
融合药品语义的混合推荐算法
2022-01-09 05:19王瑞洋
计算机技术与发展 2021年12期
王瑞洋,李 涛
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
近些年,医疗水平极速发展,医药知识也渐渐得到普及。在网上或者门店购药的人越来越多。然而一种疾病表征对应着大量的药品。面对品类繁杂的药品,用户很难从中选择出对自己最具疗效的药品。另一方面,药店企业众多,同质化现象严重;药店做到个性化服务,从中脱颖而出。个性化推荐系统能够对大量的用户交互数据进行分析,挖掘出用户的资源偏好和不明确需求,实现信息资源的精准过滤和推送[1]。将推荐算法应用于药品领域,不仅能够帮助用户做出选择,解决用户的购药难题;而且还可以帮助药店企业实现智能信息化服务,吸引更多用户群体,增加药店的营业收入。所以,做好药品的推荐意义深远。
矩阵分解算法[2]不受专业领域知识的限制,可以使用各种形式的数据,因而应用广泛。但是矩阵分解算法没有合理地利用丰富的数据资源,不关注用户或者项目的属性信息及其所处的上下文环境。该算法训练模型使用的评分矩阵十分稀疏,导致训练后的模型精度不高,预测不准确,进而影响到后续的推荐效果。
针对数据稀疏这一问题,许多国内外科研人员结合具体的应用场景提出了对应的改进算法。文献[3]考虑了用户偏好的改变,并建立项目信任关系,改进了社交网络推荐模型;文献[4]认为评分相似的用户隐式特征向量也应该相似,因此在概率矩阵分解的过程中加入了用户约束矩阵来约束用户特征向量,同时使用卷积神经网络识别用户评论信息,缓解了项目特征向量上下文信息缺失的问题;文献[5]从用户和项目两个角度计算出用户偏好相似度和项目关联度来改进矩阵分解模型,使得推荐结果集不受数据稀疏问题的干扰;文献[6]使用了关联规则来分析高维数据,组合和重构高维特征,提高算法组合推荐的能力;文献[7]从用户群组的角度出发,计算出用户群组的相似性,实现了有效的群组推荐;文献[8]利用评分矩阵和标签矩阵联合监督,让概率矩阵分解模型可以学习到更多的标签信息,有效提高了算法的准确性。
虽然上述算法借助辅助信息优化了相关模型,有效缓解了数据稀疏性问题,但是它们只是简单地利用用户或项目的特征属性,没有深入分析所推荐项目的语义信息,导致模型学习到的特征与项目真实的语义不符,将上述算法应用在药品推荐时表现不佳。因此,文中提出了融合药品语义的混合推荐算法,以此来提高药品推荐的质量。该模型从类别和功能两个方面挖掘出药品的语义知识。首先通过构造药品类别标签矩阵计算出药品的类别关联度;然后使用卷积神经网络提取药品主治功能的文本特征;最后使用药品的类别关联度和主治功能特征约束矩阵分解过程。该模型联合了药品语义知识表示,在评分矩阵高稀疏性的条件下,也能够准确地预测出用户与药品的偏好关系,实现药品的精准推荐。
