
DenseNet在声纹识别中的应用研究*
2022-01-24 02:16:24张玉杰
计算机工程与科学 2022年1期
张玉杰,张 赞
(陕西科技大学电气与控制工程学院,陕西 西安710021)
1 引言
声纹识别是一种生物识别技术,可根据一段语音识别出说话人的身份[1]。从传统的高斯混合模型GMM(Gaussian Mixture Model)[2]到深度学习算法[3 - 5],声纹识别技术得到了快速发展。近年来,随着语谱图的出现,研究者提出采用语谱图与卷积神经网络相结合的方式进行说话人身份识别[6 - 8],其优势在于语谱图具有很强的综合表征能力,能够充分表示说话人身份的完整信息,且卷积神经网络CNN(Convolutional Neural Network)擅于提取特征的能力,使声纹识别系统的识别性能得到大幅度提升。
针对基于语谱图的声纹识别算法的研究目前仍处于初级阶段,文献[6-8]将卷积神经网络视为一种特征提取器,所用卷积层数较少,网络的表达能力有限。而基于端到端的深度卷积神经网络模型不仅能够利用深层的网络结构提取深度特征,而且端到端的方式使CNN具有特征提取与分类2种能力。DenseNet(Dense convolutional Network)作为一种端到端的网络模型,采用密集连接结构一方面能够构建更深层次的网络,另一方面加强了特征传播,在图像分类领域取得了较好的效果[9,10]。本文借鉴图像处理的方法,将DenseNet应用于语谱图声纹识别中,以提高声纹识别的识别率。但是,利用DenseNet进行声纹识别时,存在以下问题:声纹识别在许多场合下需要在嵌入式设备上进行,大量的卷积池化操作会带来网络参数量的增加,导致在提取声纹特征时网络的存储数据量增大,计算效率降低,不利于在对参数量有严格限制的嵌入式环境中运行;采用Softmax 损失训练的DenseNet网络提取的特征只具有可分离性,未考虑类内的紧凑性,使特征没有很好的表征性能,降低了声纹识别的精确度。
本文将DenseNet用于语谱图处理实现声纹识别,从减少网络参数量以及提高声纹特征表征能力2个方面展开研究,对DenseNet进行优化,提高DenseNet在语谱图声纹识别中的识别效果。
2 语谱图及声纹识别算法存在问题
2.1 语谱图
语谱图[11]是将语音信号的频域特性通过时间域上的累积而形成的一种二维图像,动态地显示了语音频谱与时间之间的变化关系。语谱图中包含对应时刻频率与能量强度组成的空间特征信息以及随时间变化的时序特征信息,这些信息根据颜色的深浅形成了不同的纹理,在这些纹理中包含了大量的说话人的个性特征信息,根据语谱图纹理的区别,可以鉴别不同的说话人。
语谱图的生成过程如图1所示。依据语音信号的短时平稳特性将语音信号分割为若干帧信号,再对每一帧信号加窗处理,然后进行傅里叶变换得到信号的幅频特性,通过对幅度值进行对数变换和彩色映射获得语音信号对应的语谱图。

Figure 1 Generation process of the spectrogram图1 语谱图的生成过程
2.2 DenseNet在声纹识别应用中存在的问题
借鉴基于深度学习的图像处理方法,按照图1的过程生成说话人的语谱图,将语谱图作为原始数据,输入至DenseNet网络中进行声纹识别。按照语谱图的处理要求,DenseNet的网络结构如图2所示,主要由1个初始卷积、N个密集连接模块(Dense Block)、多个传输层(Transition Layer)和1个分类层(Classification Layer)组成。Dense Block结构图如图3所示,x0,x1,…,xl-1为第0层到第l-1层的特征图,通过对各层特征图的拼接,再经过非线性变换Hl(*)得到第l层的特征图xl,其过程如式(1)所示:
xl=Hl([x0,x1,…,xl-1])
(1)
其中,非线性变换H(*)由一个1×1卷积和一个3×3的卷积组成,1×1卷积被称为瓶颈层(Bottleneck Layer),其输出通道数为4k(k是一个超参数,被称为增长率),其作用是既融合了各个通道的特征,又通过降维减少了输入到3×3卷积的特征图数量,减少网络的计算量。

