
基于混合生成对抗网络的多视角图像生成算法
2022-01-09 10:23刘邵凡
自动化学报 2021年11期
卫 星 李 佳 孙 晓 刘邵凡 陆 阳
多视角图像生成指的是基于某个视角的图像生成其他视角的图像,该问题在实际生活中具有很多应用,例如:电商网站上商品的多视角展示、虚拟现实中的目标建模和和数据集扩充等.目前多视角图像生成已经吸引了来自计算机视觉、虚拟现实等众多领域研究人员的兴趣,并取得了一定的进展[1−5].
早期工作中,研究人员尝试使用变分自编码器(Variational autoencoder,VAE)[6]生成多视角图像.变分自编码器采用变分推断和深度表示学习来得到一个复杂的生成模型,从而摆脱了传统耗时的采样过程.但变分自编码器并不能很好地补充生成图像中的细节.此外,研究人员[7−8]还尝试先建立目标的3D 模型,再生成目标视角的图像,但这种方法的灵活性较弱,只适合于合成椅子、杯子等简单物体的图像.
近年来,有研究人员提出使用生成对抗网络(Generative adversarial network,GAN)[9]来生成多视角图像.在文献[4]中,研究人员将变分自编码器与生成对抗网络相结合,提出了一种面向服装的多视角图像生成模型VariGANs.VariGAN 模型将图像生成分为两步,采用由粗到精的方式生成高分辨率的多视角图像,本文模型也参考了这种由粗到精的生成方式.但VariGAN 模型局限于服装的多视角图像生成,并不能有效迁移至其他领域.
在文献[2]中,研究人员尝试在图像生成中引入语义指导,提出了两种多视角图像生成模型X-Fork和X-Seq.这两个模型将已知视角的图像与目标视角的语义分割图共同输入模型,填补了生成图像中的语义结构,使得生成的图像更加真实.受到文献[2]中工作的启发,文献[5]中的研究人员提出了一种基于多通道注意力机制的SelectionGAN 模型.SelectionGAN 模型将语义生成空间进一步扩大,模型通过参考生成的中间结果,进一步完善了图像中的语义细节,在卫星图与地面图的翻译任务中取得了很好的成绩.但以上的工作对于多视角生成任务中其他场景的兼容性较差,因为并不是所有场景下都有充足的语义分割图来进行训练模型.
为解决上述问题,本文提出了一种基于混合生成对抗网络的多视角图像生成模型ViewGAN,该模型可以灵活迁移至多视角生成任务中的各个场景.ViewGAN 包含多个生成器和一个多类别判别器,每一个生成器负责生成某一视角的图像.如图1 所示,模型分两步生成图像:1) 模型运用粗粒度模块(Coarse image module) 生成低分辨率(Low resolution,LR)下的目标图像;2) 在低分辨率目标图像的基础上,模型运用细粒度模块(Fine image module)完善图像的语义结构,生成高分辨率(high resolution,HR)下的目标图像.

图1 本文模型ViewGAN 在DeepFashion、Dayton 和ICG Lab6 数据集上的测试样例Fig.1 Examples of ViewGAN on three datasets,i.e.,DeepFashion,Dayton and ICG Lab6
本文的ViewGAN 模型与以往工作的不同之处在于:1) ViewGAN 包含多个生成器和一个判别器,每一个生成器负责生成某一视角的图像,这保证了ViewGAN 模型可以灵活迁移至各种多视角生成任务中,甚至还可以运用到图像翻译的其他领域,例如风格转换等;2) 为了加强图像生成过程中的语义约束,本文使用蒙塔卡罗搜索方法(Monte Carlo search,MCS)[10]对低分辨率目标图像进行多次采样,并根据采样结果计算相应的惩罚值,惩罚机制可以迫使每个生成器生成语义更加丰富的图像,避免出现模式崩塌(Mode collapse)[11];3) 模型中的多类别判别器使每个生成器更加专注于生成它们指定视角的图像,避免生成与其他视角相似的图像,从而进一步完善了图像的语义结构;4) 本文将ViewGAN模型与目前主流的图像生成模型(例如:Pix2Pix[12],VariGAN[4],X-Fork 和X-Seq[2],SelectionGAN[5])进行了对比,并在3 个公开数据集上进行了大量的实验,实验结果表明:本文模型在3 个数据集上都取得了最好成绩,这表明了本文模型的灵活性和生成图像的高质量.
综上所述,本文的主要贡献总结如下:
1) 提出了一种基于混合生成对抗网络的多视角图像生成模型ViewGAN,该模型包括多个生成器和一个判别器,采用由粗到精的方式生成不同视角下的高质量图像.
2) 提出了一种基于蒙特卡洛搜索的惩罚机制来加强图像生成过程中的约束,这使得每个生成器能够获得更充足的语义指导,在对应视角的图像中增加更多的语义细节.
3) 在3 个数据集上与目前的主流模型进行了大量的对比实验,实验结果证明了ViewGAN 在各种场景下的有效性与灵活性.
1 相关工作
1.1 图像生成
随着深度学习技术的发展,图像生成已经变成了一个热门的话题.变分自编码器(VAE)[6]是一种基于概率图模型的生成模型.在文献[13]中,研究人员提出了一种可由视觉特征生成图像的Attribute2Image 模型,该模型通过合成前景和背景来建模图像.之后研究人员[14]尝试在VAE 中引入注意力机制,提出了一种DRAW 模型,该模型在一定程度上提升了图像的质量.
近年来,研究人员在采用生成对抗网络[9]在图像生成方向取得了不错的成绩,生成器被训练生成图像来欺骗判别器,判别器被训练区分真实图像和虚假图像.之后大量基于GAN 的变体相继提出,例如条件生成对抗网络(Conditional GANs)[15]、Bi-GANs[16]、InfoGANs[17]等.GANs 还可以基于标签[15],文本[18−19]或者图[12,20−22]来生成图像.
但上述模型生成的图像普遍存在模糊、失真等问题,模型并没有学会如何生成图像,而是简单地重复训练集中图像的内容.本文模型也是一种基于输入图像的条件生成对抗网络,但本文模型凭借新颖的惩罚机制引入了更充足的语义指导,进一步完善了图像的语义结构,在一定程度上克服了图像失真的问题.
1.2 多视角图像生成
早期的研究人员通过对物体进行3D 建模来合成不同视角的图像[7−8,23].在文献[8]中,研究人员提出一种3D−2D 映射机制,从而使模型可以从2D 数据中学习到3D 特征.之后有研究人员[23]提出一种3D-GAN 模型,该模型可以依据复杂的概率空间生成3D 物体.
在文献[2]中,研究人员尝试使用图像翻译的方法进行多视角生成,使用条件生成对抗网络在卫星图-街景图转换任务中取得了不错的成绩.之后在文献[4]中,研究人提出了一种面向服装的多视角图像生成模型VariGANs.VariGAN 模型将图像生成分为两步,采用由粗到精的方式生成高分辨率的多视角图像.受到上述工作的启发,文献[5]中的研究人员提出了一种基于多通道注意力机制的SelectionGAN 模型.SelectionGAN 模型将语义生成空间进一步扩大,模型通过充分参考生成的中间结果,进一步完善了图像中的语义细节,在卫星图与街景图的翻译任务中取得了很好的成绩.
但上述模型对于数据的要求极为严格,模型需要大量的数据或者辅助的语义分割图进行训练,这大大限制了模型的灵活性和兼容性.为解决这个问题,本文提出了一种基于混合生成对抗网络的多视角图像生成模型,本文模型包括多个生成器和一个判别器,这使得模型可以同时训练生成多个视角的图像.大量实验结果证明,在不需要大量的数据或者语义分割图辅助训练的前提下,本文模型在3 个数据集上都取得了不错的成绩.
2 GAN 的相关背景
生成对抗网络(GAN)[9]包括两个对抗学习的子网络:一个生成器和一个判别器,它们基于最大−最小博弈理论同时进行训练.生成器G的目的在于将一个d维的噪声向量映射成一幅图像,并尽可能地使生成的图像接近真实图像;另一方面,判别器D用来鉴别图像是来自于生成器的虚假图像还是来自真实数据的真实图像.整个生成对抗网络的目标函数可表示为

