
语义图驱动的面向复杂逻辑关系的自然语言问答
2022-01-20 02:57金季豪高大启刘旭利
中文信息学报 2021年12期
金季豪,阮 彤,高大启,叶 琪,刘旭利,薛 魁
(华东理工大学 信息科学与工程学院,上海 200237)
0 引言
自然语言问答是一种便捷的人机交互模式,机器将自然语言问句解析成计算机所能理解和执行的语言,并将答案返回。其中,基于知识库的问答(Knowledge Base Question Answering,KBQA)是给定一个自然语言的问题,生成知识库所能支持的查询语言,最后通过知识库查询出问题答案的过程。
传统的KBQA是基于互联网知识图谱的,特点是集中于事实性问题,表达相对比较简单,而知识库规模大且数据模式不确定。然而,随着知识图谱的普及,医疗领域也发布了大量的图谱数据。面向行业数据的KBQA的特点是数据规模和术语相对受限,但问题的复杂度会高很多,会有较多关联关系和统计需求。
知识库问答的主流方法可以分为四类: ①基于模板的方法[1-3],早期通过将问句解析成三元组,并与知识库中三元组进行相似度计算来得到答案。②基于语义解析的方法[4-7],将自然语言问句转化为逻辑形式,通过对逻辑形式进行自下而上的解析,得到一种可以表达整个句子含义的逻辑形式,并通过查询语句在知识库中查询得到答案。③基于信息抽取的方法[8],先在知识库中查询实体从而得到以实体节点为中心的知识库子图,子图中的点和边作为候选答案,通过规则和模板进行信息抽取,建立分类器对候选答案进行筛选从而得到答案。④基于端到端的方法[9-10],通过深度学习的方法,将自然语言问答看作一个序列到序列的任务,通过减少中间环节来提高最终准确率。
传统的方法大多面向比较简单的事实性问句,对于复杂的问句处理并不适用。然而,医疗领域中有大量复杂句式需要解析,诸如“被诊断为2型糖尿病后服用了瑞格列奈治疗的病人有哪些?”,句中隐含着2个医疗事件“诊断事件”“用药事件”及其时序关系。这样的复杂句比比皆是。对于基于模板的方法[11],当问题允许的复杂度变高时,可能的句式也会增多,模板构造数量太大。而对于语义解析的方法,当将原始语义改写为组合范畴文法时,对于语句不规范、不标准的情况,需要各种额外处理。而对于端到端的方法,由于可解释性比较弱,出现异常时修正会比较困难。
为此,本文面向复杂逻辑关系的自然语言问题,定义了语义图(Semantic Graph,SG)的表示形式,该形式可以看作是一种独立于语言的中间语义表示。在此基础上,形成了语义图驱动的自然语言问答框架(Semantic Graph Driven Question Answering,SGDQA),通过实体识别(Entity Recognition,ER)、实体对齐(Entity Alignment,EA),利用序列到序列(Sequence to Sequence,SS)模型得到语义图线性序列,最后通过槽填充(Slot Filing,SF)后在知识库中查询得到问题答案。此外,面向OpenKg公开的医疗领域图谱数据集(1)http://www.openkg.cn/dataset/peg,通过初始模板、基于语义图的扩充方法、在医疗知识图谱中查询得到实体与属性,构建了3 000个具有复杂逻辑关系的自然语言问题与答案。抽取1 800个问题进行训练,600个进行验证,600个测试,其中,基于注意力机制的序列到序列模型达到了97.67%准确率,启发式规则的槽填充达到了94.88%准确率,系统整体性能达到91.5%。
