
基于知识关联的多层本体立方体设计与实现
2022-01-07 07:01刘政昊
现代情报 2022年1期
刘政昊






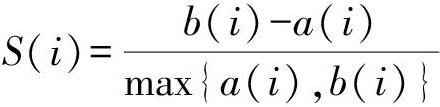







摘 要:[目的/意义]结合金融证券行业特征,借鉴层次式设计思路和数据立方体概念,提出多层领域本体立方体模型并完成构建。[方法/过程]复用FBIO本体进行知识建模;利用LDA主题建模与BIRCH层次聚类完成概念提取;基于依存句法和深度学习框架的知识抽取完成本体实例扩充;通过维度分类和基于概率的实体空间向量表示增强语义关联性。[结果/结论]多层构建方式和立方体结构增加了知识内在关联,为金融概念知识提供多层次、细粒度的知识组织方式;也为本体构建提供新的思路。
关键词:多层领域本体;本体立方体;金融证券;知识关联;层次聚类;知识抽取
DOI:10.3969/j.issn.1008-0821.2022.01.008
〔中图分类号〕G254 〔文献标识码〕A 〔文章编号〕1008-0821(2022)01-0072-15
Abstract:[Purpose/Significance]Based on the characteristics of financial securities industry,a multilevel domain ontology cube model was proposed and constructed by referring to the concept of hierarchical design and data cube.[Method/Process]FBIO was used ontology for knowledge modeling;LDA topic modeling and Birch hierarchical clustering were used to complete concept extraction.Ontology instance expansion was completed by knowledge extraction based on dependency syntax and deep learning framework.Semantic relevance was enhanced through dimension classification and probabilistic entity space vector representation.[Result/Conclusion]The multi-level structure and the cube structure increased the internal correlation of knowledge,and provided a multi-level and fine-grained knowledge organization mode for financial concept knowledge.It also provides new ideas for ontology construction.
Key words:multilayer domain ontology;ontology cube;financial securities;knowledge association;hierarchical clustering;knowledge extraction
金融是现代经济的核心。随着经济全球化进程的加速,各金融机构间的关联日趋紧密,各细分行业产生的海量数据关联也趋于多样化,金融市场已成为开放、互联的复杂巨系统[1]。金融科技概念的兴起也引发了金融行业新一轮的技术革命,在国家大数据战略背景下,金融大数据发挥了重要的价值[2-5]。然而,金融行业积累的丰富数据资源在给加速金融行业转型升级带来新的机遇的同时也引发了新的问题。在证券行业,由于业务、产品、客户多模块线条需要统一布局,存在着数据多源异构且稀疏性强、知识动态性和关联性显著等特点[6],加之证券投资领域知识体系本就纷繁复杂,这无疑增加了投研人员和投资者的认知和分析成本,从长远来看,也不利于证券行业的数字化和智能化发展。因而,如何对金融知识进行有效组织与关联以提高金融领域知识的利用效率,已成为学术界与业界共同关注的热点问题。
本体(Ontology)作为一种能在语义和知识层次上描述多源异构知识的建模工具,被认为是大数据环境下解决“信息和知识孤岛问题”的最佳方法[7-8]。领域本体(Domain Ontology)是对具体专业领域内知识的概括与集合,不仅定义领域内基本概念,还覆盖各个概念之间的关系,提供该领域内的重要术语及理论、实例和相互关系领域活动等[9]。基于领域本体的知识表示与组织保证知识理解的唯一性,同时能够适应涉及的知识领域多样性以及语义关系复杂性的特点[10]。
