
基于GA-SVM模型的虹膜质量评估方法
2022-01-21 12:29吴祖慷朱晓冬刘元宁王超群周智勇
吉林大学学报(理学版) 2022年1期
吴祖慷, 朱晓冬, 刘元宁, 王超群, 周智勇
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012; 3. 吉林大学 软件学院, 长春 130012)
近年来, 人们对信息安全的需求日益增加, 生物信息识别技术凭借高精度等突出优势正逐步取代传统身份认证方法, 虹膜识别技术更是由于高识别率和可靠性而得到广泛关注. 虹膜识别过程主要包括图像采集、 预处理、 特征提取和特征识别4个模块. 获取图像的质量优劣直接影响系统的识别效果, 所以在处理虹膜图像前设置虹膜图像的质量评价步骤十分必要[1].
Daugman[2]通过计算整幅图像的二维Fourier频谱中的高频能量判断虹膜图像的清晰度; Wildes[3]利用虹膜外边缘处的灰度变化值评价图像粗糙程度; 陈戟等[4]使用基于小波包分解的方法评判虹膜图像纹理质量. 在评价指标融合方面, Aditya等[5]采用累加计算评估因素的方法进行图像多方位质量测评; Gao[6]提出了粗-精评价指标相结合的方法, 并利用支持向量机(support vector machine, SVM)对指标进行融合得到分类结果; 晁静静等[7]利用GA-BP(genetic algorithm-back proagation)神经网对多指标进行融合完成对虹膜图像的综合评价.
为提高虹膜图像质量评价方法的准确性, 本文结合ISO/IEC 27974-6: 2015[8]国际虹膜图像质量评价参考指标, 首先提出基于图像处理的虹膜图像活性检测方法, 然后利用清晰度评价指标对虹膜图像进行初步筛选, 最后利用离心度、 瞳孔放缩度、 瞳孔有效区域、 虹膜圆环区域清晰度4个评价指标, 结合SVM对指标进行有效融合, 并利用遗传算法(GA)对模型进行参数优化. 通过GA-SVM模型对图像的质量评价结果进行训练, 预测虹膜图像的综合评估分数, 本文方法的框架如图1所示.

图1 本文方法框架Fig.1 Framework of proposed method
1 虹膜图像质量评价指标
1.1 虹膜活体检测
为杜绝伪造和盗取他人的生物信息用于身份识别, 在质量评价前, 通常需要判定输入的虹膜图像是否具有活性. 目前的经典方法有利用瞳孔收缩反应[9]、 基于神经网络二分类、 透镜接触方法、 动作指令检测、 光场成像[10]等. 本文利用图像处理中图像减法运算完成对序列虹膜图像的动态检测, 对序列相邻两幅图像灰度值分量相减, 得到目标的动态表达. 选取某类虹膜序列图像8张, 若相邻图像间发生动态变化, 则同一人在不同波段的图像便会呈现图像间的差别, 如图2前7张序列相邻图像的动态表达; 相反, 通过伪造等不具有活性的虹膜图像通常不会呈现图像的动态性, 如图2最后一张图片. 表1列出了序列图像瞳孔参数的变化, 由表1瞳孔坐标(x,y)和半径参数r的变化可知, 序列图像是活性动态的.

表1 序列图像瞳孔参数的变化

图2 序列相邻图像的动态表达Fig.2 Dynamic expression of sequential adjacent images
1.2 整幅虹膜图像清晰度检测
首先对虹膜图像进行清晰度评价, 本文采用Laplace梯度法[11]. 设虹膜图像为M×N维, 利用二阶Laplace算子对原始虹膜图像进行卷积, 分别提取水平和竖直方向的梯度, 计算平均灰度值, 作为清晰度指标值Q1.图像越清晰,Q1值越大, 并对Q1值小于设定阈值W1的图像进行筛除, 根据不同类别数据分别选取阈值W1.清晰度评价指标计算公式为

(1)
其中Gx(x,y)和Gy(x,y)分别表示虹膜图像像素点f(x,y)和卷积模板作用的结果.本文同时利用DefRto失焦检测对Laplace梯度法进行补充, 得到失焦检测值DR, DR值越小表示图像失焦越严重, 对虹膜图像清晰度的评价结果如图3所示.

