像局部篡改操作所产生的痕迹类似。
3)深度伪造视频会经历有损压缩进行存储。相比于图像JPEG压缩,视频有损压缩的压缩比更高,会更大程度地破坏原始视频信号的高频信息,增加检测难度。
近年来,深度伪造视频检测的相关研究成果大量涌现,部分取证方法基于面部生成内容的异常痕迹(Liu等,2021;Guarnera等,2020),而另一部分取证方法则基于人脸拼接边界的不连续性进行检测(Li等,2020b)。
深度伪造视频技术和GAN图像生成技术既有关联,又有明显区别。其关联在于,GAN图像生成技术是深度伪造视频技术的一个环节。换句话说,深度伪造视频包含GAN图像的异常痕迹。而其不同之处在于,GAN图像生成技术是一种全局的信号处理过程;而深度伪造视频技术则是一种局部的信号处理过程。关于深度伪造视频的取证技术可以参考Verdoliva(2020)综述的具体介绍,这里不再赘述。
3 基于GAN的反取证技术
在多媒体取证研究的早期阶段,反取证技术作为取证技术的对抗方式,一直受到研究人员的广泛关注。针对传统多媒体取证方法,已形成了一系列以博弈论为基础,以取证特征统计特性为对象的反取证算法(Stamm和Liu,2011)。而随着深度神经网络的发展,特别是GAN的提出,反取证技术迎来了新的发展机遇。新型反取证算法从取证分析者的对立角度,通过数据驱动的方式对待测图片进行修改,引导现有取证方法输出错误结果。其研究成果可用于揭示现有取证方法的脆弱性,进一步促进取证算法的优化与发展。
目前,基于GAN的反取证方法可根据攻击者掌握取证模型的具体信息划分为:白盒反取证(攻击)方法和黑盒反取证(攻击)方法。白盒反取证方法假设可获得取证模型的具体信息,包括网络结构、网络参数和训练集数据等。此时,取证模型对于攻击者是透明的。而黑盒反取证方法与之相反,攻击者无法获得取证模型的具体信息,仅能获得取证模型的输出结果。因此,黑盒反取证方法具备更高的实际应用价值,即攻击者在对取证模型具体信息未知的情况下仍能实施反取证操作。显然,黑盒反取证方法具有更大的难度和挑战。现阶段,研究者倾向对不同取证问题针对性地设计基于GAN的反取证方法。主要包括两类:1)面向图像生成溯源的反取证方法(如设备源鉴定和计算机图形图像(computer graphics,CG)检测);2)面向图像编辑处理的反取证方法(如JPEG压缩、中值滤波和对比度增强等)。
3.1 面向图像生成溯源的反取证方法
此类反取证方法的目的是掩盖待测图像的生成(采集)过程。现阶段,研究人员主要关注设备源鉴定和计算机图形图像检测两类问题的反取证技术。
3.1.1 设备源鉴定的反取证方法
近年来,设备源鉴定算法大多基于深度学习进行设计,均能够取得比传统方法更好的检测性能。研究人员针对上述取证算法设计了对应的反取证方法。Chen等人(2018)提出一种白盒反取证方法,在GAN模型的生成器前端引入去马赛克(demosicing)痕迹模块,从而绕过对应取证模型的检测。该组研究人员在此基础上提出了一种黑盒反取证方法(Chen等,2019),通过使用一个“替代网络”来拟合目标取证模型的输出,可以成功地将攻击迁移到目标取证模型。
3.1.2 CG图像检测的反取证方法
CG(computer graphics)图像是完全由计算机生成的图像,仅凭肉眼已经很难分辨出CG图像和自然图像。尽管现有图像取证模型能够对两者进行区分,但针对CG图像检测的反取证方法仍可通过重新生成攻击图像,抹去或减少原有的生成痕迹。Peng等人(2020)发现现有反取证方法生成的攻击图像仍具有一定缺陷,如纹理细节丢失、光照变化和色彩失真等,提出了基于黑盒攻击的CGR-GAN(CG facial image regeneration GAN)。其中,生成器学习CG图像到自然图像的风格映射函数,使得CG图像的风格逼近自然图像,并保留原始人物脸部轮廓。Cui等人(2019)通过在鉴别器前加入Sobel滤波器,增强图像的轮廓信息,以提升反取证模型的效率。而Li等人(2021)则在隐藏空间内使用基于梯度下降的方法,使反取证图像能够绕过取证检测的同时保持良好的画面质量。
