
光学识别技术在机车检修记录单电子化中的应用
2022-01-10 11:40颜家云张慧源彭联贴
控制与信息技术 2021年6期
颜家云,张慧源,李 晨,彭联贴
(中车株洲电力机车研究所有限公司, 湖南 株洲 412001)
0 引言
机车检修记录单用于记录机车大修、中修、小修和辅修过程中所有零部件的检修情况,数据内容涵盖检修者、检修日期、零部件故障损耗情况、零部件生产厂家及型号、零部件更换信息等。建立机车检修记录结构化数据库,可以基于大数据分析实现零部件故障预警与灵活的库存管理,降低检修频率,优化人员配置,促进机车检修降本增效。现阶段机车检修中心已逐步实现检修过程电子化录入;但由于历史原因,依然存在大量的纸质检修单,其信息待补录到系统数据库中。人工筛查分类输入存在效率低、耗时长等问题,因此有必要引入光学字符识别(optical character recognition, OCR)技术来识别文本内容,提高纸质工单补录效率。
OCR技术是通过算法分析图像上的文本数据符号特征及上下文联系,并翻译成计算机文字,其已在卡证、财务票据及车牌等方面的识别取得了广泛的应用,极大地提高了工作效率。早期的OCR技术多采用模板匹配算法[1],该类算法识别效率低,鲁棒性较差,容易受外界因素干扰。随着计算机与人工智能技术的发展,深度学习成为OCR技术的主流[2],其识别流程主要分为文本区域检测与文本内容识别两个阶段。连接文本候选网络[3](connectionist text proposal network, CTPN)是使用较为广泛的文本检测网络,其将文本检测细分为一连串小尺度文本框检测,提高了序列化文本框检测能力。卷积循环神经网络(convolutional recurrent nerual network, CRNN)[4]是主流的文本内容识别算法选择,其利用长短期记忆网络[4](long-short term memory, LSTM)、门控循环单元(gated recurrent unit, GRU)[5]等类循环网络的注意力机制,大幅提升较长、可变文本序列的识别效果。百度公司提出的PaddlePaddle-OCR[6]是当前市场最为流行的中文识别开源算法框架,其结合了基于可微二值化(differentiable binarization, DB)的文本分割检测网络[7]与基于双向LSTM(BiLSTM)的文本识别网络[4],采用轻头部网络、模型瘦身等策略,实现了精度与延时的平衡,在移动边缘端也能达到较好的识别效果。
随着轨道交通行业数字化与智能化的发展,专业场景OCR应用需求逐渐浮现。文献[8]结合YOLOv3目标检测算法与Tesseract5.0字符识别算法,实现了高铁摩擦片编码的识别应用。文献[9]结合YOLOv3目标检测算法与简单卷积神经网络分类器对轨道旁公里标进行识别,为探伤车位置校正提供精度与实时性保障。针对机车纸质检修记录单OCR识别需求,本文提出一种改进的基于PaddlePaddle-OCR的文本识别算法。其首先采用傅里叶变换与霍夫变换进行文本倾斜角度检测校正,然后依次使用以ResNet18为主干网络的DB分割模型进行文本检测,使用以ResNet34为主干网络、以深度BiLSTM为头部的识别模型实现文本内容最终识别,同时进行了消融实验研究。实验结果验证了该算法在检修记录单表头关键信息识别方面的准确性和有效性。