领域本体的构建方法一直是当前本体研究热点,传统的人工构建方法需要领域专家的介入,成本较高且难以复用[11-12]。随着人工智能的发展,越来越多基于深度学习的自动化构建方法受到了学者们广泛关注[13-16]。本文以金融证券行业为例,提出了一种能够多维度表征知识概念的本体立方体结构框架,首先对概念进行主题建模和层次聚类,构建概念间层级关系;然后基于信息抽取方法和技术,对大量的非结构化语料进行有效的实体和关系抽取,并依据概念间的语义相似性进行维度分类,从而构建起实例本体立方体结构,为实现金融知识的有效关联与融合提供了理论模型支持,同时也为领域本体构建方法提供了新的实现思路。
1 相关研究
1.1 领域本体構建方法与技术
随着人工智能第三次热潮的到来,本体概念频繁地被人工智能与知识工程领域所提及。目前,领域本体的构建方法与技术已经相对成熟。早在2003年,欧盟信息社会技术方案委员会就通过研究本体构建的36种方法,分析了以文本、字典、知识库及半结构化图表为数据源的领域本体构建技术、方法与工具[17]。同时期中国科学院则致力于研究形式化本体在领域知识的复用和共享中的作用以及领域知识复用的虚拟领域本体的构建方法与技术[18],并取得了一定成果。随着对领域本体构建研究的深入,越来越多的学者试图通过不同的技术和方法对不同领域进行本体建模。
在以统计学习为主的构建技术中,自然语言处理、信息检索等技术被广泛应用在领域本体构建的各个模块,如国外学者Shih C W等[19]的基于词汇共现与合并的水结晶模型(Crystallizing Model);Sanchez D等[20]的基于核心动词挖掘技术;国内研究者郑姝雅等[21]面向用户生成内容的术语抽取技术;邓诗琦等[22]面向智能应用的应用驱动循环技术等。这些技术的基本思想都是利用词汇单元的共现信息识别它们的关系并应用在概念和关系抽取中,构建过程注重应用关联规则挖掘等浅层语义,虽然一定程度上提高了构建效率,但准确率低下,难以扩展和复用。此外,Shamsfard M等[23]在调研中发现,领域本体的构建中多数研究仍主要关注层次关系(Hierarchical Relation),对于非层次关系的抽取与表示常常无能为力,因此仅采用统计学习为主的技术构建的本体维度略显单一,只适合体系较为单一明确且知识关联特征不明显的领域。
与统计学习技术相对应的语言学构建技术则更加注重对深层语义的理解与分析,因此语义字典、语义模板等被应用在实际的领域本体构建中。国外学者Zouaq A等[24]提出了一种基于深度语义分析与图论方法结合的领域本体构建方法;Lee C S等[25]在构建过程中利用语形学的概念构建了概念间的关系,同时结合领域专家对概念和关系进行了修正;国内学者刘萍等[26]基于语言学的方法对领域本体构建的概念抽取和关系识别进行了综述分析,并认为深度语义和知识关联特征需要多源异构数据融合和概念语义增强理解才能实现。基于语言学的方法可以在一定程度上解决术语多含义的问题并降低关系识别的误差和丢失,从而获得更高性能和更加权威的本体知识,但是由于领域知识的高度复杂性和动态性,仅靠语言学主导的领域本体构建在实际应用中依旧会受到较大的限制。
1.2 金融领域本体建模
本体作为一种能够在语义和知识层次上描述信息系统的建模工具,被广泛应用于各领域的知识表示与关联中。在特定的金融领域中,好的本体模型作为金融知识表示的模式层可以很大程度上满足金融行业对数据质量和语义关联严谨性的需求[27],因此也受到该领域学界业界的广泛关注。现有的金融本体中最为知名的是美国企业数据管理委员会(Enterprise Data Management Council,EDM Council)主导,通过众包方式构建的FIBO(Financial Industry Business Ontology)。FIBO作为领域本体,定义了金融基本概念(FBC)、金融指标(IND)、金融实体(BE)、证券和股票(SEC)以及贷款(LOAN)等领域内的实体及其关系,并且在构建中也运用了层级化的思想。然而,FIBO尚处于本体开发周期的初级阶段[28],主要对基本术语进行规范和共享,对金融知识的关联表现一般。Browne O等[29]对FIBO进行了扩展,将以前未映射的股票和债券纳入其中,并开发了数据管理框架,但这一改进只部分解决了数据交换的问题,多层次语义无法关联的问题依旧存在。
此外,Ren R等[30]基于金融新闻库构建了特定金融领域本体,該本体试图存储所有与金融新闻相关的重要信息,其语义表达能力较强,但由于缺乏规范性的构建流程,本体涉及的范围边界模糊、收集的概念颗粒度不适当,难以大规模运用;Yang B[31]提出物流金融风险本体论OntoLFR,并构建了物流金融风险本体论模型,以适应风险在预警和事前控制中的可变性、复杂性和关联性,虽然该本体构建目的明确,但领域知识的揭示需要借助来自上层的知识体系及相关领域的大量概念,而该模型没有提供规范化的标准,难以与相关领域集成;强韶华等[32]基于本体的规则推理技术和案例推理技术构建了金融事件本体,并建立基于本体的主题事件案例库设计案例推理(CBR)表示、检索与重用,其优点在于融合了金融舆情数据并考虑了本体推理,但其在金融领域属性设计、基于本体的CBR+RBR关联模型设计上均存在一定的缺陷,并且本体案例库的设计规模较小,存在与实际应用脱节的问题。
