
基于互信息贝叶斯网络的交通事故严重程度分析*
2022-01-08 04:57吕通通陆林军张延猛
交通信息与安全 2021年6期
吕通通 张 湛 陆林军 张延猛
(上海交通大学船舶海洋与建筑工程学院 上海 200240)
0 引 言
省际客运行业因其运载量大、灵活机动等特点,存在多种事故风险。随着交通运量不断拉升,行业安全问题愈发凸显。以上海市省际客运事故数据为例,从2014—2019年,事故数量总体呈递增趋势,增量达到80%。因此,有必要对事故严重程度进行分析,探究事故规律,以合理制定对策降低事故风险。
近年来,国内外学者从多个方面对道路交通事故进行了研究。宗芳等[1]利用结构方程模型结合贝叶斯网络对常规公交失火事故成因进行了组合评估。Zhang Yingyu等[2]利用因果分类框架与促成因素交互模型相结合的方法宏观分析了全国28省道路交通行业事故成因。Sam等[3]利用广义有序Logit模型分析加纳地区公共汽车事故成因。Miyama等[4]采集了日本301名公交司机的调查问卷,并利用多元回归模型进行分析,探究疲劳驾驶对客运事故的影响。陈昭明等[5]利用混合Logit模型分析事故严重程度与道路、环境、驾驶员等因素间的关系。Jiang Chenming等[6]使用偏态logistic分析人-车碰撞事故致因。Wang Xuesong等[7]利用随机效应两水平Logit模型分析了上海某公交公司725名驾驶员问卷,寻找事故主要原因。对于省际客运行业,研究多从单车车辆结构[8-9]及制动性能[10]对行车事故影响进行分析。此外,还有研究从运营管理[11]角度对安全风险及决策进行探究。针对省际客运事故综合成因分析的研究较少。Besharati等[12]用Logit模型对伊朗省际客运司机问卷调查结果进行分析,从人、车、环境层面分析了撞车事故成因。