3.2 面向图像编辑处理的反取证方法
图像编辑处理在图像传输存储和质量优化等应用中具有十分重要的作用,如JPEG压缩和中值滤波等。然而,上述编辑处理也会在一定程度上破坏原始图像信号,时常被攻击者用于掩盖篡改痕迹。为了进一步隐藏图像的编辑处理历史,攻击者基于GAN针对常用图像编辑处理也设计了一系列反取证方法。
3.2.1 JPEG域编辑处理的反取证方法
JPEG是如今使用最广泛的图像有损压缩格式。针对JPEG压缩或JPEG重编码的反取证技术受到广泛关注。Luo等人(2018)首次使用GAN针对JPEG压缩进行反取证研究,考虑到JPEG压缩抑制了图像的高频信息,且经过压缩后的图像低频部分与原始图像相似。因此,该算法将高频率信息作为鉴别器的输入,以捕获生成图像和未压缩图像之间的统计差异。Wu等人(2020)则将面向JPEG压缩的反取证问题看做一种图到图的转换问题,并使用基于高频DCT系数的损失函数来重建图像的高频分量。Wu等人(2021a)在自身研究基础上提出JPA-GAN(JPEG restoration and anti-forensics GAN),对高频DCT系数损失函数进行改进,考虑高频滤波后的DCT系数矩阵与其自身取平均值后的差值,并设计合理的高频滤波器,使生成图像具有较高的图像质量,并在不可检测性和图像质量之间取得一个较好的平衡。
3.2.2 空域编辑处理的反取证方法
空域编辑处理也是一类常见的编辑方式,例如:使用中值滤波进行图像去噪,或使用对比度增强提高画面美观程度等。因此,针对上述编辑操作的反取证研究也受到广泛关注。Kim等人(2018)利用GAN网络重构中值滤波前的图像,使得重构图像能够遵循原始图像的统计特性。该方法为黑盒反取证方法,无需取证模型的先验知识。为了进一步增强反取证的性能,Xie等人(2021)提出双域(dual domain)反取证GAN网络,该网络包括一个生成器和两个判别器。其中生成器基于全卷积网络(fully convolutional network)生成任意尺寸大小的图像。另一方面,两个判别器分别在取证特征域和空间域进行判别。该模型生成的攻击图像具有良好视觉质量和抗取证分析能力。此外,Zou等人(2021)利用GAN网络对空域对比度增强操作进行反取证研究,通过将直方图和灰度共生矩阵引入损失函数的设计,从而进一步提升视觉质量和反取证效果。
3.2.3 多重编辑处理的反取证方法
前面提到的反取证方法大多针对单一图像编辑处理进行反取证研究。如何隐藏或还原多重图像编辑处理所遗留的痕迹仍然具有较大挑战性。Wu等人(2019)将该问题视做图到图的迁移问题,根据带有梯度惩罚的WGAN网络架构(Wasserstein generative adversarial networks with gradient penalty, WGAN-GP)设计面向多重编辑处理的反取证算法。此后,为了使模型既能保持对单一图像编辑处理的检测精度,又能够完成多重图像编辑处理的检测任务,Wu和Sun(2021)在此基础上进行训练方式和集成方式的扩展,提出集成式和整体式的多重操作反取证策略。Zhao等人(2021)对面向多重操作的反取证攻击的可移植性进行研究,在GAN网络中添加替代网络集成多个预训练好的取证模型来学习多样化的取证痕迹,同时将判别器和替代网络的结果用于指导生成器训练,提升对未知取证模型的反取证效果。
目前,基于GAN的反取证方法大多针对特定的图像编辑操作进行设计,对未知编辑操作反取证目标的迁移性较差。随着取证研究的不断发展,当取证模型更新后,对应的反取证模型也不断迭代,两者形成一个对抗博弈的过程。值得注意的是,反取证模型的目的在于隐藏或修改图像生成或图像编辑处理所产生的痕迹,但GAN网络由于其生成器结构的固有特性,在生成图像中会留下特定痕迹。上述问题与传统反取证算法在移除目标痕迹的同时,尽可能减少引入新的痕迹具有类似特点。
