
MDF-ANet:低光照环境下的无人驾驶视觉融合分割方法
2022-01-23 08:26:50常亮白傑胡会会钟宏亮
北京理工大学学报 2022年1期
常亮, 白傑, 胡会会, 钟宏亮
(1. 同济大学 汽车学院,上海 200082; 2. 中国科学院 微小卫星创新研究院,上海 201210)
图像语义分割是计算机视觉领域中的一项基本研究内容,是根据目标邻域特征针对每个像素进行分类,最终得到一个具有像素级语义标注的图像,在各领域中都具有极其重要作用,如自动驾驶[1]、通道安检、医疗健康领域等[2],在自动驾驶领域,通过图像语义分割可帮助进行避障和路径规划[3-4];在通道安检领域,可准确分割并识别出危险物品;在医疗领域,可帮助医师进行病灶的分割和识别. 随着深度学习技术发展及计算机硬件性能的提高,深层次大规模的神经网络在图像语义分割方面已经取得了很大的进展.
一般在利用卷积神经网络对图像进行分类时,会在卷积层的后面引入全连接层, 即将图像的二维特征转换为一维特征,不利于图像语义分割,LONG等[5]提出了去除全连层的全卷积神经网络( fully convolutional networks,FCN),使网络具有密集预测能力的同时允许任一尺寸的图像作为输入,后面的基于深度学习的语义分割研究几乎都采用全卷积神经网络作为基础,使端到端的图像分割网络得以推广,同时提出了使用反卷积进行上采样,并使用上采样的粗糙分割特征图与高分辨特征图进行跳跃连接以改善上采样层中粗糙的像素定位,从而实现像素精准分割. 深度学习网络中的池化层增大了感受野但会因此丢弃部分位置信息,为解决此问题,人们提出了两种不同的解决思路. U-net采用编码-解码结构进行分割网络设计,编码器通过使用池化层,缩小图像尺寸提高滤波器的感受野,而解码器则通过上采样恢复图像空间维度,且在每次上采样后在通道维度上级联编码器中同一尺度的特征,来帮助解码器恢复图像的细节,在医学图像上得到很大的应用[2]. CHEN等[6]提出了空洞卷积在不降低图像分辨率的情况下提高滤波器的感受野,并且在网络后使用全连接条件随机场进行处理,恢复图像边缘的信息,在一定程度上改善了分割效果. ZHAO等[7]在使用空洞卷积的基础上添加了金字塔池化模块,聚合不同区域的上下文信息,在语义分割上产生了更好的效果. 近几年,注意力机制不但在NLP领域取得主导地位,而且在图像分割领域也得到了极大的关注,FU[8]提出一个新型的集成双路注意力机制的语义分割模型,在空洞卷积的特征提取模块后采用两个并行的位置注意力模块和通道注意力模块,进行语义信息的聚合.
但现存的语义分割方法大多是在正常光照条件下的研究,缺乏低光照环境下的探索,当光照强度降低时,性能往往降低很多. 在自动驾驶领域中,会遇到各种各样的自然条件[9],对于低光照场景下,光照不足会导致图像信息丢失,造成图像上目标间的边界细节丢失,没有足够的特征来进行视觉处理,而简单地使用图像亮度增强方法会引入噪声,影响图像分割效果. KVYETNYY等[10]认为低光照图像是噪声干扰的结果,使用图像预处理的方式能够提高目标检测率,提出了一个双边滤波和小波阈值的方式进行去噪处理,然后再进行图像检测. RASHED等[11]提出了一个基于Lidar光流计算和相机光流计算的CNN结构用于低光照条件下运动目标的检测,但此方法仅限于动态目标的检测,不够全面,自动驾驶中也要避让很多静态障碍物. 王昊然[12]提出了一种利用迁移学习的低光照场景语义分割算法,将提取的理想场景图像的特征,如包含有利于图像分割的亮度和颜色信息,补充到低光照图像特征中,进而提升低光照图像的语义分割效果. SASAGAWA等[13]提出了一种域自适应的新方法,使用glue层和生成模型合并不同领域的预训练模型,用于低光照条件下的目标检测,与创建新的数据集相比,花费的资源更少.
针对上述低光照条件下图像亮度不足,信息丢失问题,本文提出了一种深度图辅助图像语义分割的两路融合网络,两路网络分别使用深度图和RGB图作为输入,并且在不同尺度的输出层上通过自注意力机制模块进行特征图融合,最后将多个尺度的输出特征共同输入到多尺度融合模块,对不同尺度的特征进行互补性融合,有效地提高图像分割效果.