上述研究多使用回归模型分析方法,其本身难以筛选特征因素,且在处理非线性问题上表现不佳。此外,这些研究多通过问卷调查方式获取数据,存在较大主观性,且忽视了对既有数据的挖掘。基于此,本文选用贝叶斯网络分析方法处理非线性问题,引入1种有监督的离散算法优化样本数据分类,提出互信息与交叉验证相结合的方法进行因素相关性排序,并构造数个先验网络分别进行结构学习,通过比选得到最优模型,从人、车、路、环境方面对事故严重程度影响进行综合分析。以期从方法层面弥补行业安全评估样本量小及主观偏差影响,从应用层面有针对性的为行业管理部门提供决策依据,进而降低行业事故率。
1 建模方法
1.1 CACC数据离散方法
由于省际客运行业事故数据相对其他行业较少[7],且存在样本分布不均匀的问题。为了充分利用有限数据,本文引入Tsai ChengJung等[13]提出的1种基于类属性相依系数(class-attribute contingency coefficient,CACC)的离散算法。该算法是1种静态、全局、自上而下的有监督离散算法,能够有效进行数据离散并保留更多知识。
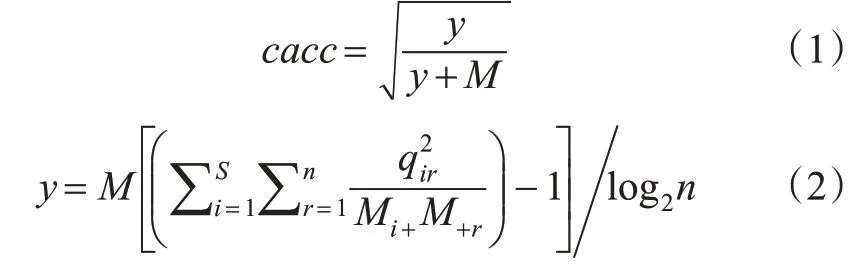
式中:M为样本总量;n为区间数;qir为在区间[dr-1,dr]中的第i类的样本量(i=1,2,…,S;r=1,2,…,n);Mi+为第i类样本的总量;M+r为区间[dr-1,dr]内的样本总量。算法利用式(1)~(2)作为评分函数来衡量变量之间依赖程度。CACC算法较目前流行的CAIM、CDD算法可以充分考虑所有样本分布,避免发生过拟合[13]。执行流程如下。
步骤1。给定1个样本量为M,具有l个待离散变量及S个目标类的数据集。文中M=741,l=7,S=3(“死亡事故”“受伤事故”“财产损失事故”)。
步骤2。对于每1个待离散变量Xl,找到其中的最大值和最小值作为初始化区间边界。
步骤3。将初始区间中的值按升序排列,计算所有相邻值的中点。
步骤4。对变量进行迭代划分,并利用式(1)生成每一次迭代的cacc值,若该值不再提高,输出最优区间划分结果。
1.2 先验网络构建