本文的贡献点如下: ①首先,面向领域中经常出现的事件以及事件之间的逻辑关系,构造了语义图中间表示方式,定义了主链、支链、环结构等各种图形化的结构以及结构的拼接。本文的语义图可以称为结构化语义图,与通用的图形化的语义表达方式有显著区别。②本文面向公开的医疗领域图谱数据集合,通过模板提取、语义扩充等方法,构建了3 000个具有复杂逻辑关系的自然语言问题与答案。③对于复杂自然语言问题,利用路径生成模型将自然语言问题翻译成语义图的线性序列。其中,基于注意力机制的序列到序列模型达到了97.67%的准确率。④提出了语义图驱动的问答框架并在医疗数据集上验证了框架和算法的有效性。框架包括实体识别、实体对齐、语义图线性序列生成等步骤,最后通过槽填充并查询出问题答案。启发式规则的槽填充达到了94.88%的准确率,系统整体性能达到91.5%。
1 相关工作
早期的知识库问答主要是采用模板匹配的方法。文献[1-3]通过把问句解析为三元组,用相似度计算的方法和知识库中的三元组进行匹配,进而得到答案。该方法的缺点是无法捕捉句子的完整语义,故而文献[12]提出了一种可以将问句映射到SPARQL[13]模板上的方法,该方法依赖句法语法信息,在映射句子内部含义的同时使用了统计的方法进行实体识别以实例化SPARQL模板。针对手工构建模板较困难的问题,文献[14]提出了模板自动生成的方法,使用变量来替换问句中的实体,再用问答语料有监督地训练问句-模板的映射模型[15]。
由于模板匹配的方法局限性较大,过份依赖模板,后来就有了基于语义解析的方法。通过定义简单的可再生的组合规则[4],通过组合范畴文法(Combinatory categorial grammar,CCG)产生逻辑表达式,并使用桥接提高语料的覆盖度。文献[16]通过重述问句并打分,获得与原问句最相匹配重述,然后建立原句、重述问句、答案的条件概率模型。
此外,还有基于信息抽取的方法,利用子图匹配的图搜索算法[17],将自然语言短语映射到知识库的前K谓词并生成短语词典,然后提出语义查询图来表达用户意图,并在知识库中找匹配子图。
近年来,有了基于端到端的方法,将自然语言问题看作是一个序列到序列的任务。文献[18-20]将知识库问答任务拆分为实体对齐、路径生成和答案生成三部分。为了优化路径生成从而提升系统整体性能,文献[9]补充了路径生成的验证过程。文献[10]将句子到逻辑表达式的转化问题看作机器翻译的过程,先定义问句的语义图与构建的动作序列,最后提出基于循环神经网络的序列到动作的解析模型。
2 方法描述