综合现有研究可以发现,虽然领域本体的构建方法和应用趋于多元化,但是由于知识系统的复杂性,在对领域异构知识的共享与重构时,未能很好地完成信息的广泛组织和有效关联。目前的领域本体构建思路偏重于专业性和针对性,但依旧存在本体难以服用和集成、概念体系不规范等问题,而且忽略了本体作为一种可共享的概念集合所应当具备的通用性与集成性。在金融领域,本体对于金融知识组织和表示具有很强的指导意义,但目前的构建过程并不十分规范;此外,现有的金融本体中影响力较大的FIBO本体不完全适用于中国的金融体系,且该本体包含范围太广,并没有聚焦于特定的细分领域,因此不能很好地刻画细粒度的概念和知识。综上,本文以金融证券领域为例,基于现有研究的不足,重点解决的核心问题是:如何利用和改进多层本体框架,构建多层次、多维度的领域本体,提供一组具有正确类别、层级结构和关联关系的金融证券领域概念语料库,以便更好地管理金融领域知识、支持经济决策。
2 多层本体立方体模型设计
2.1 概念定义
在数据库领域中,数据立方体是数据仓库和联机分析处理研究领域的一种核心数据模型,它可以多维度表征数据特征,现有的很多研究借鉴了这一思路,如Li J等[33]通过构建语义—空间—时间数据立方体(Semantics-Space-Time Cube),探讨了语义、空间和时间这3个异构信息方面的相互关系,并得出文本语义随时间和空间的变化规律;Esteban P E等[34]使用基于RDF数据立方体词汇表的多维模型方法,向开放链接数据添加值,完成了数据多维度特征的分析;师智斌[35]则借助FCA理论,以形式化的概念和概念层次为基础进行了高性能数据立方体及其语义研究。由此可见,数据立方体的本质在于多维度、多刻面的特征表示。
本体作为知识库的表现形式之一,融合多维度信息可以从不同侧面展示本体知识的隐含特征,因此可以利用数据立方体的结构形式进一步丰富其语义表达的多维性和灵活性。本文依托数据立方体概念,将能够多维表征关联知识实例的本体模型定义为“本体立方体(Ontology Cube)”,具体定义如下:
定义1:本体立方体(Ontology Cube)是指由维度构建出来的多维知识表示和存储空间,是一种为了满足用户从多角度多层次进行知识查询和分析的需要而建立起来的基于事实和维的本体实例模型,其包含了所有要检索分析的领域知识实例和关系,所有的关联知识的操作都在立方体上进行。
表1对数据立方体和本体立方体涉及的基本概念、存储对象、主要解决的问题和典型应用场景进行了详细的对比介绍。
2.2 构建思想
框架布局和层次设计是在复杂性概念和具有结构特征的实例之间构建关系系统的前提。金融证券行业是对信息高度敏感的行业,也是信息源高度异构、知识体系最为庞杂的代表行业之一,因此需要建立一种能够多层次且多维度刻画领域知识的本体结构,以便能够实现对复杂知识体系规范而明确的描述,从而增强概念间的语义关联。对此提出以下构建思想:
1)借鉴由任守纲等提出的层次式领域本体模型[36],面向不同层次的知识体系并遵循自顶而下的本体构建原则,构建由基础层、概念层和实例层构成的3层领域本体模型。其中,位于基础层的顶层本体提供了领域特征的普遍联系,揭示了领域知识在更高语义层次上的关系,为概念层本体提供了底层抽象;概念层的概念本体作为衔接抽象概念与应用实例的中间层次,能够描述领域基本特征的明确化概念并针对领域核心知识类别进行规范化和明确化的表示;而应用本体作为实例层,可以实现领域内的具体实例集成表示。
2)根据Zhang L L等的划分依据,将实例层的各金融实体划分为行业、企业和内部环境3个维度[37],形成本体立方体结构。三者从不同的范围和方向搭建了领域知识框架,其本身也作为类与类的关系(行业—企业关系、行业—内部环境关系、企业—内部环境关系)包含在本体之中。
行业(Industry):“行业”维度或称为“市场”维度,从宏观层面描述金融证券相关实体、属性及其关系。金融证券行业/市场的主要属性包括名称、行业经营状态、行业政策、行业能力(市场容量、输出值和业内的公司数量),行业财务指标、行业的生命周期(初创期、成长期、成熟期和衰退期)及行业系统性风险等。
企业(Company):“企业”维度从中观层面描述领域知识。其主要属性包括公司或机构名称和数量,公司或机构治理结构的股权结构、管理结构、贸易联盟结构,企业/机构竞争合作,企业财务指标、公司的生命周期、企业外部风险等。其中企业财务指标是一个比较宽泛的概念,具有比较明显的数值属性。财务指标及其对应的财务实体通常用来反映财务实体的状态、变化和关系,其属性包括更新频率、时间、数据源等。