为提高贝叶斯网络学习效率,避免形成局部最优解,一般需构造部分先验网络以缩小搜索空间。对交通事故建模一般使用专家知识,也有结合专家知识与机器学习的混合方法。研究希望尽可能排除主观误差,拟采用机器学习方法建模。近年因果推断理论逐渐发展,对于构建先验网络有较高实用价值,但其只适用于二值变量。而DBe方法虽然适用多值变量,却需要至少3 000条样本数据支撑以满足建模效果[14]。互信息方法能够有效处理高维小样本数据,但传统方法存在估计偏差,且要解决边定向的问题[15]。结合本研究实际,提出1种先验网络构造方法。在进行方法论证后,采用1种改进的互信息(mutual information,MI)方法[16]。该方法以最大k临近(k-nearest neighbor,KNN)思想近似地估计Shannon信息熵,熵值与相关度成正比,以此找到变量间相关关系。

式中:I(X,Y)为X,Y之间的互信息值;ψ(x)为digamma函数,Γ(x)为伽马函数,ψ(x)=Γ(x)-1dΓ(x)/dx,它满足递归函数ψ(x+1)=ψ(x)+1x,ψ(1)=-C,C≈0.577 215 6;…为求均值;mx,my分别为水平与垂直方向落入k邻域的样本点的数量。方法关键在于k值选取,k值越小,一般系统误差越小;k值越大,可以相应减小统计误差。下面给出本文先验网络构造方法。
步骤1。选取最佳k值。由于方法基于KNN理论构造,本文改用交叉验证方法,将经过CACC算法处理的数据集分为若干子集,为了控制模型偏差,经过测试选取其中70%作为训练集,30%作为测试集,计算所有训练样本到测试样本的欧氏距离并建立距离降序矩阵,选定第k个距离确定为k邻域,利用k邻域分类所有训练样本,再用测试集测试分类准确性,输出分类准确率最高的k值。
步骤2。形成变量关联度序列。根据最佳k值,进行互信息计算得到变量间相关关系。从因果逻辑出发对变量划分因果,提取目标变量的关联变量按互信息值降序排列,形成关联度序列。
步骤3。部分边的定向策略。为避免互信息方法估计偏差[15],在关联度序列基础上,设置不同互信息值作为阈值,由因至果连接事故严重性相关节点,建立先验网络,反复经过模型验证选取最优网络。
1.3 基于互信息的贝叶斯网络模型
贝叶斯网络是1种有向无环图,由变量节点和有向边组成。本文选用基于评分函数的GTT(greedy thick thinning)算法建模,该算法可在给定先验网络条件下,执行网络加边和网络减边2个步骤,不断迭代直至整体网络结构评分最高并输出初始网络。结合本文先验网络构造方法,可以有针对性的应对个体错误敏感性[17]。
