
基于改进SSD的视频行人目标检测*
2022-01-21 00:34赵九霄李国燕
传感器与微系统 2022年1期
赵九霄, 刘 毅, 李国燕
(天津城建大学 计算机与信息工程学院,天津 300384)
0 引 言
视频监控已经成为生活中不可或缺的一部分,其重点应用于驾驶辅助系统、安检等方面。行人检测作为视频监控中的关键组成部分,其研究目的是在复杂场景下准确并且快速检测出行人目标。现阶段行人检测特征提取方法主要分为传统的基于人工设计的特征提取方法和基于神经网络的特征提取方法。
传统目标检测方法[1,2]对浅层特征描述较好,对数据量较少的数据集具有良好的分辨能力,但对于数据量较多的数据集则显示出计算能力的不足,且存在着不能体现深层次特征的问题。基于神经网络方法[3]可以为视频行人检测提供较为深层次的特征,并且可以应对数据集带来的计算量过大的问题,但却没有解决帧与帧之间运动信息联系的问题。
为了解决上述问题,Kang K等人[4]提出了一种基于静止图像的行人检测框架,结合时间信息来规范检测结果。随着递归神经网络(recurrent neural network,RNN)在视觉和序列学习[5]、目标跟踪[6]、目标识别[7]方面的成功应用,文献[8]为了解决当输入图像为长序列时RNN体系结构精度退化的问题,将可以产生高精度的长短期记忆(long short-term memory,LSTM)网络引入到模型中,该方法具有较高的精度。Liu M等人[9]创建了一个交织的递归卷积体系结构,并提出了一个有效的瓶颈层,与常规LSTM相比,可以提高运算效率。文献[10]提出了一种ConvLSTM结构,并利用它建立了端到端的可训练模型。Karpathy A等人[11]提出了一种用自然语言描述生成图像的模型,构建了一种多形态递归神经网络体系结构。可见目前的研究中还存在着计算量较大、准确率低且不能充分的解决跨帧的运动信息联系问题。
本文提出了一种基于改进SSD的视频行人目标检测方法。首先,改进经典的SSD(single shot multibox detector),将基础网络VGG—16(visual geometry group network—16)替换为改进的MobileNet网络,并使用区域化密集连接,可以在避免梯度消失的同时增加网络的运算效率。其次,将GRU(gate recurrent unit)与改进的SSD框架结合。GRU单元的反馈连接和门控机制使模型能记忆空间依赖关系,并选择性地传播相关运动信息,将上下帧的运动信息反馈给检测网络以提升检测准确率,并减少运算量。
1 图像数据预处理
1.1 图像增强
灰度世界算法[12]是基于灰度世界假设的,灰度世界算法在物理上假设自然界物体光的平均反射值通常是一个固定值,它近似于灰色。采用色彩平衡方法将该假设应用于训练集中的图像,可以从图像中消除环境光的影响,从而达到增强图像的效果。
1.2 样本标注
本文选用的数据集来源于道路流量视频,一共切分为3 120 帧连续图像。为更好地发挥检测框架的性能优势,将训练集中的图像转换为VOC2012格式,训练集图像的长度被重新缩放到500个像素,并相应地调整宽度,以保持原始的纵横比,因为需要检测的对象只有行人,所以类别为1。
1.3 样本扩增
通过对训练样本旋转来实现数据扩增。旋转包括水平旋转、垂直旋转、镜像旋转,旋转的角度范围为+30°~-30°,并对新增样本进行筛选,去除劣质样本。
1.4 数据集的制作
在经过对图像数据的预处理之后,得到的数据如表1所示,分为三类。第一类是原始图像训练集,第二类是经过图像增强后的训练集,第三类是经过样本扩增后的训练集。

表1 训练集数量
2 改进的SSD行人目标检测框架
2.1 SSD模型
Liu W等人[13]提出SSD是一种快速高效的目标检测方法,这种检测算法是在YOLO(you only look once)和Faster R-CNN的研究基础上衍生而来。SSD框架分为两部分,第一部分是由经典模型VGG—16[14]组成的特征提取部分,第二部分是由四层卷积层构成的多尺度特征检测部分。
SSD框架结构图如图1所示。在Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2和Conv11_2特征层的每一个单元中按照不同长宽比分别提取4~6个默认框。