其中,x表示由真实数据pdata采样得到的真实数据,z表示从高斯分布pz采样得到的d维噪声向量.
条件生成对抗网络(Conditional GANs)[15]通过引入辅助变量来控制模型的生成结果.在条件生成对抗网络中,生成器基于辅助信息生成图像,判别器基于辅助信息和图像(虚假图像或者真实图像)做出判断.整个网络的目标函数可表示为
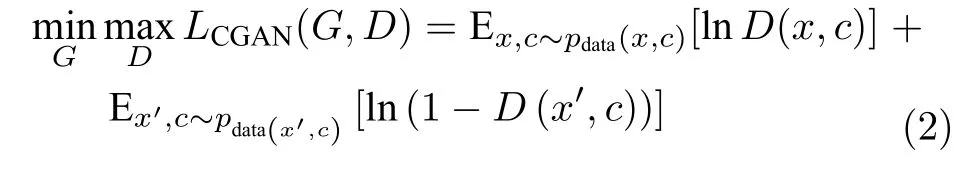
其中,c表示引入的辅助变量,x′=G(z,c) 表示生成器生成的图像.
除对抗损失外,以往的工作[20−21]还尝试最小化真实图像和虚假图像之间的L1 或者L2 距离,这能够帮助生成器合成与真实图像更加相似的图像.以往工作证明:相比于最小化L2 距离,最小化L1 距离更能够帮助模型减少图像中的模糊和失真,因此我们在本文模型中也使用了L1 距离.最小化L1 距离可表示为
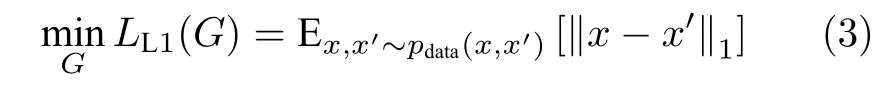
因此这类条件生成对抗网络的目标函数就是式(2)和式(3)之和.
3 ViewGAN 模型
3.1 任务定义
这里首先对多视角生成任务进行简短的定义.假设有一个多视角集合其中vi对应某一具体视角,例如正面或者侧面.一个物体在视角vi下的图像定义为给定某个视角的图像,多视角图像生成任务是指生成其他不同视角的图像,其中vj ∈V,ji.
3.2 整体框架
本文提出的ViewGAN 模型的整体框架如图2所示.假设我们要生成k种不同视角的图像(例如:正面、侧面和背面三种视角),我们使用k个生成器和一个判别器,其中分别表示第i个生成器和判别器的网络参数.表示从真实数据分布中采样得到的某一视角的图像,表示第i个生成器Gi生成的图像.
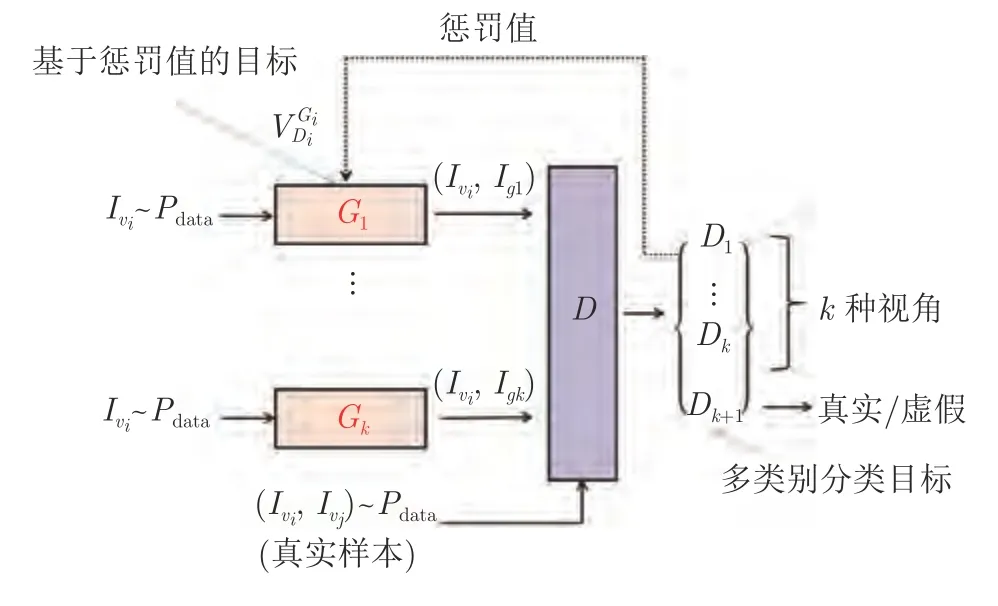
图2 ViewGAN 模型的整体框架Fig.2 The framework of ViewGAN
整个模型的训练可以分为两个对抗学习过程:生成器的学习和判别器的学习.第i个生成器Gi的目标是生成视角vi下的图像,并使得生成的图像能够欺骗判别器.换句话说,生成器的目标在于最小化合成图像与真实图像之间的距离.与之相反,判别器的目的在于尽可能的区分k种视角下的虚假图像和真实图像,并针对虚假图像计算出准确的惩罚值.
3.3 多粒度生成器
生成器的整体框架如图3 所示,图中展示的是第j个生成器.训练时中生成图像的过程分为3 步:1) 输入已知视角vi下的图像和目标视角vj下的图像,生成器首先使用粗粒度生成模块生成低分辨率的目标图像2)采用蒙特卡洛搜索策略对低分辨率目标图像进行N次采样,从而得到N幅中间结果图像;3) 引入注意力机制提取N幅中间结果图像的特征,并将注意力机制的输出与已知视角vi下的图像输入到细粒度生成模块中,细粒度生成模块生成最终结果,即高分辨率的目标图像.
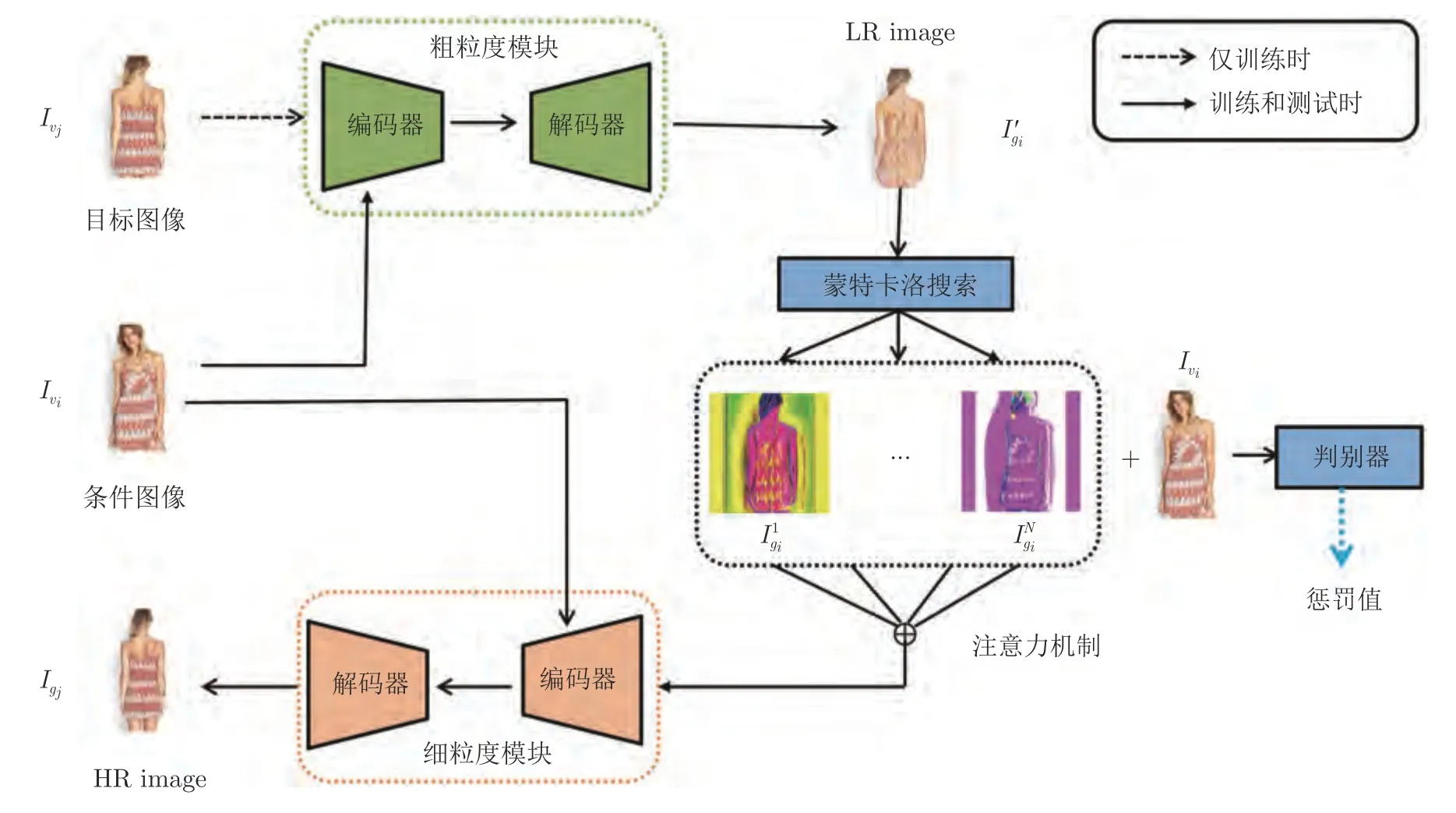
图3 生成器 ( Gj) 的整体框架Fig.3 The framework of the generator Gj
3.3.1 惩罚机制
为加强图像生成过程中的语义约束,进一步完善图像中的语义细节,我们提出了一种基于蒙特卡洛搜索策略的惩罚值机制.它使混合生成对抗网络中每个生成器更加专注于生成相应视角的图像.