得到初始网络后,利用最大期望算法(expectation-maximization algorithm,EM)进行参数学习,得到各因素节点的条件概率。本文模型建立流程见图1。

图1 模型建立流程图Fig.1 Flow of modeling
2 省际客运事故严重程度模型构建
2.1 数据来源
数据来源于上海市交通委员会安全生产监督管理平台数据库,提取了全市2005—2019年790条省际客运事故数据,每条数据包含18个变量。通过数据清洗剔除缺失、错误数据后,剩余有效数据741条。
针对事故严重程度进行分析,筛选其中14个相关变量(离散变量12个,连续变量2个)。为便于研究,按照因果逻辑将变量分为影响因素变量(含盖人员、车辆、道路、环境类别)及事故结果变量(含盖伤亡及财产损失情况)2类,各变量具体信息见表1。
2.2 构建先验网络
2.2.1 数据离散
利用Matlab R2020a软件根据步骤实现CACC算法,为便于研究,设置最大区间数为5,以“事故类型”为监督变量进行离散。各变量区间划分见表1。

表1 建模变量区间划分Tab.1 Variable-interval division of modeling
2.2.2 构造先验网络
执行交叉验证(见图2),得到最优k=21。
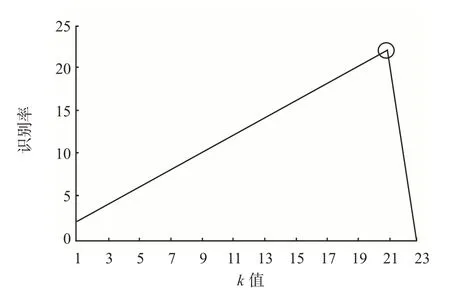
图2 最佳k值选取Fig.2 Selection of the optimal k value
利用Matlab编程计算各变量间互信息值,得到MI矩阵,见表2。
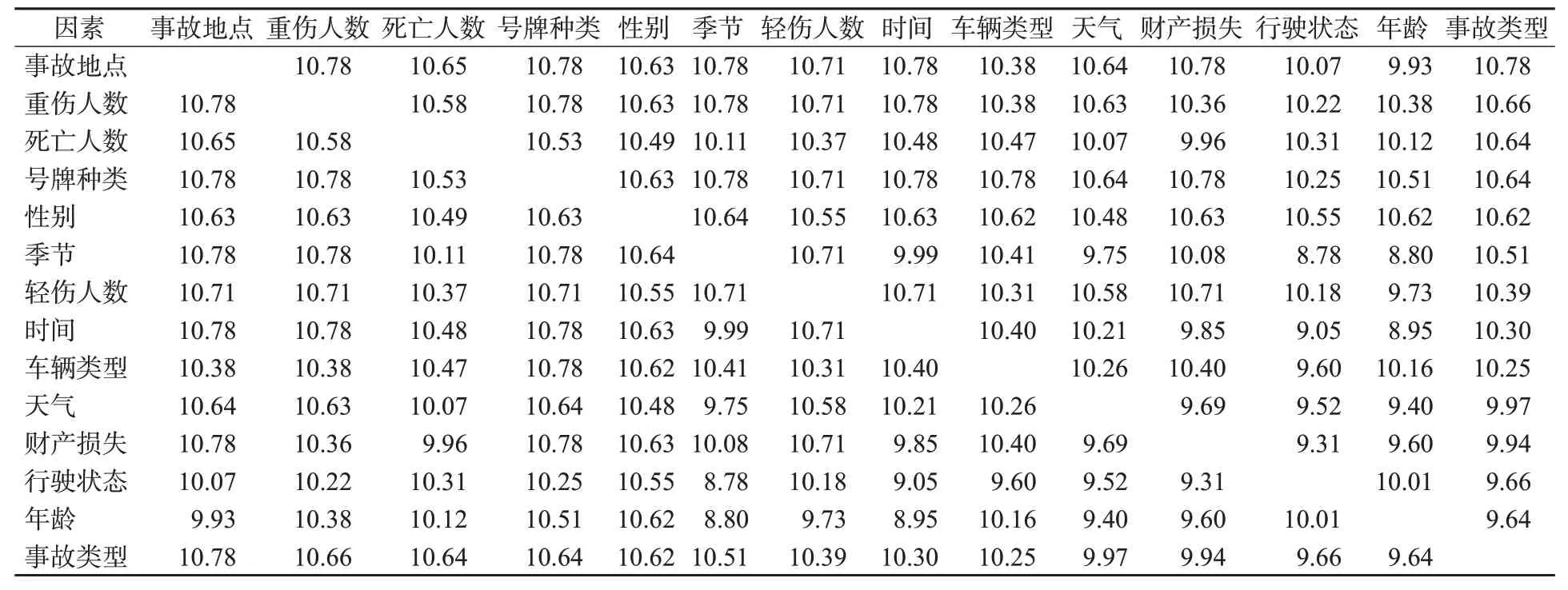
表2 互信息矩阵Tab.2 Mutual information matrix