内部环境(Inner Environment):“内部环境”维度则是从微观层面进行知识表示。其主要属性包括公司产品架构、公司人员组织结构、产品财务指标(包括增长阶段、产能、销售、价格等)、公司内部文化(公司价值观、公司战略、公司理念等)以及企业内部风险等。
具体的多层本体立方体模型如图1所示。在该模型中,基础层和概念层不具有维度倾向性,仅具有层次关系;实例层本体则被定义为由行业—企业—内部环境3个维度组成的立方体结构,其中由概念映射的实例集合可以构成特定的子立方体,每個子立方体内存储着由概率值作为空间坐标的实体和关系。此外,所有概念和实体可跨层映射与关联。
3 多层金融股权本体立方体构建
3.1 研究框架
本文依托前述多层本体立方体的设计思路和本体规范化构建流程,分别从知识建模、知识挖掘、知识抽取和知识关联的视角逐步完成多层、多维本体立方体的半自动化构建,并提出如图2所示的研究框架,具体研究步骤如下:
1)数据获取与预处理:获取证券行业报告、企业研报及公告、财经新闻短讯、证券领域专业术语及相关学术文献等多源异构数据,通过分词、去停用词等预处理形成初始语料库。
2)知识建模与表示:结合领域专家知识完成对描述通用知识特征的上层本体构建,然后复用FIBO本体框架,并用OWL语言进行描述和建模。
3)知识组织与挖掘:利用LDA模型对概念主题建模,并对概念进一步进行BIRCH层次聚类,在继承上层本体的基础上实现层次概念及关系的组织。
4)知识抽取与扩展:首先基于依存句法实现知识实例的语义三元组抽取;而后针对特定的实体和关系利用FinBert深度学习预训练模型实现实体和关系的进一步抽取和扩充。
5)知识关联与融合:对概念和实例按构建维度分类,并利用相似度算法计算语义相似性,以确定其空间位置;最后将3层本体立方体结构聚合,完成证券本体立方体的构建。
3.2 知识建模:基础层构建
上层本体可通过四元组O=(C,P,R,X)抽象化表示,其中C表示本体中概念集合,P表示概念属性的集合,R表示概念间关系的集合,X则表示本体公理与规则集合。
以证券领域为例,上层本体的基本概念集合可表示为C={金融主体,金融合约,事件,机构,指标,时间,空间}。其中金融主体是指参与金融活动的个体,如股东、法人、债权人等;金融合约是金融活动得以实施的凭证,如合约文书、口头合约;事件特指在金融活动中金融主体或机构参与的活动,如公司破产、对外投资等;机构主要指从事金融服务业有关的金融中介机构,同时也包含政府机构及合法存在的社会机构等。此外,概念与概念之间除了is-a、is-part-of、is-kind-of、is-instance-of、is-attribute-of等继承与依赖关系,还可以人为定义不同实体概念的关系,实现概念间的初步关联,如在企业—企业关系中,R企业={同业资金往来,控股,合作,竞争}。上层本体公理与规则X代表领域本体内存在的事实,可以对本体内类或者关系进行约束,如机构、事件等属于金融概念的范围。在实际构建与建模过程中,由于开发人员知识背景以及人力、时间的限制,将每一个相关的领域本体都进行构建是不现实的;考虑到国外已经构建了成熟的金融领域本体且不同语言描述的本体在基本概念定义上大体相同,为提高本体构建效率,研究复用了FIBO本体。FIBO本体虽然是领域本体,但主要关注金融全领域的普遍联系[38],并涵盖了证券子领域的通用概念、属性与关系,可以指导上层本体的构建。
构建上层本体的核心是完成对通用知识的表示,研究采用OWL语言完成通用概念的建模。基本元素在知识表示过程中首先需要对信息资源和知识资源进行面向对象的抽象,以提取概念及其关系;其次需要按照OWL的语法要求构建相应的类(包括概念、属性、关系等)并将类存储在OWL类型声明文档中。
在基础层,OWL强大的表达能力还得到了许多概念构造函数和公理的支持,除了可以通过“subClassOf”和“subPropertyOf”形成概念的层级结构,通过“domain”“range”“equivalentProperty”“hasValue”等描述概念间的约束关系外;还可以通过“equivalentClass”“sameAs”“inverseOf”形成语义关联关系;通过“intersectionOf”“unionOf”等形成概念的逻辑组合;通过“uniqueProperty”“transitiveProperty”等实现概念及其关系的公理定义[39]。上述定义还为概念层和实例层的构建提供了规范的表示框架,便于相关概念和实体的规范表示与扩充,从而从更高的语义层面指导概念层和实例层的设计与实现。
3.3 知识挖掘:概念层构建
3.3.1 概念主题建模
目前在金融领域,现有的结构化语料尚未达到能够构建共享概念模型的程度,因此,利用主题建模的方式挖掘非结构化文本信息有助于领域概念的识别。本文采用LDA主题模型构建特征词项,经过聚类得到的特征词可以为概念主题划分和层级聚类奠定基础。