1 MDF-ANet模型
本文设计了一个相对独立两路融合网络框架,分别对原始的RGB和深度图进行处理,并设计融合模块整合两路提取的特征层,充分利用不同传感器在不同外界条件下的感知特性,提高了整个模型对低光照条件下的感知效率. 如图1所示,MDF-ANet模型框架大致可以分为3个模块:特征提取、特征融合和多尺度融合上采样. 两路特征提取子网络分别使用深度图和RGB图作为输入,并且在不同尺度的输出层上通过特征融合模块进行融合;为了进一步聚合高阶特征,在最后一个尺度特征层后接一个空间金字塔池化模块(spatial pyramid pooling,SPP)[7],最后将多个尺度的输出特征共同输入多尺度融合上采样模块,得到最后的分割图.
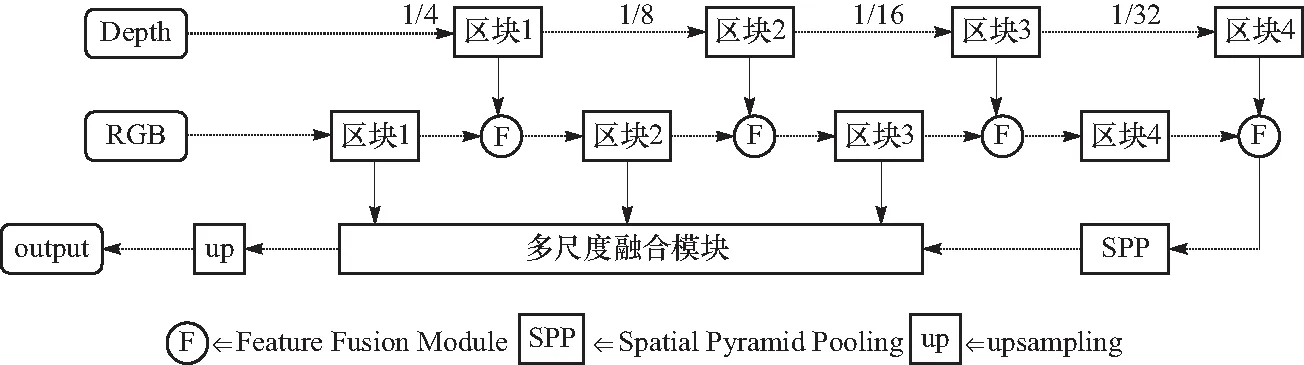
图1 整体网络结构示意图
1.1 特征提取模块
特征提取模块主要提取图像的纹理信息及空间信息,尤其是物体丰富的边缘信息,对图像分割具有很大的帮助. 但对于被动传感器相机来说,低光照情况下,会引入很多的噪声,不利于图像分割;但主动传感器激光雷达所得到的深度图几乎不受光照的影响,且测距误差小. 故本文设计了一个两路融合网络,一路处理相机数据RGB图像,另一路处理激光雷达得到的深度图像. 相机数据是一个三通道的RGB数据,而雷达数据是离散的空间点,对雷达点云的处理一般包括俯视图处理、直接点云输入和极坐标处理. 俯视图处理或是直接点云输入经过特征提取网络提取的特征层和RGB特征层属于不同视角,不能直接进行融合处理,大多进行目标检测框与框之间的后处理,不利于图像分割,故本文中使用极坐标处理,即空间点云经过坐标变换转换成前视图的深度图,便于进行后续的特征层融合.
本文中选用ResNet-18[14]作为RGB特征提取的基干网络,ResNet-18具有适当的深度和残差结构,兼具实时性和性能;因深度图和RGB图具有相同的特征视角,特征提取具有一定的相似性,故采用相同的特征提取网络,在相同特征尺度层通过特征融合模块进行特征融合.
1.2 特征融合模块
不同的传感器所含信息丰富度不同,比如RGB包含更多的色彩信息,更易于像素分类,而深度图包含更多的距离和空间信息,更易于不同目标之间像素分割. 且传感器数据有效信息质量会随着外界条件的不同而不同,比如低光照条件下,RGB数据中包含更多的噪声,有效信息减少,而深度图则不受光照的影响. 传统的特征层融合方式,即不同传感器特征层简单相加或是合并,相当于是平等使用不同源数据特征层,不能很好地利用不同数据在不同条件下的特性,提出使用注意力机制的特征融合模块[9],针对不同条件下,自动弱化不重要信息,加强有效互补的信息融合,特征融合模块网络结构如图2所示.