提取“事故类型”相关MI值,将对应变量根据变量划分降序排列(见表3)。将各变量节点按此序列排列,作为先验网络初始节点序列。以0.1为间隔,从9.6~10.7设置12个MI值作为阈值,根据给定互信息阈值,将大于阈值的影响因素变量节点逐一向结果变量节点作有向边构造先验网络。再加入全连、全不连先验网络作为对照组,进行贝叶斯网络结构学习。利用“留一法”(leave one out,LOO)交叉验证对14个模型进行精度测试,留一法被证明较k折交叉验证更贴合本研究实际[18]。由测试结果(见图3)可知,当连接阈值为10.5时网络最优,见图4。

表3 变量节点序列Tab.3 Variable node sequence
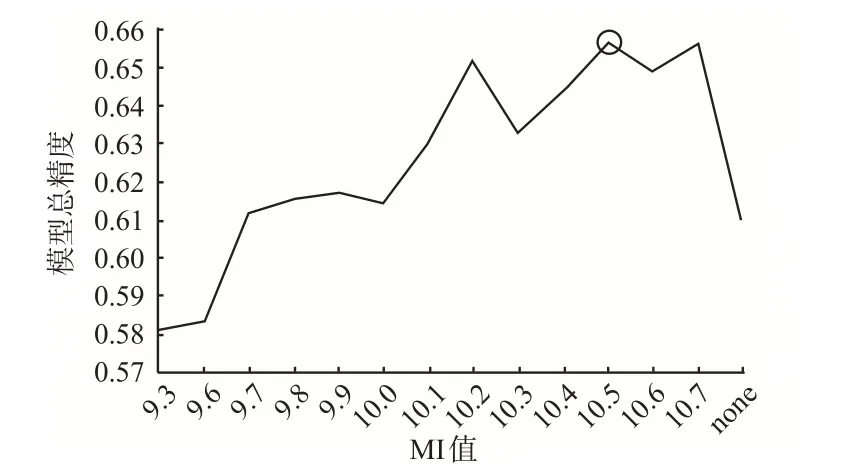
图3 不同互信息模型测试结果Fig.3 Test results of different mutual information models

图4 贝叶斯先验网络Fig.4 Prior networks of Bayesian
2.3 模型构建
根据选定先验网络构造贝叶斯网络模型,利用GeNIe 3.0软件实现模型可视化。随后利用软件自带EM算法进行参数学习,得到各变量条件概率分布情况见图5。
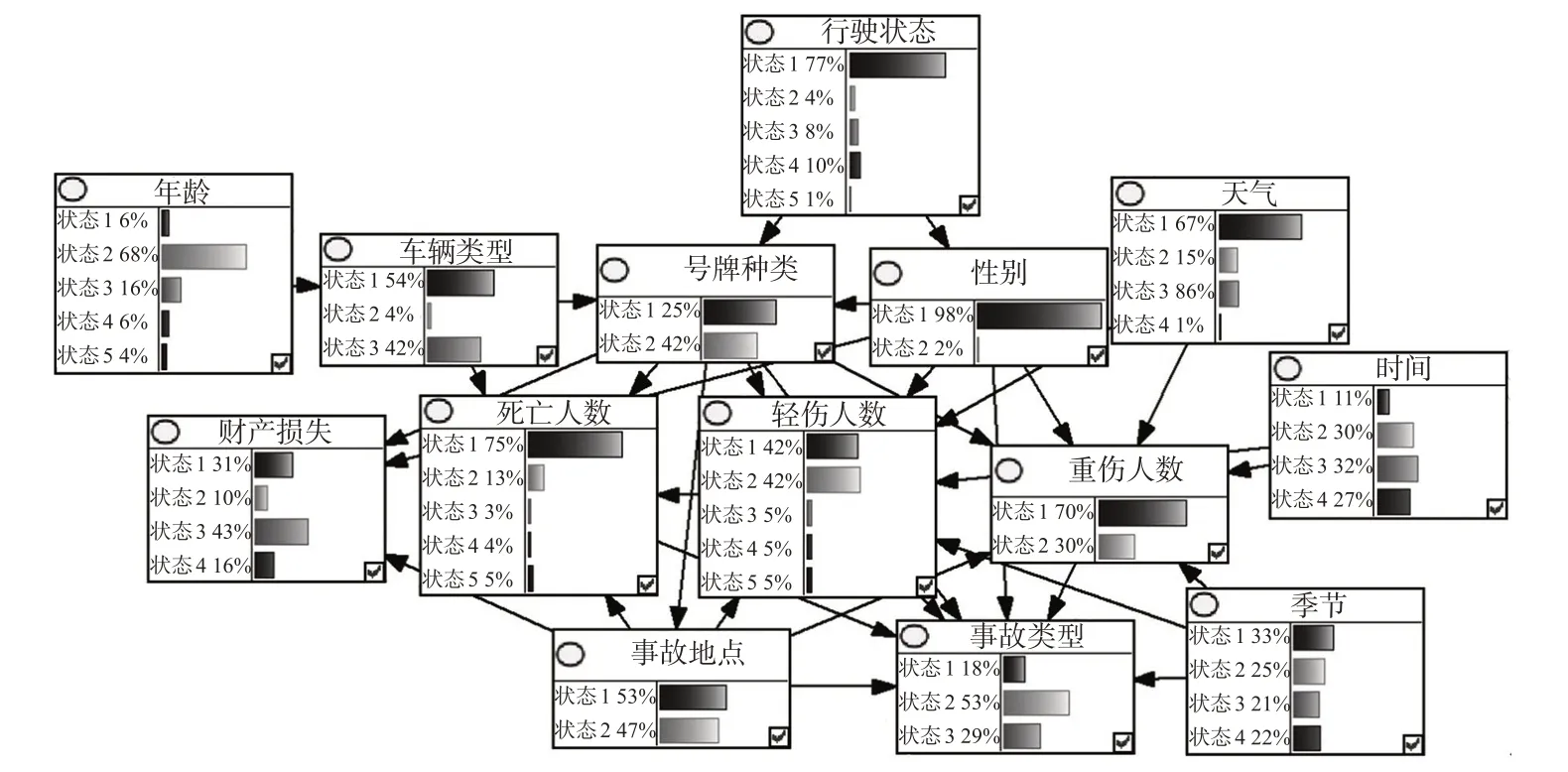
图5 省际客运事故严重程度分析模型Fig.5 Accident severity analysis model of inter-provincial passenger transport
2.4 模型验证
为衡量数据挖掘效果及模型实用性,利用受试者工作特征曲线(receiver operating characteristic curve,ROC)检验模型泛化能力[19],曲线右侧面积称为AUC(the area under the ROC curve),AUC>0.5表示模型可行,面积越大模型泛化能力越好。
对比相同建模方法下本文模型与等宽离散、Hierarchical聚类离散模型,以及相同离散方法下本文模型与纯数据、专家知识模型(专家知识由上海市道路运输行业安全数据需求分析及标准化体系建设试点项目实地调研获取)的事故严重程度预测表现,各模型对比结果见图6。