面对复杂逻辑关系的自然语言问题,本文首先设计了一个SGDQA的流程框架,如图1所示。首先定义了语义图的表现形式,并给出了语义图的线性编码算法,也就是图1中的offline过程,这部分在2.1节中将展开详细描述。图1中的自然语言问句由面向OpenKG公开的医疗领域图谱数据集合通过半自动构建的方法得到,一共构造了3 000条具有复杂逻辑关系的医疗自然语言问句,这部分在2.2节中进行描述。自然语言问句经过图1中的步骤3进行实体识别,得到移除实体信息的字符序列和预测的实体两部分,将预测的实体送去知识库中实体对齐,将字符序列通过路径生成模型得到语义图线性序列,这部分将在2.3节中阐述。最后,通过启发式的槽填充,查询得到问题的答案,图1中剩下的第6步和第7步在2.4节中进行说明。

图1 基于语义驱动的面向复杂逻辑关系的自然语言问答流程
2.1 语义图
在知识库的问答中,表述不同但是语义相同的句子最终会被解析为相同的结构化查询语言,如基于RDF[13]的图数据库Jena的SPARQL查询语言。所以,语义图可以转化为等价的图查询语言SPARQL。
2.1.1 语义图定义
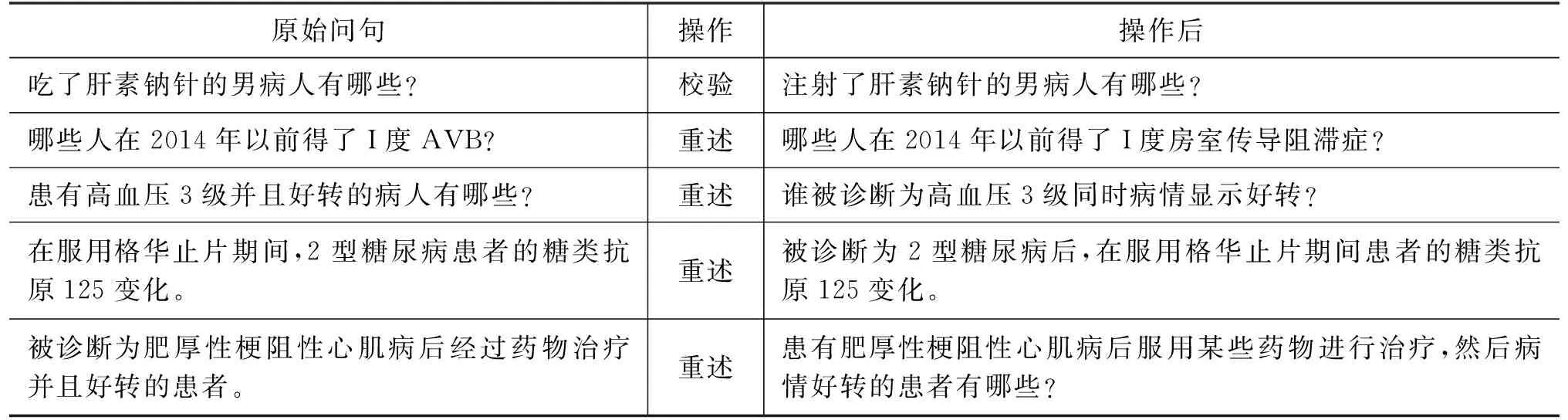
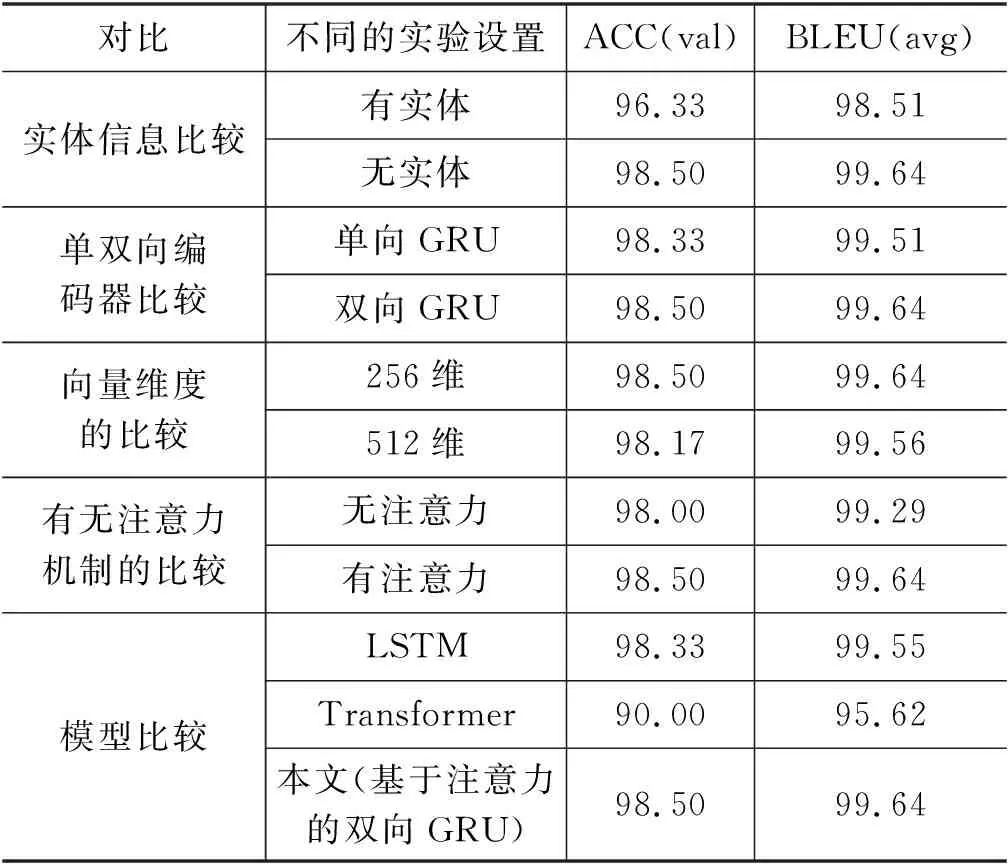
设G=(N,E),其中,G为语义图;N={n1,…,ni,…,nk}(0 任一语义图都可以用SPARQL语句来对应。本文通过对主链、支链、环结构的定义来实现语义图的拼接与扩展。图2展示了一个语义图到SPARQL转换的例子,自然语言问句是“哪些男性病人在诊断了高血压之后服用了硝苯地平控释片?”。其中,图2左半部分的“?诊断事件”、“?x”、“?治疗事件”代表变量;关系“参与主体”说明事件的参与对象是病人,“参与客体”则表示医疗事件的参与者是药品、手术等非生命实体。而图2的右半部分就是与左边语义图相对应的SPARQL语句伪代码。 本文的语义图比其他的语义图的设计元素多了事件的概念以及时序关系,并支持拼接扩展语义图。本文先通过语义图可拼接扩展的方式,在原有的初始集上面推荐扩展更为复杂的问句,生成医疗自然语言数据集。处理的句子包含多个事件与时序关系,用其他论文中语义图的方法无法解决本文的复杂逻辑关系的自然语言问答。 图2 语义图示例和对应的SPARQL查询语句 通过与其他文献中类似图结构的对比可以发现,本文能处理更为复杂的问句,并且通过拼接扩展丰富了数据集。文献[10]通过Seq2Act的方法来构造语义图,使用该文的方法构造本文的问句时会出现在类“疾病”与“药品”上无法构造时序边的问题,因为两个类型之间不可能存在时序关系,只有两件事才存在先后关系。文献[11]通过定义问句模板的方法,通过问句到模板的映射来进行构造语义图,局限性较大,由于本文的医疗问句包含事件、时序关系,以及存在多事件拼接,所以一旦问句超出模板的范围或者模式,用该方法则无法构造。 2.1.2 语义图线性编码 一个问句会唯一对应一个语义图,一个语义图可以表示相同语义的多个不同形式的问句。考虑到直接保存图所需空间较大,本文提出了一种在约束条件下将语义图编码为线性序列的方法。N包括实体节点、类节点、事件节点和常量节点,E包括属性与关系。如图3所示,其中Constant1、Constant2和Constant3是常量节点, Drug与Disease是实体节点,“?e”“?e1”是事件变量节点,“?x”是实体变量节点。 