
面向政府公文的关系抽取方法研究
2022-01-09 05:19崔从敏施运梅李云汉李源华周楚围
计算机技术与发展 2021年12期
崔从敏,施运梅,袁 博,李云汉,李源华,周楚围
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2.北京信息科技大学,北京 100101)
0 引 言
随着政务大数据化的快速发展,公文文本数据存在量大、增速快、类型多、处理复杂的特点,但是目前处理数据主要依赖于传统的人工方式,效率低、准确率低,具有时延性,为政府办公带来许多挑战,消耗了巨大的人力财力,所以如何准确挖掘出其中的关键信息愈加重要。
现阶段在政府公文领域中应用NLP技术,可以将非结构化的自然语言文本转化为结构化的信息,从而挖掘出文本中潜藏的有价值的内容,减轻人工压力。NLP的一个重要的子任务就是实体关系抽取,将非结构的文本语句转换为知识三元组,用简单的数据结构解释文本中的实体关系。基于监督学习的方法虽然可以通过训练数据抽取特征,但过程中要达到期望的准确率和召回率需要大量的人工标注数据来辅助训练。在现如今数据量大、类型多的大背景下,基于远程监督的关系抽取方法因其省去了大量的人工标注加上其能够在不同领域适用的特性,已成为目前研究热点。
近年来,深度学习方法被广泛应用到实体关系抽取任务中,其通过对实体的位置信息进行向量化表示,来提供神经网络自动提取的文本特征,继而预测实体中的关系类型。基于RNN、CNN、LSTM的方法为其中三种代表方法,但这些神经网络模型通常在关系分类中没有充分考虑标记实体及其位置信息,而实际上实体的位置信息在关系分类中起到非常重要的作用。此外,CNN还需要大量的人工标注语料库进行训练才能达到良好的分类效果。因此,有研究将胶囊网络应用于实体关系抽取,其不需要大量标注的数据集就可以取得不错的效果。同时随着对自注意力机制的深入研究,有研究将Transformer架构应用在关系抽取任务上,以及利用语言模型BERT进行关系抽取的工作,都取得了良好效果。
针对预训练语言模型的研究近年来发展迅猛[1-3],预训练语言模型能够捕捉两个目标实体的信息,并且基于上下文信息捕捉文本的语义信息。在数据量足够大的规模下,预训练能够获取文本的上下文的特征表示,应用于下游任务中,无需大规模的训练数据就能取得更好的效果。
由于中文与英文存在语言特性差异,且目前公文领域标注数据集少,所以现有的方法不能很好地解决政府公文领域中的关系抽取问题。因此,该文提出基于ALBERT预训练语言模型和胶囊网络相结合的远程监督关系抽取方法(Albert_Capnet)。针对政府公文领域中的人事任免信息,通过基于远程监督的关系抽取技术,抽取人名和职务之间的关系。首先使用ALBERT预训练模型对文本进行特征表示,获取文本深层语义信息;然后将其特征向量输入到胶囊网络中传输低层到高层的特征,用向量的长度对关系进行分类,判断所属职务是上任还是卸任;最后使用训练完成的关系抽取模型对待抽取的文本语料进行抽取。