1 基础算法原理
本文对检修记录单的OCR识别主要涉及傅里叶变换文本倾斜角度检测方法[10]、以ResNet18[11]为主干与多尺度DB分割网络为头部的文本区域检测网络、以双向LSTM为头部与连接时序分类(connectionist temporal classification, CTC)[12]为损失函数的文本内容识别网络。
1.1 文本倾斜角度检测
傅里叶变换因旋转不变性在图像文本倾斜角度检测应用中拥有较好的鲁棒性。对于一幅待检测图像,首先对其进行二维离散傅里叶变换得到图像频谱,然后进行高低频谱交换来实现频谱移中。为降低零频谱幅值过大影响,取频谱幅值对数。设定阈值进行频谱二值化,利用霍夫变换检测二值化频谱图中直线的角度并以此作为图像文本的倾斜角度。
图1示出一幅纸质检修记录单文本倾斜角度检测过程,其中频谱二值化阈值为0.7倍最高频谱。

图1 检修记录单文本倾斜角度检测Fig. 1 Inclination angle detection of maintenance record sheet
1.2 文本区域检测网络
将DB模块引入基于语义分割的文本检测网络[7],可大幅提升一般场景文本检测的准确率与速度。标准二值化(standard binarization, SB)与DB可分别用式(1)和式(2)表示。相比标准二值化,DB由于其可微属性,使得图像文本语义概率图二值化模块能直接进行梯度反向传递,从而实现语义分割与后处理端到端的训练,最终提高文本语义概率图的预测准确率。
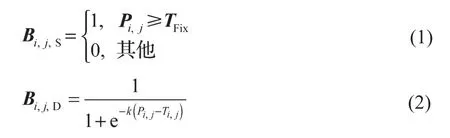
式中:Bi,j,S——标准二值化图数据矩阵;Pi,j——文本语义概率图数据矩阵;TFix——固定阈值;Bi,j,D——可微二值化图数据矩阵;k——放大比例系数,本文取k=50;Ti,j——自适应阈值图数据矩阵;i——水平方向坐标值;j——垂直方向坐标值。
图2为融入DB模块的文本检测语义分割网络[7]。以ResNet18主干网络为例,图像被输入网络,依次进入conv1_x, conv2_x, conv3_x, conv4_x和conv5_x,共5个阶段,每个阶段由相应数量的残差模块组成;连续得到5张特征图,宽高尺寸分别缩小为原图的1/2, 1/4, 1/8, 1/16和1/32。从1/4尺寸特征图开始,每张特征图会与下个尺寸的侧向连接特征图2倍上采样结果进行元素求和,获取该尺寸的侧向连接特征图,其中1/32尺寸特征图被直接作为本尺寸的侧向连接特征图;最后4张侧向连接特征图经过合并,得到用于语义分割的特征图。经过卷积与激活等相关算子计算,输出语义概率图与自适应阈值图,两者作为式(2)的输入可实现图像的二值化;基于二值化图,可求得文本框的精准位置。
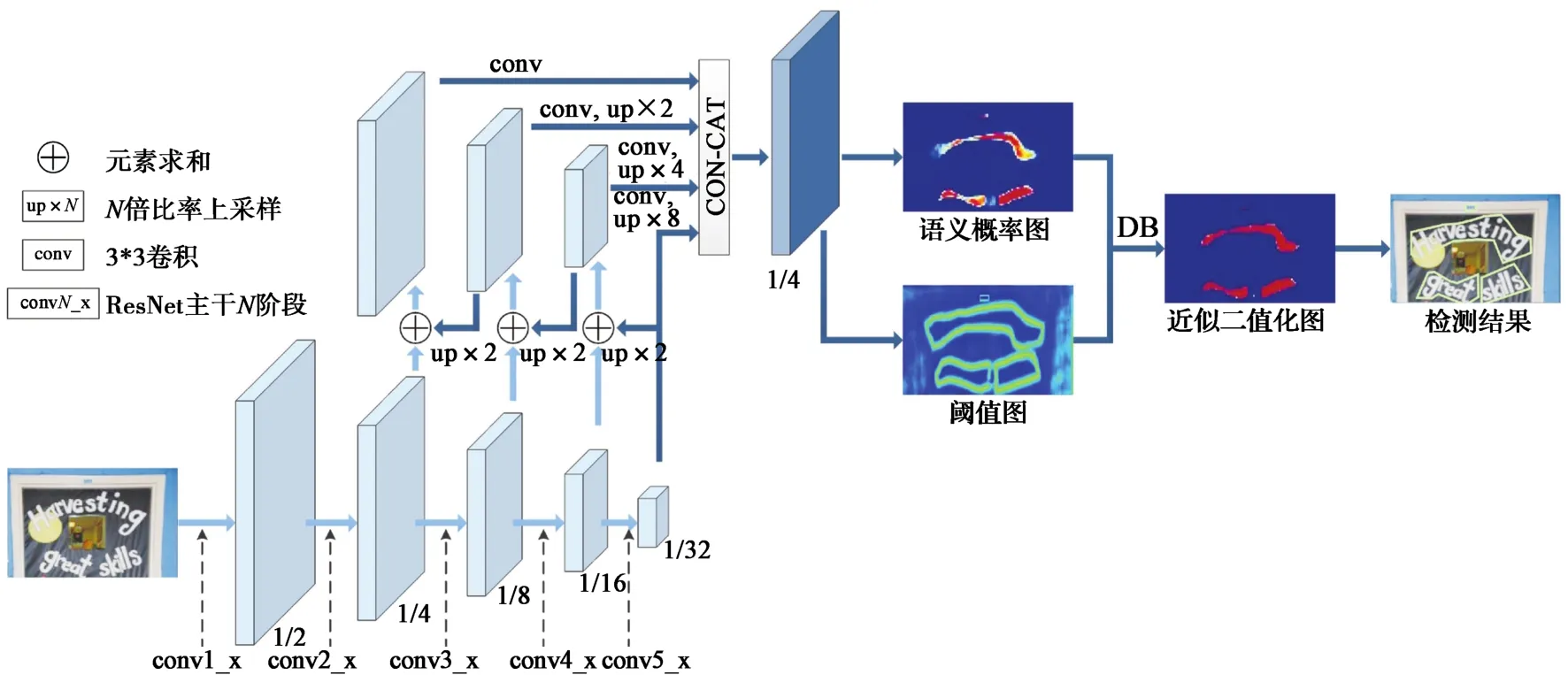