之后,我们将N张中间结果图像和已知视角的图像送入判别器,根据判别器的输出结果计算惩罚值.计算过程可表示为

3.3.2 注意力机制
通过采样得到N幅中间结果图像后,我们希望参考中间结果图像为下一步的生成提供充足的语义指导.因此我们提出一种基于多通道的注意力机制,区别于以往工作中合成图像仅从RGB 三通道空间中生成的方法,我们将采样得到的N幅中间结果作为特征集来构建更大的语义生成空间,模型通过参考不同通道的信息来提取更加细粒度的信息.并将计算结果输入到细粒度生成模块中,从而得到高分辨率目标图像.

3.3.3 目标函数
综上所述,生成器通过最小化以下目标函数来不断优化

3.4 多类别判别器
参考文献[24]中有关半监督学习的工作,我们使用了一种多类别判别器用来区分不同视角下的真实图像和虚假图像,判别器的输入包括已知视角的图像和目标视角的图像.
3.4.1 目标函数
模型中包含k个生成器,每个生成器负责生成某一视角下的图像,所以判别器要输出k+1 种类的概率分布.前k个类别的概率值Di(i ∈1,···k)分别表示输入图像属于第i种视角的概率,第k+1个类别的概率值表示输入图像是虚假图像的概率.判别器通过最小化以下目标来进行优化
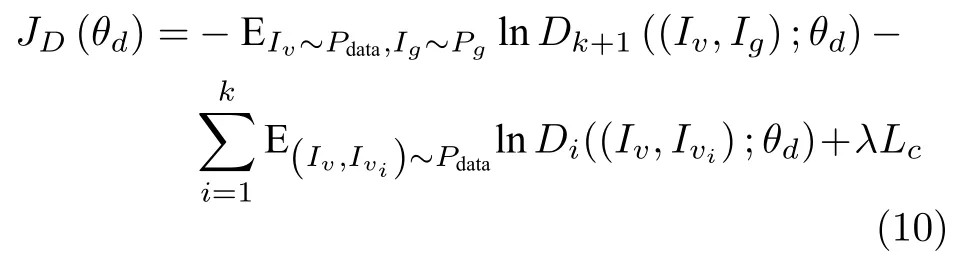
其中,Pg表示生成器生成的图像,Pdata表示真实数据分布.Iv表示任一视角的真实图像,Ig表示以Iv作为输入时生成器生成的图像,表示视角vi下的真实图像,Di(·) 表示判别器输出结果中第i个类别的概率值,Lc表示类内损失.下面详细阐述类内损失的含义,参数λ用于控制两种损失的平衡.
下面详细论述多类别判别器是如何协助每个生成器更专注于生成指定视角的图像,避免出现图像模糊或者模式崩塌现象.为了便于描述,这里使用X表示采样得到的图像对,例如虚假图像对(Iv,Ig)或者真实图像对
首先,理想情况下第i个生成器可以学习到视角vi下图像的真实分布.判别器的目标函数如式(9)所示,且=1,Di ∈[0,1],∀i.由此可以得到判别器学习到的最优分布:
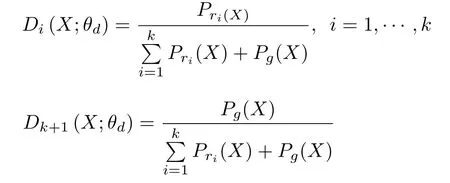
基于式(5),生成器的目标是最小化以下等式:

3.4.2 类内损失
判别器要对多个生成器生成的视角图像进行判断,而每个视角的图像之间具有一定的重合部分,仅采用GAN 网络对抗损失进行监督学习容易导致图像的视角类别预测错误,因此我们在对抗损失的基础上引入了类内损失用于减小类内特征差异,并增加类间差异.类内损失可表示为
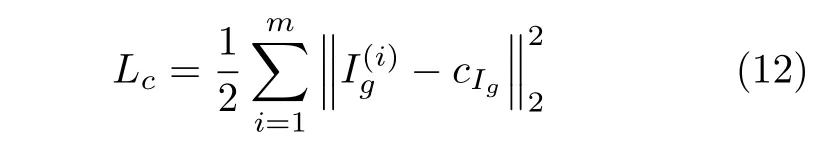

其中,δ(·) 是条件表达式,当vi=vj即当前图像属于视角vj时,条件δ(vi=vj) 为1,其他情况下条件δ(vi=vj)为0.
训练时将k个生成器与多类别判别器进行对抗学习,并交替训练它们,优化算法如算法1 所示.
算法1.ViewGAN 的对抗学习过程

3.5 网络结构
对于多视角生成问题,输入和输出之间存在大量底层特征共享,应该直接将特征在网络之间传递.为了解决网络特征传递问题,我们采用U-Net[25]作为生成器和判别器的基础结构并使用Conv-BNReLu 模块作为中间结构,网络结构如表1 和表2所示.其中CONV BLOCK 卷积块由3 个串联的卷积核大小为3 的卷积层和滤波器大小为2 的平均池化层组成,其中卷积层的步长等于1 并采用1 个像素填充;DECONVBLOCK 由2 个串联的卷积核大小为3 的卷积层和滤波器大小为2 的上采样层组成,卷积层的设置与CONV BLOCK 相同;HIDDEN LAYER 由1 个大小为3 的卷积核的卷积层组成.