为保证文本来源的多样性,并能够从行业、企业和内部环境的角度分别进行主题建模,本文爬取百度百科金融证券领域相关词条325个,调用Tushare接口获得上市公司简介及主营业务4 270条,获取公司研报及证券行业短讯共1 000条,此外还人工收集了350条专业术语解释,共同作为主题建模的语料库。
在模型参数设置方面,采用专家咨询法集合困惑度判断法设定主题数K=5,learning_decay=0.7,learning_offset设为50,训练结果如表2所示。
进一步地,利用pyLDAvis实现主题建模可视化,如图3所示。图中左侧气泡分布表示不同主题,圆圈大小代表每个主题的出现频率,而主题间的位置远近表达了主题接近性。距离越大,说明主题之间的差异性越高,困惑度也就越小。图3右侧则显示了Topic1前30个特征词。其中浅蓝色表示该词在整个文档的权重,红色表示该词在当前主题中所占的权重。此外,超参数λ可以调节特征词的显示,λ越接近1表示该主题下更频繁出现的词与主题更相关;λ越接近0则表示该主题下更特殊、更独有的词与主题更相关。
3.3.2 概念层次聚类
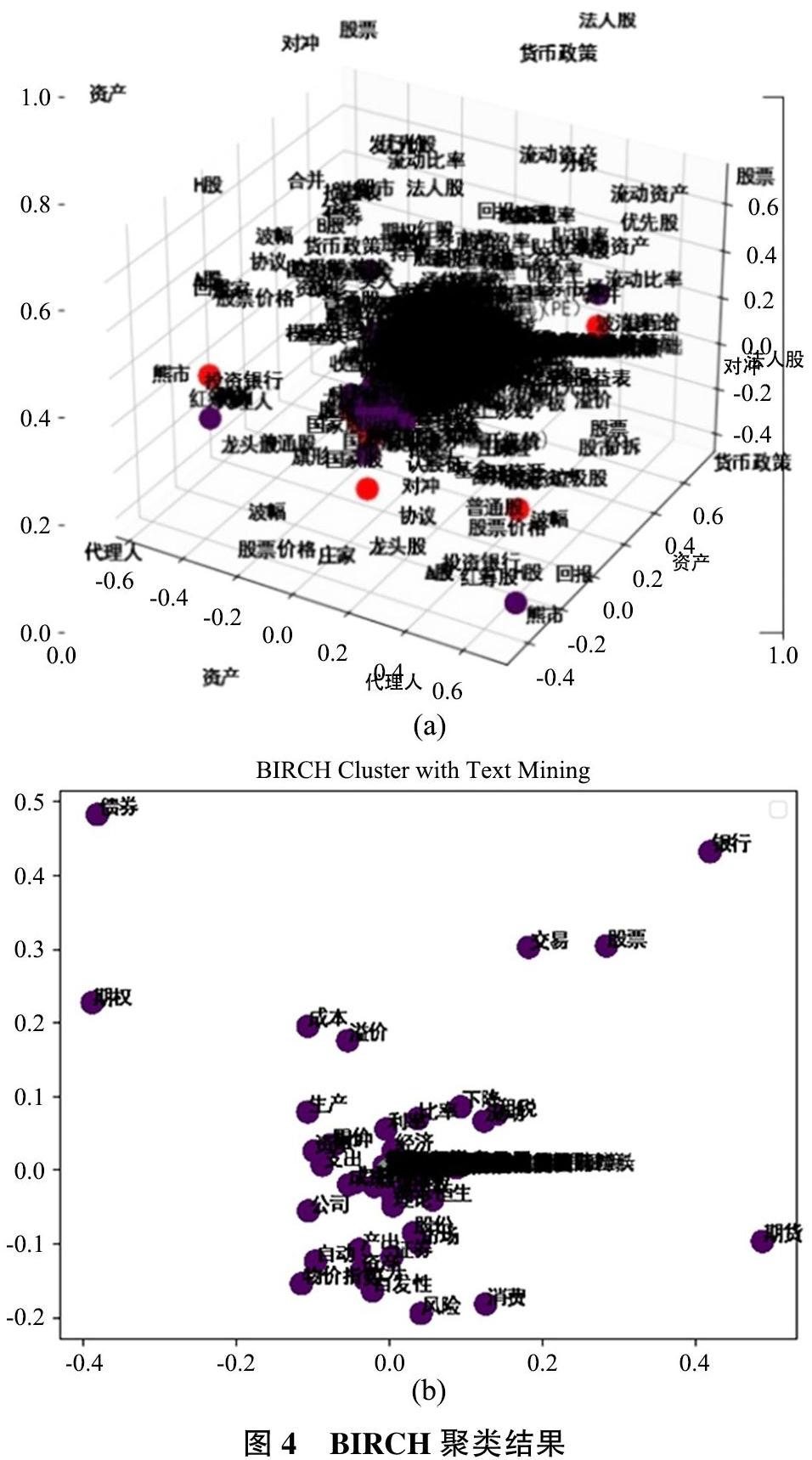
基于概念主题建模得到了大量的实体标志词,然而各概念间的层次关系较为混乱,无法构建出结构清晰的概念本体模型。基于此,在上层本体的框架基础上利用LDA主题模型和语义特征构建自定义特征词典获取具有代表性的特征词,然后通过BIRCH聚类算法划分领域内概念的层次关系。BIRCH算法是一种增量的聚类方法,首先用自底向上的层次算法,然后用迭代的重定位来改进结果,且聚类效率很高。实验的具体步骤如下:
1)层次聚类。BIRCH聚类算法无需提前设定聚类数目,初始聚类结果设定为与前述主题相等的5个簇,如图4(a)所示,可以看到此时概念间的父类子类关系并不明显。为了能够将主题建模得到的词向量达到较好的层次聚类效果,将得到的聚类数目最多的簇再次聚类,以此类推共迭代10次,图4(b)展示了最后一次迭代的聚类结果。
2)聚类评价。研究采用轮廓系数(Silhouette Coefficient)对聚类结果进行评价。如式(1)所示,轮廓系数S(i)结合内聚度a(i)和分离度b(i)两种因素,当S(i)趋近于1时,说明样本i聚类越合理。最后一次迭代时的轮廓系数为0.4577,表明聚类结果已较为理想。
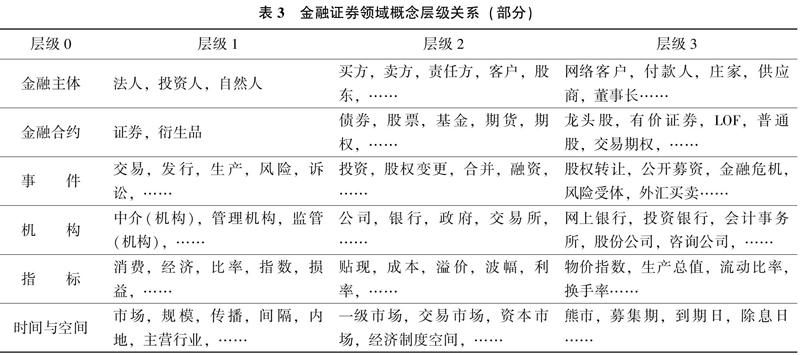
3)层级与类别划分。将词向量对应到具体的词语,从最后一次的迭代结果开始向上追溯,根据每次的聚簇形状,结合词语所表达的概念范畴可大致划分成3層概念集合(其中第0层继承自上层本体,不包含在内),具体的层级关系如表3所示。
从表3可以发现,基于上层本体框架的层级聚类能够在一定程度上表征领域的层级关系,但由于金融领域的特殊性,各术语概念间的层级关系并不十分明显,且概念间存在多种潜在的关联关系如时空关联、事件关联等,导致BIRCH聚类效果并不突出;也正因如此,构建多维度的本体立方体模型显得十分必要。
3.4 知识抽取:实例层构建
实例层的应用本体引用和继承上层本体集成的模块,并通过对概念本体的映射,实现领域内的实例集成表示与本体扩充。然而,要构建应用本体需要对大量的证券领域实体和非层级关系进行抽取,传统的语言学模板方法需要构建大量的规则,虽然准确率较高,但不适应数据量较大的情况;因此后来又陆续提出了基于句法分析的关系抽取和基于深度学习的监督/半监督关系抽取方法。本文先基于依存句法规则进行开放域三元组抽取,而后根据提取结果,借助深度学习框架完成限定域实体的辅助抽取,从而实现了应用本体的进一步扩充。
3.4.1 基于依存句法的开放域实体关系抽取
依存句法分析(Dependency Parsing)能够根据词性及词间的位置关系判断句中各成分的语法依存关系,因此,基于依存句法的实体关系抽取主要依赖于句中的谓词,当以谓词为代表的关系中含有论元时,能够提取出语义三元组。本文采用LTP自然语言处理工具实现多源文本数据的三元组有效提取,通过设置抽取规则,如表4所示,为扩充本体实例及其关系提供技术支持。
对于抽取的结果,将表义模糊的实体和非表意关系进行人工剔除,最终得到32 627个实体及其关联的1 928种语义关系,部分抽取结果如图5所示。
3.4.2 基于深度学习的限定域实体抽取
开放域的抽取固然可以有效地扩充实体和关系,然而一方面由于获取的头尾实体及关系类型过多导致难以有效组织应用本体结构;另一方面基于句法分析得到的实体虽然表义明确但过于冗长,且一些证券领域的专有名词和公司名未能被很好地识别出来。对此特别对公司股票、组织机构、人名地名、主营产品和风险事件进行了实体识别。