Figure 2 Network structure of DenseNet 图2 DenseNet网络结构

Figure 3 Network structure of densely connected modules 图3 密集连接模块的网络结构
为了防止随着网络层数的增加,特征维度增长过快,Dense Block模块之间通过Transition Layer连接。假设传输层的输入通道数为k,采用1×1卷积产生θ×k个特征,当0<θ<1时传输层起到模型压缩的作用,再通过2×2池化操作缩小特征图大小,减少网络的参数量。
将DenseNet应用于声纹识别对语谱图进行处理时,可以将语谱图看作是一种纹理图像,说话人的语音个性特征体现在像素间的空间几何特征与时序特征上,利用DenseNet进行声纹识别时,利用其特征重用特性和对卷积池化层累积的特性,语音原本的序列特性可得到充分体现。但是,随着卷积池化层的增多,网络的数据量随之增大,DenseNet的瓶颈层和传输层分别采用小的卷积核对特征图的维度进行压缩,在一定程度上减少了网络的参数量。但由于网络层数的加深,网络的参数量与计算量仍处于“超重”状态,不利于在资源有限的嵌入式平台上实现声纹识别。
DenseNet的Classification Layer由全局池化层、全连接层和Softmax层组成,经过全局池化层和全连接层能够得到语谱图中描述说话人的语音特征,再用Softmax函数进行归一化处理得到每个说话人的概率。DenseNet使用交叉熵损失函数作为目标函数,通过网络训练划分不同说话人类别。但是,对于声纹识别来说,该方法只考虑到类内的距离,提取到的声纹特征并没有更好的表征能力,不足以实现说话人身份的精确识别。
3 声纹识别算法优化
针对DenseNet应用于声纹识别领域存在参数量大、特征表征能力弱的情况,本文对网络进行优化。一方面在不损失精度的前提下,对网络结构进行优化以减少参数量;另一方面通过多个损失函数的联合监督训练,增强声纹特征的表征能力,实现说话人身份的精确识别。
3.1 DenseNet网络结构的优化
深度可分离卷积DSC(Depth Separable Convolution)是一种能够有效减少网络参数量的方法,本文将其应用至DenseNet网络中以降低算法的运算复杂度。
本文设计的DenseNet网络结构如表1所示,采用了4个密集连接模块和3个传输层。其中,4个密集连接模块的密集连接单元个数分别为6,12,24和16。为了减少网络的参数量,使用深度可分离卷积将Dense Block模块中3×3的标准卷积分为一个3×3深度卷积DW(Depthwise Convolution)和一个1×1逐点卷积PW(Pointwise Convolution)。DW卷积的作用是对每一个输入通道的特征图做单独卷积,一个卷积核负责一个通道;再利用PW卷积对DW卷积产生的特征图进行组合,改变输出通道数。