图1 SSD框架结构
SSD的损失函数包括两部分,第一部分是对应搜索框的位置(loc)损失,第二部分是类别置信度(Conf)损失
(1)
(2)
(3)
式中c为置信度,l为预测框,g为真框,loc为位置损失,Conf为置信度损失,a为分类和回归的误差权重,N为匹配到默认框的数量。
2.2 基础网络及改进
传统的SSD使用VGG—16作为基础特征提取网络,但其存在着计算量较大的问题。通过将改进的MobileNet作为SSD的基础特征提取网络来解决以上问题。
为了在有限性能的硬件条件下提高效率,开发了轻量网络MobileNet[15]。MobileNet[15]可以通过减少参数,达到减少计算量的目的,并且不以牺牲精度为代价。图2表明MobileNet是由可深度分离卷积构成的,它包括深度层(Depthwise)和点向层(Pointwise)。Depthwise是使用3×3卷积核的深卷积层,而Pointwise是使用1×1卷积核的卷积层,每个卷积结果均采用批量归一化算法和线性整流函数(rectified linear unit,ReLU)进行处理。

图2 标准卷积与深度可分离卷积对比
在输入输出图像尺寸不发生变化的情况下,传统卷积核的计算量C1为
C1=Dk×Dk×M×N×DF×DF
(4)
式中DF为输入与输出特征图的宽度与高度,M为输入特征图的通道数,N为输出特征图的通道数,Dk为卷积核的长和宽。相比之下,深度可分离卷积的总计算量C2为
C2=Dk×Dk×M×DF×DF+M×N×DF×DF
(5)
(6)

针对MobileNet网络特征传递较弱以及梯度消失的问题,将密集连接加入到MobileNet网络中。原理是将网络中的所有层连接,并将前面所有层的特征映射连接,一方面可以缓解梯度消失,另一方面可以把每一层的特征图依次传递给下一层,该方式不仅可以增强特征的传递,也可以在一定程度上减少参数量,从而减少运算量。
如图3所示,将池化层之前的所有层分为三个区域,采用密集连接方式连接。通过该方法将所有层的特征映射连接起来,第一个区域的输入为Input的输出,第二个区域的输入为第一个区域的输出,第三个区域的输入为第一、二个区域的输出组合,该区域的卷积运算结果为第一、二、三区域的输出组合,图4为改进后SSD框架。

图3 改进后的区域密集连接结构
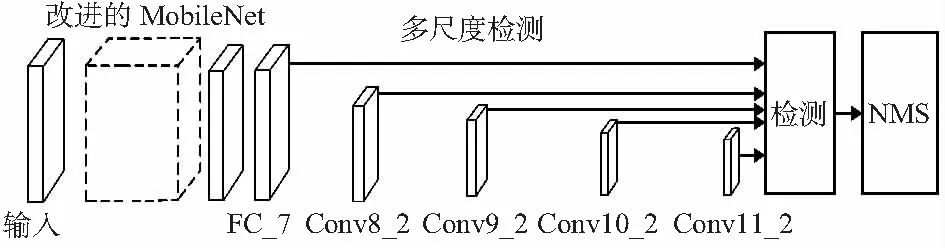
图4 改进后SSD框架结构
2.3 GRU辅助单元
人类的思想具有连贯性,但神经网络并不具备这种连贯性,更无法将帧与帧之间的运动信息逐层传递,因此,将GRU引入到检测框架中。
2.3.1 输入端
使用的GRU架构可以从输入帧获取到空间结构。选择改进的SSD作为前端检测行人的框架,并将检测的结果保留为c+4的位置类别得分向量。具体来说,向量是由c个对象类别分数和4个位置参数组成。
除了位置—分数向量外,因为需要检测一些远距离小目标,因此,选用ROI Pooling为每个检测到的对象提取了一个固定大小的描述符。选用Conv6,Conv7,Conv8层以及FC层的特征映射,利用这四个层产生的特征映射作为ROI Pooling层,并将输出框集中到这些特征映射上,以计算固定大小的特征描述符。每个检测到的盒子都是从几个层中得到的,以产生一个固定长度的s×s特征描述符。将输出的参数设置为7,除了最后输出的特征描述符的大小为7×7之外,还添加了一个归一化过程,使不同尺度的特征位于同一个单位球上。
将不同对象的位置、类别分数向量以及特征描述符向量分别连接成二维N×D的帧级张量,其中D=(c+4)+(s×s),它是每个检测对象的复合特征长度,并取当前帧N个对象来形成帧级向量。
为了利用过去的帧,使GRU能够选择性地记住什么是有用的预测,需要将当前的帧级张量与T-1帧向后叠加,得到一个具有T×N×D大小的叠加张量输入,得到的帧级向量将被输入到GRU体系结构中。
2.3.2 输出端
给定帧T中,x∈Rπ×N×D,使用关联GRU输出具有相同大小的改进预测x。其中,只考虑当前帧Y的预测,当前帧Y由n个对象预测组成,假设帧中的地面真实对象在数量上不超过n,可以用零向量进行填充,以保持所有输出对象预测数值的不变。每个对象预测包括三个项,分别为通过四维表示的对象位置、类别分数c和s×s大小的关联特征。SSD与GRU的结合如图5所示。
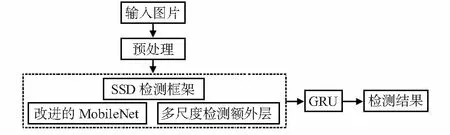
图5 改进后SSD与GRU结合框架
改进方法可以解决给定输入张量的对象回归和对象关联问题。回归类别分数和对象位置是从GRU的每个时间步长中得到的,并且这些时间步长处于隐藏状态。而关联特征是在连续的两个时间步长之间计算的。每个帧中的隐藏状态完全取决于网络的当前输入情况及其在时间t-1中的隐藏状态。总体算法流程如图6所示。
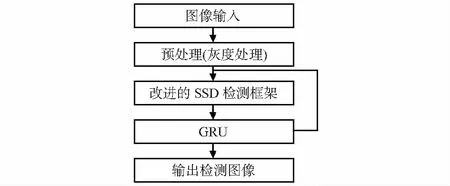
图6 检测算法流程
3 模型的训练与测试
3.1 实验平台
训练采用的CPU为Intel®CoreTMi7—7700HQ CPU(内含GPU),内存为32G,操作系统为Microsoft Windows 10,训练需要安装Tensorflow2.0,OpenCV,Python3.6.6等。
3.2 参数设置
为了优化调参过程以及快速选取纠正误差项的最佳值。实验使用非极大值抑制(non-maximum suppression,NMS)方法,如果超过某一阈值则被视为同一对象,分数最低的一个将被删除,用式(7)计算IOU(intersection over union),B1和B2表示两个包围框
(7)
通常NMS中的阈值设置为0.3,但这里将阈值设置为0.1。使用较低值的原因是,当创建可用作评估数据的集成数据时,会存在坐标位移问题。因此,将正确的集合包围框设置为公共包围框的平均值,并将所有实验中经过非极大值抑制留下的候选区域数量设置为100(默认设置为300),其他设置保持不变,后续所有测试和训练都在以上设置的基础上进行。对于GRU,模型学习率为0.003,最终的训练次数为1 500次。
3.3 视频行人检测网络训练
采用基于Tensorflow2.0版本进行训练。图7改进SSD框架对第132帧的检测结果。

