
基于DCGAN的路面裂缝图像生成方法
2022-01-07 08:51裴莉莉孙朝云孙静李伟张赫
中南大学学报(自然科学版) 2021年11期
裴莉莉,孙朝云,孙静,2,李伟,张赫
(1. 长安大学信息工程学院,陕西西安,710064;2. 石河子大学计算机网络中心,新疆石河子,832003;3. 西安翔腾微电子科技有限公司,陕西西安,710068)
目前国内大批公路都已进入大中型公路改建、扩建和待养护的阶段,养护任务也不断增加[1−2]。在所有出现的路面病害中,裂缝一般最先出现,并会逐步加重或演变成其他病害[3]。随着人工智能技术的快速发展,深度学习方法在路面检测分割等方面都取得了巨大进步[4]。
深度学习是最先进的像素级目标检测方法,但是它依靠大量的样本数据才能实现准确网络训练。若数据集规模较小,则容易发生过拟合现象,这让深度学习框架的可行性受到限制。生成式模型能按照所要求的目标数据分布生成结果[5−6]。GOODFELLOW等[7]提出了生成式对抗网络,该网络能够学习到样本的特征分布,最终生成高质量逼真图像。
在生成式对抗网络(generative adversarial networks,GAN)网络的改进方面,国外的研究起步较早,已出现多种变体[8−9],ARJOVSKY 等[10]针对原始生成对抗网络训练困难、损失函数无法指导模型训练过程、生成样本多样性差等问题,通过引入Wasserstein 距离来改进GAN 模型,从而提升图像生成效果。SHABAN 等[11]提出了一种基于生成对抗网络的新模型StainGAN,不仅消除了原始生成对抗网络对样本图像的依赖,而且实现了与目标域的高度相似性。在应用领域方面,生成式对抗网络作为一种流行的数据集增广[12−13]和生成[14]的手段,已广泛应用于医疗[15−16]、农业生产[17]等众多领域[18−21]。CHOI 等[22]为扩充假指纹数据,提出了一种验证DCGAN生成的假指纹与真实的假指纹相似的方法,实验证明DCGAN生成的假指纹在4个相似度指标上与真实的假指纹相似,可以用来增强假指纹数据。陈俊周等[23]提出了基于级联GAN 的人类面部图像修复方法,最终修复后的面部图像具有更加丰富细节特征。
目前该图像生成技术在道路领域的应用中还比较少,李良福等[24]针对桥梁上宽度很小的裂缝分割难度大的问题,将分割网络结构加入到GAN 的判别器中,形成了一个同时具有超分辨率重建和分割的综合性模型。ZHANG 等[25]基于生成式对抗网络学习裂缝特征,将裂缝和较大尺寸的裂纹共同输入网络进行背景图像转换,克服了图像生成过程中的“全黑”问题。由以上研究可以看出,GAN 网络能够生成特定属性的图像,这对于受损图像的恢复和小样本数据集的增广都具有重要的研究意义和应用价值。
生成式对抗网络虽然得到大幅提升,但还是存在一些问题,例如该网络在公开数据集上需要训练上万张真实图片来生成更加丰富的样本,但在实际工程应用中,尤其是针对特定问题或特定环境下的图像集增广问题的应用还比较少。在公路智能检测方面,目前国内还处于探索阶段,检测车采集的道路图片往往背景复杂且受光线影响严重,裂缝等病害经常难以分辨,深度学习技术尤其是生成式对抗网络在智慧道路领域的应用还有限。DCGAN 模型是近年来一种对GAN 改进比较成功的模型,因此,本文选择该网络对自主采集小样本裂缝图像数据进行训练,生成沥青路面裂缝图像,解决利用深度学习进行路面病害检测工作时训练样本紧缺和丰富性不足的问题,提高后期裂缝检测网络的精度。
