
基于卷积神经网络的卫星遥感图像拼接
2022-01-21 12:40王永军初剑峰
吉林大学学报(理学版) 2022年1期
刘 通, 胡 亮, 王永军, 初剑峰
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 长春市公安局 网安支队, 长春 130051)
卫星遥感技术广泛应用于军事侦察、 地表分析和资源勘察等领域. 在卫星遥感图像的处理过程中, 由于单幅图像的视角有限, 因此常需要将两幅或多幅图像进行拼接以获取更宽广视野的图像. 遥感影像拼接也称为影像镶嵌, 是指对两幅或两幅以上含有重叠区域的图片, 将相同部分交叠在一起, 而其他部分保持不变, 从而合并成一幅整体图片. 卫星遥感影像拼接的关键在于: 1) 如何使计算机识别出不同遥感图像中的相同部分; 2) 在拍摄过程中, 由于相机的移动不能做到完全稳定, 两幅图片的相同区域也会存在平移、 缩放、 扭曲变形等问题, 因此需要对图片进行调整, 使对应部分达到理想效果.
目前主流的卫星遥感图像拼接方法是以尺度不变特征转换(scale-invariant feature transform, SIFT)为代表的传统经典算法[1-4], 该方法基于尺度不变性, 包括图像配准和几何变换两部分. 图像配准是指在每幅图像中检测出特征关键点及其局部特征描述子[5], 以此实现图像中特征点的匹配; 几何变换是指对图像进行一定的变形, 使对应特征点在最大程度上达到重合. 以SIFT为代表的传统方法在一定程度上对图像匹配进行了较好的实现, 但该方法也存在不足. 如果遥感影像来自不同视角的卫星, 而视角差别又较大时, 图像中的物体可能会发生较大形变. 在这种情况下, 传统方法通常不能获得正确的拼接效果. 近年来, 随着人工智能与深度学习的发展, 深度学习在计算机视觉应用方面取得了优异的成绩[6]. 因此本文考虑通过引入深度学习实现卫星遥感图像拼接.
本文采用卷积神经网络(convolutional neural network, CNN)模型[7]代替SIFT经典方法实现图像配准与几何变换, 设计一种卷积神经网络模型, 并通过人工合成图像对的方法生成适用于它的训练数据集. 该模型可以端到端地进行训练以学习图像配准的能力, 并取代SIFT方法估计出图像的几何变换参数. 相比于传统方法, 卷积神经网络模型对发生较大形变的卫星遥感图像具有更好的拼接效果.
1 预备知识
1.1 卫星遥感图像拼接传统方法
目前通常采用SIFT算法及其改进算法进行卫星遥感图像的拼接, 如加速鲁棒性特征(speeded up robust features, SURF)算法, 这些算法的原理基本一致, 拼接方法一般分为图像配准和几何变换两部分.
1) 图像配准: 选择一种特征检测器(如SIFT特征检测器), 通过特征检测器可从一幅图像中提取出关键点(标准局部特征). 首先, 将特征检测器分别作用于要匹配的两幅图像, 提取出两幅图像各自的关键点集; 其次, 分别对两个关键点集计算描述子——选择同类型的描述子提取器(如SIFT描述子提取器), 由此获得两幅图像各自关键点集对应的局部描述子; 然后选择一种匹配器, 通过将两幅图各自的描述子集合输入匹配器, 得到一组初步的试探性匹配结果; 最后对初步匹配结果进行筛选, 只保留高质量的匹配, 删除低质量的匹配, 并按照匹配程度由高到低排序.
2) 几何变换: 即通过旋转和平移使两幅图像的对应特征点达到重合. 通过两幅图像中相对应的特征关键点, 找出两幅图像相同部分的几何变换参数(如Homography矩阵), 一般采用的方法是随机抽样一致性(random sample consensus, RANSAC)算法或Hough投票法[8].
利用经典方法实现的卫星遥感图像拼接效果一般较好, 但也有失效或出现较大误差的情况, 通常是由于图像中主体对象的外观描绘发生了较大变化. 遥感影像常来自不同视角的卫星, 当视角存在较大差异时, 图像中的物体难免发生较大形变. 在这种情况下, 传统方法通常不能获得正确的拼接效果.