图2 基于注意力机制的特征融合模型
假定RGB输入特征层为X=[x1,x2,...,xC]∈C×H×W,深度图输入特征层为D=[d1,d2,...,dC]∈C×H×W,O∈C×H×W为融合后特征层,计算表达式为
O=(X⊗ca(X))⊗sa(X⊗ca(X))+
(D⊗ca(D))⊗sa(D⊗ca(D))
(1)
式中:⊗代表向量点乘;ca代表通道注意力模型;sa代表空间注意力模型.X和D分别经过各自的注意力机制模块后获得不同的权重值,然后与各自的特征层点乘加权,再相加融合,能够自动加强有效信息的融合.
1.2.1通道注意力机制
卷积神经网络的原理是通过采集图像局部感受野的空间和通道信息,并根据采集的信息提取包含不同信息的表征. 比如纹理信息和形状信息,每个卷积层包含多个滤波器,每个滤波器对输入特征的所有通道进行计算,学习表征不同的图像特征,如X=[x1,x2,...,xC]∈C×H×W就是由C个滤波器进行卷积计算过得到的C个H×W的特征图. 每个特征图包含的信息量不同,对图像分割的贡献程度也不同[15],应根据不同特征层的重要程度给予不同的计算权重,使网络偏向于输入信号中信息量较大的部分,本文中使用的通道注意力机制如图3所示.
首先将特征层经过全局的平均值池化和最大值池化,得到每个通道特征图的表征值,大小为C×1, 平均池化就是对特征层中每个特征图计算均值,公式为
(2)
式中:W,H分别代表特征图的宽和高;Im代表特征层中的第m个特征图,m∈(1,C);Am表征第m个特征图的平均值,A为一个大小为C×1的向量.
最大值池化就是对特征层中的每个特征图计算最大值,公式为
Mm=max(Im)
(3)
式中:Im代表特征层中的第m个特征图,m∈(1,C);Mm表征第m个特征图的最大值;M是一个大小为C×1的向量.
为了进一步学习不同特征图的权重同时减少计算量,使最大值池化层和平均值池化层接入一个共享层,共享层由一个通道减少的1×1卷积层、ReLU层和一个通道增加至初始通道数的1×1卷积层组成,能够使模型充分地学习不同特征图的权重,并在一定程度上防止过拟合现象. 最后将两路的特征进行相加,得到一个C×1向量,然后输入sigmoid函数得到不同通道的权重,限定权重为在0~1之间的浮点数,计算过程为
ca(X)=sigmoid(φ(φ1(X))+φ(φ2(X)))
(4)
式中:φ表示共享层网络;φ1,φ2分别表示均值池化和最大值池化操作.
1.2.2空间注意力机制
当看一个场景或是一副图像时,会自动聚焦于场景中的关键位置,对重要位置给予更多关注. 空间注意力机制就是仿照人类视觉的注意力机制[16]设计的. 其通过自动学习图像中的不同位置特征信息并分配不同权重,突出关键信息,忽略不重要信息,利用有限的注意力从大幅图像中提取出高价值信息,本文中空间注意力机制如图4所示.
