
璧南河流域水质评价与污染源解析
2022-01-18 12:17辜小花陈双扣
重庆科技学院学报(自然科学版) 2021年6期
卢 飞 辜小花 陈双扣 刘 晓
(1. 重庆科技学院 电气工程学院/化学化工学院, 重庆 401331; 2. 重庆市环境保护信息中心, 重庆 401147)
0 前 言
水质评价、污染源识别和污染源贡献率定量计算,是水环境监控的重要内容。水质评价的常用方法有单因子评价法、综合污染指数评价法和统计方法等[1]。但这些方法大多计算过程复杂,对数据质量的要求较高,不够简捷[2-4]。刘埮等人基于单因子评价法提出了一种更加有效的评价方法 —— 水质污染指数法(water pollution index,WPI)[5],通过污染指数这一指标量化水质污染程度,使主要污染物识别、水质类别评价和水质定量评价的结果得以优化。
在水质评价过程中,扩散模型和受体模型是常用的污染源解析模型[6]。扩散模型是用于描述污染物在水体中运动规律的数学模型,其中需要输入大量的水质、水文、气象参数,实际应用范围受限。受体模型是用于分析源与受体之间关系的源解析模型。按照数据的需求度,可将受体模型分为两种:一种是受体浓度和污染源排放成分谱均为已知的模型,如化学质量平衡模型(CMB)[7];另一种是污染源排放成分谱为未知而受体浓度为已知的多元统计受体模型,如因子分析/主成分分析模型(FA/PCA)和正定矩阵因子分析模型(PMF)[8-10]。CMB模型具有原理简单、易于实现的优势,因此广泛应用于大气和水污染源解析工作中;但由于污染源排放成分谱获取比较困难,其应用范围有一定的局限性。多元统计模型不需要具体的污染源信息,只需受体浓度数据即可完成污染源解析工作,因此应用更加广泛。但是,单独的FA/PCA模型无法定量描述污染源对水质指标的影响程度[11],通常需要与回归法结合起来使用[12-13]。
璧南河流域地跨璧山、永川、江津等3个行政区,其水环境的质量对于沿岸的居民生活和城市发展有着至关重要的影响。针对璧南河流域的水质污染问题,本次研究采用了WPI法进行水质定量评价,并通过因子分析法和聚类算法定性识别流域的污染源种类,最后采用FA-MLR(因子得分-多元线性回归分析)模型计算各污染源的贡献率。
1 璧南河流域水质概况
根据璧南河“一河一策”方案,璧南河各水功能区的目标水质均设定为Ⅲ类。结合河流水质现状及治理工作安排,预计2019年各水功能区的水质将不低于Ⅳ类,远期逐步达到Ⅲ类。其中,两河口断面为国控断面,预计2020年目标水质达到或优于Ⅳ类。但时至今日,这些目标均未实现。
目前,璧南河流域的水环境问题仍比较突出,少数地区的废污水排放不达标,导致了水体污染逐渐加重。璧南河干流水环境质量整体较差,化学需氧量、氨氮、总磷均超标[14]。
本次研究所采用的水质数据,取自璧南河流域两河口断面和何家桥断面2016 — 2019年共48个月的监测数据,监测频次为每月1次。其中,实际监测因子有21项,监测数据存在一定程度的异常和缺失情况。为了有效地进行分析并获得可靠的结果,对数据进行了异常值剔除和缺失值插补等预处理,最终选定10项监测因子用于水质分析,其中包括pH、NH3N、氟化物(氟离子浓度)、CODMn、CODCr、挥发酚(总酚)、DO、石油类物质(矿物油类化学物质,各种烃类的混合物)、BOD5、TP(见表1)。