1.2 卷积神经网络
深度学习广泛应用于计算机视觉领域, 在行人检测[9]、 对象分类[10]、 图像分割[11]等领域都有优异表现. 深度学习已被用于学习功能强大的图像特征[12-14]. 相比于经典方法, 深度学习对外观变化具有更高的鲁棒性[15]. 卷积神经网络在深度学习领域应用广泛, 其具有可实现提取特征、 降维、 加速、 减少运算、 提高泛化能力和包容形变等诸多优点, 相比全连接网络运算量小很多, 因此可用卷积神经网络提取图像特征. 本文采用深度学习的方法, 设计一种卷积神经网络模型并进行训练, 代替经典方法实现对卫星遥感图像的拼接.
2 模型设计
2.1 网络架构设计
英国牛津大学视觉几何组(visual geometry group, VGG)提出了一种经典的卷积神经网络模型VGG-Net, 其是在ImageNet[16]上进行训练用于图像分类的卷积神经网络模型. VGG-Net使用5个卷积组, 一般有11~19层, VGG-Net模型的几种常见结构如图1所示. 其中具有16层的结构称为VGG-16模型, 它是VGG-Net的经典模型之一. VGG-16模型的5个卷积组层数分别是2,2,3,3,3, 共有13层卷积层. 数字16表示13层卷积层与3层全连接层, 不包括下采样层(即池化层).

图1 VGG-Net结构Fig.1 Structure of VGG-Net
在图1中, 每个卷积层后边的括号内都注明了该层所采用的卷积核大小与输出通道数. 例如, (3-64)表示采用的卷积核大小为3×3, 输出通道数为64. 图1第二列中11层结构出现的局部响应标准化(local response normalization, LRN)是一种用于防止数据过拟合的函数. 由于本文研究采用的是16层结构, 故不对LRN进行说明.
VGG-Net原本用于图像分类, 但其卷积层部分能很好地对图像特征进行提取. 与以AlexNet为代表的其他架构相比, VGG-Net的层数更多, 通道数也更多, 因此可达到更高和更细颗粒度的准确性, 可提取更多有效信息, 非常适合遥感卫星图像这类包含丰富细节的高分辨率图像.
本文参考VGG-16的架构设计神经网络. 在VGG-16的结构中, 全连接层部分对图像特征提取未发挥作用, 因此只需使用其卷积层部分即可. 考虑到权重因子过多会减慢计算速度, 因此本文未将13个卷积层全部使用, 而是权衡后截取到第10个卷积层. 在每组卷积层结束后都进行一次批量标准化, 此外还在全连接层前添加一个Dropout函数以防止过拟合.
2.2 回归网络设计
在回归网络结构设计上, 本文在最后添加两个全连接层, 第一层设置1 000个神经元接收卷积层的输出, 最后一层的神经元设置为8, 这是因为本文想得到的几何变换参数是由8个数构成的4×2矩阵. 这样设置的目的是将两幅卫星遥感图像拼接在一起, 使相同部分完全重合. 实际上, 仅通过移动几乎不可能使两幅图像的共同区域完全重合, 这是因为在获得不同图像时一定会有条件差异. 遥感图像可能来自于不同卫星, 导致两幅图像必然存在视角上的差异, 即使是由同一卫星获得的两幅图像, 由于拍摄时间、 拍摄角度、 拍摄距离远近等因素的变化, 也会使两幅卫星遥感图像的坐标系出现差异, 将导致图像中拍摄对象的形状发生一定的变化. 在这种情况下, 无法直接对卫星遥感图像完成拼接, 必须先对图像做几何变换, 将两幅遥感图像调整到同一坐标系下, 才能完成后续的图像拼接.
对于要进行匹配的两幅图像, 通过单应性矩阵可以将一幅图像中每个位置上的点映射到另一幅图像的对应位置上. 如果用IA和IB表示两幅图像, 则IA中位于(x,y,1)处的点通过单应性矩阵进行几何变换后将映射到IB中位于(x′,y′,1)处的点, 如图2所示.