表1 生成器网络结构Table 1 Generator network architecture
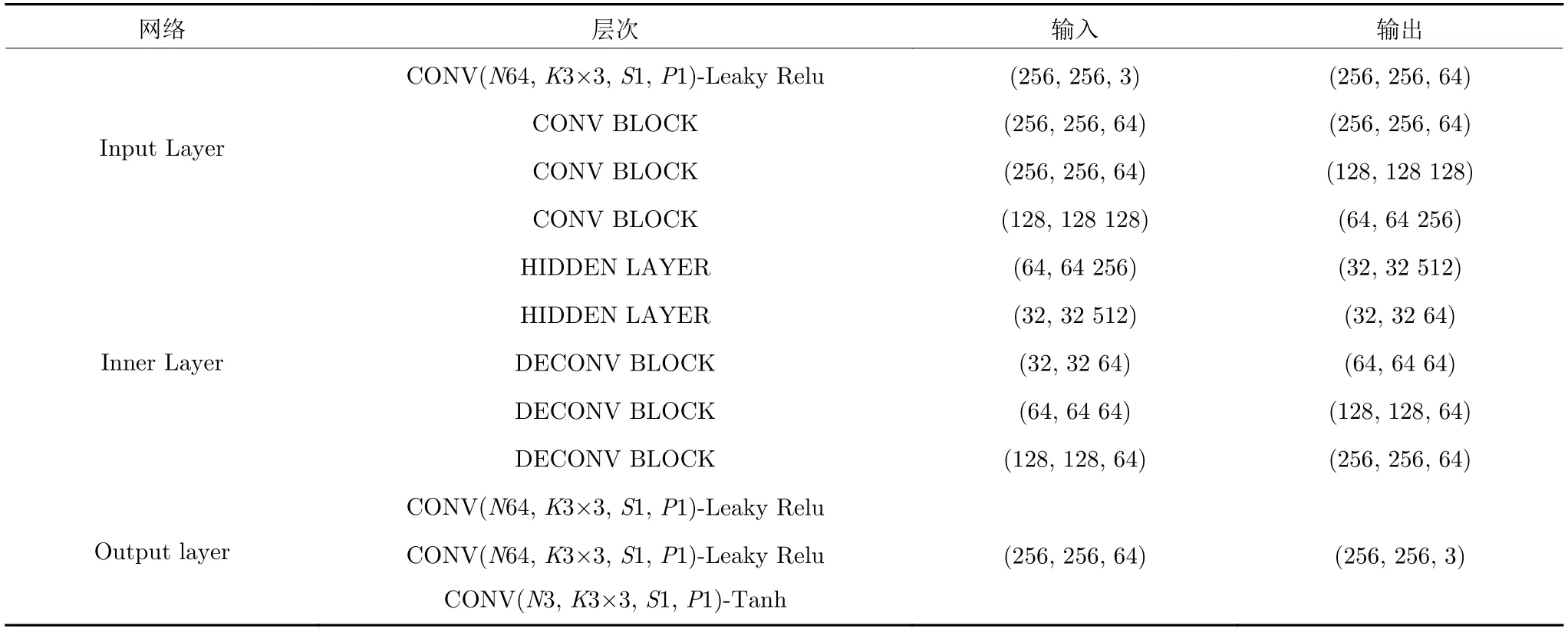
表2 判别器网络结构Table 2 Discriminator network architecture
U-Net 是一种在编码器和解码器之间具有跳跃连接的网络,这种网络结构允许更多的原图像纹理的信息在高层特征层中进行传播.对于每个生成器Gi,编码器第一层卷积层滤波器大小为64,解码器最后一层卷积层用于将通道数映射为输出图片通道数(彩色图片为3 通道,黑白图片为2 通道).除了编码器的第一层卷积层,其余所有卷积层后都连接BatchNorm 层进行特征归一化.
4 实验与分析
4.1 数据集
1) DeepFashion[26].该数据集包含8697 幅服饰的多视角图像,每件服饰具有三个视角:正面、侧面和背面.从中挑选出6000 幅图像作为训练集,2000幅图像作为测试集,图像尺寸为256×256 像素.
2) Dayton[27].该数据集包含超过13 万幅街道视角−鸟瞰视角的图像,从中挑选出55000 幅图像作为训练集,5000 幅图像作为测试集.图像的原始尺寸为354×354 像素,我们将图像尺寸调整为256×256 像素.
3) ICG Lab6[28].该数据集包含6 名人员的室内场景活动图,共使用4 个不同方位的静态摄像头进行拍摄.从中挑选6000 幅图像作为训练集,1500幅图像作为测试集.图像的原始尺寸为1024×768像素,我们将图像尺寸调整为256×256 像素.
4.2 基线模型
我们将本文模型与目前主流的多视角图像生成、图像翻译模型进行对比.
1) Pix2Pix[12].采用对抗损失学习从x∈X到y ∈Y的映射,其中,x和y分别表示不同域X和Y中的图像,在图像翻译任务上取得了较好成绩.
2) X-Fork[2].与Pix2Pix 结构类似,生成器通过学习映射:G:{Ia}→{Ib,Sb}来生成多视角图像.其中Ia,Ib分别表示视角a和视角b下的图像,Sa表示视角b下的语义分割图.
3) X-Seq[2].两个CGAN(G1,G2)的组合模型,其中G1 合成目标视角的图像,G2 基于G1 的输出图像合成目标视角的语义分割图.两个生成器之间的输入−输出依赖约束了生成的图像和语义分割图,有效地提升了图像的质量.
4) VariGAN[4].变分自编码器和GAN 网络的组合模型,采用由粗到精的方法生成高分辨率的多视角图像,在DeepFashion 等服饰数据集上取得了较好的结果.
5) SelectionGAN[5].在X-Seq 模型的基础上引入了一种多通道注意力机制来选择性地学习模型的中间结果,从而实现了一种由粗到精的级联式语义指导,使合成图像具有更丰富的语义细节.
4.3 定量评估
在定量实验中,我们采用Inception score[24],Top-k预测准确率指标从高层特征空间的角度来评估合成图像.此外,我们还采用一些像素级别的相似度指标来衡量生成的图像,包括:结构相似性(Structural similarity,SSIM)、峰值信噪比(Peak signal-to-noise ratio,PSNR)和SD (Sharpness difference).
4.3.1 Inception score 和Top-k 预测准确率
1) Inception score 指标.Inception score (IS)是一种面向生成模型的常见定量指标,它可以衡量模型生成的图像是否清晰、生成的图像是否多样.其计算式为
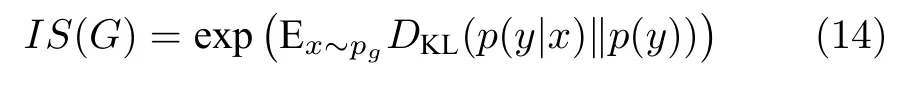
其中,G表示生成器,x表示生成的图像,y表示合成图像的预测标签.