图3 同类不同样本虹膜图像的清晰度Fig.3 Definition of iris images of different samples in same class
1.3 虹膜斜眼和超边界检测
首先对图像进行开闭运算、 二值化、 Canny边缘检测等预处理, 得到一张噪声较少的虹膜图像; 再采用Hough圆检测方法完成对虹膜图像的定位分割, 并得到瞳孔圆心坐标、 半径和虹膜半径等参数; 最后通过橡皮圈模型对分割图像进行归一化处理, 调整归一化图像尺寸为512×64, 选取右上侧睫毛眼睑遮挡程度较小, 尺寸为256×32的ROI区域, 进行直方图均衡化[12]处理以增强图像纹理特征, 效果如图4所示.
在拍摄虹膜图像时, 会得到一些瞳孔偏移、 眼球翻转程度较大和超边界的图像, 这些图像通常会导致定位偏差和虹膜区域图像不完整. 本文采用一种离心度评价指标, 即计算瞳孔圆心到图像中心距离和图像半对角线长度的比值大小, 离心度值越大表明图像偏移程度越严重, 进而对有上述问题的虹膜图像进行筛选. 设离心度评价指标为L1, 计算公式为

(2)
其中Δd表示瞳孔中心到图像中心的距离,d表示图像对角半径, (x1,y1)表示图像中心点坐标, (xpupil,ypupil)表示瞳孔中心坐标.对虹膜图像的离心度评价结果如5所示.

图4 虹膜图像的定位、 分割、 归一化、 增强结果Fig.4 Localization, segmentation, normalization and enhancement results of iris images

图5 虹膜图像偏移度测试结果Fig.5 Results of deviation test of iris images
1.4 虹膜有效区域检测
1.4.1 瞳孔放缩检测
人眼瞳孔受到光强影响会产生缩放现象, 当瞳孔扩放程度较大时, 会减少虹膜的有效纹理信息量, 难以提取更多的虹膜特征.本文通过瞳孔放缩评价指标, 对瞳孔过分扩张的虹膜进行筛查.通过对虹膜图像进行定位处理, 得到瞳孔区域的半径值和虹膜外圆的半径值, 设瞳孔放缩评价指标为T1, 计算公式为

(3)
其中Spupil表示瞳孔区域面积,Siris表示虹膜区域面积,T1表示虹膜有效可用区域占比.T1值越大, 虹膜图像包含的特征信息越多, 越有利于特征提取和识别.对虹膜图像瞳孔放缩的评价结果如图6所示.

图6 虹膜图像瞳孔扩张、 收缩检测结果Fig.6 Pupil dilation and contraction detection results of iris images
1.4.2 瞳孔有效区域
本文采用的虹膜定位方法为同心圆检测, 因而瞳孔被睫毛、 眼睑遮挡程度会反应出虹膜图像的遮挡程度和有效区域面积.在定位阶段, 若瞳孔可见区域较小, 则Hough圆无法检测出瞳孔圆, 由此可筛除闭眼程度较大的虹膜图像. 对于其余闭眼情形, 本文提出一种瞳孔有效区域评价指标, 利用对虹膜图像瞳孔黑色素个数和瞳孔内圆面积的占比, 反映瞳孔的有效区域面积, 从而侧面反映虹膜有效区域占比程度, 筛除包含纹理特征较少的虹膜图像. 设瞳孔有效区域评价指标为T2, 计算公式为

(4)
其中Spupil表示表示瞳孔区域面积,Bpupil表示瞳孔区域黑色像素点个数, 得到评价结果如图7所示.

图7 虹膜图像瞳孔有效区域检测结果Fig.7 Pupil effective area detection results of iris images
1.5 虹膜圆环区域清晰度评价
虹膜图像的清晰评价是针对整幅虹膜图像进行的, 筛除的多数为由于移动和眨眼导致的运动模糊图像, 不能有效评判人眼部分离焦模糊.实际上, 对虹膜图像定位分割后得到的虹膜圆环区域纹理的清晰度更能表达虹膜图像质量的优劣.因此, 本文提出一种基于归一化虹膜区域图像和ROI区域的清晰度评价方法, 评价指标记为Qnor和Qroi, 评价方法同样利用Laplace梯度方法, 对归一化后的虹膜区域进行清晰度质量评价. 设虹膜圆环区域清晰度评价指标为
Q2=ω1×Qnor+ω2×Qroi,
其中ω1和ω2为Qnor和Qroi对应的权值, 评价结果如图8所示.