主要贡献在于:(1)提出一种基于ALBERT预训练语言模型和胶囊网络相结合的关系抽取方法,适用于小样本数据集,提高了关系抽取质量;(2)将远程监督关系抽取技术应用到政府公文领域,构建人名-职务知识库,并按该方法实现人名职务关系的实例抽取的迭代扩充,解决公文领域中标记数据集少的问题,大大减轻人工标注成本。
1 相关工作
关系抽取作为信息抽取的一项关键技术,在知识库自动构建、问答系统等领域有着极为重要的意义。现有的关系抽取方法可以分为4类,分别是有监督关系抽取、半监督关系抽取、远程监督关系抽取和无监督关系抽取[4]。
有监督实体关系抽取将关系抽取任务视为分类任务,将标记好的数据作为训练集输入到分类模型中进行训练,能得到较高的准确率和召回率,但在构造训练集的过程中会耗费大量人工成本。为此,Mintz等人[5]提出基于远程监督的关系抽取方法,首先构建外部知识库,将待标注文本与外部知识库进行实体对齐,自动标注关系,然后通过分类任务实现关系抽取,大大减少了人工标注的成本。
现阶段半监督和无监督的关系抽取技术还不发达,远程监督关系抽取方法可以极大地减少人工标注成本,并解决因缺乏标记中文知识库导致的问题,因而近年来受到了学者们的关注。
由于远程监督的强假设,目前主要采取多示例学习[6-9]和注意力机制[10-14]来缓解数据噪声问题。PCNN(Piece-Wise-CNN)模型[8]在池化层将两个实体位置分为三段进行池化,并且将具有相同实体对和关系标注的所有句子看成一个包,将标注的关系作为整个包的标签进行训练,从而能够更好地捕捉两个实体间的结构化信息。但是PCNN可能会舍弃多个正确标注的句子,造成数据浪费,从而导致提取到的特征可能是片面的,这种数据处理方式对小数据样本并不友好。随后清华大学刘知远团队提出了PCNN+ATT(Piece-Wise-CNN-ATTention)模型[10],其在句子间特征提取上运用了自注意力机制,为包内每个句子赋予权重,可以更全面提取包的信息,是目前常用的中文远程监督关系抽取模型。
1.1 预训练语言模型
在NLP任务中,随着近年来算力的不断提升,基于深度学习的训练方法成为业界的主流方法,但是大多依赖于大量标注数据。预训练模型通过基于特征集成的方式和基于模型微调的方式将语言模型学习到的文本表示当做下游任务的输入特征进行应用,有效减轻了任务对于标注数据的依赖。