4 GAN图像被动取证技术面临的挑战
面向GAN生成图像的被动取证与反取证技术研究已取得一定进展,但仍处于起步阶段。在实际取证场景中,GAN图像被动取证技术面临诸多挑战,并且与其他取证问题存在明显差异(Hulzebosch等,2020)。
4.1 对后处理操作的鲁棒性
不法分子可以利用基于GAN的图像生成技术构建虚假身份或发布虚假新闻,并在社交网络进行传播。因此,面向GAN生成图像的取证技术应该对图像在社交网络平台传播过程中经历的图像处理操作具有良好的鲁棒性,例如:JPEG压缩、尺寸裁剪和对比度增强等。然而,现有取证算法,例如GAN图像检测算法,若没有充分考虑数据增强策略,则对常见后处理操作和多操作组合的鲁棒性较差。为了说明上述问题,进行如下实验。
在数据集方面,从官方公布的CelebA-HQ和PGGAN(https://github.com/tkarras/progressive_growing_of_gans)数据集中随机选取5 000对真实图像和虚假图像,按照6 ∶1 ∶3的比例构建训练集,验证集和测试集。本实验选择两种基于空域信息的卷积神经网络算法(Wang等,2020a; Mi等,2020)以及一种基于频域信息的卷积神经网络算法(Frank等,2020)进行测试。Wang等人(2020a)采用ResNet50结合数据增强操作训练一个通用型检测器。而Mi等人(2020)则引入自注意力模块学习GAN图像全局的异常模式。另一方面,Frank等人(2020)则将图像的DCT变换频谱作为浅层卷积神经网络的输入进行检测。其中,对Wang等人(2020a)不仅测试了利用上述训练集直接进行优化得到的模型,还测试了官方公布的模型。
在实验配置方面,考虑计算复杂度问题,原本1 024×1 024像素分辨率的图像样本采用一定的方式生成256×256像素的图像。实验中考虑裁剪(crop)和尺寸缩放(resize)两种方式。具体地,裁剪操作首先将原始图像划分为不重叠的256×256像素图像块,然后随机选择一块。而尺寸缩放则使用双三次插值法生成256×256像素的图像。训练和测试时采用相同方式处理样本。为了保证对比的公平性,学习率都设为1E-5,批大小设置为64,最多训练200个轮次,并使用Adam优化器(Kingma和Ba,2015)进行模型优化。实验均采用准确率(Acc)作为性能评价指标
Acc=(TP+TN)/(P+N)×100%
式中,TP和TN分别表示判断正确的正负样本数量,P和N分别表示正负样本的总数量。
实验主要考虑了JPEG压缩(量化因子包括:95,85和75)、高斯模糊(采用1维卷积核,标准差取值包括:0.5,1.0和1.5)、尺寸缩放(采用双三次插值算法先按比例放大,再随机裁剪256×256像素的图像块,缩放因子包括:180%,200%和220%)等后处理操作。在实验中,仅对测试样本施加后处理操作。实验结果在表2中列出,其中最优的检测结果加粗表示。
如表2所示,随着后处理操作的强度不断增加,例如:使用更小的量化因子或更大的缩放因子,空域检测方法的准确率均出现下降,而频域检测方法在大多数情况下变得无法进行检测。特别是采用裁剪作为图像预处理操作,性能下降更为明显。相比于使用裁剪获得256×256像素的样本,尺寸缩放操作能够增强Wang等人(2020a)和Mi等人(2020)两种算法的抗干扰能力。其中Mi等人(2020)使用自注意力机制模块,能够关注GAN图像存在的全局缺陷信息,平均鲁棒性更好。此外,采用Wang等人(2020a)官方提供的检测模型对不同后处理的干扰能取得较好的检测效果。这说明对训练样本进行数据增强是提升鲁棒性的一种有效方式,但也存在计算量较大的问题。实验进一步测试了两种典型的GAN图像检测算法,即基于浅层卷积神经网络的检测算法(Mo等,2018)和基于颜色分量差异的检测算法(Li等,2020a)。实验结果表明其鲁棒性弱于Wang等人(2020a)基于深度残差网络的检测算法。

