
基于知识图谱嵌入的多跳中文知识问答方法
2022-01-21 12:53张天杭李婷婷张永刚
吉林大学学报(理学版) 2022年1期
张天杭, 李婷婷, 张永刚
(吉林大学 计算机科学与技术学院, 符号计算与知识工程教育部重点实验室, 长春 130012)
知识图谱(knowledge graph, KB)作为一种结构化的语义知识库, 以其灵活的组成结构和丰富的语义表示能力, 已成为人工智能应用的重要基础. 典型的知识图谱是一个以实体作为节点, 实体间关系作为边的图结构知识库. 目前已有一些成熟的大规模知识图谱, 如Wikidata和DBPedia[1], 在中文领域也有如CN-DBPedia[2]的大规模知识图谱. 知识图谱规模的扩大为知识图谱的应用奠定了基础, 知识图谱问答(knowledge-based question answering)是知识图谱的重要应用方向之一[3]. 知识图谱问答方法旨在对用户输入的自然语言问题进行分析处理与理解, 并在知识图谱上展开推理和搜索, 将搜索结果作为答案输出给用户, 答案通常为知识图谱中的一个或多个实体节点.
目前主流的知识图谱问答方法分为两类: 基于语义解析方法和基于答案排序方法. 基于语义解析方法的主要思路是采用语义分析器将自然语言问题转化为可执行语义表示, 通过语义表示完成知识图谱查询. 语义表示通常是一种逻辑表达式, 典型方法有λ-DCS[4]、 带类型的lambda表达式[5]等, 这类方法通常需要人工标注的“问题-逻辑表达式”数据, 成本巨大. 随着知识图谱规模的迅速扩大, 该方法的发展受到限制. 基于答案排序方法是将问答任务视为一个信息检索任务, 对知识库中的候选实体进行评分和排序, 选择得分最高的实体或实体集合作为答案输出. Yao等[6]基于人工设计的特征向量, 训练二分类器完成答案的评分和筛选. 随着深度学习的发展, 主流的研究方法开始采用神经网络对自然语言问题和知识图谱进行表示学习, 基于学习到的向量表示完成对候选答案的筛选和评分. Bordes等[7]提出了学习问题和实体在低维空间的嵌入向量, 并计算向量相似度完成对候选答案的打分; Saxena等[8]基于知识图谱嵌入方法, 使句向量嵌入模型学习知识图谱嵌入中的关系向量表示, 并采用知识图谱嵌入模型的评分函数对候选答案进行评分, 有效缓解了知识图谱稀疏性带来的性能损失. 知识图谱嵌入是目前热门的研究方向, 随着深度学习的发展, 近年来不断提出新的嵌入模型. Bordes等[9]提出了一种平移距离模型TransE, 学习实体和关系在低维空间中的平移不变性, 并在一些相关问题上证明了知识图谱嵌入的有效性; Nickel等[10]提出了RESCAL语义评分模型, 模型对三元组事实的潜在语义进行建模, 从语义角度完成知识图谱的嵌入表示.
当前主流的基于知识图谱嵌入的问答方法仅使用单一的评分机制, 对候选实体进行评分和排序后, 将得分最高的单一实体作为答案输出, 在面对多答案实体时可能会出现遗漏答案的情况. 这类方法虽然可以利用知识图谱嵌入时学习到的语义信息, 但没有显式地构建知识图谱查询. 本文提出一种改进的基于知识图谱嵌入的多跳中文知识问答方法MHCKBQA, 在答案评分部分引入关系链路评分机制, 在得到最优答案实体时输出相同关系链路上的所有候选实体, 从而有效解决了答案遗漏的问题, 并提升了基于知识图谱嵌入问答方法的鲁棒性. 在问题嵌入模型中, 本文针对中文知识问答领域改进句向量的嵌入方式, 使模型能更好地理解中文语义.
1 MHCKBQA中文知识图谱问答方法
常见的知识图谱问答任务分为单跳问题和多跳问题. 单跳问题是指应用知识库中单条事实即可进行回答的问题; 多跳问题是指需要两条或两条以上事实共同作为回答依据的问题. 图1为几种问题的区别. 目前的一些研究方法在单跳问题的回答上准确率已较高, 但在多跳问题的问答上仍存在许多困难和挑战[11], 这些挑战主要为: 1) 由于多跳问题相对于单跳问题具有更高的语义复杂度, 因此模型难以从问题句子中准确地分离出多重语义关系; 2) 真实的知识图谱具有稀疏性, 经常会缺失某些实体间的关系, 以图1中的问题3为例, 若(〈鲁迅〉,中文名,〈周树人〉)这一事实的关系链接在知识库中缺失, 则现有方法很难搜索到真实答案. 目前的一些知识图谱嵌入方法能有效地捕获知识库中潜在的语义关系, 且对缺失的链路具有较好的预测能力, 所以本文以知识图谱嵌入模型为主体提出一种多跳中文知识问答方法MHCKBQA.