1 沥青路面裂缝图像集构建
1.1 图像采集
本文实验采集的图像是沥青路面的横缝和纵缝图像,采集方式主要通过车载运动相机拍摄和人工手机拍摄相结合的方式,采集区域主要包括城市道路和校区内道路,最终采集到沥青路面横纵缝图片共4 146幅,图像采集过程如图1所示。
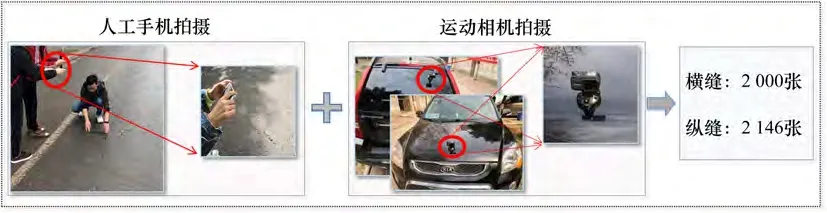
图1 裂缝图像采集Fig.1 Crack image acquisition
1.2 图像处理
由于裂缝图像由不同设备采集且采自多个路段,因此,图像大小和特点不一,同时背景及路况复杂。在没有将原始裂缝图像进行灰度化处理时,生成式对抗网络会学习到原图大量的彩色信息,导致生成的裂缝图像严重失真。为解决该问题,需要对图像进行灰度化处理。同时,运动相机采集的裂缝图像受采集设备自身震动干扰的影响严重,需要使用滤波的方式对路面图像进行去噪。去噪后,为了使网络能够更好地学习到图像的细节特征,采用直方图均衡化和伽马变换的方法增强路面裂缝图像,变换效果如图2所示。
从图2可见:经过均衡化和伽马变换后路面裂缝特征明显增强,但图像背景噪声再次出现,为了去除图中小面积噪点,需要对图片进行二次滤波。处理后路面背景颜色与裂缝颜色差距更加明显,使得生成式对抗网络更容易学习裂缝图像的特征信息。全部预处理流程如图3所示。

图2 裂缝图像增强处理前后效果对比Fig.2 Crack image contrast enhancement before and after effect comparison

图3 裂缝图像处理流程图Fig.3 Flow chart of crack image processing
2 深度卷积生成式对抗网络
2.1 DCGAN网络模型结构设计
分别对生成网络和判别网络进行建模,网络结构如图4所示。
1)DCGAN 生成器网络结构。由图4(a)可以看出:本文采用的生成器网络总共有5层,其中卷积层为4 层,全连接层为1 层。将1 个100 维的且服从(0,1)均匀分布的随机变量作为生成器的输入。首先,该图像通过1 个全连接层得到1 个4×4×1 024 的图像;其次,经过4 个转置卷积层,不断扩大图像;最后,得到生成器输出的裂缝图像。
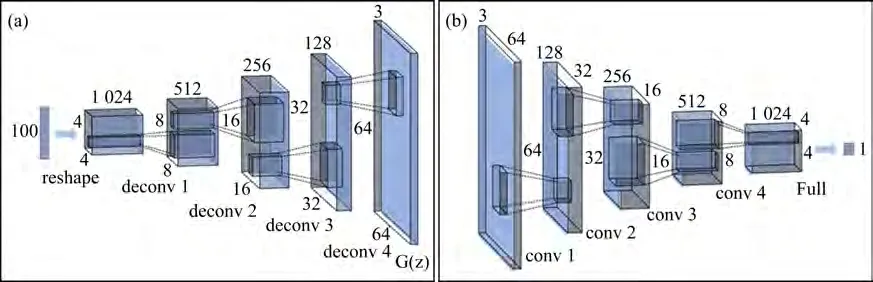
图4 DCGAN网络结构Fig.4 DCGAN network structure
2)DCGAN判别器网络结构。判别器的输入为生成的裂缝图像和真实裂缝图像,输出是1个判断真伪的概率,即这个概率可以判别出输入图像的真伪。由图4(b)可见:输入图像首先通过4次连续的采样,逐渐缩小图像,最后,经过全连接层得到1个代表输入图像真伪的概率。
该模型对原始生成式对抗网络模型的改进主要有:
1)生成器和判别器结构都没有继续采用卷积神经网络的池化层,但判别器延续卷积神经网络的整体架构,而生成器用反卷积层代替卷积层。
2)将批量标准化层(BN,batchnorm)应用在判别器和生成器的每一层。
3)利用1×1卷积层替换所有的全连接层。
4) 在生成器的最后1 层使用Tanh 函数,其他层均采取Relu函数。
5)在判别器的最后1 层使用sigmoid 函数,其他层均采取leakyrelu函数。
