
重采样在微博机器人识别中的应用研究
2022-01-20 12:48:14罗云松黄慕宇
中文信息学报 2021年12期
罗云松,黄慕宇,贾 韬
(1. 西南大学 计算机与信息科学学院,重庆 400715;2. 长安汽车金融有限公司,重庆 400020)
0 引言
类别分布不平衡的数据广泛存在于现实生产生活中,并且在诸多领域具有重要的科学研究价值。在诸如网络安全检测、欺诈交易识别、医疗诊断、垃圾邮件过滤、工业故障异常检测等不平衡分类领域中,虽然少类样本的占比极低,但其重要性远大于多类样本。例如在社交媒体机器人检测中,Twitter上的机器人账号约占总量的5%~9%[1],而这少量的机器人账户却产生了约24%的虚假推文。近年来如微博等国内社交媒体的迅速发展使得中国民间信息发布的门槛大幅降低,不同信息在快速传播的同时也具有不同以往的强影响力[2]。许多海内外非法技术团体利用微博的这些特点,大量注册机器人账号并将其用于宣传、营销、炒作等活动。这些机器人群体通过劫持热门话题,间接地刺激和诱导激进民众,从而形成巨大的虚假舆论场[3-5],这些行为在扰乱网络秩序的同时,也会妨害经济利益,造成恶劣的社会影响。因此,微博机器人账户的识别研究对促进微博等社交媒体的发展以及社会治安管理都有非常重要的意义。
目前,围绕微博机器人账户识别的研究主要有两种方式,即监督学习和无监督学习。其中监督学习又可以分为基于特征内容的识别算法和基于图模型的识别算法[6]。基于特征内容的监督学习是将微博机器人检测看作一个分类问题,利用微博账号的各种特征来区分机器人账号与正常账号[7]。所使用的特征内容包括微博文本、粉丝数、关注数以及个人资料等多种属性[8]。张等人[9]选择互相关注数等属性作为分类器的输入,使用遗传算法和贝叶斯模型的集成框架提高了微博机器人识别的准确率。Gargari等人[10]提出了一种基于构造账户资源模式这一重要特征的新颖检测框架并在特定背景下获得了较高的识别率。Chen等人[11]根据机器人账户的交互行为来定义特征向量并量化传播行为,然后再使用决策树算法进行识别。Yuan等人[12]综合分析了机器人账户的多个特征,利用熵值来衡量各个特征的权重,建立了结合多属性的微博水军识别模型。此外,近年来还出现了许多利用深度神经网络(Deep Neural Networks,DNN)模型对社交媒体机器人进行识别的研究工作[13-15]。
基于图模型的微博机器人识别是利用账户之间的关注、转发等关联关系,构造相应的社交网络,再使用不同图挖掘算法来区分机器人与正常用户[16]。Wang等人[17-18]通过引入复杂关系模型,对网络节点之间的关系建模分析,迭代得到网络水军的置信度。程等人[19]发现用户双向关注比和账户注册时间是区分机器人与正常用户的重要特征,并提出一种基于用户关系图特征表示的算法。Jiang等人[20]根据每个账户的最大似然度计算谣言的传播规模,并基于此提出了一种结合网络拓扑属性的传播网络时变模型。文献[21-23]对大多数社交网络中的异常检测方法进行了总结。
无监督学习是通过各种聚类算法对所有账户的特征进行降维,观测其形成的类簇,从而达到识别目的。Miller等人[24]通过对Twitter用户中的个人信息以及文本特征进行聚类,达到了较高的识别率。Chu等人[25]则采用对Twitter内容中URL的最终跳转地址进行聚类的方式,来判断类内账号是否为机器人账号。
在以往的微博机器人识别研究中,研究人员大多是爬取搜集多个微博账号的特征信息并人工标注是否为机器人账号。这种方式获得的数据集往往样本量较少,并且验证集机器人与正常用户的分布比例相对平衡。由于在微博机器人识别中天然的样本不平衡性,利用平衡的验证集评价的模型,必然在处理真实问题时存在局限性,然而已有的研究相对缺少针对相应条件下机器人识别算法性能降低的比较分析。