因为Dayton 数据集和DeepFashion 数据集中包含了ImageNet 数据集[29]中未标注的户外物体类别和服装类别,所以不能直接使用预训练的Inception 模型.对于Dayton 数据集,使用在Places数据集[30]上训练的AlexNet 模型[31]进行评分;对于DeepFashion 数据集,使用预训练的PaperDoll[32]模型进行评分;对于ICG Lab6 数据集,采用在ImageNet 数据集上训练的Inception 模型进行评分.
同时我们注意到:这些预训练模型针对合成图像输出的置信度分数较为分散,合成图像并没有包含所有类别的目标.因此我们只在Top-1 和Top-5类别上计算Inception score,其中 “Top-1”表示每幅图像的预测标签中概率最大的k个标签不变,其余标签的概率进行平滑处理.
2) Inception score 评估结果.基于Inception score 的实验结果如表3 所示.从实验结果可以看出:本文模型ViewGAN在DeepFashion 数据集和ICG Lab6 数据集上均优于基线模型.其中Deep-Fashion 数据集的图像风格、服装样式等变化较大,以往模型很难生成这种多样性较强的图像,而本文模型通过采用分布式生成的方法,使模型有足够的内存来学习如何生成各种样式的服装以及同一服装不同视角下的变化.ICG Lab6 数据集的图像取自复杂的室内环境,对图像分辨率的要求较高.以往模型缺乏对图像细节的补充,导致生成模糊、失真的图像,而本文模型采用惩罚机制加强了对图像语义细节的约束,能够生成更加清晰的高质量图像.
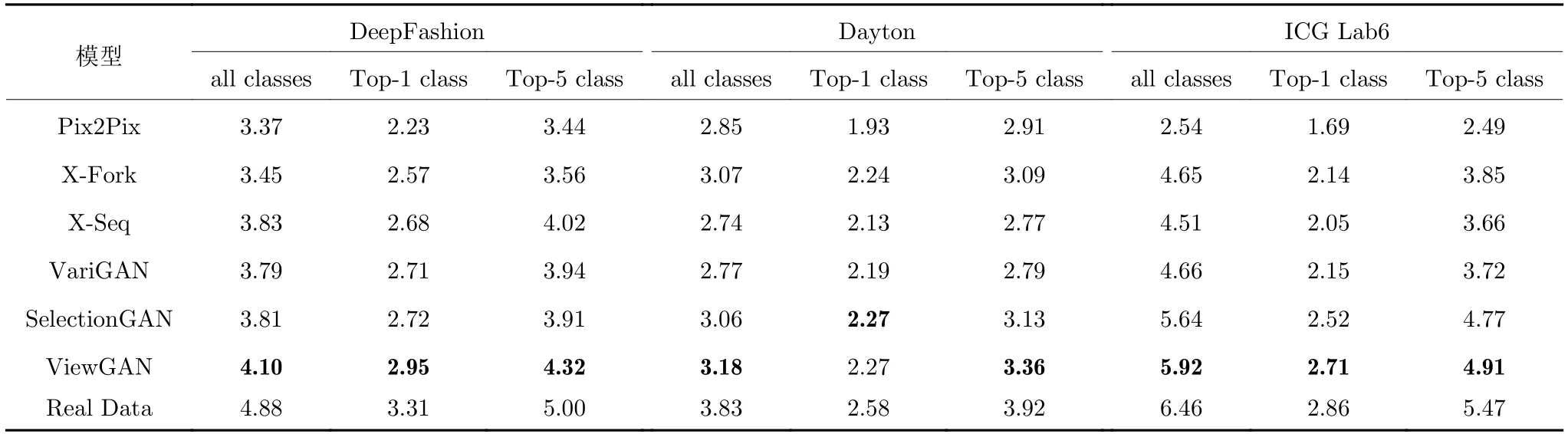
表3 各模型Inception score 统计表,该指标越高表明模型性能越好Table 3 Inception score of different models (For this metric,higher is better)
同时我们注意到ViewGAN 在Dayton 数据集下Top-1 类别的得分仅次于SelectionGAN.这主要是因为Dayton 数据集中的多视角图像是区别较大的户外图像,这种多视角图像生成任务具有较大的难度,SelectionGAN 中引入了目标图像的语义分割图来辅助生成,本文模型却没有引入外部知识.因此本文模型生成的图像具有一定的不确定性,从而导致图像中存在模糊的区域,但ViewGAN 的得分与SelectionGAN 的得分很接近,这也表明了本文模型的潜力.
3) Top-k指标.此外,我们还计算了真实图像和合成图像的Top-k预测准确率.我们使用与Inception score 同样的与训练模型来获得真实图像的标注和合成图像的预测标签.实验计算了Top-1 预测准确率和Top-5 预测准确率.每种准确率的计算方法有两种方法:a)考虑所有的测试图像;b)只考虑那些预测标签概率值超过0.5 的测试图像.
4) Top-k评估结果.基于Top-k的实验结果如表4 所示.由实验结果可知:本文模型在3 个数据集上的性能均优于基线模型,显著提升了预测准确率.这说明本文模型生成图像具有较高的清晰度、丰富的语义细节,在复杂多变的DeepFashion 数据集和Dayton数据集上表现出了较强的鲁棒性.
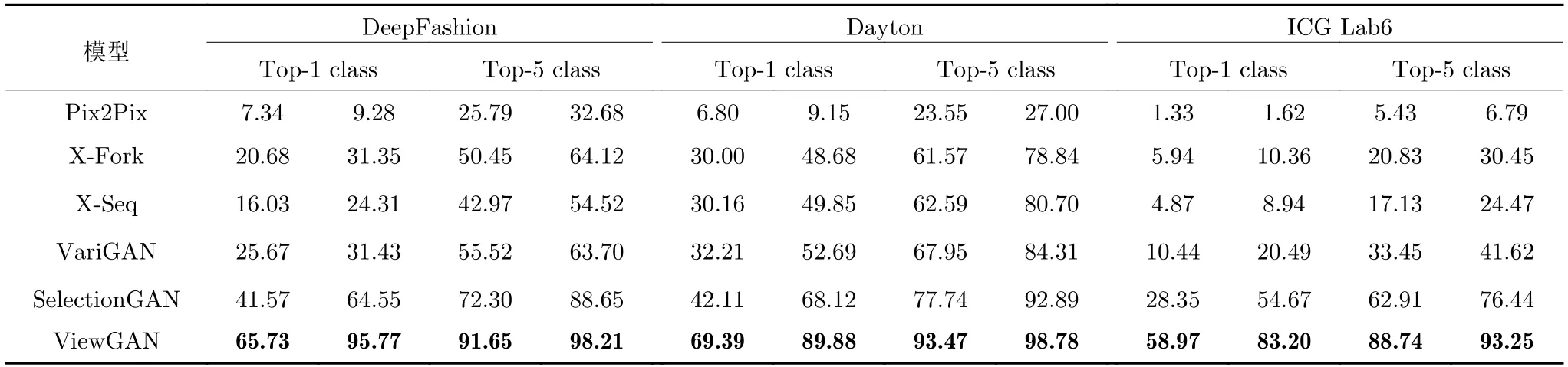
表4 各模型Top-k 预测准确率统计表,该指标越高表明模型性能越好Table 4 Accuracies of different models (For this metric,higher is better)
值得注意的是,本文模型在ICG Lab6 数据集上的准确率要略低于在其他两个数据集的准确率.这主要是因为ICG Lab6 数据集中的图像包含较多小目标物体,这对合成清晰图像来说本身就是一个很大的挑战,因此以往模型最高只达到了76.44%的准确率.而本文模型引入基于蒙特卡洛搜索的惩罚机制,充分利用了模型的中间结果,保证了图像具有更细致的语义细节,最高达到了93.25%的准确率.