本文将实体识别环节视为一个序列标注问题,通过BIO标注法对随机抽取的2 000条文本进行人工标注,然后使用FinBERT+Bi-LSTM+CRF实体标注深度学习框架进行训练。具体来说,首先利用FinBERT预训练模型对词向量进行训练,而后将生成词向量通过与定义的实体标签信息进行合并编码作为输入到Bi-LSTM模型加强词性分析,捕捉前后文的双向语义信息,最后通过CRF解码完成命名实体识别任务。
本文将实验数据按照7∶1∶2分为训练集、开发集和测试集,设置learning rate=0.001,banch_size=32,epochs=20。最终的实验结果如表5所示。
上述结果可以看出,机构名和公司名的识别效果较好,而风险识别结果较差,这与标注样本的规范性和实体在文本中所占比例有关。研究对语料中未标注文本进行了实体抽取,人工去重和剔除错误结果后,共抽取出23 245个实体,完成了对领域实体的扩充。
3.5 知识关联:多层本体立方体聚合
3.5.1 文本分类与空间向量表示
多层本体的聚合完成了多层次、细粒度的金融领域知识表示,但是对于证券领域内大量跨层级实体和非层级关系的表征依旧显得无能为力。比如“信用风险”在不同的语境下的风险对象可能是企业或个人,甚至可能是整个产业链;再如“合作”关系的主体可能涉及到不同层次下的金融主体与金融机构。由此可见,概念本身的多义性决定了其能够在不同维度表征不同含义,而并非只能划归到单一的维度或类别中。本体立方体可以将实体表示为基于概率的三维向量,从而加强语义关联的能力。
基于依存句法的三元组较好地保留了语境和语义信息,可以作为分类的原始语料。因此,研究将提取的语义三元组视为一个整体进行分类,并用概率表示头实体和尾实体的分类结果;对于相同的实体,则取平均值作为最终的空间向量值。得到的结果将其进一步划分在不同的子立方体内,完成实体的最终定位。
在实验中,依照2.2节的维度划分情况将随机抽取的8 000个三元组分为行业(市场)、企业和内部环境3类,然后将数据按8∶2分为训练集和测试集。实验采用Keras+Finbert深度学习框架完成分类任务,设定banch size=16,epochs=5,采用Adam优化器,实验结果如表6所示。
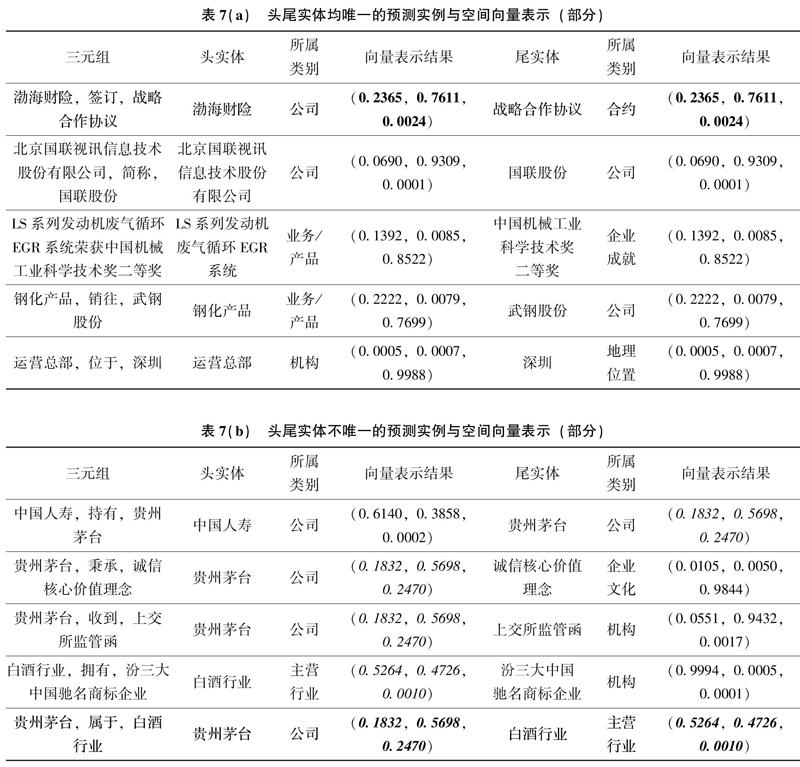
实验结果表明,对于三元组的维度分类总体效果是符合预期的。在最后的预测任务中,直接用Softmax激活函数所表达的分类概率作为每个三元组的头实体和尾实体的坐标值。例如三元组(渤海财险,签订,战略合作协议)被分为“行业/企业/内部环境”的概率分别为0.2365/0.7611/0.0024,那么头实体“渤海财险”和尾实体“战略合作协议”的相对坐标均为(0.2365,0.7611,0.0024),只是由于二者分属不同的概念类别,因此被存储在不同的子立方体中;再如(贵州茅台,属于,白酒行业)这一三元组整体的输出概率为0.0533/0.9446/0.0021,但由于头尾实体在语料库中均出现多次,所以二者最终的相对坐标以平均值的形式被表征出来。表7分别呈现了在语料库中头尾实体唯一(a)和不唯一(b)两种情况下部分预测实例和基于概率的空间向量表示结果。
3.5.2 多维本体关联与融合
三层本体通过语义数据映射模型将所有的概念和实体逐一映射、完全关联。在构建过程中,从上而下的构建模式将知识元素映射到底层的实体、关系及属性,大大增强了本体结构的稳定性与可扩展性;而在应用过程中,自下而上的归纳与融合能够逐步提炼出缺失的金融证券知识概念与关系模式,并能够进一步利用语义数据映射补充至上层本体。此外,连接不同层级和不同子立方体之间的关系對于完整、多维的概念知识描述尤其重要。基于表7的实例及空间向量表示,图6直观展示了多层本体立方体的映射、关联与融合结果。
为了便于本体的存储与可视化,研究选用本体构建工具Protégé5.5.0版本对证券领域本体进行编辑,通过OWL语言对本体进行描述,部分概念及关系如图7所示。
在概念层到应用层的实例化过程中,研究采用D2RQ技术实现关系数据向RDF格式的转换,并将实例化数据结果存储在RDF数据库graphDB中。在数据映射技术的基础上,对本体中术语和数据源抽取知识中词汇的映射关系等加以构建处理,从而促使不同的数据源的数据能够综合在一起,不同源的实体也会指向现实的同一个客体[40],最后融合而成的实例知识库提供了一种存储和管理的新方式。
3.6 多层本体立方体评价
本体的评价是领域本体构建非常重要的环节,能够帮助判断本体是否符合领域需求以不断迭代改进。目前尚未由通用而规范的本体评价方法,本文借鉴了黄奇等[41]对本体映射系统的评价体系,将评价的维度分为内容多样性、结构深入性、语义关联性和本体实用性4个方面,每个层面采取定性或定量的细化评价方法。
3.6.1 内容多样性
在内容多样性的评价层面,研究借鉴了Onto QA本体评价方法。该方法是Tartir S等[42]在2005年提出的一种评价本体通用性的方法,评价指标包括类的丰富性(CR)、关系丰富性(RR)、属性丰富性(AR)等,如表8所示。