图3 语义图结构示例 语义图包含主链、支链与环结构三部分,对其编码定义如下: (1) 主链结构。主链用Ga表示,Ga= 图4 主链、支链和环结构 (2) 支链结构。设支链用Gb表示,Gb= (3) 环结构。设环用Gc表示,Gc= 本文之前已经定义了语义图形式及其三种图形化结构,这节重点描述利用语义图来将已经收集的句式模板进行扩充,并通过在Jena图数据库中查询实体、属性值、事件之间的时序关系来丰富问答数据集,最后对半自动化构建的问句进行人工校验与重述。 2.2.1 句式模板收集与映射 句式模板是指将自然语言问句中的实体替换成实体类型、属性值替换成属性名称后的句子。就如上述问句“哪些男性病人在诊断了高血压之后服用了硝苯地平控释片?”对应的句式模板是“哪些[性别]病人在诊断了[疾病]之后服用了[药品]?”。其中,不同的句式模板可能会拥有相同的语义图和相同SPARQL语句模板。 算法1 语义图线性序列的构造算法 本文从临床科研需求里收集了122个基于电子病历数据的高频统计查询问句作为初始集,并按照“临床科研”“医学统计”和“医学科研”等中英文关键词检索医学文献,并且从文献里提取出了83个有效的统计查询需求,并对以上205个问句进行人工实体、属性替换,获得了197个句式模板。同时对基于电子病历数据的潜在查询场景分析,额外补充了66个模板,总计得到了263个句式模板。最后为以上263个句式模板标注SPARQL语句模板,去重后剩余247个句式模板和相对应的SPARQL模板。 2.2.2 句式模板扩充与实例化 经过上一步骤得到了247个句式模板和与之相对应的SPARQL语句模板。本文通过语义图中边的个数来定义一个句子的复杂程度,也就是跳数。为了使最后的问句更加复杂与多样化,本文利用语义图可拼接可扩充的性质,对原有的句式模板进行推荐扩展,在节点上增加支链个数以加大跳数。最后将以上句式的SPARQL语句在医疗事件图谱中查询得到实体、属性等信息并填回句式汇总,从而得到一个完整的医疗自然语言问句,最终获得3 083条自然语言问句和SPARQL查询语句。具体的构造算法2的流程如下。 算法2 半自动构造医疗数据集及其SPARQL模板算法 2.2.3 人工校验与重述 相同语义的句子可以拥有不同的表述方式,体现在句式的不同和谓词的多样性上面。如“哪些男性病人在诊断了高血压之后服用了硝苯地平控释片?”可以表述为“患有高血压后服用了硝苯地平控释片的病人有哪些?”“患有高血压的患者有多少”和“高血压患者总数是多少”这两个句子表达着同样的语义。对于成环的句子,可能会存在事件之间逻辑关系不正确或者时序关系出错的情况,所以人工校验的时候是一个重点。此外,上述的步骤获得的问句一方面可能存在一些不符合语法规则的情况,另一方面也难以体现自然语言的丰富性和多样性,因此需要进行人工校验和重述。针对以上问题,本文将上述步骤获得的3 083条句子交付给5名临床数据标注者进行校验和重述,以保证问句的准确性、多样性和丰富性,最终得到3 000条自然语言问句。表1列出了5条人工校验和重述前后的自然语言问句样例。 