4.3.2 结构相似性、峰值信噪比和Sharpness difference
1) 指标.参考文献[33−34]中的工作,我们利用结构相似性、峰值信噪比和SD (Sharpness difference)指标来衡量合成图像与真实图像之间的像素级相似度.
2) 结构相似性(SSIM).基于图像的亮度、对比度等属性评估图像之间的相似度,其取值范围为[−1,1],值越大则图像之间的相似度越高.结构相似性的计算式为
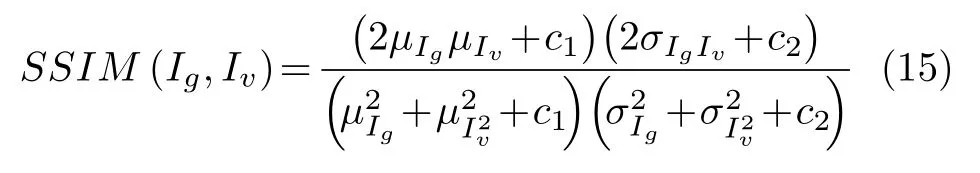
其中,µIg,µIv分别表示合成图像Ig和真实图像Iv的均值,,分别表示图像Ig和的标准差.c1,c2是为了避免分母为0 而引入的常数.
3) 峰值信噪比(PSNR).通过测量到达噪音比率的顶点信号来评估合成图像相对于真实图像的质量.峰值信号比越大,合成图像的质量越高.峰值信噪比的计算式为
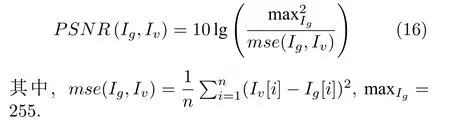
4) SD (Sharpness difference)测量图像生成过程中清晰度的损失,为了计算合成图像和真实图像之间的清晰度差异,我们参考文献[35]中的思路,计算图像之间的梯度变化
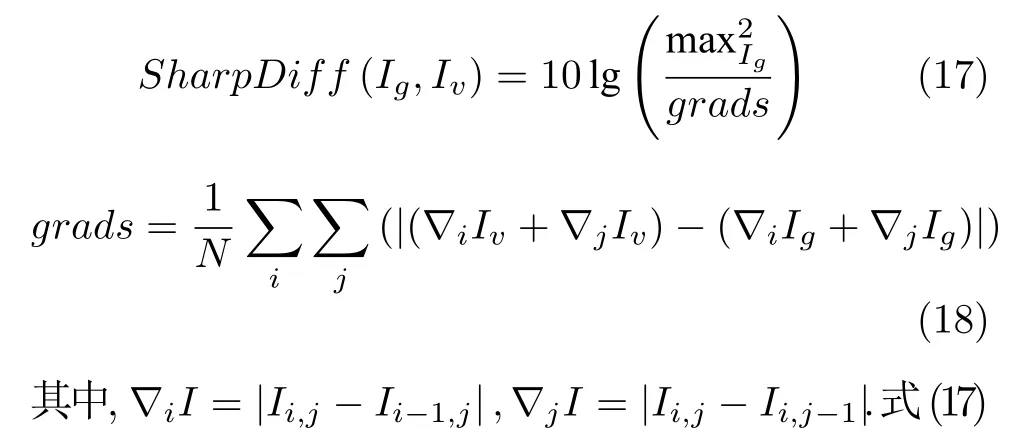
中的SharpDiff可看作是梯度的倒数,我们希望图像之间的梯度尽量小,所以SharpDiff就应该尽量大.
5) 结果.基于SSIM,PSNR,SD 的实验结果如表5所示.由实验结果可以看出:本文模型ViewGAN在3 个数据集上的得分均高于基线模型的得分.相比于目前主流的SelectionGAN 模型,本文模型ViewGAN 在ICG Lab6 数据集上的SSIM 分数提升了32.29%,SD 分数提升了10.18%,在DeepFashion数据集上的PSNR 得分提升了14.32%.
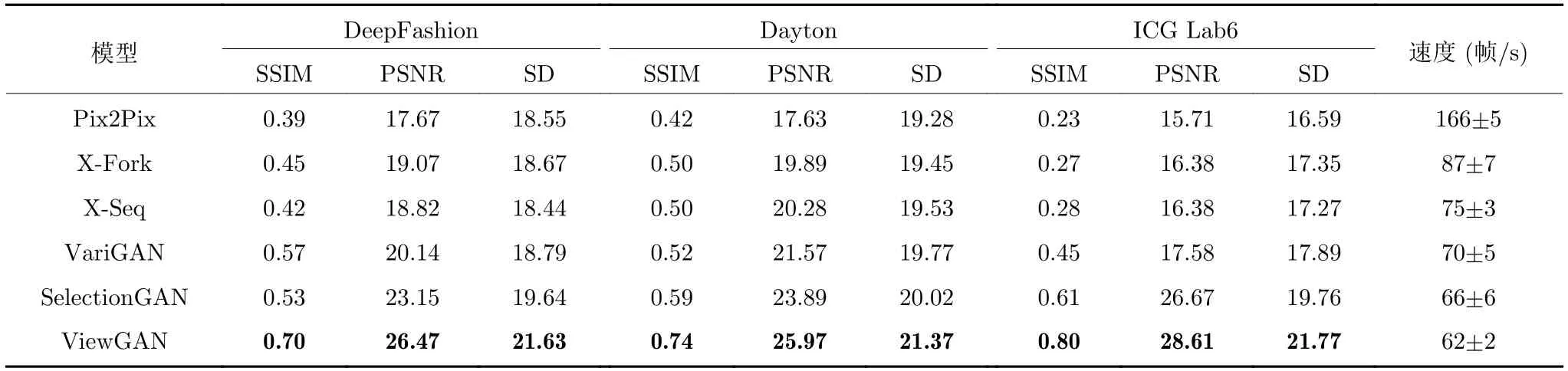
表5 各模型SSIM,PSNR,SD 和速度统计表,其中FPS 表示测试时每秒处理的图像数量,所有指标得分越高表明模型性能越好Table 5 SSIM,PSNR,SD of different models.FPS is the number of images processed per second during testing(For all metrics,higher is better)
上述定量实验结果证明:面向室内、室外等复杂环境,本文模型能够学会如何生成高质量多视角图像,而不是简单地重复训练集中的图像.这种分布式的生成方式使每个生成器专注于学习固定视角的图像,提出的惩罚机制能够进一步完善图像的语义细节,使得生成的图像更加逼真,显著地化解了图像中的人工痕迹.
6) 速度对比实验.为验证各个模型在速度上的差异,我们在Dayton 数据集上对各个模型测试时的速度进行了对比实验.实验结果如表5 所示,从实验结果看出:ViewGAN 的测试速度低于所有基线模型,这要是因为采用由粗到精的两阶段生成方法势必会造成计算量的增加,此外蒙特卡洛搜索耗时较多.但事实上,ViewGAN 和SelectionGAN 的速度差距不大,且62 帧/s 可以满足实际应用中的需要.
7) 最小数据量实验.为了验证训练集规模对于模型性能的影响,我们在DeepFashion 数据集上对ViewGAN 的最小训练样本量进行了探究实验.实验结果如表6 所示,从实验结果可以看出:随着训练集规模的缩小,ViewGAN 的性能下降较为缓慢.直至训练集规模缩小至60%时,ViewGAN 在各指标上的得分才低于基线模型SelectionGAN 在完整数据集上的得分,这表明ViewGAN 具有较强的鲁棒性,即使在小规模数据集上仍能学习到关键的特征信息,在一定程度上克服了以往模型泛化能力不强的缺点.