预训练模型的发展分为浅层的词嵌入到深层编码两个阶段。在浅层词嵌入阶段,研究目标主要聚焦在基于特征的方法上,并不注重上下文的语义关系,其代表方法为NNLM、word2vec等。深层编码通过一个预训练编码器输出上下文相关的词向量,解决一词多义的问题,如Peter等人提出的ELMo模型及Devlin等人提出的BERT模型,使得模型能够学习到句子与句子间的关系。
BERT的问世证明了预训练语言模型对下游的NLP任务有很大的提升,可以帮助提高关系抽取效果。Shi P等人[15]简单地使用BERT预训练语言模型方式,将句子输入到BERT模型中获取文本的语义表征,再连接一个全连接层作分类,完成关系抽取任务,通过实验结果表明其取得了不错的效果。Wu等人[16-17]将BERT模型应用于关系抽取任务,使用BERT学习到实体的位置信息及语义特征,从而提高模型对实体的表征能力。Livio等人[18]也证明通过BERT提取实体的位置及句子的语义信息能够提高关系抽取任务性能。
但是由于BERT模型过大,在参数和梯度的同步上消耗大量训练时间,因此,Lan等人[19]提出ALBERT模型,通过对嵌入层的参数进行分解、层间参数共享来大幅减少预训练模型参数量,加快BERT的训练速度。此外ALBERT还提出用句子顺序预测任务代替BERT中的预测下一个句子任务,使得模型能学习到更细粒度的关于段落级的一致性的区别,提高了下游任务中多句编码任务的性能。
Google在阅读理解、文本分类等13项NLP任务中进行了大量对比实验,结果表明,有233 M参数量的ALBERT_xxlarge模型,全面优于有1 270 M参数的BERT_xlarge模型。另外,ALBERT中的albert_tiny模型,其隐藏层仅有4层,模型参数量约为1.8 M,非常轻便。相对于BERT,ALBERT不仅提升了训练速度、推理预测速度约10倍,且基本保留了精度。
1.2 关系抽取与胶囊网络
关系抽取任务可被定义为关系分类任务,传统的机器学习算法如支持向量机(SVM)、逻辑回归(Logistic Regression)、朴素贝叶斯(Naive Bayes)等,仅适用于小规模的数据训练,且随着数据量增大,处理海量数据过程会费时费力。
近年来,将CNN或RNN与注意力机制结合的方法成为解决关系分类问题的最新方式,但是CNN或RNN难以提取不同卷积核所获得的特征之间的关系。Sabour等人[20]提出基于动态路由算法的胶囊网络模型,弥补了CNN的缺陷,并在MNIST数据集上验证了该模型在图像分析领域具有很好的效果。