单应性矩阵是一种常用的几何变换方法, 其一般形式是一个3×3矩阵, 表示为
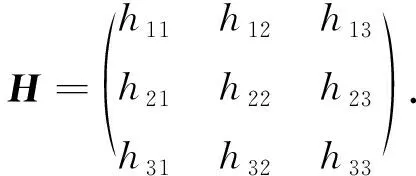
(1)
其能将一幅图像中每个位置(x,y)上的点映射到另一幅图像的对应位置(x′,y′)上, 表示为
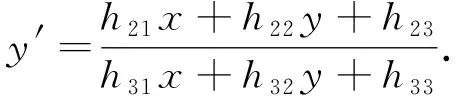
(2)
单应性矩阵除这种3×3矩阵的形式外, 还有一种4×2矩阵形式, 其为基于角点位置变化得到的[17], 如图3所示.将视角1得到的图像记为图A, 视角2得到的图像记为图B. 在这种情况下, 图A中四边形的4个角点映射为图B中的一个四边形.
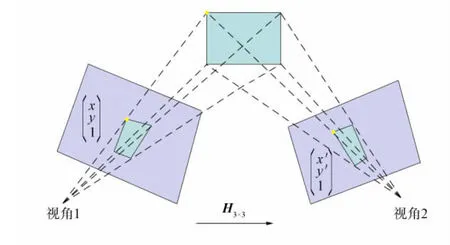
图2 同一对象在不同视角下的位置对应关系Fig.2 Position correspondence of same object in different perspectives

图3 4个角点在不同视角图像中的映射Fig.3 Mapping of four corner points in images from different perspectives

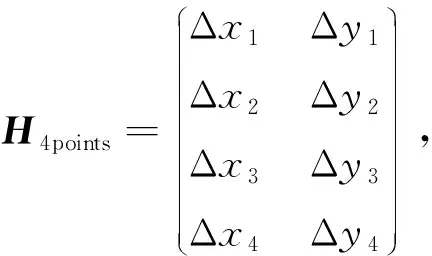
(3)

单应性矩阵的这两种形式是等效的, 一旦知道两幅图像中4个角点的偏移量, 即可将H4points转换为3×3的H矩阵.由于单应性矩阵的4×2形式表示的是4个角点的偏移量, 而通过偏移量可直观查看网络模型估计出的结果, 因此本文以4×2形式单应性矩阵的值作为模型的回归结果.
3 模型训练
3.1 损失函数
训练模型包含数据集与标签集.对于神经网络模型, 输入为一组图像IA和IB, 而输出为IA到IB的几何变换参数, 即单应性矩阵H.因此, 所需的数据集应该是由大量图像对构成的, 而数据对之间对应的单应性矩阵H已知, 实验中需要用矩阵H作为标签集.但在机器学习领域广泛采用的数据集中并没有这种形式的数据集.本文的方法是: 选择一个图片数据集, 使用随机生成的单应性矩阵H对数据集中的图片进行变换, 并将变换后的图像与原图像组成一对, 即得到了训练的特征值, 而随机生成的单应性矩阵则作为训练的真实标签值, 记为HGT.回归网络产生8个数字, 即模型估计出的8个偏移量, 将其与HGT中的8个数字进行比较, 计算它们的欧氏距离, 作为模型的损失函数.
欧氏距离是指m维空间中两个点之间的距离.以二维空间为例, 若点A为(x1,y1), 点B为(x2,y2), 则A,B两点间的欧氏距离计算公式为
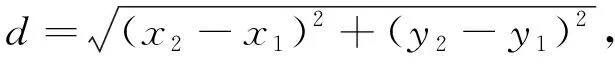
(4)
其中d表示二维空间中点A与点B之间的欧氏距离.若以三维空间为例, 点A为(x1,y1,z1), 点B为(x2,y2,z2), 则A,B两点间的欧氏距离计算公式为
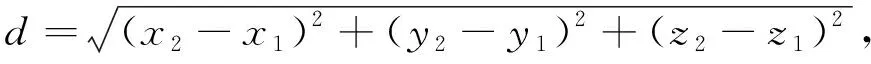
(5)
其中d表示三维空间中点A与点B之间的欧氏距离.推广到n维空间, 若点A为(p1,p2,…,pn), 点B为(q1,q2,…,qn), 则A,B两点间的欧氏距离计算公式为
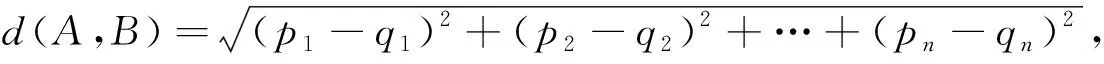
(6)
即

(7)
其中d(A,B)表示n维空间中点A与点B之间的欧氏距离.