表1 人工校验和重述前后的自然语言问句样例 本文路径生成任务的输入是字符序列构成的自然语言问句,输出是语义图的线性结构,采用了基于注意力机制的编码-解码模型。该任务与序列到序列生成的模式相符,其中源序列为自然语言问句,譬如“哪些患者患有高血压?”,将“高血压”这个实体移除后替换为“Variable”这一中间变量进行占位,则目标序列为结构化语言,如“DISEASE !sem:hasObject Variable sem:hasActor AnswerVariable sem:actorType peg-o:PERSON”。 图5为基于注意力机制的路径生成模型。其中,编码器负责源序列特征的提取,而解码器是将编码的特征信息生成为目标序列,注意力机制的作用是在解码过程中计算编码信息和输出序列的参数权重。 图5 编码-解码过程 2.3.1 编码器与编码过程 模型用了RNN的变体——门控循环单元网络(Gate Recurrent Unit,GRU)来组成编码器,图6是其内部结构。GRU与LSTM的不同是,直接用隐藏状态来传递特征信息,去除了细胞特征。GRU包含更新门和重置门,其中更新门决定特征信息的新增与移除,重置门计算移除历史特征信息的程度。 图6 GRU网络内部结构 2.3.2 解码器与含注意力机制的解码过程 设X表示源序列,X= (1) 解码器使用单向门控循环网络,预测t时刻概率分布依赖于t时刻之前的字符信息特征与编码器对源序列的编码。解码过程由以下4个步骤组成。 (1) 解码器初始化通过q个时间步的编码向量特征来进行初始化,并得到初始隐状态向量,如式(2)所示。 (2) 其中,fi是第i个编码特征向量,h0是解码器在t=0时刻的隐状态向量,W是线性变换矩阵。 (2) 计算特征分数用解码器隐状态和编码特征向量计算贡献度,高贡献的特性向量赋予高权重,如式(3)所示。 scoret=W1·tanh(W2·F+W3·ht -1) (3) (3) 归一化,计算上下文向量。将注意力分数进行归一化后获得其概率分布,在编码特征向量序列上应用概率分布,从而得到含注意力的上下文向量表示,如式(4)、式(5)所示。 (4) 递归解码。根据上一时刻的解码器隐状态及输出字符表示向量,更新门控循环单元网络隐状态,并计算当前时间步字符的概率分布,如式(6)~式(8)所示。 inputt=concat(yt,contextt) (6) ht=gru(inputt,ht -1) (7) yt +1=softmax(W·ht) (8) 其中,inputt表示t时刻输出字符向量和上下文特征向量的拼接。yt+1是t+1时刻输出字符的概率分布。 将输入的自然语言问句经过路径生成模型后得到了语义图的线性序列,然后将线性序列转化为SPARQL语句,其中建立实体与占位符之间的映射关系叫作槽填充。根据槽填充方法不同,可以将占位符分为3类,分别为中间变量占位符、答案变量占位符和实体占位符。 (1) “Variable”属于中间变量占位符。填充方法是给每个变量定义唯一符合SPARQL语法的名称,如“?var1”“?var2”等。 (2) “AnswerVariable”属于答案变量占位符。因为答案变量占位符在语义图中是唯一存在的,所以直接添加“?”