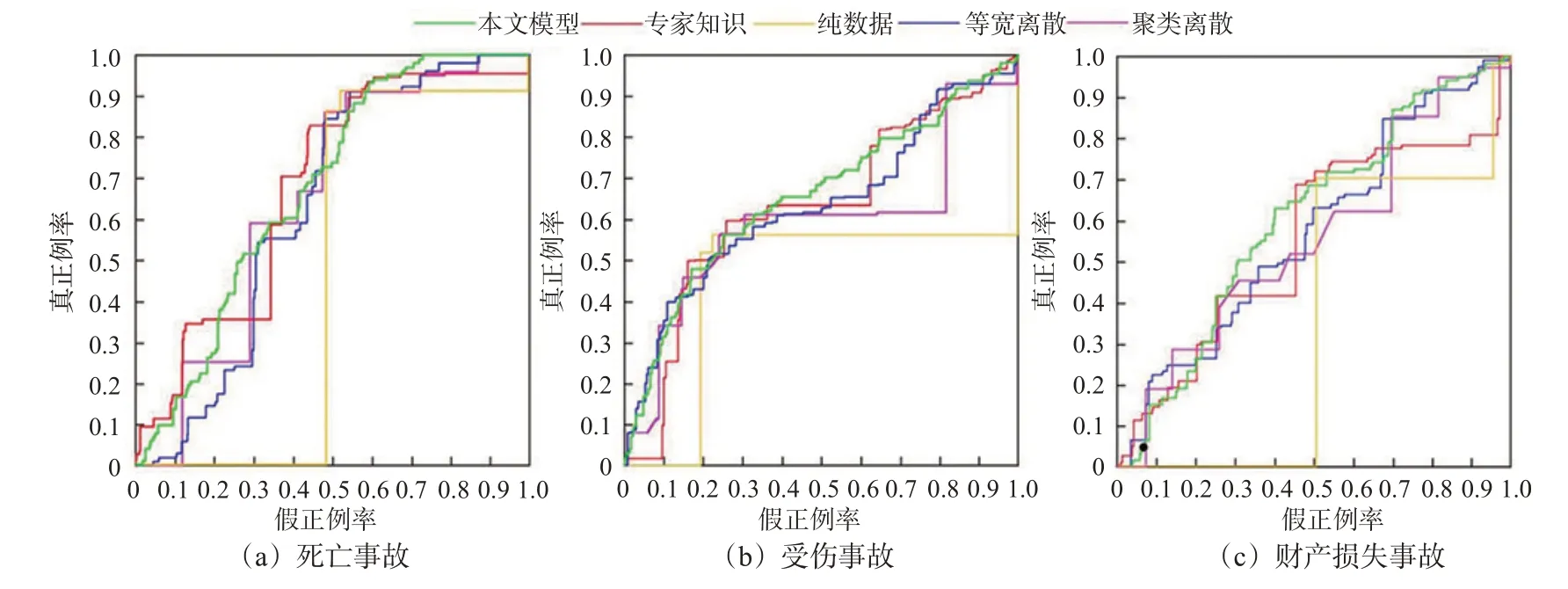
图6 不同模型ROC曲线对比Fig.6 Comparison of ROC curves of different models
算得本文模型的泛化能力及稳定性优于其他模型,AUC面积均值达到0.644 588。同时,交叉验证结果显示:103条“死亡事故”命中102条,512条“受伤事故”命中497条,125条“直接财产损失”命中121条,命中率达到97.3%。
3 省际客运事故严重程度分析
3.1 事故严重性总体致因分析
1)敏感度。敏感度分析可以揭示变量节点的微小变化对于事故严重性的扰动程度。以结果变量为目标项进行敏感度分析(见图7),灰度越高表示该节点越容易对事故造成扰动。对各个结果变量进行敏感度指数计算并取均值,得到:天气、性别、车辆类型对事故严重性的影响最大,敏感度均值分别达到0.184,0.148 6,0.101 2。
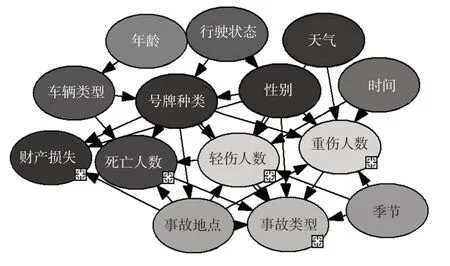
图7 敏感度分析Fig.7 Sensitivity analysis
2)影响权重。进一步讨论3个变量中每个状态对事故严重性的影响,根据区间划分特征,将“事故类型”中的“死亡事故”“受伤事故”“财产损失事故”类表征为3个严重程度级别,以“死亡事故”为最严重。通过设置3个变量中某类为“证据”(即绝对发生),利用软件更新目标变量的后验条件概率,观察“死亡事故”类及“死亡人数”最严重类的条件概率变化情况,取平均值并进行归一计算,得到某一类在变量中的权重。将影响因素变量的敏感度指数作归一处理,乘以类权重,得到该类对事故严重性的影响权重,见表4。

表4 条件概率分析Tab.4 Conditional probability analysis
观察结果发现“女性驾驶员”“中型客车”“雪、大风、雾”对事故严重程度影响最大,应着重关注。注意到“男性”权重仅占到“女性”的45%,但其权值依然较高;“大型客车”对事故严重性影响程度仅次于“中型客车”,“小型客车”相对安全,说明客车尺寸与安全性并非单调关系[3]。
3.2 不同事故严重性致因分析