表2 对不同后处理操作的检测准确率Table 2 Experimental accuracy for different post-processing operations /%
4.2 对未知GAN模型的泛化能力
随着GAN技术的不断发展,越来越多种类的GAN模型由研究人员相继提出,这导致取证分析者难以在检测模型训练集中包括所有潜在的GAN模型。对于未知GAN模型图像的检测,在没有考虑特殊学习策略的情况下,现有算法检测性能会出现明显下降。为了说明上述问题,进行如下实验。测试集GAN图像的生成过程考虑了训练阶段未出现的GAN模型,包括:StarGAN(Choi等,2018)、BigGAN(Brock等,2019)和StyleGAN2(Karras等,2020),并将用于GAN模型训练的样本作为测试集真实图像,其他部分采用与4.1节相同的实验配置。此外,训练集和测试集采用相同的尺寸预处理方式。
如表3所示,当训练集与测试集样本均由同一种GAN模型(PGGAN)生成时,所有算法均能取得良好的检测结果。从其他情况的结果可以看出,目前算法对于未知GAN模型的泛化能力不足。BigGAN在模型结构上与PGGAN具有较大差异,同时训练数据集也有所不同。StarGAN属于条件GAN模型,而检测模型在训练过程中选用的PGGAN属于非条件GAN。上述情况模拟了实际取证场景中可能存在的未知GAN模型场景。当GAN模型框架发生较大变化时,算法的检测性能将会出现明显下降。值得注意的是,采用Wang等人(2020a)官方提供的检测模型在不同的跨GAN检测场景下展示出了更好的平均性能。这也意味着对训练样本进行适当数据扩充是提升泛化能力的一种有效途径。
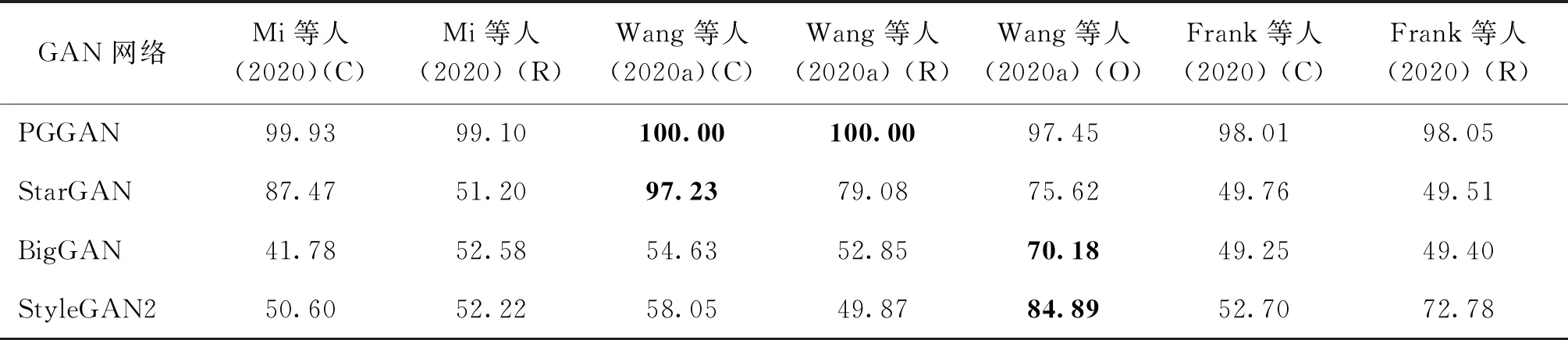
表3 对不同(未知)GAN生成图像的检测准确率Table 3 Experimental accuracy for images generated by different (unknown) GANs /%
此外,对基于空域信息的检测方法,当选用裁剪(crop)作为尺寸预处理操作时,模型对于未知模型生成图像的检测性能优于使用尺寸缩放(resize)的尺寸预处理方法。裁剪操作保留了图像原始像素点,然而损失了图像的语义内容。缩放操作尽可能保持了图像的语义信息,却会丢失大量细节。因此,上述实验结果可能的原因是裁剪操作使得取证模型更多关注生成图像的“指纹”信息,减少了对图像内容语义过拟合的风险。另外,从表2可知,使用缩放操作进行尺寸预处理,对提升取证模型抗后处理操作的鲁棒性具有帮助。关于尺寸预处理操作的影响值得更加深入的讨论。
本文进一步考虑实际应用中可能存在的对抗情况,即使用GAN图像检测算法识别基于GAN的反取证图像。本实验作如下假设:取证方和反取证方均缺乏对方所使用模型的先验知识,各自独立实施算法。在实验中,采用反取证算法JRA-GAN (Wu等,2021a)(https://github.com/wujianyuan/JRG-GAN)按照与原文相同的实验设置对3 000幅原始灰度图像(从BossBase数据集中随机选取)进行处理得到的3 000幅JPEG反取证图像(量化因子为75),分别作为测试集的负样本和正样本。由于JRG-GAN是对灰度图像进行反取证,本实验将4.1节实验中基于空域信息(Wang等,2020a)和基于频域信息(Frank等,2020)的算法,利用训练集对应的灰度图重新训练检测模型,采用缩放操作(resize)统一图像尺寸,其他实验设置保持不变。实验结果如表4所示。

表4 对反取证图像的检测准确率Table 4 Detection accuracy of anti-forensics image /%