使其符合语法即可。 (3) 除上述中间变量占位符和答案变量占位符以外的都属于实体占位符。对于实体占位符,采用启发式规则建立与实体之间的映射。规则一: 实体占位符的表示类型与实体类型必须一致;规则二: 如果一个实体占位符对应多个同类型的实体,那么应保证实体占位符在语义图线性序列中的顺序与实体本身在自然语言问句中的顺序一致。 在之前的工作中,已经使用上海市三家三甲医院的数据构建了3个专科、173 395个医疗事件和501 335个时序关系的医疗数据集并进行公开。为了评估本文的方法,本文通过半自动化构建、人工重述与专家审核构造了面向临床科研的问答数据集共3 000条问句,随机按3∶1∶1划分为1 800条训练集、600条验证集、600条测试集,其中自然语言问句的字符长度集中在10~40之间。 3.1.1 实验设置 模型使用Pytorch建立,编码器和解码器采用了GRU,训练采用随机梯度优化器(Stochastic Gradient Descent,SGD)来最小化交叉熵损失函数(Cross Entropy Loss Function),迭代次数为20次。 3.1.2 评测指标 对于路径生成任务里的语义图线性序列生成,模型性能的衡量指标采用全局准确率(Global Accuracy,GA),衡量模型预测序列和标准序列在n元短语上的相似性采用BLEU (Bilingual Evaluation understudy)值。全局准确率是模型预测正确的序列占全部序列的比例。全局准确率的计算如式(9)、式(10)所示。 (9) (10) BLEU值的计算如式(11)、式(12)所示。 其中,Pn是预测序列的n元组和标准序列的精确度,BP是长度惩罚因子,避免BLEU倾向于较短的序列。 3.1.3 实验结果 本模型中,编码器采用双向GRU,解码器采用单个GRU并用注意力机制来提高模型性能。实验结果从实体信息对模型性能的影响、单双向编码器对模型的影响、向量维度对模型的影响、注意力机制对模型的影响以及LSTM与GRU的对比来进行分析。 (1) 实体信息对模型性能的影响 通常来说,实体包括命名实体、时间、数字等。从表2中可以看出,包含实体信息的问句对于目标序列的生成有负面影响,因为在解码的过程中,实体较多会影响注意力机制的发挥,导致关键特征的注意力分数下降,从而在验证集上准确率较低,实验表明实体信息对模型准确率的影响在0.3%左右。 (2) 单向双向编码器对模型性能的影响 单向编码器顾名思义就是对于输入序列进行编码时,GRU网络只能进行单向计算,但是序列从右到左与从左到右一样包含着信息与特征。从表2可以看出,双向GRU网络在训练收敛后的模型准确率更高,有效地证明了双向GRU能更好地表示自然语言问句信息。 表2 基于注意力机制的路径生成模型评测结果 (单位: %) (3) 向量维度对模型性能的影响 GRU网络有内部向量参数,通过设置不同的参数来映射GRU网络对特征信息的容纳能力。由表2可知,随着向量维度的增加,模型准确率增益减少。 (4) 注意力机制对模型性能的影响 当自然语言问句较长时,训练时容易丢失句子的信息,引入注意力机制有助于增强对句子有选择的记忆。