1 相关工作
1.1 矩阵分解
矩阵分解[9]认为每个用户和项目都有各自的特征,每个特征用向量表示,所有特征向量连接起来构成各自的特征矩阵,它们可以通过原始矩阵分解得到,不受其他因素的影响。同时还可以通过矩阵乘积的方式复现原始矩阵,填补原来矩阵中缺失的值进行推荐预测。概率矩阵分解(PMF)[10]是应用概率论的相关知识解释矩阵分解的过程,从而提升算法的推荐精度。PMF的概率图如图1所示。
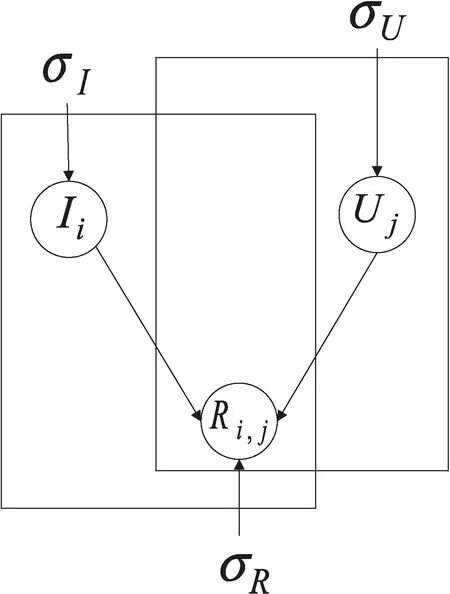
图1 PMF概率图
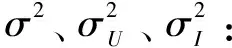
(1)
(2)
(3)
因此,依照概率论的贝叶斯公式,U、I的概率分布为:
(4)
将公式展开两边取对数,求极值即可得到隐因子特征矩阵U、I的解。
1.2 卷积神经网络
卷积神经网络(CNN)改变了传统神经网络,使用以下网络结构:
(1)卷积层,可以学习到局部特征,重用卷积参数;
(2)池化层,能够实现特征转换和参数降维。
CNN使用了不同大小的卷积核来提取输入数据的特征,有效减少了神经网络的参数;且每个卷积核只关注数据的一部分,因此可以更加准确地学习到局部特征。同时使用池化层对局部特征进行特征转化和采样,进一步缩小参数空间。
由于其出色的特征提取功能,人工智能的各大领域都在使用卷积神经网络。近年来,推荐算法研究者们也在不断地尝试优化推荐算法的模型。有研究者发现将神经网络加入到推荐算法中能够提高算法的精度。因此CNN网络也逐渐被使用在推荐算法领域。2016年Kim等首次将CNN使用在推荐算法中,提出了卷积矩阵分解模型[11]。Wang等为提高中文景点实体识别的准确性,使用CNN网络对文本中的信息进行抽取,学习到文本中的上下文信息[12]。Pelchat等[13]使用CNN网络来学习音乐的频谱和音符等特征,把从歌曲的时间片生成的频谱图图像作为神经网络的输入,将歌曲分为各自的音乐流派。
2 算法设计
PMF模型能够增加矩阵分解算法的可解释性和算法精度,但是忽略了项目的语义信息,重要特征缺失严重,导致推荐结果不精。不同于其他种类的商品,药品蕴含着丰富的专家领域知识。因此文中通过药品类别和主治功能文本挖掘出药品的语义知识,然后融合到PMF模型中,实现模型的更优化。