表6 最小数据量实验结果Table 6 Minimum training data experimental results
4.4 定性评估
在3 个数据集上的定性评估结果如图4~ 6 所示,测试图像的分辨率均为256×256 像素.从实验结果可以看出:本文模型ViewGAN 生成的图像更加清晰,有关物体或场景的细节更丰富.在Deep-Fashion 数据集中,以往模型易生成模糊失真的图像,ViewGAN 学会了如何生成多样性强的服饰图像,在服饰的图案、人物的姿态上具有更多的语义细节.在Dayton 数据集中,ViewGAN 能够生成更加自然的图像,图像中的房屋、草木和汽车都更符合实际,减轻了图像中的人工痕迹.在ICG Lab6数据集中,ViewGAN 在面对复杂环境时仍表现出较好的性能,图像中的桌椅、电脑等小目标都十分逼真,在清晰度方面非常接近真实图像.

图4 各模型在DeepFashion 数据集上的测试样例Fig.4 Results generated by different models on DeepFashion dataset
4.5 消融分析
为了分析本文模型中不同组件的功能,我们在DeepFashion 数据集上进行了消融分析实验.实验结果如表7 所示.由实验结果可知:相比于模型A,模型B 的性能更好,这表明由粗到精的两阶段生成方法能够更好地提升图像的清晰度.模型C 的性能得到进一步的提升,这是因为本文模型采用的混合生成对抗网络有效地扩充模型的内存容量,使得每个生成器更擅长生成指定视角的图像.模型D 通过引入类内损失促进了每个生成器的学习,在提升系统稳定性的同时提升了图像的质量.而模型E 的得分表明:而本文提出的惩罚机制显著提升了模型的性能,使模型在生成过程中得到了充足的语义约束,这大大增强了合成图像的清晰度和真实感.
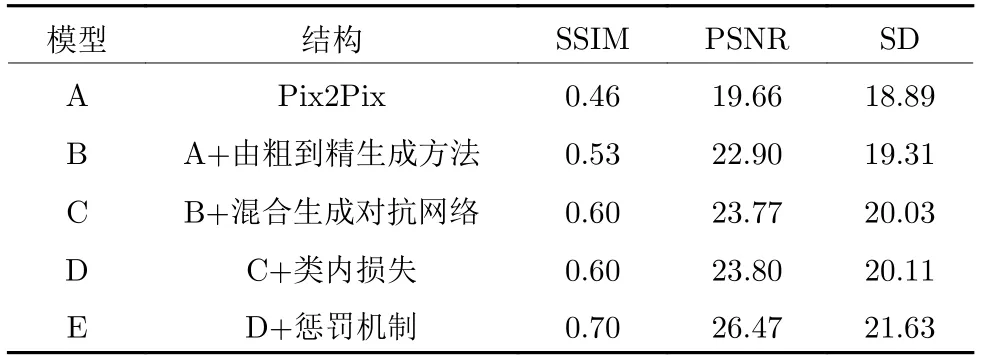
表7 消融分析实验结果Table 7 Ablations study of the proposed ViewGAN