由表2可知,含有注意力机制的序列到序列模型能比不含注意力机制的准确率高0.5%,有效证明了含有注意力机制时能有效增加对句子有益特征的权重。 (5) GRU与LSTM、Transformer对比 通常情况下,GRU与LSTM在很多任务上不相上下。不过GRU的参数较少,更容易收敛,但是在大数据集的任务上,LSTM的表达能力会好一些,如果在Transformer上面的表现不如GRU好的话,可能是因为本文的临床科研的问答数据集较少,所以通过表2选择了基于注意力机制的双向GRU作为本文模型。 3.2.1 评测指标 语义图驱动的面向复杂逻辑的自然语言问答是将实体识别、路径生成、知识库查询等几个过程串联的整体过程。本文使用准确率作为评测指标,系统总体准确率由路径生成准确率和答案准确率组成,如式(13)所示。 总体准确率=路径生成准确率×答案准确率 (13) 其中,路径生成准确率上文已经分析,答案准确率代表医疗事件知识库中查询到的答案与标准答案的比例。 3.2.2 实验结果与错误分析 由于序列的输出存在乱序的可能,所以这序列和答案的比较是通过人工一一比较进行的。路径生成模型在7次训练后收敛,在验证集上效果较好,将最优模型用于600条测试集后得到语义图线性序列,双向GRU与标准序列一致的最多,达586个,占比97.67%。将预测正确的序列通过槽填充后得到586条SPARQL语句,其中正确的语句有556条,占比94.88%。在知识库中进行查询并与标准答案进行对比,其中一致的有549个,占比93.69%。 根据评测公式得到基于深度神经网络和语义图的问答的总体准确率为91.5%。在测试集上存在51条与标答不符的错误解析,其中,7条属于实识别与实体对齐错误,14条属于路径生成错误,30条属于基于启发式规则的槽填充错误。 本文针对领域中经常出现的事件及其逻辑关系,定义构造了语义图中间表示来解决。本文针对医疗语料稀缺的问题,半自动化地构建了3 000个具有复杂逻辑关系的问句,并且用路径生成模型将自然语言问题翻译成语义图的线性序列,提出了SGDQA的流程框架。但是文章也存在不足,语料不够多可能会引起训练结果的误差,未来还可以尝试用联合学习的方法来简化流程,并尝试更多的模型来进行实验对比。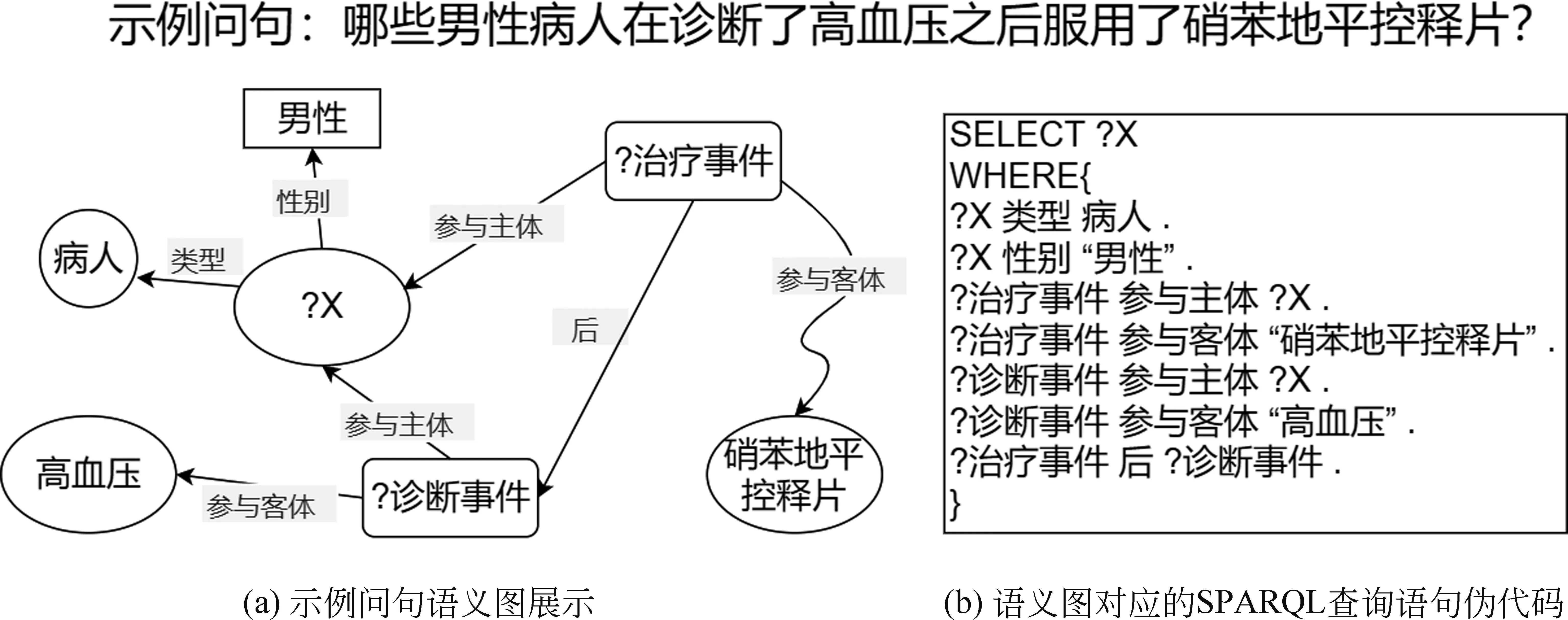


2.2 数据集构造


2.3 基于注意力机制的路径生成模型

2.4 槽填充
3 实验与错误分析
3.1 基于注意力机制的路径生成模型评测
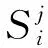
3.2 总体评测与错误分析
4 总结与展望
猜你喜欢
中国外汇(2019年18期)2019-11-25
制造技术与机床(2019年6期)2019-06-25
哲学评论(2017年1期)2017-07-31
新高考(英语进阶)(2017年3期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
时代英语·高三(2014年5期)2014-08-26
读写算·高年级(2009年3期)2009-11-16