Table 1 Network structure of improved DenseNet
在模型训练中,假设瓶颈层输出大小为H×W×N的特征图,利用3×3的卷积核进行卷积操作后,输出大小为H×W的P通道特征图,则标准卷积参数量PSC与计算量FSC分别如式(2)和式(3)所示:
PSC=3×3×P×N
(2)
FSC=H×W×3×3×N×P
(3)
而深度可分离卷积的参数量PDSC与计算量FDSC分别如式(4)和式(5)所示:
PDSC=3×3×N+N×P
(4)
FDSC=H×W×32×N+H×W×N×P
(5)
深度可分离卷积与标准卷积的计算量与参数量之比如式(6)所示:
(6)
因此,采用深度可分离卷积,在模型的精度损失较小的情况下运算量减少近8~9倍,极大地提高了模型的运算效率。
3.2 损失函数的改进
为了提高声纹特征的表征能力,使特征具有很好的类内紧凑性和类间可分离性,本文采用Softmax损失函数(Softmax+交叉熵损失函数)与中心损失函数(Center Loss)[12]联合监督的方式来训练DenseNet,其损失函数的具体表达式如式(7)所示:
L=Ls+λLc
(7)
其中,L表示总损失,Ls表示Softmax损失,Lc表示中心损失,λ用于平衡2个损失函数。其中Softmax损失函数的表达式如式(8)所示:
(8)
其中,xi表示第i个特征;yi是xi的真实类别标签;Wyi与Wj分别表示将xi判别为yi类和第j类的权重向量,即最后全连接层中权重W的第yi和第j列;byi与bj分别表示yi类和第j类的偏置项;m表示小批量(mini-batch)的大小。
Center Loss损失函数如式(9)所示:
(9)
其中,cyi表示第yi类特征的类中心。可以看出,中心损失函数为每一个类别提供一个类别中心,使参与训练的每一个样本都能向同一类别的中心靠拢,达到聚类的效果。
由式(8)和式(9)可以得到,在Softmax损失的监督下训练的网络可以划分不同类别,但未曾考虑类内特征的紧凑性;中心损失虽然最小化了类内距离,但并未考虑类间的可分离性。因此,采用两者相结合的方式对算法进行寻优,可以扩大类内的紧凑性和类间可分离性,实现说话人身份的高精度判别。
4 实验仿真及分析
4.1 实验数据集
实验采用的语音数据集来自希尔贝壳中文普通话AISHELL-ASR0009OS1开源语音数据库,400名发言人参与录制,分别来自中国不同口音区域,录制过程在安静的室内环境中进行,每人录制300多个语音片段,同一人的语音放在一个文件夹下,随机抽取10人的语音进行实验,一段语音被截取为1.5 s时长的语音片段,按照8∶2的比例分为训练集与测试集,训练集包括41 909幅语谱图,测试集包括10 472幅语谱图。
4.2 实验设置
硬件平台:GPU:NVIDIA Tesla V100;RAM:32 GB;显存:16 GB;操作系统:Ubuntu 16.04LTS,实验基于Keras框架。首先对语音信号进行处理,语音信号的采样率为11 025 Hz,帧长为25 ms,则傅里叶变换点数为256,每帧语音信号的长度为256,帧叠为128,按照图1所示的方法得到说话人的语谱图大小为119×129,随机挑选2人的语谱图如图4所示,图中明显的横方向的条纹,称之为“声纹”,不同说话人的语谱图声纹纹理有所区别。

Figure 4 Spectrogram with 119×129 图4 119×129语谱图
为了验证本文声纹识别算法的有效性,设计4组实验进行对比,具体实验细节如表2所示。