图2 基于DB模块的文本检测语义分割网络Fig. 2 Segmentation network for text regions detection based on DB module
1.3 文本内容识别网络
作为文本识别主流网络架构,CRNN[4]包含CNN卷积层与LSTM循环层,充分利用了序列图像的空间特征与上下文联系,大幅提升了文本识别的准确率与鲁棒性。以“轴箱检修记录”工单表头识别为例,图3所示CRNN文本识别网络[4]将文本区域检测网络检测出的文本裁剪图像输入CRNN网络中。首先,进入以ResNet系列为主干的卷积网络,提取多层卷积特征图。如图3中黄色虚线框所示,从左至右将特征图划分为“时间”连续的特征序列块,分别映射原始图像连续的视野区域。由浅入深地将映射同一视野的多层特征块连成一条特征柱,作为该“时刻”输入到循环神经网络的信号;特征块宽度取1像素,设计最后池化层,使得特征块高度为1像素。接着,将特征序列输入基于LSTM的循环神经网络以提取“时间”序列特征。相比单向LSTM,所采用的BiLSTM彻底兼顾了特征序列上下文联系,表征能力更强。最后,将循环网络预测结果输入转录层进行转录、识别,该层使用CTC算法,可实现单调对齐、多对一映射的识别并输出结果。如图3所示,循环网络预测结果为“-轴-箱箱-检修修记录录”,其中“-”为CTC算法设定的空位标志符,经过转录最终识别结果为“轴箱检修记录”。

图3 CRNN文本识别网络Fig. 3 Text recognizing network based on CRNN
2 机车检修记录单OCR识别
基于OCR的机车检修记录单文本检测识别流程如图4所示。在训练模式中,人工制作文本检测与文本识别数据集,分别用于训练文本检测与文本识别神经网络模型。其中,文本检测网络采用以ResNet18为主干、可微二值化特征金字塔网络(DB feature phyramid natwork, DB-FPN)为头部的分割网络;文本识别网络采用CRNN网络,其卷积层为ResNet18结构,循环层为深度BiLSTM结构。首先选择推理模式并输入检修记录单图像,利用傅里叶变换与霍夫变换方法检测图像文本倾斜角度。倾斜角度取值范围为 [0°, 90°],以倾斜角度是否落在 (10°, 80°)区间内作为文本倾斜程度判断标准。若落在该区间内,则认为倾斜较严重,需要采用仿射变换方法对图像进行旋转校正。接着,采用文本检测网络检测文本区域位置,输出可能的文本框位置坐标与置信度。文本内容识别模块依据前向传递的文本框位置进行图像裁剪,裁剪后的文本图像被输入到CRNN文本识别网络中,最终输出文本图像的文本识别内容。
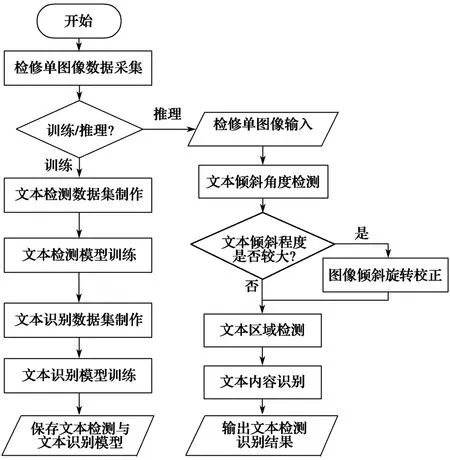
图4 机车检修记录单OCR识别流程Fig. 4 Flow of OCR for locomotive maintenance record sheet
3 试验结果与分析
3.1 机车检修记录单识别