图1 单跳和多跳知识问答示例Fig.1 Examples of single-hop and multi-hop knowledge question answering
本文对知识图谱定义为: 给定实体集合E与关系集合R, 一个知识图谱KG可表示为一个三元组集合, 即KG⊆E×R×E.对于KG中任意三元组t, 可表示为一个有序对(h,r,t), 其中h,t∈E且r∈R, 通常称h为头实体,t为尾实体. 在此基础上, 将MHCKBQA的任务定义为: 已知知识图谱KG⊆E×R×E, 给定一个自然语言问题qi与该问题的中心实体h, 其中h∈E, 问答方法的作用是给出答案实体集合Ai⊆E, 对于∀a∈Ai是问题qi合理的答案实体.
MHCKBQA的整体流程可分为两部分, 如图2所示, 分别为基于知识图谱嵌入的答案评分部分和链路评分及答案筛选部分. 基于知识图谱嵌入的多跳中文知识问答方法流程步骤如下:
1) 对于输入问题q及其头实体hq, 通过查询预训练得到的嵌入向量表得到ehq;
2) 通过句向量嵌入模型计算得到问题q的嵌入向量wq;
3) 对于所有候选答案a计算知识图谱嵌入评分
其中ea可通过查询嵌入向量表获得;
4) 对进一步缩小范围的候选答案a, 计算链路评分SR(R(hq,a),q);
5) 通过符合评分选出最优答案实体
6) 基于abest构建查询链路, 得到答案集合A, 根据hq和abest是否连通有如下查询方法:
①hq和abest连通时,A=SPARQL(h,R(hq,abest));
②hq和abest不连通时,A={abest};
7) 将集合A作为方法计算结果返回.