图7 网络训练检测结果
由图7可以看出,在类别为人的前提下,检测的准确度都达到了80 %以上,检测结果充分说明了方法的可行性。
表2为与目前各种主流的四种检测算法速度对比。可以看出,改进SSD方法耗费训练时间较少,所需硬件成本较低,使用普通电脑配置(酷睿i7,16 GB内存,Tensorflow2.0),使用的视频行人目标数据集,训练一步所需时间仅为5 s左右,总训练时长为8h左右。相比之下,Faster—R—CNN,YOLO等传统检测方法的单步训练时长较长,因此,所用方法在低性能设备上也可以进行训练。相比传统检测模型,改进SSD方法可以减少训练时间,同时对设备的性能需求较低,非常适合于城市道路行人目标识别。

表2 四种不同方法检测速度比较
需要识别的种类只有行人,因此无需考虑其他类别,该方法使用的数据集标准均为VOC2012。由表3可以看出,改进后的SSD方法的检测准确率高于经典的YOLO,SSD等检测算法。
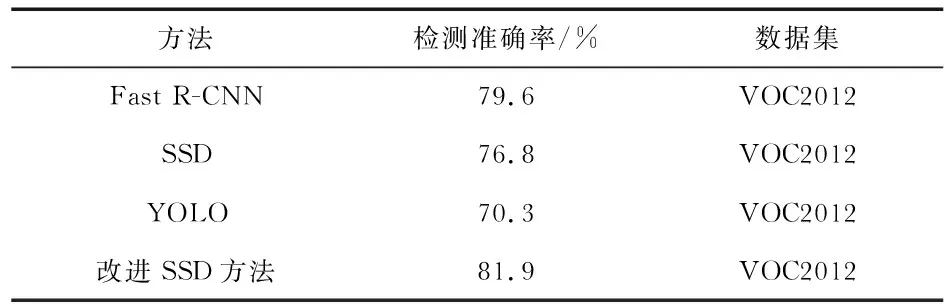
表3 四种不同方法检测精度比较
4 结束语
通过替换SSD基础特征提取网络VGG—16为改进的MobileNet,以及将GRU与检测框架相结合,使改进后的模型更适合于检测视频行人目标。同时,在建立帧与帧之间的关联性的同时减少了训练参数。改进后的SSD检测框架在准确率提升以及检测速度提高方面优于经典的检测算法,实验验证了该方法的有效性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
现代职业教育·职业培训(2019年12期)2019-02-03
小天使·一年级语数英综合(2017年6期)2017-06-07