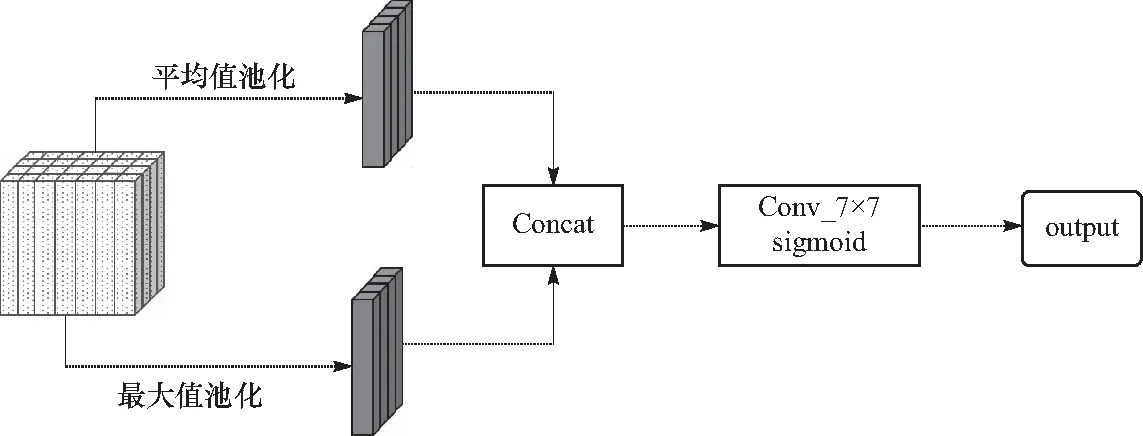
图4 空间注意力机制
首先将特征层在通道维度上进行平均值池化和最大值池化,得到特征图上每个位置的表征值,大小为H×W,平均池化就是对特征图中多个通道特征计算均值,公式为
(5)
式中:C,W,H分别代表特征层的通道数、宽和高;Ik代表特征层中的第k个特征图,k∈(1,C);IA(i,j)表示在通道维度上进行平均池化输出特征图的第i行j列的值,IA是一个大小为H×W的特征图.
通道维度上的最大值池化就是对特征图中多个通道特征计算最大值,公式为
IM(i,j)=max([I1(i,j),I2(i,j),…,IC(i,j)])
(6)
IM表示通道维度上最大池化的输出特征图,是一个大小为H×W的矩阵.
再将最大值池化和平均值池化输出图在通道上进行合并,然后输入一个7×7卷积层和sigmoid函数得到不同通道的权重,限定权重为在0~1之间的浮点数,计算过程为
sp(X)=sigmoid(φsp([ω1(X),ω2(X)]))
(7)
式中:φsp表示卷积网络层;ω1,ω2分别表示均值池化和最大值池化操作.
1.3 多尺度融合上采样模块
语义分割是对图像中的像素进行类别预测,小而细的物体通常在高分辨率特征层得到很好的预测,大结构的物体通常在低分辨率特征层才能够进行正确的识别,因为在缩小图像尺寸时,网络才能更好地观测到大物体的上下文信息. 如图5所示,本文引入一种多尺度融合上采样模块的方法以解决上述问题[17].

图5 多尺度融合的上采样模块
首先对低分辨率特征层scale 1/32进行双线性插值的上采样操作变成和其上一尺度scale 1/16同样大小的特征层,然后与其上一尺度特征层一起进入Attn模块,通过注意力机制使网络学习一个相邻尺度之间的相关权重,两个相邻尺度的特征层分别点乘相应的权重图,再相加作为此次融合的输出;进一步作为此尺度下的输出与scale 1/8的特征层合并输入Attn模块,进行相同的操作. 基于注意力机制的多尺度融合上采样模块能够更好地结合互补性的多尺度特征信息,有效地提高图像分割性能.
Attn模块结构图如图6所示. 两路输入进入模块后,先进行通道的级联拼接,然后通过一个3×3的卷积网络、BN、RLU,再接一个1×1卷积网络,能够进一步探索通道之间的相关性,最后通过一个sigmoid函数,约束权重在0~1之间.

图6 Attn模块结构
2 实验
2.1 实验设置
本文中实验框架采用Pytorch1.5、CUDA10.2、CUDNN7.6,2080Ti显卡. 训练时对输入数据进行裁剪、随机水平翻转、随机0.5~2倍的放大缩小等数据增强操作,采用ResNet-18作为基干网络,并使用ResNet-18在ImageNet上的训练结果作为预训练权重,加快模型训练. 本文采用语义分割领域常用的Cityscapes[18]数据集进行实验. Cityscapes[18]数据集是一个城市街道数据库,其中包含相机RGB图像和视差图,通过相应的相机参数计算得到其深度图进行实验,其中包括常见的精细语义标注的19类目标,2 795张训练图像、500张验证图像数据和1 525张测试图像,图像原始大小为2 0481 024. 本文目标是提出一种适用于低光照图像分割的语义分割方法,但就目前所知,还没有纯粹的包含低光照或是夜晚图像及其相应深度图的数据集,因此本文把Cityscapes训练集和验证集图像调整为256256,并通过图像转换的方法CycleGAN[11]及其训练权重[19]生成大小为256256的低光照图像,称为Small-dark-cityscapes数据集,包括2 795张训练集、500张验证集数据.