此后,胶囊网络被引入到文本领域解决NLP问题,如文本分类[21]、情感分析[22-23]、机器翻译[24]等任务。目前,在分类模型中,胶囊网络通常被应用到分类模型的最后一层,以取代最大池化层来完成分类任务。特别是赵等人2018年首次将胶囊网络应用在文本分类任务中,提出基于胶囊网络的文本分类模型,其性能超过CNN和LSTM,从而证实了胶囊网络能够有效地提升分类任务的准确性。Peng等人[25]将胶囊网络应用到中文实体关系分类中,提出结合自注意力机制和胶囊网络的实体关系分类模型,该模型仅需要少量的训练语料,就能有效地捕捉词位置信息。
中文关系抽取依赖于文本分类技术。胶囊网络提供一种基于聚类的思想来代替池化层来完成特征的整合的方案,在分类任务中,能够学习到文本局部和整体之间的关联信息,克服CNN池化时信息丢失的局限性,从而更好地进行分类、提取文本段落与全文之间关联特征信息,最终达到提高关系抽取效果的目的。
2 Albert_Capnet关系抽取模型
对政府公文中领导人职务关系抽取的框架如图1所示。通过远程监督的思想,构建关系示例公文集,将其划分为训练数据集和测试数据集,输入到Albert_Capnet关系抽取模型中进行关系分类训练,最终得到关系抽取结果。从而实现将非结构化的人事信息转化为结构化的三元组信息,描述政府公文领域的人名职务关系,并进行存储,具体步骤如下:
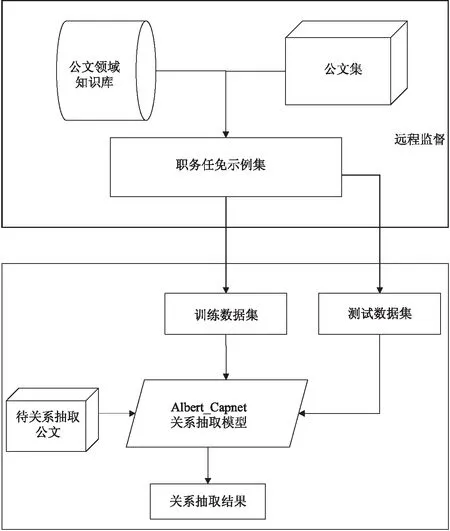
图1 关系抽取框架
(1)构建职务任免示例集。
职务任免示例集用于关系抽取模型的训练,由公文集中存在人事任免关系的句子和人名职务三元组共同构成。公文集中存放的是来自于政府网站的人事任免信息,公文领域知识库是通过对公文集进行词法和句法分析,得到的实体对集合V。实体对(E1,E2)∈V,其中E1为人名,E2为职务。基于远程监督的思想,将公文领域知识库中的实体对和公文集进行实体对齐,为实体对匹配关系标签,得到人名职务三元组。
(2)关系抽取模型训练与测试。
将职务任免示例集划分为训练数据集和测试数据集,其中,训练数据集用于训练关系抽取模型,测试数据集用于评估模型的准确率。
(3)职务关系抽取。
将待抽取公文输入到Albert_Capnet关系抽取模型中,对职务任免关系进行预测,得到关系抽取结果。
2.1 Albert_Capnet模型结构
Albert_Capnet模型用于抽取公文中人名-职务关系,模型由四部分组成,分别为输入层、ALBERT预训练语言模型层、胶囊网络层和输出层。模型具体结构如图2所示。

图2 Albert_Capnet关系抽取模型
(1)输入层。
输入层中接收的数据是职务任免示例集X,输入文本采用如式(1)所示的形式化方式表示,其中Xi表示职务任免示例集中的第i个词。
X=(X1,X2,…,XN)
(1)
(2)ALBERT层。