2.2 DCGAN网络参数优化过程
在深度学习网络中,复杂网络的输出结果与网络参数的设置有很强的相关性,这些参数及其组合方式的评估标准是使损失函数降到最低[26]。具体过程为:假设有n个样本,网络真实输出结果见式(1),其理想输出结果见式(2),网络的训练过程即寻找能够使损失函数L(y, )ŷ 降为最低的网络参数的过程。

式中:n为样本总个数;y为网络真实输出结果;yn为第n个样本的真实输出结果;ŷ为网络理想输出结果;ŷn为第n个样本的理想输出结果。
每个训练批次的损失函数是第j批次数据的实际值,yj是模型的预测概率。模型的损失函数是由每批次的损失函数求和后再取平均得到,如式(3)所示:
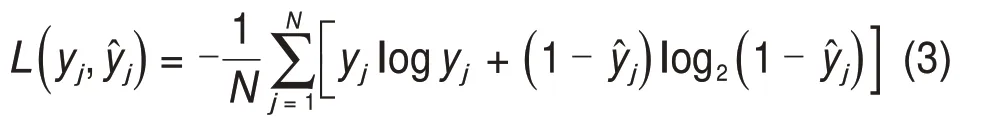
为了找到能够使损失函数降到最小权重w和偏置b,一般采用梯度下降法更新每个网络层中权重w及偏置b,如式(4)~(5)所示。
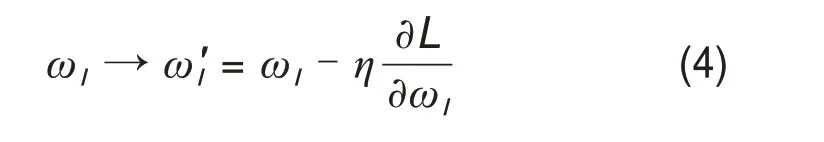
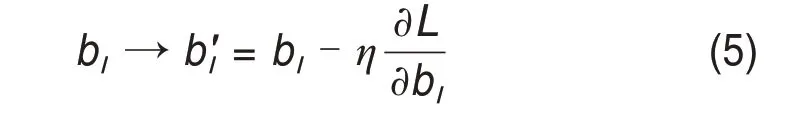
式中:η为学习速率;l表示网络中不同层间某一连接部分;L为式(3)计算得到的损失函数;ω'为更新后的权重;b'为更新后的偏置。
由于同一类训练样本一般是类似的,因此,每个小批次的梯度会近似等于整个训练数据的梯度。计算每个小批次的梯度时,在每步过程中都随机抽取一些数据进行计算,而不是计算所有训练样本的梯度。把整个训练数据随机划分为若干小批次样本输入网络进行训练,可以有效缩短模型的收敛时间。小批次梯度的选取也存在着最优解,当梯度越小时,模型的收敛速度越低;而当梯度越大时,计算每个批次梯度所需要的时间就越长。因此,需要分析训练样本中目标和背景特征以及图像尺寸来确定小批次所包括的最合适图像数量。在每次完全训练结尾时,计算并对比验证集的损失函数,确定能够最小化损失函数的网络为最优网络。
3 基于DCGAN 的路面裂缝图像生成
3.1 实验参数设置及优化器选择
分割预处理之后的裂缝图像,将得到效果较好的1 159张横缝和1 159张纵缝作为网络的输入,按照表1中参数对裂缝图像生成模型进行训练。

表1 改进后DCGAN网络模型参数设置Table 1 Parameters settings of improved DCGAN network model parameters
结合数据集的特点和模型的训练时间选择合适的优化器,从而不断更新网络参数,使得输出结果在一定程度上尽可能达到最优。选择常用的SGD,Adam 和RMSprop 这3 种优化器对模型进行优化,发现对参数进行一次更新时,SGD;Adam和RMSprop所需的训练时间分别为45,32和37 s。同时,Adam是以RMSprop为基础的优化器,增加了纠偏和动量机制,在梯度逐渐稀疏时,Adam优化效果更佳。因此,选用Adam 作为模型的优化器。
3.2 图像生成结果
图5所示为不同迭代次数下DCGAN生成的沥青路面裂缝图像。为更加全面展示不同迭代次数的生成效果,在每组实验生成的图片中,随机选取3张虚拟生成图片作为代表进行展示。由图5 可见:模型在迭代次数为100次时能够生成裂缝图像,但此时生成的裂缝图像网格化程度深且严重失真;在迭代次数为200次时生成的裂缝图像网格化得到很好改善;在迭代次数为300次时生成的裂缝轮廓已经开始显现,但清晰度不够;在迭代次数为400次时生成的裂缝图像背景略微模糊,但裂缝轮廓已经接近真实了;在迭代次数为500次和600次时生成的裂缝图像已经十分接近真实图像。