1)后验概率。进一步分析各类事故严重程度关联因素。针对各
结果变量分别进行后验概率分析,提取对“死亡人数”“轻伤人数”“重伤人数”及“财产损失”有明显影响的分析结果见表5~6。
2)分析结果。由表5可知,“女性”驾驶员引起3人以上死亡概率提高12%;驾驶员“年龄”与死亡人数成正比;大、中型客车更易引起死亡事故,“中型客车”造成多人死亡概率同比上升6%。“路段”更易导致死亡发生;秋冬季较其他季节更易引发死亡;天气对死亡人数整体影响较大,天气恶劣程度与死亡人数呈正相关;凌晨00:00—05:00时引发死亡风险上升5%;“左转弯、停车、倒车、掉头”或其他违规驾驶更易导致死亡发生,这可能是由于上述行为会增加与其他车辆或行人的冲突点。
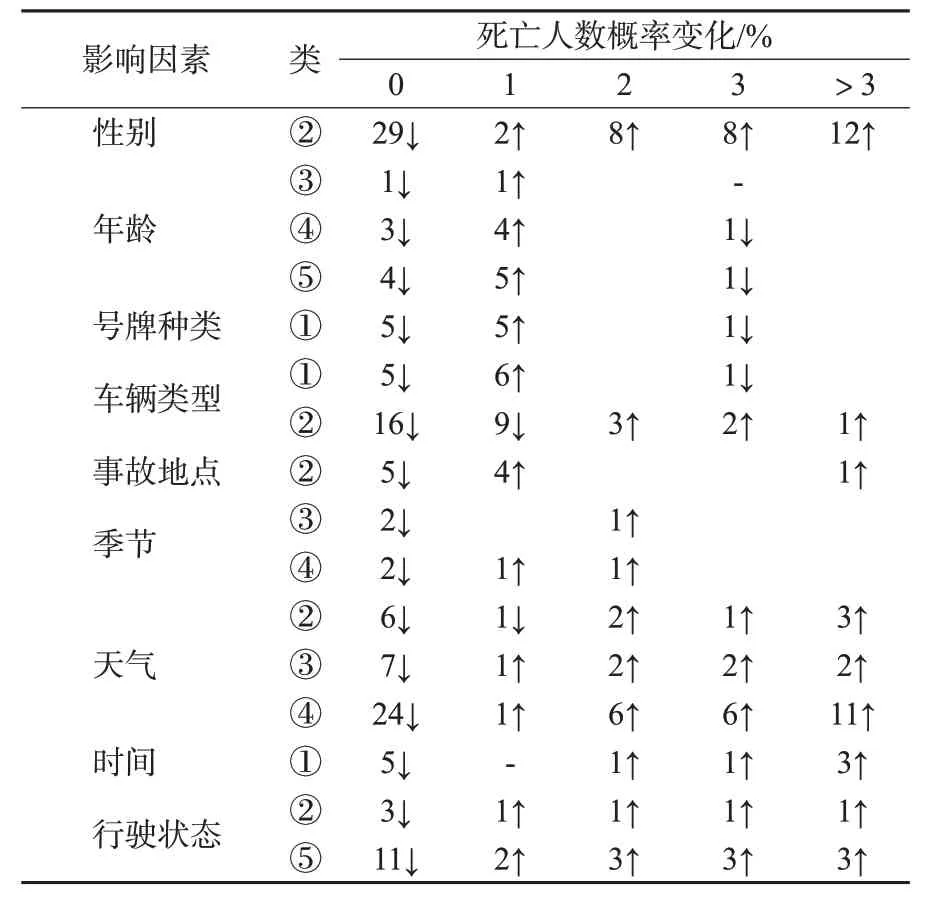
表5 死亡人数后验概率分析Tab.5 Posterior probability analysis of the number of deaths
由表6可知,对于受伤人数,“女性”驾驶员造成事故引发群体受伤概率最高;“27岁以下”驾驶员反而易引发受伤事故,这可能与年轻驾驶员高应变能力但缺乏经验、易低估危险性有关[3];与文献[7]不同,47岁以上驾驶员,其年龄与死亡、财产损失风险呈正比;此外,年龄因素对群死群伤事故贡献不大;“小型客车”事故易引发人员受伤,且重伤概率上升6%;路口虽然受到交通管制死亡事故风险降低[3],但引发受伤概率较路段平均提高5%;秋冬季节引发受伤风险增加,秋季风险更大,但冬季重伤率降低3%;天气恶劣程度与受伤风险成正比,且更易引发群伤事故;00:00—05:00时引发群伤事故概率平均上升9%。对于财产损失:“年龄”与财产损失呈正相关,且“27岁以下”驾驶员造成重大财产损失风险下降7%;“中型客车”事故风险更高,但“大型客车”易造成更多财产损失,这可能与车辆自身价值有关;“路口”事故造成重大财产损失的风险明显低于“路段”;行驶状态为“变更车道、躲避障碍、驶离路面”对伤亡人数无明显影响,却会导致财产损失风险上升。模型学习结果还认为“天气”“季节”“时间”3个因素与财产损失无直接关联。