图2 MHCKBQA整体流程Fig.2 Overall process of multi-hop Chinese knowledge graph question answering
1.1 知识问答中的知识图谱嵌入
1.1.1 知识图谱嵌入
典型的知识图谱嵌入方法分为两部分: 一是定义实体和关系在向量空间(通常为d或d)中的表示形式; 二是给出在该表示形式下一个三元组的评分函数ftriple(h,r,t).评分函数的主要作用是评价三元组的合理性, 在该前提下, 嵌入模型可根据评分函数的类型分为距离转移模型和语义评分模型, 前者将事实的合理性视为向量间的距离, 后者是评价实体间的潜在语义关系.
在基于知识图谱嵌入的答案评分中, 将评分过程视为一个链路预测问题, 希望通过问题嵌入模块去学习问题句子中包含的多跳关系语义, 将“问题-答案”合理性的评价与嵌入模型中的三元组评分相结合.文献[12]研究表明, ComplEx方法对复杂的潜在语义关系具有优秀的建模能力, 且模型预训练算法的时间复杂度较低(O(d)), 适合大规模知识图谱的嵌入, 所以本文选用ComplEx嵌入方法.
1.1.2 ComplEx嵌入方法
ComplEx嵌入方法将实数空间中的语义嵌入扩展到虚数空间中, 给定一个头实体与尾实体h,t∈E和关系r∈R, ComplEx根据评分函数(1)学习虚数空间中的向量表示eh,et,wr∈d.在嵌入模型中, 所有被认为合理的三元组有Φ(r,s,t)>0, 所有被认为不合理的三元组有Φ(r,s,t)<0, 且
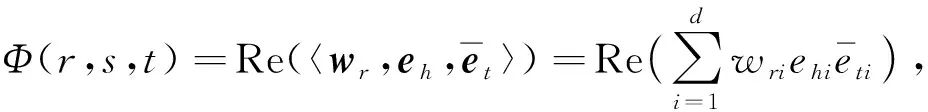
(1)
1.2 基于知识图谱嵌入的答案评分
答案选择模块中占主导地位的是基于知识图谱嵌入的答案评分, 本文采用一个改进问题嵌入模型得到句向量wq, 结合相关实体的嵌入向量ehq和ea, 通过评分函数计算得到该部分的答案评分, 该评分函数由基于ComplEx方法的评分函数改进而得.
1.2.1 问题嵌入
问题嵌入模块的主要任务是将自然语言组成的问题句子q嵌入到一个复数空间中, 得到一个句向量wq∈d.在一些英文问答方法中, 获得句向量的典型方法是在BERT[13]预训练语言模型的基础上针对下游任务进行微调. BERT预训练模型是将文本作为一个标记序列进行处理, 以响应最小的文本单元, 英文的文本单元是以空格区分的单词, 中文的文本单元是单个汉字字符. 但从语言学角度, 中文中词粒度的文本单元会携带比字粒度更多的语义信息, BERT的处理方式显然会损失句子中的语义信息. 在本文方法中, 采用中文预训练语言模型ZEN[14]对问句进行处理, 该模型融入了N-gram词汇表进行表示增强, 更大程度地保留了中文句子的语义信息. 问题嵌入模型的整体结构如图3所示.

图3 基于ZEN的问题嵌入Fig.3 Question embedding based on ZEN
由图3可见, 网络利用ZEN模型将问题q嵌入到一个768维的向量中, 再经过4个全连接层, 最后映射到复数空间d中. 学习的根据是利用ComplEx中的语义评分函数, 用句向量wq近似拟合关系向量wr, 得到多跳关系的复合语义表征.给定一个问题q及其头实体hq, 有参考答案集合Cq, 网络基于

(2)

(3)
定义的标准进行学习, 损失函数为交叉熵损失函数.
1.2.2 评分函数
在进行答案推理时, 通过问题嵌入得到句向量wq, 同时已知头实体和候选答案实体的嵌入向量ehq和ea, 模型可以对每个候选答案计算出答案评分Sa(a,h,q), 计算公式为

(4)
式(4)中答案评分函数和三元组评分函数在形式上一致, 这是模型能充分利用到知识图谱嵌入中无监督信息的主要原因.为缩减候选答案范围, 可给出评分阈值Sth, 仅选取评分高于阈值的答案作为链路评分的候选答案集合.
1.3 链路评分及答案筛选
与构建查询方法不同, 基于知识图谱嵌入方法得到的答案不依赖于查询路径, 该方法的优点是对于稀疏的知识图谱具有链路预测能力, 在查询路径缺失的情况下仍然能使正确答案具有较高的得分, 缺点是模型的鲁棒性较差. 该缺点主要体现在以下两方面:
1) 知识图谱问答的优势之一是知识图谱中存在的关系路径具有更高的可信度与可解释性, 单纯地利用知识图谱嵌入进行答案评分会弱化该优势;
2) 真实答案集合通常由同一条查询链路上的多个实体组合而成, 知识图谱嵌入评分很难得到准确的答案集合.
为克服上述缺点, 本文在基于知识图谱嵌入评分的基础上引入链路评分机制, 以增强该方法的鲁棒性.
1.3.1 链路评分
问题q的头实体hq和答案实体a之间的查询链路R(hq,a)由一个关系序列(r1,r2,…,rn)组成, 为度量关系与问题之间的相关性, 本文基于