另一方面,当前已有在算法或数据层面改善不平衡分类的研究。重采样就是一种从数据层面上解决不平衡分类的简单有效方法[26]。由于当前研究并没有过多关注机器人与正常用户分布严重不平衡这一特点,重采样技术在微博机器人识别这一场景下的应用较少,尤其缺少重采样技术对已有算法性能影响的系统性分析。
针对以上两个问题,本文使用微热点大数据平台提供的微博机器人数据,该数据集取自2019年4月1日到5月8日新浪微博6个热点话题下的真实数据,数据量大且正负样本分布严重不平衡。本文的主要贡献总结如下:
(1) 提出了一种结合重采样方法的微博机器人识别框架,使用5种重采样方法对训练集进行处理,比较了7种监督学习算法的性能差异。由于不同重采样方法与不同识别算法的结合对结果的提升各不相同,因此相关对比分析为不同场景下的算法选择提供了借鉴,为后续其他研究提供了有益的参考。
(2) 采用随机平衡欠采样(Random Undersampling,RUS)的方式模拟了以往研究中小规模平衡样本下的模型训练情况。通过比较基于该平衡样本训练的模型与结合重采样算法的模型在样本不平衡条件下的识别性能,量化说明了过去研究在处理真实识别问题中存在的局限性。
(3) 分析了不同采样方法下特征重要性排名的变化,在一定程度上解释了结合重采样的微博机器人识别框架分类性能提升的原因,同时总结了机器人账户特征上存在的共性特点。
1 重采样及监督学习算法介绍
1.1 重采样
为了更好地处理广泛存在的不平衡分类问题,部分研究专注于在监督学习算法层面上进行改进,而另一部分则侧重于在数据层面上进行重采样处理。现有重采样方法大致分为过采样和欠采样两类,其中过采样是通过增加少类样本的数量来平衡数据集,而欠采样则是减少多类样本使之与少类样本数量相当,然后组成新的子样本集。重采样的主要目的是降低训练集的不均衡程度,使得正负样本大致相当后再做训练,从而提高少类样本的分类正确率。Esmaeel等人[27]提出了一种基于多次重采样的新型洪水敏感性综合预测模型,实验结果显示重采样提高了模型的泛化性能。Wang等人[28]为解决化学预测ADMET中因数据不平衡而导致的较高假阳性率问题,提出了一种同时使用机器学习和重采样方法对二维分子描述的化学物质模型。Borges等人[29]为创建一种能够在加密货币交换市场上进行交易的投资策略而提出了一种对金融序列进行重采样的机器学习算法。Liang等人[30]为解决Fitbit腕带经常将唤醒归为睡眠的低特异性识别问题,提出了一种结合四种重采样策略的决策树算法,结果表明重采样能使Fitbit的特异性最多提高75%。在现有的重采样方法中,ADASYN过采样和NearMiss欠采样是应用最为广泛、最具代表性的两种算法。除此之外,本文还选择了包括SMOTE过采样在内的其他3种重采样算法来增加不同重采样的覆盖度。
1.1.1 ADASYN过采样
ADASYN[31](Adaptive Synthetic Sampling,ASS)是一种自适应合成的抽样算法,其主要思想是使用少类样本的密度分布作为自动确定合成样本数目的标准,且根据少类样本的重要程度不同,通过自适应改变少类样本的权重,为每个少类样本产生相应数目的合成样本。具体过程如下:
(1) 计算需要生成的新样本总量G,如式(1)所示。
G=(Sma-Smi)×β
(1)
其中,Sma为多类样本数量,Smi为少类样本数量,β∈[0,1]为控制生成样本数量的系数。
(2) 对于每个少类样本xi,找出其K个近邻样本并计算其密度分布Γi,如式(2)所示。
(2)

(3) 对每个少类样本xi计算需要合成的样本数量gi,如式(3)所示。
gi=Γi×G
(3)