2.2 实验结果与分析
为了验证本文方法的有效性,本文基于Cityscapes及Small-dark-cityscapes数据集不同实验设置的实验结果如表1所示,实验将Cityscapes和Small-dark-cityscapes训练集划分训练数据和验证数据,将Cityscapes和Small-dark-cityscapes验证集作为测试数据. RGB-day 表示只用正常光照RGB图像作为模型输入,如大多数现存文献方法一样,只考虑了白天正常光照情况下的图像分割,可作为本实验的比较基准,在Cityscapes验证集上达到63.57%mIOU. MDF-ANet-no-night代表本文所提出的方法,采用白天正常光照条件下的RGB图和深度图作为输入,与RGB-day做对比,达到了67.10% mIOU,体现了使用RGB和深度图融合的本文方法的有效性. RGB*Depth、RGB + Depth分别代表使用特征层通道上拼接、特征层相加的融合方式进行特征层融合,和MDF-ANet-no-night方法结果相比较,说明了本文提出的基于注意力机制融合的方法具有一定的优势.

表1 Cityscapes及Small-dark-cityscapes验证集上不同实验设置的实验结果
为了进一步体现本文方法对低光照图像的分割效果,表1中展示了不同方法对Small-dark-cityscapes验证集的分割效果,RGB-night 表示只使用生成的低光照的RGB进行训练和验证,达到了41.0%mIOU的效果,说明低光照情况下,亮度不足,造成RGB数据有效信息丢失,网络无法提取到足够的有效特征进行像素分割. RGB-day-night表示同时使用正常光照和低光照条件下的RGB数据进行训练,并只在低光照图像上进行验证,达到了45.18%的mIOU,说明扩展训练数据范围,在一定程度上能够提高模型精度. MDF-ANet表示本文方法使用正常光照和低光照条件下的RGB数据及其深度图进行训练,在Small-dark-cityscapes验证集达到59.80%的mIOU, 相比前两种方法mIOU分别提高了18.8%, 14.62%,充分证明了本文方法的有效性. 为了综合体现本文方法的分割性能,表1中展示了不同方法对Cityscapes+Small-dark-cityscapes验证集的分割结果. 在全部验证集上,本文方法MDF-ANet相对于RGB-day、RGB-day-night,在mIOU和精准度上分别取得了明显的提高,再一次说明了在各种不可测的外部环境下,多模态数据融合模型是进行场景分割识别的趋势,能够进行信息互补,使模型具有较高的稳定性.
图7展示了本文分割算法的示例结果,每行代表一个数据样本,从左至右依次为输入数据RGB图、深度图、标注图像和预测结果图. 第一行为白天数据样本,可以看到本文算法对细长的柱形物体也能预测出来,对较小的目标具有很好的识别度. 第二、三行为通过生成网络生成的低光照图像样本,在RGB图像中几乎看不清的目标,如行人、柱子,在其深度图中具有明显的形态信息,可以很好地观测出来,本文分割算法同时输入RGB图和深度图,对两种数据源特征图进行互补性融合,达到能够在低光照条件下识别目标的目的,具有很好的鲁棒性.

图7 本文分割算法的示例结果图
3 结 论
针对低光照情况下图像亮度不足,信息丢失,语义分割性能降低的问题,本文提出了一个新的融合RGB和深度图的语义分割网络:首先,分别使用RGB和深度图作为融合网络两路分支特征提取子网络的输入;然后,在每个输出尺度上通过特征融合模块进行特征融合;最后,将特征图通过多尺度融合上采样模块,进行不同感受野的充分特征融合后得到分割结果. 在Cityscapes数据集实验及自己生成的低光照数据集上进行了验证,相比较只使用RGB输入的模型,性能提高了9.1%,在NVIDIA 2080Ti显卡上达到了35 fps. 在下一步的研究中,探索更加有效的融合方式以达到缩小模型参数量的同时提高模型效果的目标.
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
中国机械工程(2022年8期)2022-05-09 12:32:02
软件导刊(2022年3期)2022-03-25 04:45:04
中国机械工程(2021年8期)2021-05-07 05:49:10
计算机应用(2019年3期)2019-07-31 12:14:01
音乐教育与创作(2019年8期)2019-05-16 04:06:34
计算机技术与发展(2019年1期)2019-01-21 00:56:38
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