本文设计的回归网络输出4×2形式单应性矩阵中的8个数字, 将其与真实单应性矩阵中的8个数字比较, 计算他们的欧氏距离作为损失函数. 模型通过使用反向传播和随机梯度下降(stochastic gradient descent, SGD)最大程度地减小损失函数, 以学习神经网络的权重.
3.2 训练数据
训练卷积神经网络模型通常需要大量数据, 但现有的公共数据集中符合实验要求的类型较少, 即以发生几何变换的一对图像作为特征, 以它们的几何变换关系作为标签. 因此, 需通过自行合成数据进行训练. 本文实验的方法是: 下载一个图像数据集, 然后对其中的图像数据做随机几何变换, 即在一定范围内随机生成一个单应性矩阵H, 并通过H将数据集中的原图像做几何变换, 将变换后的图像与原图像构成一个图像对, 作为训练的特征值, 而随机生成一个单应性矩阵H即为与其对应的特征值. 将该操作应用于下载图像数据集中的每张图像, 即得到了实验需要的整个数据集.
本文采用PASCAL VOC数据集, 对其图像进行处理后用于训练. PASCAL VOC原是一个用于目标检测和分割模型的数据集, 共包括14 961张JPG格式的图片. 事实上, 任何数量足够多的数据集都可使用这种合成数据集方法用于训练. 在尺寸大小满足要求的前提下, 可以将任意一张图像经过处理后作为训练样本, 通过该方法可以根据需要收集尽可能多的训练实例, 也可以在训练达到一定程度后更换新的图像数据集进行训练, 使模型更好地学习不同类型的图像特征, 甚至可以自行拍摄照片, 经过处理后的照片同样可以作为模型训练的数据集. 合成训练数据过程如下.
步骤1) 为减少计算量, 首先将图像转换为单通道灰度图. 参考VGG-16模型的输入要求, 实验中使用的并不是原始尺寸的图像, 而是在原图像上随机裁剪出一个224×224尺寸的正方形部分, 将该正方形部分的图像记为A, 将其作为训练输入特征的图像对之一.
步骤2) 记录下A的4个角点位置, 然后选定一个范围对4个角点进行随机位移, 本文设随机范围为[-56,56]. 通过4对点横纵坐标的8个偏移量, 可得到一个单应性矩阵H.该算法可通过OpenCV软件库中的getPerspectiveTransform( )实现.
步骤3) 求出矩阵H的逆矩阵H′, 然后将H′应用于原始尺寸的灰度图, 以产生几何变换后的新图像.在新图像中找到与矩形A相同的位置, 裁剪出一个与A尺寸相同的224×224的正方形部分, 将该正方形部分的图像记作B, 将其作为训练输入特征图像对中的另一个元素.
步骤4) 将两个224×224×1的正方形灰度图A和B堆叠, 生成一个224×224×2的图像, 将其作为输入卷积神经网络模型的特征值, 并将步骤2)中的8个偏移量作为训练的标签值.
由于本文实验设计的模型输入要求为224×224×2, 不同于VGG-16模型要求的224×224×3, 因此不能直接载入VGG-16模型训练好的权重, 而需要从头开始训练模型. 为减少训练中的计算量, 本文实验对模型做进一步修改, 在对图片进行卷积提升通道数过程中, 通道数达到128时保持这一通道数不变. 如果继续扩大通道数到256甚至512, 或许能使模型具有更好的学习能力, 但更大的计算量会使训练模型花费更多的时间. 本文最终设定128通道数, 而不再继续扩大. 经过调整后最终确定的模型结构如图4所示, 每个卷积层后都有一个ReLU激活函数(未标出).

图4 修改后的卷积神经网络架构Fig.4 Modified CNN architecture
本文实验选择Adam优化器对模型进行训练, 动量设为0.9, 学习速率设为0.005. 初步设定训练50 000轮, 每轮在训练集中随机选择5 000个样本进行训练, 每次批量传入50个样本. 50 000轮训练完毕后, 将学习速率减小为0.000 5, 再次训练50 000轮, 使模型最终达到收敛.