该层对句子中的词进行编码并提取深层语义特征。ALBERT是以单个汉字作为输入的,输出为向量形式E,如式(2)所示,其中Ei表示单个字的向量。
E=(E1,E2,…,EN)
(2)
经过多层双向的Transformer编码器的训练,最终输出文本的特征表示T,如式(3)所示,其中Ti表示文本中第i个词的特征向量。
T=(T1,T2,…,TN)
(3)
(3)胶囊网络层。
本层用于传输低层到高层的文本特征,实现实体关系分类。该层的输入是ALBERT的特征向量输出。首先构建出低级胶囊网络层,经由动态路由的方法将低层特征输入到高层胶囊网络层中,最终得到与分类结果相匹配的输出胶囊。
(4)输出层。
从胶囊网络的输出向量中选择长度最大的类别,作为最终模型预测的关系分类类别。
2.2 ALBERT层
Albert-Capnet关系抽取模型使用ALBERT预训练语言模型进行特征提取,采用词嵌入和位置嵌入的方法,将数据之间的关联性融入到数据中,使输入词学习到文本的语义信息和位置信息,解决特征提取中误差传播问题,从而达到提高关系抽取效能的目的。
ALBERT与BERT相同,使用Transformer的编码器来提取输入序列的特征信息,自注意力机制将模型上下层直接全部连接,使词嵌入具有更丰富的语义信息。ALBERT模型结构如图3所示。其中Ei表示单个词或字的向量输入,Trm即Transformer,Ti表示最终隐藏层的输出,通过编码器中的注意力矩阵和注意力加权后,每个Ti都具有整句话上下文的语义信息。
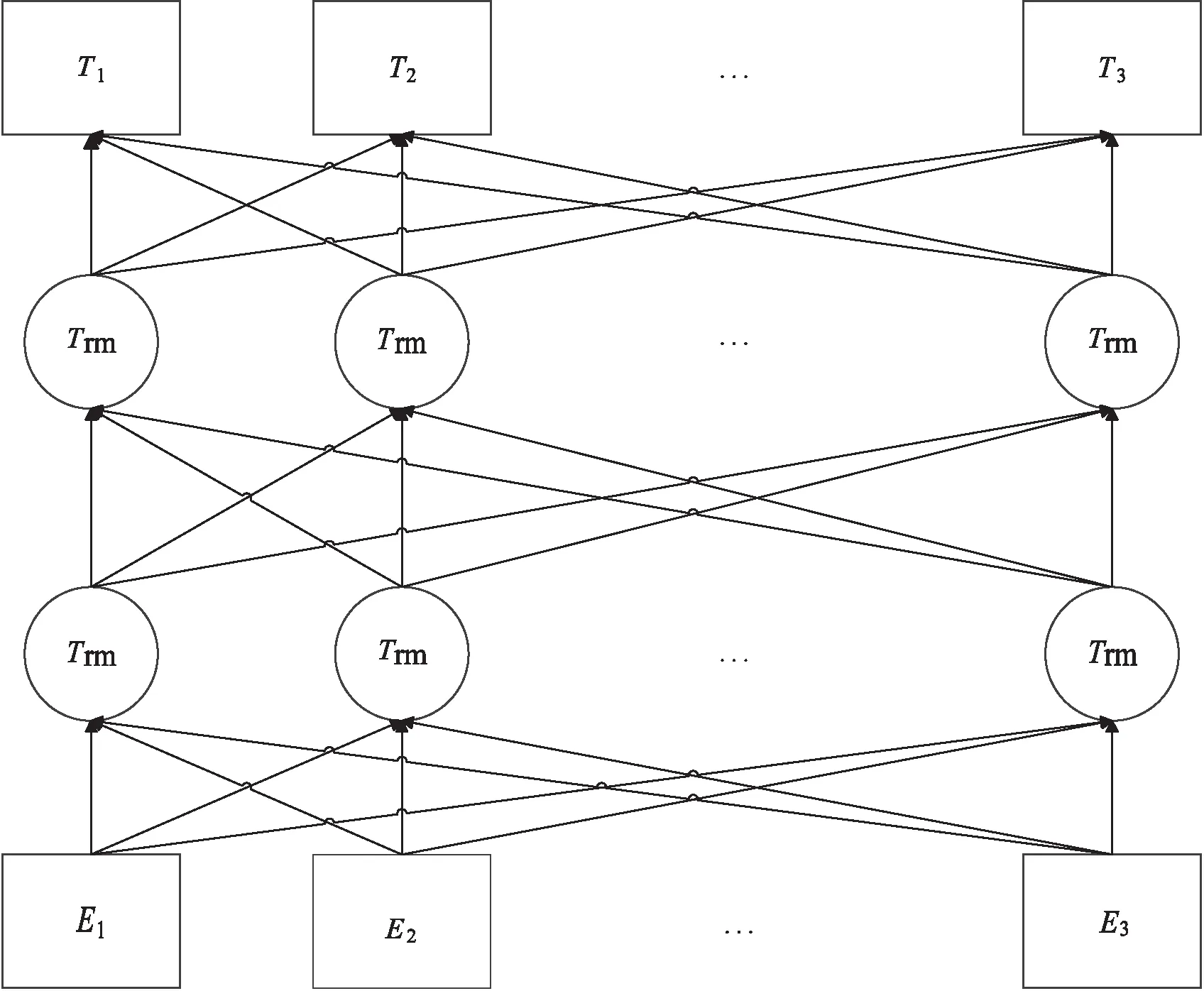
图3 ALBERT层的结构
为了使ALBERT模型定位到两个实体间的位置信息,在文本中插入实体定位字符。在每个输入句子的开头添加[CLS]字符,在头实体前后添加[E11]和[E12]字符,尾实体前后添加[E21]和[E22]字符,对位置进行标记。将头实体、尾实体用向量表示,作为实体特征。
自注意力机制公式如式(4),其中Q、K、V分别代表输入序列中每个词的query、key和value向量,dk是K矩阵的维度。
(4)
将提取到的全局语义特征和实体特征进行拼接融合,共同作为胶囊网络层的输入。
2.3 胶囊网络层
胶囊网络是基于聚类的思想,利用动态路由机制实现低层特征与高层特征的融合,提取丰富的文本信息和词位置信息,在实体关系分类中起到重要作用。胶囊网络结构如图4所示,分为低层胶囊网络层、动态路由层和高层胶囊网络层。

图4 胶囊网络结构
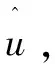
(5)
通过对输入向量加权并求和得到向量S,S是高层胶囊网络的输入,公式如式(6)所示。
(6)