(5)
构建一个网络学习相关性的度量评分Sr(ri,q), 并以此给出链路评分SR(R(hq,a),q).其中wri为知识图谱嵌入中的关系向量, ZEN(·)为中文预训练语言模型,σ(·)为激活函数, 在本文方法中为Sigmoid函数. 由此可针对头实体hq和答案实体a之间是否连通这两种不同情况给出不同链路评分函数.
当头实体hq和答案实体a之间存在最优连通链路R(hq,a)时, 链路评分函数为

(6)
当头实体hq和答案实体a之间不存在连通链路时, 链路评分函数为

(7)
其中φa是指单跳可达答案实体a的关系集合.式(6)的意义是给可能存在链路缺失的答案实体一个评分补足项, 用于消除偏差, 当知识图谱较稠密时该项可设为0.
1.3.2 答案筛选
为处理多答案实体的情况, 本文在答案筛选中引入同链路查询机制:
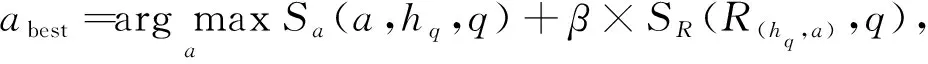
(8)
首先根据知识图谱嵌入评分和链路评分对答案实体进行复合评分, 排序后给出最优答案实体, 其中β是一个超参数.
当头实体hq和最优答案实体abest之间存在最优连通链路R(hq,abest)时, 答案集合A为
A=SPARQL(h,R(hq,abest)),
(9)
其中SPARQA(h,R)表示基于头实体h经关系序列R进行一次图数据库查询得到的实体集合.当头实体hq和最优答案实体abest之间不存在连通链路时, 答案集合A为
A={abest}.
(10)
从而可得在给定问题q和头实体hq时对应的答案集合A.
2 实验结果与分析
2.1 数据集与知识图谱
在单跳问答任务上, NLPCC-ICCPOL-2016 KBQA任务中提供了一个包含14 609个问答对的训练集和一个包含9 870个问答对的测试集. 该数据集不包含MHCKBQA训练时需要的查询路径, 所以本文利用NLPCC官方提供的实体消歧数据集对数据进行二次标注, 通过反向查询的方法构建了每个问题的查询关系路径. 在多跳问答任务上, 实验选用文献[15]中在NLPCC数据集上通过问句扩充的方式构建的NLPCC-MH数据集, 其中包含一个具有4 000个问答对的训练集和一个具有1 000个问答对的测试集, 数据集包含经过标注的查询路径, 但人工校验发现数据集中有少量明显的标注错误, 本文实验对此进行了校正.
在NLPCC-ICCPOL-2016 KBQA任务中提供一个具有4 306万条三元组的通用知识图谱, 为便于实验, 本文将其限制为通用知识图谱的子集, 对于NLPCC-ICCPOL-2016 KBQA任务, 构建一个具有433 819条三元组的知识图谱, 对于NLPCC-MH任务, 构建一个具有173 483条三元组的知识图谱.
2.2 评测指标
本文使用平均F1值作为评测指标度量知识问答方法的性能, 表示为