从表8的评价结果可以看出对证券领域本体定义的类和概念相对丰富,并能够较为充分地体现出关系多样性,但是概念的属性相对较少,证实了金融证券领域概念分散、关系复杂且基础属性较少的特点。
3.6.2 结构深入性
结构深入性体现了本体在结构关系层面是否充分挖掘,并直接影响了语义层面的关联性。本文通过设定“多层”本体的概念丰富了本体的结构表现形式,同时各层本体具有完整的映射关系,如层级关系映射、类和实例映射。此外,实例层的立方体结构直观地刻画了各实例的维度倾向性和距离关系,为本体结构提供了新的设计思路。
3.6.3 语义关联性
语义关联性是对概念实体丰富性和结构深入性的扩展,也是本文的核心内容。语义关联性可以由层次聚类、关系抽取和维度分类的效果直接体现。层次聚类结果表明,证券领域概念层级关系在文本信息中较难发现,仍需依赖人工梳理;关系抽取结果反映出领域关系的多样性,基于句法分析的抽取虽然使得部分实体过于冗长,但最大程度地保留了语义信息;维度分类和实体的空间映射作为本文的创新之一,对于丰富各实例的语义表达起到了一定的增强作用。
3.6.4 本体实用性
实用性是从使用者的角度出发对构建的本体进行全面的评价,它是对内容、结构和语义的综合评判。在实用性层面,借鉴黄奇的评价指标,如表9所示,结合实际情况进行合理的解释说明,并通过公式φ=∑4i=1αiβi加以量化。
对指标的量化打分需要领域专家的介入,本文构建的本体实用性评分为0.8104,说明具备一定的理论研究和应用价值。然而上述关于实用性的量化指标依旧过于主观,未来针对特定领域的本体评价体系仍需进一步完善。
4 结论与展望
金融大数据的价值源于其蕴涵的广泛存在的知识关联,而传统的金融大数据的扁平化组织忽略了数据内在的联系,也没有考虑多源异构数据的有效组织与融合。本文依托于本体及其构建理论,针对传统单层领域本体知识表示模型无法进行规范而明确描述的弱点,构建了包含基础层、概念层和实例层在内的多层领域本体,同时结合证券领域特殊性,考虑“行业—企业—内部环境”三级维度概念对领域知识的影响,借鉴数据立方体概念,提出并构建了“多层金融领域本体立方体”知识表示模型,豐富和扩展了本体构建的理论与方法论体系。在具体的构建过程中,按照知识获取、挖掘、抽取、关联及存储的知识管理周期思路,并依靠主题建模、层次聚类、关系抽取和维度分类等自然语言处理技术实现了证券领域本体架构的半自动化构建,具有一定的应用价值。
当然,任何领域的知识几乎都是无穷尽的,领域之间也总是存在交叉性,而且领域内的知识也是动态发展变化的,因此本文构建的本体存在一定的局限性。在数据获取方面,虽然语料来源丰富,但对文本内容的真实性和有效性未作处理,各来源比例也未进行规范;在数据处理方面,由于处理的数据规模有限,加之证券领域概念复杂分散,因此无法全部覆盖,需要人工干预。未来将会对语料来源进行进一步的规范说明,并继续探索领域本体自动构建的相关算法;此外,随着知识图谱的不断发展,在后续研究中可以考虑将构建的本体与知识图谱直接映射,从而更好地应用在领域知识的表示、分析、关联与融合中。
参考文献
[1]钱学森,于景元,戴汝为.一个科学新领域——开放的复杂巨系统及其方法论[C]//中国系统工程学会第六次年会,1990:526-532.
[2]Hasan M M,Popp J,Oláh J.Current Landscape and Influence of Big Data on Finance[J].Journal of Big Data,2020,7(1):1-17.
[3]Zhang P,Yu K,Yu J,et al.QuantCloud:Big Data Infrastructure for Quantitative Finance on the Cloud[J].IEEE Transactions on Big Data,2018,4(3):368-380.
[4]丁晓蔚,苏新宁.基于区块链可信大数据人工智能的金融安全情报分析[J].情报学报,2019,38(12):1297-1309.
[5]陈云.金融大数据[M].上海:上海科学技术出版社,2015.
[6]林天华,张倩倩,祁旭阳,等.证券大数据分析研究[J].计算机技术与发展,2020,30(10):179-186.
[7]李善平,尹奇韡,胡玉杰,等.本体论研究综述[J].计算机研究与发展,2004,(7):1041-1052.
[8]刘仁宁,李禹生.领域本体构建方法[J].武汉工业学院学报,2008,27(1):46-49,53.
[9]El-Diraby T E.Domain Ontology for Construction Knowledge[J].Journal of Construction Engineering and Management,2013,139(7):768-784.
[10]张文秀,朱庆华.领域本体的构建方法研究[J].图书与情报,2011,(1):16-19,40.