经过ADASYN过采样处理后的数据集会根据分布Γi自动合成对应数量的少类样本,从而使少类样本得到平衡。具体生成少类样本的方式与SMOTE算法相同,见式(4)。
1.1.2 SMOTE过采样
SMOTE[32](Synthetic Minority Oversampling Technique)是一种对少类样本进行分析并根据少数类样本人工合成新样本达到平衡数据集目的的过采样算法,它的原理就是在少类样本之间进行插值从而产生额外的少类样本。具体来说,对于一个少类样本xi,求出离xi距离最近的k个少数类样本,其中距离定义为多维特征空间的欧氏距离,然后随机选择一个最近邻的样本xj,从xi与xj的连线上随机选取一个点xk作为新的少数类样本,如式(4)所示。
xk=xi+(xj-xi)×δ
(4)
其中,δ∈[0,1],最后将新的少类样本添加到数据集中得到新的训练集。
1.1.3 NearMiss欠采样
NearMiss[33]是一种基于k近邻算法(k-Nearest Neighbour,k-NN)的启发式欠采样方法,根据启发规则可细分为三种方式。第一种是选出到最近的N个少类样本平均距离最小的多类样本,将这些多类样本删除后组成新的子样集。第二种是选出到最远的N个少类样本平均距离最小的多数类样本删除。第三种是为每个少类样本都选择出M个近邻样本(同时包含少类和多类),然后筛选出距离N个近邻样本平均距离最大的多类样本进行删除。总之,欠采样的本质是删除多类样本从而平衡数据集,而NearMiss就是针对该选择哪些多类样本进行删除而提出的算法。本文中使用的是第一种方式。
1.1.4 TomekLinks欠采样
TomekLinks[34]是一种数据清洗方法(Data Cleaning Technology),这种方法也是通过某种启发性规则来清洗重叠的样本从而达到欠采样目的。对于一对属于不同类别的两个样本x与y,如果不存在另一个样本z,使得样本x与z之间的距离或者样本y与z之间的距离小于样本x与y之间的距离,那么就称样本x与y是一对TomekLink。因此样本x与y互为近邻关系并且很有可能是处于决策边界的噪声数据,然后通过删除TomekLinks中的多类样本以达到欠采样的目的。
1.1.5 SMOTETomek组合采样
SMOTE算法的缺点是生成的少类样本容易与周围的多类样本产生重叠从而造成误分,而TomekLinks则可以剔除重叠的噪声样本。因此SMOTETomek[35]组合采样的思想就是将SMOTE与TomekLinks两种算法结合起来,通过先进行过采样再进行数据清洗的方式达到平衡数据集的目的。
1.2 基于内容特征的监督学习机器人识别算法
因数据集所含的特征都为内容特征,故本文使用基于特征内容的监督学习算法来对机器人账户进行识别。
1.2.1 随机森林算法
随机森林[36](Random Forest,RF)是一种用随机方式建立的,以多个CART决策树为基分类器的集成分类算法。该算法先通过Bagging自助采样法随机从数据集中采样出T个包含有m个训练样本的子样集,然后基于每个子样集随机选取一定特征训练出一个CART树,再将这些决策树的分类结果用简单投票法输出。RF的随机性体现在数据集的随机选取以及待选特征的随机选取两方面。其中CART树是以基尼指数作为特征选择的度量方式,具体定义如式(5)所示。
(5)
其中,D为样本集;K表示类别个数;ρk表示类别为k的样本占所有样本的比值。RF算法具有对缺失值不敏感、不易过拟合的优点。
1.2.2 XGBoost算法
XGBoost[37]是一种通过Gradient Tree Boosting实现的集成树算法,其基分类器也为CART树,可以解决分类、回归等问题。假设训练集为(xi,yi),其中xi∈m,yi∈。xi表示具有m维的特征向量,yi表示样本标签,算法包含K棵树,XGBoost算法的定义如式(6)所示。