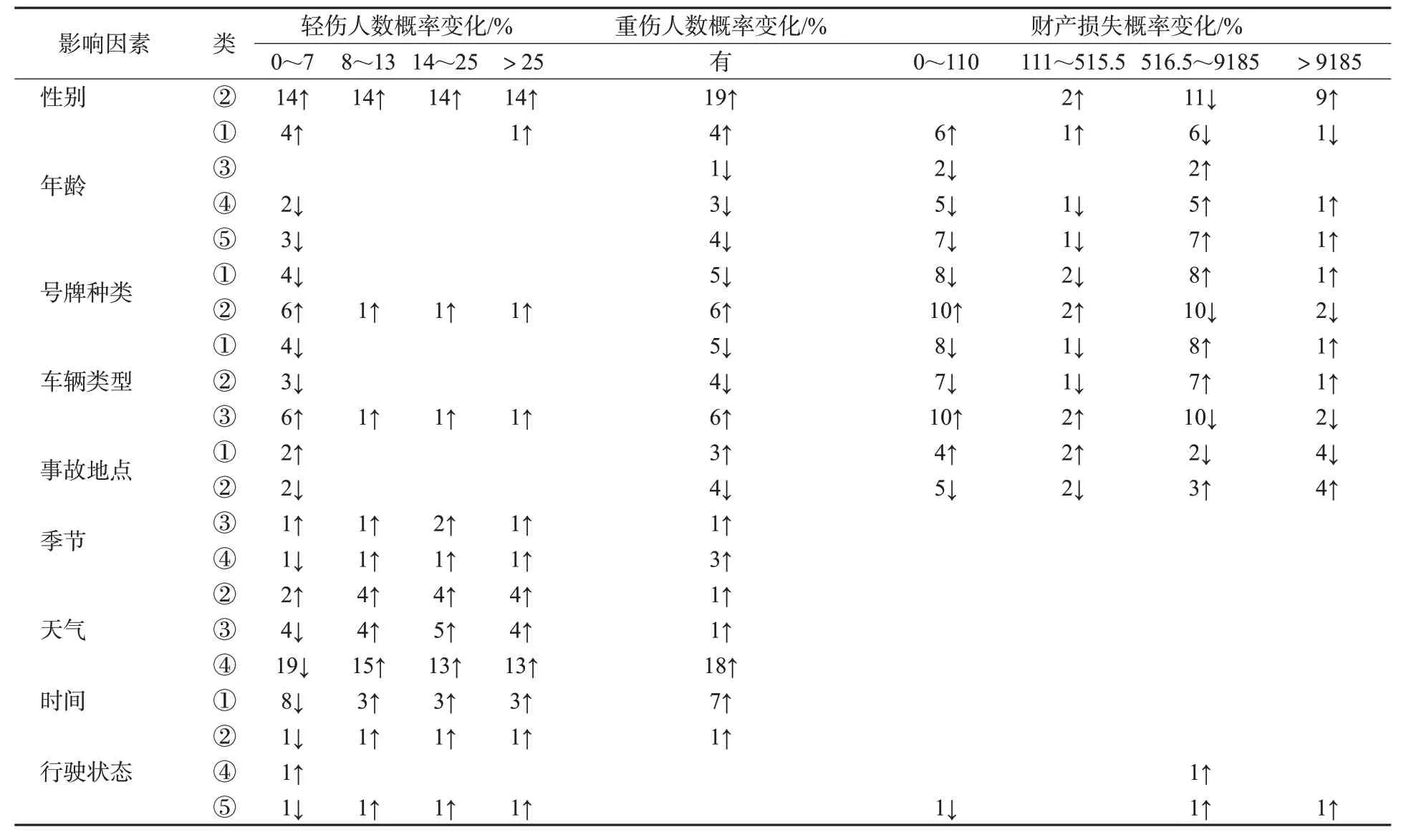
表6 受伤及财产损失后验概率分析Tab.6 Posterior probability analysis of injury and property loss
综上,女性及47岁以上驾驶员、中型客车、路段、秋冬季、恶劣天气、凌晨00:00—05:00时及左转弯等驾驶行为会增加事故死亡风险;女性驾驶员、恶劣天气及凌晨00:00—05:00时增加了7人以上受伤风险;女性及大龄驾驶员、大中型客车、路段及行驶状态为“变更车道、躲避障碍、驶离路面”增加了重大财产损失风险。
4 结束语
1)以省际客运为例,建立了基于互信息贝叶斯网络的交通事故严重程度分析模型。通过CACC算法提高了数据利用率,选择最优互信息值连接变量节点,适用于小样本数据建模。通过ROC分析证实了模型泛化能力。
2)从人员、车辆、道路、环境4个方面进行定量分析。结果显示,“女性”“中型客车”“雪、大风、雾”对整体事故严重性有明显影响。进一步讨论了各因素对于不同事故严重程度的影响。
随着数据量增加,模型精度会逐步提高。由于数据库记录要素有限,不免存在其他影响因素未被考虑的情况。未来行业安全生产监管大数据会更加完善,在利用专家知识及行业经验进行安全评价之外,使用数据挖掘结合机器学习方法对事故致因进行定性关联和定量分析,可有效提升风险防控及隐患排查精细化水平。
猜你喜欢
环境工程技术学报(2022年3期)2022-06-05
——兼论“二维码偷换案”
法制博览(2018年17期)2018-01-22
中国公路(2017年11期)2017-07-31
湖南行政学院学报(2016年4期)2016-12-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
少儿科学周刊·儿童版(2015年5期)2015-08-17
哈尔滨师范大学自然科学学报(2015年6期)2015-04-23
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