图8 虹膜圆环区域清晰度评价结果Fig.8 Evaluation results of definition of iris cirrus region
2 多指标融合的虹膜图像质量评价模型
2.1 指标融合方法
对图像质量特征进行融合, 就是构造一个关于特征和图像质量的映射模型[13].目前已有很多融合的分类方法, 如Bayes概率方法、 神经网络方法等, 但上述方法均存在参数较多、 易陷入局部最优等问题[14]. 而SVM具有小样本、 处理非线性能力强、 精度高等特点, 所以本文选用SVM作为指标融合分类器. SVM利用核函数将低维的输入空间数据通过非线性映射函数映射到高维特征空间, 将输入空间中线性不可分问题转化为特征空间中的线性可分问题; 输入要分类样本的特征向量矩阵, 同样本标签一起放入模型中训练, 输出分类结果. 但SVM仍存在许多问题, 如: 由于样本集数量对训练模型的泛型及适用性会产生影响, 因此如何选取合适的样本集; 如何选择适用样本特点的核函数; 如何确定最优的核函数参数以及平衡系数等. 为提高SVM分类精度及对参数进行有效优化, 本文选取具有全局择优能力强、 不易陷入局部最优解及自适应和自学习等优点的GA作为参数优化方法.
2.2 GA-SVM分类器
SVM分类器设计的关键是确定核函数. 高斯核通过比较样本间的相似度, 在一个刻画相似度的空间中, 使同类样本更好地聚集, 进而线性可分. 径向基核(radial basis function, RBF)作为高斯核最常用的一种, 在处理大部分问题时效果都不会出现较大偏差, 且RBF需要确定的参数比其他核函数少, 函数复杂程度更低, 因此本文选用RBF核函数.
优化SVM分类器的关键是确定惩罚系数C和核参数γ.惩罚系数C值越大, 对误分类的惩罚越大, 对训练集测试准确率高, 但泛化能力较弱;C值越小, 对误分类惩罚越小, 允许容错, 将其作为噪声点, 泛化能力较强.本文采用GA对SVM进行优化的算法流程如图9所示.
GA对SVM进行优化的算法主要步骤如下.
1) 数据标准化: 对训练样本数据和测试样本数据进行标准化处理, 消除量纲差异.
2) 编码和种群初始化: 对惩罚系数C和核参数γ编码, 随机生成初始化种群.
3) GA停止优化判断: 计算个体适应度, 并对种群进行选择、 交叉、 变异, 直至满足GA终止条件, 得到优化参数.
4) SVM分类精度判断: 将得到的优化参数应用到SVM分类器中进行实验测试, 判断是否符合期望精度, 若未达到, 则转步骤3).
5) 测试分类: 利用训练好的GA-SVM模型对测试集进行分类, 得到分类结果.

图9 基于GA选取最优参数流程Fig.9 Process of selecting optimal parameters based on GA
3 实验结果与分析
本文实验环境为CPU主频2.20 GHz, 内存4 GB, Win10操作系统, 编程工具为VS2010和Python 3.9.0. 实验选用吉林大学生物信息识别实验室自主采集的JLU-6.0虹膜库(http://www.jlucomputer.com/index/irislibrary/irislibrary.html)作为实验虹膜库, 包含103类图像, 左右双眼, 每类400张图像, 共计82 400张图像; 本文选取JLU-6.0虹膜库中50类图像, 每类包含100张图像, 共计5 000张虹膜图像. 其中通过清晰度指标初步筛除203张模糊图像, 将剩余的4 797张图像构成实验数据集IrisData, 并根据匹配结果对每个样本进行标记. 然后将IrisData按质量优劣分成三部分, 其中质量较好部分包含1 535张图像, 质量合格部分包含2 734张图像, 质量不合格部分包含528张图像. 质量较好是指通过计算综合质量分数评分较高且针对任何方法都能进行匹配的样本数据, 故本文重点研究剩余的两类图像. 通过对随机3类数据的测试, 将样本数据的训练集和测试集划分为(1/2)∶(1/2),(2/3)∶(1/3)和(3/4)∶(1/4), 利用分类器训练优化得到的平均分类准确率分别为94.594 6%,94.898 0%,93.243 2%. 表2列出了不同比例训练集和测试集的分类准确性. 参数测试如图10所示. 考虑到既要满足较高的准确性, 又要兼顾有足够的训练数据泛化模型, 因此本文从剩余3 262张质量合格和不合格图像中每部分随机挑选出2/3共2 175张图像作为训练集IrisData_Train, 剩余的1/3共1 087张图像作为测试集IrisData_Test.

图10 测试集∶训练集=(1/3)∶(2/3)时的参数测试结果Fig.10 Test results of parameters with a ratio of 1/3 test set to 2/3 training set