图5 DCGAN生成的路面裂缝图像Fig.5 DCGAN generated pavement crack image
3.3 图像生成效果评价
对GAN 网络生成的图像质量评价中还没有固定客观的指标[27]。为了客观评价模型的生成效果,本文选用Inception Score 评价指标对CIFAR-10 公共数据集和本文采用的裂缝数据集进行测试,并对生成路面裂缝图像的质量进行定量评价。
经过计算,发现CIFAR-10 公共数据集真实图像的I得分(Inception Score 得分)为11.24±0.12,生成图像的I得分为6.64±0.14;本文裂缝图像集真实图像的I得分为10.56±0.09,生成图像的I得分为5.34±0.15。生成图像的I得分与真实数据集有一定区别但相差不大,可以在一定程度上表征生成的裂缝与真实图像集之间具有良好的相似性和多样性。
为了更直观验证本文工作的有效性和意义,选择Faster R-CNN[28]检测模型作为生成式对抗网络生成的路面裂缝图像质量的评价模型。设计不同训练集验证提出的方法对裂缝检测的实际效果,其中常规增广方式是指图像翻转、平移和镜像的增广方式。
检测平均精度(average precision,AP)是评价深度学习网络对目标检测效果最常用的量化指标,不同训练集训练的精度如表2 所示,由表2 可见:基于DCGAN网络增广的裂缝图像与常规图像增广方法得到的裂缝图像相比,其扩充的数据集质量更好。这2种增广方法都能够明显提升裂缝检测精度,但是对比实验7 中3 000 张真实裂缝图像的结果,可以发现训练精度较高。
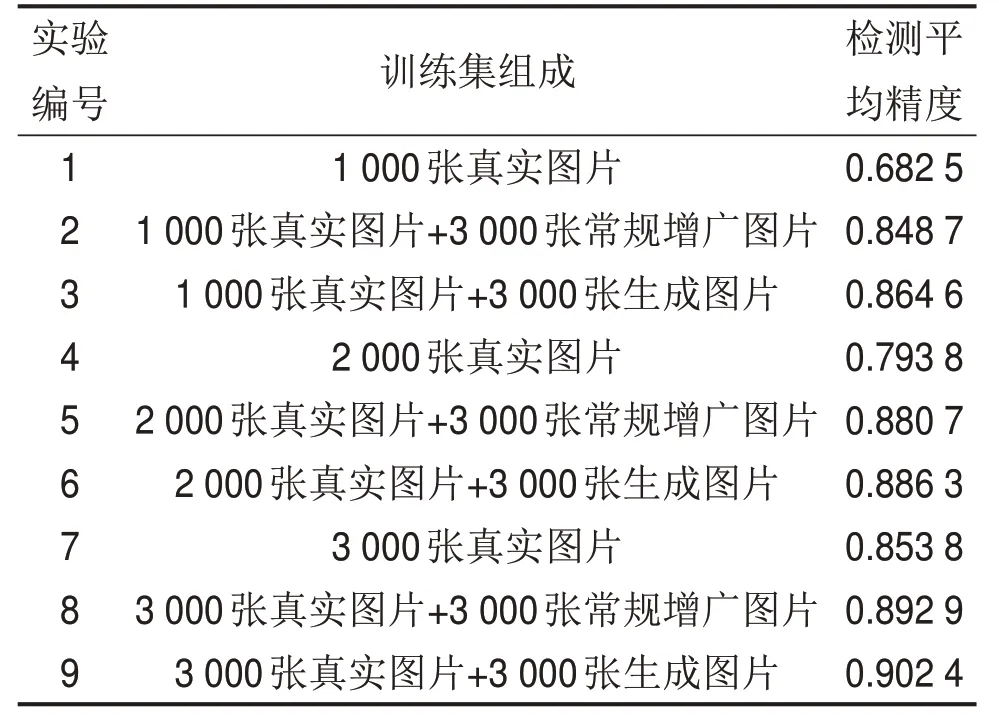
表2 Faster R-CNN验证实验训练集设计Table 2 Faster R-CNN experiment design
利用DCGAN增广后路面裂缝图像数据集训练的Faster R-CNN 模型对横向裂缝和纵向裂缝的检测效果分别如图6所示。

图6 裂缝检测结果Fig.6 Crack detection results
4 结论
1) 对DCGAN 模型的多轮迭代训练和模型优化,能够学习到裂缝有效特征,生成较逼真的路面裂缝图像。
2)通过检测模型对原始图像集、常规增广后图像集以及本文提出的裂缝图像生成模型增广后的图像集分别进行训练,发现在同等训练集情况下,由本文提出的生成模型增广得到的图像集训练检测模型的效果最优。本文提出的方法可以用于路面裂缝图像数据集的增广。
猜你喜欢
建材发展导向(2021年15期)2021-11-05
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
意林·全彩Color(2018年7期)2018-08-13
北京航空航天大学学报(2018年1期)2018-04-20
华人时刊(2016年19期)2016-04-05
海峡姐妹(2016年6期)2016-02-27
专用汽车(2015年4期)2015-03-01
筑路机械与施工机械化(2014年2期)2014-03-01