(6)
其中,fK(xi)表示第K棵树,函数f(x)表示对样本特征进行映射,使每个样本落在该树中的某个叶子节点上。每个叶子节点均包含一个权重分数作为落在此叶子节点的样本在本棵树的预测值ω。计算样本在每棵树的ω之和,并将其作为最终的输出预测值。XGBoost的目标函数定义如式(7)所示。
(7)
该目标函数由两项组成: 第一项为损失函数,用于评估模型预测与真实值的误差;第二项为正则化项,用于控制复杂程度,防止出现过拟合。
XGBoost算法通过引入泰勒公式来简化目标函数,式(7)就改写为:
(8)
其中,gi为损失函数的一阶梯度统计,hi为二阶梯度统计,ωj为叶子节点的权重,Ij为叶子节点j的样本集,λ为L2正则化系数,γT为正则项通过叶子节点数及其系数控制模型复杂程度。
1.2.3 Lightgbm算法
针对XGBoost算法在处理高维特征大数据时占用内存大、运行缓慢的不足,微软于2017年提出了一种Lightgbm[38]的集成提升树算法。该算法通过使用以下三个子算法优化了XGBoost算法的模型复杂度。
(1) 直方图算法(Histogram): Lightgbm引入Histogram算法代替预排序算法,将连续特征离散到固定数量的分箱上,同时构造一个宽度等于该数量的直方图用于信息统计。该直方图算法无需遍历数据,只需要遍历固定数量的分箱即可找到最佳分裂节点,使算法时间复杂度降低。
(2) 基于梯度的单边采样算法(Gradient-based one-side sampling,GOSS): 其主要思想是通过对样本使用降采样的方法来减少目标函数的计算复杂度。其创新之处在于只对梯度绝对值较小的样本按照一定比例进行采样,而保留了梯度绝对值较大的样本。由于目标函数增益主要来自于梯度绝对值较大的样本,因此这种方法在计算性能和计算精度之间取得了很好的平衡。
(3) 互斥特征捆绑算法(Exclusive Feature Bundling,EFB): 在许多数据集中都存在大量的稀疏特征,这些稀疏特征因几乎不会同时取非零值而被认为是互斥的。EFB算法利用这种互斥性,将多个互斥特征捆绑成一个新的特征,减少用于构建直方图的特征数量,进而降低计算复杂度。
Lightgbm通过引入以上三种算法使其内存消耗与计算量比XGBoost更低。
1.2.4 Catboost算法
Catboost[39]算法是一种专门针对类别型特征的监督学习算法。该算法通过引入贪心目标变量统计(Greedy Target-based Statistics,Greedy TS),将类别特征分组成有限个群体再进行One-hot编码转为数值型特征进行处理。Greedy TS的计算如式(9)所示。
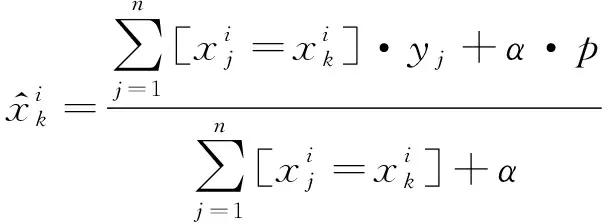
(9)

2 实验流程与评价指标
2.1 数据集描述
本文采用微热点平台提供的自2019年4月1日到5月8日微博上出现的6个热点话题的真实数据。数据集包括“发布时间”“用户性别”等14个特征和1个类别标签“是否是机器人”,具体特征表和示例样本如表1所示,6个热点话题数据集中的正常用户与机器人用户比例如表2所示。
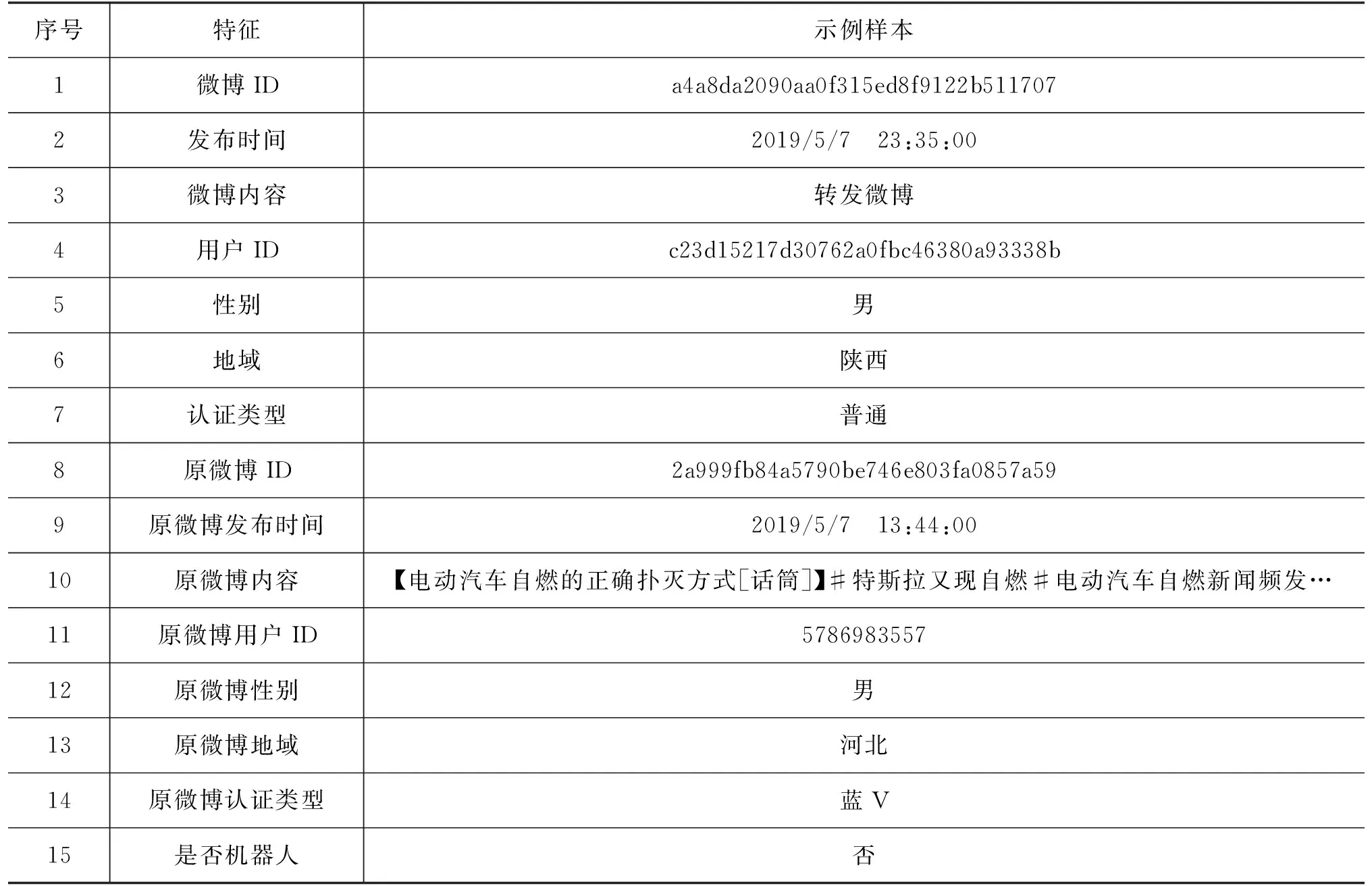
表1 特征说明

表2 数据集总量与不平衡比例说明
2.2 探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)是数据挖掘的重要步骤,其中的特征工程分析直接决定了后期算法的分类结果。由于EDA本身并没有严格的流程,本文主要从数据清洗、特征工程以及降维聚类这三方面开展EDA工作。
2.2.1 数据清洗