(11)
其中Q为测试集中整体的问题集合,Ci为测试集中给出问题qi的标准答案集合,Ai为问答方法对于问题qi给出的答案集合.
2.3 实验结果
将本文方法与文献[16]中基于键值对记忆网络的知识问答方法KV-KB进行对比, 后者是知识图谱问答的一个经典方法. 此外, 在NLPCC-KBQA的单跳知识问答任务上, 将本文方法与文献[17]中基于LSTM的知识库自动问答(LSTM-based)方法进行对比, 为确保对比实验的公平性, 假设已经完成了实体链接任务, 仅选用对比方法中的答案选择模块进行对比. 在NLPCC-MH任务上, 将本文方法与Seq2Seq[18]方法进行比较. 为验证引入知识图谱嵌入模型后, 问答方法在知识图谱较稀疏时的链路预测能力, 实验通过随机丢弃25%的三元组方法生成了不完整的知识库, 并在不完整知识库上进行实验.
在NLPCC单跳知识问答数据集上的实验结果表明, 当β=0.5时, 本文方法性能较好, 实验结果列于表1. 在NLPCC-MH多跳知识问答数据集上的实验结果列于表2, 在该实验中β=0.3.

表1 不同方法在NLPCC-KBQA数据集上单跳知识问答实验结果对比

表2 不同方法在NLPCC-MH数据集上多跳知识问答实验结果对比
2.4 结果分析
在单跳问答任务上, MHCKBQA方法在完整数据集下的平均F1值接近针对单跳中文知识问答设计的基于LSTM的自动问答方法, 尤其是在知识图谱不完整的情况下, MHCKBQA方法仍然保持了较高的平均F1值, 说明本文方法具有较好的链路预测性能. 在多跳问答任务上, MHCKBQA方法在完整和不完整的知识图谱上都取得了3个方法中最佳的F1值. Seq2Seq方法在知识图谱较稀疏的情况下不能预测出可靠的关系序列, 而MHCKBQA方法仍然具有较好的链路预测能力. KV-KB方法在两个任务上均弱于MHCKBQA方法, 说明该方法在训练集中问答对数量较少且知识图谱较复杂的情况下没有充分学习到答案预测能力.
由实验结果可见, MHCKBQA方法因为链路评分机制的引入, 能更好地避免遗漏答案的情况, 对F1值有提升作用, 也更符合人们对问答方法的预期效果; 且通过知识图谱嵌入模型, 可利用知识图谱中潜在的语义信息, 这种语义信息使方法的答案评分机制具有一定的链路预测能力, 在稀疏的知识图谱下方法也能保持较好的性能. 而知识图谱的稀疏性恰是真实世界中知识图谱的重要特征, 所以MHCKBQA方法在真实的知识库上具有较好的问答性能.
在实验过程中本文提出了一些提升MHCKBQA方法推理速度的优化策略:
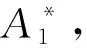
2) 搜索头实体hq与答案实体a之间最优链路的操作较消耗时间, 可以在搜索最优连通路径时指定最大深度Depthmax, 超过该深度时停止搜索, 归为二者不连通的情况.
综上所述, 本文基于知识图谱嵌入的多跳中文知识问答方法MHCKBQA在进行答案评分时, 创新性地结合了知识图谱嵌入评分算法与链路评分算法, 通过复合评分构建了一个具有高可信度的查询路径, 有效解决了当前基于知识图谱嵌入问答方法中遗漏答案的现象. 针对中文语境, 该方法选用基于ZEN改进的中文句向量嵌入模型拟合复杂语义关系, 对多跳问答任务的语义理解更准确. 同时因为知识图谱嵌入的引入, 使问答方法具有一定的链路预测能力, 在不完备的知识图谱上MHCKBQA方法仍然具有较强的推理能力. 本文问答方法在NLPCC-KBQA和NLPCC-MH两个数据集上性能较好, 尤其是在多跳问答任务上和知识图谱稀疏的情况, MHCKBQA方法与对比方法相比具有明显优势.
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
移动通信(2021年5期)2021-10-25
新城乡(2018年6期)2018-07-09
科技创新导报(2016年27期)2017-03-14
长江学术(2015年1期)2015-02-27
中国报道(2009年12期)2009-01-15