用非线性函数squash对高层胶囊网络输出的向量S进行压缩,如公式(7)所示。
(7)
低层胶囊网络通过动态路由算法将信息传输到高层胶囊网络中,将临时变量bij初始化为0,以公式(8)和公式(9)进行迭代更新,值保存到cij。
(8)
(9)
胶囊网络通过传输低层到高层之间的特征,学习到文本局部和整体之间的关联信息,其最终输出为向量长度,值为类别概率值。
3 实 验
3.1 实验环境
实验环境设置如表1所示。

表1 实验环境配置
3.2 数据集
实验数据选取从中国政府网站获取的中央、地方、驻外、其他四类人事信息,构成公文集,共4 698篇公文文本。从实验数据中划分出训练集4 000条,测试集698条。该文利用哈工大的LTP(Language Technology Platform)进行词法和句法分析,对候选实体进行筛选,最终得到实体897例,包括804例人名和93例职务。采用远程监督学习的方式为实体对自动标注关系类型,并构建人名-职务知识库。人名-职务知识库格式和部分内容如图5所示。
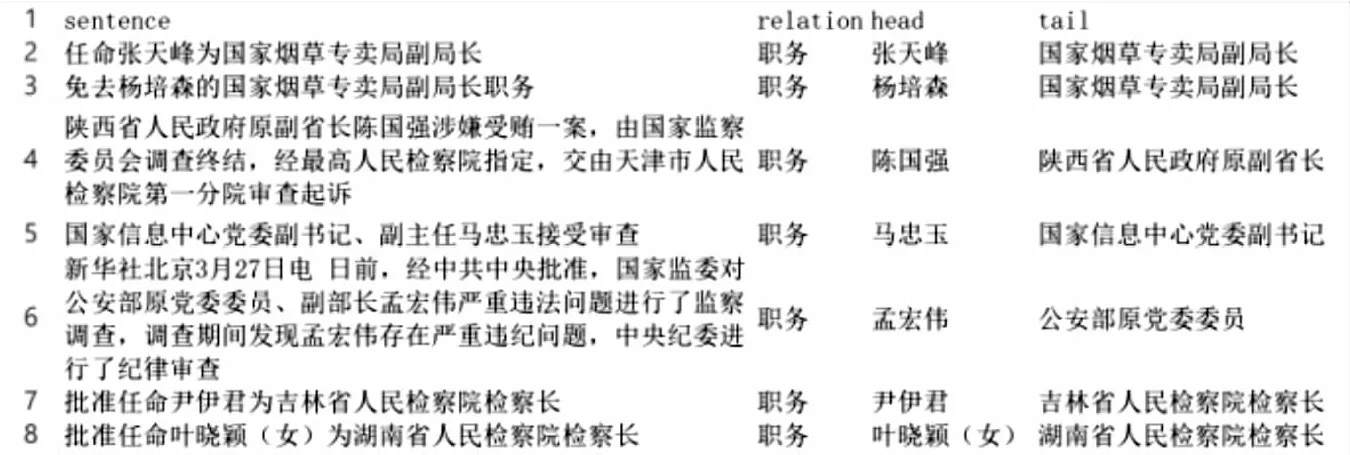
图5 部分人名-职务知识库
3.3 模型中的参数设置
在实验参数方面,该文通过多次实验并对实验结果进行验证,最终选定最优的实验参数。在预训练语言模型的选择中,采用albert_tiny中文预训练模型。采用Adam优化器调整学习率,交叉熵损失函数对模型参数进行调优,模型具体的参数设置如表2所示。
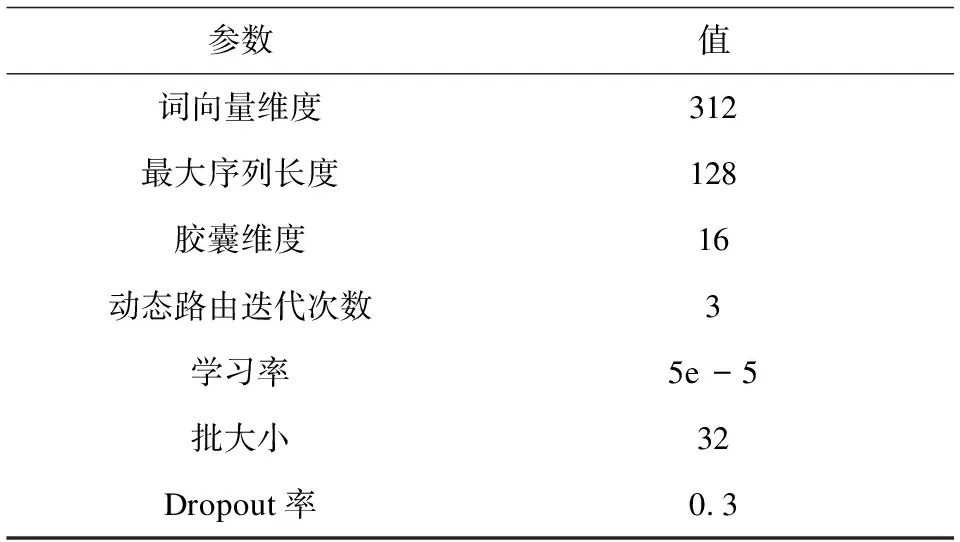
表2 实验参数设置
3.4 实验结果与分析
3.4.1 不同分类器效果比较
为验证胶囊网络在政府公文领域的分类效果,使用ALBERT提取文本特征,不同的机器学习分类器进行对比实验,包括:逻辑回归(Logistic Regression)、朴素贝叶斯(Naive Bayes)和支持向量机(SVM)。
表3为使用ALBERT提取特征,不同机器学习分类器的关系抽取实验结果。

表3 不同分类器关系抽取效果 %
根据实验结果分析,Albert-Capnet关系抽取模型在政府公文领域数据集上的分类效果优于Logistic Regression、Naive Bayes和SVM的传统机器学习分类器的分类效果。同时,实验也证明了胶囊网络能提取丰富的文本信息和词位置信息,在小样本数据集上具有良好的分类效果。