Table 2 Experimental grouping
实验1为梅尔倒谱系数MFCC(Mel Frequency Cepstral Coefficients)+高斯混合模型GMM分类方法中,MFCC采用16维特征,GMM的阶数为10阶。实验2和实验3采用的网络结构参数如表1中的“DenseNet”部分所示,实验4采用的网络结构参数如表1中的“改进的DenseNet”部分所示。其中,Dense Block模块的增长率k设置为32;Transition层的压缩系数为0.5,即特征图通过传输层特征维度减少一半;中心损失函数的中心学习率设置为0.6,λ取0.01。本次实验采用Adam优化器,批量大小为64,学习率设置为0.001,迭代次数为40次。定义识别率为性能评价指标,即识别正确的语音片段的数量与测试数据集中的总语音片段数量的比值。
4.3 实验结果分析
(1)收敛性分析。
通过对实验2~实验4进行仿真训练,模型损失值与迭代次数的关系如图5所示。由图5可以看出,实验2比实验3和实验4的收敛速度更快,而实验3和实验4的收敛速度比较接近。说明在Softmax损失的监督下,DenseNet网络能够很快收敛,Center Loss的加入对网络的收敛速度有一定的抑制作用,但是随着迭代次数的增加,3组实验的Loss值都呈下降趋势且趋于平稳,表明3组实验的网络都可以正常收敛。
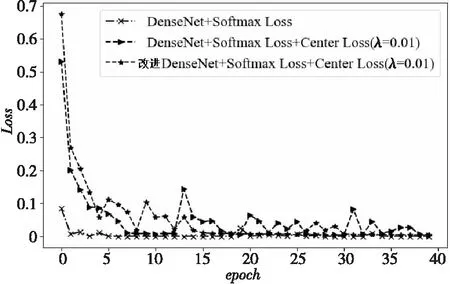
Figure 5 Effect of epoch on Loss value图5 迭代次数对Loss值的影响
(2)模型大小与参数量。
原DenseNet网络与基于深度可分离卷积的DenseNet网络的参数量和模型大小如表3所示,改进的DenseNet网络的参数量减少了25.5%,模型大小减少了24.6%。
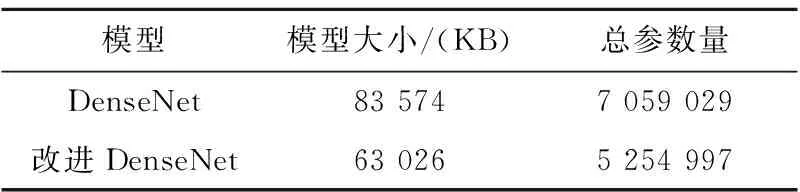
Table 3 DenseNet network model size
(3)识别率。
表4反映了4组实验的识别率,由表4可知,实验2与实验1相比,识别率提高了12.4%,充分体现了基于DenseNet网络的声纹识别方法优于传统的MFCC+GMM模型;实验3与实验2相比,识别率提高了1.94%,实验4与实验2相比,识别率提高了1.9%,说明Center Loss与Softmax Loss相结合更有利于说话人身份的识别,提高了声纹识别的识别率;实验3与实验4相比,基于深度可分离卷积的DenseNet网络与原网络的识别率基本接近,说明DenseNet网络结构上的改变并未影响网络的识别率,还有效地减少了网络参数,提高了网络的计算效率。

Table 4 Recognition rates comparision of four groups of experiments
(4)特征可视化。
针对实验2与实验4,利用PCA(Principal Component Analysis)算法对最后一层全连接层所提取的特征进行降维,再进行特征可视化,可视化结果如图6和图7所示。由图6可以看出Softmax Loss虽然能够将每一类别分开,但是同一类别特征比较分散。与图7进行对比,可以明显看出加入中心损失函数后,DenseNet网络提取的声纹特征有很好的聚类效果,进一步表明改进的DenseNet网络+Center Loss+Softmax Loss更适合于声纹识别任务。

Figure 6 Feature visualization results based on Softmax Loss图6 基于Softmax Loss的特征可视化结果

Figure 7 Feature visualization results based on Softmax Loss and Center Loss图7 基于Softmax Loss 与Center Loss的特征可视化结果
5 结束语
将DenseNet应用于语谱图实现声纹识别,从提高网络的运算效率和增强声纹特征的表征能力2个方面对DenseNet展开研究,提出采用深度可分离卷积以及增加中心损失函数项实现对DenseNet的优化。实验结果表明,与优化前比较,网络参数量减少了25.5%,模型大小减少了24.6%;从仿真结果可以看出,优化后的网络提取的声纹特征具有很好的类内紧凑性与类间可分离性,特征的表征能力得到了增强。由此可以得出,改进后的DenseNet在语谱图声纹识别方面具有很好的识别效果,是一种有效的声纹识别方法。
猜你喜欢
时代汽车(2024年12期)2024-07-05 22:35:03
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
通信产业报(2018年32期)2018-11-24 10:37:58
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
电子技术与软件工程(2017年24期)2018-01-17 12:39:59
中国科技博览(2017年17期)2017-06-14 00:23:40
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
电脑知识与技术(2016年12期)2016-06-14 00:01:51
东南大学学报(自然科学版)(2015年5期)2015-03-15 00:54:56
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