2.1 药品类别关联度
药品的分类属性是一个药品的重要信息。对药品进行分类,可以减小用户的选择范围,节约用户的时间成本。当用户购买一种药品时,首先会考虑此药品是否符合其种类需求,如:高血压类患者购买药物时首先会关注此药品是否为高血压类药物。假设药品的分类集合为F={F1,F2,…,Fn},n代表分类个数。因此可以得到药品-分类矩阵C。其中:药品个数用m表示,Fj代表药品Ii的第j个类别信息。如果Fj值等于1,则表示药品Ii属于该分类的药品;相反地,如果Fj值等于0,则表示药品Ii不属于该分类的药品。根据各个药品之间的类别标签矩阵,可以计算出推荐药品之间的类别关联度。药品Ii和药品Ij之间的类别关联度计算公式为:
(5)
其中,FIi,k表示药品Ii是否属于第k个分类,CIi,Ij表示药品Ii和药品Ij的类别关联强度,CIi,Ij的值越大说明两个药品在分类上越相近,CIi,Ij可以在[0,1]之间取值。得到药品之间的类别关联关系,即可以构造一个(m×m)维的药品类别关系矩阵C'。对于药品类别关系矩阵C',其后验概率分布可以表示为:
(6)
其中,g(x)=1/(1+exp(-x))为sigmoid函数,是为了确保高斯分布的均值μ的取值范围在[0,1]之间;Iij指数表示推荐药品Ii和Ij的类别关联关系,如果CIi,Ij为0,则Iij也为0;如果CIi,Ij不为0,Iij的值等于1。
通过上述公式便可以得到药品的类别关联度关系及其矩阵的贝叶斯概率分布。现实场景中,在使用概率矩阵分解进行药品推荐时,模型训练得到的药品隐因子特征同样应该符合药品的类别关联关系。因此,文中将药品的类别关系矩阵C'加入到PMF模型训练的过程,约束在原始评分矩阵高度稀疏的情况下,药品隐因子特征在类别语义上的正确性。此时,如果只考虑药品类别信息对模型的影响,对PMF模型进行优化,便可以得到联合药品类别的PMF模型。其概率图如图2所示。
在以上模型中,药品特征矩阵I加入了药品的类别信息,新的概率公式可以表示为:
(7)
上述模型加入了药品类别信息的约束,补充了药品的部分语义,来改善模型的性能。但是药品的类别信息无法完整地表达出药品的语义知识,还缺少药品主治功能的文本信息。因为在医药领域,类别和功效才是药品语义的完整表示。
2.2 药品主治功能文本特征
即使是同一类别的药品,在功能功效上也会存在着细微的差别。正如平时所看到的说明书一样,药品的功能效用主要以文本的形式存储。其文本描述包含了大量的专业术语、关键性词汇等,表达简约主题鲜明。因此,如果能够得到药品功效的数学表示,将其加入到PMF模型中,约束药品隐因子向量,就可以进一步优化文中算法。