6个热点话题数据集中主要含有重复值,异常值和缺失值三种类型的脏数据。重复值方面主要出现在用户ID等4个ID属性的特征上。由于本文专注于微博机器人账号的识别检测,因此对用户ID这一属性的重复值进行剔除,而对其他三个属性的重复值不作处理。具体剔除的方式是选择出现的第一个重复值而剔除剩余的全部。缺失值处理方面,尽管如XGBoost、Lightgbm等算法有关于缺失值的处理,但考虑到与其他监督学习算法的对比以及样本量大小等因素,本文对缺失值仍然采用剔除的处理方式,即只要出现缺失值则删除这个样本。我们也对所有出现异常值的样本进行了删除,如在性别中出现了除“男”和“女”之外的其他特征的异常样本。
2.2.2 特征工程
本文采用构造差异性特征的方式来增加新的特征属性,如用原微博发布时间减去当前微博发布时间得到“发布时间间隔”这一新的特征;对认证类型这一特征进行数字编码后,用原微博认证类型减去当前微博认证类型得到“认证类型差异”这一特征属性。本文采用发布时间、性别、地域、认证类型、原微博发布时间、原微博性别、原微博地域、原微博认证类型、发布时间间隔以及认证类型差异共10个特征属性,舍弃了ID和发布内容等6个属性。
2.2.3 降维聚类
在确定10个特征后,需要对属性进行降维聚类并观察数据集正负样本的分布状态,以确定相应监督学习算法的选择。以对数据集4进行平衡欠采样后得到的150∶150子样本集为例,采用t-SNE、PCA和SVD三种算法进行降维后,发现浅色的正常用户与黑色的机器人用户在二维特征空间中基本重叠在一起,如图1所示。这是由于在10个特征中,除了“发布时间间隔”这一属性为数字型特征外,其他特征全部都为类别型特征,而针对类别型特征的编码方式如label编码等,都会在类别型属性所含元素较少的情况下使样本发生重叠。所以在建模分类的时候须选择能较好处理多种类别型特征重叠的监督学习算法。
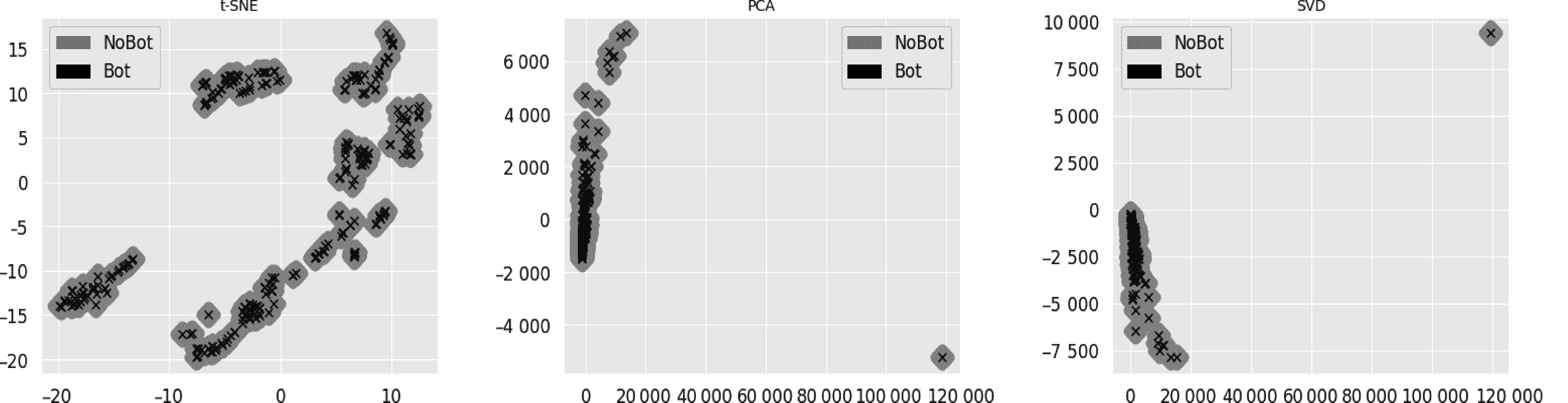
图1 三种降维算法结果图
2.3 实验流程与评价指标2.3.1 实验流程
本文提出的结合重采样技术的改进微博机器人识别框架如下: 首先对原始数据集进行数据清洗和特征工程等探索性分析;然后采用五折交叉验证的方式对数据集进行划分,由于数据集具有不平衡性,所以在划分的时候也是按照不同类别的相同比例划分;接着对划分好的训练集进行重采样,并在经过重采样后的训练集上应用各种监督学习算法,训练识别模型;最后在验证集上使用多种评估指标评价算法的性能,具体框架如图2所示。
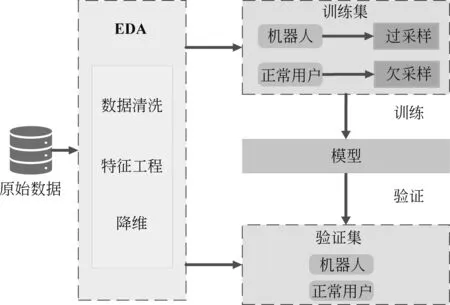
图2 结合重采样的机器人识别算法框架
2.3.2 评价指标
以往的微博机器人识别研究一般仅采用准确率(Accuracy)为评价标准,但该指标在类别不平衡的数据集上评估效果较差。例如,在正负样本比例为9∶1的验证集上,如果一个算法把全部样本都识别为正类,那么其准确率为90%,而负类样本的召回率则为0。由于微博机器人识别研究为类别不平衡学习,在选择评价指标时应区别对待不同类别的准确率,所以本文采用Recall、G-mean[40]、AUC等指标来评估算法性能。为定义相关的评价指标,需要引入混淆矩阵,如表3所示。

表3 二分类混淆矩阵
其中,TN(True Negative)为正常用户样本被预测为正常的数量,TP(True Positive)为机器人样本被预测为机器人的数量,FN(False Negative)、FP(False Positive)分别是预测错误的实际机器人和正常用户样本数目。以这四个基本指标衍生出多种不同场景下的评价指标,其中Recall和G_mean对于不平衡分类较为重要,其基本公式如式(10)、式(11)所示。