根据表4的结果可以看出,无论是基于空域还是频域信息,取证方在不具备反取证方所用算法先验知识时,无法进行有效的取证分析(检测准确率接近50%)。上述结果的原因主要为:现有的主流GAN图像被动取证技术采用基于神经网络的有监督学习框架,而GAN生成图像的取证痕迹是一种弱信噪比信号。检测模型在训练阶段容易对训练集样本的图像内容过拟合。因此,即使基于GAN的反取证图片包含了GAN生成器产生的特殊痕迹,但该痕迹对于取证方仍表现为一种未知模式。上述实验结果表明,在攻防对抗过程中,取证方还需加强对未知攻击模式的防御能力。
5 结 语
面向GAN生成图像的被动取证与反取证技术进行了系统梳理与总结。GAN技术的快速发展一方面为多媒体领域提供了极大推动力,另一方面也对数字图像的完整性和真实性造成了新的威胁。通过对GAN图像生成与自然图像采集的原理进行分析,总结了GAN生成图像在颜色以及纹理两方面存在异常痕迹,可作为相关取证问题的线索。针对GAN图像检测问题,现有算法从空间域和频率域通过设计手工特征或利用端到端卷积神经网络的方式提取检测特征。其中,采用基于取证特征的预处理能够一定程度提高卷积神经网络的检测鲁棒性。此外,通过优化网络结构或引入新的训练策略能达到提升泛化性的目的。而针对GAN模型溯源问题,研究人员已证实GAN图像具有类似相机采集图像PRNU的“指纹”信息,并且该“指纹”信息与GAN模型结构和训练集样本均有密切关系。并且,将GAN图像的像素信息或频域信息输入卷积神经网络进行多分类,均能取得一定的溯源效果。此外,研究人员也成功利用GAN模型进行反取证,包括面向图像生成过程的反取证(设备源鉴定和CG图像检测等)以及图像编辑过程的反取证(JPEG压缩和中值滤波等),并已取得一定效果。然而,从国内外研究现状的梳理总结和本文实验结果看,现有研究工作考虑的取证场景仍存在诸多局限。总体来说,面向GAN生成图像的被动取证及反取证技术仍处于起步阶段,面临以下问题:
1)取证与反取证技术的可解释性不足。现有GAN图像被动取证技术主要采用卷积神经网络构成检测框架。上述基于数据驱动的思路虽然能取得良好的检测效果,但可解释性不足。研究人员难以分析是何种信息(局部或全局、纹理或颜色等)对鉴别GAN图像起到更主要的作用。另一方面,现有基于GAN的反取证技术主要研究网络结构及损失函数的优化设计。虽然对目标取证痕迹的隐藏能力越来越强,但难以对反取证过程引入的新痕迹进行理论分析。换句话说,当前基于GAN的反取证技术的安全性缺乏理论支撑。
2)取证技术的鲁棒性和泛化性较弱。在实际应用场景中,待测图像可能经历后处理操作(例如:社交网络平台传播过程中的后台转码操作)或由未知GAN模型生成。面对上述情况,现有GAN图像被动取证技术表现出较弱的鲁棒性和泛化性。虽然已有研究人员尝试将数据增强和其他学习策略(例如:增量学习)用于改进相关性能,但效果提升仍不明显。在未来研究中,可以考虑采用异常检测等其他框架设计GAN图像被动取证算法,以应对不断更新的GAN模型及应用场景中潜在的后处理干扰。
3)反取证技术缺乏多特征域协同的抗分析能力。现有基于GAN的反取证技术在设计网络损失函数时通常仅考虑目标特征域的信息(空域或频域等)。在训练过程中,GAN模型会根据单一特征域损失函数更新网络参数。虽然能够成功隐藏目标特征域的取证痕迹,但GAN生成器网络结构(例如:上采样模块)的固有特性会在其他特征域留下新痕迹,存在被其他取证分析算法再次发现的风险。因此,如何设计反取证技术的网络结构、损失函数和训练策略,使其在多个常见特征域上均能隐藏取证痕迹仍是需要探究的问题。
4)对抗博弈场景下,缺乏图像真实性鉴定的新机制。由于GAN模型在训练过程中具有对抗博弈特性,攻击者对图像内容的生成编辑与防御者对图像真实性的鉴定分析已形成对抗博弈关系。分析人员难以完全掌握实际应用中潜在的恶意干扰。对于上述新场景,仍缺乏图像真实性鉴定的可靠机制。今后,可以借鉴主动取证技术的相关思想,结合端到端生成式神经网络将验证信息预先嵌入数字图像,并确保嵌入信息后图像仍具有良好的视觉质量。分析人员可通过提取验证信息对图像真实性进行鉴定。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
读者(2015年9期)2015-05-04