为了获取药品主治功能的语义特征,文中预处理药品的主治功能文本,拿到关键性的词句:(1)对药品主治功能文本分词;(2)去掉停用词、符号;(3)提取关键词,将文本长度设置为k个单词长度。
对药品主治功能文本预处理后,使用CNN来提取药品功能文本中深层次的语义信息,从而生成药品主治功能的特征向量表示。CNN网络结构如图3所示。
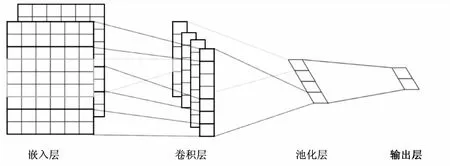
图3 CNN结构
(1)输入层/嵌入层。
输入层/嵌入层将预处理后的药品主治功能文本词序列转化为文本矩阵,作为下一层卷积层的输入。预处理后的一个药品的功能文本是由l个单词构成的序列。首先利用单词嵌入模型将每个单词转换为数字向量;然后药品功能文本的词向量可以连接起来,形成一个矩阵。
该矩阵可被表示为:
D=[d1,d2,…,di,…,dl]∈Rl×k
(8)
其中,l为单词的个数,也即药品功能文本的长度,di表示一个单词嵌入后的词向量,k为每个药品词向量的嵌入维数。
(2)卷积层。
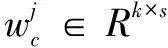
(9)
这里,选用relu作为激活函数;*是卷积操作,D:,i:i+s-1表示滑动窗口取得的药品局部特征,输入是药品功能文本矩阵D第i到i+s-1列的词向量。通过上式可以得到药品深层次语义文本特征向量ci:
(10)
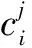
(3)池化层。
将卷积运算后得到的药品功能文本特征输入到池化层,进行max-pooling池化,其目的是固定药品功能的特征长度,实现特征卷积的不变性。
x=[max(c1),max(c2),…,max(ci),…,max(cl)]
(11)
其中,x表示经过池化层池化后的药品功能特征;ci表示卷积后的药品功能特征向量。
(4)输出层。
输出层的输入是池化层输出的结果,通过神经网络全连接层使用非线性投影产生药品功能文本语义特征向量。其中,第i个神经元的权重是wi,第i个神经元的偏执是bi:
S=relu(wl·…·relu(w1·x+b1)+…+bl)
(12)
综上所述,药品的功效文本通过多层网络操作,被转为数学向量,作为最终的特征向量输出。文中将上述过程表示为一个函数,该函数接受药品原始功能的描述文本作为输入,输出药品功能特征向量,用于约束矩阵分解后得到的药品隐式特征值:
tj=cnn(P,Xj)
(13)