Naive Bayes假设文本中的词是彼此独立的,词之间不具有关联性,并且只有训练样本数量非常多的情况下才能达到非常准确的效果,因此不适合做小样本数据集上的文本分类器。Logistic Regression和SVM在分类结果上取得了很大的优势,而且分类的时间较深度学习来说缩短了很多,但是需要人工进行特征构造,可扩展性差。Logistic Regression适合处理二分类问题,但是不能解决非线性问题。SVM把高维空间的复杂性问题转化为求核函数问题,在小样本训练集上能够取得不错的效果,但是需要大量的存储空间。
3.4.2 不同关系抽取方法的比较
为对比不同关系抽取方法的抽取效果,选择两种在远程监督关系抽取中被广泛应用的模型作为对比实验模型,即PCNN和PCNN-ATT。PCNN是常用的远程监督关系抽取模型,PCNN-ATT是目前已知远程监督中文关系抽取数据集上效果最好的模型,也是基准模型。不同关系抽取方法结果对比如表4所示。
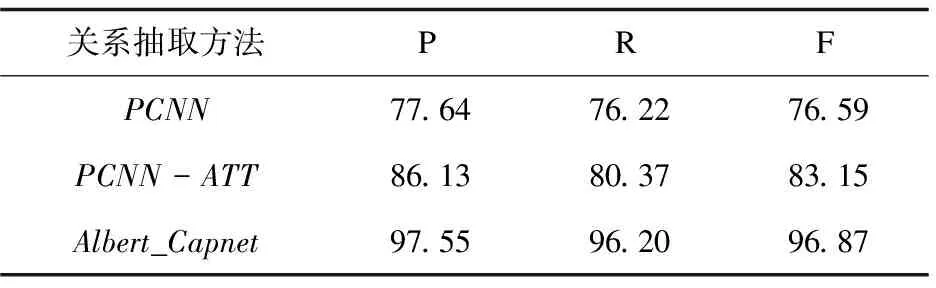
表4 不同关系抽取方法的对比效果 %
实验结果表明,PCNN提取的文本特征是片面的,在小样本数据集上的效果不好,PCNN-ATT通过提高包中正确标注句子的注意力权重,提高了关系抽取效果。而Albert_Capnet关系抽取方法能够有效提取文本中的深层语义信息和词位置信息,在准确率、召回率、F1值上均远高于PCNN和PCNN-ATT方法。
通过以上两个实验,表明Albert_Capnet关系抽取模型在政府公文领域的小样本数据集上具有更好的抽取性能。
4 结束语
通过分析政府公文领域特点,该文提出了基于ALBERT预训练模型和胶囊网络相结合的远程监督关系抽取模型,针对抽取人名-职务间的职务关系,进行分类,大大减少了人工对数据标记所耗费的时间和精力,解决了公文领域标注数据集少的问题。ALBERT通过字嵌入和位置嵌入的方式,提取文本中深层的语义信息,解决特征提取中的误差传播问题。对比实验结果表明,胶囊网络在公文领域的小样本数据集上具有良好的分类效果,可以有效提高分类精确度。
对于政府网站日益增加的政府公文,采用远程监督的关系抽取方法可以减少人工标注成本,提高关系抽取效率,进而保证了获取重要信息的质量和实效性。该方法所获实例可扩充现有公文领域知识库,辅助政府工作人员在书写公文时快速获取人事信息。
该文聚焦于单一的实体关系抽取,未来将着眼于能否同步抽取多个实体间的多类关系等信息。
猜你喜欢
计算机系统应用(2021年11期)2022-01-06
当代陕西(2019年5期)2019-03-21
妇女之友(2018年8期)2018-09-17
21世纪商业评论(2018年3期)2018-03-02
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
现代出版(2014年6期)2014-03-20
小学阅读指南·高年级版(2009年3期)2009-03-27