图5 各模型在Dayton 数据集上的测试样例Fig.5 Results generated by different models on Dayton dataset
为进一步探索本文提出的基于蒙特卡洛搜索的惩罚机制,我们将ViewGAN 生成图像的过程进行了可视化,如图7 所示.从图中可以看出,低分辨率目标图像仅仅画出了人物的基本轮廓,缺乏服饰的细节.而利用蒙特卡洛搜索进行多次挖掘后,提取出了不同层次的语义信息,如服饰的蕾丝边、手臂的轮廓等,之后调用细粒度模块将这些语义信息填补到目标图像中,从而得到最终逼真的高分辨率目标图像.

图6 各模型在ICG Lab6 数据集上的测试样例Fig.6 Results generated by different models on ICG Lab6 dataset

图7 ViewGAN 生成图像的可视化过程((a)输入图像;(b)粗粒度模块合成的低分辨率目标图像;(c)蒙特卡洛搜索的结果;(d)细粒度模块合成的高分辨率目标图像)Fig.7 Visualization of the process of ViewGAN generating images ((a) The input image;(b) The LR image generated by coarse image module;(c) Intermediate results generated by Monte Carlo search module;(d) The HR image generated by fine image module)
5 总结与未来方向
本文提出了一种多视角图像生成模型ViewGAN,它可基于不同视角的图像合成新视角的图像.模型首先利用粗粒度模块生成低分辨率目标图像,之后利用蒙特卡洛搜索挖掘中间结果的语义信息,细粒度模块基于搜索结果合成高分辨率目标图像.在3个公开数据集DeepFashion,Dayton 和ICG Lab6上的定量实验与定性实验证明:相比于目前的主流模型,本文模型能够生成更加清晰的、多样性的目标图像.其中消融分析实验证明了本文提出的基于蒙塔卡罗搜索的惩罚机制显著提升了图像的质量.此外,本文模型可灵活迁移至多视角生成的各个场景,未来我们将进一步探索该方法在图像风格迁移、图像翻译等领域的应用.
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
数学年刊A辑(中文版)(2020年2期)2020-07-25
作文小学中年级(2020年6期)2020-07-24
开放教育研究(2020年2期)2020-03-31
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
自然资源遥感(2014年3期)2014-02-27
新课程学习·中(2013年3期)2013-06-14