ROC(Receiver Operating Characteristic)曲线又称接受者操作特征曲线,是监督学习中另一种重要的模型评价指标。该指标以伪阳性率FPR为X轴,真阳性率TPR为Y轴构造出ROC空间。给定一个二元分类模型和相应的阈值后,通过不断调整分类阈值就能得到该模型的ROC曲线。虽然ROC曲线能综合评估模型的优劣,但如果两条ROC曲线出现了交叉,则很难直观地评估两个模型,于是出现了AUC (Area Under the Curve )指标。AUC定义为ROC 曲线下的面积,反映了分类器对样本的排序能力,同时考虑了分类器对正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。AUC的值越大,说明模型性能越好,具体如式(12)所示。

(12)
其中,M和N分别表示正负样本的数量,rankinsi表示正样本概率排第i名的样本,分子表示所有正样本概率大于负样本概率的样本数量。
3 实验结果分析
3.1 微博机器人识别结果
本文采用原始数据集生成的训练集以及经过多种重采样处理之后的训练集进行模型训练。 分类算法包含3种传统监督学习算法: 朴素贝叶斯(Naive Bayes,NB)、支持向量机(Support Vector Machine,SVM)、k近邻(k-Nearest Neighbor, kNN)以及4种集成提升树算法: Lightgbm、XGBoost、RF、Catboost。
尽管微博机器人识别研究是一个传统的二分类问题,但在现实的应用场景中,模型将一个正常用户识别为机器人和将机器人识别为正常用户所产生的代价是不一样的,后者产生的负面影响会明显大于前者。因此,微博机器人识别研究关注的重点是模型对机器人账户的识别准确率。经过多种重采样处理后7种算法在6个数据集上的Recall如表4所示。
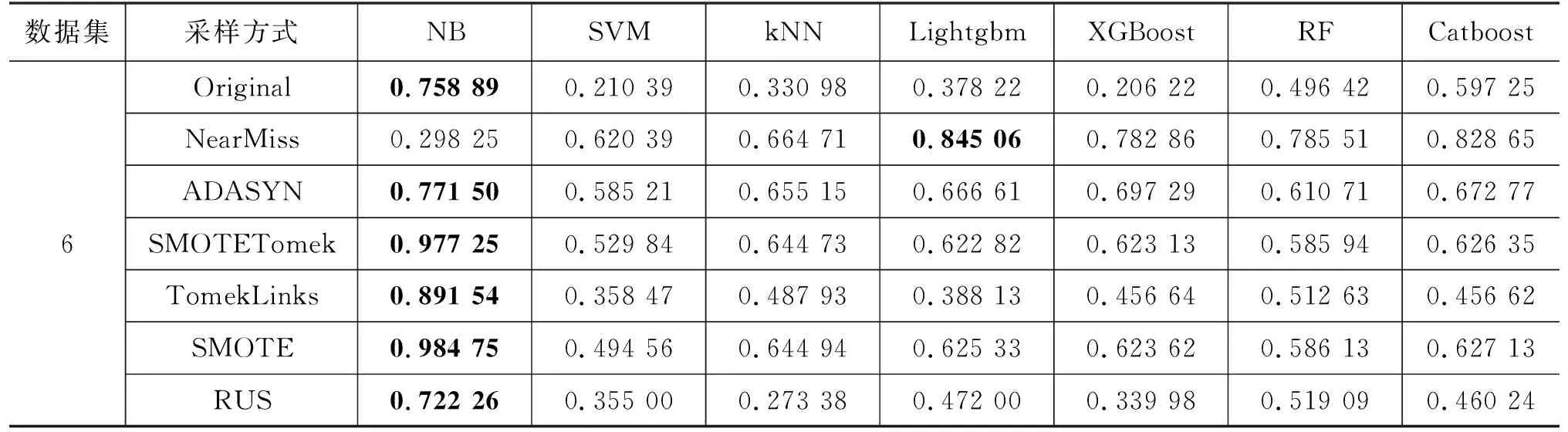
续表
其中,NB在所有原始训练集上的Recall最高,而在NearMiss欠采样下却表现较差。在ADASYN过采样下,NB 在5个数据集上的Recall都为最高。在不平衡比例最大的数据集5上,SVM、Lightgbm和XGBoost三种算法在原始训练集下的Recall和G_mean都为0,即三种算法都未能准确识别出一个机器人账户。而在数据集5上进行重采样之后,算法的Recall都有了较大的提高。总的来说,除了NB之外,其余6种算法在应用NearMiss欠采样之后Recall的提升比应用ADASYN过采样要高。SMOTE、TomekLinks和SMOTETomek三种采样方式都会使算法的召回率有一定程度的提高。
G_mean是衡量不平衡数据集分类效果的综合指标,表5为不同采样方式下7种算法在6个数据集上的G_mean。在原始训练集上,RF在1、2、4数据集上表现最好。在结合NearMiss欠采样的训练集上,XGBoost在1、2、4数据集上表现最好。在结合ADASYN过采样的训练集上,Lightgbm在1,3,4,5四个数据集上表现最好。
从表4和表5中可以看出,NB的Recall虽然很高但其G_mean却很低,模型整体泛化性不强,而4种基于树模型的集成算法的Recall和G_mean则比较平均。总的来说,在6个数据集上应用ADASYN、SMOTE、TomekLinks和SMOTETomek之后,大部分算法的G_mean较原始训练集都会得到提高,而在应用NearMiss欠采样之后,部分算法会降低,其余的G_mean都会提高。

表5 不同采样方式采样方式下7种算法在6个数据集上的G_mean
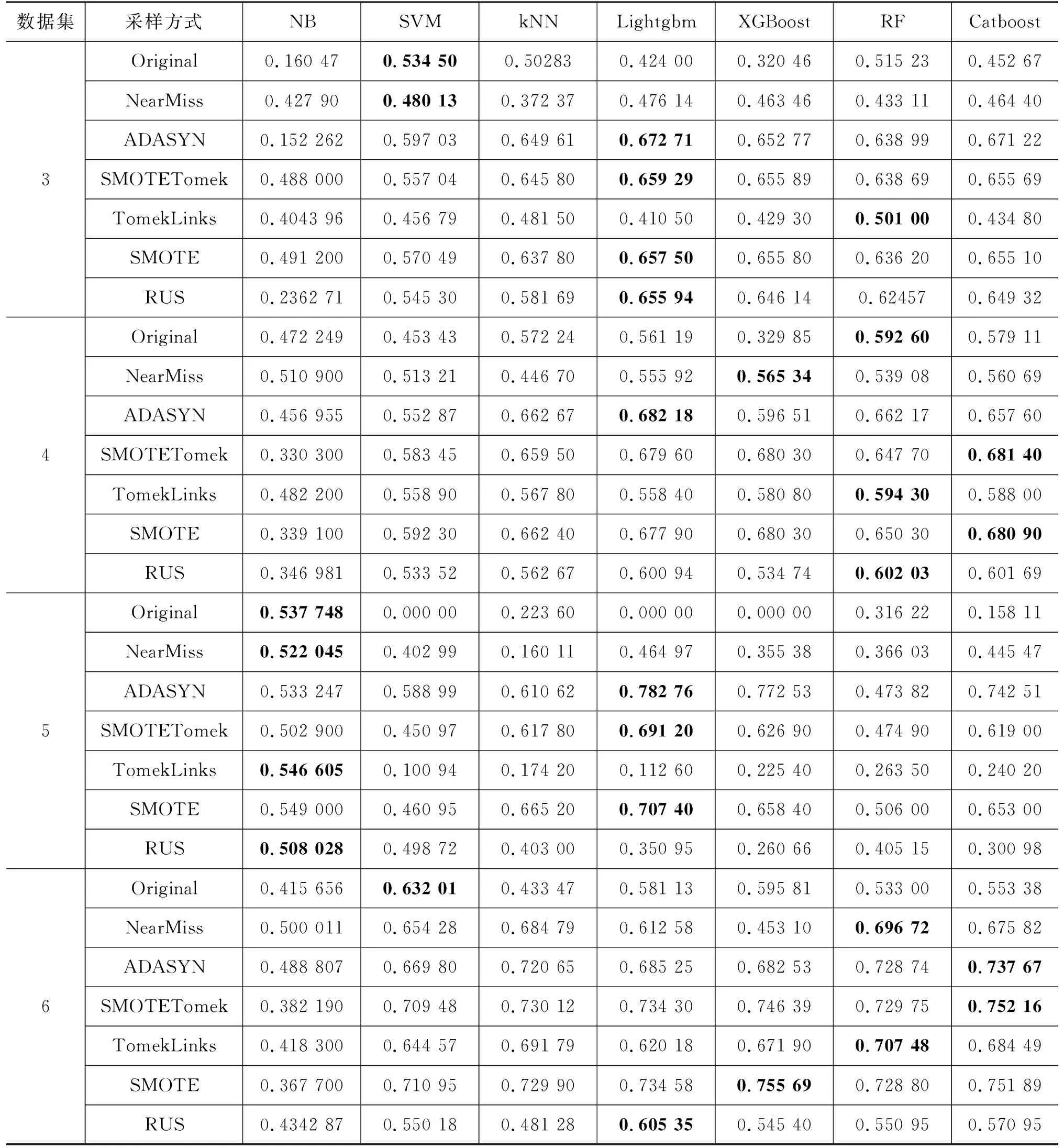
续表
表6为7种算法在6个数据集上的AUC对比。整体上Catboost、Lightgbm和SVM三种算法模型的AUC较高。在多种采样方式的对比中,除了NB之外,其余结合ADASYN过采样的6种算法的AUC都比结合NearMiss欠采样要高。因此,在整个数据集上算法模型结合ADASYN过采样的机器人识别结果较结合NearMiss欠采样好。