表1 水质数据
2 水质评价方法
2.1 WPI法
通过水质污染指数进行水质分级,将水质从优到劣依次分为Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、劣Ⅴ类,如表2所示。当WPI值不超过Ⅴ类水质标准限值时,其计算过程如式(1)所示:
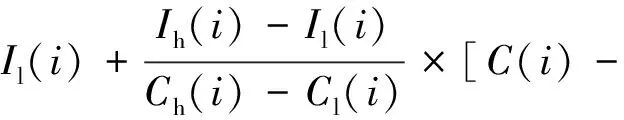
Cl(i)]Cl(i)
≤Ch(i) (1) 式中:I(i)为第i个水质指标所对应的WPI值;Il(i)为第i个水质指标所在类别标准下限质量浓度所对应的指数;Ih(i)为第i个水质指标所在类别标准上限质量浓度所对应的指数;C(i)为第i个水质指标的监测值;Cl(i)为第i个水质指标所在类别的标准下限质量浓度;Ch(i)为第i个水质指标所在类别的标准上限质量浓度。 此外,特殊情况下的计算方法参考文献[15]和文献[16]。 采用因子分析法对数据进行简化,揭示各变量之间的内部依赖关系及数据之间的基本结构,用少数独立的不可观测变量(因子)表示其基本结构。这几个因子能够反映原变量的主要信息,原变量可以用其线性组合来表示。分析模型如式(2)所示: X=AF+E (2) 式中:X为水质监测因子;A为因子载荷矩阵;F为公因子,用于解释污染源类型;E为X的特殊因子。 表2 WPI水质分级规则 采用因子分析法提取污染因子,根据实际情况为污染因子命名,从而实现污染源定性识别。因子分析的主要步骤包括: (1) 对数据进行标准化处理,消除各个变量的数量级和量纲影响; (2) 判断样本是否适合进行因子分析; (3) 构造因子变量; (4) 旋转因子,使因子具有更好的可解释性; (5) 解释因子命名。 将因子分析得到的因子得分作为自变量,将水质指标实测质量浓度作为因变量,建立因子得分与质量浓度相关的数学模型。模型中,因变量为Y,影响因变量的k个自变量分别为X1,X2,…,Xk,假设每一个自变量Xi对因变量Y的影响都呈线性趋势,则因子得分的多元回归模型如式(3)所示: Y=β0+β1·X1+β2·X2+…+βk·Xk+φ (3) 式中:β为回归系数;φ为误差项;Y为污染指标质量浓度监测值;X为因子得分。 贡献率P的计算如下: (4) 根据两河口和何家桥断面2016 — 2019年历史监测数据,对其水质进行评价,结果如表3所示。其中,两河口断面的水质长期达到Ⅳ类,2016、2019年的TP指标达到了Ⅳ类,2017、2018年的TP和CODCr指标达到了Ⅳ类。何家桥断面的水质也是长期达到Ⅳ类,但其污染情况相对更为复杂,不同年份的主要污染指标不同。其中较为严重的指标是CODCr,4年间都达到了Ⅳ类;此外,TP、CODMn、BOD5和石油类物质也曾达到Ⅳ类。综上所述,璧南河流域的TP、CODCr、CODMn、BOD5和石油类物质这5个指标受到的影响较为严重。 表3 水质评价结果 为了验证本研究案例是否适用因子分析法,首先采用KMO和Bartlett球形检验法进行数据样本检验。检验结果显示,两河口断面和何家桥断面数据样本中的KMO值均大于0.5(分别为0.53、0.62),且Bartlett球形检验的贡献率都小于0.05。这表明可以采用因子分析法对璧南河流域环境数据进行分析。 通过层次聚类分析获得数据的特性,结果如图1所示。聚集到同一类别下的污染因子可能源于同一个污染源。将两河口数据聚类为3类:第1类是TP、高锰酸钾指数和BOD5;第2类是氟化物、pH值和DO;第3类是挥发酚、NH3N、石油类物质和BOD5。将何家桥数据聚类为3类:第1类是CODCr、BOD5;第2类是氟化物、DO、pH值和高锰酸钾指数;第3类是TP、NH3N、挥发酚和石油类物质。 在Python 3.6环境下编程进行因子分析,得到两河口、何家桥断面的因子特征值及贡献率,最终提取的公因子数根据Kaiser标准规则来确定[1]。 通过因子分析得知,两河口样本前3个因子的特征值都大于1,方差贡献率分别为32.4%、16.6%和12.6%,方差累计贡献率达到61.6%(见表4)。对于两河口断面数据样本,提取前3个因子即可解释其中的大部分信息,且聚类结果分为3类比较合理。同样,何家桥数据也是如此。因此,分别提取两河口和何家桥数据中前3个因子作为公因子。 为了突出各公因子的显著指标变量,需对因子荷载矩阵进行正交转换,使旋转后的各指标荷载向1或0两极化转换。在此,采用最大方差正交法进行旋转,结果如表5、表6所示。 两河口断面数据中的第1个因子(F1)在CODMn、CODCr、BOD5和TP上的载荷较大,载荷值分别为0.794、0.836、0.823和0.592,因此将F1定义为城市面源因子。第2个因子(F2)在NH3N、挥发酚和石油类上有较大的载荷,其载荷值分别为0.632、0.783和0.690,NH3N在工业废水、生活废水和畜禽养殖废水中含量较高,表征畜禽养殖的农业非点源污染。