4 实 验
4.1 与SIFT拼接方法的对比
本文实验设计的模型实现了图像拼接的图像配准与几何变换, 即该模型具备了和传统SIFT方法同样的能力. 为检验训练后模型对图像的拼接效果, 将其与传统经典算法进行比较. 本文选择SIFT+RANSAC的经典算法进行比较, 以几何变换部分所得到的单应性矩阵的欧氏距离作为评价指标. 将随机生成的单应性矩阵作为真实值, 首先计算模型估计所得值与真实值的误差(计算结果保留4位小数), 再计算经典算法所得值与真实值的误差, 然后对两种方法所得误差进行对比. 为对两种方法做出综合性评价, 需在整个数据集上进行统计, 得出各自的平均误差.
对于经典算法, 计算误差值时选择3×3单应性矩阵比4×2单应性矩阵更方便. 因此为便于对比, 在计算误差值时, 先将模型估计值与真实值都转换为3×3单应性矩阵形式再计算欧氏距离. 这样可以更直观地对两种方法进行比较. 通过以3×3单应性矩阵的欧氏距离作为误差, 对整个PASCAL VOC数据集进行统计后可得: 模型估计的平均误差为61.060 4, 经典SIFT算法的平均误差为75.111 5. 因此, 本文模型的效果更好.
模型训练完毕后, 需要检验模型对图像的处理效果. 由于模型最终完成了图像配准与几何变换两个步骤, 因此不但可以通过误差值进行评价, 还可以直接从视觉效果上进行对比观察. 为验证模型对不同图像的适用能力, 选用不同于训练数据集的其他数据集进行实验.
选取dogs-vs-cats数据集进行检验. 从数据集中随机抽取一幅图片, 并随机生成一个单应性矩阵H以对其做几何变换, 组成一对图像. 分别用CNN模型与传统SIFT方法计算这对匹配图像的几何变换参数, 即单应性矩阵. 将CNN模型得到的单应性矩阵记为Hcnn, 将传统SIFT算法得到的单应性矩阵记为Hsift. 不同算法在dogs-vs-cats数据集上的几何变换效果如图5所示, 其中: 图5(A)为随机抽取的原始图像, 其中方框部分即本文随机选定的区域, 随机移动它的4个角点可得真实单应性矩阵HGT; 图5(B)为通过真实单应性矩阵HGT对原始图像选定区域做几何变换后的效果, 它使原图发生了扭曲; 图5(C)为用CNN模型对图像对做匹配, 预测得到单应性矩阵Hcnn, 通过Hcnn对原始图像选定区域做几何变换后的效果; 图5(D)为用SIFT方法对图像对做匹配, 计算得到单应性矩阵Hsift, 通过Hsift对原始图像选定区域做几何变换后的效果.

图5 不同算法在dogs-vs-cats数据集上的几何变换效果Fig.5 Geometric transformation effects of different algorithms on dogs-vs-cats data set
由图5可见, 与图5(B)的真实变换效果相比, 本文方法图像与其更接近. 即使不借助计算得出的误差数值, 仅凭视觉观察也可见图5(C)与图5(B)的差异更小, 两幅图方框内的区域基本一致, 而图5(D)中方框的右下角已经扩大到了边界外. 图5(C)计算得到的欧氏距离误差为7.785 3, 图5(D)图像计算得到的欧氏距离误差为31.290 7, 对比可知, 本文图像的误差更小, 卷积神经网络模型得到的单应性矩阵Hcnn与真实值HGT更接近.
为实验的严谨性, 本文在数据集上进行了多次测试, 模型预测的效果普遍强于传统SIFT方法. 测试结果如图6~图8所示. 图6为在dogs-vs-cats数据集上随机抽取3张图像进行测试的结果. 此外, 为验证模型对不同图像的适应能力, 分别在COCO2017数据集和ImageNet ILSVRC2012数据集上进行测试, 每个数据集随机选择3张图片进行测试, 测试结果如图7和图8所示.