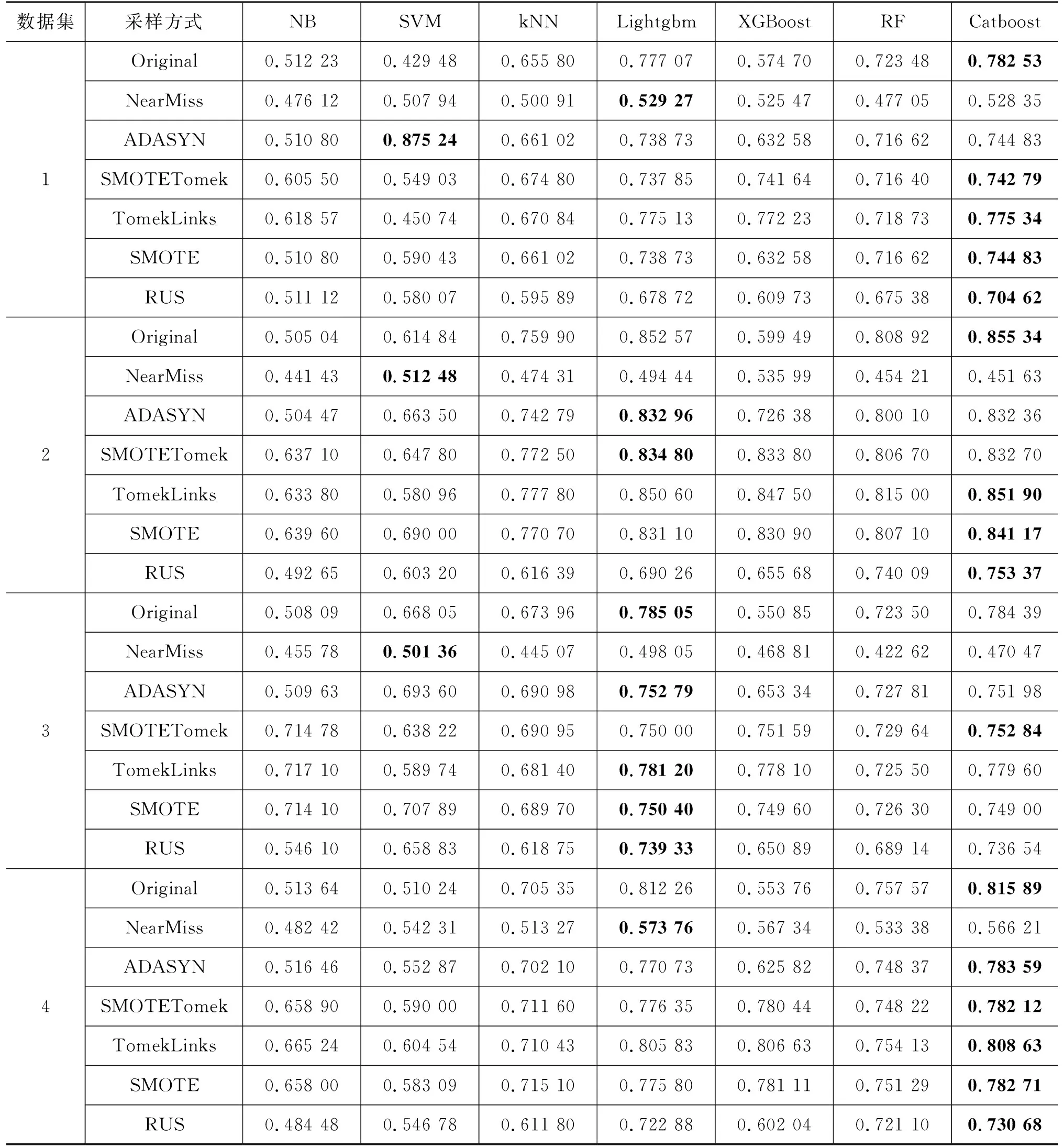
表6 不同采样方式下7种算法在6个数据集上的AUC

续表
综上,使用重采样方法能够让模型的机器人识别精度大幅提高,相应的重采样算法能够剔除处于分类边界的模糊样本或生成不同的少类样本来增大分类器的拟合程度,从而提升泛化性。但现实生活中的微博机器人识别还要结合不同的业务背景。如果只是追求高召回率而放弃查准率,那么微博平台的大量正常用户就会被识别为机器人用户,从而使整个平台的用户体验变差。所以,本文认为在真实微博机器人识别场景下,根据不同的业务背景应采取不同模型结合不同重采样处理的方式来进行框架构建。如果只是以提高机器人账户识别率为目的,应采用NB或结合NearMiss欠采样的其他算法框架。如果要在查准率、召回率和特异度之间取得平衡,追求较高的AUC和较好的泛化性,则应采用结合过采样处理的集成树算法。总的来说,欠采样和过采样都能使模型的Recall得到提高,G_mean整体上得到提高。其中NearMiss欠采样在大幅提高召回率的同时会让G_mean和AUC降低,而过采样在能使模型召回率得到一定程度提高的同时基本上保持AUC不变。
3.2 小规模平衡样本对识别结果的影响
当前对微博机器人识别的研究大多基于爬取搜集的小规模平衡数据集,并不能反映真实情况下的数据统计特征,因此基于小规模平衡样本训练的模型,在处理真实问题上可能存在局限性。为进一步量化分析,我们使用经过随机欠采样处理后的平衡训练集来模拟以往研究中的模型训练和验证。RUS通过随机选取一些多类样本剔除,最终得到正负样本接近的训练集。与本文讨论的其他欠采样方法相比,RUS在减少样本的过程中并没有考虑保留整体数据的特征,仅仅通过简单删除的方法获得平衡的训练样本,与爬取搜集数据的情况较为类似。结合以往研究中的数据情况,我们按照6个数据集机器人样本数量的1/100,将训练集随机欠采样成1∶1的子样本集进行训练 (数据集5为30∶30)。实验结果表明,RUS处理后训练出的模型,大部分在真实数据集上的召回率会有较大程度的下降。如在数据集2中,RUS处理后所训练的最佳模型(Lightgbm),其召回率比Nearmiss处理后的最佳模型低了20个百分点,比ADASYN处理后的最佳模型低了超过30个百分点。而在G_mean和AUC指标上,小规模平衡样本所训练的模型与重采样处理后训练的模型相差不大。
因此,以往研究使用爬取方式搜集的少量数据,由于具有较大随机性,训练出的模型对真实场景下的拟合程度不高,整体泛化性较低。如果使用这种模型对现实中的微博机器人账户进行识别,则会出现识别率降低的问题,与其他方法训练出的模型相比存在较大不足。
3.3 重采样对特征重要性的影响
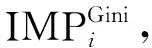
(13)
定义所有节点的集合为N,特征xi是在第K棵决策树中作为节点分裂的属性,则特征xi在整个模型中的重要性如式(14)所示。
(14)
图3为4种集成树模型在数据集5上的特征重要性计算结果。因4种算法的特征重要性性质相同而计算方式不同,计算结果会存在数值区间上的较大差异,所以对4种算法的特征重要性结果做了归一化处理。从图3可以看出,尽管特征的排名顺序各有不同,但在4种整体表现较好的集成树算法中,发布时间、原微博发布时间和发布时间间隔三个特征的重要性都排在前三位,并且大幅高于其他七个特征。因此,微博账户与时间相关的特征是模型对机器人账户识别的重要属性[41-42]。
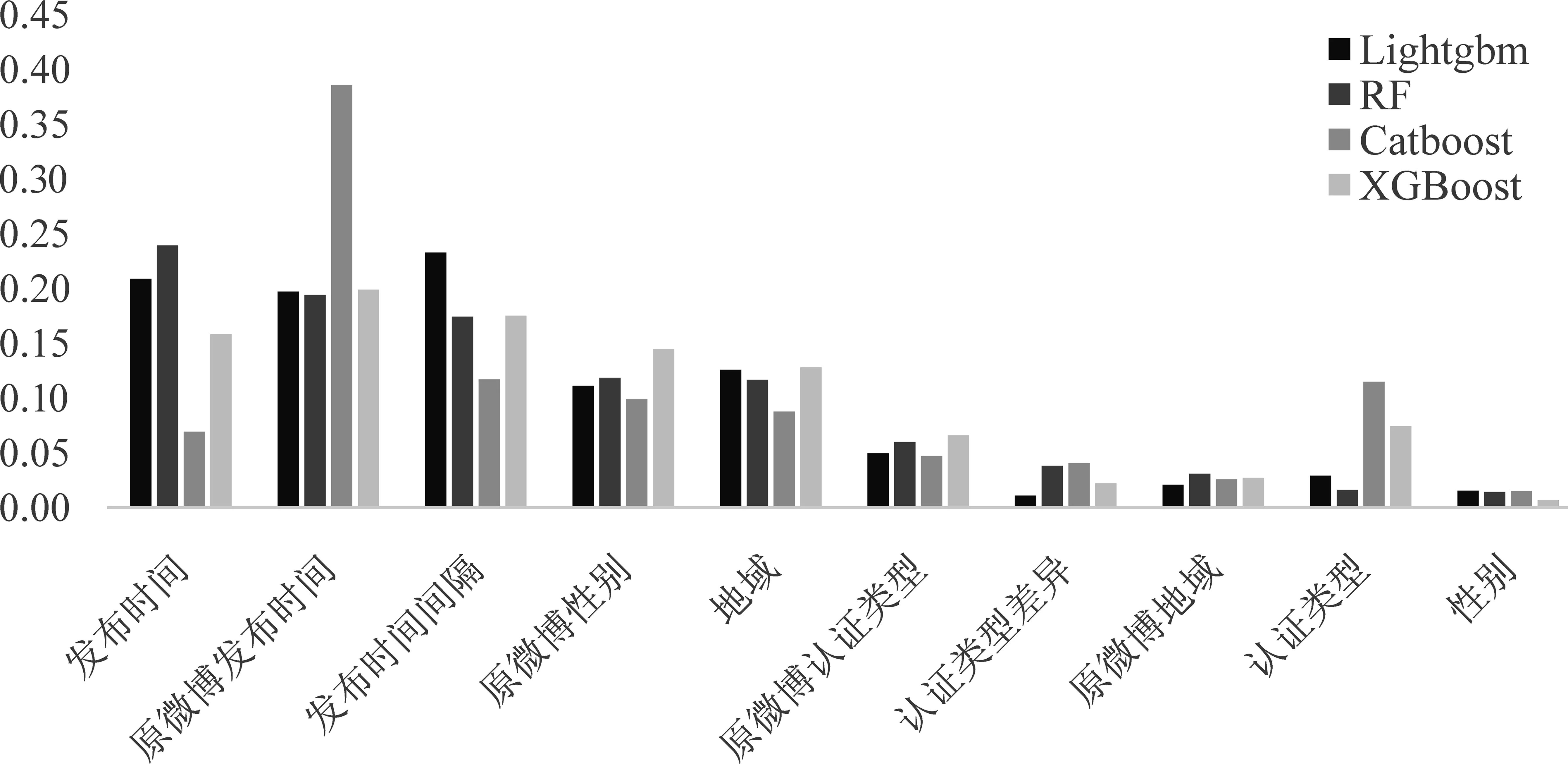