因此,对于药品隐因子特征矩阵I,其条件概率分布应满足:
(14)
2.3 模型优化
在使用PMF模型进行药品推荐时,由于评分矩阵稀疏性问题,得到的药品隐式特征不符合药品的真实语义。利用错误的药品特征进行推荐便丢失了原有的精度。

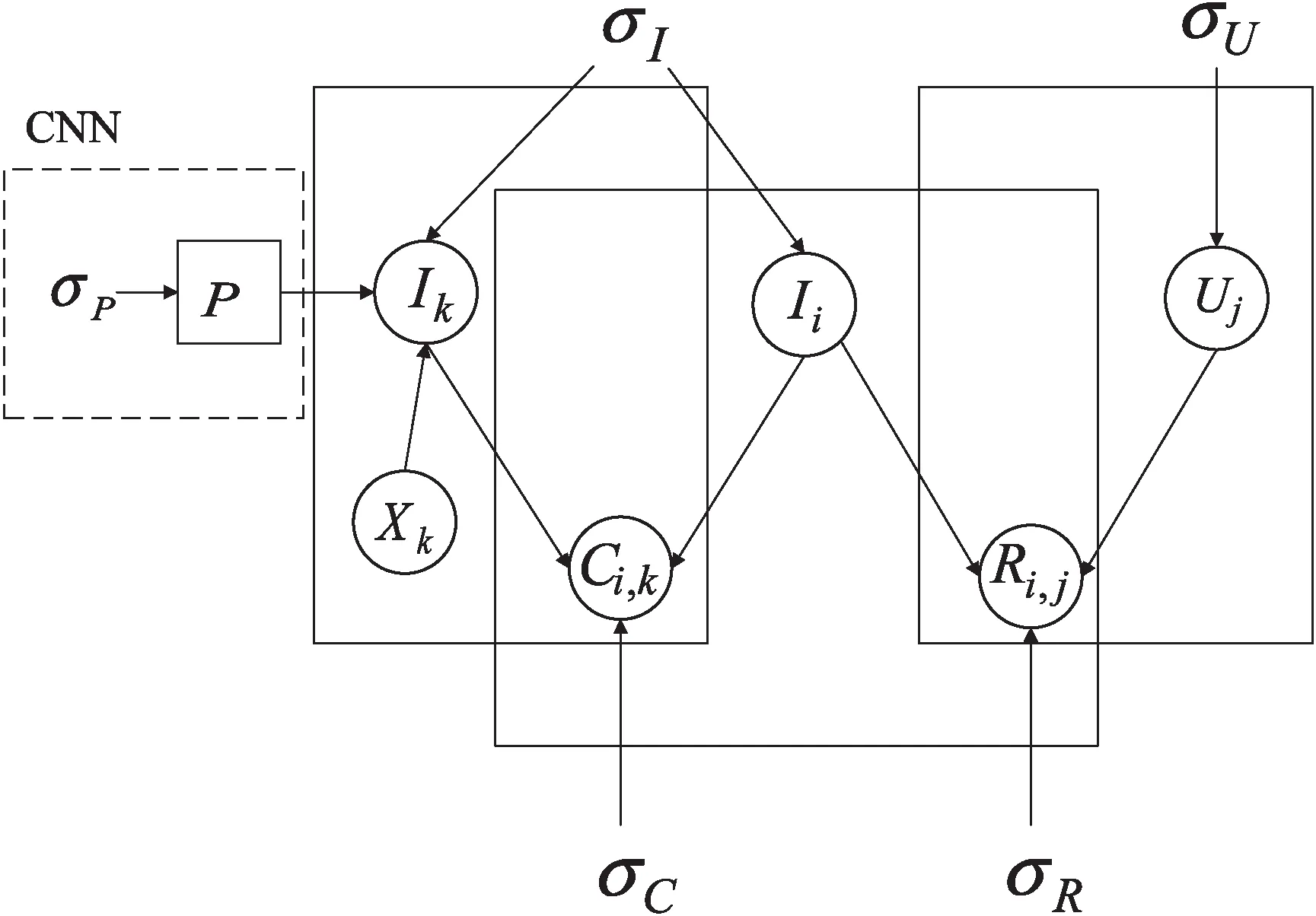
图4 H-DS概率图
根据贝叶斯公式,联合药品的类别标签和主治功能特征两方面的语义信息,U、I的后验概率分布可以表示为:
(15)
为了求解U、I,首先对以上概率公式取对数,然后约简式子可得损失函数为:
(16)
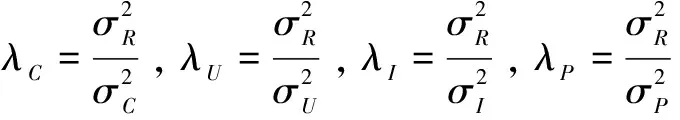
有了损失函数,便可以对Ui和Ij求偏导,分别得到对应的偏导函数:
(17)
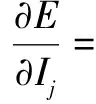
λI(Ij-cnn(P,Xj))
(18)
根据用户和项目隐向量Ui和Ij的偏导函数,文中使用梯度下降法[14]对用户和项目隐向量Ui、Ij交替更新,反向传播算法更新CNN网络,来优化模型。
2.4 算法流程
文中算法的整体流程可概括如下:
算法:融合药品语义的混合推荐算法(H-DS)。
输入:用户-药品评分矩阵、药品的分类信息以及主治功能文本;
输出:用户-药品组合对的喜好预测值。
步骤1:根据药品分类信息构造药品分类矩阵,使用公式(5)计算药品间关联度。
步骤2:预处理药品主治功能文本数据,提取文档中的关键词,使用词向量模型将单词编码成向量,经过CNN模型得到最终的特征。
步骤3:在满足高斯分布的前提下,将用户和药品的特征矩阵进行初始化。
步骤4:固定药品特征矩阵,计算用户特征向量与药品特征向量乘积与原始评分的误差,根据公式(17)使用梯度下降的方式更新用户特征向量。
步骤5:固定用户特征矩阵,计算用户特征向量和药品特征向量乘积与原始评分的误差以及药品特征向量与类别关联度、主治功能文本特征间的误差总和,根据公式(18)使用梯度下降的方式更新药品特征向量。
步骤6:重复步骤4和步骤5,持续训练模型。观察损失函数(16)的变化情况,待其不在大幅波动。
步骤7:输入用户和药品ID,得到H-DS算法的预测评分值。
3 实验结果与分析
3.1 数据集和评价指标
文中的实验数据来源于某连锁药店提供的线上真实销售数据。这些数据反映了该药店的一个门店在半年之内主营药品的销售情况,包含了325个主营药品、26 937个会员、94 817条消费记录,数据稀疏度为98.9%。实验时随机划分数据集。文中选用的估算模型预测准确性的指标有:平均绝对误差MAE和均方根误差RMSE。定义如下:
(19)
(20)
在公式(19)和公式(20)中,n表示测试数据样本空间大小,pi表示使用算法产生的预测评分,ri表示用户和药品的真实交互值,可以是评分、购买等行为表示。如果算法的性能很好,那么相应的MAE和RMSE值应该越小。
3.2 参数设置
模型的参数直接影响着模型的学习能力,选取合理的参数值能够极大地提高模型的精度。本节主要针对参数λC、λI、λU以及隐因子特征维数d进行实验,估算最优的参数组合。
图5显示了隐因子特征维数d在RMSE和MAE这两个指标上对H-DS算法的影响趋势。MAE和RMSE的值随着参数d的变化而变化,维数d的值越大,其对应的误差值越小。因为特征维数越高,用户和药品特征矩阵就越大,特征分类越具体;当参数d达到70之后,MAE和RMSE逐渐稳定了下来,在一定的范围内持续波动,因此本算法的参数d设置为70。
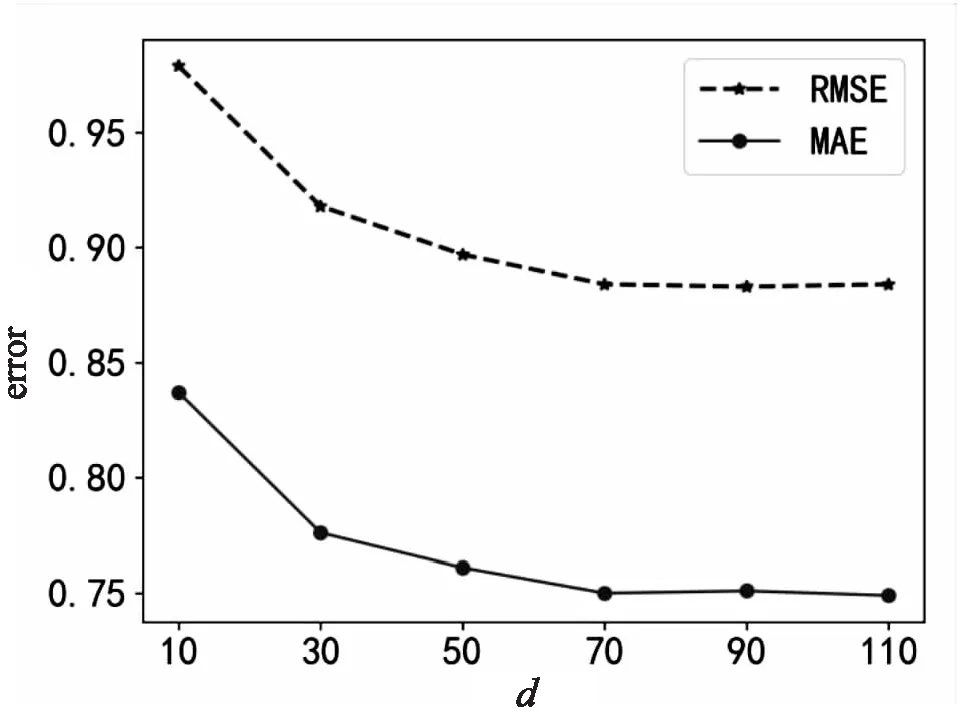
图5 参数d对文中算法的影响
图6~图8分别显示了参数λU、λC、λI对算法的影响。在图6中,当λU增大到1时,MAE和RMSE的值渐渐减小;当λU大于1之后,MAE和RMSE的值又逐步增大;在λU=1处,误差取得最小值。从图7和图8可以看出,MAE和RMSE对参数λC和参数λI十分敏感,说明融入药品语义对算法的性能十分重要。图7中MAE和RMSE的值刚开始迅速缩小,而后缩小趋势减弱最后趋近于稳定。图8中显示λI对文中算法的影响与参数λU类似,随着λI的变化MAE和RMSE同样先减小后增大,当λI=0.1时,MAE和RMSE值最小。
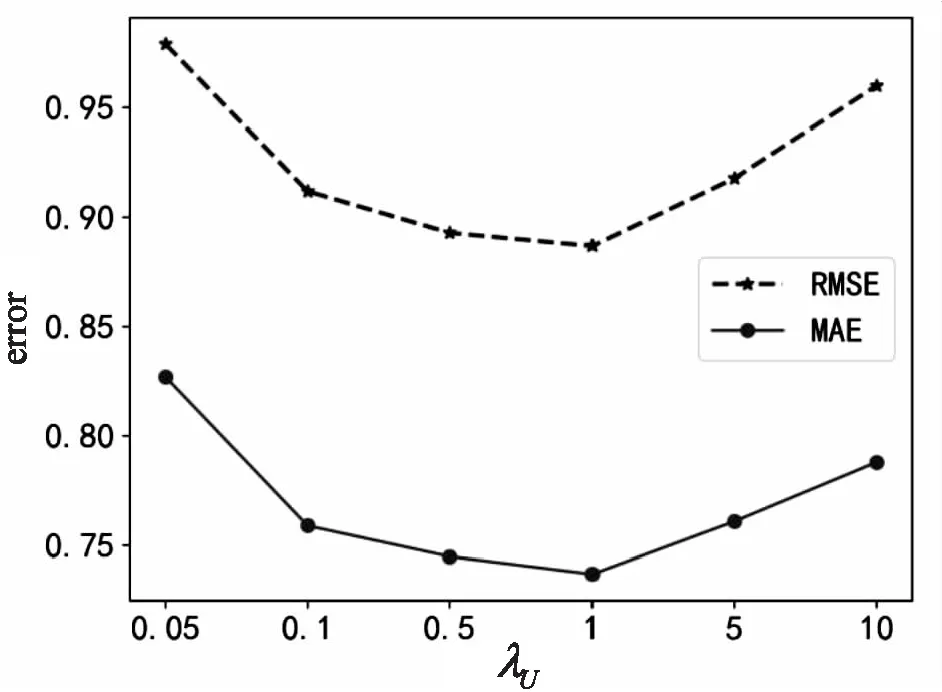
图6 参数λU对文中算法的影响
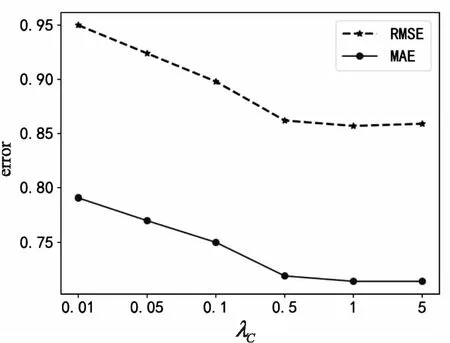
图7 参数λC对文中算法的影响

图8 参数λI对文中算法的影响
在分析了上述超参数对文中算法的影响后,最终将参数的值设置如下:d=70、λU=1、λC=1、λI=0.1。然后进行不同算法的对比实验,进而分析出各种算法的性能。
3.3 实验结果
文中旨在解决由数据稀疏性导致的药品推荐不准确问题,提出一种包含了药品语义的模型。此方法主要考虑了药品语义的两方面内容:类别关联度和主治功能文本特征,采用了矩阵分解和卷积神经网络的相关技术。
为了更加准确地评估算法(H-DS)的性能,设计了几组对比实验,比较的方法有:
(1)PMF[10]是最原始的概率矩阵分解算法。该算法使用概率论来解释推导模型。
(2)ConvMF[11]在模型中加入了评论文本的特征,约束项目隐因子特征,保证模型的准确性。
(3)CTR[15]是一个混合模型,其将主题模型(LDA)和PMF算法结合,综合考虑了用户评分信息和用户对项目的描述文字信息。
(4)CDL[16]是一种结合了栈式降噪自编码(SDAE)的算法模型,该模型部分利用了辅助信息,以此来提高推荐精度。
与以上方法进行对比,实验结果如表1所示。
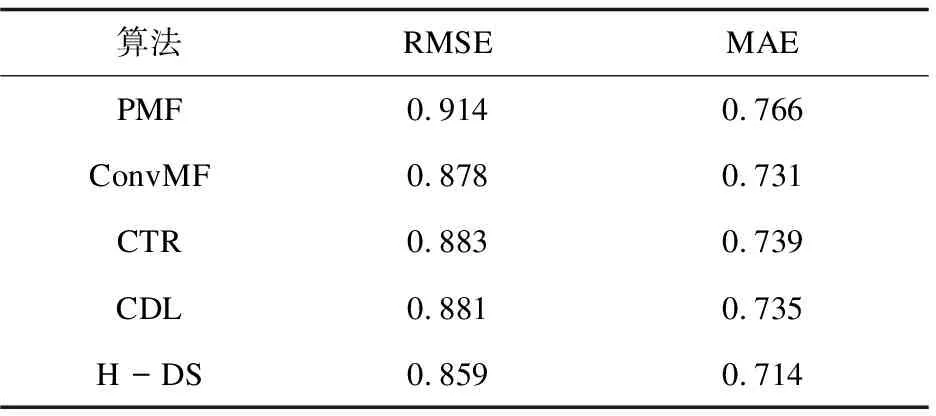
表1 实验结果
通过上述实验结果可以看出,提出的推荐算法H-DS要优于实验中的其他推荐算法,在药品推荐领域表现更优。H-DS相较于基本的概率矩阵分解算法(PMF)在MAE和RMSE评估指标上分别提升了6%和7%,性能提升最为明显。CTR、CDL、ConvMF三种算法在数据集上的表现相近,均优于PMF。它们都是PMF的改进模型,使用了药品有关的部分特征属性。H-DS与CTR、CDL、ConvMF相比,降低了2%~4%左右的误差值。说明,虽然CTR、CDL和ConvMF三种模型也使用到了药品的特征,但是对药品的数据信息利用较为简单。H-DS更加充分地挖掘了药品的语义信息,将药品的语义知识很好地融入到模型中,有效提升了药品推荐的精度。
4 结束语
把现有推荐算法应用在药品推荐领域时,算法原有精度的丢失,无法满足药品推荐要求。因此文中提出了新的改进方法。该方法从两个方面挖掘药品的语义信息:首先使用药品类别信息构造药品分类矩阵计算出药品间的类别关联度,然后为了提取药品主治功能文本内容中的语义特征,把卷积神经网络使用到推荐算法中;把概率矩阵分解作为基础模型,同时融入药品的类别关联度和主治功能文本语义来训练模型,学习药品更深层的特征。实验表明,该算法充分挖掘了药品的语义信息,降低了模型误差,推荐效果更好。但是,该算法主要使用药品信息改进算法模型,具有一定局限性。未来将研究用户属性和时序行为对药品推荐的影响,并将用户行为和药品语义结合在一起,进一步提高药品推荐的精度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
少儿画王(3-6岁)(2020年4期)2020-09-13
上海师范大学学报·自然科学版(2019年5期)2019-12-13
东方教育(2018年20期)2018-08-22
长江学术(2015年1期)2015-02-27
微型计算机(2009年4期)2009-12-23