[11]付苓.大数据环境下领域本体构建框架研究[J].图书馆,2017,(11):66-71.
[12]丁晟春,李岳盟,甘利人.基于顶层本体的领域本体综合构建方法研究[J].情报理论与实践,2007,(2):236-240.
[13]Singh A,Anand P.Automatic Domain Ontology Construction Mechanism[C]//Intelligent Computational Systems.IEEE,2013:304-309.
[14]Yan Y,Jiang Z,Liu X,et al.An Intelligent Approach for Construction Domain Ontology[C]//IEEE International Conference on Automation & Logistics.IEEE,2009:1283-1288.
[15]王思麗,杨恒,祝忠明,等.基于BERT的领域本体分类关系自动识别研究[J].情报科学,2021,39(7):75-82.
[16]肖奎,谭小虎,吴天吉.一种面向领域的本体自动构建方法[J].小型微型计算机系统,2013,34(7):1514-1517.
[17]Gomez-Perez A,Manzano-Macho D.A Survey of Ontology Learning Techniques and Applications[J].Technical Report of the OntoWeb Project:Deliverable 1.5,2003.
[18]陈刚,陆汝钤,金芝.基于领域知识重用的虚拟领域本体构造[J].软件学报,2003,(3):350-355.
[19]Shih C W,Chen M Y,Chu H C,et al.The Enhancement of Domain Ontology Construction Using a Crystallizing Approach[J].The Experts Systems with Applications,2011,38(6):7544-7557.
[20]Sanchez D,Moreno A.Learning Non-taxonomic Relationships from Web Documents for Domain Ontology Construction[J].Data & Knowledge Engineering,2008,64(3):600-623.
[21]郑姝雅,黄奇,张戈,等.面向用户生成内容的本体构建方法[J].情报科学,2019,37(11):43-47.
[22]邓诗琦,洪亮.面向智能应用的领域本体构建研究——以反电话诈骗领域为例[J].数据分析与知识发现,2019,3(7):73-84.
[23]Shamsfard M,Barforoush A A.The State of the Art in Ontology Learning:A Framework for Comparison[J].Knowledge Engineering Review,2003,18(4):293-316.
[24]Zouaq A,Gasevic D,Hatala M.Towards Open Ontology Learning and Filtering[J].Information Systems,2011,36(7):1064-1081.
[25]Lee C S,Kao Y F,Kuo Y H,et al.Automated Ontology Construction for Unstructured Text Documents[J].Data & Knowledge Engineering,2007,60(3):547-566.
[26]刘萍,胡月红.领域本体学习方法和技术研究综述[J].现代图书情报技术,2012,(1):19-26.
[27]Ruan T,Xue L J,Wang H F,et al.Building and Exploring an Enterprise Knowledge Graph for Investment Analysis[C]//Proceedings of the International Semantic Web Conference.Heidelberg:Springer,2016:418-436.
[28]Kayed A,Hirzallah N,Shalabi L A A,et al.Building Ontological Relationships:A New Approach[J].Journal of the American Society for Information Science and Technology,2008,59(11):1801-1809.
[29]Browne O,OReilly P,Hutchinson M,et al.Distributed Data and Ontologies:An Integrated Semantic Web Architecture Enabling More Efficient Data Management[J].Journal of the Association for Information Science and Technology,2019,70(6):575-586.
[30]Ren R,Zhang L L,Cui L M,et al.Personalized Financial News Recommendation Algorithm Based on Ontology[J].Elsevier B.V.,2015,55:843-851.
[31]Yang B.Construction of Logistics Financial Security Risk Ontology Model Based on Risk Association and Machine Learning[J].Safety Science,2020,123(C).
[32]强韶华,罗云鹿,李玉鹏,等.基于RBR和CBR的金融事件本体推理研究[J].数据分析与知识发现,2019,3(8):94-104.
[33]Li J,Chen S M,Chen W,et al.Semantics-Space-Time Cube:A Conceptual Framework for Systematic Analysis of Texts in Space and Time[J].IEEE Transactions on Visualization and Computer Graphics,2020,26(4):1789-1806.
[34]Esteban P E,Candela G,Trujillo J,et al.Adding Value to Linked Open Data Using a Multidimensional Model Approach Based on the RDF Data Cube Vocabulary[J].Computer Standards & Interfaces,2020,68(1):1-15.
[35]师智斌.高性能数据立方体及其语义研究[D].北京:北京交通大学,2009.
[36]任守纲,徐焕良,刘小军,等.层次式本体模型的领域分析与设计方法的研究[J].计算机与应用化学,2009,26(11):1385-1388.
[37]Zhang L L,Zhao M H,Feng Z L.Research on Knowledge Discovery and Stock Forecasting of Financial News Based on Domain Ontology[J].International Journal of Information Technology & Decision Making,2019,18(3):953-979.
[38]Petrova G G,Tuzovsky A F,Aksenova N V.Application of the Financial Industry Business Ontology(FIBO)for Development of a Financial Organization Ontology[J].2017,803(1):012116.
[39]Gruber T R.Towards Principles for the Design of Ontologies Used for Knowledge Sharing[J].International Journal of Human-Computer Studies,1995,43(5-6):907-928.
[40]曹敏,邹京希,唐立军,等.基于知识图谱技术的海量非结构化配网数据集成方法[P].云南:CN107330125A,2017-11-07.
[41]黄奇,范佳林,陆佳莹,等.本体映射系统的评价体系研究[J].情报学报,2017,36(8):781-789.
[42]Tartir S,Arpinar I B,Moore M,et al.OntoQA:Metric-Based Ontology Quality Analysis[C]//IEEE ICDM 2005 Workshop on Knowledge Acquisition from Distributed,Autonomous,Semantically Heterogeneous Data and Knowledge Sources.IEEE,2005.
(責任编辑:孙国雷)