图3 4种集成树算法中的特征重要性
我们通过分析不同重采样处理后模型时间属性的特征重要性排名变化,来探究重采样对模型识别机器人账户的影响。表7为不同采样方式下4种集成树算法特征重要性在数据集5上的排名情况。原微博发布时间这一特征在过采样数据集上排名第一,而在欠采样中则排名靠后。在过采样处理中,训练集样本量较原始数据有较大增加,而原微博发布时间这一特征的重要性也会上升;而在欠采样中,训练集样本数量相对减少,其重要性也相对下降。又如,Lightgbm和Catboost两个模型在原始训练集上排名第三的特征分别为地域和原微博性别,而过采样之后变为发布时间间隔和发布时间。这说明重采样通过减少训练集的噪声样本数或生成少类样本让模型的拟合程度提高,使得不同特征在同一算法中的重要性发生了改变,尤其是与时间相关的三个特征在名次上发生了较大的变化,从而改变了最终的分类结果。
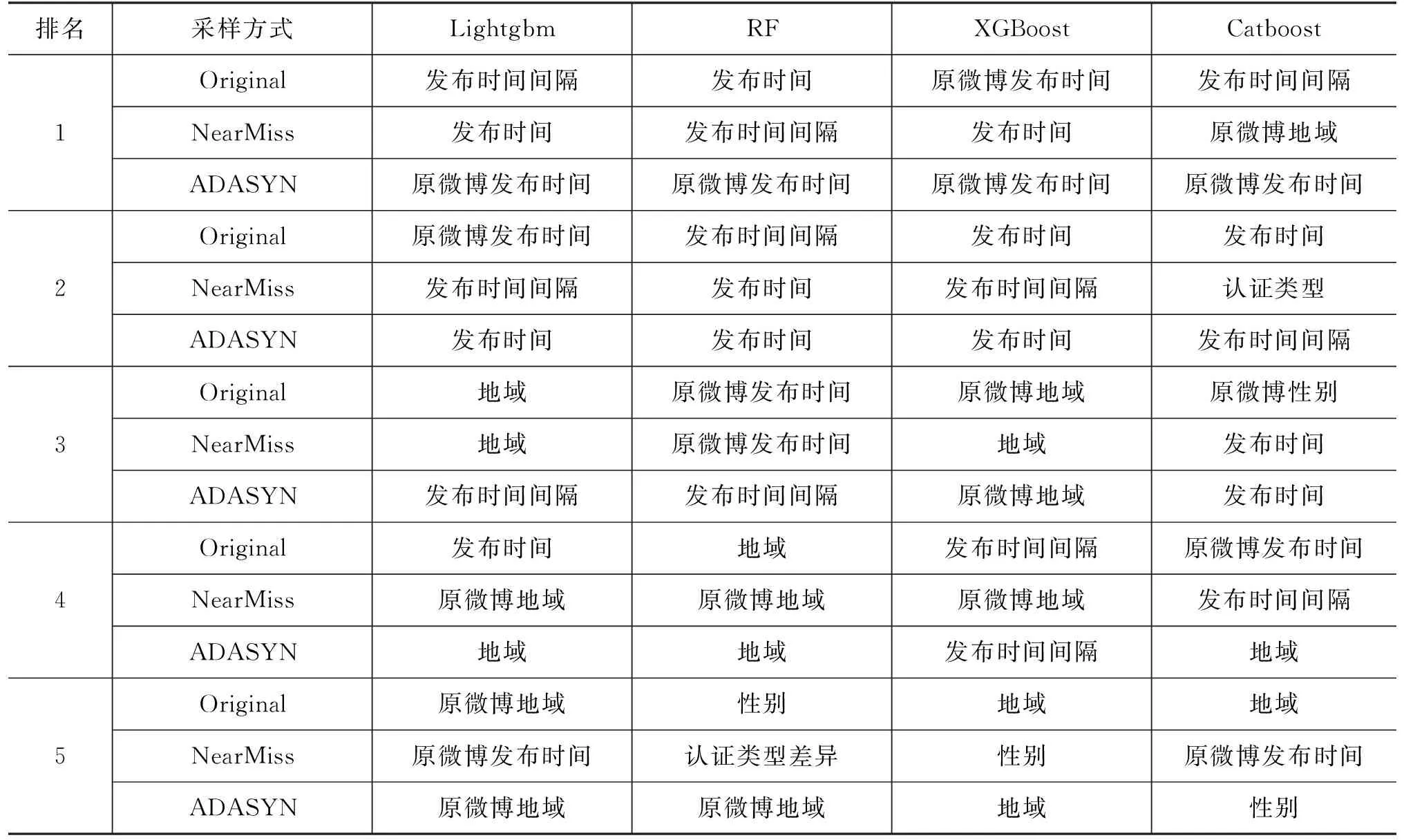
表7 不同采样方式下4种集成树算法的Feature Importance排名
4 结语
本文以微热点平台的微博机器人数据集为基础,针对少量机器人用户识别率低的问题,提出一种结合重采样方法的微博机器人识别框架,该框架先对原始数据进行数据清洗,特征构造,训练集划分等工作,再对训练集进行重采样。在平衡训练集上训练出模型后,再通过划分好的验证集进行评估。本文用随机平衡欠采样的方式模拟了以往研究中小规模平衡样本下的模型训练情况,讨论了过往研究在处理真实识别问题中存在的局限性。在不同采样方式的基础上综合评估了7种监督学习算法的分类性能,同时讨论了不同重采样方式对特征重要性排名的影响。实验结果表明,在重采样后的训练集上训练出的算法模型能够在正常用户与机器人用户分布严重不平衡的验证集上得到较高的机器人账户识别率,也进一步说明了重采样方法对机器人识别的必要性。同时本文也针对不同的业务背景,总结了不同模型结合不同重采样处理方式进行机器人识别框架的构建,探究了结合重采样的微博机器人识别框架分类性能提升的原因。最后我们对本数据集机器人账户特征上存在的共性特点进行了总结: 账号认证类型基本上都为普通;机器人账户倾向于转发认证类型为蓝V的官方微博账户;地域和原微博地域是海外的账户有很大概率是机器人账户;部分具有相同特征的机器人账户会在一个较短的时间间隔内大量转发同一条微博。
本文提出的结合重采样的机器人识别框架能够在类别不均衡的验证集上对机器人账户有较高的识别率,但同时将正常用户误分为异常用户的概率也较高。如何将召回率、查准率和特异度同时提高是下一步的研究重点。此外,本文主要利用了微博用户的发布时间、地域、认证类型等特征进行建模分析,而用户的关注数、粉丝数以及发布内容等多种属性也非常重要。在未来的微博机器人识别研究中,也需要从网络科学、传播学、情感分析、用户兴趣属性[43-47]等多种角度去分析机器人用户的行为特点。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国外汇(2019年17期)2019-11-16 09:31:14
中国外汇(2019年10期)2019-08-27 01:58:28
特别健康(2018年4期)2018-07-03 00:38:20
数学物理学报(2017年5期)2017-11-23 07:51:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:13:44
少儿科学周刊·少年版(2015年4期)2015-07-07 21:09:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:08:08
少儿科学周刊·儿童版(2015年4期)2015-06-17 03:37:19