表2 不同比例训练集和测试集的分类准确性
3.1 评价指标提取和数据标准化
将离心度L1、 瞳孔放缩度T1、 瞳孔有效区域T2、 虹膜圆环区域清晰度Q2这4个测度评价指标经标准化处理, 将指标数据转化为[0,1]内的数, 以消除数量级差异较大导致的误差, 加速网络训练的收敛.数据标准化方法采用min-max法[15], 其函数形式为
w=(w-wmin)/(wmax-wmin),
(5)
其中wmax和wmin分别表示每类数据中得分最大和最小的指标值.将标准化后的评价指标分别作为样本向量的分量, 样本向量的表达式为
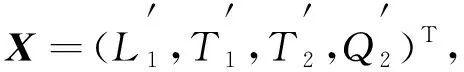
(6)
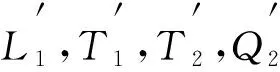
3.2 虹膜图像评估结果和模型效果分析
目前针对虹膜质量评价算法性能的优劣尚未统一标准, 但评价方法需达到一定的准确性[16-17].因此本文从评价指标的准确性和模型的分类准确性两方面进行测试.
3.2.1 与主观一致性的指标有效性分析
为验证本文提出指标的有效性, 针对上述指标, 从同一类400张虹膜图像中选取8张质量由低到高依次变化的样本, 编号为1~8, 根据多测度指标对相应虹膜图像样本进行评分.得到虹膜图像不同质量状态和各评价指标的关系如图11所示.由图11可见: 随着虹膜图像质量状态越来越好, 清晰度Q1、 虹膜圆环区域清晰度Q2指标值呈增长趋势, 且基于虹膜圆环区域评价相比于针对整幅图像评价更能反映虹膜图像清晰度的好坏程度, 如图11(A)所示. 瞳孔有效区域T2指标值越来越大, 离心度L1、 瞳孔放缩度T1值越来越小, 如图11(B)所示.因此, 实验结果与本文所述的各指标属性基本一致, 本文提出的各评价指标和主观评价具有一致性, 即本文提出的各评价指标是有效且准确的.

图11 与主观一致性的指标有效性分析结果Fig.11 Analysis results of effectiveness of indicators consistent with subjectivity
3.2.2 计算指标顺序对质量评价效率的影响
为降低评价因子的计算量, 在对虹膜图像计算评价指标值时, 考虑到指标值的计算依据对虹膜图像的定位等操作, 本文对各指标进行了因果关系分析和顺序调整, 分析结果如下.
1) 活体检测: 无前提, 直接对图像进行形态学处理.
2) 清晰度: 无前提, 直接对图像进行函数运算.
3) 离心度: 瞳孔定位, 得到瞳孔坐标和半径.
4) 瞳孔放缩度: 瞳孔定位, 虹膜定位, 得到瞳孔半径和虹膜半径.
5) 瞳孔有效区域: 瞳孔定位, 得到瞳孔半径.
6) 虹膜圆环区域清晰度: 瞳孔定位, 虹膜定位, 归一化, 截取图像.
通过上述指标依据的前提条件, 得到各指标的关系顺序: 1)→2)→5)→3)→4)→6), 对指标顺序进行调整, 得到调整前后(单张图像平均)的指标计算时间列于表3.由表3可见, 合理对评价因子的计算顺序进行调整可缩短评价时间, 并提高评价效率.

表3 调整前后指标计算时间的对比
3.2.3 GA-SVM模型分类准确性分析
通过训练集IrisData_Train对GA-SVM进行训练得到最优参数, 本文得C=1.87,γ=8.0; 根据GA-SVM训练模型对测试集IrisData_Test进行分类, 正确率达98.804 0%, 因此, 本文提出的GA-SVM质量评估分类模型能达到较好的正确分类率.
本文同时验证了SVM,BP,GA-BP方法对图像质量分类的准确性, 对比结果列于表4.

表4 不同方法对图像质量分类准确性的比较
3.2.4 质量评价模型对虹膜图像识别的影响
验证虹膜的识别率是检验图像质量评价对虹膜识别是否有效的唯一判别方法. 本文对通过各方法模型筛选出的图像进行识别, 验证本文评价模型筛选的图像更适用匹配认证. 对虹膜图像进行预处理, 本文采用Gabor算法对增强处理后的ROI区域进行特征提取, 并对比样本特征图像间的Hamming距离判断虹膜是否匹配, 结果如图12所示. 采用正确识别率(CRR)、 等错率(EER)指标对各方法进行测试, 结果列于表5.

图12 Hamming距离计算虹膜图像匹配Fig.12 Calculation of iris image matching based on Hamming distance

表5 不同方法对虹膜图像识别的正确率和等错率
综上所述, 为提高虹膜图像质量评价的准确性, 本文提出了一种基于GA-SVM模型的多测度虹膜图像质量评价方法, 针对虹膜图像质量评价中普遍存在的问题给出了较全面的解决方案. 实验结果表明, 该方法在主观评价一致性和与其他模型对比测试方面, 均得到了较准确的分类效果.
猜你喜欢
医院管理论坛(2022年8期)2022-10-14
中国典型病例大全(2022年11期)2022-05-13
科学与生活(2021年16期)2021-11-25
快乐作文(7.8年级)(2019年6期)2019-09-10
百科知识(2018年21期)2018-11-27
文萃报·周二版(2018年51期)2018-08-04
阅读与作文(初中版)(2017年6期)2017-07-05
求学·素材版(2016年12期)2017-01-03
恋爱婚姻家庭·养生版(2015年2期)2015-05-14
小学教学参考(综合)(2015年2期)2015-05-04