本文基于所采集检修记录单图像,人工标注制作数据集。所制作的文本区域检测数据集有450张图像,样例如图5所示,其中训练集350张、验证集50张、测试集50张。基于此数据集,训练采用ResNet18为主干的文本区域检测网络,硬件为2块Nvidia Tesla V100显卡,训练轮次为500轮,单卡批次大小为16张图片。训练完成后,保存验证集精度最高的神经网络模型。

图5 文本检测数据标注样例Fig. 5 Annotation of text detection dataset
所制作文本内容识别数据集中有46 486张裁剪图像,样例如图6所示,其中训练集32 541张、验证集9 297张、测试集4 648张。基于此数据集,训练采用以ResNet18为卷积层主干的文本内容识别网络,硬件为2块Nvidia Tesla V100显卡,训练轮次为500轮,单卡批次大小为384张图片。训练字典为PaddlePaddle_OCR开源的包含6 623个字符的中文字典,单行最多识别字符数为56。训练完成后,保存验证集精度最高的神经网络模型。

图6 文本识别数据标注样例Fig. 6 Annotation of text recognition dataset
将文本检测与文本识别训练结果模型用于OCR识别推理。图7示出其中一张机车检修记录单识别结果。可以看出,检修记录单中关键表头信息“中修机车检修记录” “班组:中修组” “机辆机车检修-07”文本信息被精准识别。基于表头关键信息,可以实现检修记录单电子化图像的快速分类归档。检修记录单图片识别算法运行所用硬件为Intel(R)Xeon(R) Silver 4110 CPU @ 2.10 GHz。表1示出25张角度正常、图片尺寸为3742×2806的检修记录单识别结果。可见,表格印刷体与手写体文本都能被准确识别。
3.2 针对文本倾斜校正的消融实验
相比原有的PaddlePaddle_OCR,本文所提出的OCR识别流程增加了文本倾斜校正的过程。以PaddlePaddle_OCR V2.1.0公开的网络结构与推理模型为基准,针对文本倾斜校正的消融实验结果如图8及表2所示。可以看到,图像倾斜角度较大时,文本区域检测效果较差,这与分割网络中卷积层的像素视野方向局限性有关。在进行文本倾斜校正后,文本区域检测精度从0.445 2提升至0.877 9,关键表头信息准确率从0.260 8提升至0.882 7,证明了本文所提方法的有效性。推理耗时由倾斜角度检测校正时间、文本检测时间和文本识别时间这3部分组成。未进行倾斜校正时,由于检测出的待进一步识别的文本框较少,因此耗时必然会短些。


图8 针对文本倾斜校正的消融实验Fig. 8 Ablation study of image rotation with inclination angle

表2 25张倾斜检修记录单识别结果Tab. 2 Recognition of 25 locomotive maintenance record sheets with large inclination angle
3.3 卷积核尺寸与文本检测识别