但F2与挥发酚和石油类的相关度更高,挥发酚和石油类主要来源于造纸和化学等工业废水排放,因此将F2定义为工业污染因子。第3个因子(F3)在pH值和DO上有较大载荷,其载荷值分别为0.802和0.829,因此将F3定义为生活污水因子。 何家桥断面数据中的第1个因子(F1)在NH3N、氟化物、挥发酚、石油类物质和TP上有较大载荷,其载荷值分别为0.630、0.645、0.902、0.855和0.660,氟化物、挥发酚和石油类物质主要来源于造纸和化学等工业废水排放,因此将F1定义为工业污染因子。第2个因子(F2)在CODCr和BOD5上的载荷值分别为0.863和0.905,因此将F2定义为城市面源因子。第3个因子(F3)在pH值和DO上的载荷值分别为0.654和0.841,因此将F3定义为生活污水因子。 图1 层次聚类结果 表4 因子方差解释 表5 旋转之后的因子载荷矩阵 表6 旋转之后的方差贡献率 采用FA-MLR模型计算污染源对各个污染指标的贡献率。基于因子分析所识别的污染源类型,应用FA-MLR模型建立水质指标监测浓度和污染源之间的函数关系。应用FA-MLR模型预测各个指标的浓度,然后选取污染较严重水质指标的实际值和预测值进行线性拟合分析。 以线性回归决定系数R2为评价指标,R2的取值范围为0~1.0,取值越接近1表明拟合程度越高。当R2大于0.7时,比较的两个对象具有良好的一致性[17]。从图2所示拟合结果可以看出,预测质量浓度和实测质量浓度的R2均大于0.7,这表明两者具有良好的一致性。应用FA-MLR模型进行污染源定量解析,具有较好的实用性,结果可靠。通过FA-MLR计算,得到各污染源对监测指标的贡献率,如表7所示。 图2 预测质量浓度与实测质量浓度拟合曲线 表7 各污染源对监测指标的贡献率 % 两河口断面水质主要受到F1(城市面源)的影响,F1对各指标的贡献率分别为:NH3N,11.78%;CODMn,11.17 %;CODCr,16.07%;BOD5,35.71%;TP,15.46%。其次,受到F2(工业污染)的影响,F2对各指标的贡献率分别为:NH3N,25.03 %;挥发酚,41.56 %;石油类物质,31.34%。最后,受到F3(生活污水)的影响,F3对DO的贡献率为14.41%。 何家桥断面水质主要受到F1(工业污染)的影响,F1对各指标的贡献率分别为:NH3N,24.95%;氟化物,10.71%;挥发酚,35.28%;石油类物质,31.99%;TP,15.61%。其次,受到F2(城市面源)的影响,F2对各指标的贡献率分别为:CODCr,14.03%;BOD5,22.25%。最后,受到F3(生活污水)的影响,F对DO的贡献率为18.73%。 采用水污染指数法(WPI)对璧南河流域水质污染状况进行评价。结果表明,璧南河整体水质长期处于Ⅳ类,水体主要的污染指标为TP、CODCr、CODMn、BOD5和石油类物质。 对两河口和何家桥断面历史数据进行因子分析,并综合层次聚类的结果判断分别提取了3个因子。两河口数据中的第1个因子(F1)在CODMn、CODCr、BOD5和TP上有较大载荷,何家桥数据中的第1个因子(F1)在NH3N、氟化物、挥发酚和石油类物质上有较大的载荷。确认两河口的主要污染源为城市面源污染,何家桥的主要污染源为工业污染。应用水质指数法确认污染严重的指标为TP、CODCr、CODMn、BOD5和石油类物质。解析结果与实际情况相吻合。 应用FA-MLR模型计算了两河口断面和何家桥断面主要污染源的贡献率。两河口主要污染源为城市面源,对NH3N、CODMn、CODCr、BOD5和TP的贡献率分别为11.78%、11.17 %、16.07%、35.71%和15.46%;何家桥主要污染源为工业污染,对NH3N、氟化物、挥发酚、石油类物质和TP的贡献率分别为24.95%、10.71%、35.28%、31.99%和15.61%。2.2 因子分析法

2.3 FA-MLR模型
3 璧南河流域水质评价

4 璧南河流域污染源识别
4.1 数据检验
4.2 层次聚类分析
4.3 因子分析
4.4 污染源识别




5 璧南河流域污染源贡献率计算


6 结 语
猜你喜欢
建材发展导向(2022年20期)2022-11-03
科学技术创新(2022年30期)2022-10-21
中国信息化(2022年6期)2022-07-18
新疆钢铁(2021年1期)2021-10-14
西部交通科技(2021年9期)2021-01-11
军事运筹与系统工程(2020年2期)2020-11-16
环境(2019年4期)2019-04-20
领导文萃(2017年11期)2017-06-12
卷宗(2011年9期)2011-05-14
新华月报·下(2008年3期)2008-03-24