图6 不同算法在dogs-vs-cats数据集上3次测试的几何变换效果Fig.6 Geometric transformation effects of different algorithms are tested three times on dogs-vs-cats data set

由图6~图8可见, 相比于SIFT方法, CNN模型实现的几何变换效果与真实几何变换效果更接近, 其欧氏距离误差值也普遍小于SIFT方法, 与视觉观感一致. 在ImageNet ILSVRC2012数据集的第三个示例中, 即图8的最后一组图像中观察到: 此时SIFT方法所得结果的误差在数值上其实略小于CNN模型所得结果的误差——CNN模型的欧氏距离误差值为30.535 3, 而SIFT方法的欧氏距离误差值只有29.375 7, 但在视觉效果上可明显看出, 仍然是第三列图像与第二列的真实结果更接近, 即CNN模型比SIFT方法得到的效果更好. 这是因为本文是通过比较3×3形式的单应性矩阵的欧氏距离计算误差的, 因此需要比较9对数字. 当通过预测或计算得到的矩阵中的大部分数值与真实矩阵数值非常接近, 但有单一或少量数值偏差较大时, 就会导致数值偏差较小而视觉上形状差异更大的情况. 因此欧氏距离应该作为衡量误差参考的一个相对标准而不是绝对标准, 还应该对比视觉效果做综合性的评价. 同时从这种特殊情况也可知, 当SIFT方法的欧氏距离误差接近甚至低于CNN模型时, CNN模型依然能得到更好的综合效果.
仍以3×3单应性矩阵的欧氏距离作为误差, 分别在dogs-vs-cats测试集、 COCO2017测试集和ImageNet ILSVRC2012验证集上统计两种方法的平均误差进行对比. 在dogs-vs-cats测试集上, CNN模型估计的平均误差为63.247 3, 经典SIFT算法的平均误差为74.709 3; 在COCO2017测试集上, CNN模型估计的平均误差为61.690 7, 经典SIFT算法的平均误差为74.957 7; 在ImageNet ILSVRC2012验证集上, CNN模型估计的平均误差为61.622 6, 经典SIFT算法的平均误差为75.201 7. 因此, 在这几个数据集上得到的数据较稳定, 与之前在训练集上的所得结果基本一致, 波动较小. 说明CNN模型的平均误差稳定小于SIFT方法的平均误差, CNN模型能更好地实现图像配准和几何变换, 即对图像具有更好的拼接能力.
4.2 卫星遥感图像拼接实际效果
本文实验使用卷积神经网络模型代替传统SIFT方法实现卫星遥感图像拼接, 克服了传统算法不适用于较大形变的缺点. 下面通过一组视角差异较大的卫星遥感图像进行测试, 分别使用这两种方法对其进行拼接, 对比它们的拼接效果. 图9为一组来自不同视角的卫星遥感图像, 分别用CNN模型和传统SIFT方法对这两幅图像进行拼接, 拼接效果如图10所示. 由图10可见, CNN模型明显优于传统SIFT方法. CNN模型实现了遥感图像拼接, 而传统的SIFT方法出现了明显的错误, 右侧上方的深色道路与中间扇形建筑物的边缘都出现了两次. 实验中多次选取来自不同视角的卫星遥感图像进行拼接测试, CNN模型均优于SIFT方法的图像拼接能力. 因此, 相比于经典方法, 卷积神经网络模型对外观变化具有更高的健壮性, 在图像发生较大形变的条件下也能取得较好的拼接效果.

综上所述, 在卫星遥感图像的拼接技术中, 传统方法存在不适用于在不同视角下发生较大形变图像的缺点. 为解决该问题, 本文采用深度学习方法代替传统方法, 实现了该条件下的卫星遥感图像拼接. 设计了一种端到端的卷积神经网络架构, 其可通过训练学习图像间的特征与对应关系, 实现图像配准并得到单应性矩阵, 完成图像的拼接. 由于模型的训练过程不依赖于传统方法中对图像特征点和描述子的提取, 而是以卷积提取的特征图作为图像特征, 因此能较好改善形变较大时特征提取不准确的情况. 对比实验结果表明, 卷积神经网络模型相比于传统方法对卫星遥感图像拼接能力更好.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
读与写·教育教学版(2017年10期)2017-11-10
软件(2017年6期)2017-09-23
南都周刊(2015年4期)2015-09-10