本文OCR识别对象为纸质检修工单,与自然场景相比,其文本行文方向具有一定规则性,受卷积层感受视野方向局限性启发,可调整文本区域检测网络与文本内容识别网络的卷积核尺寸比例,探索不同卷积核尺寸对文本检测与识别结果的影响。
在文本区域检测网络中,原始主干网络ResNet18的卷积核尺寸为3×3(行文垂直方向×行文方向),修改后卷积核尺寸分别为3×5, 3×7,5×3和7×3。针对这5种尺寸进行模型训练与验证,将5个训练结果模型在测试集中进行泛化性能测试,结果如表3所示。可以看出,当卷积核尺寸为3×3或者3×5,文本检测效果更好。当卷积核沿文本垂直方向扩展或者沿文本方向扩展过长时,检测效果反而更差,这或许是因为本文纸质检修工单文本检测目标间距离较近,如图7 所示,多行文本紧密连接可能会影响单行文本检测效果。在相同检测效果下,相比卷积核尺寸3×5,卷积核尺寸3×3更适合产品应用,因为其参数量更少,计算效率更高。

表3 不同卷积核尺寸文本检测结果Tab. 3 Text detection results with different convolution kernel size
在文本内容识别网络中,原始主干网络ResNet18的卷积核尺寸为3×3(行文垂直方向×行文方向),同样修改卷积核尺寸分别为3×5, 3×7,5×3和7×3。针对这5种尺寸进行模型训练与验证,将5个训练结果模型在测试集中进行泛化性能测试。测试结果如表4所示,可以发现,几种卷积核尺寸文本识别精度接近。这表明文本识别网络对卷积核尺寸的敏感性比文本检测网络更低,这与其深度BiLSTM循环层有关,其联系上下文的输入输出非对称机制发挥了重要作用。

表4 不同卷积核尺寸文本识别结果Tab. 4 Text recognition with different convolution kernel size
4 结语
本文提出一种改进的基于PaddlePaddle_OCR的文本识别方法,其可实现机车检修记录单表头信息的精准识别与表格文本信息的准确识别以及检修记录单的快速分类归档,为后续表单细分场景深入研究提供数据基础。所提方法相比原版PaddlePaddle_OCR增加了文本倾斜校正流程,大幅提升了文本倾斜场景文本区域检测及相应文本内容识别效果。本文还探索了主干网络卷积核尺寸比例对文本检测网络与文本识别网络的影响。综合考虑检测精度与效率,文本检测网络卷积核尺寸优先选择3×3,文本识别网络则对卷积核尺寸不敏感。需要注意的是,本文方法对表格结构识别未能取得较好的效果,后续将对表格信息提取、数据结构化等方面进行进一步研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
China’s foreign Trade(2021年6期)2021-12-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
家庭影院技术(2020年2期)2020-03-25
下一代英才(2018年4期)2018-05-21
科学与财富(2018年9期)2018-05-14
商周刊(2016年22期)2017-09-30
BOSS臻品(2016年10期)2016-10-24
